 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Jacobian Granger Causal Neural Networks for Analysis of Stationary and Nonstationary Data
May 19, 2022
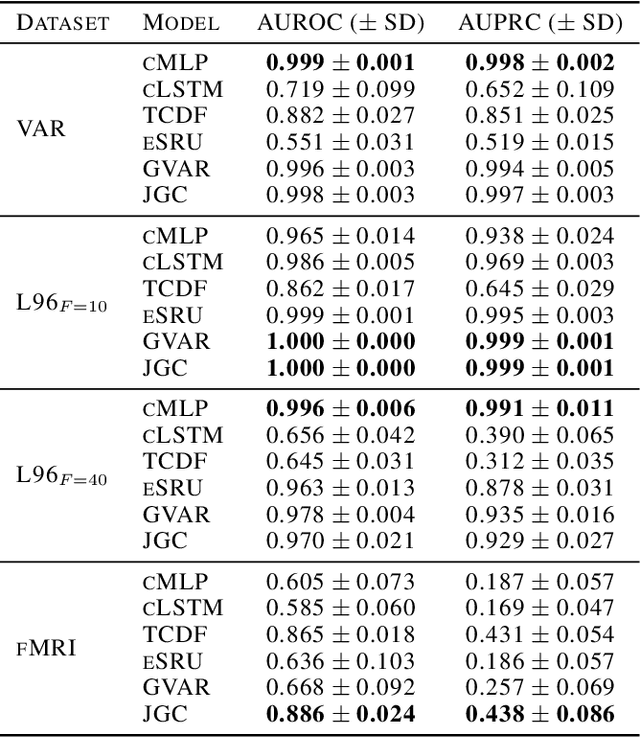
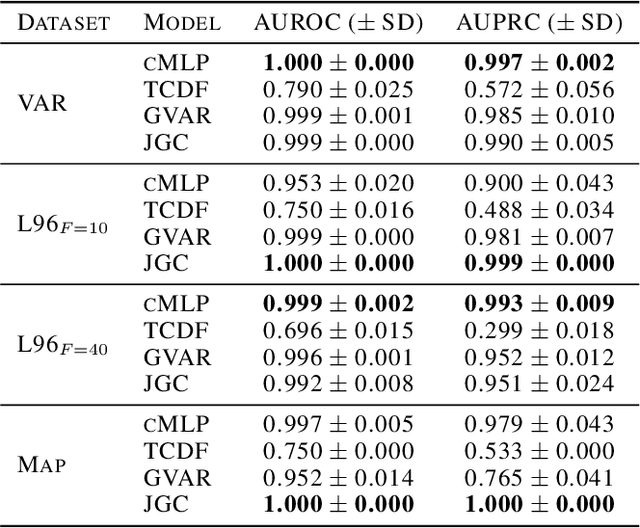
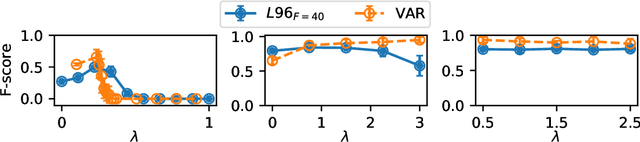
Granger causality is a commonly used method for uncovering information flow and dependencies in a time series. Here we introduce JGC (Jacobian Granger Causality), a neural network-based approach to Granger causality using the Jacobian as a measure of variable importance, and propose a thresholding procedure for inferring Granger causal variables using this measure. The resulting approach performs consistently well compared to other approaches in identifying Granger causal variables, the associated time lags, as well as interaction signs. Lastly, through the inclusion of a time variable, we show that this approach is able to learn the temporal dependencies for nonstationary systems whose Granger causal structures change in time.
Disentangled and Side-aware Unsupervised Domain Adaptation for Cross-dataset Subjective Tinnitus Diagnosis
May 03, 2022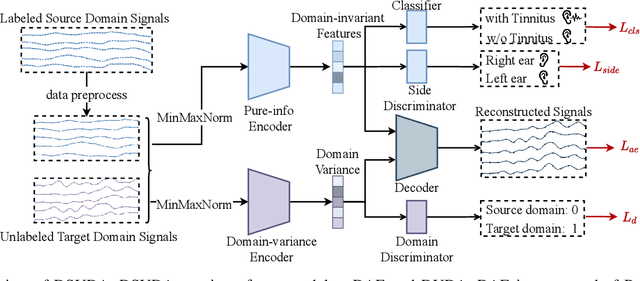
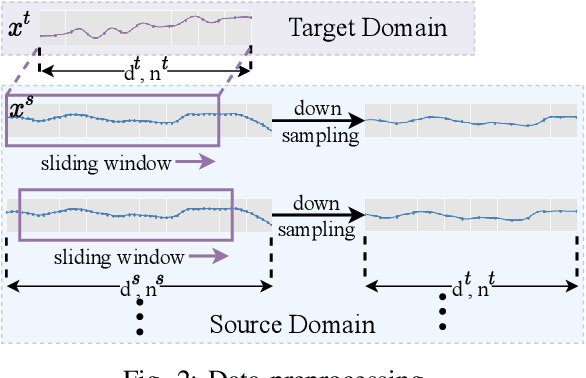
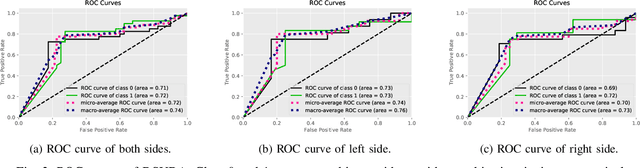
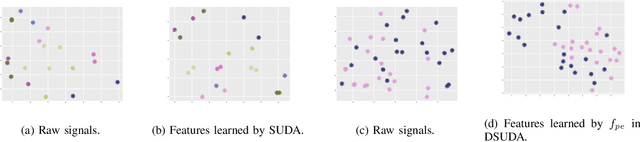
EEG-based tinnitus classification is a valuable tool for tinnitus diagnosis, research, and treatments. Most current works are limited to a single dataset where data patterns are similar. But EEG signals are highly non-stationary, resulting in model's poor generalization to new users, sessions or datasets. Thus, designing a model that can generalize to new datasets is beneficial and indispensable. To mitigate distribution discrepancy across datasets, we propose to achieve Disentangled and Side-aware Unsupervised Domain Adaptation (DSUDA) for cross-dataset tinnitus diagnosis. A disentangled auto-encoder is developed to decouple class-irrelevant information from the EEG signals to improve the classifying ability. The side-aware unsupervised domain adaptation module adapts the class-irrelevant information as domain variance to a new dataset and excludes the variance to obtain the class-distill features for the new dataset classification. It also align signals of left and right ears to overcome inherent EEG pattern difference. We compare DSUDA with state-of-the-art methods, and our model achieves significant improvements over competitors regarding comprehensive evaluation criteria. The results demonstrate our model can successfully generalize to a new dataset and effectively diagnose tinnitus.
Hindsight is 20/20: Leveraging Past Traversals to Aid 3D Perception
Mar 22, 2022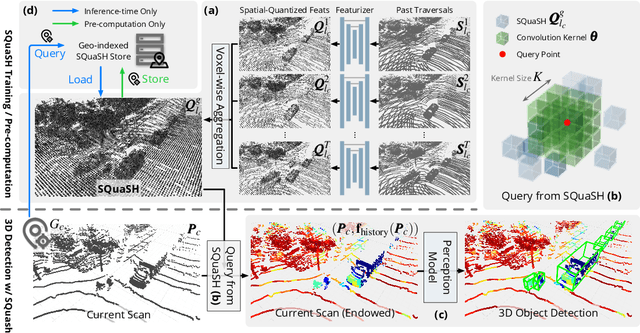
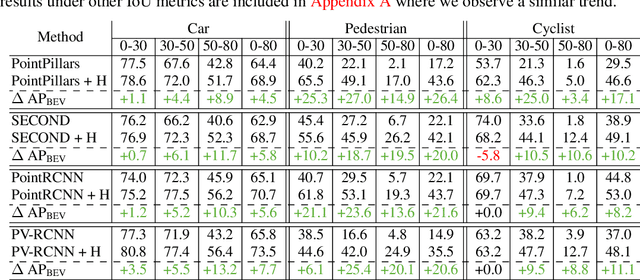
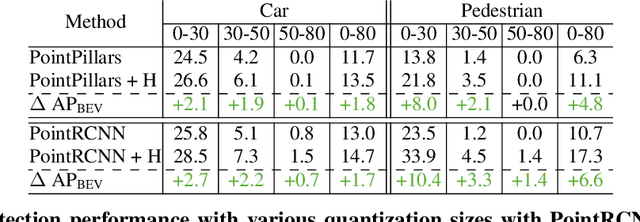
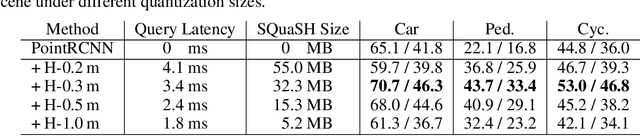
Self-driving cars must detect vehicles, pedestrians, and other traffic participants accurately to operate safely. Small, far-away, or highly occluded objects are particularly challenging because there is limited information in the LiDAR point clouds for detecting them. To address this challenge, we leverage valuable information from the past: in particular, data collected in past traversals of the same scene. We posit that these past data, which are typically discarded, provide rich contextual information for disambiguating the above-mentioned challenging cases. To this end, we propose a novel, end-to-end trainable Hindsight framework to extract this contextual information from past traversals and store it in an easy-to-query data structure, which can then be leveraged to aid future 3D object detection of the same scene. We show that this framework is compatible with most modern 3D detection architectures and can substantially improve their average precision on multiple autonomous driving datasets, most notably by more than 300% on the challenging cases.
PointShuffleNet: Learning Non-Euclidean Features with Homotopy Equivalence and Mutual Information
Mar 31, 2021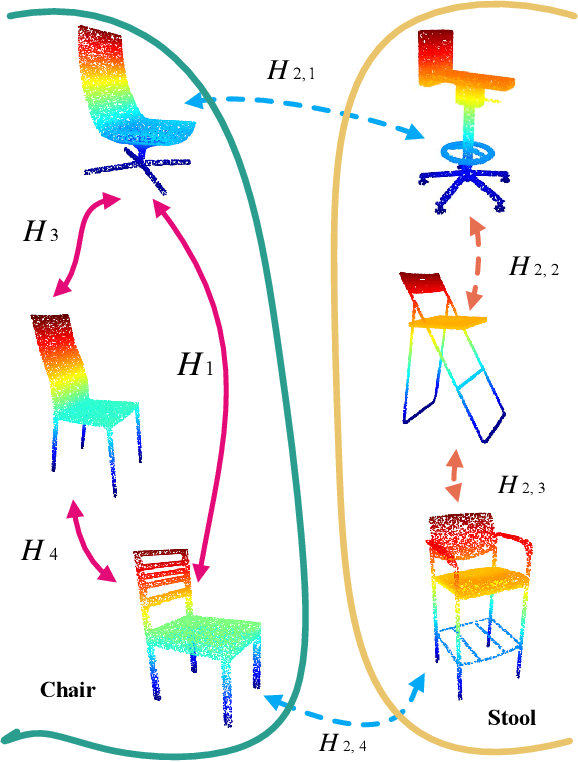
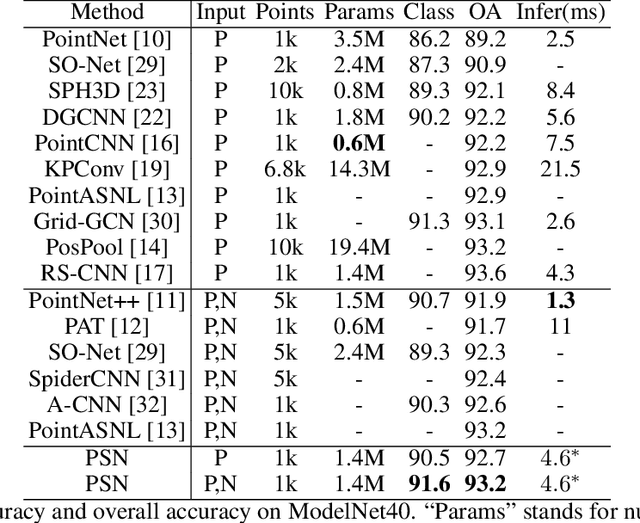
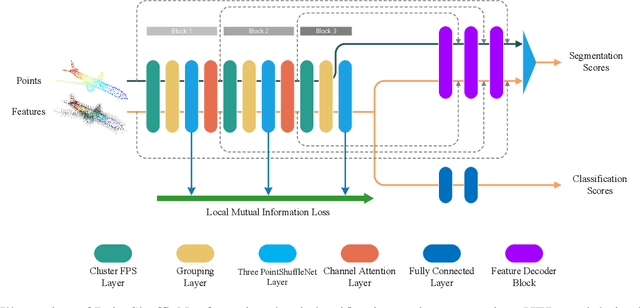
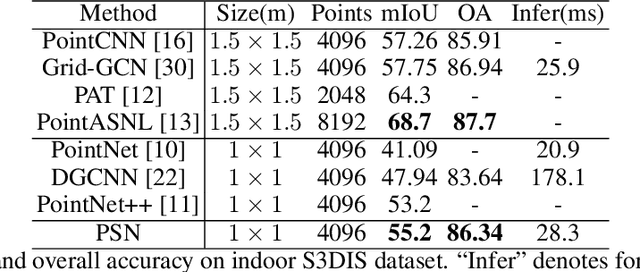
Point cloud analysis is still a challenging task due to the disorder and sparsity of samplings of their geometric structures from 3D sensors. In this paper, we introduce the homotopy equivalence relation (HER) to make the neural networks learn the data distribution from a high-dimension manifold. A shuffle operation is adopted to construct HER for its randomness and zero-parameter. In addition, inspired by prior works, we propose a local mutual information regularizer (LMIR) to cut off the trivial path that leads to a classification error from HER. LMIR utilizes mutual information to measure the distance between the original feature and HER transformed feature and learns common features in a contrastive learning scheme. Thus, we combine HER and LMIR to give our model the ability to learn non-Euclidean features from a high-dimension manifold. This is named the non-Euclidean feature learner. Furthermore, we propose a new heuristics and efficiency point sampling algorithm named ClusterFPS to obtain approximate uniform sampling but at faster speed. ClusterFPS uses a cluster algorithm to divide a point cloud into several clusters and deploy the farthest point sampling algorithm on each cluster in parallel. By combining the above methods, we propose a novel point cloud analysis neural network called PointShuffleNet (PSN), which shows great promise in point cloud classification and segmentation. Extensive experiments show that our PSN achieves state-of-the-art results on ModelNet40, ShapeNet and S3DIS with high efficiency. Theoretically, we provide mathematical analysis toward understanding of what the data distribution HER has developed and why LMIR can drop the trivial path by maximizing mutual information implicitly.
Resolution-enhanced OCT and expanded framework of information capacity and resolution in coherent imaging
Apr 06, 2021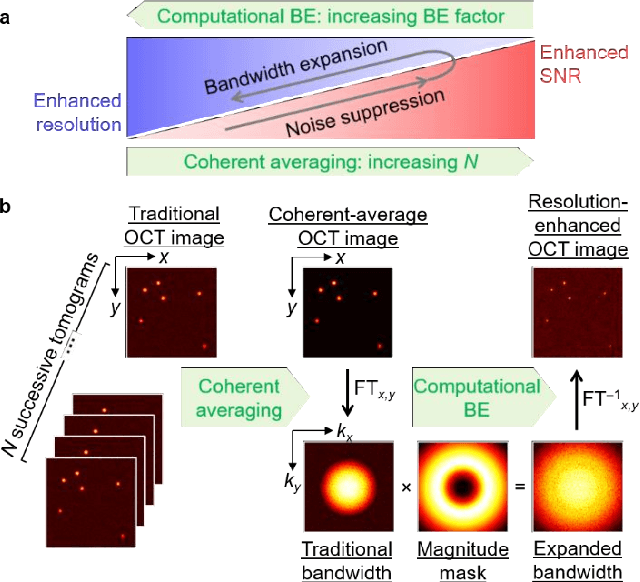
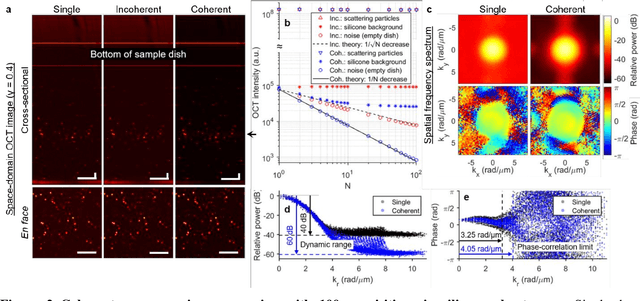
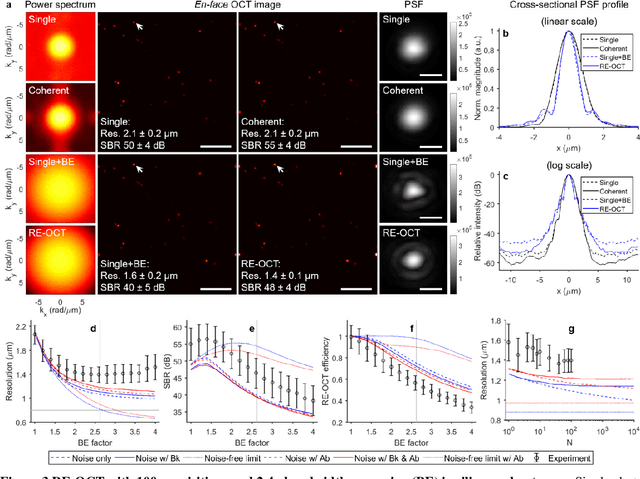
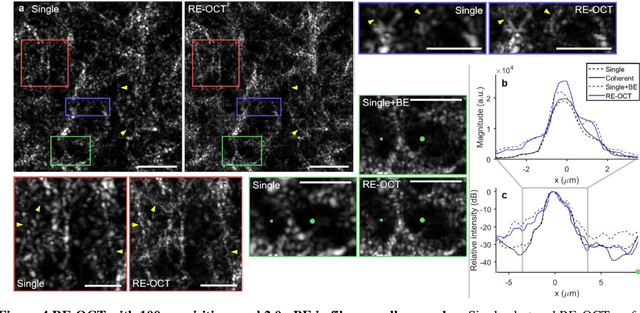
Spatial resolution in optical microscopy has traditionally been treated as a fixed parameter of the optical system. Here, we present an approach to enhance transverse resolution in beam-scanned optical coherence tomography (OCT) beyond its aberration-free resolution limit, without any modification to the optical system. Based on the theorem of invariance of information capacity, resolution-enhanced (RE)-OCT navigates the exchange of information between resolution and signal-to-noise ratio (SNR) by exploiting efficient noise suppression via coherent averaging and a simple computational bandwidth expansion procedure. We demonstrate a resolution enhancement of 1.5 times relative to the aberration-free limit while maintaining comparable SNR in silicone phantom. We show that RE-OCT can significantly enhance the visualization of fine microstructural features in collagen gel and ex vivo mouse brain. Beyond RE-OCT, our analysis in the spatial-frequency domain leads to an expanded framework of information capacity and resolution in coherent imaging that contributes new implications to the theory of coherent imaging. RE-OCT can be readily implemented on most OCT systems worldwide, immediately unlocking information that is beyond their current imaging capabilities, and so has the potential for widespread impact in the numerous areas in which OCT is utilized, including the basic sciences and translational medicine.
Learning Task-Independent Game State Representations from Unlabeled Images
Jun 13, 2022
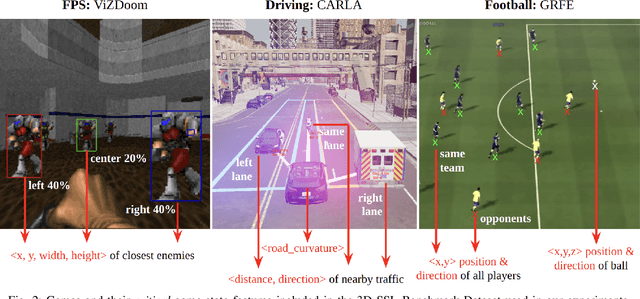
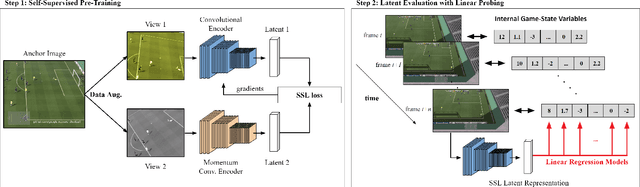
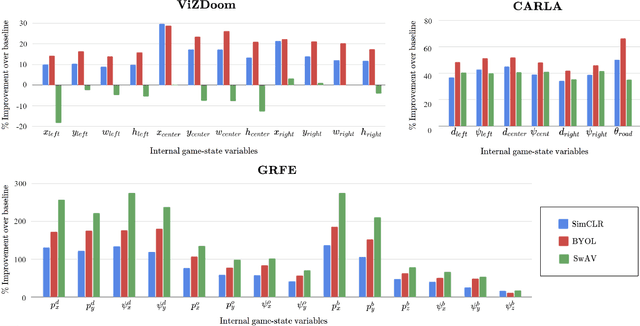
Self-supervised learning (SSL) techniques have been widely used to learn compact and informative representations from high-dimensional complex data. In many computer vision tasks, such as image classification, such methods achieve state-of-the-art results that surpass supervised learning approaches. In this paper, we investigate whether SSL methods can be leveraged for the task of learning accurate state representations of games, and if so, to what extent. For this purpose, we collect game footage frames and corresponding sequences of games' internal state from three different 3D games: VizDoom, the CARLA racing simulator and the Google Research Football Environment. We train an image encoder with three widely used SSL algorithms using solely the raw frames, and then attempt to recover the internal state variables from the learned representations. Our results across all three games showcase significantly higher correlation between SSL representations and the game's internal state compared to pre-trained baseline models such as ImageNet. Such findings suggest that SSL-based visual encoders can yield general -- not tailored to a specific task -- yet informative game representations solely from game pixel information. Such representations can, in turn, form the basis for boosting the performance of downstream learning tasks in games, including gameplaying, content generation and player modeling.
reStructured Pre-training
Jun 22, 2022
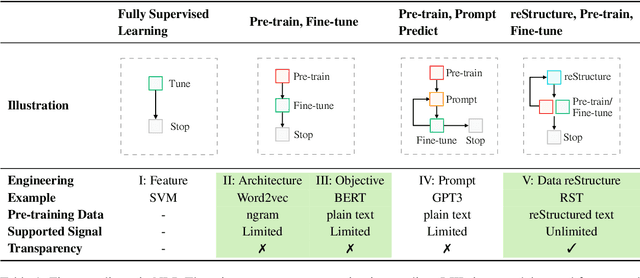
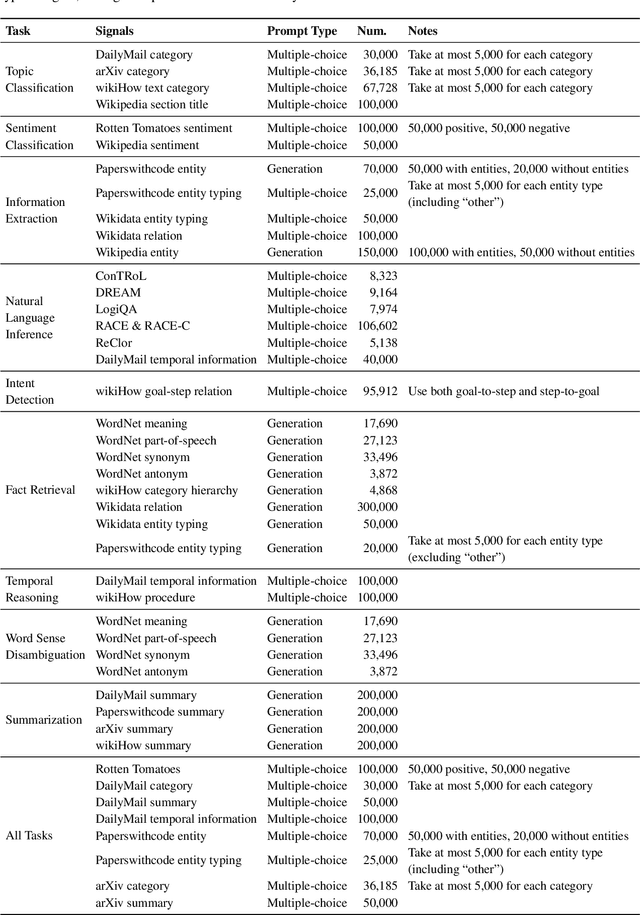
In this work, we try to decipher the internal connection of NLP technology development in the past decades, searching for essence, which rewards us with a (potential) new learning paradigm for NLP tasks, dubbed as reStructured Pre-training (RST). In such a paradigm, the role of data will be re-emphasized, and model pre-training and fine-tuning of downstream tasks are viewed as a process of data storing and accessing. Based on that, we operationalize the simple principle that a good storage mechanism should not only have the ability to cache a large amount of data but also consider the ease of access. We achieve this by pre-training models over restructured data that consist of a variety of valuable information instead of raw data after overcoming several engineering challenges. Experimentally, RST models not only surpass strong competitors (e.g., T0) on 52/55 popular datasets from a variety of NLP tasks, but also achieve superior performance in National College Entrance Examination - English (Gaokao-English),the most authoritative examination in China. Specifically, the proposed system Qin achieves 40 points higher than the average scores made by students and 15 points higher than GPT3 with 1/16 parameters. In particular, Qin gets a high score of 138.5 (the full mark is 150) in the 2018 English exam (national paper III). We have released the Gaokao Benchmark with an online submission platform. In addition, we test our model in the 2022 College Entrance Examination English that happened a few days ago (2022.06.08), and it gets a total score of 134 (v.s. GPT3's 108).
Self-Supervised Representation Learning With MUlti-Segmental Informational Coding (MUSIC)
Jun 13, 2022
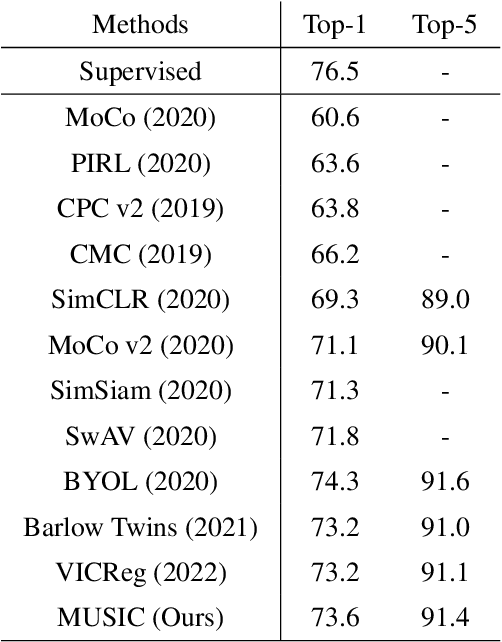
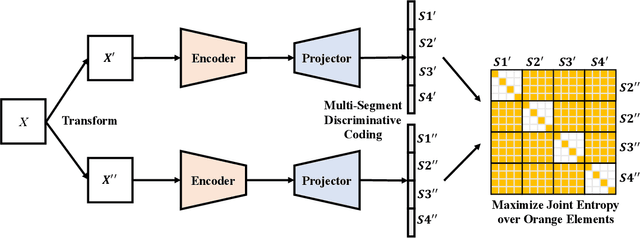
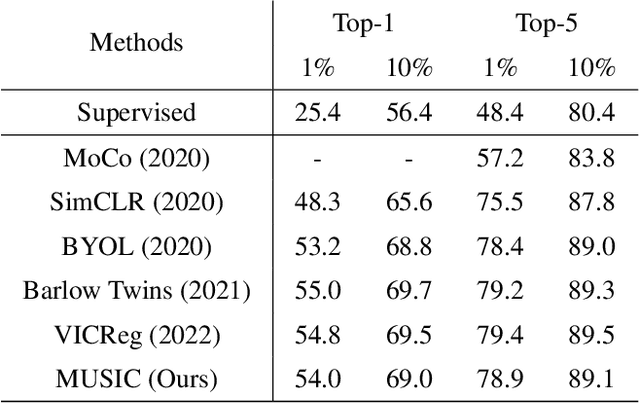
Self-supervised representation learning maps high-dimensional data into a meaningful embedding space, where samples of similar semantic contents are close to each other. Most of the recent representation learning methods maximize cosine similarity or minimize the distance between the embedding features of different views from the same sample usually on the $l2$ normalized unit hypersphere. To prevent the trivial solutions that all samples have the same embedding feature, various techniques have been developed, such as contrastive learning, stop gradient, variance and covariance regularization, etc. In this study, we propose MUlti-Segmental Informational Coding (MUSIC) for self-supervised representation learning. MUSIC divides the embedding feature into multiple segments that discriminatively partition samples into different semantic clusters and different segments focus on different partition principles. Information theory measurements are directly used to optimize MUSIC and theoretically guarantee trivial solutions are avoided. MUSIC does not depend on commonly used techniques, such as memory bank or large batches, asymmetry networks, gradient stopping, momentum weight updating, etc, making the training framework flexible. Our experiments demonstrate that MUSIC achieves better results than most related Barlow Twins and VICReg methods on ImageNet classification with linear probing, and requires neither deep projectors nor large feature dimensions. Code will be made available.
PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images
Jun 02, 2022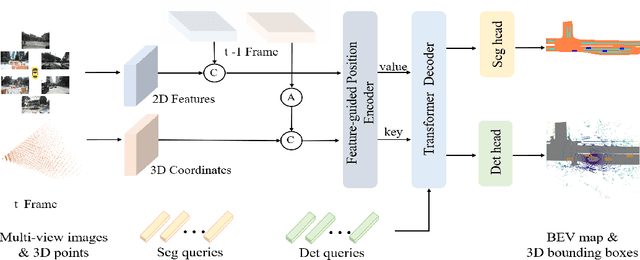
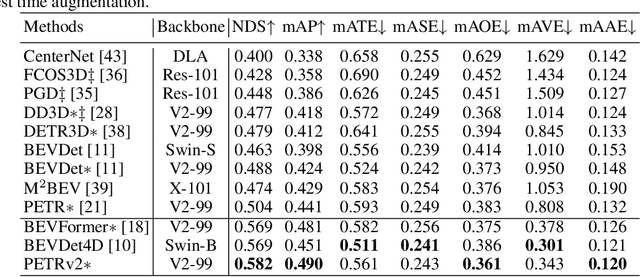
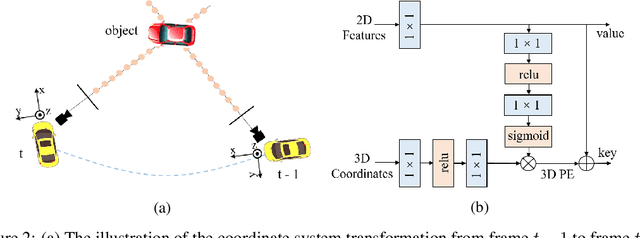
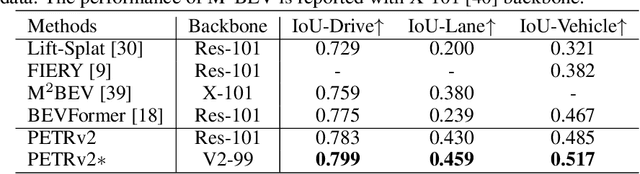
In this paper, we propose PETRv2, a unified framework for 3D perception from multi-view images. Based on PETR, PETRv2 explores the effectiveness of temporal modeling, which utilizes the temporal information of previous frames to boost 3D object detection. More specifically, we extend the 3D position embedding (3D PE) in PETR for temporal modeling. The 3D PE achieves the temporal alignment on object position of different frames. A feature-guided position encoder is further introduced to improve the data adaptability of 3D PE. To support for high-quality BEV segmentation, PETRv2 provides a simply yet effective solution by adding a set of segmentation queries. Each segmentation query is responsible for segmenting one specific patch of BEV map. PETRv2 achieves state-of-the-art performance on 3D object detection and BEV segmentation. Detailed robustness analysis is also conducted on PETR framework. We hope PETRv2 can serve as a unified framework for 3D perception.
Researching Alignment Research: Unsupervised Analysis
Jun 06, 2022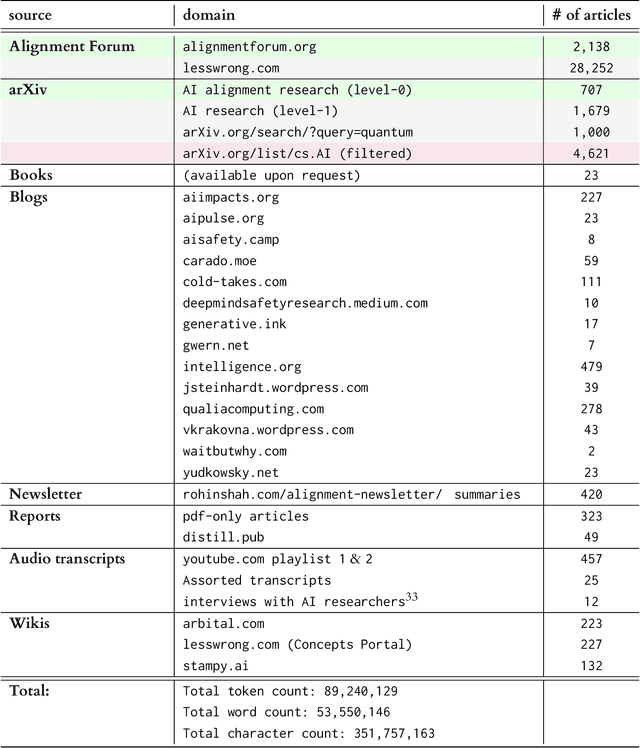
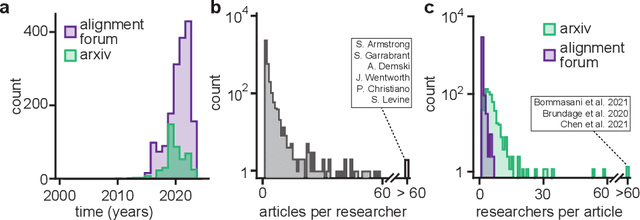
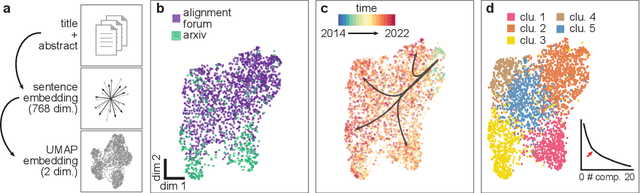

AI alignment research is the field of study dedicated to ensuring that artificial intelligence (AI) benefits humans. As machine intelligence gets more advanced, this research is becoming increasingly important. Researchers in the field share ideas across different media to speed up the exchange of information. However, this focus on speed means that the research landscape is opaque, making it difficult for young researchers to enter the field. In this project, we collected and analyzed existing AI alignment research. We found that the field is growing quickly, with several subfields emerging in parallel. We looked at the subfields and identified the prominent researchers, recurring topics, and different modes of communication in each. Furthermore, we found that a classifier trained on AI alignment research articles can detect relevant articles that we did not originally include in the dataset. We are sharing the dataset with the research community and hope to develop tools in the future that will help both established researchers and young researchers get more involved in the field.