 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Video Representation Learning with Motion-Contrastive Perception
Apr 10, 2022
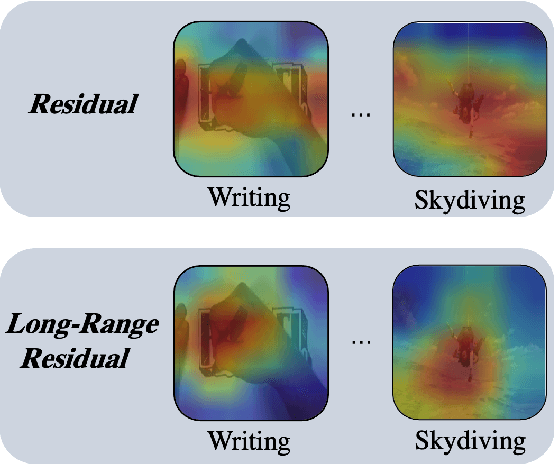
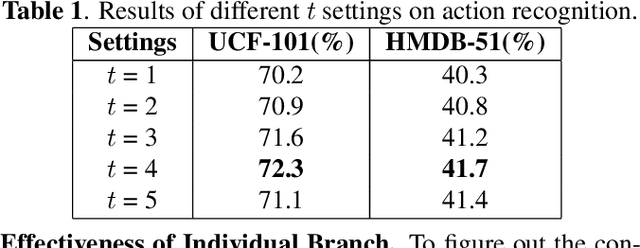
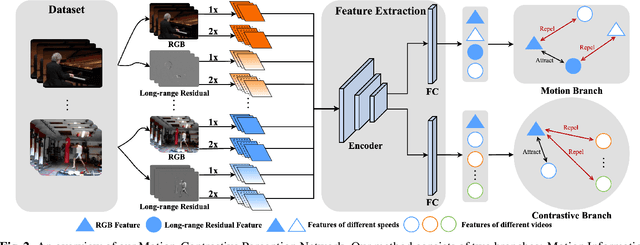

Visual-only self-supervised learning has achieved significant improvement in video representation learning. Existing related methods encourage models to learn video representations by utilizing contrastive learning or designing specific pretext tasks. However, some models are likely to focus on the background, which is unimportant for learning video representations. To alleviate this problem, we propose a new view called long-range residual frame to obtain more motion-specific information. Based on this, we propose the Motion-Contrastive Perception Network (MCPNet), which consists of two branches, namely, Motion Information Perception (MIP) and Contrastive Instance Perception (CIP), to learn generic video representations by focusing on the changing areas in videos. Specifically, the MIP branch aims to learn fine-grained motion features, and the CIP branch performs contrastive learning to learn overall semantics information for each instance. Experiments on two benchmark datasets UCF-101 and HMDB-51 show that our method outperforms current state-of-the-art visual-only self-supervised approaches.
Privacy-Preserving Image Classification Using Vision Transformer
May 24, 2022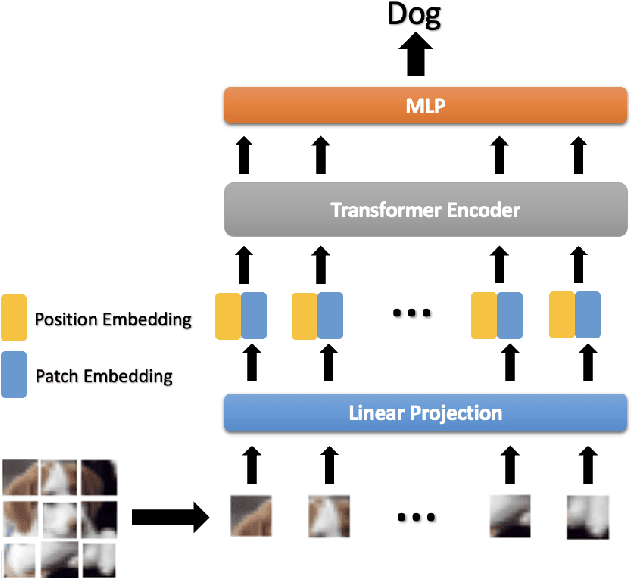
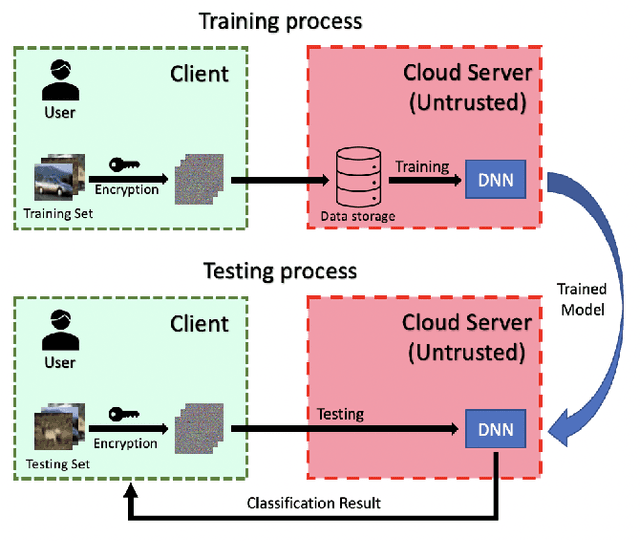


In this paper, we propose a privacy-preserving image classification method that is based on the combined use of encrypted images and the vision transformer (ViT). The proposed method allows us not only to apply images without visual information to ViT models for both training and testing but to also maintain a high classification accuracy. ViT utilizes patch embedding and position embedding for image patches, so this architecture is shown to reduce the influence of block-wise image transformation. In an experiment, the proposed method for privacy-preserving image classification is demonstrated to outperform state-of-the-art methods in terms of classification accuracy and robustness against various attacks.
"You Can't Fix What You Can't Measure": Privately Measuring Demographic Performance Disparities in Federated Learning
Jun 24, 2022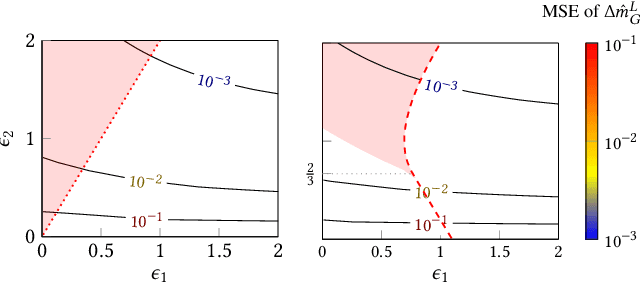
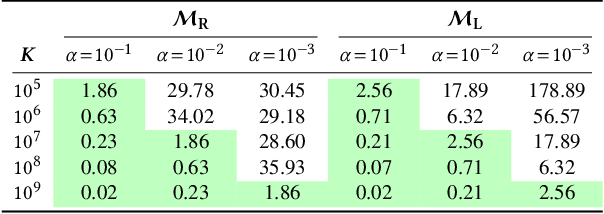
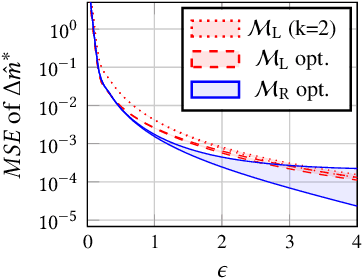
Federated learning allows many devices to collaborate in the training of machine learning models. As in traditional machine learning, there is a growing concern that models trained with federated learning may exhibit disparate performance for different demographic groups. Existing solutions to measure and ensure equal model performance across groups require access to information about group membership, but this access is not always available or desirable, especially under the privacy aspirations of federated learning. We study the feasibility of measuring such performance disparities while protecting the privacy of the user's group membership and the federated model's performance on the user's data. Protecting both is essential for privacy, because they may be correlated, and thus learning one may reveal the other. On the other hand, from the utility perspective, the privacy-preserved data should maintain the correlation to ensure the ability to perform accurate measurements of the performance disparity. We achieve both of these goals by developing locally differentially private mechanisms that preserve the correlations between group membership and model performance. To analyze the effectiveness of the mechanisms, we bound their error in estimating the disparity when optimized for a given privacy budget, and validate these bounds on synthetic data. Our results show that the error rapidly decreases for realistic numbers of participating clients, demonstrating that, contrary to what prior work suggested, protecting the privacy of protected attributes is not necessarily in conflict with identifying disparities in the performance of federated models.
Data-Driven, Soft Alignment of Functional Data Using Shapes and Landmarks
Apr 10, 2022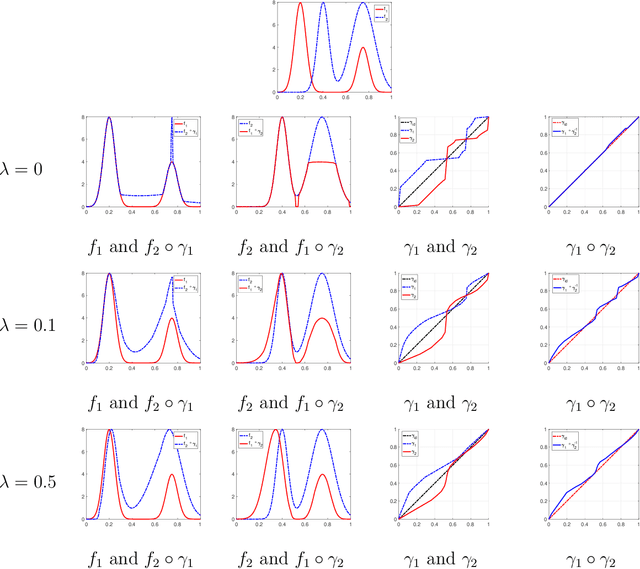
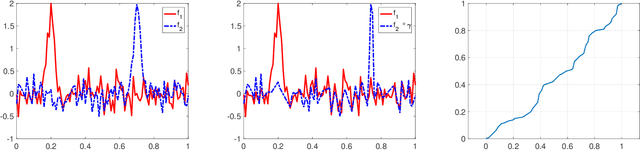
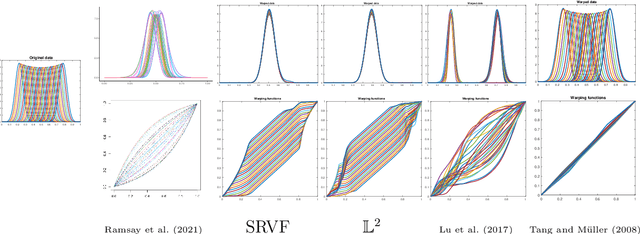
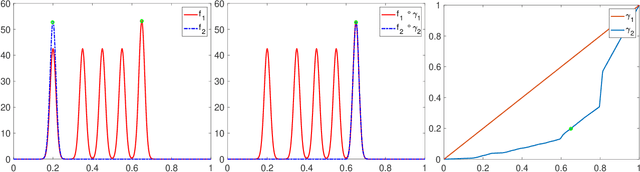
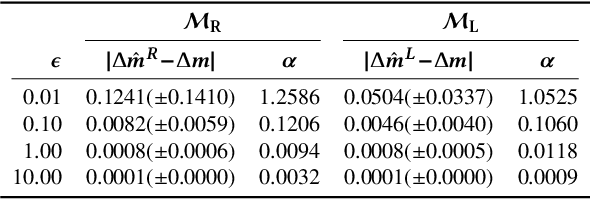
Alignment or registration of functions is a fundamental problem in statistical analysis of functions and shapes. While there are several approaches available, a more recent approach based on Fisher-Rao metric and square-root velocity functions (SRVFs) has been shown to have good performance. However, this SRVF method has two limitations: (1) it is susceptible to over alignment, i.e., alignment of noise as well as the signal, and (2) in case there is additional information in form of landmarks, the original formulation does not prescribe a way to incorporate that information. In this paper we propose an extension that allows for incorporation of landmark information to seek a compromise between matching curves and landmarks. This results in a soft landmark alignment that pushes landmarks closer, without requiring their exact overlays to finds a compromise between contributions from functions and landmarks. The proposed method is demonstrated to be superior in certain practical scenarios.
The Influence of Dataset Partitioning on Dysfluency Detection Systems
Jun 07, 2022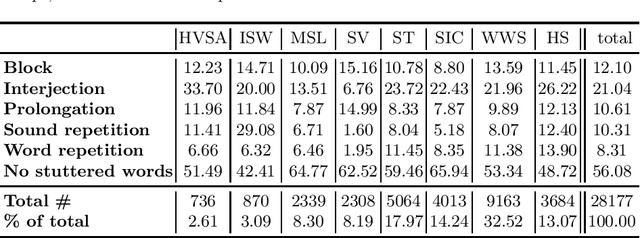

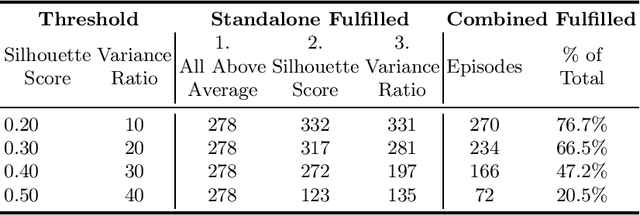
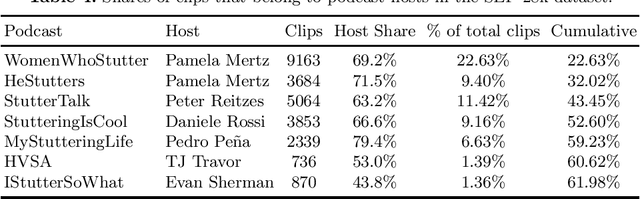
This paper empirically investigates the influence of different data splits and splitting strategies on the performance of dysfluency detection systems. For this, we perform experiments using wav2vec 2.0 models with a classification head as well as support vector machines (SVM) in conjunction with the features extracted from the wav2vec 2.0 model to detect dysfluencies. We train and evaluate the systems with different non-speaker-exclusive and speaker-exclusive splits of the Stuttering Events in Podcasts (SEP-28k) dataset to shed some light on the variability of results w.r.t. to the partition method used. Furthermore, we show that the SEP-28k dataset is dominated by only a few speakers, making it difficult to evaluate. To remedy this problem, we created SEP-28k-Extended (SEP-28k-E), containing semi-automatically generated speaker and gender information for the SEP-28k corpus, and suggest different data splits, each useful for evaluating other aspects of methods for dysfluency detection.
Information contraction in noisy binary neural networks and its implications
Feb 01, 2021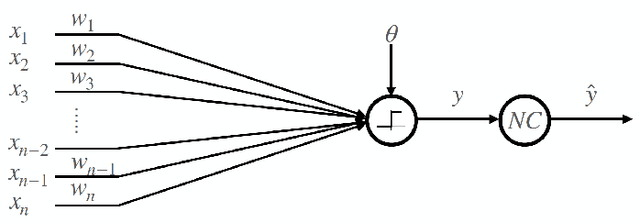
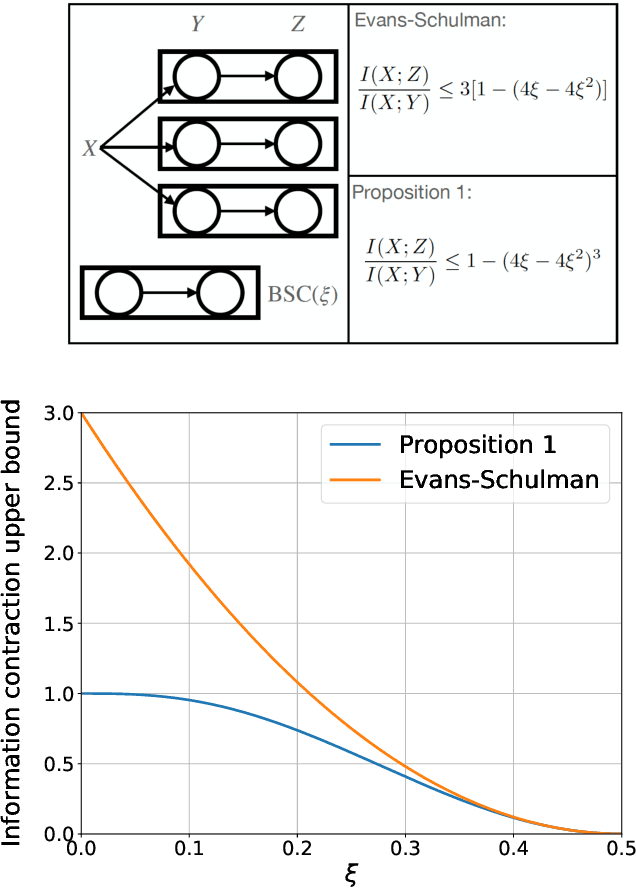
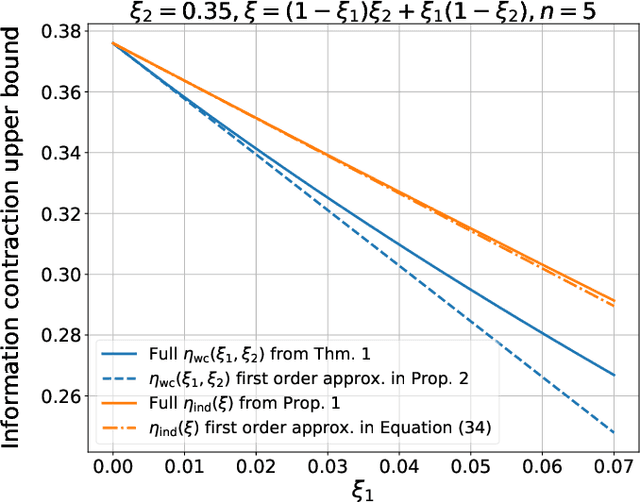
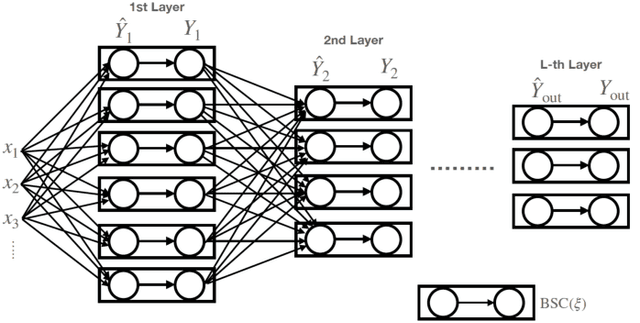
Neural networks have gained importance as the machine learning models that achieve state-of-the-art performance on large-scale image classification, object detection and natural language processing tasks. In this paper, we consider noisy binary neural networks, where each neuron has a non-zero probability of producing an incorrect output. These noisy models may arise from biological, physical and electronic contexts and constitute an important class of models that are relevant to the physical world. Intuitively, the number of neurons in such systems has to grow to compensate for the noise while maintaining the same level of expressive power and computation reliability. Our key finding is a lower bound for the required number of neurons in noisy neural networks, which is first of its kind. To prove this lower bound, we take an information theoretic approach and obtain a novel strong data processing inequality (SDPI), which not only generalizes the Evans-Schulman results for binary symmetric channels to general channels, but also improves the tightness drastically when applied to estimate end-to-end information contraction in networks. Our SDPI can be applied to various information processing systems, including neural networks and cellular automata. Applying the SDPI in noisy binary neural networks, we obtain our key lower bound and investigate its implications on network depth-width trade-offs, our results suggest a depth-width trade-off for noisy neural networks that is very different from the established understanding regarding noiseless neural networks. Furthermore, we apply the SDPI to study fault-tolerant cellular automata and obtain bounds on the error correction overheads and the relaxation time. This paper offers new understanding of noisy information processing systems through the lens of information theory.
mSHINE: A Multiple-meta-paths Simultaneous Learning Framework for Heterogeneous Information Network Embedding
Apr 09, 2021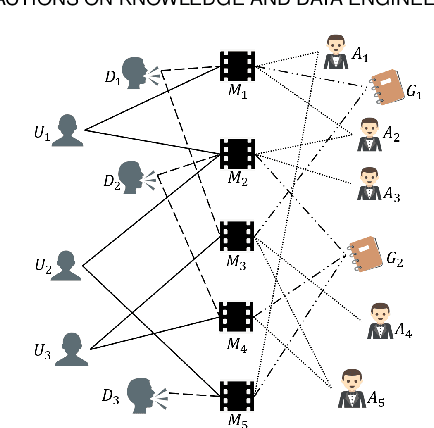
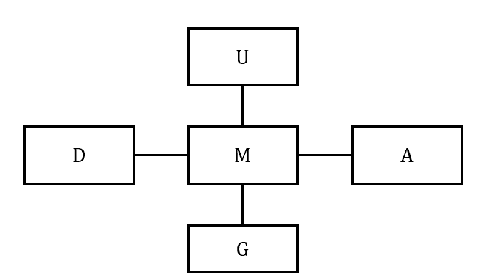
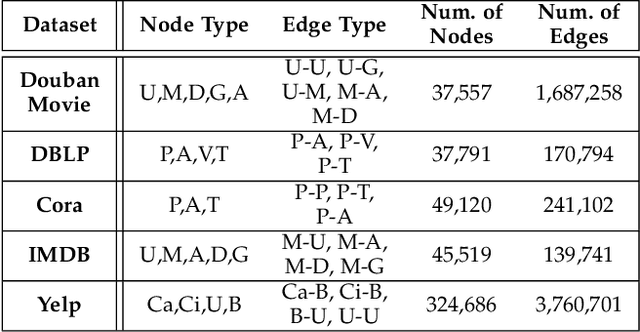
Heterogeneous information networks(HINs) become popular in recent years for its strong capability of modelling objects with abundant information using explicit network structure. Network embedding has been proved as an effective method to convert information networks into lower-dimensional space, whereas the core information can be well preserved. However, traditional network embedding algorithms are sub-optimal in capturing rich while potentially incompatible semantics provided by HINs. To address this issue, a novel meta-path-based HIN representation learning framework named mSHINE is designed to simultaneously learn multiple node representations for different meta-paths. More specifically, one representation learning module inspired by the RNN structure is developed and multiple node representations can be learned simultaneously, where each representation is associated with one respective meta-path. By measuring the relevance between nodes with the designed objective function, the learned module can be applied in downstream link prediction tasks. A set of criteria for selecting initial meta-paths is proposed as the other module in mSHINE which is important to reduce the optimal meta-path selection cost when no prior knowledge of suitable meta-paths is available. To corroborate the effectiveness of mSHINE, extensive experimental studies including node classification and link prediction are conducted on five real-world datasets. The results demonstrate that mSHINE outperforms other state-of-the-art HIN embedding methods.
Powering COVID-19 community Q&A with Curated Side Information
Jan 27, 2021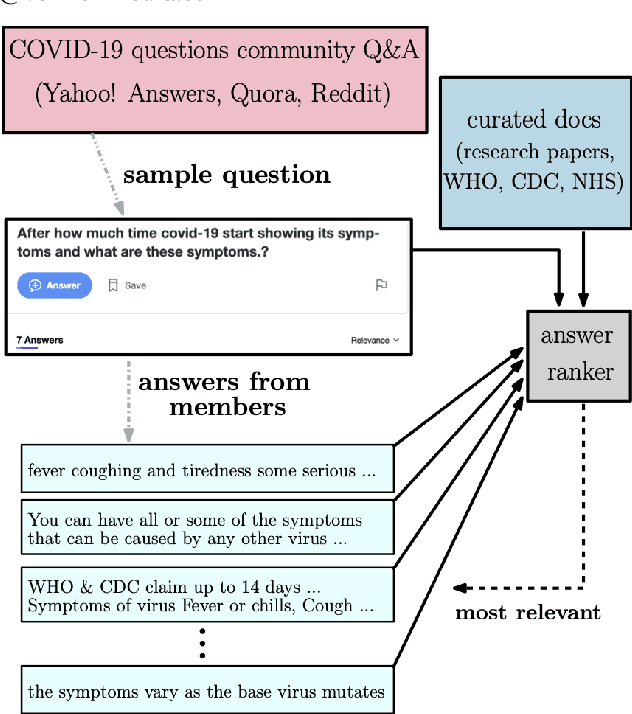

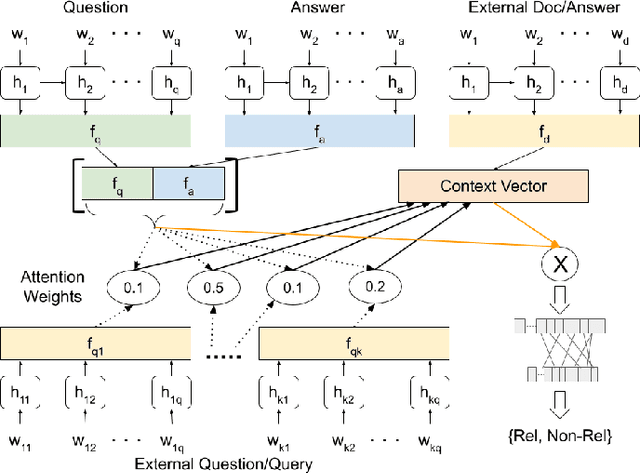
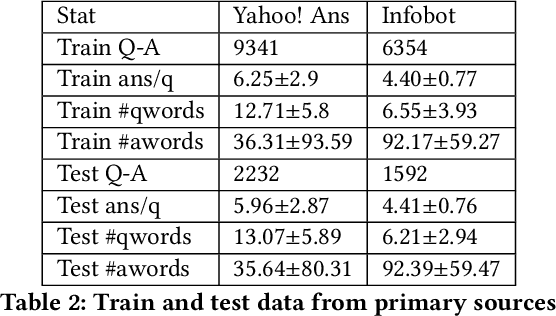
Community question answering and discussion platforms such as Reddit, Yahoo! answers or Quora provide users the flexibility of asking open ended questions to a large audience, and replies to such questions maybe useful both to the user and the community on certain topics such as health, sports or finance. Given the recent events around COVID-19, some of these platforms have attracted 2000+ questions from users about several aspects associated with the disease. Given the impact of this disease on general public, in this work we investigate ways to improve the ranking of user generated answers on COVID-19. We specifically explore the utility of external technical sources of side information (such as CDC guidelines or WHO FAQs) in improving answer ranking on such platforms. We found that ranking user answers based on question-answer similarity is not sufficient, and existing models cannot effectively exploit external (side) information. In this work, we demonstrate the effectiveness of different attention based neural models that can directly exploit side information available in technical documents or verified forums (e.g., research publications on COVID-19 or WHO website). Augmented with a temperature mechanism, the attention based neural models can selectively determine the relevance of side information for a given user question, while ranking answers.
Deep Embedded Multi-View Clustering via Jointly Learning Latent Representations and Graphs
May 08, 2022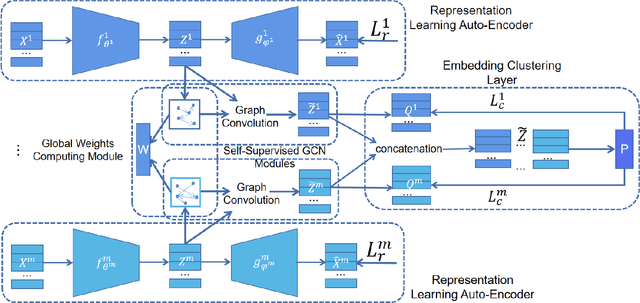
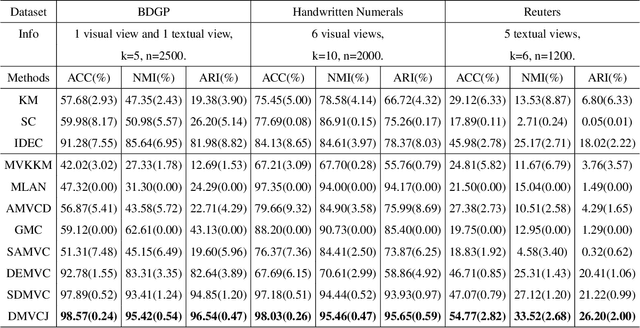

With the representation learning capability of the deep learning models, deep embedded multi-view clustering (MVC) achieves impressive performance in many scenarios and has become increasingly popular in recent years. Although great progress has been made in this field, most existing methods merely focus on learning the latent representations and ignore that learning the latent graph of nodes also provides available information for the clustering task. To address this issue, in this paper we propose Deep Embedded Multi-view Clustering via Jointly Learning Latent Representations and Graphs (DMVCJ), which utilizes the latent graphs to promote the performance of deep embedded MVC models from two aspects. Firstly, by learning the latent graphs and feature representations jointly, the graph convolution network (GCN) technique becomes available for our model. With the capability of GCN in exploiting the information from both graphs and features, the clustering performance of our model is significantly promoted. Secondly, based on the adjacency relations of nodes shown in the latent graphs, we design a sample-weighting strategy to alleviate the noisy issue, and further improve the effectiveness and robustness of the model. Experimental results on different types of real-world multi-view datasets demonstrate the effectiveness of DMVCJ.
Deep-Learning-Aided Distributed Clock Synchronization for Wireless Networks
Jun 24, 2022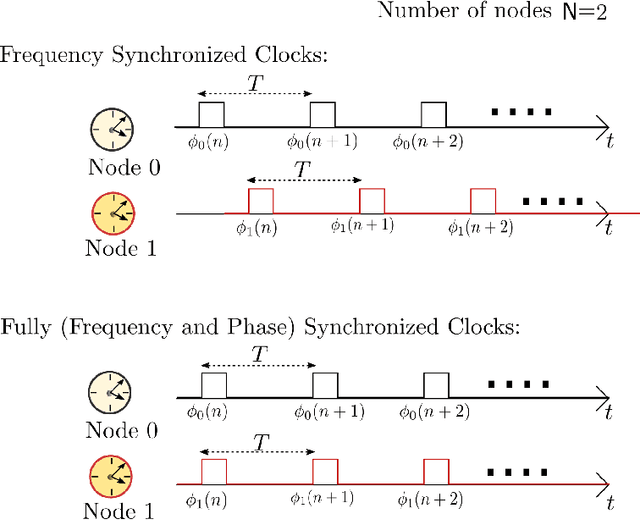
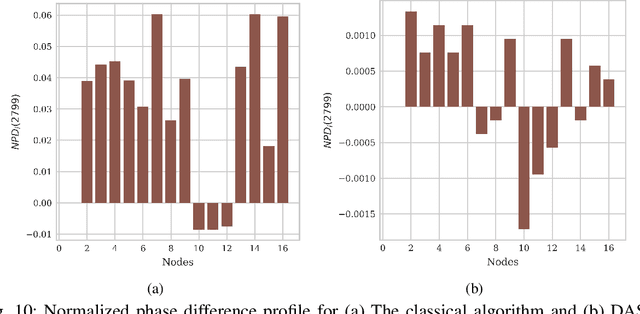
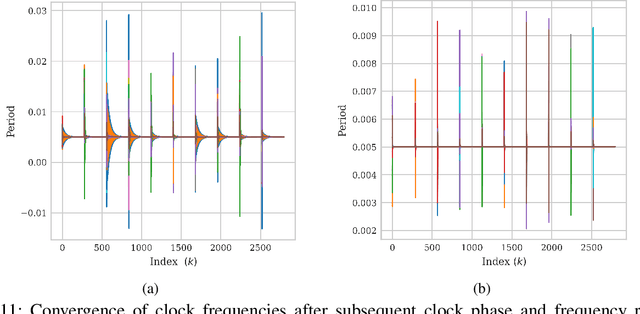
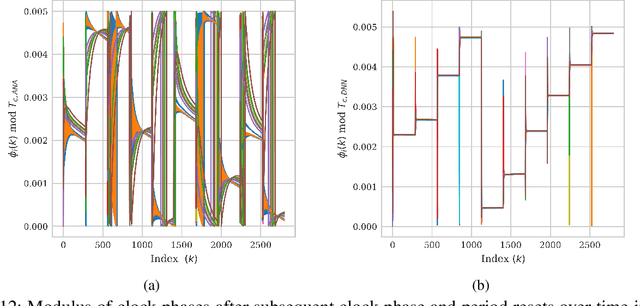
The proliferation of wireless communications networks over the past decades, combined with the scarcity of the wireless spectrum, have motivated a significant effort towards increasing the throughput of wireless networks. One of the major factors which limits the throughput in wireless communications networks is the accuracy of the time synchronization between the nodes in the network, as a higher throughput requires higher synchronization accuracy. Existing time synchronization schemes, and particularly, methods based on pulse-coupled oscillators (PCOs), which are the focus of the current work, have the advantage of simple implementation and achieve high accuracy when the nodes are closely located, yet tend to achieve poor synchronization performance for distant nodes. In this study, we propose a robust PCO-based time synchronization algorithm which retains the simple structure of existing approaches while operating reliably and converging quickly for both distant and closely located nodes. This is achieved by augmenting PCO-based synchronization with deep learning tools that are trainable in a distributed manner, thus allowing the nodes to train their neural network component of the synchronization algorithm without requiring additional exchange of information or central coordination. The numerical results show that our proposed deep learning-aided scheme is notably robust to propagation delays resulting from deployments over large areas, and to relative clock frequency offsets. It is also shown that the proposed approach rapidly attains full (i.e., clock frequency and phase) synchronization for all nodes in the wireless network, while the classic model-based implementation does not.