 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Real Time Multi-Object Detection for Helmet Safety
May 19, 2022
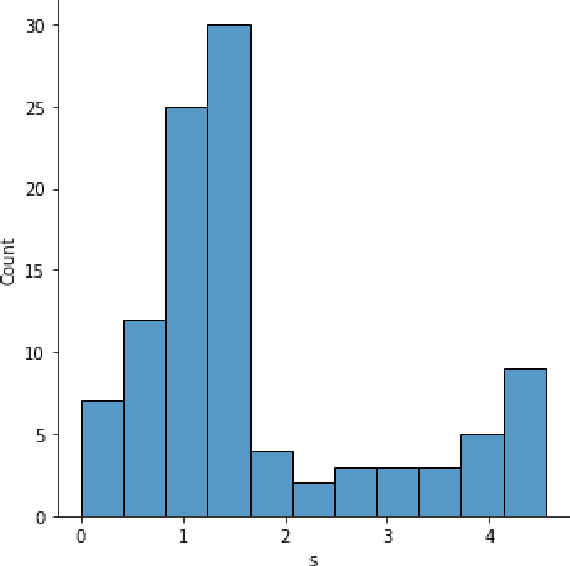

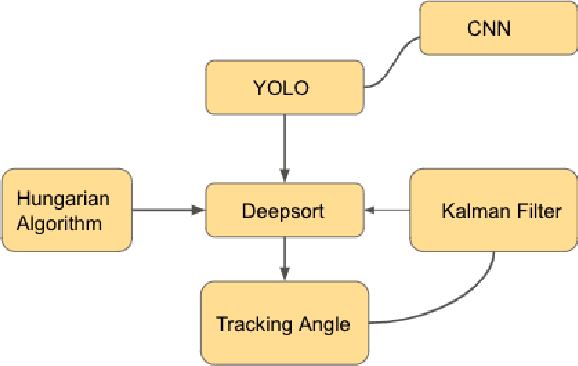
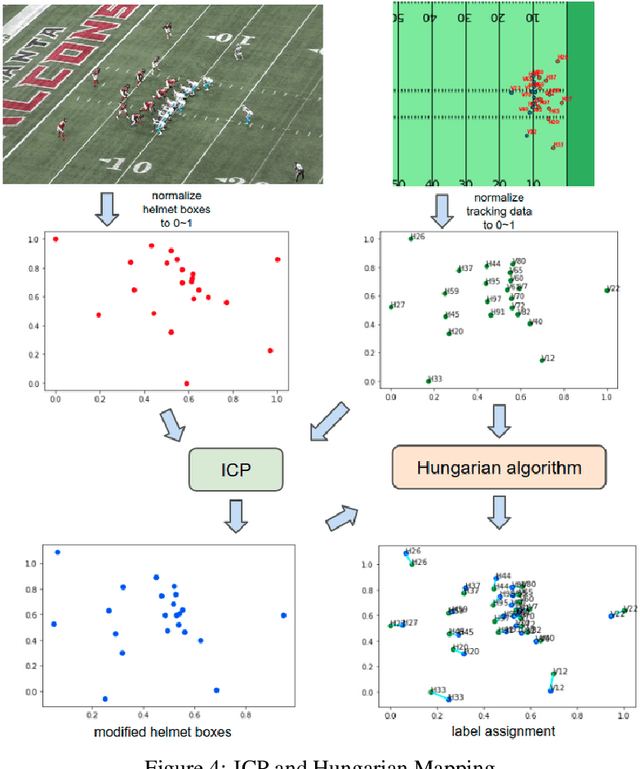
The National Football League and Amazon Web Services teamed up to develop the best sports injury surveillance and mitigation program via the Kaggle competition. Through which the NFL wants to assign specific players to each helmet, which would help accurately identify each player's "exposures" throughout a football play. We are trying to implement a computer vision based ML algorithms capable of assigning detected helmet impacts to correct players via tracking information. Our paper will explain the approach to automatically track player helmets and their collisions. This will also allow them to review previous plays and explore the trends in exposure over time.
A Perspective on Neural Capacity Estimation: Viability and Reliability
Mar 22, 2022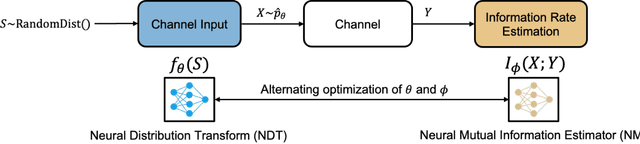
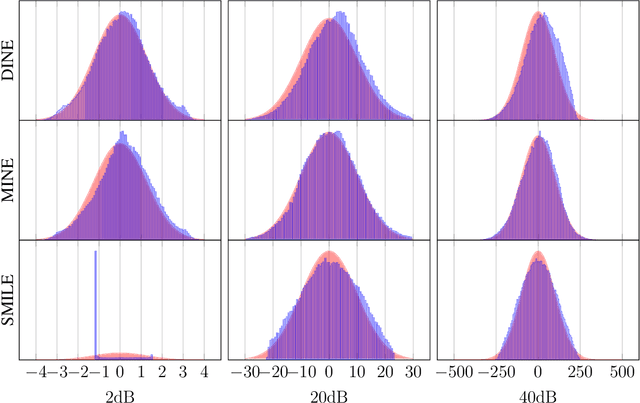
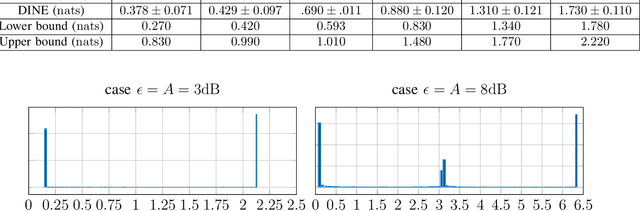
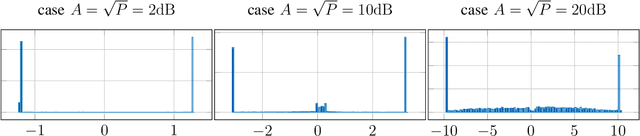
Recently, several methods have been proposed for estimating the mutual information from sample data using deep neural networks and without the knowledge of closed-form distribution of the data. This class of estimators is referred to as neural mutual information estimators (NMIE). In this paper, we investigate the performance of different NMIE proposed in the literature when applied to the capacity estimation problem. In particular, we study the performance of mutual information neural estimator (MINE), smoothed mutual information lower-bound estimator (SMILE), and directed information neural estimator (DINE). For the NMIE above, capacity estimation relies on two deep neural networks (DNN): (i) one DNN generates samples from a distribution that is learned, and (ii) a DNN to estimate the MI between the channel input and the channel output. We benchmark these NMIE in three scenarios: (i) AWGN channel capacity estimation and (ii) channels with unknown capacity and continuous inputs i.e., optical intensity and peak-power constrained AWGN channel (iii) channels with unknown capacity and a discrete number of mass points i.e., Poisson channel. Additionally, we also (iv) consider the extension to the MAC capacity problem by considering the AWGN and optical MAC models.
DualCF: Efficient Model Extraction Attack from Counterfactual Explanations
May 13, 2022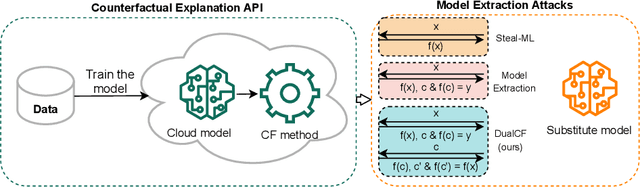
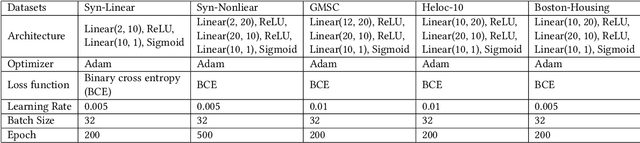
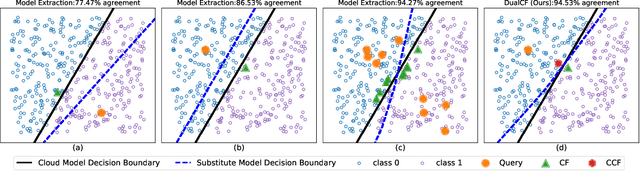
Cloud service providers have launched Machine-Learning-as-a-Service (MLaaS) platforms to allow users to access large-scale cloudbased models via APIs. In addition to prediction outputs, these APIs can also provide other information in a more human-understandable way, such as counterfactual explanations (CF). However, such extra information inevitably causes the cloud models to be more vulnerable to extraction attacks which aim to steal the internal functionality of models in the cloud. Due to the black-box nature of cloud models, however, a vast number of queries are inevitably required by existing attack strategies before the substitute model achieves high fidelity. In this paper, we propose a novel simple yet efficient querying strategy to greatly enhance the querying efficiency to steal a classification model. This is motivated by our observation that current querying strategies suffer from decision boundary shift issue induced by taking far-distant queries and close-to-boundary CFs into substitute model training. We then propose DualCF strategy to circumvent the above issues, which is achieved by taking not only CF but also counterfactual explanation of CF (CCF) as pairs of training samples for the substitute model. Extensive and comprehensive experimental evaluations are conducted on both synthetic and real-world datasets. The experimental results favorably illustrate that DualCF can produce a high-fidelity model with fewer queries efficiently and effectively.
Autoregressive Model for Multi-Pass SAR Change Detection Based on Image Stacks
Jun 05, 2022Change detection is an important synthetic aperture radar (SAR) application, usually used to detect changes on the ground scene measurements in different moments in time. Traditionally, change detection algorithm (CDA) is mainly designed for two synthetic aperture radar (SAR) images retrieved at different instants. However, more images can be used to improve the algorithms performance, witch emerges as a research topic on SAR change detection. Image stack information can be treated as a data series over time and can be modeled by autoregressive (AR) models. Thus, we present some initial findings on SAR change detection based on image stack considering AR models. Applying AR model for each pixel position in the image stack, we obtained an estimated image of the ground scene which can be used as a reference image for CDA. The experimental results reveal that ground scene estimates by the AR models is accurate and can be used for change detection applications.
* 9 pages, 10 figures
Time-Limited Waveforms with Minimum Time Broadening for the Nonlinear Schrödinger Channel
Jun 22, 2022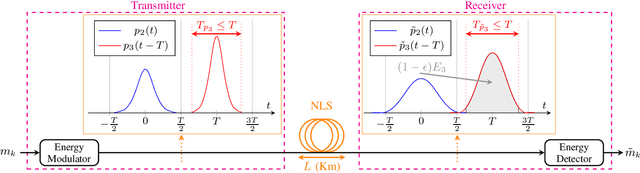
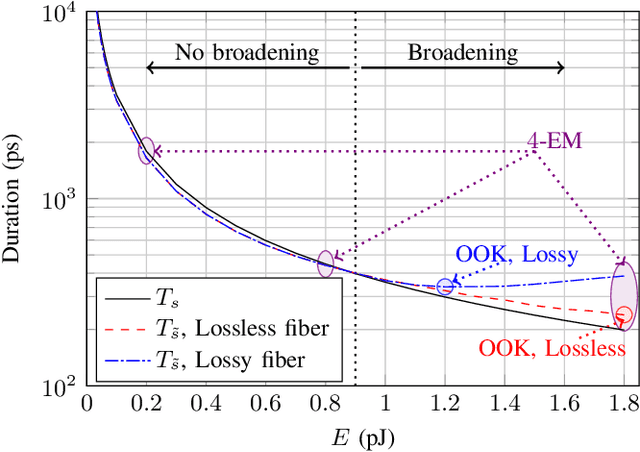
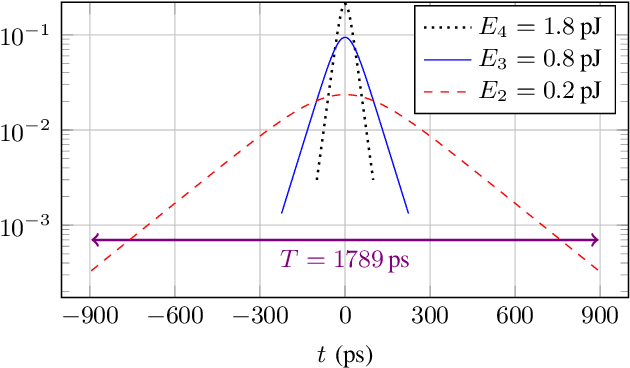
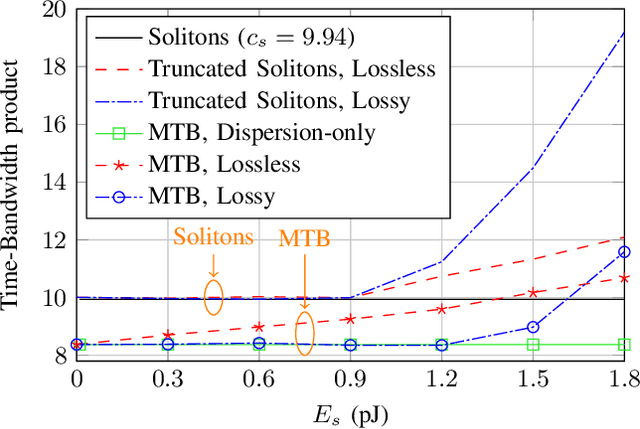
Simple fiber optic communication systems can be implemented using energy modulation of isolated time-limited pulses. Fundamental solitons are one possible solution for such pulses which offer a fundamental advantage: their shape is not affected by fiber disperison and nonlinearity. Furthermore, a simple energy detector can be used at the receiver to detect the transmitted information. However, systems based on energy modulation of solitons are not competitive in terms of data rates. This is partly due to the fact that the effective time duration of a soliton depends on its chosen amplitude. In this paper, we propose to replace fundamental solitons by new time-limited waveforms that can be detected using an energy detector, and that are immune to fiber distortions. Our proposed solution relies on the prolate spheroidal wave functions and a numerical optimization routine. Time-limited waveforms that undergo minimum time broadening along an optical fiber are obtained and shown to outperform fundamental solitons. In the case of binary transmission and a single span of fiber, we report rate increases of 33.8% and 12% over lossy and lossless fibers, respectively. Furthermore, we show that the transmission rate of the proposed system increases as the number of used energy levels increases, which is not the case for fundamental solitons due to their effective time-amplitude constraint. For example, rate increases of 164% and 70% over lossy and lossless fibers respectively are reported when using four energy levels.
What do End-to-End Speech Models Learn about Speaker, Language and Channel Information? A Layer-wise and Neuron-level Analysis
Jul 01, 2021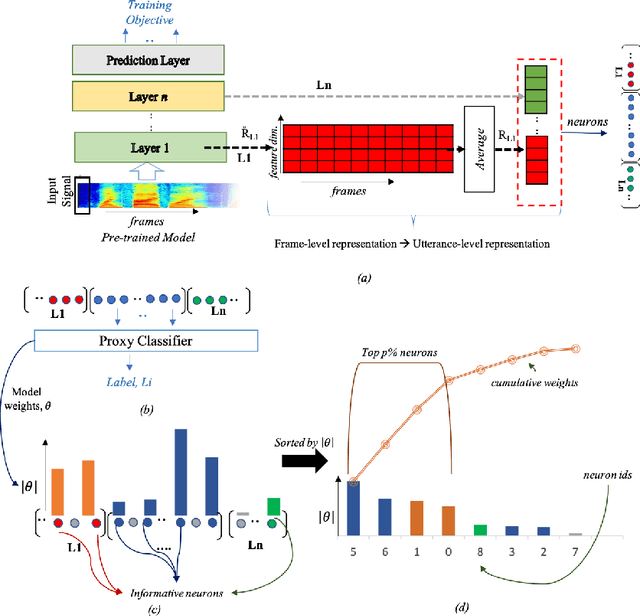
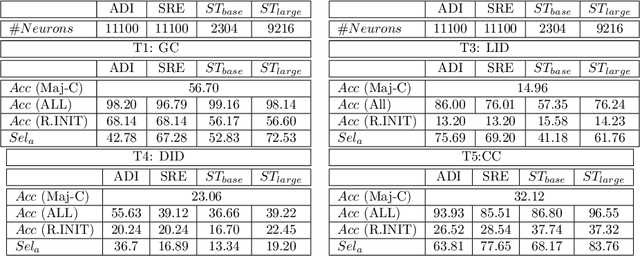
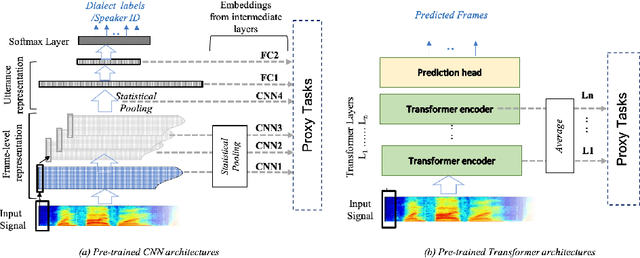
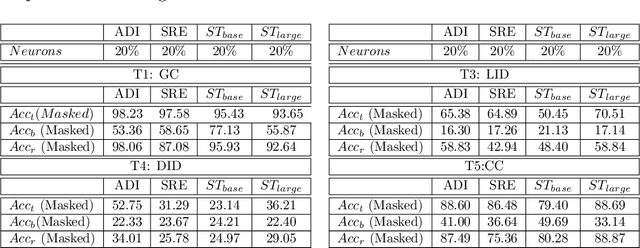
End-to-end DNN architectures have pushed the state-of-the-art in speech technologies, as well as in other spheres of AI, leading researchers to train more complex and deeper models. These improvements came at the cost of transparency. DNNs are innately opaque and difficult to interpret. We no longer understand what features are learned, where they are preserved, and how they inter-operate. Such an analysis is important for better model understanding, debugging and to ensure fairness in ethical decision making. In this work, we analyze the representations trained within deep speech models, towards the task of speaker recognition, dialect identification and reconstruction of masked signals. We carry a layer- and neuron-level analysis on the utterance-level representations captured within pretrained speech models for speaker, language and channel properties. We study: is this information captured in the learned representations? where is it preserved? how is it distributed? and can we identify a minimal subset of network that posses this information. Using diagnostic classifiers, we answered these questions. Our results reveal: (i) channel and gender information is omnipresent and is redundantly distributed (ii) complex properties such as dialectal information is encoded only in the task-oriented pretrained network and is localised in the upper layers (iii) a minimal subset of neurons can be extracted to encode the predefined property (iv) salient neurons are sometimes shared between properties and can highlights presence of biases in the network. Our cross-architectural comparison indicates that (v) the pretrained models captures speaker-invariant information and (vi) the pretrained CNNs models are competitive to the Transformers for encoding information for the studied properties. To the best of our knowledge, this is the first study to investigate neuron analysis on the speech models.
Training Language Models with Natural Language Feedback
May 02, 2022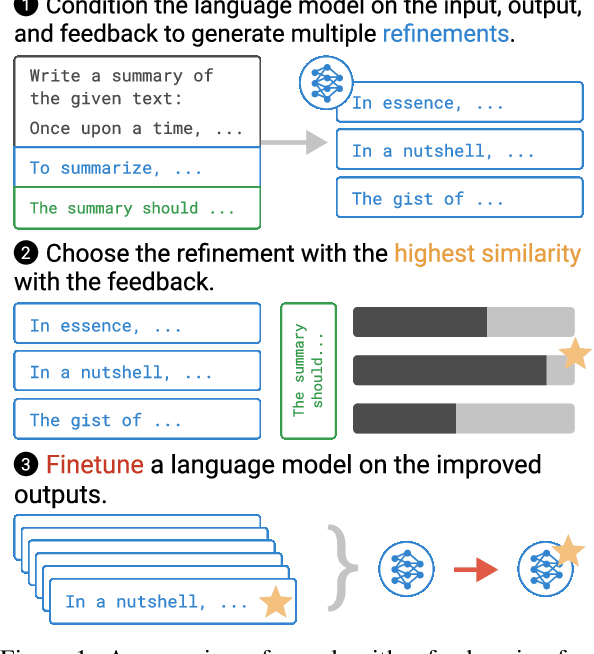
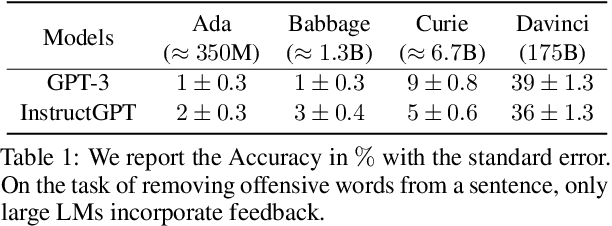
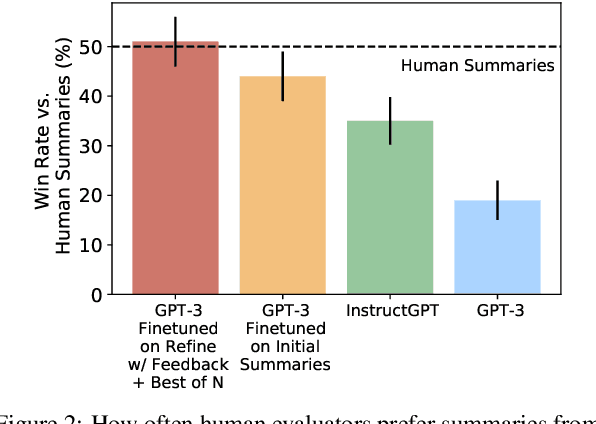
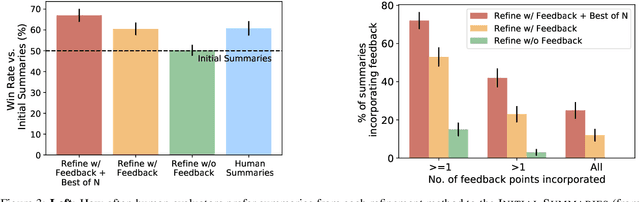
Pretrained language models often do not perform tasks in ways that are in line with our preferences, e.g., generating offensive text or factually incorrect summaries. Recent work approaches the above issue by learning from a simple form of human evaluation: comparisons between pairs of model-generated task outputs. Comparison feedback conveys limited information about human preferences per human evaluation. Here, we propose to learn from natural language feedback, which conveys more information per human evaluation. We learn from language feedback on model outputs using a three-step learning algorithm. First, we condition the language model on the initial output and feedback to generate many refinements. Second, we choose the refinement with the highest similarity to the feedback. Third, we finetune a language model to maximize the likelihood of the chosen refinement given the input. In synthetic experiments, we first evaluate whether language models accurately incorporate feedback to produce refinements, finding that only large language models (175B parameters) do so. Using only 100 samples of human-written feedback, our learning algorithm finetunes a GPT-3 model to roughly human-level summarization.
I'm Me, We're Us, and I'm Us: Tri-directional Contrastive Learning on Hypergraphs
Jun 09, 2022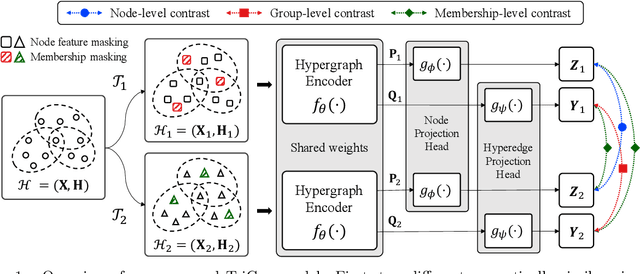
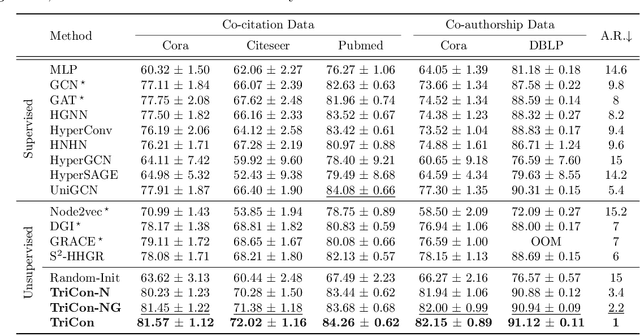
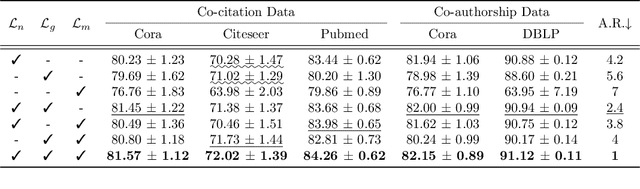
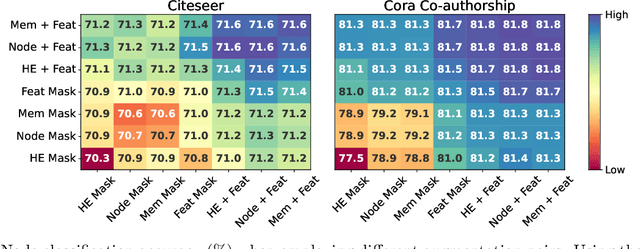
Although machine learning on hypergraphs has attracted considerable attention, most of the works have focused on (semi-)supervised learning, which may cause heavy labeling costs and poor generalization. Recently, contrastive learning has emerged as a successful unsupervised representation learning method. Despite the prosperous development of contrastive learning in other domains, contrastive learning on hypergraphs remains little explored. In this paper, we propose TriCon (Tri-directional Contrastive learning), a general framework for contrastive learning on hypergraphs. Its main idea is tri-directional contrast, and specifically, it aims to maximize in two augmented views the agreement (a) between the same node, (b) between the same group of nodes, and (c) between each group and its members. Together with simple but surprisingly effective data augmentation and negative sampling schemes, these three forms of contrast enable TriCon to capture both microscopic and mesoscopic structural information in node embeddings. Our extensive experiments using 13 baseline approaches, five datasets, and two tasks demonstrate the effectiveness of TriCon, and most noticeably, TriCon consistently outperforms not just unsupervised competitors but also (semi-)supervised competitors mostly by significant margins for node classification.
Scalable First-Order Bayesian Optimization via Structured Automatic Differentiation
Jun 16, 2022Bayesian Optimization (BO) has shown great promise for the global optimization of functions that are expensive to evaluate, but despite many successes, standard approaches can struggle in high dimensions. To improve the performance of BO, prior work suggested incorporating gradient information into a Gaussian process surrogate of the objective, giving rise to kernel matrices of size $nd \times nd$ for $n$ observations in $d$ dimensions. Na\"ively multiplying with (resp. inverting) these matrices requires $\mathcal{O}(n^2d^2)$ (resp. $\mathcal{O}(n^3d^3$)) operations, which becomes infeasible for moderate dimensions and sample sizes. Here, we observe that a wide range of kernels gives rise to structured matrices, enabling an exact $\mathcal{O}(n^2d)$ matrix-vector multiply for gradient observations and $\mathcal{O}(n^2d^2)$ for Hessian observations. Beyond canonical kernel classes, we derive a programmatic approach to leveraging this type of structure for transformations and combinations of the discussed kernel classes, which constitutes a structure-aware automatic differentiation algorithm. Our methods apply to virtually all canonical kernels and automatically extend to complex kernels, like the neural network, radial basis function network, and spectral mixture kernels without any additional derivations, enabling flexible, problem-dependent modeling while scaling first-order BO to high $d$.
iBoot: Image-bootstrapped Self-Supervised Video Representation Learning
Jun 16, 2022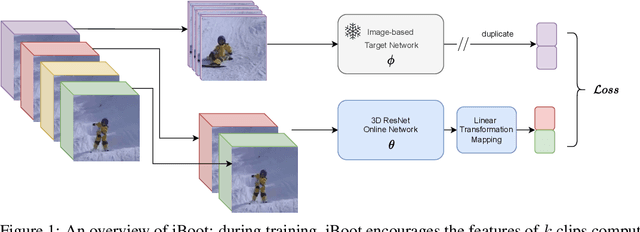



Learning visual representations through self-supervision is an extremely challenging task as the network needs to sieve relevant patterns from spurious distractors without the active guidance provided by supervision. This is achieved through heavy data augmentation, large-scale datasets and prohibitive amounts of compute. Video self-supervised learning (SSL) suffers from added challenges: video datasets are typically not as large as image datasets, compute is an order of magnitude larger, and the amount of spurious patterns the optimizer has to sieve through is multiplied several fold. Thus, directly learning self-supervised representations from video data might result in sub-optimal performance. To address this, we propose to utilize a strong image-based model, pre-trained with self- or language supervision, in a video representation learning framework, enabling the model to learn strong spatial and temporal information without relying on the video labeled data. To this end, we modify the typical video-based SSL design and objective to encourage the video encoder to \textit{subsume} the semantic content of an image-based model trained on a general domain. The proposed algorithm is shown to learn much more efficiently (i.e. in less epochs and with a smaller batch) and results in a new state-of-the-art performance on standard downstream tasks among single-modality SSL methods.