 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reading Relevant Feature from Global Representation Memory for Visual Object Tracking
Feb 23, 2024
Reference features from a template or historical frames are crucial for visual object tracking. Prior works utilize all features from a fixed template or memory for visual object tracking. However, due to the dynamic nature of videos, the required reference historical information for different search regions at different time steps is also inconsistent. Therefore, using all features in the template and memory can lead to redundancy and impair tracking performance. To alleviate this issue, we propose a novel tracking paradigm, consisting of a relevance attention mechanism and a global representation memory, which can adaptively assist the search region in selecting the most relevant historical information from reference features. Specifically, the proposed relevance attention mechanism in this work differs from previous approaches in that it can dynamically choose and build the optimal global representation memory for the current frame by accessing cross-frame information globally. Moreover, it can flexibly read the relevant historical information from the constructed memory to reduce redundancy and counteract the negative effects of harmful information. Extensive experiments validate the effectiveness of the proposed method, achieving competitive performance on five challenging datasets with 71 FPS.
Applications of 0-1 Neural Networks in Prescription and Prediction
Feb 29, 2024A key challenge in medical decision making is learning treatment policies for patients with limited observational data. This challenge is particularly evident in personalized healthcare decision-making, where models need to take into account the intricate relationships between patient characteristics, treatment options, and health outcomes. To address this, we introduce prescriptive networks (PNNs), shallow 0-1 neural networks trained with mixed integer programming that can be used with counterfactual estimation to optimize policies in medium data settings. These models offer greater interpretability than deep neural networks and can encode more complex policies than common models such as decision trees. We show that PNNs can outperform existing methods in both synthetic data experiments and in a case study of assigning treatments for postpartum hypertension. In particular, PNNs are shown to produce policies that could reduce peak blood pressure by 5.47 mm Hg (p=0.02) over existing clinical practice, and by 2 mm Hg (p=0.01) over the next best prescriptive modeling technique. Moreover PNNs were more likely than all other models to correctly identify clinically significant features while existing models relied on potentially dangerous features such as patient insurance information and race that could lead to bias in treatment.
Measuring Bargaining Abilities of LLMs: A Benchmark and A Buyer-Enhancement Method
Feb 29, 2024Bargaining is an important and unique part of negotiation between humans. As LLM-driven agents learn to negotiate and act like real humans, how to evaluate agents' bargaining abilities remains an open problem. For the first time, we formally described the Bargaining task as an asymmetric incomplete information game, defining the gains of the Buyer and Seller in multiple bargaining processes. It allows us to quantitatively assess an agent's performance in the Bargain task. We collected a real product price dataset, AmazonHistoryPrice, and conducted evaluations of various LLM agents' bargaining abilities. We find that playing a Buyer is much harder than a Seller, and increasing model size can not effectively improve the Buyer's performance. To address the challenge, we propose a novel approach called OG-Narrator that integrates a deterministic Offer Generator to control the price range of Buyer's offers, and an LLM Narrator to create natural language sentences for generated offers. Experimental results show that OG-Narrator improves the buyer's deal rates from 26.67% to 88.88% and brings a ten times of multiplication of profits on all baselines, even a model that has not been aligned.
Can You Learn Semantics Through Next-Word Prediction? The Case of Entailment
Feb 29, 2024Do LMs infer the semantics of text from co-occurrence patterns in their training data? Merrill et al. (2022) argue that, in theory, probabilities predicted by an optimal LM encode semantic information about entailment relations, but it is unclear whether neural LMs trained on corpora learn entailment in this way because of strong idealizing assumptions made by Merrill et al. In this work, we investigate whether their theory can be used to decode entailment judgments from neural LMs. We find that a test similar to theirs can decode entailment relations between natural sentences, well above random chance, though not perfectly, across many datasets and LMs. This suggests LMs implicitly model aspects of semantics to predict semantic effects on sentence co-occurrence patterns. However, we find the test that predicts entailment in practice works in the opposite direction to the theoretical test. We thus revisit the assumptions underlying the original test, finding its derivation did not adequately account for redundancy in human-written text. We argue that correctly accounting for redundancy related to explanations might derive the observed flipped test and, more generally, improve linguistic theories of human speakers.
The 6th Affective Behavior Analysis in-the-wild (ABAW) Competition
Feb 29, 2024This paper describes the 6th Affective Behavior Analysis in-the-wild (ABAW) Competition, which is part of the respective Workshop held in conjunction with IEEE CVPR 2024. The 6th ABAW Competition addresses contemporary challenges in understanding human emotions and behaviors, crucial for the development of human-centered technologies. In more detail, the Competition focuses on affect related benchmarking tasks and comprises of five sub-challenges: i) Valence-Arousal Estimation (the target is to estimate two continuous affect dimensions, valence and arousal), ii) Expression Recognition (the target is to recognise between the mutually exclusive classes of the 7 basic expressions and 'other'), iii) Action Unit Detection (the target is to detect 12 action units), iv) Compound Expression Recognition (the target is to recognise between the 7 mutually exclusive compound expression classes), and v) Emotional Mimicry Intensity Estimation (the target is to estimate six continuous emotion dimensions). In the paper, we present these Challenges, describe their respective datasets and challenge protocols (we outline the evaluation metrics) and present the baseline systems as well as their obtained performance. More information for the Competition can be found in: \url{https://affective-behavior-analysis-in-the-wild.github.io/6th}.
Negative Sampling in Knowledge Graph Representation Learning: A Review
Feb 29, 2024Knowledge graph representation learning (KGRL) or knowledge graph embedding (KGE) plays a crucial role in AI applications for knowledge construction and information exploration. These models aim to encode entities and relations present in a knowledge graph into a lower-dimensional vector space. During the training process of KGE models, using positive and negative samples becomes essential for discrimination purposes. However, obtaining negative samples directly from existing knowledge graphs poses a challenge, emphasizing the need for effective generation techniques. The quality of these negative samples greatly impacts the accuracy of the learned embeddings, making their generation a critical aspect of KGRL. This comprehensive survey paper systematically reviews various negative sampling (NS) methods and their contributions to the success of KGRL. Their respective advantages and disadvantages are outlined by categorizing existing NS methods into five distinct categories. Moreover, this survey identifies open research questions that serve as potential directions for future investigations. By offering a generalization and alignment of fundamental NS concepts, this survey provides valuable insights for designing effective NS methods in the context of KGRL and serves as a motivating force for further advancements in the field.
Effective Message Hiding with Order-Preserving Mechanisms
Feb 29, 2024Message hiding, a technique that conceals secret message bits within a cover image, aims to achieve an optimal balance among message capacity, recovery accuracy, and imperceptibility. While convolutional neural networks have notably improved message capacity and imperceptibility, achieving high recovery accuracy remains challenging. This challenge arises because convolutional operations struggle to preserve the sequential order of message bits and effectively address the discrepancy between these two modalities. To address this, we propose StegaFormer, an innovative MLP-based framework designed to preserve bit order and enable global fusion between modalities. Specifically, StegaFormer incorporates three crucial components: Order-Preserving Message Encoder (OPME), Decoder (OPMD) and Global Message-Image Fusion (GMIF). OPME and OPMD aim to preserve the order of message bits by segmenting the entire sequence into equal-length segments and incorporating sequential information during encoding and decoding. Meanwhile, GMIF employs a cross-modality fusion mechanism to effectively fuse the features from the two uncorrelated modalities. Experimental results on the COCO and DIV2K datasets demonstrate that StegaFormer surpasses existing state-of-the-art methods in terms of recovery accuracy, message capacity, and imperceptibility. We will make our code publicly available.
High-Speed Motion Planning for Aerial Swarms in Unknown and Cluttered Environments
Feb 29, 2024Coordinated flight of multiple drones allows to achieve tasks faster such as search and rescue and infrastructure inspection. Thus, pushing the state-of-the-art of aerial swarms in navigation speed and robustness is of tremendous benefit. In particular, being able to account for unexplored/unknown environments when planning trajectories allows for safer flight. In this work, we propose the first high-speed, decentralized, and synchronous motion planning framework (HDSM) for an aerial swarm that explicitly takes into account the unknown/undiscovered parts of the environment. The proposed approach generates an optimized trajectory for each planning agent that avoids obstacles and other planning agents while moving and exploring the environment. The only global information that each agent has is the target location. The generated trajectory is high-speed, safe from unexplored spaces, and brings the agent closer to its goal. The proposed method outperforms four recent state-of-the-art methods in success rate (100% success in reaching the target location), flight speed (67% faster), and flight time (42% lower). Finally, the method is validated on a set of Crazyflie nano-drones as a proof of concept.
GoalNet: Goal Areas Oriented Pedestrian Trajectory Prediction
Feb 29, 2024Predicting the future trajectories of pedestrians on the road is an important task for autonomous driving. The pedestrian trajectory prediction is affected by scene paths, pedestrian's intentions and decision-making, which is a multi-modal problem. Most recent studies use past trajectories to predict a variety of potential future trajectory distributions, which do not account for the scene context and pedestrian targets. Instead of predicting the future trajectory directly, we propose to use scene context and observed trajectory to predict the goal points first, and then reuse the goal points to predict the future trajectories. By leveraging the information from scene context and observed trajectory, the uncertainty can be limited to a few target areas, which represent the "goals" of the pedestrians. In this paper, we propose GoalNet, a new trajectory prediction neural network based on the goal areas of a pedestrian. Our network can predict both pedestrian's trajectories and bounding boxes. The overall model is efficient and modular, and its outputs can be changed according to the usage scenario. Experimental results show that GoalNet significantly improves the previous state-of-the-art performance by 48.7% on the JAAD and 40.8% on the PIE dataset.
EyeGPT: Ophthalmic Assistant with Large Language Models
Feb 29, 2024
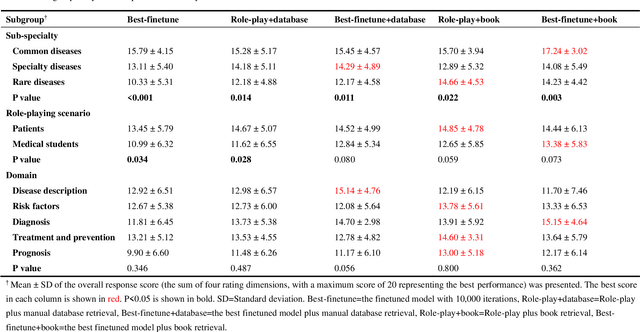
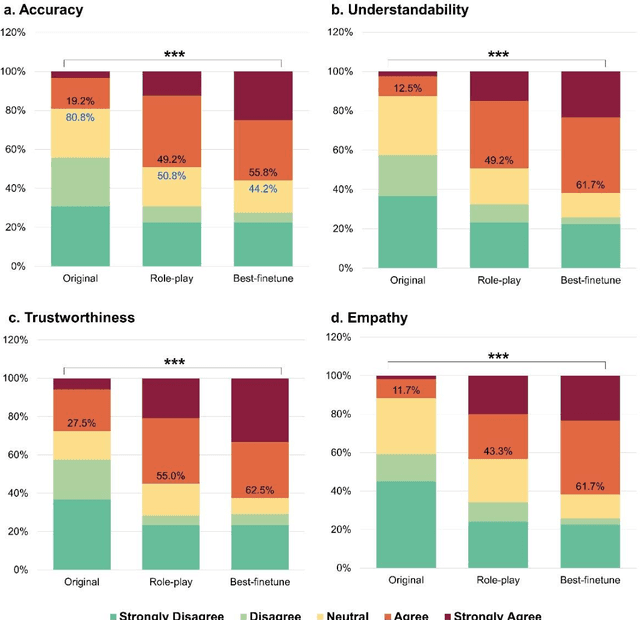
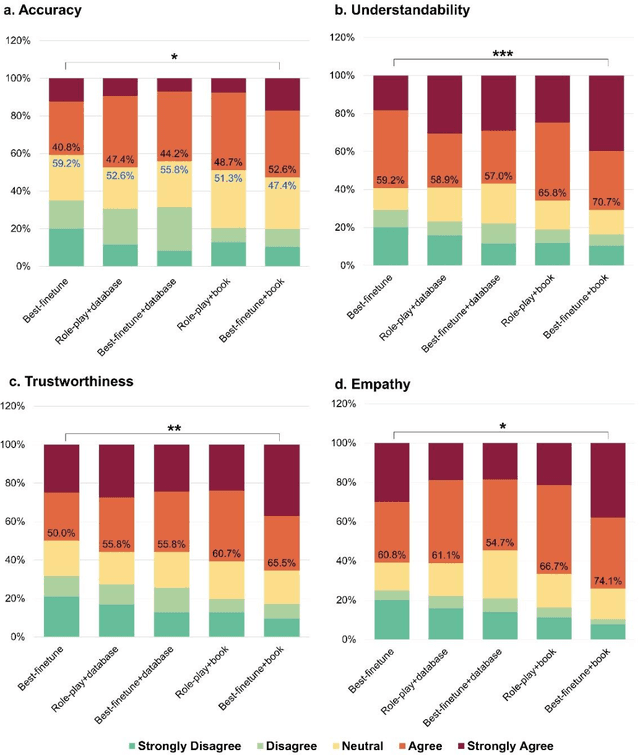
Artificial intelligence (AI) has gained significant attention in healthcare consultation due to its potential to improve clinical workflow and enhance medical communication. However, owing to the complex nature of medical information, large language models (LLM) trained with general world knowledge might not possess the capability to tackle medical-related tasks at an expert level. Here, we introduce EyeGPT, a specialized LLM designed specifically for ophthalmology, using three optimization strategies including role-playing, finetuning, and retrieval-augmented generation. In particular, we proposed a comprehensive evaluation framework that encompasses a diverse dataset, covering various subspecialties of ophthalmology, different users, and diverse inquiry intents. Moreover, we considered multiple evaluation metrics, including accuracy, understandability, trustworthiness, empathy, and the proportion of hallucinations. By assessing the performance of different EyeGPT variants, we identify the most effective one, which exhibits comparable levels of understandability, trustworthiness, and empathy to human ophthalmologists (all Ps>0.05). Overall, ur study provides valuable insights for future research, facilitating comprehensive comparisons and evaluations of different strategies for developing specialized LLMs in ophthalmology. The potential benefits include enhancing the patient experience in eye care and optimizing ophthalmologists' services.