 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Estimation of Speckle Statistics Parametric Images
Jun 08, 2022

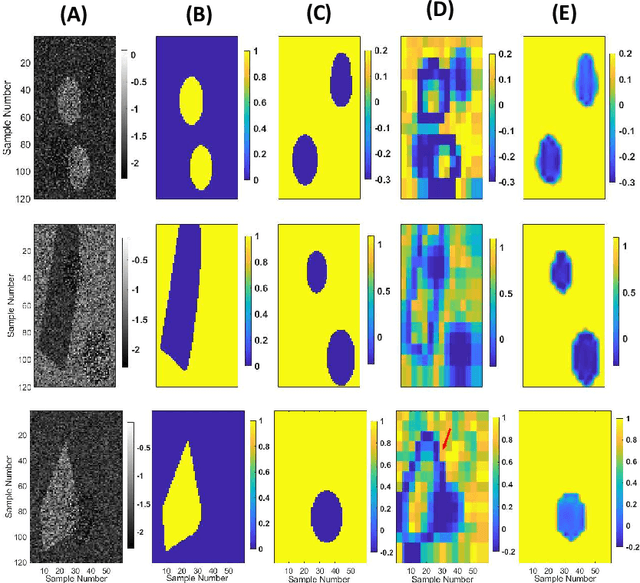

Quantitative Ultrasound (QUS) provides important information about the tissue properties. QUS parametric image can be formed by dividing the envelope data into small overlapping patches and computing different speckle statistics such as parameters of the Nakagami and Homodyned K-distributions (HK-distribution). The calculated QUS parametric images can be erroneous since only a few independent samples are available inside the patches. Another challenge is that the envelope samples inside the patch are assumed to come from the same distribution, an assumption that is often violated given that the tissue is usually not homogenous. In this paper, we propose a method based on Convolutional Neural Networks (CNN) to estimate QUS parametric images without patching. We construct a large dataset sampled from the HK-distribution, having regions with random shapes and QUS parameter values. We then use a well-known network to estimate QUS parameters in a multi-task learning fashion. Our results confirm that the proposed method is able to reduce errors and improve border definition in QUS parametric images.
SSR-GNNs: Stroke-based Sketch Representation with Graph Neural Networks
Apr 27, 2022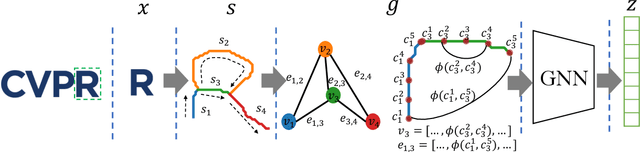
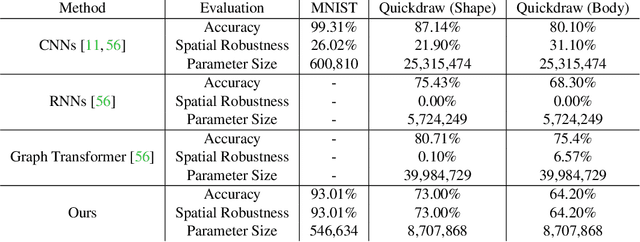
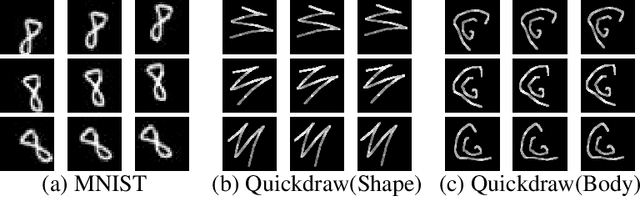
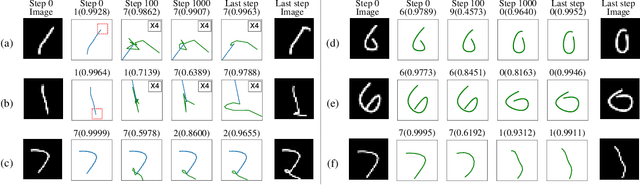
This paper follows cognitive studies to investigate a graph representation for sketches, where the information of strokes, i.e., parts of a sketch, are encoded on vertices and information of inter-stroke on edges. The resultant graph representation facilitates the training of a Graph Neural Networks for classification tasks, and achieves accuracy and robustness comparable to the state-of-the-art against translation and rotation attacks, as well as stronger attacks on graph vertices and topologies, i.e., modifications and addition of strokes, all without resorting to adversarial training. Prior studies on sketches, e.g., graph transformers, encode control points of stroke on vertices, which are not invariant to spatial transformations. In contrary, we encode vertices and edges using pairwise distances among control points to achieve invariance. Compared with existing generative sketch model for one-shot classification, our method does not rely on run-time statistical inference. Lastly, the proposed representation enables generation of novel sketches that are structurally similar to while separable from the existing dataset.
Optimizing Relevance Maps of Vision Transformers Improves Robustness
Jun 02, 2022
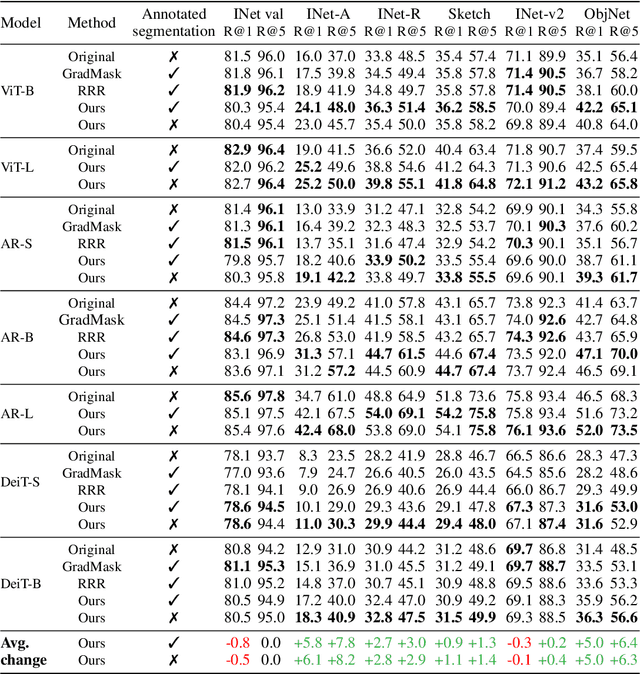
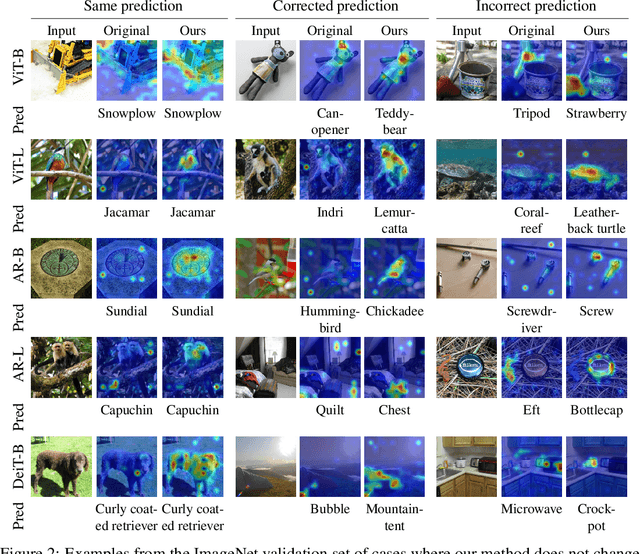
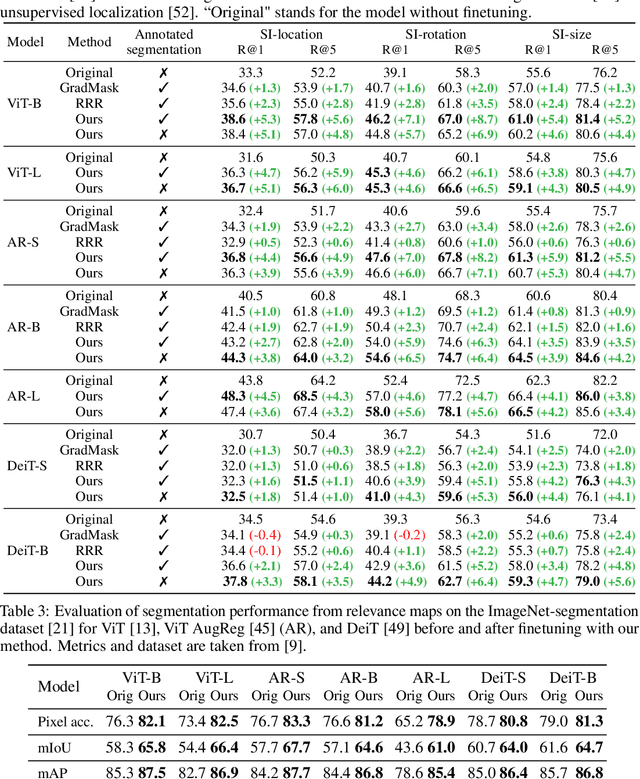
It has been observed that visual classification models often rely mostly on the image background, neglecting the foreground, which hurts their robustness to distribution changes. To alleviate this shortcoming, we propose to monitor the model's relevancy signal and manipulate it such that the model is focused on the foreground object. This is done as a finetuning step, involving relatively few samples consisting of pairs of images and their associated foreground masks. Specifically, we encourage the model's relevancy map (i) to assign lower relevance to background regions, (ii) to consider as much information as possible from the foreground, and (iii) we encourage the decisions to have high confidence. When applied to Vision Transformer (ViT) models, a marked improvement in robustness to domain shifts is observed. Moreover, the foreground masks can be obtained automatically, from a self-supervised variant of the ViT model itself; therefore no additional supervision is required.
Likelihood-free Model Choice for Simulator-based Models with the Jensen--Shannon Divergence
Jun 08, 2022
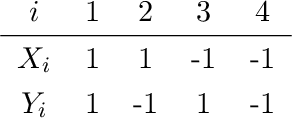
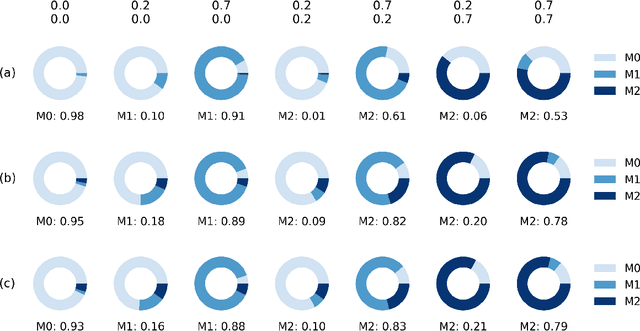
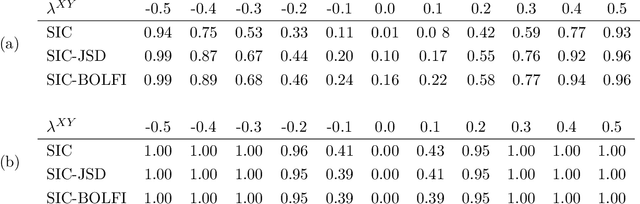
Choice of appropriate structure and parametric dimension of a model in the light of data has a rich history in statistical research, where the first seminal approaches were developed in 1970s, such as the Akaike's and Schwarz's model scoring criteria that were inspired by information theory and embodied the rationale called Occam's razor. After those pioneering works, model choice was quickly established as its own field of research, gaining considerable attention in both computer science and statistics. However, to date, there have been limited attempts to derive scoring criteria for simulator-based models lacking a likelihood expression. Bayes factors have been considered for such models, but arguments have been put both for and against use of them and around issues related to their consistency. Here we use the asymptotic properties of Jensen--Shannon divergence (JSD) to derive a consistent model scoring criterion for the likelihood-free setting called JSD-Razor. Relationships of JSD-Razor with established scoring criteria for the likelihood-based approach are analyzed and we demonstrate the favorable properties of our criterion using both synthetic and real modeling examples.
Evaluating Mixed-initiative Conversational Search Systems via User Simulation
Apr 20, 2022
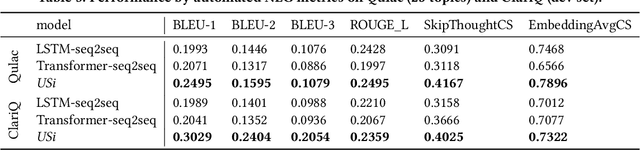

Clarifying the underlying user information need by asking clarifying questions is an important feature of modern conversational search system. However, evaluation of such systems through answering prompted clarifying questions requires significant human effort, which can be time-consuming and expensive. In this paper, we propose a conversational User Simulator, called USi, for automatic evaluation of such conversational search systems. Given a description of an information need, USi is capable of automatically answering clarifying questions about the topic throughout the search session. Through a set of experiments, including automated natural language generation metrics and crowdsourcing studies, we show that responses generated by USi are both inline with the underlying information need and comparable to human-generated answers. Moreover, we make the first steps towards multi-turn interactions, where conversational search systems asks multiple questions to the (simulated) user with a goal of clarifying the user need. To this end, we expand on currently available datasets for studying clarifying questions, i.e., Qulac and ClariQ, by performing a crowdsourcing-based multi-turn data acquisition. We show that our generative, GPT2-based model, is capable of providing accurate and natural answers to unseen clarifying questions in the single-turn setting and discuss capabilities of our model in the multi-turn setting. We provide the code, data, and the pre-trained model to be used for further research on the topic.
Image Segmentation with Topological Priors
May 12, 2022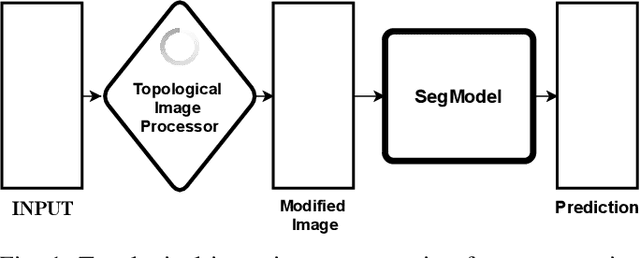
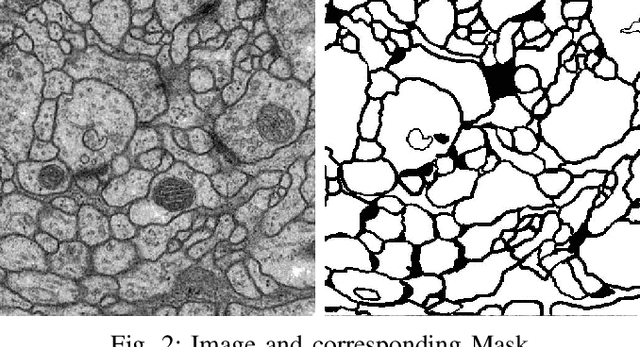
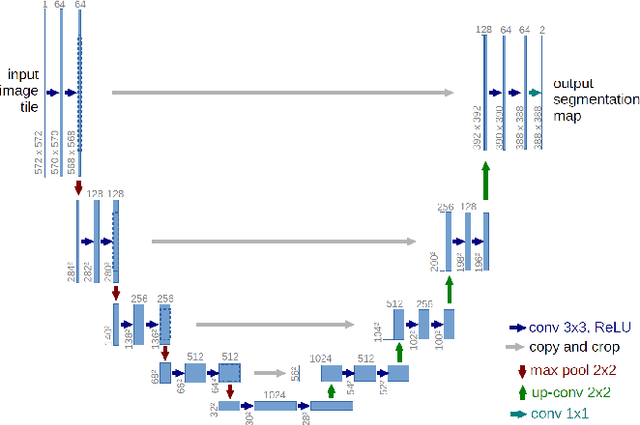
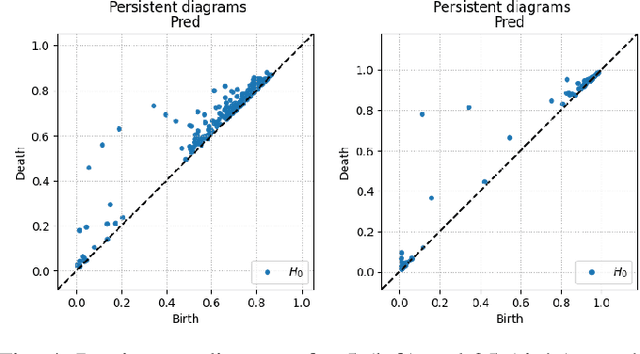
Solving segmentation tasks with topological priors proved to make fewer errors in fine-scale structures. In this work, we use topological priors both before and during the deep neural network training procedure. We compared the results of the two approaches with simple segmentation on various accuracy metrics and the Betti number error, which is directly related to topological correctness, and discovered that incorporating topological information into the classical UNet model performed significantly better. We conducted experiments on the ISBI EM segmentation dataset.
Exploring Negatives in Contrastive Learning for Unpaired Image-to-Image Translation
Apr 23, 2022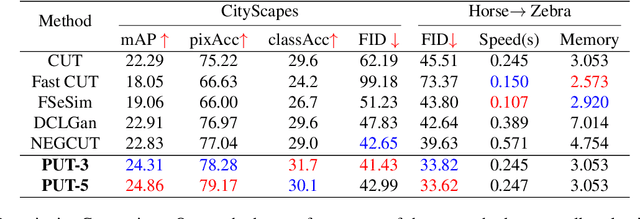
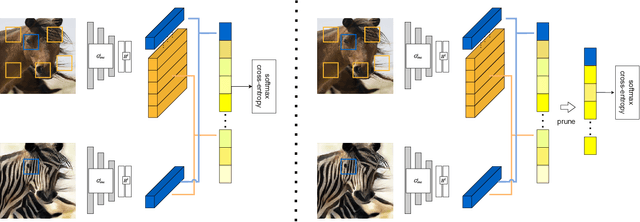

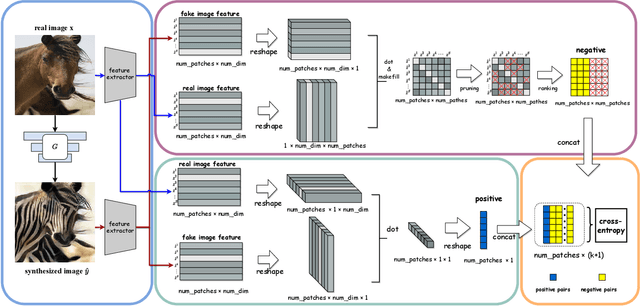
Unpaired image-to-image translation aims to find a mapping between the source domain and the target domain. To alleviate the problem of the lack of supervised labels for the source images, cycle-consistency based methods have been proposed for image structure preservation by assuming a reversible relationship between unpaired images. However, this assumption only uses limited correspondence between image pairs. Recently, contrastive learning (CL) has been used to further investigate the image correspondence in unpaired image translation by using patch-based positive/negative learning. Patch-based contrastive routines obtain the positives by self-similarity computation and recognize the rest patches as negatives. This flexible learning paradigm obtains auxiliary contextualized information at a low cost. As the negatives own an impressive sample number, with curiosity, we make an investigation based on a question: are all negatives necessary for feature contrastive learning? Unlike previous CL approaches that use negatives as much as possible, in this paper, we study the negatives from an information-theoretic perspective and introduce a new negative Pruning technology for Unpaired image-to-image Translation (PUT) by sparsifying and ranking the patches. The proposed algorithm is efficient, flexible and enables the model to learn essential information between corresponding patches stably. By putting quality over quantity, only a few negative patches are required to achieve better results. Lastly, we validate the superiority, stability, and versatility of our model through comparative experiments.
SepIt Approaching a Single Channel Speech Separation Bound
May 24, 2022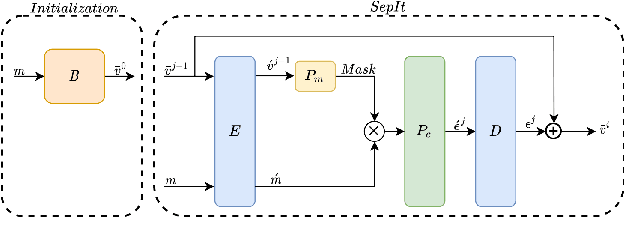
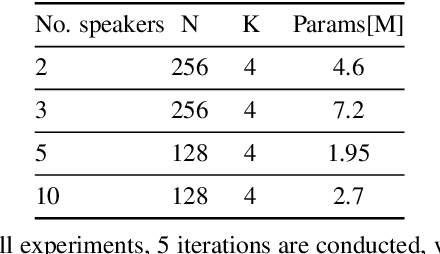
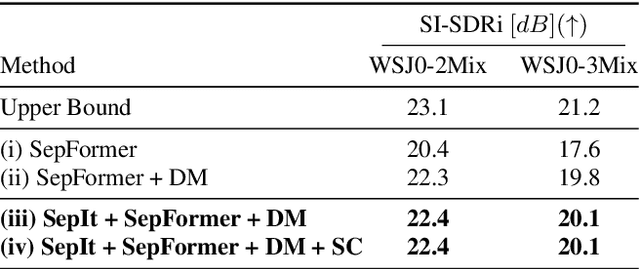
We present an upper bound for the Single Channel Speech Separation task, which is based on an assumption regarding the nature of short segments of speech. Using the bound, we are able to show that while the recent methods have made significant progress for a few speakers, there is room for improvement for five and ten speakers. We then introduce a Deep neural network, SepIt, that iteratively improves the different speakers' estimation. At test time, SpeIt has a varying number of iterations per test sample, based on a mutual information criterion that arises from our analysis. In an extensive set of experiments, SepIt outperforms the state-of-the-art neural networks for 2, 3, 5, and 10 speakers.
Genetic Meta-Structure Search for Recommendation on Heterogeneous Information Network
Feb 21, 2021
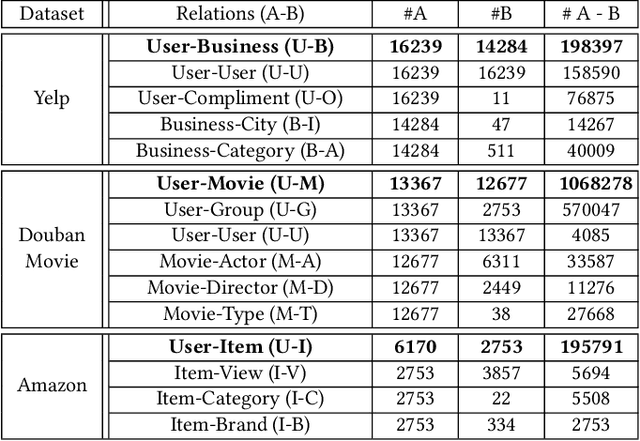
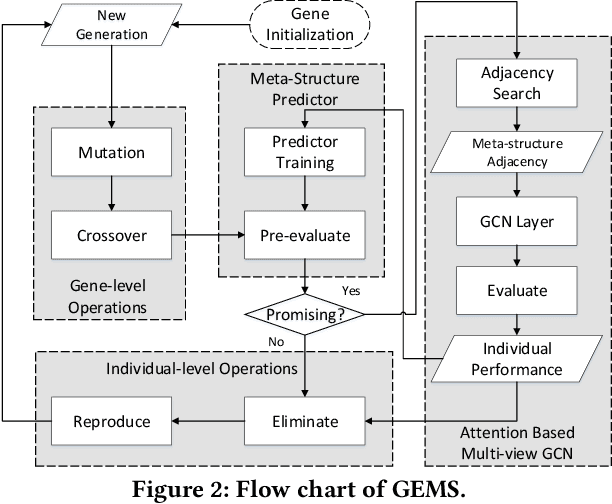

In the past decade, the heterogeneous information network (HIN) has become an important methodology for modern recommender systems. To fully leverage its power, manually designed network templates, i.e., meta-structures, are introduced to filter out semantic-aware information. The hand-crafted meta-structure rely on intense expert knowledge, which is both laborious and data-dependent. On the other hand, the number of meta-structures grows exponentially with its size and the number of node types, which prohibits brute-force search. To address these challenges, we propose Genetic Meta-Structure Search (GEMS) to automatically optimize meta-structure designs for recommendation on HINs. Specifically, GEMS adopts a parallel genetic algorithm to search meaningful meta-structures for recommendation, and designs dedicated rules and a meta-structure predictor to efficiently explore the search space. Finally, we propose an attention based multi-view graph convolutional network module to dynamically fuse information from different meta-structures. Extensive experiments on three real-world datasets suggest the effectiveness of GEMS, which consistently outperforms all baseline methods in HIN recommendation. Compared with simplified GEMS which utilizes hand-crafted meta-paths, GEMS achieves over $6\%$ performance gain on most evaluation metrics. More importantly, we conduct an in-depth analysis on the identified meta-structures, which sheds light on the HIN based recommender system design.
Exploiting Depth Information for Wildlife Monitoring
Feb 10, 2021

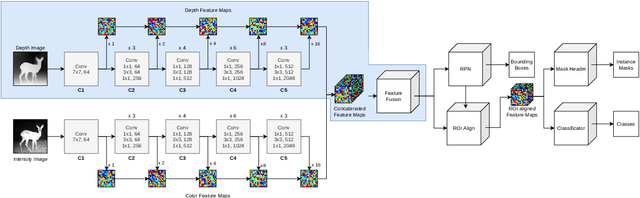

Camera traps are a proven tool in biology and specifically biodiversity research. However, camera traps including depth estimation are not widely deployed, despite providing valuable context about the scene and facilitating the automation of previously laborious manual ecological methods. In this study, we propose an automated camera trap-based approach to detect and identify animals using depth estimation. To detect and identify individual animals, we propose a novel method D-Mask R-CNN for the so-called instance segmentation which is a deep learning-based technique to detect and delineate each distinct object of interest appearing in an image or a video clip. An experimental evaluation shows the benefit of the additional depth estimation in terms of improved average precision scores of the animal detection compared to the standard approach that relies just on the image information. This novel approach was also evaluated in terms of a proof-of-concept in a zoo scenario using an RGB-D camera trap.