 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BSAL: A Framework of Bi-component Structure and Attribute Learning for Link Prediction
Apr 18, 2022
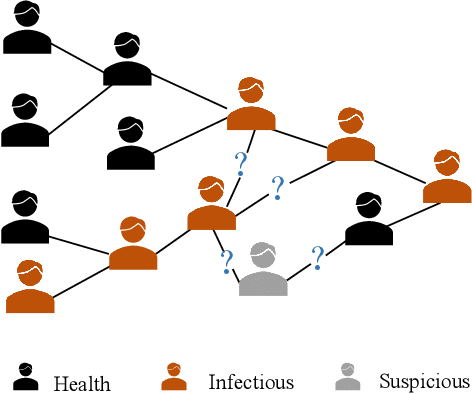

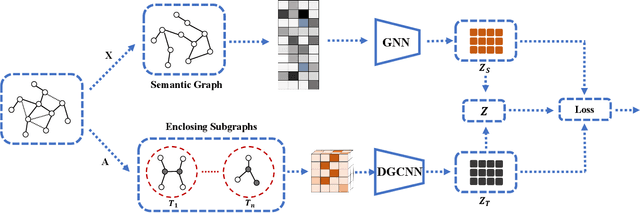
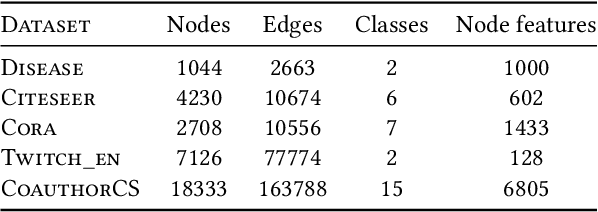
Given the ubiquitous existence of graph-structured data, learning the representations of nodes for the downstream tasks ranging from node classification, link prediction to graph classification is of crucial importance. Regarding missing link inference of diverse networks, we revisit the link prediction techniques and identify the importance of both the structural and attribute information. However, the available techniques either heavily count on the network topology which is spurious in practice or cannot integrate graph topology and features properly. To bridge the gap, we propose a bicomponent structural and attribute learning framework (BSAL) that is designed to adaptively leverage information from topology and feature spaces. Specifically, BSAL constructs a semantic topology via the node attributes and then gets the embeddings regarding the semantic view, which provides a flexible and easy-to-implement solution to adaptively incorporate the information carried by the node attributes. Then the semantic embedding together with topology embedding is fused together using an attention mechanism for the final prediction. Extensive experiments show the superior performance of our proposal and it significantly outperforms baselines on diverse research benchmarks.
Curious Exploration via Structured World Models Yields Zero-Shot Object Manipulation
Jun 22, 2022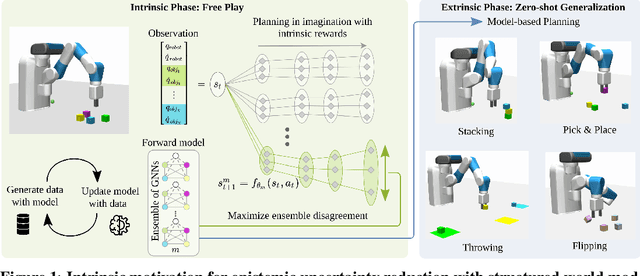

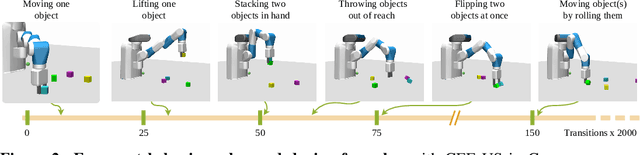
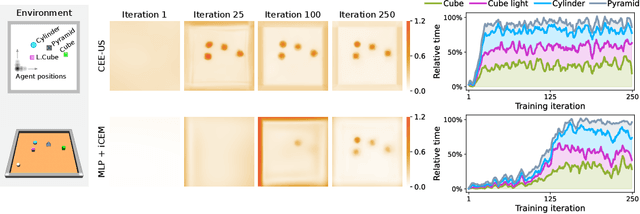
It has been a long-standing dream to design artificial agents that explore their environment efficiently via intrinsic motivation, similar to how children perform curious free play. Despite recent advances in intrinsically motivated reinforcement learning (RL), sample-efficient exploration in object manipulation scenarios remains a significant challenge as most of the relevant information lies in the sparse agent-object and object-object interactions. In this paper, we propose to use structured world models to incorporate relational inductive biases in the control loop to achieve sample-efficient and interaction-rich exploration in compositional multi-object environments. By planning for future novelty inside structured world models, our method generates free-play behavior that starts to interact with objects early on and develops more complex behavior over time. Instead of using models only to compute intrinsic rewards, as commonly done, our method showcases that the self-reinforcing cycle between good models and good exploration also opens up another avenue: zero-shot generalization to downstream tasks via model-based planning. After the entirely intrinsic task-agnostic exploration phase, our method solves challenging downstream tasks such as stacking, flipping, pick & place, and throwing that generalizes to unseen numbers and arrangements of objects without any additional training.
KGRGRL: A User's Permission Reasoning Method Based on Knowledge Graph Reward Guidance Reinforcement Learning
May 16, 2022
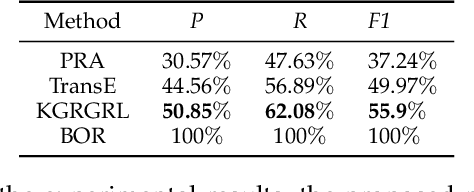
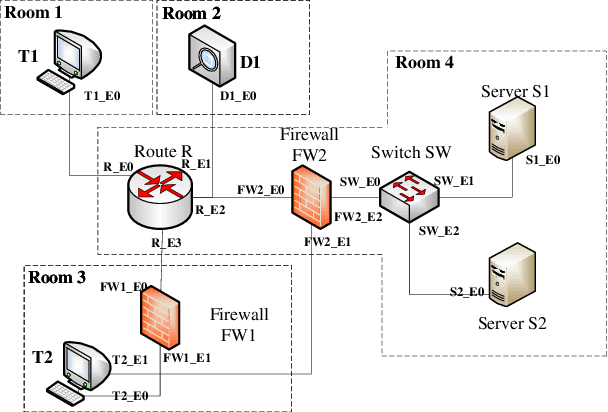
In general, multiple domain cyberspace security assessments can be implemented by reasoning user's permissions. However, while existing methods include some information from the physical and social domains, they do not provide a comprehensive representation of cyberspace. Existing reasoning methods are also based on expert-given rules, resulting in inefficiency and a low degree of intelligence. To address this challenge, we create a Knowledge Graph (KG) of multiple domain cyberspace in order to provide a standard semantic description of the multiple domain cyberspace. Following that, we proposed a user's permissions reasoning method based on reinforcement learning. All permissions in cyberspace are represented as nodes, and an agent is trained to find all permissions that user can have according to user's initial permissions and cyberspace KG. We set 10 reward setting rules based on the features of cyberspace KG in the reinforcement learning of reward information setting, so that the agent can better locate user's all permissions and avoid blindly finding user's permissions. The results of the experiments showed that the proposed method can successfully reason about user's permissions and increase the intelligence level of the user's permissions reasoning method. At the same time, the F1 value of the proposed method is 6% greater than that of the Translating Embedding (TransE) method.
Recovering Patient Journeys: A Corpus of Biomedical Entities and Relations on Twitter (BEAR)
Apr 21, 2022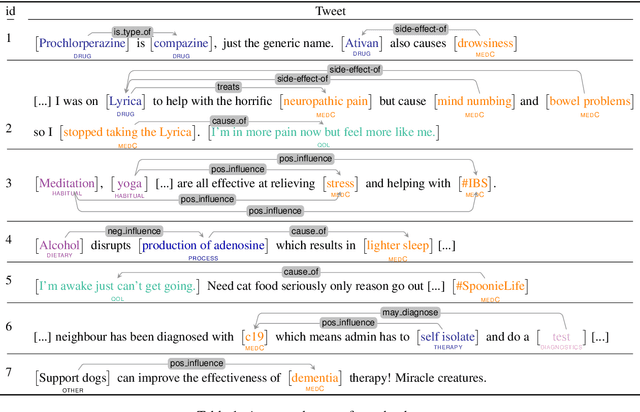
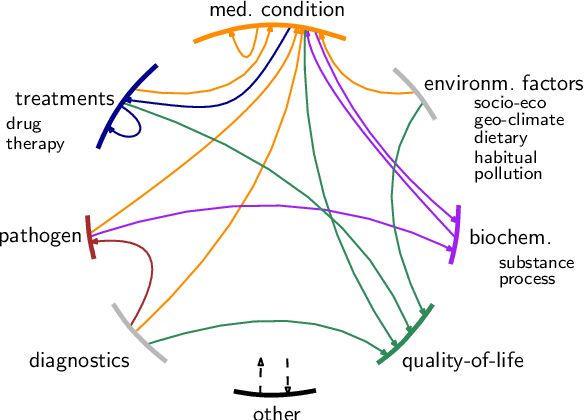
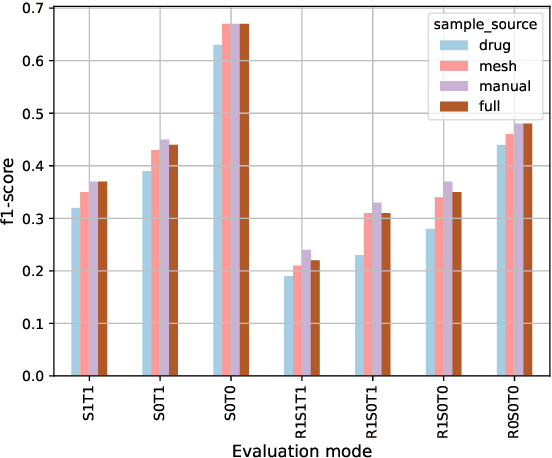
Text mining and information extraction for the medical domain has focused on scientific text generated by researchers. However, their direct access to individual patient experiences or patient-doctor interactions can be limited. Information provided on social media, e.g., by patients and their relatives, complements the knowledge in scientific text. It reflects the patient's journey and their subjective perspective on the process of developing symptoms, being diagnosed and offered a treatment, being cured or learning to live with a medical condition. The value of this type of data is therefore twofold: Firstly, it offers direct access to people's perspectives. Secondly, it might cover information that is not available elsewhere, including self-treatment or self-diagnoses. Named entity recognition and relation extraction are methods to structure information that is available in unstructured text. However, existing medical social media corpora focused on a comparably small set of entities and relations and particular domains, rather than putting the patient into the center of analyses. With this paper we contribute a corpus with a rich set of annotation layers following the motivation to uncover and model patients' journeys and experiences in more detail. We label 14 entity classes (incl. environmental factors, diagnostics, biochemical processes, patients' quality-of-life descriptions, pathogens, medical conditions, and treatments) and 20 relation classes (e.g., prevents, influences, interactions, causes) most of which have not been considered before for social media data. The publicly available dataset consists of 2,100 tweets with approx. 6,000 entity and 3,000 relation annotations. In a corpus analysis we find that over 80 % of documents contain relevant entities. Over 50 % of tweets express relations which we consider essential for uncovering patients' narratives about their journeys.
Building Spatio-temporal Transformers for Egocentric 3D Pose Estimation
Jun 09, 2022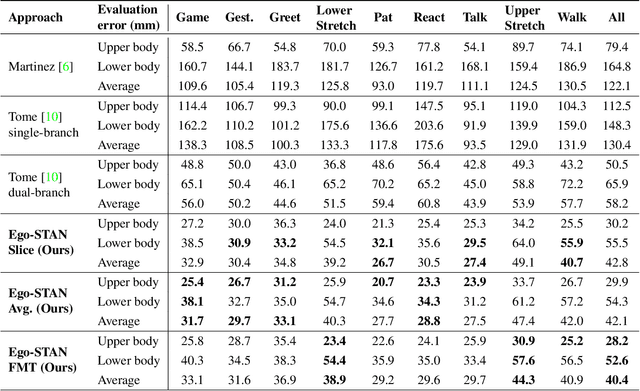
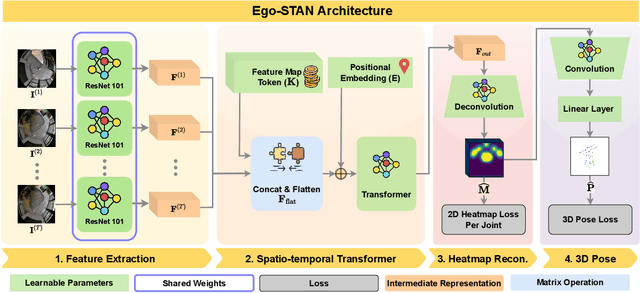
Egocentric 3D human pose estimation (HPE) from images is challenging due to severe self-occlusions and strong distortion introduced by the fish-eye view from the head mounted camera. Although existing works use intermediate heatmap-based representations to counter distortion with some success, addressing self-occlusion remains an open problem. In this work, we leverage information from past frames to guide our self-attention-based 3D HPE estimation procedure -- Ego-STAN. Specifically, we build a spatio-temporal Transformer model that attends to semantically rich convolutional neural network-based feature maps. We also propose feature map tokens: a new set of learnable parameters to attend to these feature maps. Finally, we demonstrate Ego-STAN's superior performance on the xR-EgoPose dataset where it achieves a 30.6% improvement on the overall mean per-joint position error, while leading to a 22% drop in parameters compared to the state-of-the-art.
Towards Bridging Algorithm and Theory for Unbiased Recommendation
Jun 07, 2022
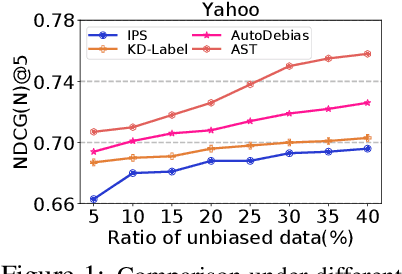
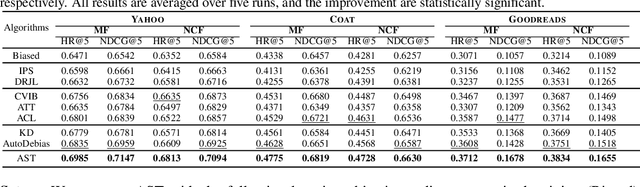
This work studies the problem of learning unbiased algorithms from biased feedback for recommender systems. We address this problem from both theoretical and algorithmic perspectives. Recent works in unbiased learning have advanced the state-of-the-art with various techniques such as meta-learning, knowledge distillation, and information bottleneck. Despite their empirical successes, most of them lack theoretical guarantee, forming non-negligible gaps between the theories and recent algorithms. To this end, we first view the unbiased recommendation problem from a distribution shift perspective. We theoretically analyze the generalization bounds of unbiased learning and suggest their close relations with recent unbiased learning objectives. Based on the theoretical analysis, we further propose a principled framework, Adversarial Self-Training (AST), for unbiased recommendation. Empirical evaluation on real-world and semi-synthetic datasets demonstrate the effectiveness of the proposed AST.
Analyzing the behaviour of D'WAVE quantum annealer: fine-tuning parameterization and tests with restrictive Hamiltonian formulations
Jul 01, 2022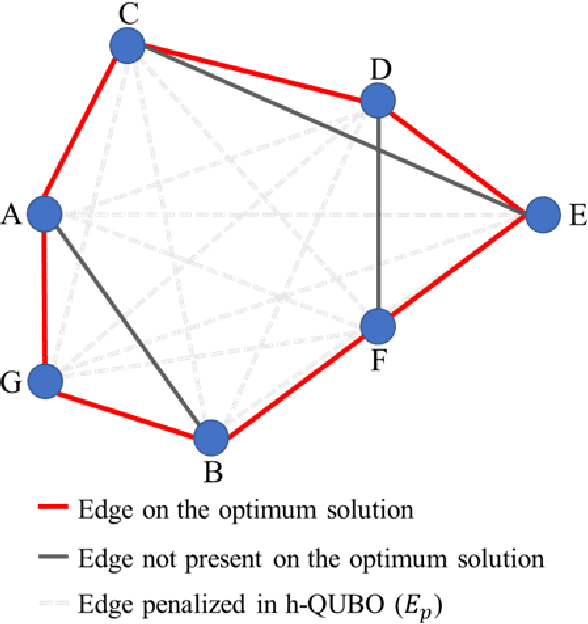
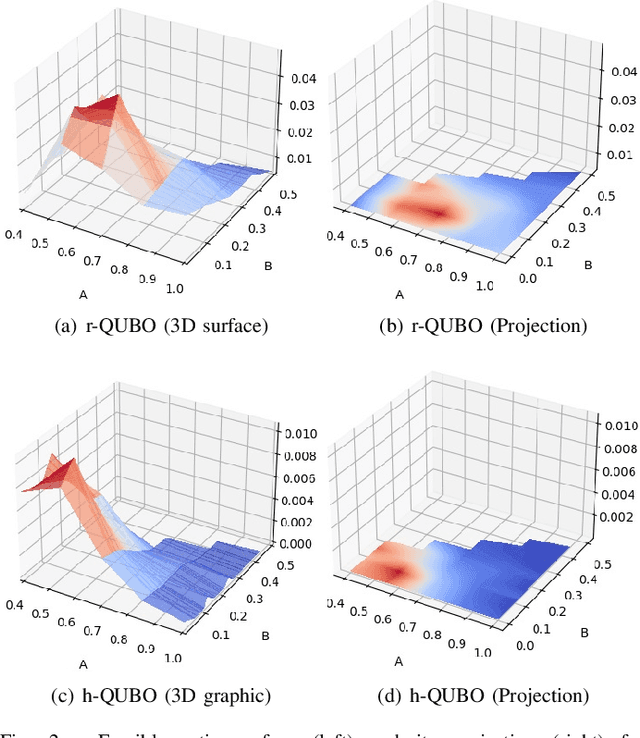
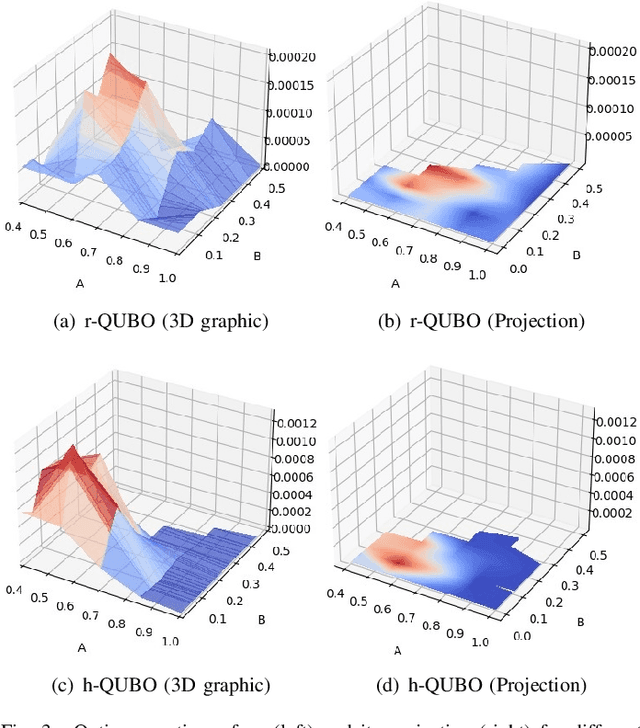
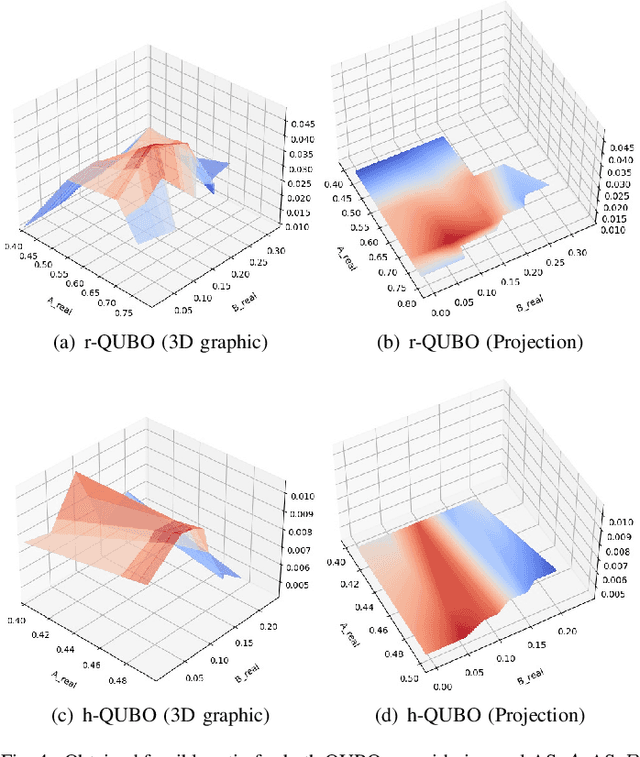
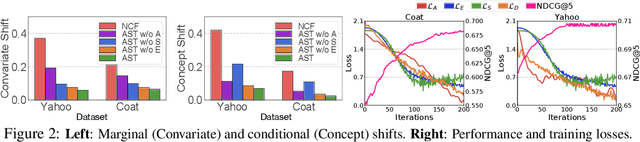
Despite being considered as the next frontier in computation, Quantum Computing is still in an early stage of development. Indeed, current commercial quantum computers suffer from some critical restraints, such as noisy processes and a limited amount of qubits, among others, that affect the performance of quantum algorithms. Despite these limitations, researchers have devoted much effort to propose different frameworks for efficiently using these Noisy Intermediate-Scale Quantum (NISQ) devices. One of these procedures is D'WAVE Systems' quantum-annealer, which can be use to solve optimization problems by translating them into an energy minimization problem. In this context, this work is focused on providing useful insights and information into the behaviour of the quantum-annealer when addressing real-world combinatorial optimization problems. Our main motivation with this study is to open some quantum computing frontiers to non-expert stakeholders. To this end, we perform an extensive experimentation, in the form of a parameter sensitive analysis. This experimentation has been conducted using the Traveling Salesman Problem as benchmarking problem, and adopting two QUBOs: state-of-the-art and a heuristically generated. Our analysis has been performed on a single 7-noded instance, and it is based on more than 200 different parameter configurations, comprising more than 3700 unitary runs and 7 million of quantum reads. Thanks to this study, findings related to the energy distribution and most appropriate parameter settings have been obtained. Finally, an additional study has been performed, aiming to determine the efficiency of the heuristically built QUBO in further TSP instances.
ViBERTgrid: A Jointly Trained Multi-Modal 2D Document Representation for Key Information Extraction from Documents
May 25, 2021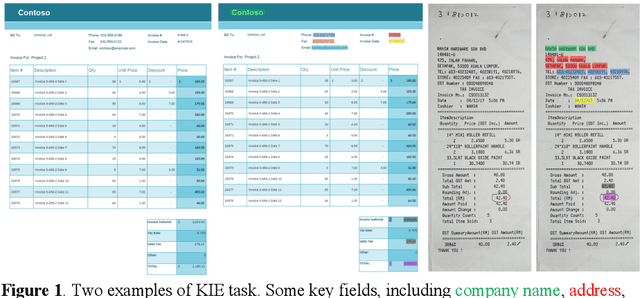
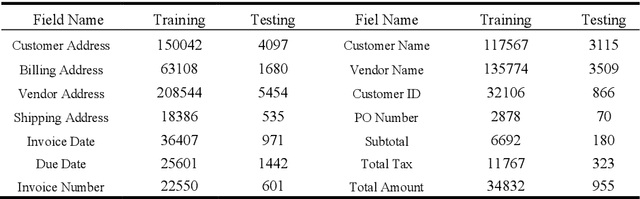
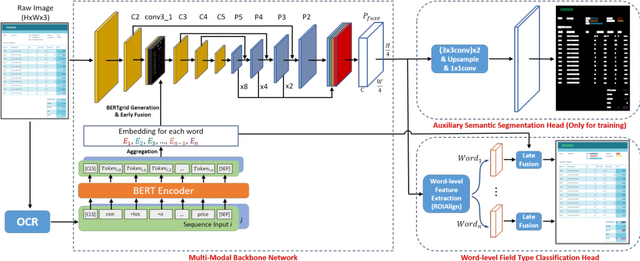
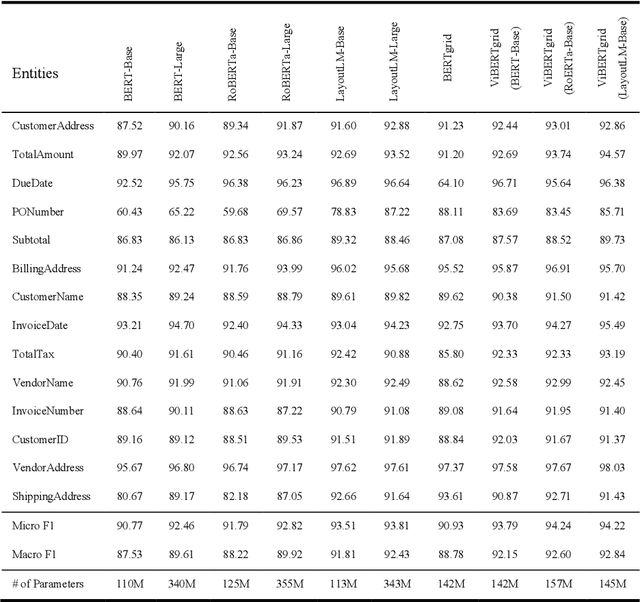
Recent grid-based document representations like BERTgrid allow the simultaneous encoding of the textual and layout information of a document in a 2D feature map so that state-of-the-art image segmentation and/or object detection models can be straightforwardly leveraged to extract key information from documents. However, such methods have not achieved comparable performance to state-of-the-art sequence- and graph-based methods such as LayoutLM and PICK yet. In this paper, we propose a new multi-modal backbone network by concatenating a BERTgrid to an intermediate layer of a CNN model, where the input of CNN is a document image and the BERTgrid is a grid of word embeddings, to generate a more powerful grid-based document representation, named ViBERTgrid. Unlike BERTgrid, the parameters of BERT and CNN in our multimodal backbone network are trained jointly. Our experimental results demonstrate that this joint training strategy improves significantly the representation ability of ViBERTgrid. Consequently, our ViBERTgrid-based key information extraction approach has achieved state-of-the-art performance on real-world datasets.
Federated Data Analytics: A Study on Linear Models
Jun 15, 2022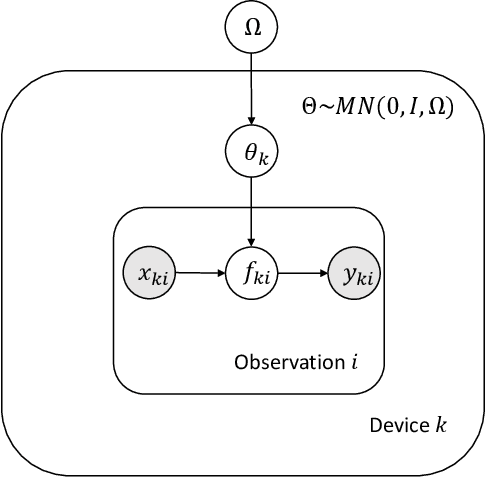
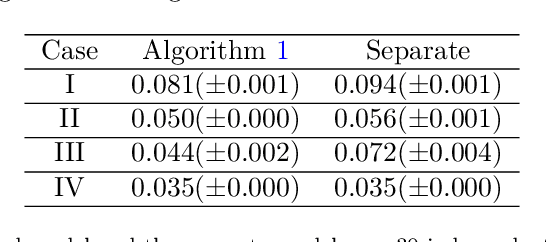
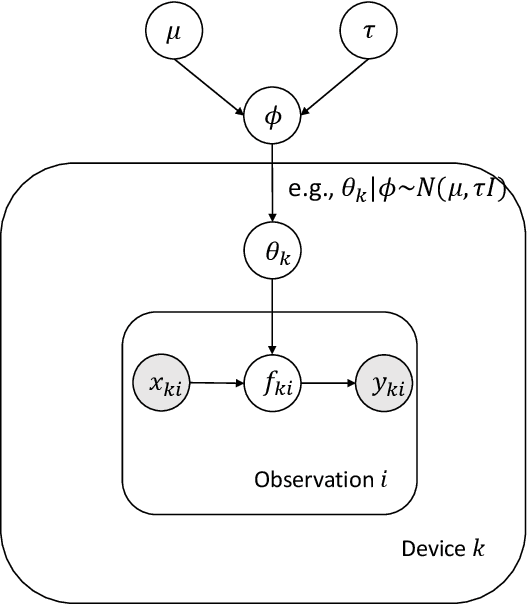

As edge devices become increasingly powerful, data analytics are gradually moving from a centralized to a decentralized regime where edge compute resources are exploited to process more of the data locally. This regime of analytics is coined as federated data analytics (FDA). In spite of the recent success stories of FDA, most literature focuses exclusively on deep neural networks. In this work, we take a step back to develop an FDA treatment for one of the most fundamental statistical models: linear regression. Our treatment is built upon hierarchical modeling that allows borrowing strength across multiple groups. To this end, we propose two federated hierarchical model structures that provide a shared representation across devices to facilitate information sharing. Notably, our proposed frameworks are capable of providing uncertainty quantification, variable selection, hypothesis testing and fast adaptation to new unseen data. We validate our methods on a range of real-life applications including condition monitoring for aircraft engines. The results show that our FDA treatment for linear models can serve as a competing benchmark model for future development of federated algorithms.
Continual Learning with Transformers for Image Classification
Jun 28, 2022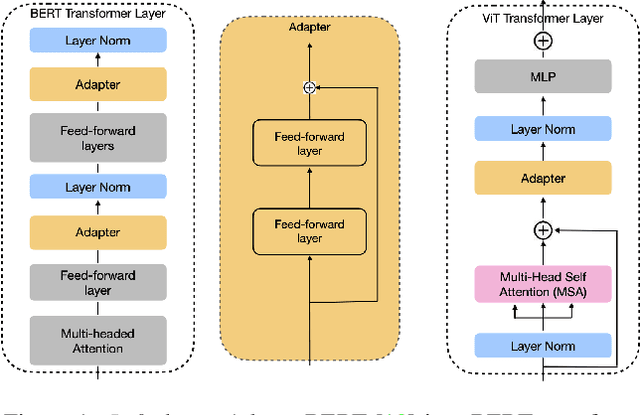
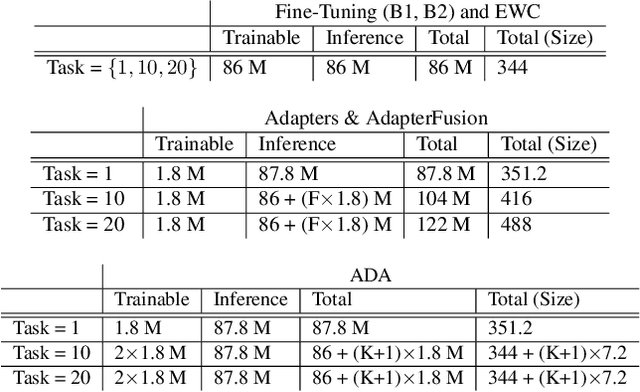
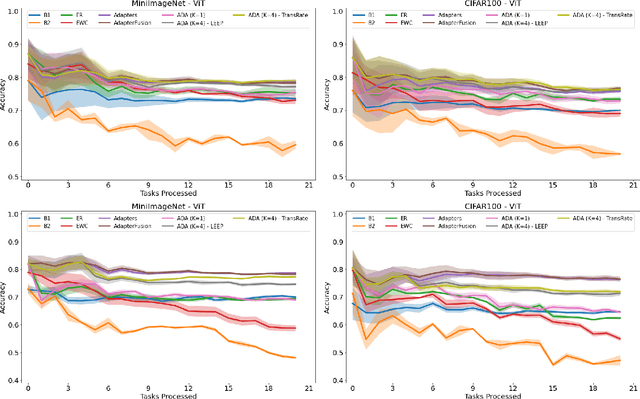
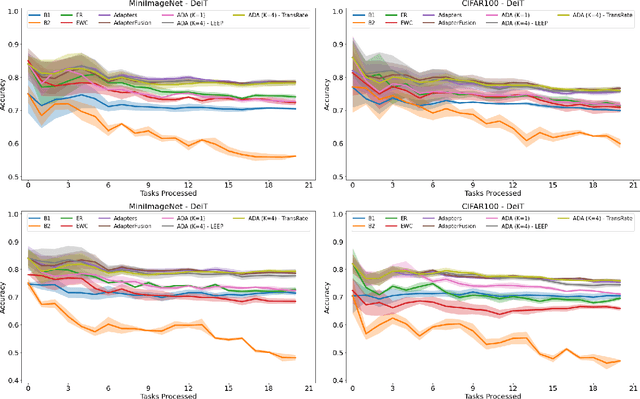
In many real-world scenarios, data to train machine learning models become available over time. However, neural network models struggle to continually learn new concepts without forgetting what has been learnt in the past. This phenomenon is known as catastrophic forgetting and it is often difficult to prevent due to practical constraints, such as the amount of data that can be stored or the limited computation sources that can be used. Moreover, training large neural networks, such as Transformers, from scratch is very costly and requires a vast amount of training data, which might not be available in the application domain of interest. A recent trend indicates that dynamic architectures based on an expansion of the parameters can reduce catastrophic forgetting efficiently in continual learning, but this needs complex tuning to balance the growing number of parameters and barely share any information across tasks. As a result, they struggle to scale to a large number of tasks without significant overhead. In this paper, we validate in the computer vision domain a recent solution called Adaptive Distillation of Adapters (ADA), which is developed to perform continual learning using pre-trained Transformers and Adapters on text classification tasks. We empirically demonstrate on different classification tasks that this method maintains a good predictive performance without retraining the model or increasing the number of model parameters over the time. Besides it is significantly faster at inference time compared to the state-of-the-art methods.