 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Structure-Aware Motion Transfer with Deformable Anchor Model
Apr 11, 2022

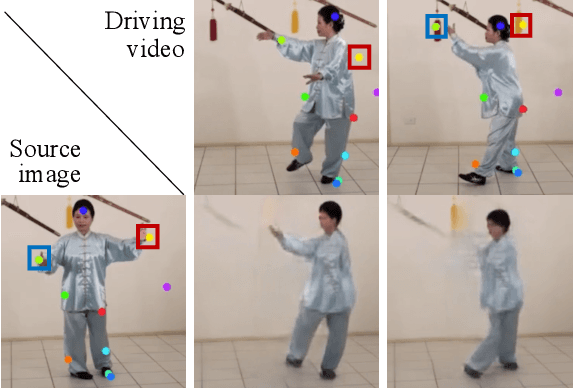

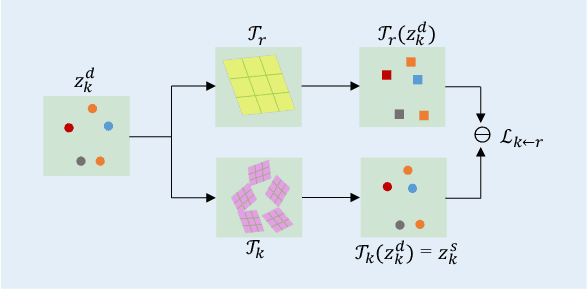
Given a source image and a driving video depicting the same object type, the motion transfer task aims to generate a video by learning the motion from the driving video while preserving the appearance from the source image. In this paper, we propose a novel structure-aware motion modeling approach, the deformable anchor model (DAM), which can automatically discover the motion structure of arbitrary objects without leveraging their prior structure information. Specifically, inspired by the known deformable part model (DPM), our DAM introduces two types of anchors or keypoints: i) a number of motion anchors that capture both appearance and motion information from the source image and driving video; ii) a latent root anchor, which is linked to the motion anchors to facilitate better learning of the representations of the object structure information. Moreover, DAM can be further extended to a hierarchical version through the introduction of additional latent anchors to model more complicated structures. By regularizing motion anchors with latent anchor(s), DAM enforces the correspondences between them to ensure the structural information is well captured and preserved. Moreover, DAM can be learned effectively in an unsupervised manner. We validate our proposed DAM for motion transfer on different benchmark datasets. Extensive experiments clearly demonstrate that DAM achieves superior performance relative to existing state-of-the-art methods.
Sentiment Analysis of Political Tweets for Israel using Machine Learning
Apr 12, 2022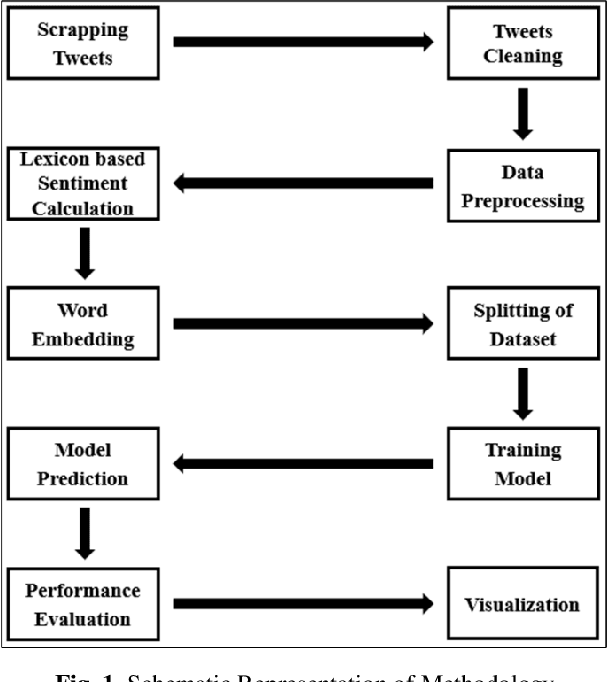
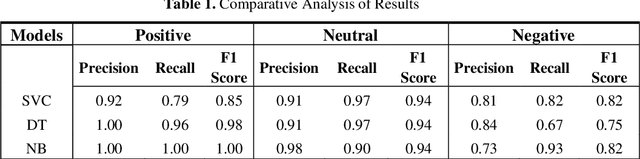

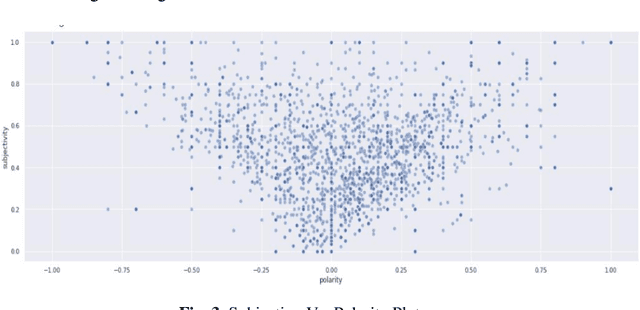
Sentiment Analysis is a vital research topic in the field of Computer Science. With the accelerated development of Information Technology and social networks, a massive amount of data related to comment texts has been generated on web applications or social media platforms like Twitter. Due to this, people have actively started proliferating general information and the information related to political opinions, which becomes an important reason for analyzing public reactions. Most researchers have used social media specifics or contents to analyze and predict public opinion concerning political events. This research proposes an analytical study using Israeli political Twitter data to interpret public opinion towards the Palestinian-Israeli conflict. The attitudes of ethnic groups and opinion leaders in the form of tweets are analyzed using Machine Learning algorithms like Support Vector Classifier (SVC), Decision Tree (DT), and Naive Bayes (NB). Finally, a comparative analysis is done based on experimental results from different models.
Time Difference on Arrival Extraction from Two-Way Ranging
Apr 12, 2022
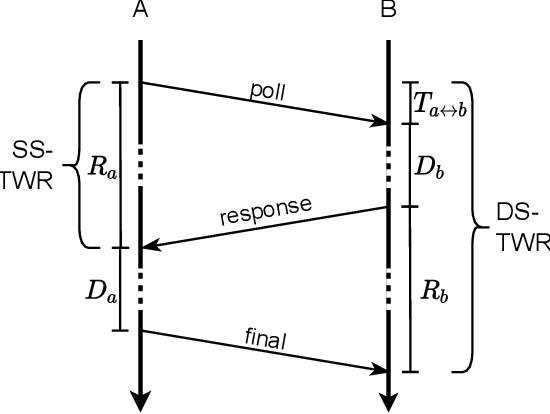
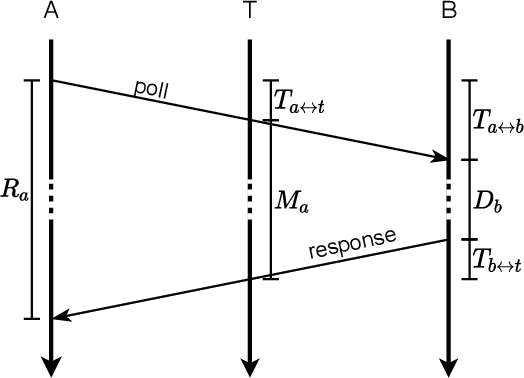
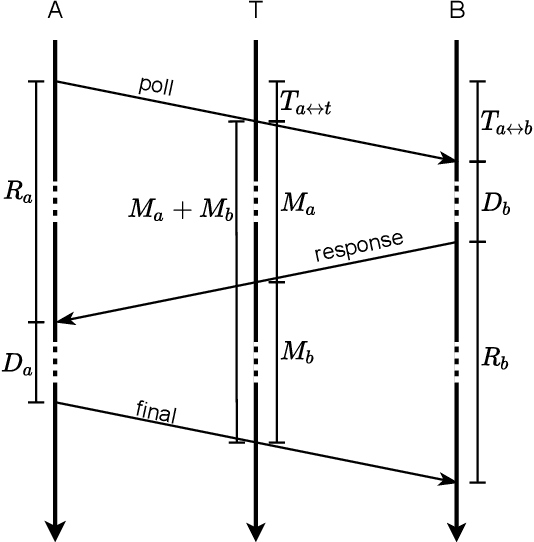
Two-Way Ranging enables the distance estimation between two active parties and allows time of flight measurements despite relative clock offset and drift. Limited by the number of messages, scalable solutions build on Time Difference on Arrival to infer timing information at passive listeners. However, the demand for accurate distance estimates dictates a tight bound on the time synchronization, thus limiting scalability to the localization of passive tags relative to static, synchronized anchors. This work describes the extraction of Time Difference on Arrival information from a Two-Way Ranging process, enabling the extraction of distance information on passive listeners and further allowing scalable tag localization without the need for static or synchronized anchors. The expected error is formally deducted. The extension allows the extraction of the timing difference despite relative clock offset and drift for the Double-Sided Two-Way Ranging and Single-Sided Two-Way Ranging with additional carrier frequency offset estimation.
Injecting Knowledge Base Information into End-to-End Joint Entity and Relation Extraction and Coreference Resolution
Jul 05, 2021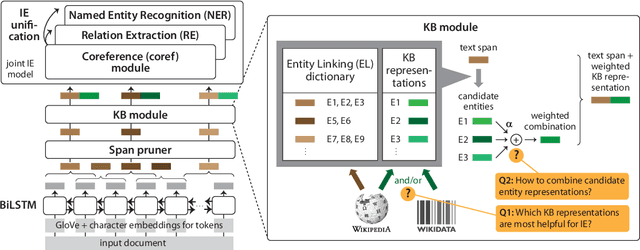

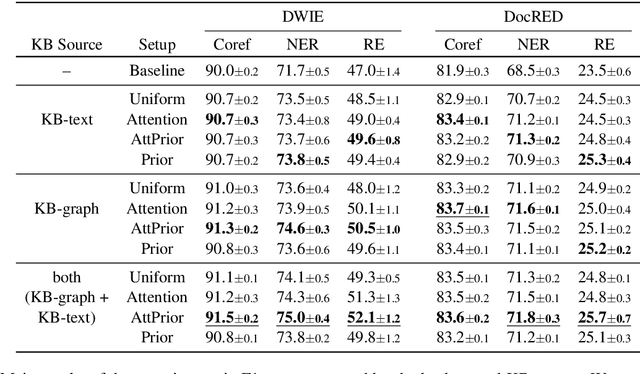

We consider a joint information extraction (IE) model, solving named entity recognition, coreference resolution and relation extraction jointly over the whole document. In particular, we study how to inject information from a knowledge base (KB) in such IE model, based on unsupervised entity linking. The used KB entity representations are learned from either (i) hyperlinked text documents (Wikipedia), or (ii) a knowledge graph (Wikidata), and appear complementary in raising IE performance. Representations of corresponding entity linking (EL) candidates are added to text span representations of the input document, and we experiment with (i) taking a weighted average of the EL candidate representations based on their prior (in Wikipedia), and (ii) using an attention scheme over the EL candidate list. Results demonstrate an increase of up to 5% F1-score for the evaluated IE tasks on two datasets. Despite a strong performance of the prior-based model, our quantitative and qualitative analysis reveals the advantage of using the attention-based approach.
Depth Estimation Matters Most: Improving Per-Object Depth Estimation for Monocular 3D Detection and Tracking
Jun 08, 2022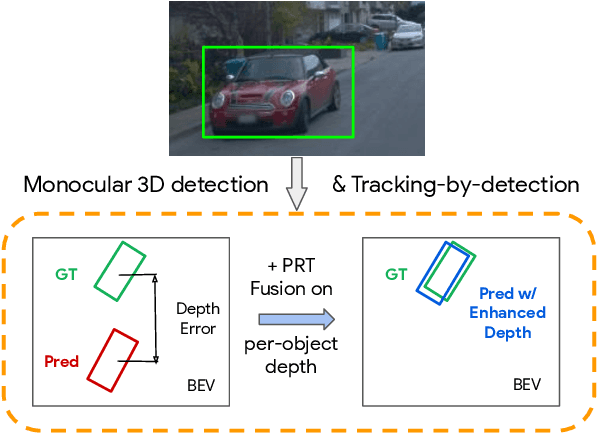
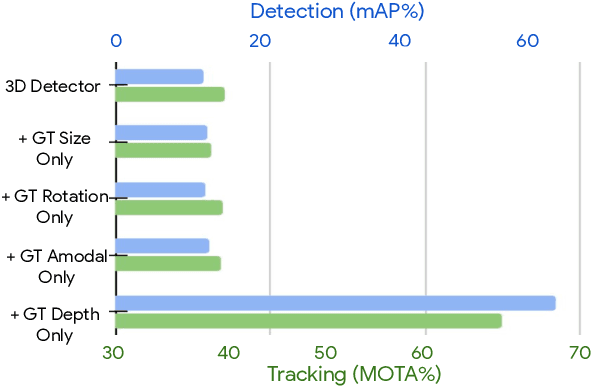
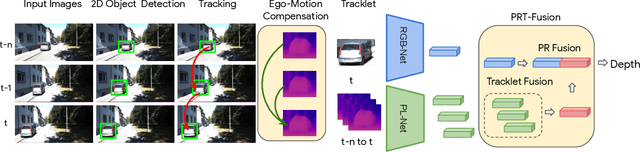
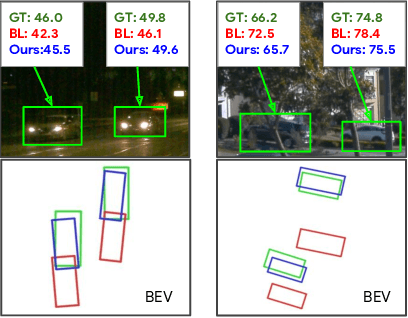
Monocular image-based 3D perception has become an active research area in recent years owing to its applications in autonomous driving. Approaches to monocular 3D perception including detection and tracking, however, often yield inferior performance when compared to LiDAR-based techniques. Through systematic analysis, we identified that per-object depth estimation accuracy is a major factor bounding the performance. Motivated by this observation, we propose a multi-level fusion method that combines different representations (RGB and pseudo-LiDAR) and temporal information across multiple frames for objects (tracklets) to enhance per-object depth estimation. Our proposed fusion method achieves the state-of-the-art performance of per-object depth estimation on the Waymo Open Dataset, the KITTI detection dataset, and the KITTI MOT dataset. We further demonstrate that by simply replacing estimated depth with fusion-enhanced depth, we can achieve significant improvements in monocular 3D perception tasks, including detection and tracking.
mSHINE: A Multiple-meta-paths Simultaneous Learning Framework for Heterogeneous Information Network Embedding
Apr 09, 2021
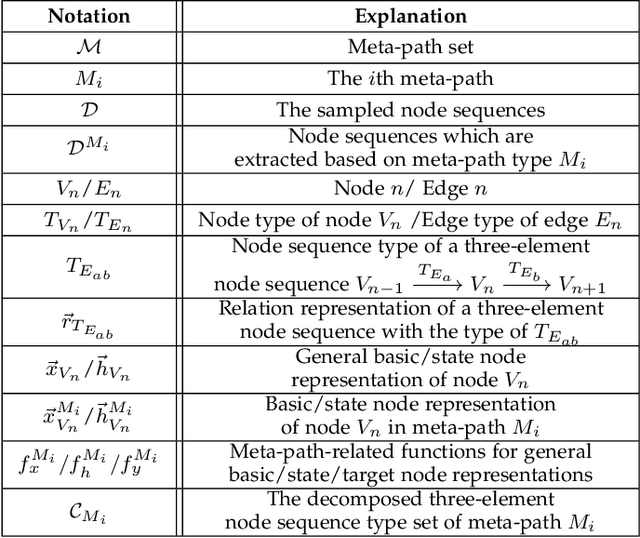
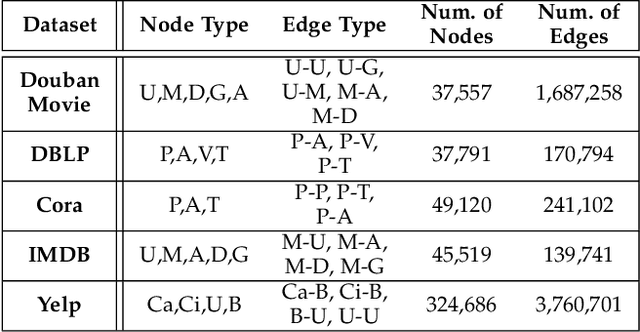
Heterogeneous information networks(HINs) become popular in recent years for its strong capability of modelling objects with abundant information using explicit network structure. Network embedding has been proved as an effective method to convert information networks into lower-dimensional space, whereas the core information can be well preserved. However, traditional network embedding algorithms are sub-optimal in capturing rich while potentially incompatible semantics provided by HINs. To address this issue, a novel meta-path-based HIN representation learning framework named mSHINE is designed to simultaneously learn multiple node representations for different meta-paths. More specifically, one representation learning module inspired by the RNN structure is developed and multiple node representations can be learned simultaneously, where each representation is associated with one respective meta-path. By measuring the relevance between nodes with the designed objective function, the learned module can be applied in downstream link prediction tasks. A set of criteria for selecting initial meta-paths is proposed as the other module in mSHINE which is important to reduce the optimal meta-path selection cost when no prior knowledge of suitable meta-paths is available. To corroborate the effectiveness of mSHINE, extensive experimental studies including node classification and link prediction are conducted on five real-world datasets. The results demonstrate that mSHINE outperforms other state-of-the-art HIN embedding methods.
Latent Diffusion Energy-Based Model for Interpretable Text Modeling
Jun 14, 2022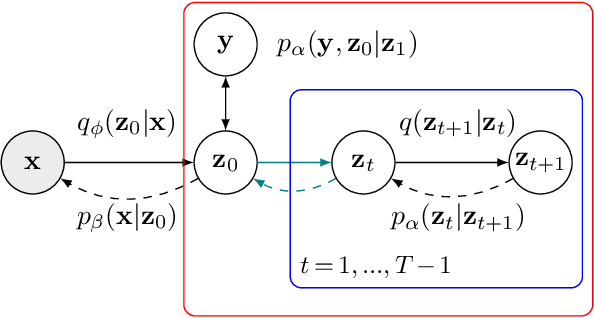
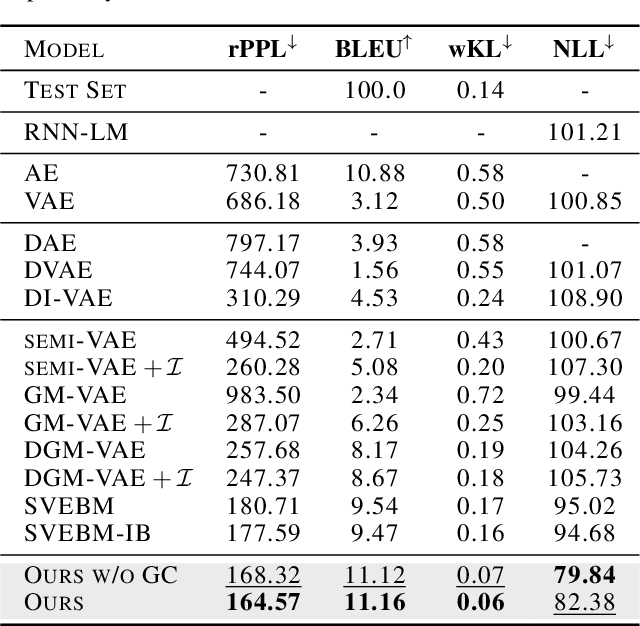
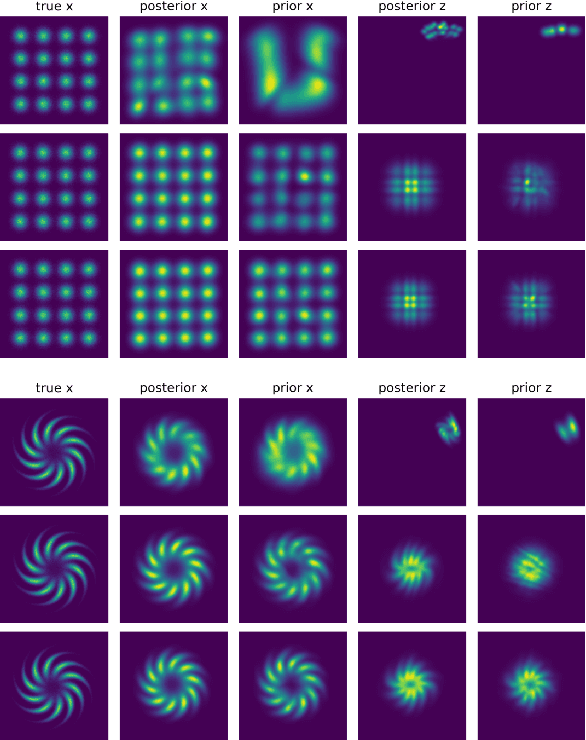

Latent space Energy-Based Models (EBMs), also known as energy-based priors, have drawn growing interests in generative modeling. Fueled by its flexibility in the formulation and strong modeling power of the latent space, recent works built upon it have made interesting attempts aiming at the interpretability of text modeling. However, latent space EBMs also inherit some flaws from EBMs in data space; the degenerate MCMC sampling quality in practice can lead to poor generation quality and instability in training, especially on data with complex latent structures. Inspired by the recent efforts that leverage diffusion recovery likelihood learning as a cure for the sampling issue, we introduce a novel symbiosis between the diffusion models and latent space EBMs in a variational learning framework, coined as the latent diffusion energy-based model. We develop a geometric clustering-based regularization jointly with the information bottleneck to further improve the quality of the learned latent space. Experiments on several challenging tasks demonstrate the superior performance of our model on interpretable text modeling over strong counterparts.
Explaining Preferences with Shapley Values
May 26, 2022
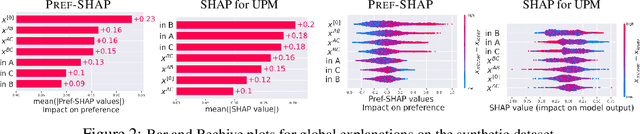
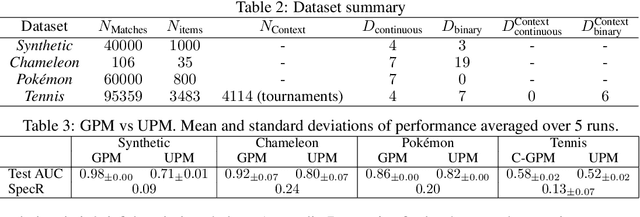
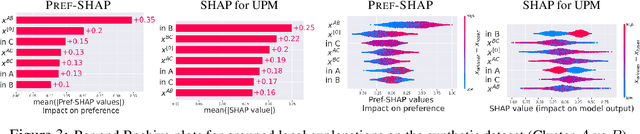
While preference modelling is becoming one of the pillars of machine learning, the problem of preference explanation remains challenging and underexplored. In this paper, we propose \textsc{Pref-SHAP}, a Shapley value-based model explanation framework for pairwise comparison data. We derive the appropriate value functions for preference models and further extend the framework to model and explain \emph{context specific} information, such as the surface type in a tennis game. To demonstrate the utility of \textsc{Pref-SHAP}, we apply our method to a variety of synthetic and real-world datasets and show that richer and more insightful explanations can be obtained over the baseline.
BolT: Fused Window Transformers for fMRI Time Series Analysis
May 23, 2022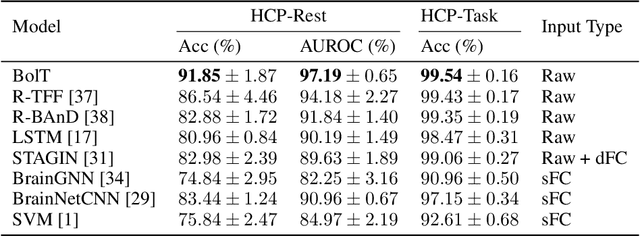
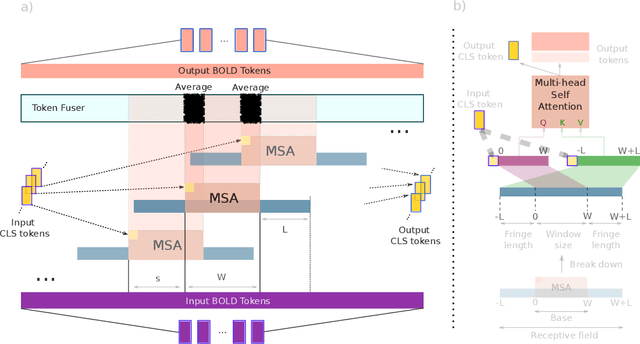
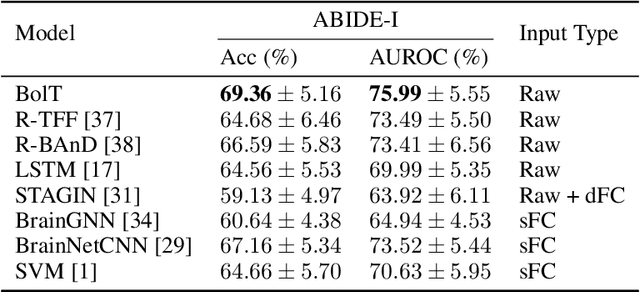
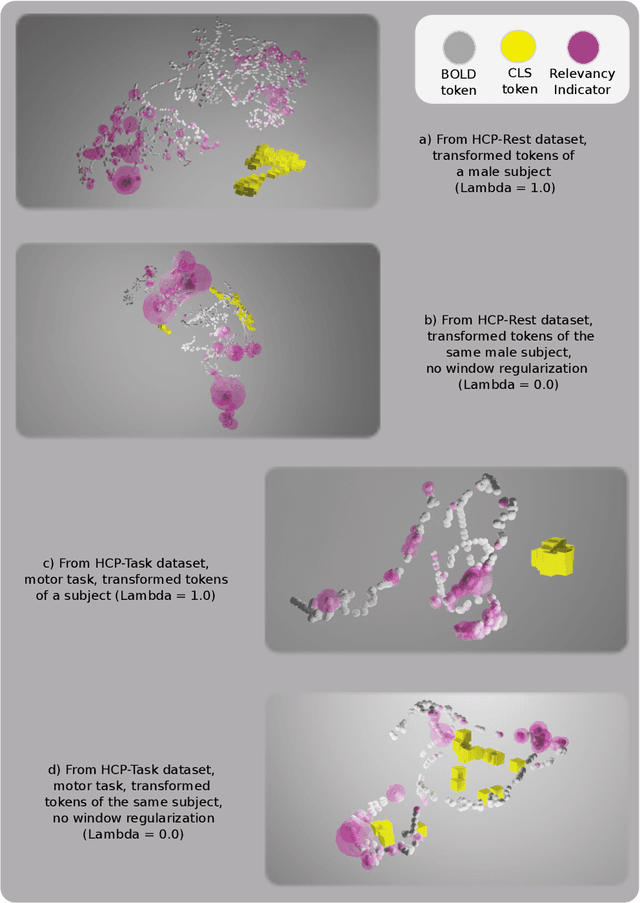
Functional magnetic resonance imaging (fMRI) enables examination of inter-regional interactions in the brain via functional connectivity (FC) analyses that measure the synchrony between the temporal activations of separate regions. Given their exceptional sensitivity, deep-learning methods have received growing interest for FC analyses of high-dimensional fMRI data. In this domain, models that operate directly on raw time series as opposed to pre-computed FC features have the potential benefit of leveraging the full scale of information present in fMRI data. However, previous models are based on architectures suboptimal for temporal integration of representations across multiple time scales. Here, we present BolT, blood-oxygen-level-dependent transformer, for analyzing multi-variate fMRI time series. BolT leverages a cascade of transformer encoders equipped with a novel fused window attention mechanism. Transformer encoding is performed on temporally-overlapped time windows within the fMRI time series to capture short time-scale representations. To integrate information across windows, cross-window attention is computed between base tokens in each time window and fringe tokens from neighboring time windows. To transition from local to global representations, the extent of window overlap and thereby number of fringe tokens is progressively increased across the cascade. Finally, a novel cross-window regularization is enforced to align the high-level representations of global $CLS$ features across time windows. Comprehensive experiments on public fMRI datasets clearly illustrate the superior performance of BolT against state-of-the-art methods. Posthoc explanatory analyses to identify landmark time points and regions that contribute most significantly to model decisions corroborate prominent neuroscientific findings from recent fMRI studies.
Diverse Instance Discovery: Vision-Transformer for Instance-Aware Multi-Label Image Recognition
Apr 22, 2022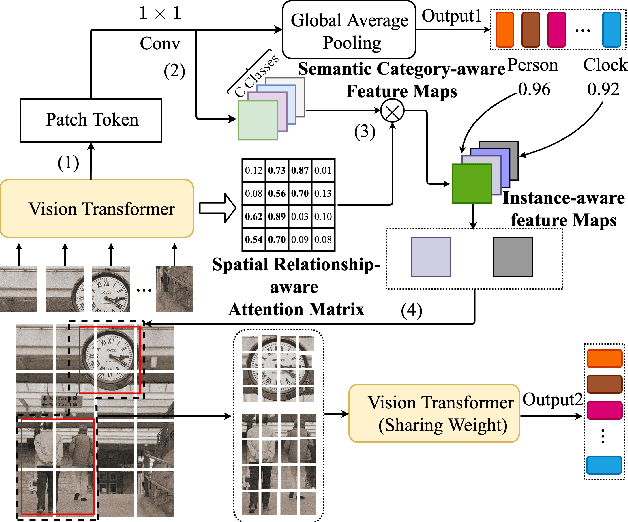
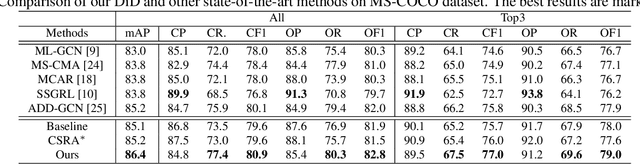
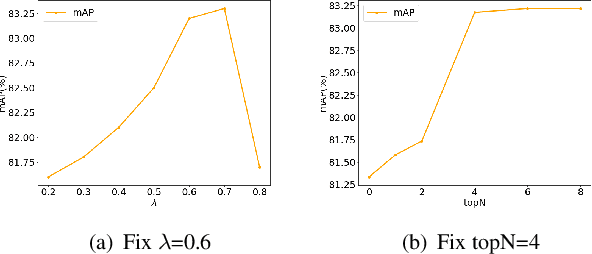
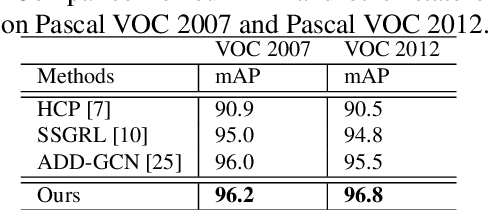
Previous works on multi-label image recognition (MLIR) usually use CNNs as a starting point for research. In this paper, we take pure Vision Transformer (ViT) as the research base and make full use of the advantages of Transformer with long-range dependency modeling to circumvent the disadvantages of CNNs limited to local receptive field. However, for multi-label images containing multiple objects from different categories, scales, and spatial relations, it is not optimal to use global information alone. Our goal is to leverage ViT's patch tokens and self-attention mechanism to mine rich instances in multi-label images, named diverse instance discovery (DiD). To this end, we propose a semantic category-aware module and a spatial relationship-aware module, respectively, and then combine the two by a re-constraint strategy to obtain instance-aware attention maps. Finally, we propose a weakly supervised object localization-based approach to extract multi-scale local features, to form a multi-view pipeline. Our method requires only weakly supervised information at the label level, no additional knowledge injection or other strongly supervised information is required. Experiments on three benchmark datasets show that our method significantly outperforms previous works and achieves state-of-the-art results under fair experimental comparisons.