 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Comprehensive Study: How the Context Information of Different Granularity Affects Dialogue State Tracking?
May 31, 2021
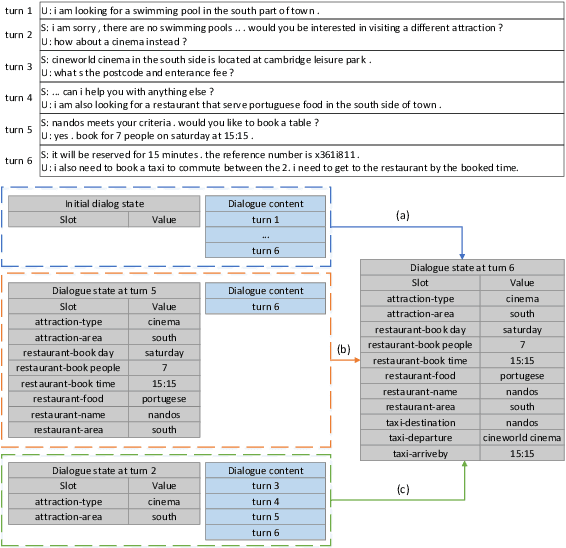
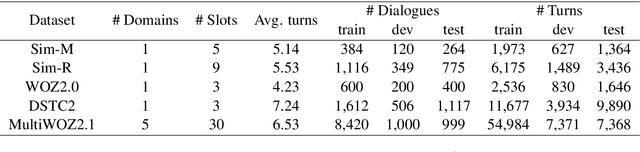

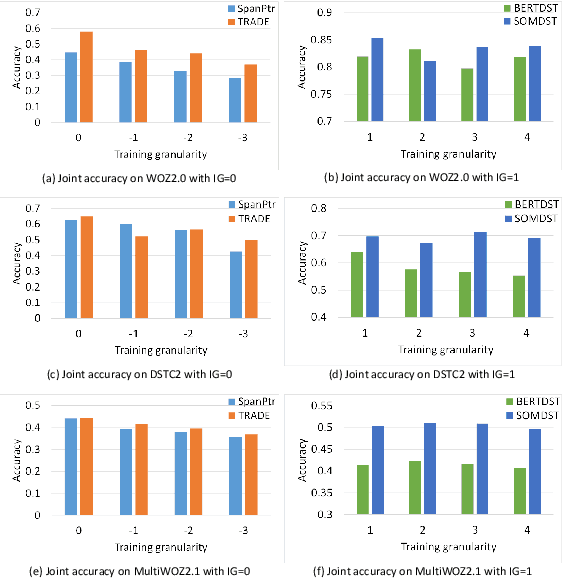
Dialogue state tracking (DST) plays a key role in task-oriented dialogue systems to monitor the user's goal. In general, there are two strategies to track a dialogue state: predicting it from scratch and updating it from previous state. The scratch-based strategy obtains each slot value by inquiring all the dialogue history, and the previous-based strategy relies on the current turn dialogue to update the previous dialogue state. However, it is hard for the scratch-based strategy to correctly track short-dependency dialogue state because of noise; meanwhile, the previous-based strategy is not very useful for long-dependency dialogue state tracking. Obviously, it plays different roles for the context information of different granularity to track different kinds of dialogue states. Thus, in this paper, we will study and discuss how the context information of different granularity affects dialogue state tracking. First, we explore how greatly different granularities affect dialogue state tracking. Then, we further discuss how to combine multiple granularities for dialogue state tracking. Finally, we apply the findings about context granularity to few-shot learning scenario. Besides, we have publicly released all codes.
R4D: Utilizing Reference Objects for Long-Range Distance Estimation
Jun 10, 2022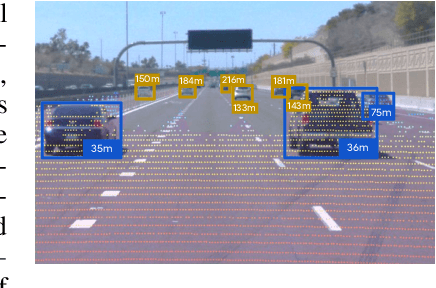

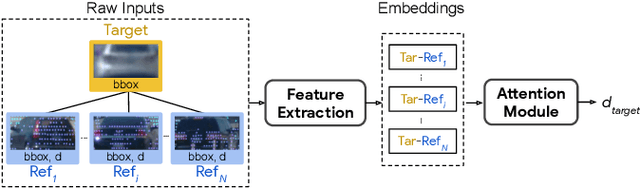
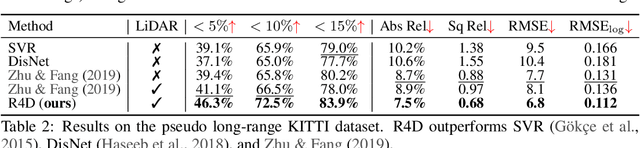
Estimating the distance of objects is a safety-critical task for autonomous driving. Focusing on short-range objects, existing methods and datasets neglect the equally important long-range objects. In this paper, we introduce a challenging and under-explored task, which we refer to as Long-Range Distance Estimation, as well as two datasets to validate new methods developed for this task. We then proposeR4D, the first framework to accurately estimate the distance of long-range objects by using references with known distances in the scene. Drawing inspiration from human perception, R4D builds a graph by connecting a target object to all references. An edge in the graph encodes the relative distance information between a pair of target and reference objects. An attention module is then used to weigh the importance of reference objects and combine them into one target object distance prediction. Experiments on the two proposed datasets demonstrate the effectiveness and robustness of R4D by showing significant improvements compared to existing baselines. We are looking to make the proposed dataset, Waymo OpenDataset - Long-Range Labels, available publicly at waymo.com/open/download.
Hashing Learning with Hyper-Class Representation
Jun 06, 2022

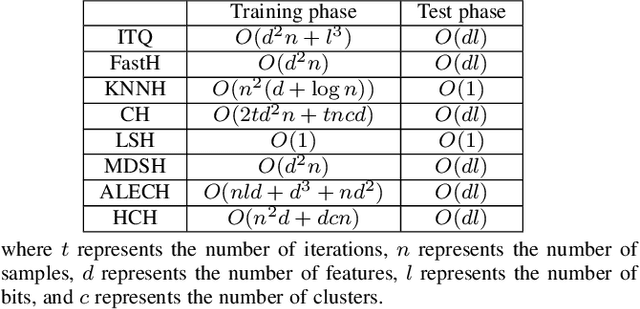
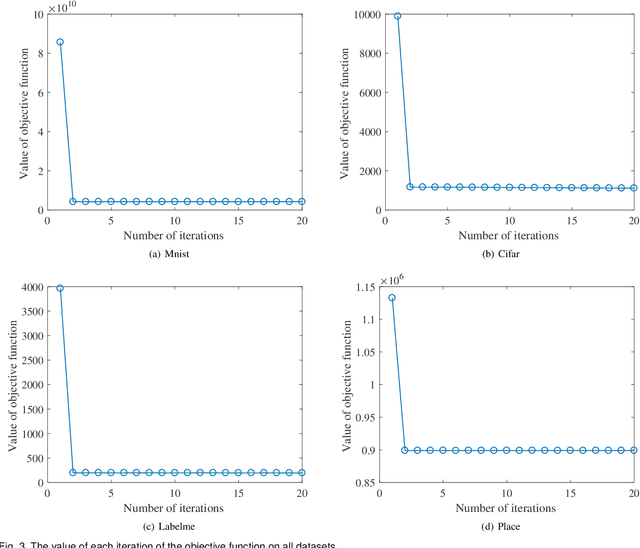
Existing unsupervised hash learning is a kind of attribute-centered calculation. It may not accurately preserve the similarity between data. This leads to low down the performance of hash function learning. In this paper, a hash algorithm is proposed with a hyper-class representation. It is a two-steps approach. The first step finds potential decision features and establish hyper-class. The second step constructs hash learning based on the hyper-class information in the first step, so that the hash codes of the data within the hyper-class are as similar as possible, as well as the hash codes of the data between the hyper-classes are as different as possible. To evaluate the efficiency, a series of experiments are conducted on four public datasets. The experimental results show that the proposed hash algorithm is more efficient than the compared algorithms, in terms of mean average precision (MAP), average precision (AP) and Hamming radius 2 (HAM2)
Learning a Degradation-Adaptive Network for Light Field Image Super-Resolution
Jun 13, 2022



Recent years have witnessed the great advances of deep neural networks (DNNs) in light field (LF) image super-resolution (SR). However, existing DNN-based LF image SR methods are developed on a single fixed degradation (e.g., bicubic downsampling), and thus cannot be applied to super-resolve real LF images with diverse degradations. In this paper, we propose the first method to handle LF image SR with multiple degradations. In our method, a practical LF degradation model that considers blur and noise is developed to approximate the degradation process of real LF images. Then, a degradation-adaptive network (LF-DAnet) is designed to incorporate the degradation prior into the SR process. By training on LF images with multiple synthetic degradations, our method can learn to adapt to different degradations while incorporating the spatial and angular information. Extensive experiments on both synthetically degraded and real-world LFs demonstrate the effectiveness of our method. Compared with existing state-of-the-art single and LF image SR methods, our method achieves superior SR performance under a wide range of degradations, and generalizes better to real LF images. Codes and models are available at https://github.com/YingqianWang/LF-DAnet.
Speech Emotion Recognition with Global-Aware Fusion on Multi-scale Feature Representation
Apr 12, 2022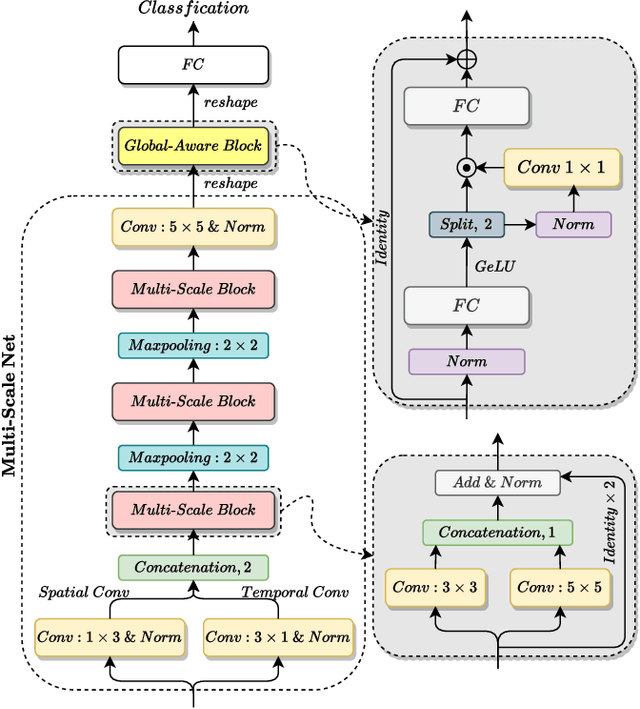
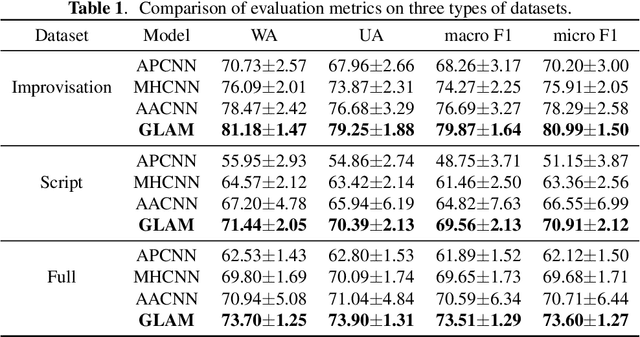
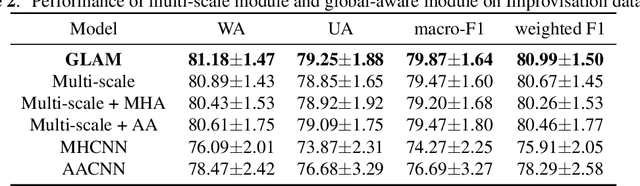
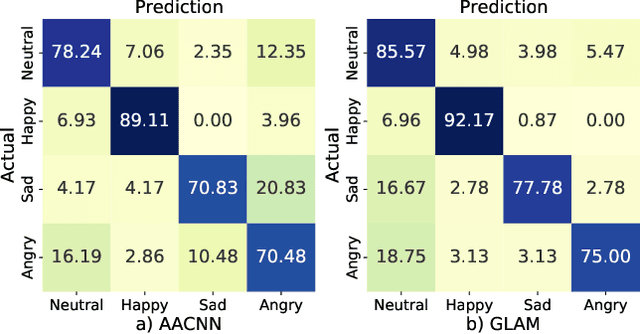
Speech Emotion Recognition (SER) is a fundamental task to predict the emotion label from speech data. Recent works mostly focus on using convolutional neural networks~(CNNs) to learn local attention map on fixed-scale feature representation by viewing time-varied spectral features as images. However, rich emotional feature at different scales and important global information are not able to be well captured due to the limits of existing CNNs for SER. In this paper, we propose a novel GLobal-Aware Multi-scale (GLAM) neural network (The code is available at https://github.com/lixiangucas01/GLAM) to learn multi-scale feature representation with global-aware fusion module to attend emotional information. Specifically, GLAM iteratively utilizes multiple convolutional kernels with different scales to learn multiple feature representation. Then, instead of using attention-based methods, a simple but effective global-aware fusion module is applied to grab most important emotional information globally. Experiments on the benchmark corpus IEMOCAP over four emotions demonstrates the superiority of our proposed model with 2.5% to 4.5% improvements on four common metrics compared to previous state-of-the-art approaches.
Time-Limited Waveforms with Minimum Time Broadening for the Nonlinear Schrödinger Channel
Jun 22, 2022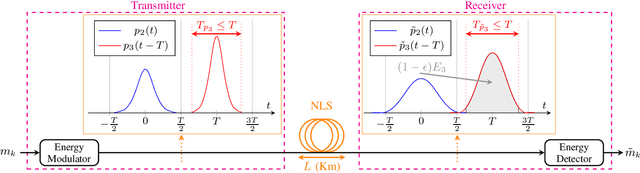
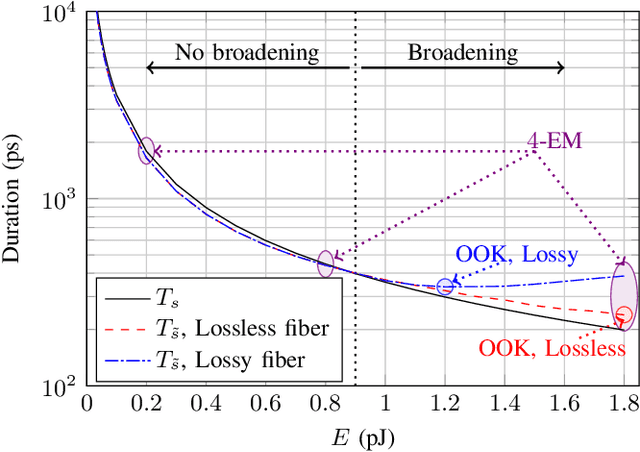
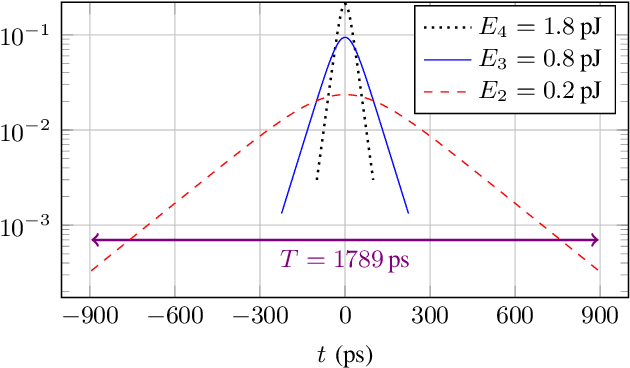
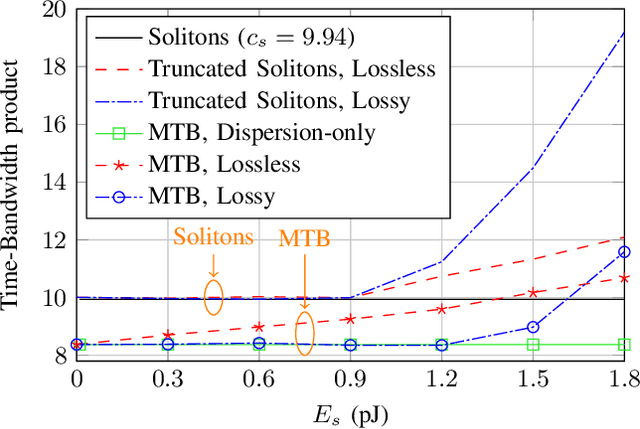
Simple fiber optic communication systems can be implemented using energy modulation of isolated time-limited pulses. Fundamental solitons are one possible solution for such pulses which offer a fundamental advantage: their shape is not affected by fiber disperison and nonlinearity. Furthermore, a simple energy detector can be used at the receiver to detect the transmitted information. However, systems based on energy modulation of solitons are not competitive in terms of data rates. This is partly due to the fact that the effective time duration of a soliton depends on its chosen amplitude. In this paper, we propose to replace fundamental solitons by new time-limited waveforms that can be detected using an energy detector, and that are immune to fiber distortions. Our proposed solution relies on the prolate spheroidal wave functions and a numerical optimization routine. Time-limited waveforms that undergo minimum time broadening along an optical fiber are obtained and shown to outperform fundamental solitons. In the case of binary transmission and a single span of fiber, we report rate increases of 33.8% and 12% over lossy and lossless fibers, respectively. Furthermore, we show that the transmission rate of the proposed system increases as the number of used energy levels increases, which is not the case for fundamental solitons due to their effective time-amplitude constraint. For example, rate increases of 164% and 70% over lossy and lossless fibers respectively are reported when using four energy levels.
Diversity Enhanced Table-to-Text Generation via Type Control
May 22, 2022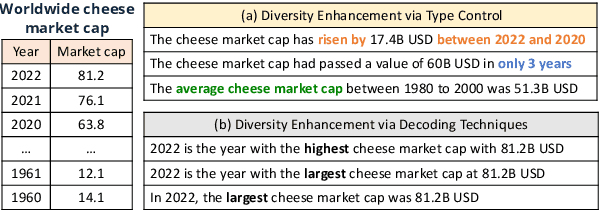

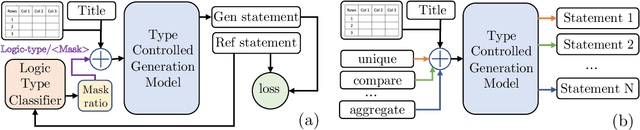

Generating natural language statements to convey information from tabular data (i.e., Table-to-text) is a process with one input and a variety of valid outputs. This characteristic underscores the abilities to control the generation and produce a diverse set of outputs as two key assets. Thus, we propose a diversity enhancing scheme that builds upon an inherent property of the statements, namely, their logic-types, by using a type-controlled Table-to-text generation model. Employing automatic and manual tests, we prove its twofold advantage: users can effectively tune the generated statement type, and, by sampling different types, can obtain a diverse set of statements for a given table.
Genetic Meta-Structure Search for Recommendation on Heterogeneous Information Network
Feb 21, 2021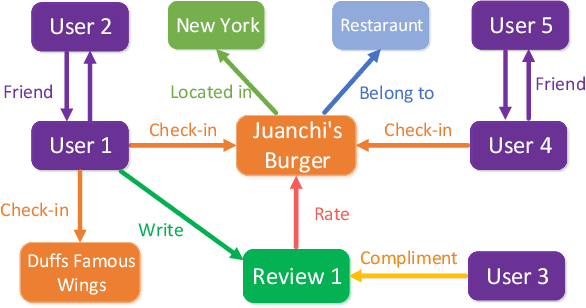
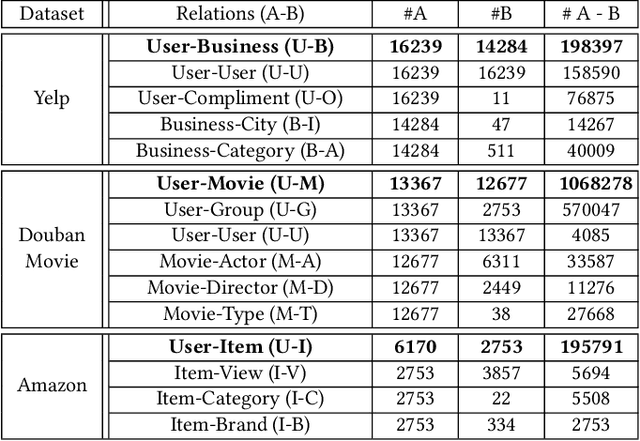
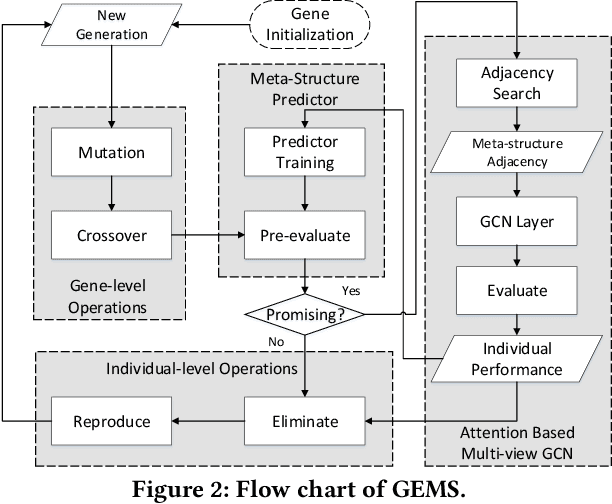

In the past decade, the heterogeneous information network (HIN) has become an important methodology for modern recommender systems. To fully leverage its power, manually designed network templates, i.e., meta-structures, are introduced to filter out semantic-aware information. The hand-crafted meta-structure rely on intense expert knowledge, which is both laborious and data-dependent. On the other hand, the number of meta-structures grows exponentially with its size and the number of node types, which prohibits brute-force search. To address these challenges, we propose Genetic Meta-Structure Search (GEMS) to automatically optimize meta-structure designs for recommendation on HINs. Specifically, GEMS adopts a parallel genetic algorithm to search meaningful meta-structures for recommendation, and designs dedicated rules and a meta-structure predictor to efficiently explore the search space. Finally, we propose an attention based multi-view graph convolutional network module to dynamically fuse information from different meta-structures. Extensive experiments on three real-world datasets suggest the effectiveness of GEMS, which consistently outperforms all baseline methods in HIN recommendation. Compared with simplified GEMS which utilizes hand-crafted meta-paths, GEMS achieves over $6\%$ performance gain on most evaluation metrics. More importantly, we conduct an in-depth analysis on the identified meta-structures, which sheds light on the HIN based recommender system design.
Visual Clues: Bridging Vision and Language Foundations for Image Paragraph Captioning
Jun 03, 2022

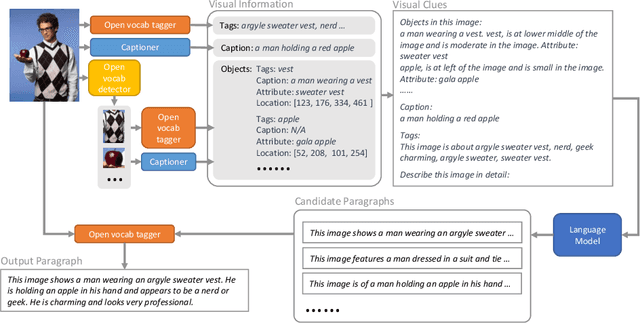
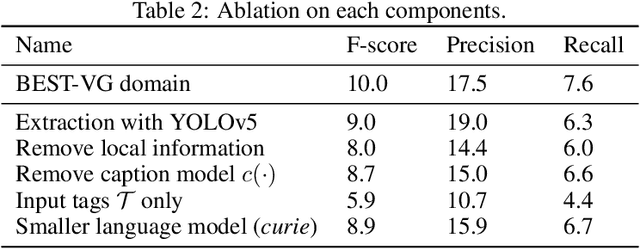
People say, "A picture is worth a thousand words". Then how can we get the rich information out of the image? We argue that by using visual clues to bridge large pretrained vision foundation models and language models, we can do so without any extra cross-modal training. Thanks to the strong zero-shot capability of foundation models, we start by constructing a rich semantic representation of the image (e.g., image tags, object attributes / locations, captions) as a structured textual prompt, called visual clues, using a vision foundation model. Based on visual clues, we use large language model to produce a series of comprehensive descriptions for the visual content, which is then verified by the vision model again to select the candidate that aligns best with the image. We evaluate the quality of generated descriptions by quantitative and qualitative measurement. The results demonstrate the effectiveness of such a structured semantic representation.
Scalable First-Order Bayesian Optimization via Structured Automatic Differentiation
Jun 16, 2022Bayesian Optimization (BO) has shown great promise for the global optimization of functions that are expensive to evaluate, but despite many successes, standard approaches can struggle in high dimensions. To improve the performance of BO, prior work suggested incorporating gradient information into a Gaussian process surrogate of the objective, giving rise to kernel matrices of size $nd \times nd$ for $n$ observations in $d$ dimensions. Na\"ively multiplying with (resp. inverting) these matrices requires $\mathcal{O}(n^2d^2)$ (resp. $\mathcal{O}(n^3d^3$)) operations, which becomes infeasible for moderate dimensions and sample sizes. Here, we observe that a wide range of kernels gives rise to structured matrices, enabling an exact $\mathcal{O}(n^2d)$ matrix-vector multiply for gradient observations and $\mathcal{O}(n^2d^2)$ for Hessian observations. Beyond canonical kernel classes, we derive a programmatic approach to leveraging this type of structure for transformations and combinations of the discussed kernel classes, which constitutes a structure-aware automatic differentiation algorithm. Our methods apply to virtually all canonical kernels and automatically extend to complex kernels, like the neural network, radial basis function network, and spectral mixture kernels without any additional derivations, enabling flexible, problem-dependent modeling while scaling first-order BO to high $d$.