 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Stochastic Variance-Reduced Newton: Accelerating Finite-Sum Minimization with Large Batches
Jun 06, 2022
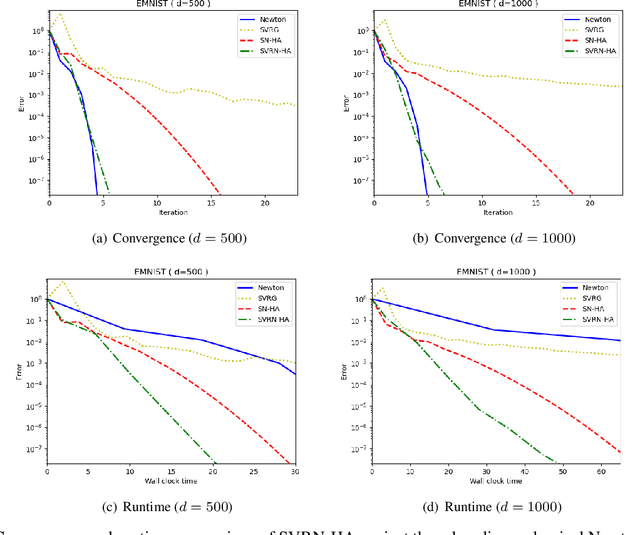
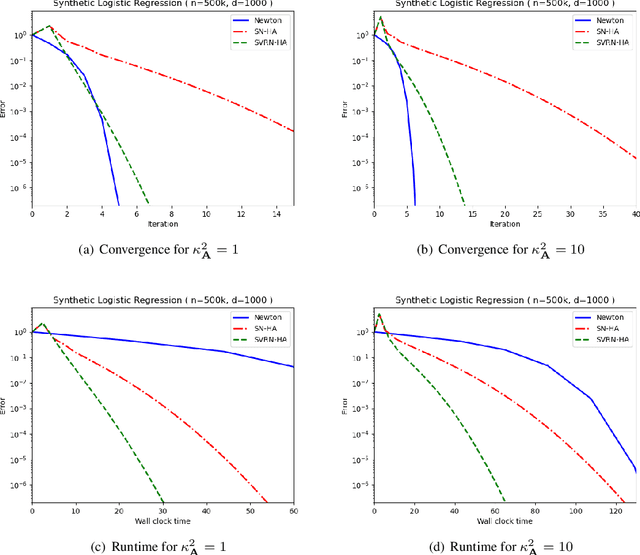
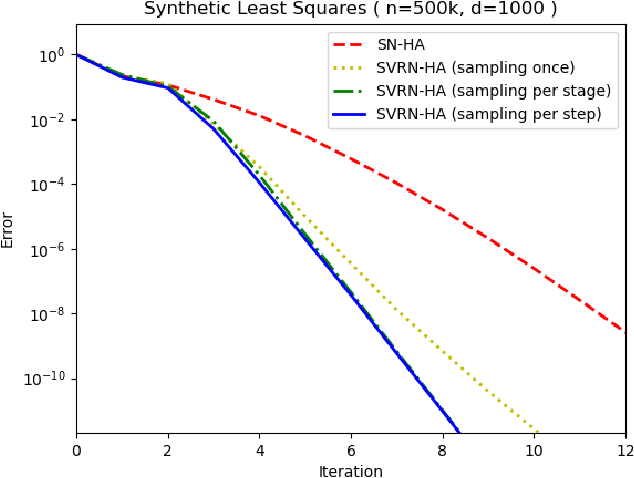
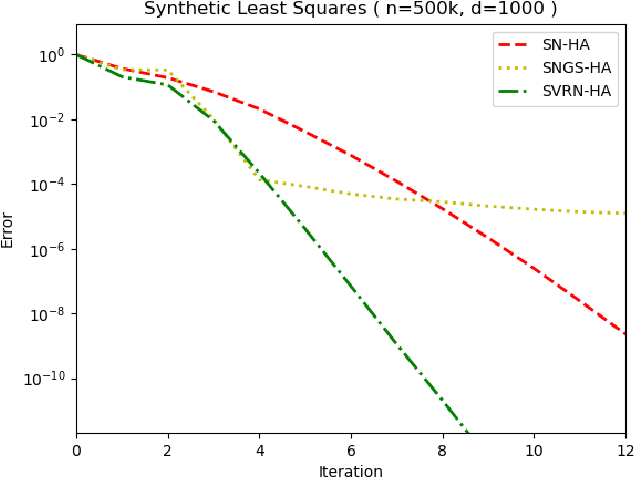
Stochastic variance reduction has proven effective at accelerating first-order algorithms for solving convex finite-sum optimization tasks such as empirical risk minimization. Incorporating additional second-order information has proven helpful in further improving the performance of these first-order methods. However, comparatively little is known about the benefits of using variance reduction to accelerate popular stochastic second-order methods such as Subsampled Newton. To address this, we propose Stochastic Variance-Reduced Newton (SVRN), a finite-sum minimization algorithm which enjoys all the benefits of second-order methods: simple unit step size, easily parallelizable large-batch operations, and fast local convergence, while at the same time taking advantage of variance reduction to achieve improved convergence rates (per data pass) for smooth and strongly convex problems. We show that SVRN can accelerate many stochastic second-order methods (such as Subsampled Newton) as well as iterative least squares solvers (such as Iterative Hessian Sketch), and it compares favorably to popular first-order methods with variance reduction.
Open ERP System Data For Occupational Fraud Detection
Jun 10, 2022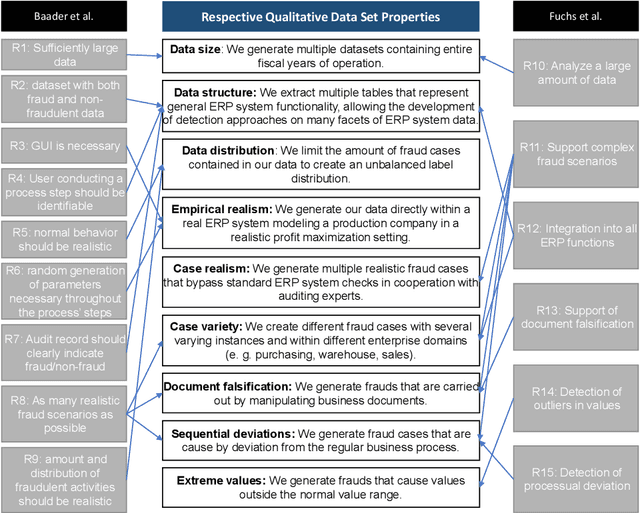
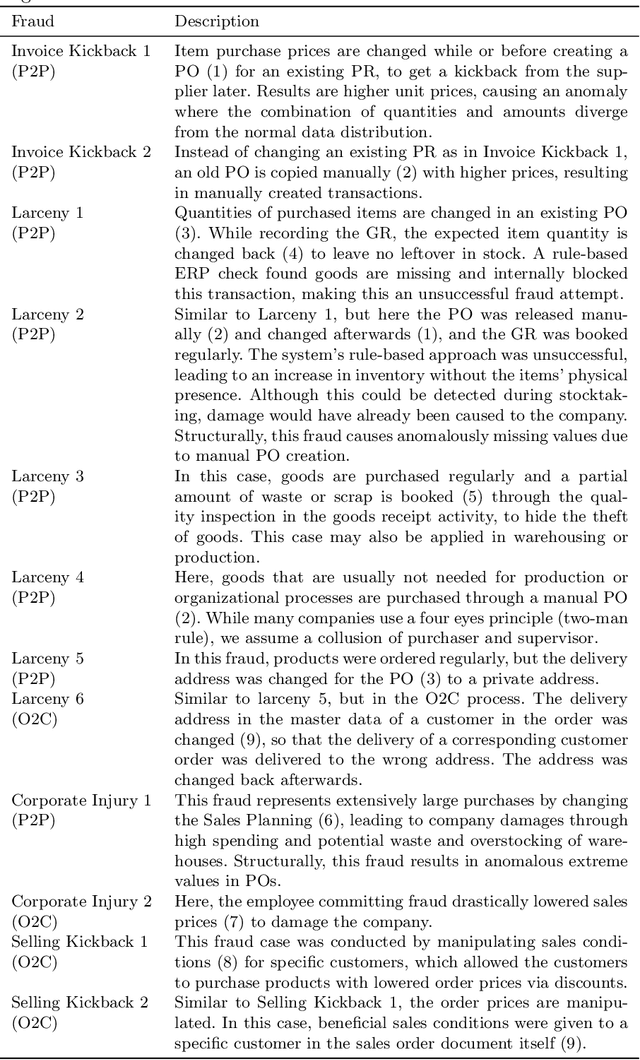

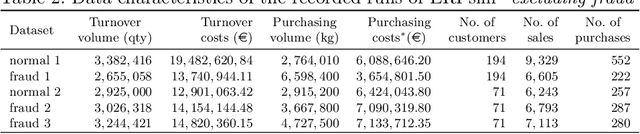
Recent estimates report that companies lose 5% of their revenue to occupational fraud. Since most medium-sized and large companies employ Enterprise Resource Planning (ERP) systems to track vast amounts of information regarding their business process, researchers have in the past shown interest in automatically detecting fraud through ERP system data. Current research in this area, however, is hindered by the fact that ERP system data is not publicly available for the development and comparison of fraud detection methods. We therefore endeavour to generate public ERP system data that includes both normal business operation and fraud. We propose a strategy for generating ERP system data through a serious game, model a variety of fraud scenarios in cooperation with auditing experts, and generate data from a simulated make-to-stock production company with multiple research participants. We aggregate the generated data into ready to used datasets for fraud detection in ERP systems, and supply both the raw and aggregated data to the general public to allow for open development and comparison of fraud detection approaches on ERP system data.
Role of Attentive History Selection in Conversational Information Seeking
Feb 07, 2021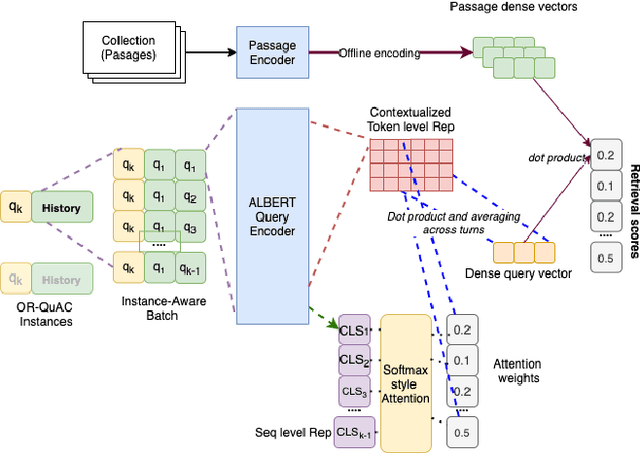
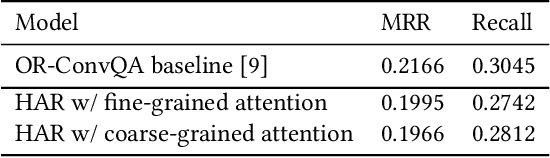
The rise of intelligent assistant systems like Siri and Alexa have led to the emergence of Conversational Search, a research track of Information Retrieval (IR) that involves interactive and iterative information-seeking user-system dialog. Recently released OR-QuAC and TCAsT19 datasets narrow their research focus on the retrieval aspect of conversational search i.e. fetching the relevant documents (passages) from a large collection using the conversational search history. Currently proposed models for these datasets incorporate history in retrieval by appending the last N turns to the current question before encoding. We propose to use another history selection approach that dynamically selects and weighs history turns using the attention mechanism for question embedding. The novelty of our approach lies in experimenting with soft attention-based history selection approach in an open-retrieval setting.
Word Order Does Matter (And Shuffled Language Models Know It)
Mar 21, 2022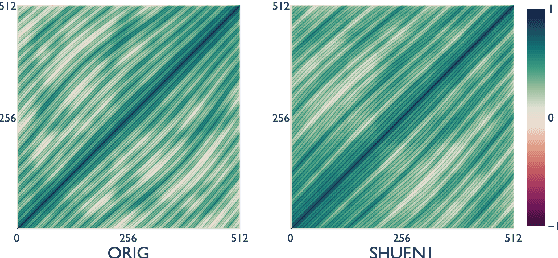
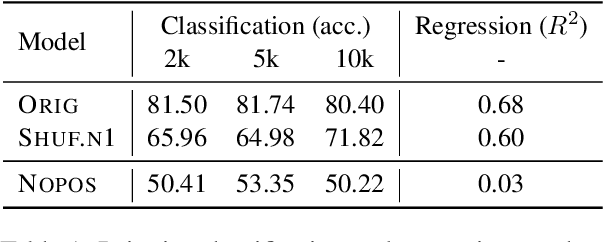
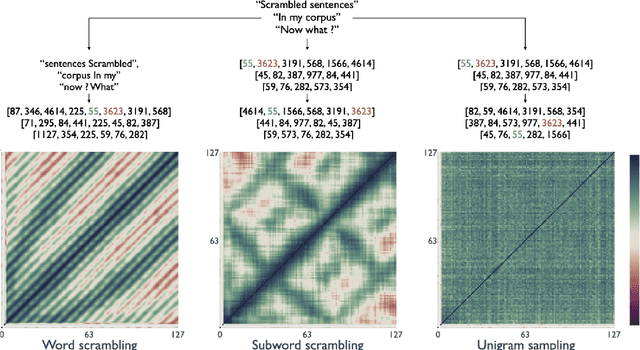
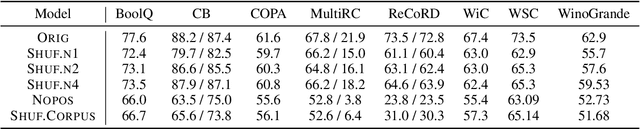
Recent studies have shown that language models pretrained and/or fine-tuned on randomly permuted sentences exhibit competitive performance on GLUE, putting into question the importance of word order information. Somewhat counter-intuitively, some of these studies also report that position embeddings appear to be crucial for models' good performance with shuffled text. We probe these language models for word order information and investigate what position embeddings learned from shuffled text encode, showing that these models retain information pertaining to the original, naturalistic word order. We show this is in part due to a subtlety in how shuffling is implemented in previous work -- before rather than after subword segmentation. Surprisingly, we find even Language models trained on text shuffled after subword segmentation retain some semblance of information about word order because of the statistical dependencies between sentence length and unigram probabilities. Finally, we show that beyond GLUE, a variety of language understanding tasks do require word order information, often to an extent that cannot be learned through fine-tuning.
Pay "Attention" to Adverse Weather: Weather-aware Attention-based Object Detection
Apr 22, 2022
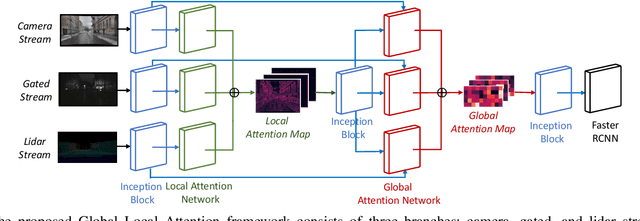
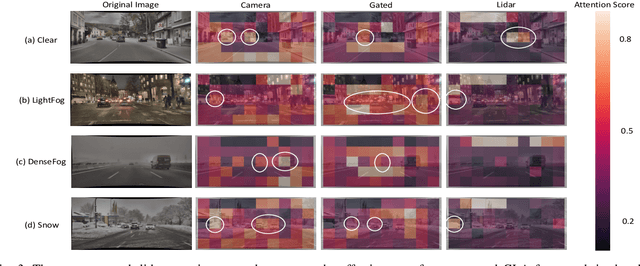
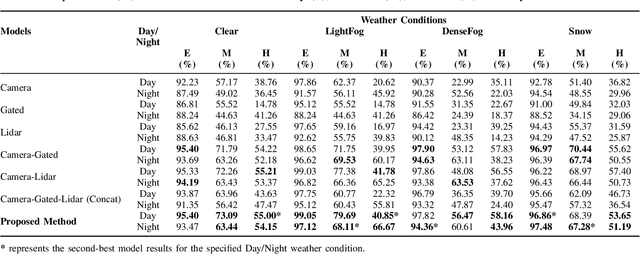
Despite the recent advances of deep neural networks, object detection for adverse weather remains challenging due to the poor perception of some sensors in adverse weather. Instead of relying on one single sensor, multimodal fusion has been one promising approach to provide redundant detection information based on multiple sensors. However, most existing multimodal fusion approaches are ineffective in adjusting the focus of different sensors under varying detection environments in dynamic adverse weather conditions. Moreover, it is critical to simultaneously observe local and global information under complex weather conditions, which has been neglected in most early or late-stage multimodal fusion works. In view of these, this paper proposes a Global-Local Attention (GLA) framework to adaptively fuse the multi-modality sensing streams, i.e., camera, gated camera, and lidar data, at two fusion stages. Specifically, GLA integrates an early-stage fusion via a local attention network and a late-stage fusion via a global attention network to deal with both local and global information, which automatically allocates higher weights to the modality with better detection features at the late-stage fusion to cope with the specific weather condition adaptively. Experimental results demonstrate the superior performance of the proposed GLA compared with state-of-the-art fusion approaches under various adverse weather conditions, such as light fog, dense fog, and snow.
A Privacy-Preserving Approach to Extraction of Personal Information through Automatic Annotation and Federated Learning
May 19, 2021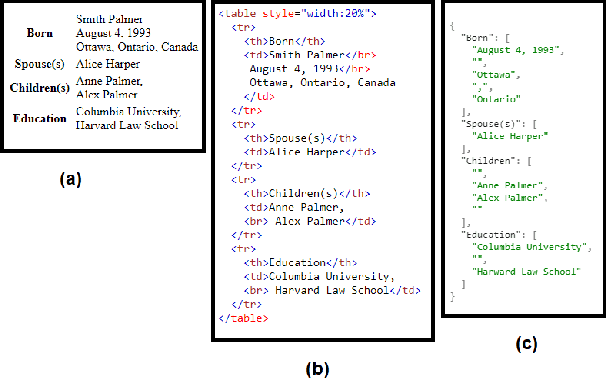



We curated WikiPII, an automatically labeled dataset composed of Wikipedia biography pages, annotated for personal information extraction. Although automatic annotation can lead to a high degree of label noise, it is an inexpensive process and can generate large volumes of annotated documents. We trained a BERT-based NER model with WikiPII and showed that with an adequately large training dataset, the model can significantly decrease the cost of manual information extraction, despite the high level of label noise. In a similar approach, organizations can leverage text mining techniques to create customized annotated datasets from their historical data without sharing the raw data for human annotation. Also, we explore collaborative training of NER models through federated learning when the annotation is noisy. Our results suggest that depending on the level of trust to the ML operator and the volume of the available data, distributed training can be an effective way of training a personal information identifier in a privacy-preserved manner. Research material is available at https://github.com/ratmcu/wikipiifed.
DcnnGrasp: Towards Accurate Grasp Pattern Recognition with Adaptive Regularizer Learning
May 11, 2022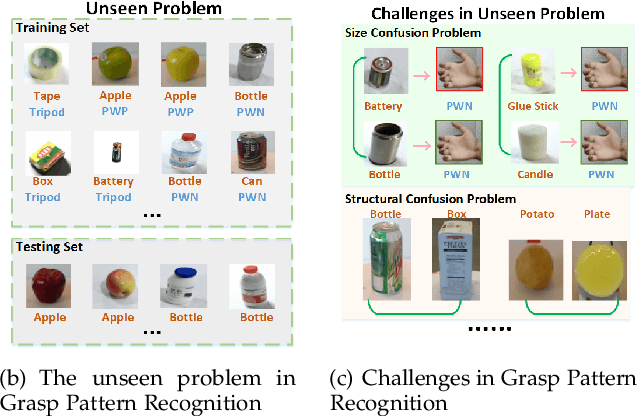

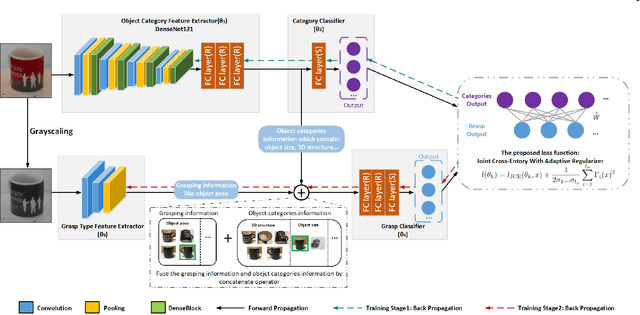

The task of grasp pattern recognition aims to derive the applicable grasp types of an object according to the visual information. Current state-of-the-art methods ignore category information of objects which is crucial for grasp pattern recognition. This paper presents a novel dual-branch convolutional neural network (DcnnGrasp) to achieve joint learning of object category classification and grasp pattern recognition. DcnnGrasp takes object category classification as an auxiliary task to improve the effectiveness of grasp pattern recognition. Meanwhile, a new loss function called joint cross-entropy with an adaptive regularizer is derived through maximizing a posterior, which significantly improves the model performance. Besides, based on the new loss function, a training strategy is proposed to maximize the collaborative learning of the two tasks. The experiment was performed on five household objects datasets including the RGB-D Object dataset, Hit-GPRec dataset, Amsterdam library of object images (ALOI), Columbia University Image Library (COIL-100), and MeganePro dataset 1. The experimental results demonstrated that the proposed method can achieve competitive performance on grasp pattern recognition with several state-of-the-art methods. Specifically, our method even outperformed the second-best one by nearly 15% in terms of global accuracy for the case of testing a novel object on the RGB-D Object dataset.
Memory-Based Model Editing at Scale
Jun 13, 2022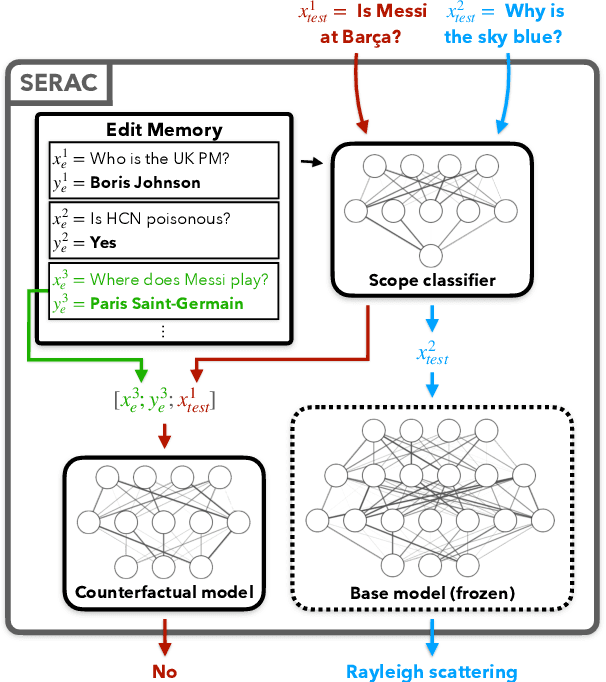



Even the largest neural networks make errors, and once-correct predictions can become invalid as the world changes. Model editors make local updates to the behavior of base (pre-trained) models to inject updated knowledge or correct undesirable behaviors. Existing model editors have shown promise, but also suffer from insufficient expressiveness: they struggle to accurately model an edit's intended scope (examples affected by the edit), leading to inaccurate predictions for test inputs loosely related to the edit, and they often fail altogether after many edits. As a higher-capacity alternative, we propose Semi-Parametric Editing with a Retrieval-Augmented Counterfactual Model (SERAC), which stores edits in an explicit memory and learns to reason over them to modulate the base model's predictions as needed. To enable more rigorous evaluation of model editors, we introduce three challenging language model editing problems based on question answering, fact-checking, and dialogue generation. We find that only SERAC achieves high performance on all three problems, consistently outperforming existing approaches to model editing by a significant margin. Code, data, and additional project information will be made available at https://sites.google.com/view/serac-editing.
Feature Learning and Ensemble Pre-Tasks Based Self-Supervised Speech Denoising and Dereverberation
Jun 10, 2022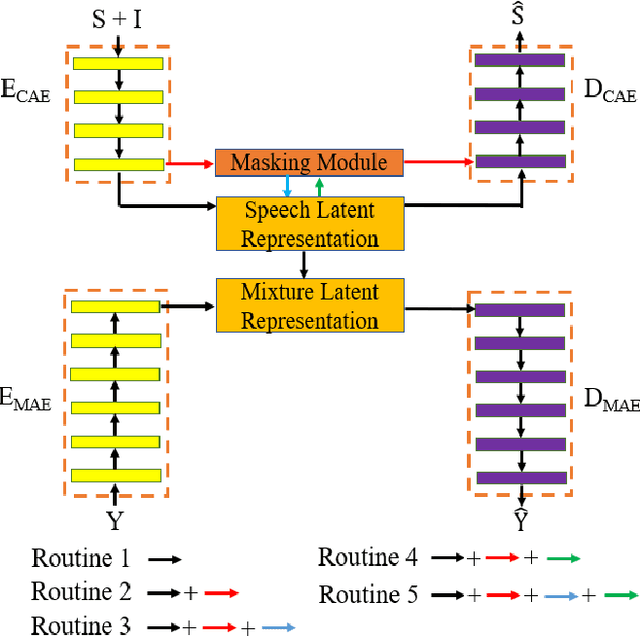
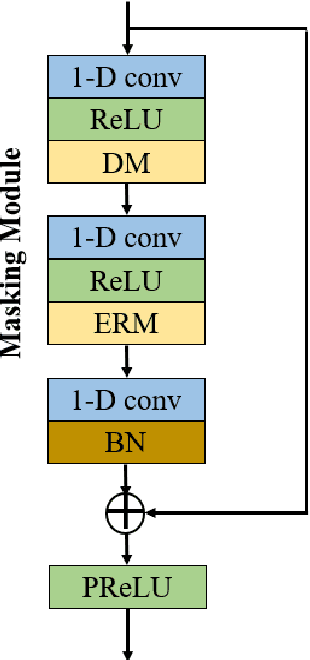
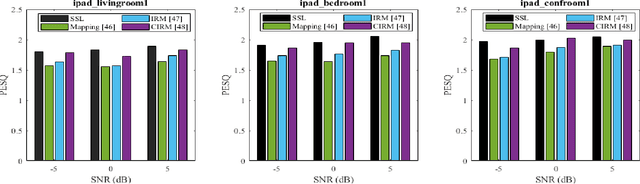
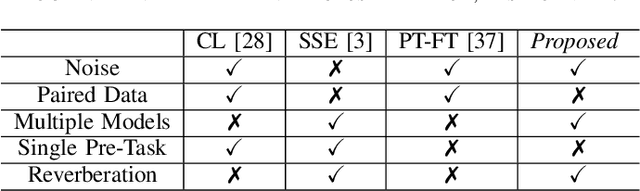
Self-supervised learning (SSL) achieves great success in monaural speech enhancement, while the accuracy of the target speech estimation, particularly for unseen speakers, remains inadequate with existing pre-tasks. As speech signal contains multi-faceted information including speaker identity, paralinguistics, and spoken content, the latent representation for speech enhancement becomes a tough task. In this paper, we study the effectiveness of each feature which is commonly used in speech enhancement and exploit the feature combination in the SSL case. Besides, we propose an ensemble training strategy. The latent representation of the clean speech signal is learned, meanwhile, the dereverberated mask and the estimated ratio mask are exploited to denoise and dereverberate the mixture. The latent representation learning and the masks estimation are considered as two pre-tasks in the training stage. In addition, to study the effectiveness between the pre-tasks, we compare different training routines to train the model and further refine the performance. The NOISEX and DAPS corpora are used to evaluate the efficacy of the proposed method, which also outperforms the state-of-the-art methods.
MVMO: A Multi-Object Dataset for Wide Baseline Multi-View Semantic Segmentation
May 30, 2022
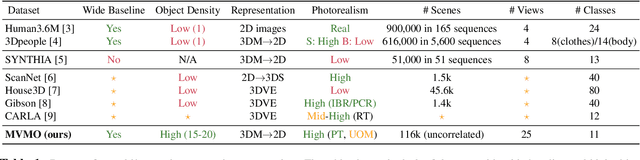
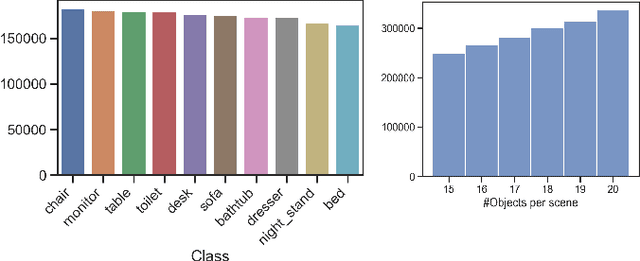
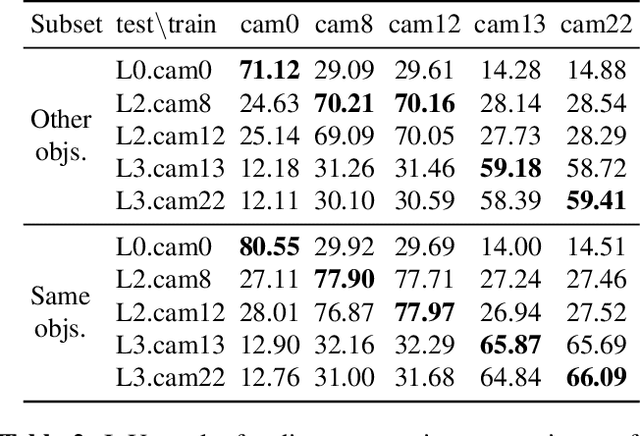
We present MVMO (Multi-View, Multi-Object dataset): a synthetic dataset of 116,000 scenes containing randomly placed objects of 10 distinct classes and captured from 25 camera locations in the upper hemisphere. MVMO comprises photorealistic, path-traced image renders, together with semantic segmentation ground truth for every view. Unlike existing multi-view datasets, MVMO features wide baselines between cameras and high density of objects, which lead to large disparities, heavy occlusions and view-dependent object appearance. Single view semantic segmentation is hindered by self and inter-object occlusions that could benefit from additional viewpoints. Therefore, we expect that MVMO will propel research in multi-view semantic segmentation and cross-view semantic transfer. We also provide baselines that show that new research is needed in such fields to exploit the complementary information of multi-view setups.