 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Style-Content Disentanglement in Language-Image Pretraining Representations for Zero-Shot Sketch-to-Image Synthesis
Jun 03, 2022

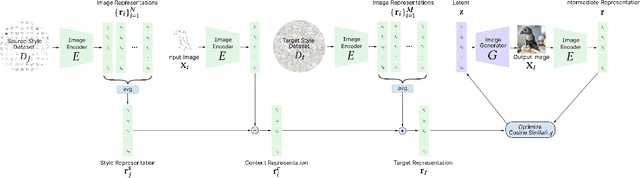


In this work, we propose and validate a framework to leverage language-image pretraining representations for training-free zero-shot sketch-to-image synthesis. We show that disentangled content and style representations can be utilized to guide image generators to employ them as sketch-to-image generators without (re-)training any parameters. Our approach for disentangling style and content entails a simple method consisting of elementary arithmetic assuming compositionality of information in representations of input sketches. Our results demonstrate that this approach is competitive with state-of-the-art instance-level open-domain sketch-to-image models, while only depending on pretrained off-the-shelf models and a fraction of the data.
Online Learning in Fisher Markets with Unknown Agent Preferences
Apr 27, 2022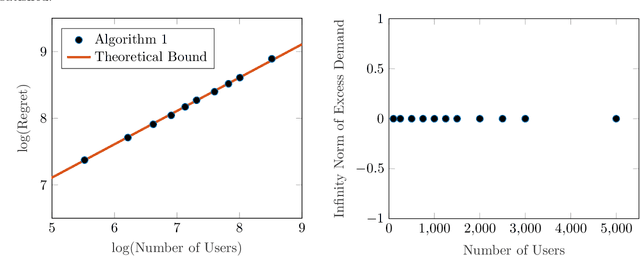
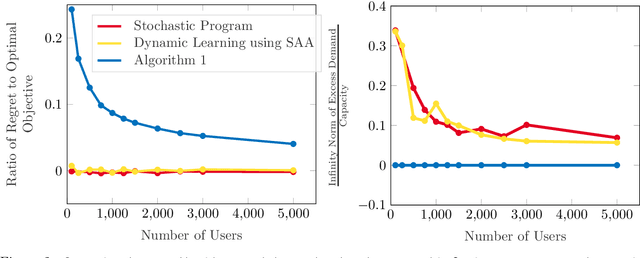
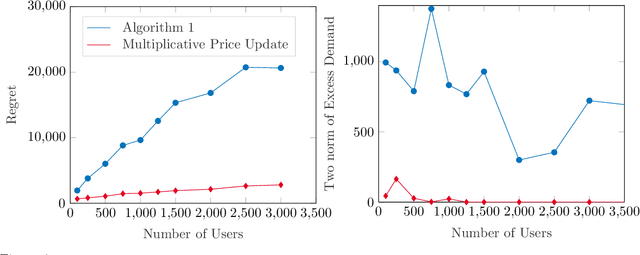
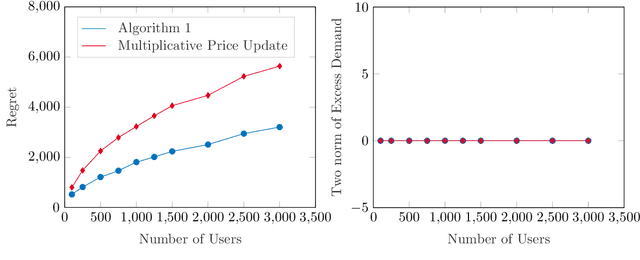
In a Fisher market, agents (users) spend a budget of (artificial) currency to buy goods that maximize their utilities, and producers set prices on capacity-constrained goods such that the market clears. The equilibrium prices in such a market are typically computed through the solution of a convex program, e.g., the Eisenberg-Gale program, that aggregates users' preferences into a centralized social welfare objective. However, the computation of equilibrium prices using convex programs assumes that all transactions happen in a static market wherein all users are present simultaneously and relies on complete information on each user's budget and utility function. Since, in practice, information on users' utilities and budgets is unknown and users tend to arrive over time in the market, we study an online variant of Fisher markets, wherein users enter the market sequentially. We focus on the setting where users have linear utilities with privately known utility and budget parameters drawn i.i.d. from a distribution $\mathcal{D}$. In this setting, we develop a simple yet effective algorithm to set prices that preserves user privacy while achieving a regret and capacity violation of $O(\sqrt{n})$, where $n$ is the number of arriving users and the capacities of the goods scale as $O(n)$. Here, our regret measure represents the optimality gap in the objective of the Eisenberg-Gale program between the online allocation policy and that of an offline oracle with complete information on users' budgets and utilities. To establish the efficacy of our approach, we show that even an algorithm that sets expected equilibrium prices with perfect information on the distribution $\mathcal{D}$ cannot achieve both a regret and constraint violation of better than $\Omega(\sqrt{n})$. Finally, we present numerical experiments to demonstrate the performance of our approach relative to several benchmarks.
Learning to Look Inside: Augmenting Token-Based Encoders with Character-Level Information
Aug 01, 2021
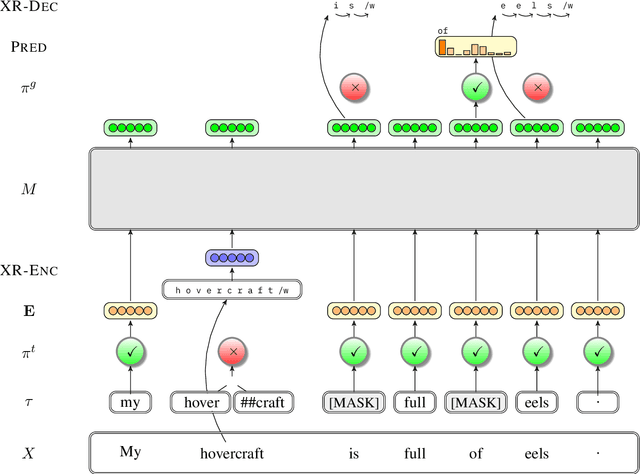

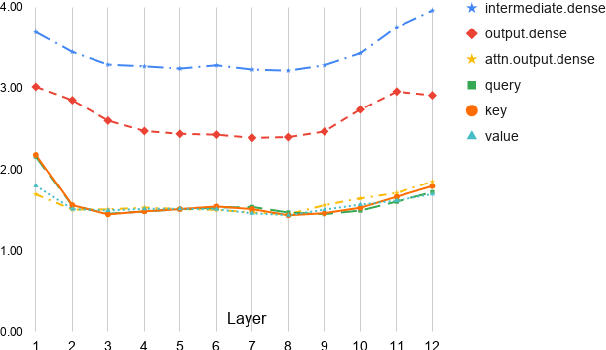
Commonly-used transformer language models depend on a tokenization schema which sets an unchangeable subword vocabulary prior to pre-training, destined to be applied to all downstream tasks regardless of domain shift, novel word formations, or other sources of vocabulary mismatch. Recent work has shown that "token-free" models can be trained directly on characters or bytes, but training these models from scratch requires substantial computational resources, and this implies discarding the many domain-specific models that were trained on tokens. In this paper, we present XRayEmb, a method for retrofitting existing token-based models with character-level information. XRayEmb is composed of a character-level "encoder" that computes vector representations of character sequences, and a generative component that decodes from the internal representation to a character sequence. We show that incorporating XRayEmb's learned vectors into sequences of pre-trained token embeddings helps performance on both autoregressive and masked pre-trained transformer architectures and on both sequence-level and sequence tagging tasks, particularly on non-standard English text.
PhD Thesis. Computer-Aided Assessment of Tuberculosis with Radiological Imaging: From rule-based methods to Deep Learning
May 31, 2022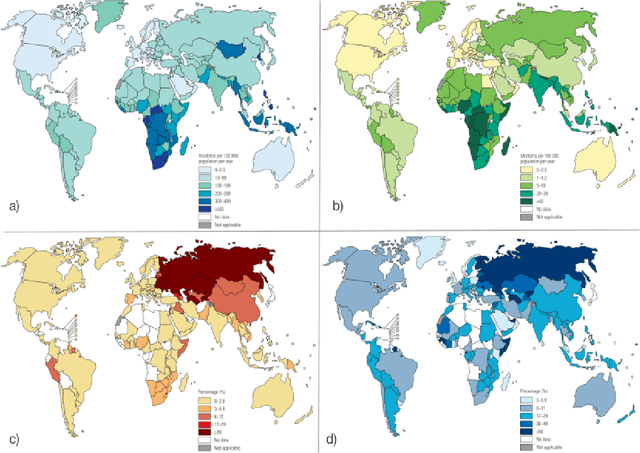
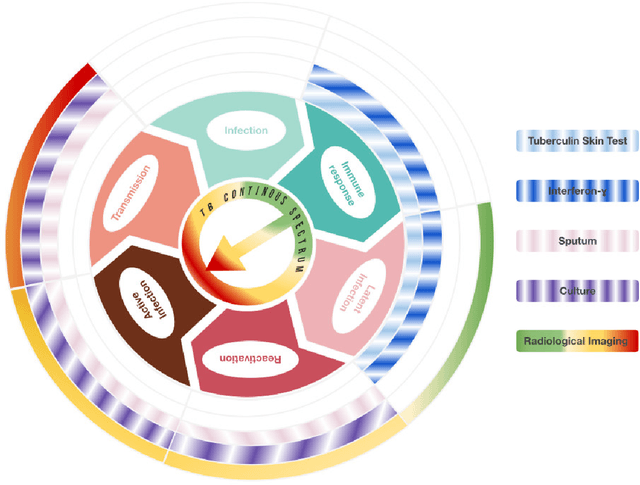
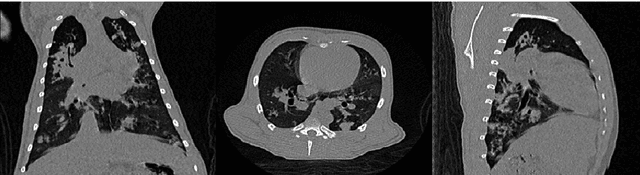
Tuberculosis (TB) is an infectious disease caused by Mycobacterium tuberculosis (Mtb.) that produces pulmonary damage due to its airborne nature. This fact facilitates the disease fast-spreading, which, according to the World Health Organization (WHO), in 2021 caused 1.2 million deaths and 9.9 million new cases. Fortunately, X-Ray Computed Tomography (CT) images enable capturing specific manifestations of TB that are undetectable using regular diagnostic tests. However, this procedure is unfeasible to process the thousands of volume images belonging to the different TB animal models and humans required for a suitable (pre-)clinical trial. To achieve suitable results, automatization of different image analysis processes is a must to quantify TB. Thus, in this thesis, we introduce a set of novel methods based on the state of the art Artificial Intelligence (AI) and Computer Vision (CV). Initially, we present an algorithm to assess Pathological Lung Segmentation (PLS). Next, a Gaussian Mixture Model ruled by an Expectation-Maximization (EM) algorithm is employed to automatically. Chapter 3 introduces a model to automate the identification of TB lesions and the characterization of disease progression. Chapter 4 extends the classification of TB lesions. Namely, we introduce a computational model to infer TB manifestations present in each lung lobe of CT scans by employing the associated radiologist reports as ground truth. In Chapter 5, we present a DL model capable of extracting disentangled information from images of different animal models, as well as information of the mechanisms that generate the CT volumes. To sum up, the thesis presents a collection of valuable tools to automate the quantification of pathological lungs. Chapter 6 elaborates on these conclusions.
Learning Feature Fusion for Unsupervised Domain Adaptive Person Re-identification
May 19, 2022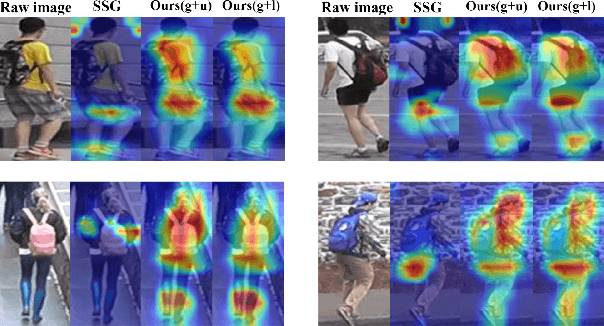
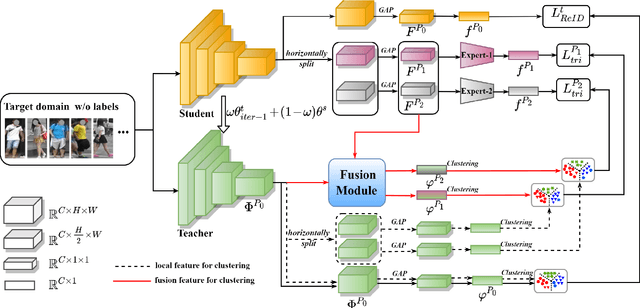
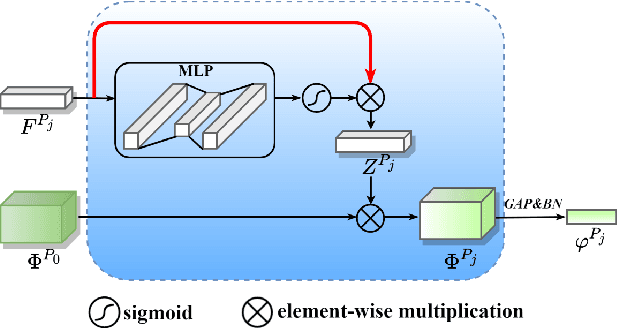
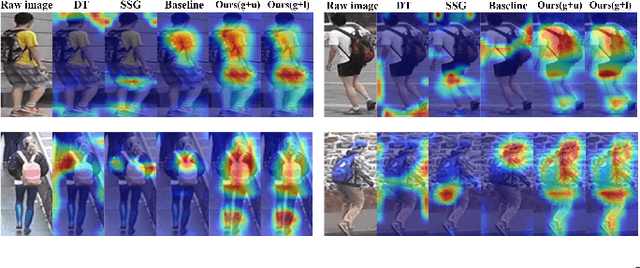
Unsupervised domain adaptive (UDA) person re-identification (ReID) has gained increasing attention for its effectiveness on the target domain without manual annotations. Most fine-tuning based UDA person ReID methods focus on encoding global features for pseudo labels generation, neglecting the local feature that can provide for the fine-grained information. To handle this issue, we propose a Learning Feature Fusion (LF2) framework for adaptively learning to fuse global and local features to obtain a more comprehensive fusion feature representation. Specifically, we first pre-train our model within a source domain, then fine-tune the model on unlabeled target domain based on the teacher-student training strategy. The average weighting teacher network is designed to encode global features, while the student network updating at each iteration is responsible for fine-grained local features. By fusing these multi-view features, multi-level clustering is adopted to generate diverse pseudo labels. In particular, a learnable Fusion Module (FM) for giving prominence to fine-grained local information within the global feature is also proposed to avoid obscure learning of multiple pseudo labels. Experiments show that our proposed LF2 framework outperforms the state-of-the-art with 73.5% mAP and 83.7% Rank1 on Market1501 to DukeMTMC-ReID, and achieves 83.2% mAP and 92.8% Rank1 on DukeMTMC-ReID to Market1501.
Resonant Tunnelling Diode Nano-Optoelectronic Spiking Nodes For Neuromorphic Information Processing
Jul 14, 2021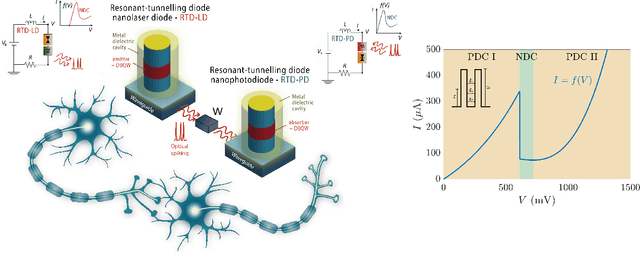
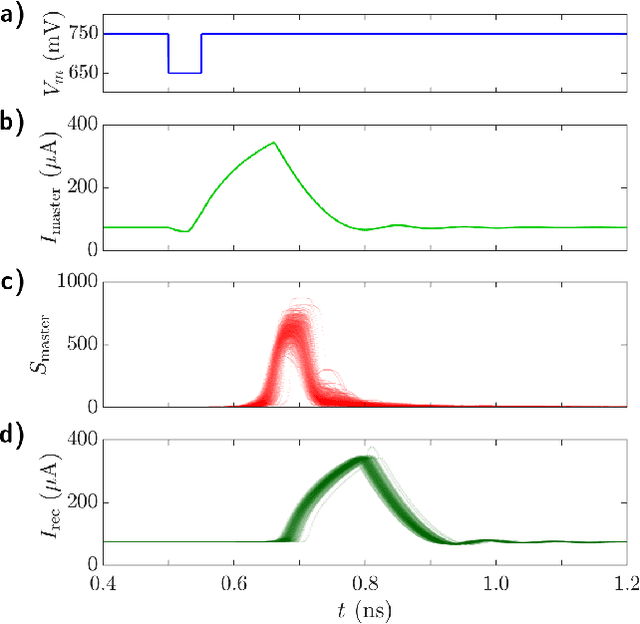
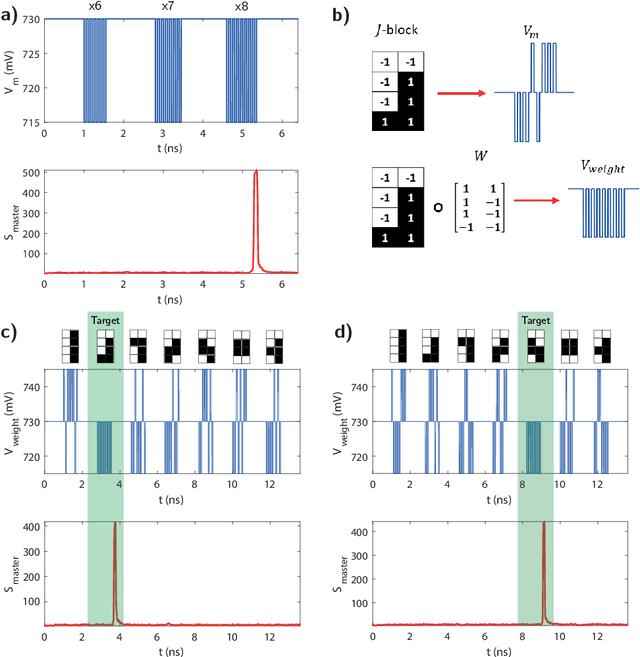
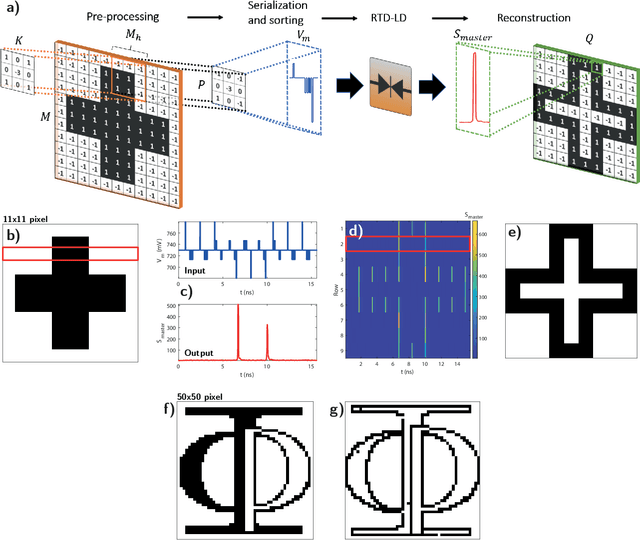
In this work, we introduce an optoelectronic spiking artificial neuron capable of operating at ultrafast rates ($\approx$ 100 ps/optical spike) and with low energy consumption ($<$ pJ/spike). The proposed system combines an excitable resonant tunnelling diode (RTD) element exhibiting negative differential conductance, coupled to a nanoscale light source (forming a master node) or a photodetector (forming a receiver node). We study numerically the spiking dynamical responses and information propagation functionality of an interconnected master-receiver RTD node system. Using the key functionality of pulse thresholding and integration, we utilize a single node to classify sequential pulse patterns and perform convolutional functionality for image feature (edge) recognition. We also demonstrate an optically-interconnected spiking neural network model for processing of spatiotemporal data at over 10 Gbps with high inference accuracy. Finally, we demonstrate an off-chip supervised learning approach utilizing spike-timing dependent plasticity for the RTD-enabled photonic spiking neural network. These results demonstrate the potential and viability of RTD spiking nodes for low footprint, low energy, high-speed optoelectronic realization of neuromorphic hardware.
Graph Enhanced BERT for Query Understanding
Apr 03, 2022
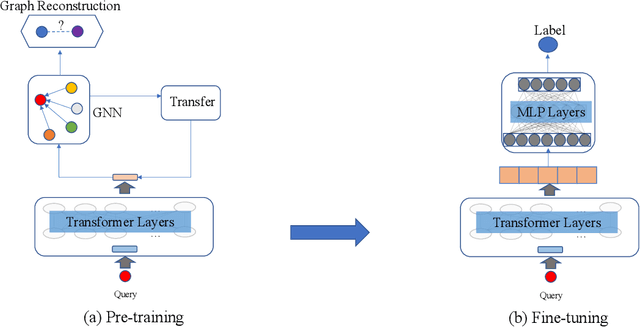
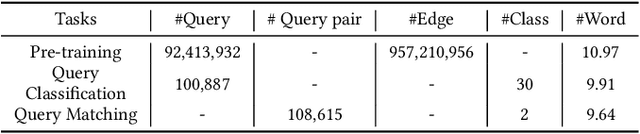
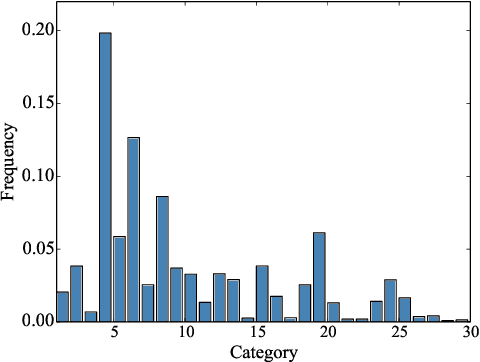
Query understanding plays a key role in exploring users' search intents and facilitating users to locate their most desired information. However, it is inherently challenging since it needs to capture semantic information from short and ambiguous queries and often requires massive task-specific labeled data. In recent years, pre-trained language models (PLMs) have advanced various natural language processing tasks because they can extract general semantic information from large-scale corpora. Therefore, there are unprecedented opportunities to adopt PLMs for query understanding. However, there is a gap between the goal of query understanding and existing pre-training strategies -- the goal of query understanding is to boost search performance while existing strategies rarely consider this goal. Thus, directly applying them to query understanding is sub-optimal. On the other hand, search logs contain user clicks between queries and urls that provide rich users' search behavioral information on queries beyond their content. Therefore, in this paper, we aim to fill this gap by exploring search logs. In particular, to incorporate search logs into pre-training, we first construct a query graph where nodes are queries and two queries are connected if they lead to clicks on the same urls. Then we propose a novel graph-enhanced pre-training framework, GE-BERT, which can leverage both query content and the query graph. In other words, GE-BERT can capture both the semantic information and the users' search behavioral information of queries. Extensive experiments on various query understanding tasks have demonstrated the effectiveness of the proposed framework.
SD-LayerNet: Semi-supervised retinal layer segmentation in OCT using disentangled representation with anatomical priors
Jul 01, 2022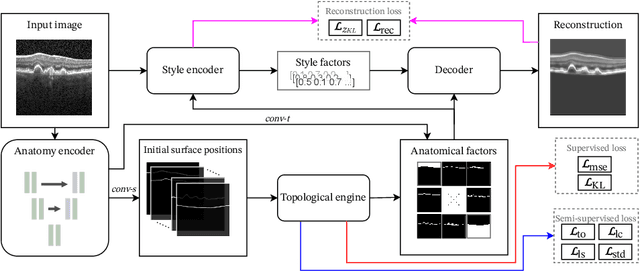
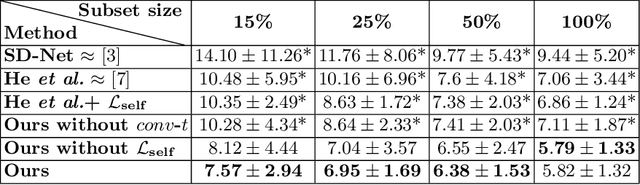
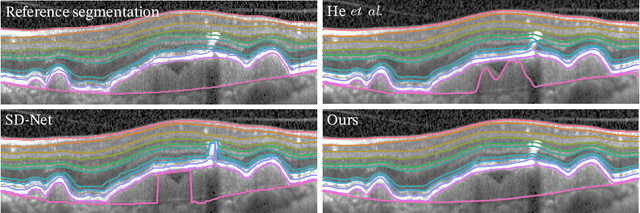

Optical coherence tomography (OCT) is a non-invasive 3D modality widely used in ophthalmology for imaging the retina. Achieving automated, anatomically coherent retinal layer segmentation on OCT is important for the detection and monitoring of different retinal diseases, like Age-related Macular Disease (AMD) or Diabetic Retinopathy. However, the majority of state-of-the-art layer segmentation methods are based on purely supervised deep-learning, requiring a large amount of pixel-level annotated data that is expensive and hard to obtain. With this in mind, we introduce a semi-supervised paradigm into the retinal layer segmentation task that makes use of the information present in large-scale unlabeled datasets as well as anatomical priors. In particular, a novel fully differentiable approach is used for converting surface position regression into a pixel-wise structured segmentation, allowing to use both 1D surface and 2D layer representations in a coupled fashion to train the model. In particular, these 2D segmentations are used as anatomical factors that, together with learned style factors, compose disentangled representations used for reconstructing the input image. In parallel, we propose a set of anatomical priors to improve network training when a limited amount of labeled data is available. We demonstrate on the real-world dataset of scans with intermediate and wet-AMD that our method outperforms state-of-the-art when using our full training set, but more importantly largely exceeds state-of-the-art when it is trained with a fraction of the labeled data.
Past and Future Motion Guided Network for Audio Visual Event Localization
May 08, 2022
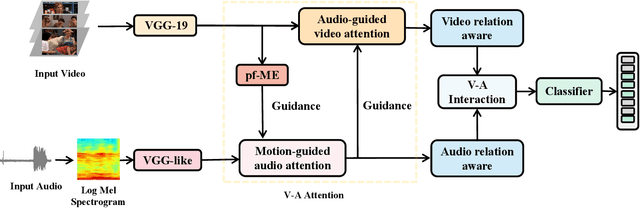
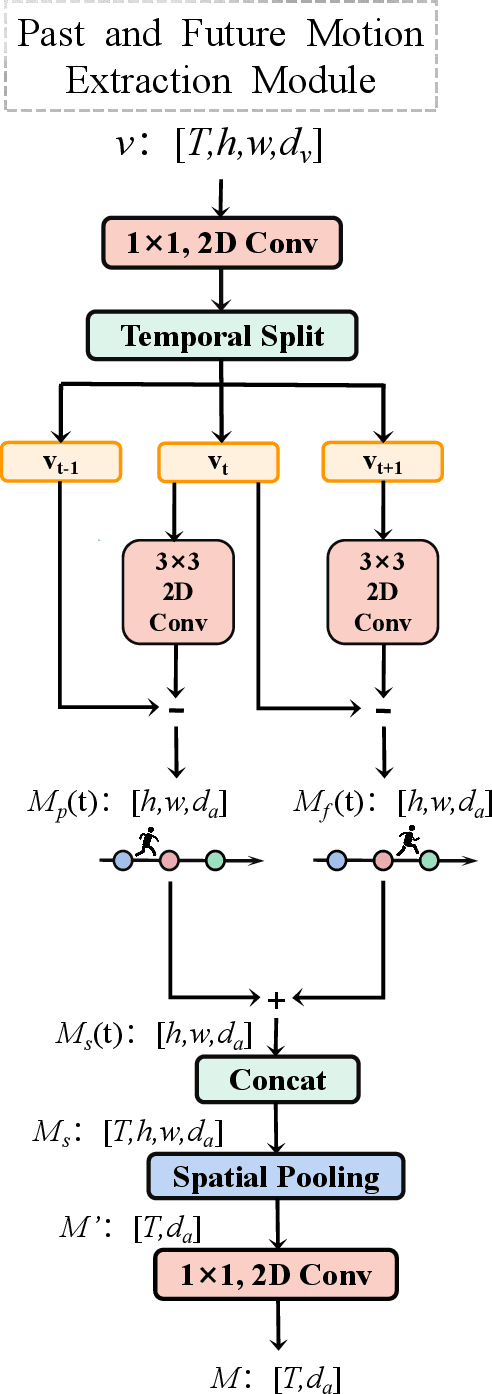
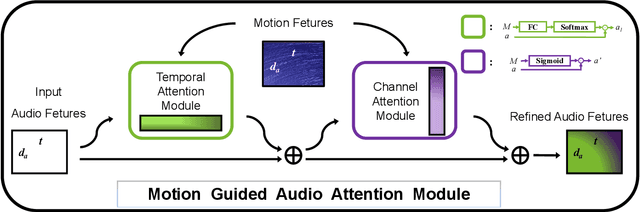
In recent years, audio-visual event localization has attracted much attention. It's purpose is to detect the segment containing audio-visual events and recognize the event category from untrimmed videos. Existing methods use audio-guided visual attention to lead the model pay attention to the spatial area of the ongoing event, devoting to the correlation between audio and visual information but ignoring the correlation between audio and spatial motion. We propose a past and future motion extraction (pf-ME) module to mine the visual motion from videos ,embedded into the past and future motion guided network (PFAGN), and motion guided audio attention (MGAA) module to achieve focusing on the information related to interesting events in audio modality through the past and future visual motion. We choose AVE as the experimental verification dataset and the experiments show that our method outperforms the state-of-the-arts in both supervised and weakly-supervised settings.
GD-VAEs: Geometric Dynamic Variational Autoencoders for Learning Nonlinear Dynamics and Dimension Reductions
Jun 10, 2022
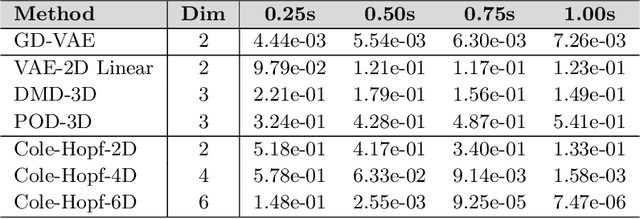
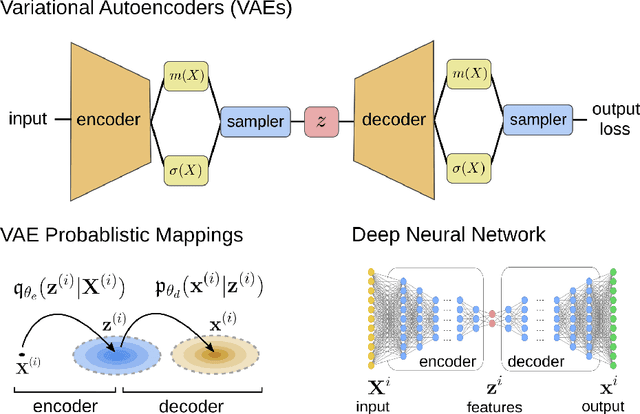
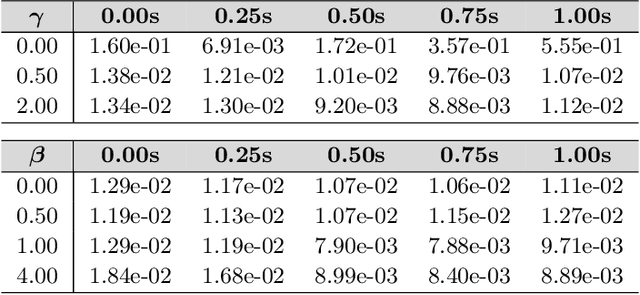
We develop data-driven methods incorporating geometric and topological information to learn parsimonious representations of nonlinear dynamics from observations. We develop approaches for learning nonlinear state space models of the dynamics for general manifold latent spaces using training strategies related to Variational Autoencoders (VAEs). Our methods are referred to as Geometric Dynamic (GD) Variational Autoencoders (GD-VAEs). We learn encoders and decoders for the system states and evolution based on deep neural network architectures that include general Multilayer Perceptrons (MLPs), Convolutional Neural Networks (CNNs), and Transpose CNNs (T-CNNs). Motivated by problems arising in parameterized PDEs and physics, we investigate the performance of our methods on tasks for learning low dimensional representations of the nonlinear Burgers equations, constrained mechanical systems, and spatial fields of reaction-diffusion systems. GD-VAEs provide methods for obtaining representations for use in learning tasks involving dynamics.