 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Position-prior Clustering-based Self-attention Module for Knee Cartilage Segmentation
Jun 21, 2022
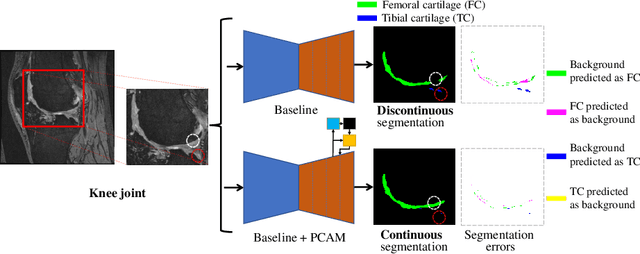
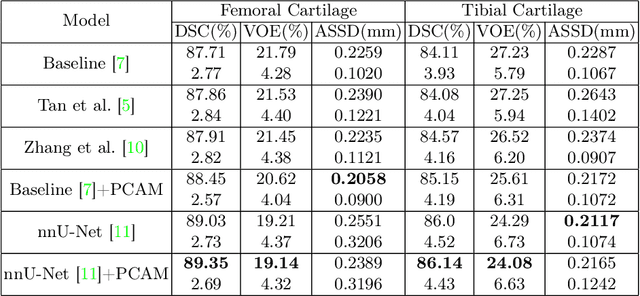
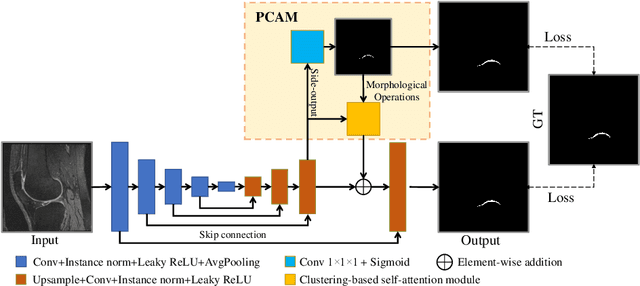
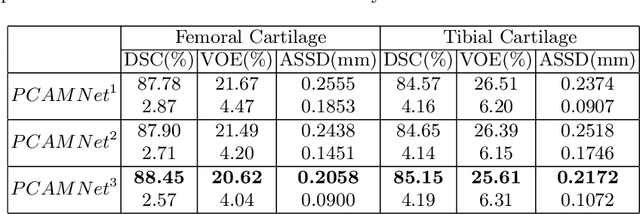
The morphological changes in knee cartilage (especially femoral and tibial cartilages) are closely related to the progression of knee osteoarthritis, which is expressed by magnetic resonance (MR) images and assessed on the cartilage segmentation results. Thus, it is necessary to propose an effective automatic cartilage segmentation model for longitudinal research on osteoarthritis. In this research, to relieve the problem of inaccurate discontinuous segmentation caused by the limited receptive field in convolutional neural networks, we proposed a novel position-prior clustering-based self-attention module (PCAM). In PCAM, long-range dependency between each class center and feature point is captured by self-attention allowing contextual information re-allocated to strengthen the relative features and ensure the continuity of segmentation result. The clutsering-based method is used to estimate class centers, which fosters intra-class consistency and further improves the accuracy of segmentation results. The position-prior excludes the false positives from side-output and makes center estimation more precise. Sufficient experiments are conducted on OAI-ZIB dataset. The experimental results show that the segmentation performance of combination of segmentation network and PCAM obtains an evident improvement compared to original model, which proves the potential application of PCAM in medical segmentation tasks. The source code is publicly available from link: https://github.com/LeongDong/PCAMNet
Fast and Provable Tensor Robust Principal Component Analysis via Scaled Gradient Descent
Jun 18, 2022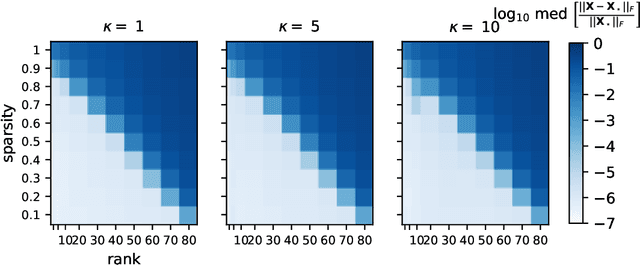
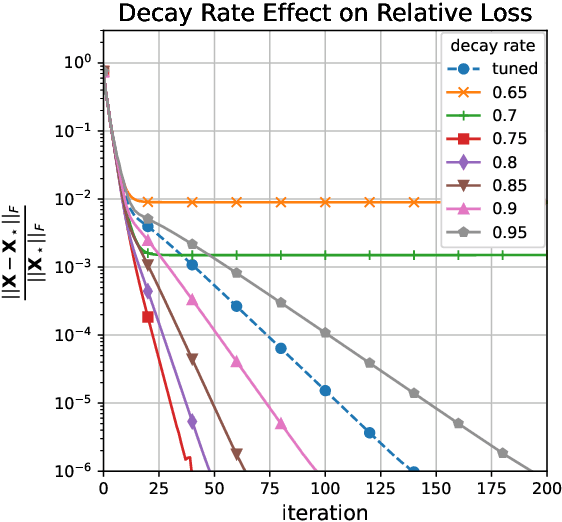


An increasing number of data science and machine learning problems rely on computation with tensors, which better capture the multi-way relationships and interactions of data than matrices. When tapping into this critical advantage, a key challenge is to develop computationally efficient and provably correct algorithms for extracting useful information from tensor data that are simultaneously robust to corruptions and ill-conditioning. This paper tackles tensor robust principal component analysis (RPCA), which aims to recover a low-rank tensor from its observations contaminated by sparse corruptions, under the Tucker decomposition. To minimize the computation and memory footprints, we propose to directly recover the low-dimensional tensor factors -- starting from a tailored spectral initialization -- via scaled gradient descent (ScaledGD), coupled with an iteration-varying thresholding operation to adaptively remove the impact of corruptions. Theoretically, we establish that the proposed algorithm converges linearly to the true low-rank tensor at a constant rate that is independent with its condition number, as long as the level of corruptions is not too large. Empirically, we demonstrate that the proposed algorithm achieves better and more scalable performance than state-of-the-art matrix and tensor RPCA algorithms through synthetic experiments and real-world applications.
Semi-Supervised Generative Adversarial Network for Stress Detection Using Partially Labeled Physiological Data
Jun 30, 2022
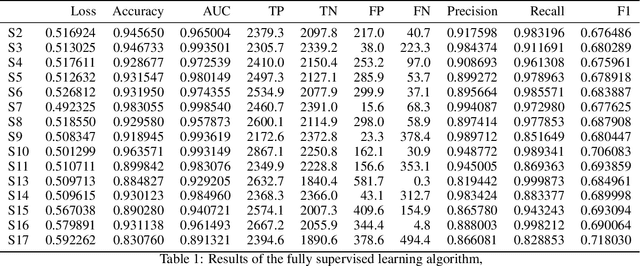
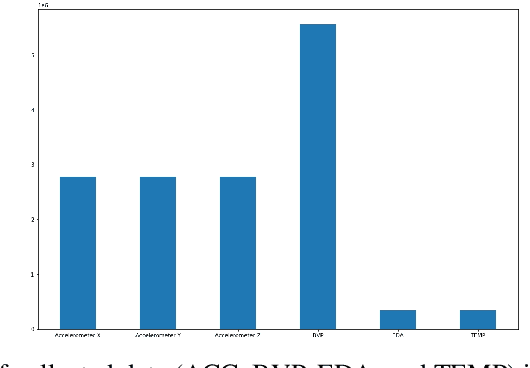
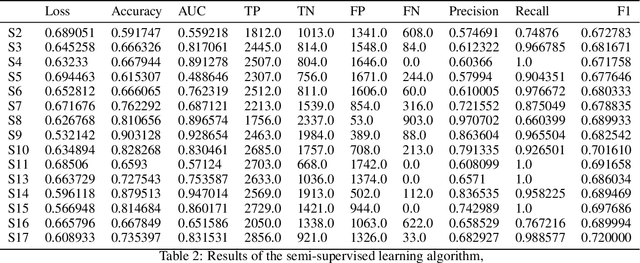
Physiological measurements involves observing variables that attribute to the normative functioning of human systems and subsystems directly or indirectly. The measurements can be used to detect affective states of a person with aims such as improving human-computer interactions. There are several methods of collecting physiological data, but wearable sensors are a common, non-invasive tool for accurate readings. However, valuable information is hard to extract from the raw physiological data, especially for affective state detection. Machine Learning techniques are used to detect the affective state of a person through labeled physiological data. A clear problem with using labeled data is creating accurate labels. An expert is needed to analyze a form of recording of participants and mark sections with different states such as stress and calm. While expensive, this method delivers a complete dataset with labeled data that can be used in any number of supervised algorithms. An interesting question arises from the expensive labeling: how can we reduce the cost while maintaining high accuracy? Semi-Supervised learning (SSL) is a potential solution to this problem. These algorithms allow for machine learning models to be trained with only a small subset of labeled data (unlike unsupervised which use no labels). They provide a way of avoiding expensive labeling. This paper compares a fully supervised algorithm to a SSL on the public WESAD (Wearable Stress and Affect Detection) Dataset for stress detection. This paper shows that Semi-Supervised algorithms are a viable method for inexpensive affective state detection systems with accurate results.
Spatial-Temporal Space Hand-in-Hand: Spatial-Temporal Video Super-Resolution via Cycle-Projected Mutual Learning
May 11, 2022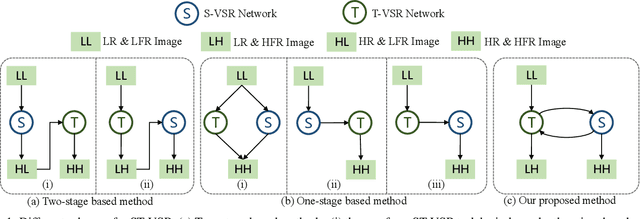
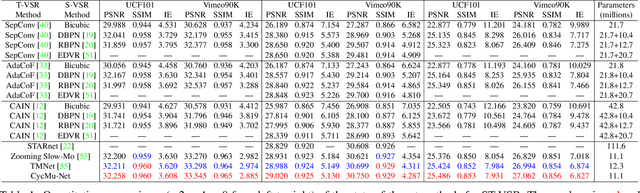
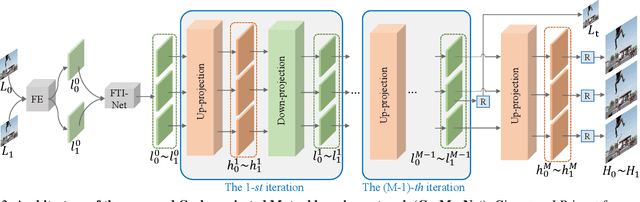
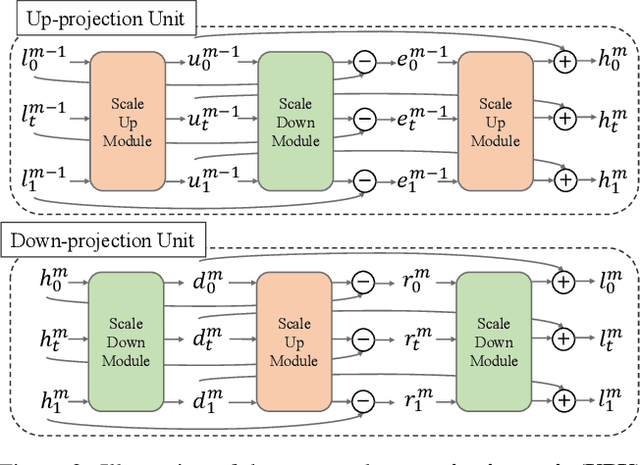
Spatial-Temporal Video Super-Resolution (ST-VSR) aims to generate super-resolved videos with higher resolution(HR) and higher frame rate (HFR). Quite intuitively, pioneering two-stage based methods complete ST-VSR by directly combining two sub-tasks: Spatial Video Super-Resolution (S-VSR) and Temporal Video Super-Resolution(T-VSR) but ignore the reciprocal relations among them. Specifically, 1) T-VSR to S-VSR: temporal correlations help accurate spatial detail representation with more clues; 2) S-VSR to T-VSR: abundant spatial information contributes to the refinement of temporal prediction. To this end, we propose a one-stage based Cycle-projected Mutual learning network (CycMu-Net) for ST-VSR, which makes full use of spatial-temporal correlations via the mutual learning between S-VSR and T-VSR. Specifically, we propose to exploit the mutual information among them via iterative up-and-down projections, where the spatial and temporal features are fully fused and distilled, helping the high-quality video reconstruction. Besides extensive experiments on benchmark datasets, we also compare our proposed CycMu-Net with S-VSR and T-VSR tasks, demonstrating that our method significantly outperforms state-of-the-art methods.
* 10 pages, 8 figures
Injecting Knowledge Base Information into End-to-End Joint Entity and Relation Extraction and Coreference Resolution
Jul 05, 2021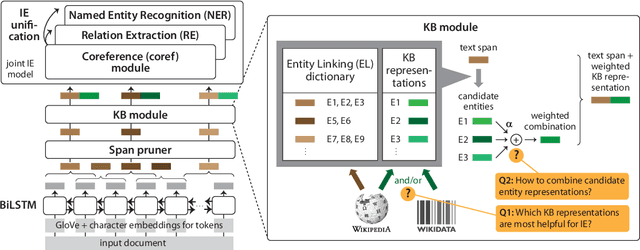

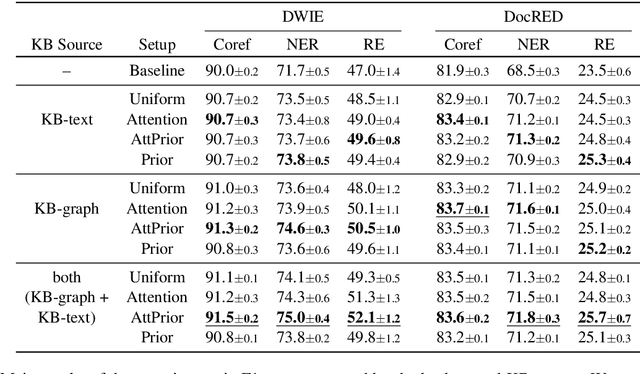

We consider a joint information extraction (IE) model, solving named entity recognition, coreference resolution and relation extraction jointly over the whole document. In particular, we study how to inject information from a knowledge base (KB) in such IE model, based on unsupervised entity linking. The used KB entity representations are learned from either (i) hyperlinked text documents (Wikipedia), or (ii) a knowledge graph (Wikidata), and appear complementary in raising IE performance. Representations of corresponding entity linking (EL) candidates are added to text span representations of the input document, and we experiment with (i) taking a weighted average of the EL candidate representations based on their prior (in Wikipedia), and (ii) using an attention scheme over the EL candidate list. Results demonstrate an increase of up to 5% F1-score for the evaluated IE tasks on two datasets. Despite a strong performance of the prior-based model, our quantitative and qualitative analysis reveals the advantage of using the attention-based approach.
mSHINE: A Multiple-meta-paths Simultaneous Learning Framework for Heterogeneous Information Network Embedding
Apr 09, 2021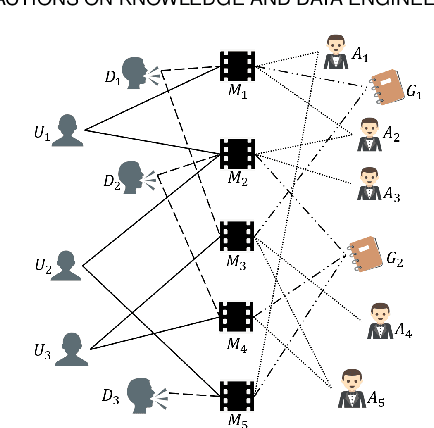
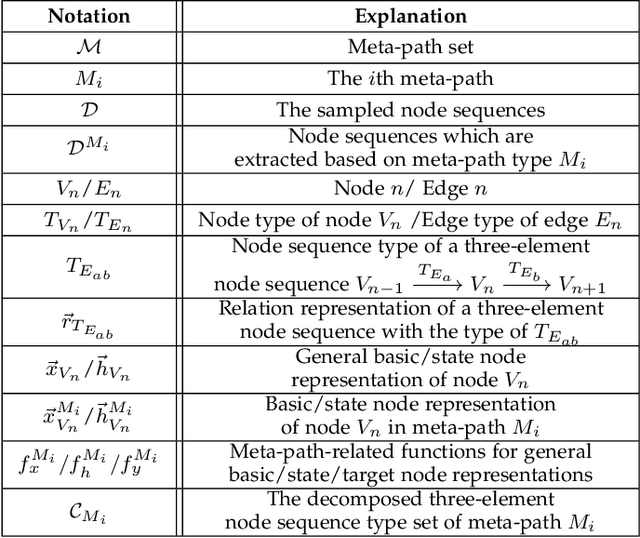
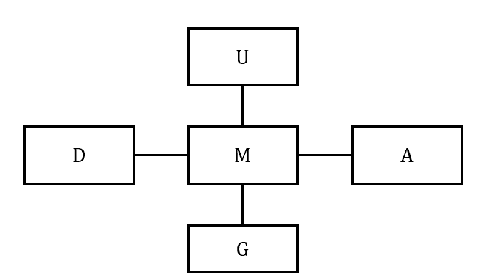
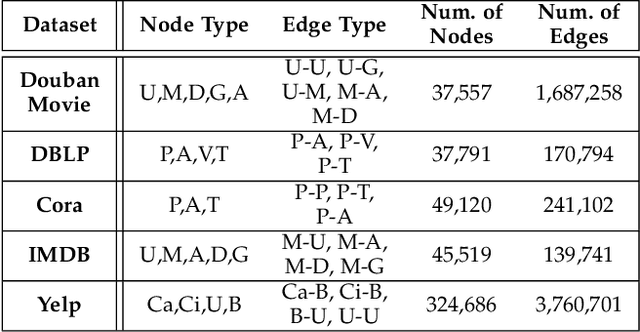
Heterogeneous information networks(HINs) become popular in recent years for its strong capability of modelling objects with abundant information using explicit network structure. Network embedding has been proved as an effective method to convert information networks into lower-dimensional space, whereas the core information can be well preserved. However, traditional network embedding algorithms are sub-optimal in capturing rich while potentially incompatible semantics provided by HINs. To address this issue, a novel meta-path-based HIN representation learning framework named mSHINE is designed to simultaneously learn multiple node representations for different meta-paths. More specifically, one representation learning module inspired by the RNN structure is developed and multiple node representations can be learned simultaneously, where each representation is associated with one respective meta-path. By measuring the relevance between nodes with the designed objective function, the learned module can be applied in downstream link prediction tasks. A set of criteria for selecting initial meta-paths is proposed as the other module in mSHINE which is important to reduce the optimal meta-path selection cost when no prior knowledge of suitable meta-paths is available. To corroborate the effectiveness of mSHINE, extensive experimental studies including node classification and link prediction are conducted on five real-world datasets. The results demonstrate that mSHINE outperforms other state-of-the-art HIN embedding methods.
Secure Federated Learning for Neuroimaging
May 11, 2022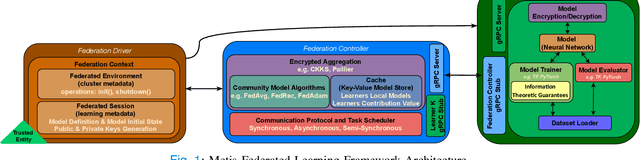
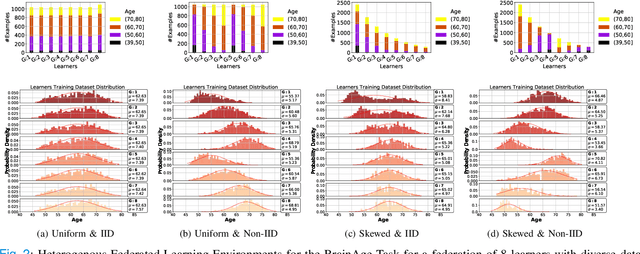
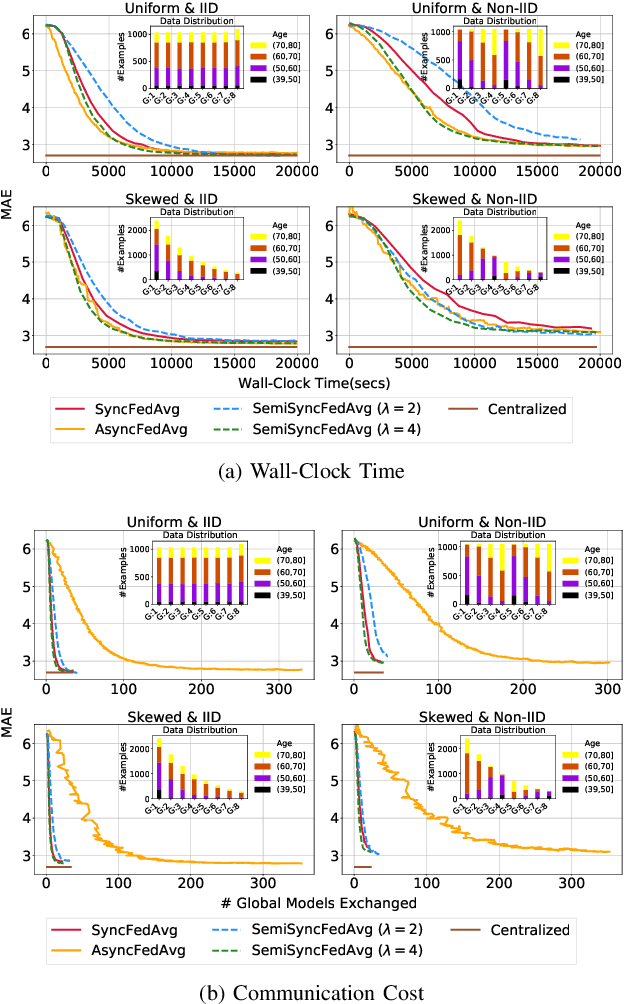
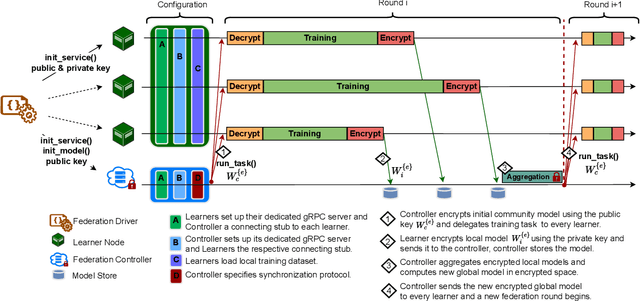
The amount of biomedical data continues to grow rapidly. However, the ability to collect data from multiple sites for joint analysis remains challenging due to security, privacy, and regulatory concerns. We present a Secure Federated Learning architecture, MetisFL, which enables distributed training of neural networks over multiple data sources without sharing data. Each site trains the neural network over its private data for some time, then shares the neural network parameters (i.e., weights, gradients) with a Federation Controller, which in turn aggregates the local models, sends the resulting community model back to each site, and the process repeats. Our architecture provides strong security and privacy. First, sample data never leaves a site. Second, neural parameters are encrypted before transmission and the community model is computed under fully-homomorphic encryption. Finally, we use information-theoretic methods to limit information leakage from the neural model to prevent a curious site from performing membership attacks. We demonstrate this architecture in neuroimaging. Specifically, we investigate training neural models to classify Alzheimer's disease, and estimate Brain Age, from magnetic resonance imaging datasets distributed across multiple sites, including heterogeneous environments where sites have different amounts of data, statistical distributions, and computational capabilities.
Fluctuation-driven initialization for spiking neural network training
Jun 21, 2022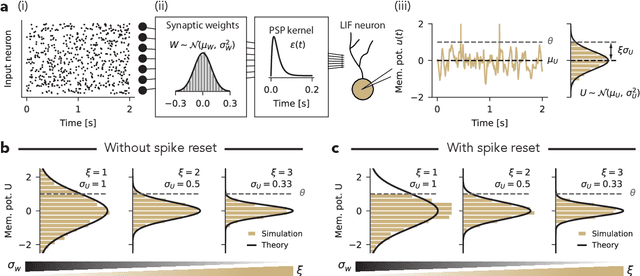

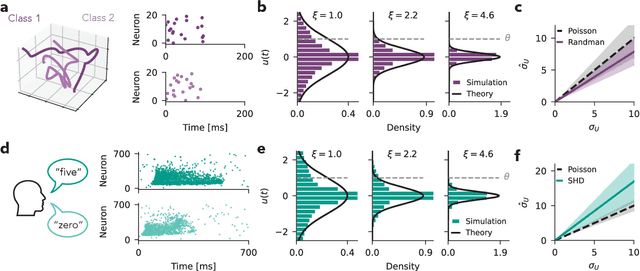

Spiking neural networks (SNNs) underlie low-power, fault-tolerant information processing in the brain and could constitute a power-efficient alternative to conventional deep neural networks when implemented on suitable neuromorphic hardware accelerators. However, instantiating SNNs that solve complex computational tasks in-silico remains a significant challenge. Surrogate gradient (SG) techniques have emerged as a standard solution for training SNNs end-to-end. Still, their success depends on synaptic weight initialization, similar to conventional artificial neural networks (ANNs). Yet, unlike in the case of ANNs, it remains elusive what constitutes a good initial state for an SNN. Here, we develop a general initialization strategy for SNNs inspired by the fluctuation-driven regime commonly observed in the brain. Specifically, we derive practical solutions for data-dependent weight initialization that ensure fluctuation-driven firing in the widely used leaky integrate-and-fire (LIF) neurons. We empirically show that SNNs initialized following our strategy exhibit superior learning performance when trained with SGs. These findings generalize across several datasets and SNN architectures, including fully connected, deep convolutional, recurrent, and more biologically plausible SNNs obeying Dale's law. Thus fluctuation-driven initialization provides a practical, versatile, and easy-to-implement strategy for improving SNN training performance on diverse tasks in neuromorphic engineering and computational neuroscience.
Neutral Utterances are Also Causes: Enhancing Conversational Causal Emotion Entailment with Social Commonsense Knowledge
May 07, 2022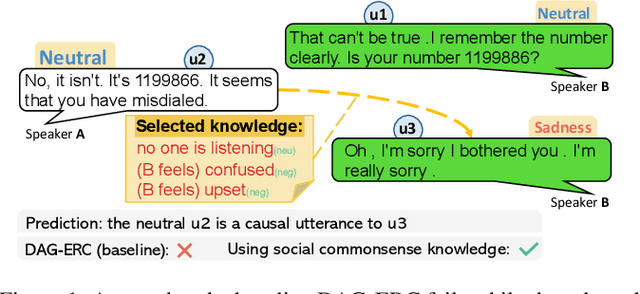
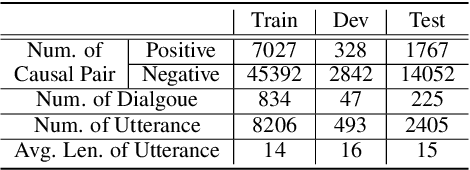
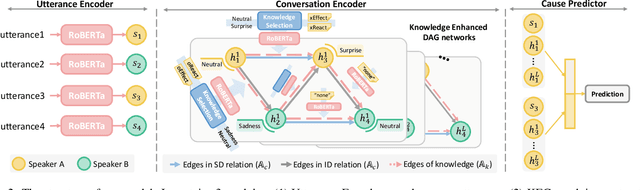
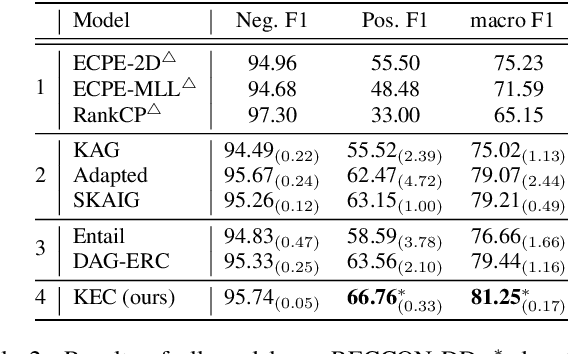
Conversational Causal Emotion Entailment aims to detect causal utterances for a non-neutral targeted utterance from a conversation. In this work, we build conversations as graphs to overcome implicit contextual modelling of the original entailment style. Following the previous work, we further introduce the emotion information into graphs. Emotion information can markedly promote the detection of causal utterances whose emotion is the same as the targeted utterance. However, it is still hard to detect causal utterances with different emotions, especially neutral ones. The reason is that models are limited in reasoning causal clues and passing them between utterances. To alleviate this problem, we introduce social commonsense knowledge (CSK) and propose a Knowledge Enhanced Conversation graph (KEC). KEC propagates the CSK between two utterances. As not all CSK is emotionally suitable for utterances, we therefore propose a sentiment-realized knowledge selecting strategy to filter CSK. To process KEC, we further construct the Knowledge Enhanced Directed Acyclic Graph networks. Experimental results show that our method outperforms baselines and infers more causes with different emotions from the targeted utterance.
ML-Based Approach for NFL Defensive Pass Interference Prediction Using GPS Tracking Data
Jun 24, 2022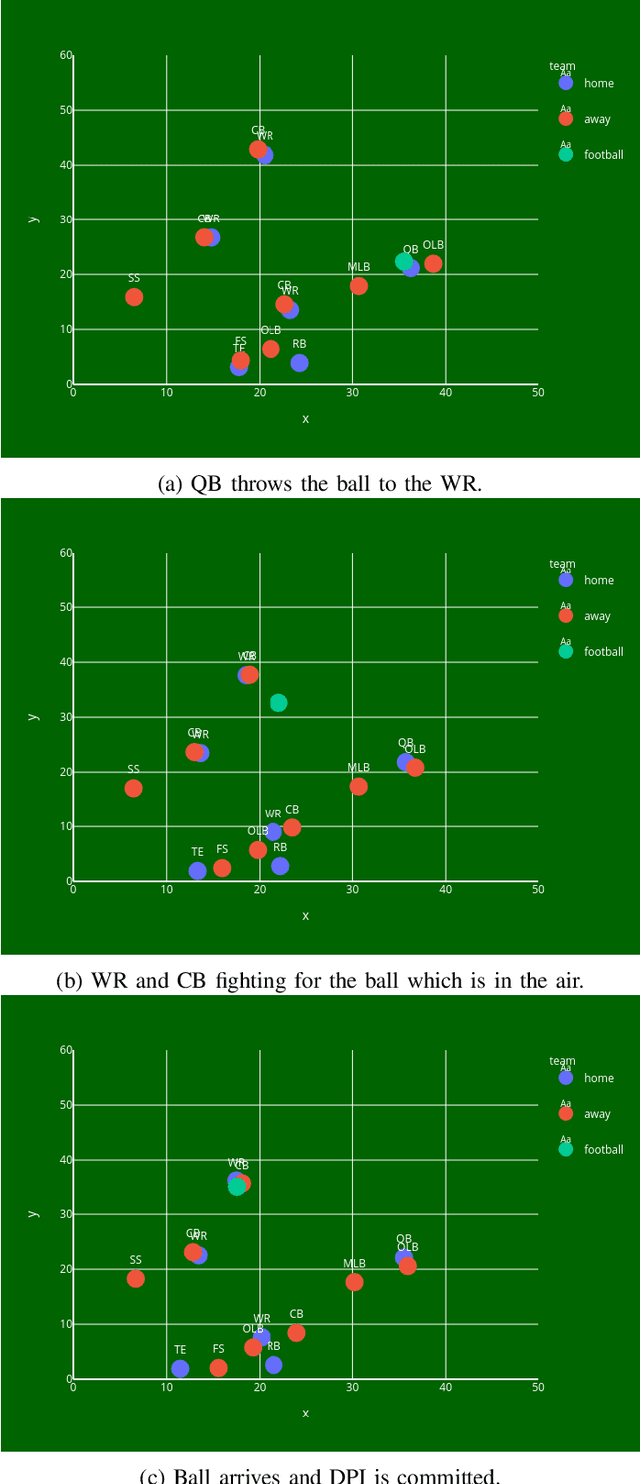
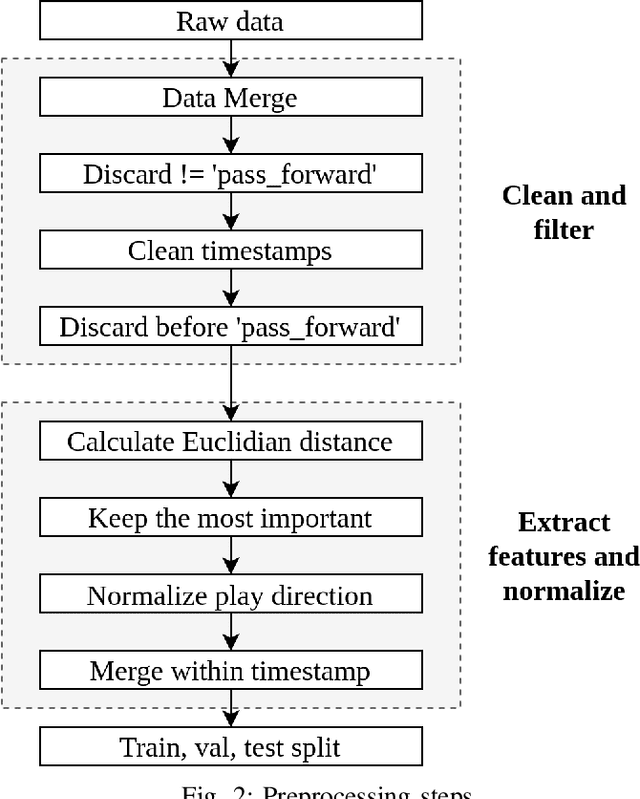


Defensive Pass Interference (DPI) is one of the most impactful penalties in the NFL. DPI is a spot foul, yielding an automatic first down to the team in possession. With such an influence on the game, referees have no room for a mistake. It is also a very rare event, which happens 1-2 times per 100 pass attempts. With technology improving and many IoT wearables being put on the athletes to collect valuable data, there is a solid ground for applying machine learning (ML) techniques to improve every aspect of the game. The work presented here is the first attempt in predicting DPI using player tracking GPS data. The data we used was collected by NFL's Next Gen Stats throughout the 2018 regular season. We present ML models for highly imbalanced time-series binary classification: LSTM, GRU, ANN, and Multivariate LSTM-FCN. Results showed that using GPS tracking data to predict DPI has limited success. The best performing models had high recall with low precision which resulted in the classification of many false positive examples. Looking closely at the data confirmed that there is just not enough information to determine whether a foul was committed. This study might serve as a filter for multi-step pipeline for video sequence classification which could be able to solve this problem.