 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Instance Discriminative Learning for Depression Detection from Speech Signals
Jun 27, 2022
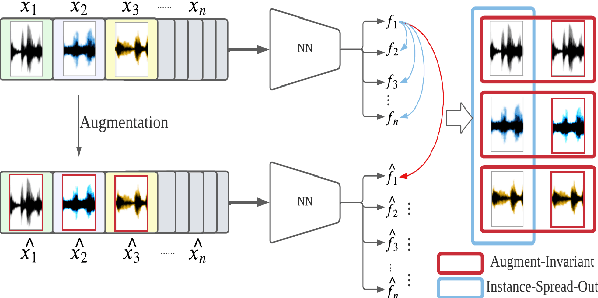
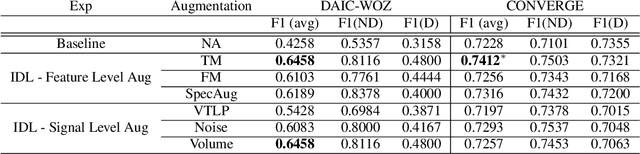
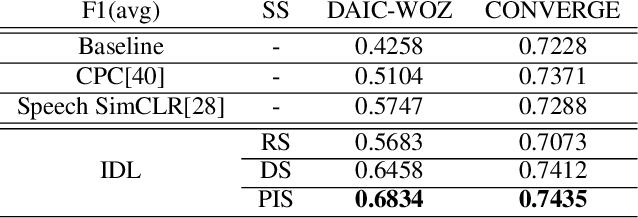
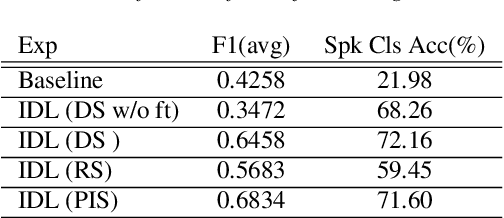
Major Depressive Disorder (MDD) is a severe illness that affects millions of people, and it is critical to diagnose this disorder as early as possible. Detecting depression from voice signals can be of great help to physicians and can be done without any invasive procedure. Since relevant labelled data are scarce, we propose a modified Instance Discriminative Learning (IDL) method, an unsupervised pre-training technique, to extract augment-invariant and instance-spread-out embeddings. In terms of learning augment-invariant embeddings, various data augmentation methods for speech are investigated, and time-masking yields the best performance. To learn instance-spread-out embeddings, we explore methods for sampling instances for a training batch (distinct speaker-based and random sampling). It is found that the distinct speaker-based sampling provides better performance than the random one, and we hypothesize that this result is because relevant speaker information is preserved in the embedding. Additionally, we propose a novel sampling strategy, Pseudo Instance-based Sampling (PIS), based on clustering algorithms, to enhance spread-out characteristics of the embeddings. Experiments are conducted with DepAudioNet on DAIC-WOZ (English) and CONVERGE (Mandarin) datasets, and statistically significant improvements, with p-value 0.0015 and 0.05, respectively, are observed using PIS in the detection of MDD relative to the baseline without pre-training.
Information Maximization Clustering via Multi-View Self-Labelling
Mar 12, 2021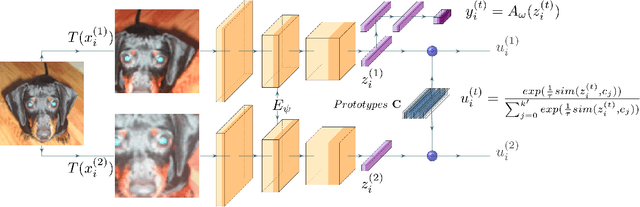
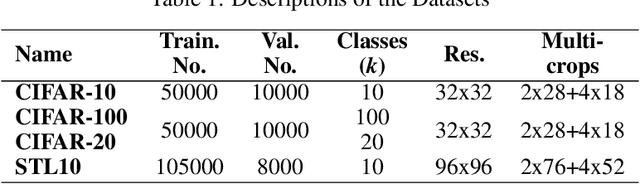
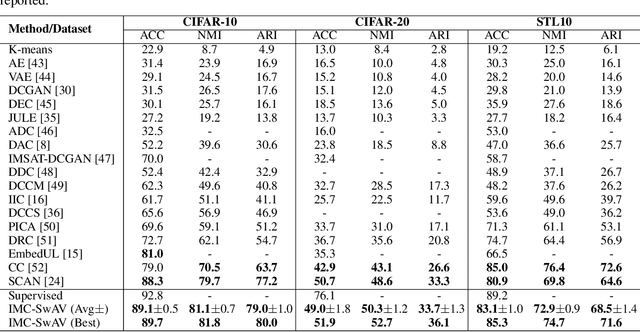
Image clustering is a particularly challenging computer vision task, which aims to generate annotations without human supervision. Recent advances focus on the use of self-supervised learning strategies in image clustering, by first learning valuable semantics and then clustering the image representations. These multiple-phase algorithms, however, increase the computational time and their final performance is reliant on the first stage. By extending the self-supervised approach, we propose a novel single-phase clustering method that simultaneously learns meaningful representations and assigns the corresponding annotations. This is achieved by integrating a discrete representation into the self-supervised paradigm through a classifier net. Specifically, the proposed clustering objective employs mutual information, and maximizes the dependency between the integrated discrete representation and a discrete probability distribution. The discrete probability distribution is derived though the self-supervised process by comparing the learnt latent representation with a set of trainable prototypes. To enhance the learning performance of the classifier, we jointly apply the mutual information across multi-crop views. Our empirical results show that the proposed framework outperforms state-of-the-art techniques with the average accuracy of 89.1% and 49.0%, respectively, on CIFAR-10 and CIFAR-100/20 datasets. Finally, the proposed method also demonstrates attractive robustness to parameter settings, making it ready to be applicable to other datasets.
Distributed Online Learning Algorithm With Differential Privacy Strategy for Convex Nondecomposable Global Objectives
Jun 16, 2022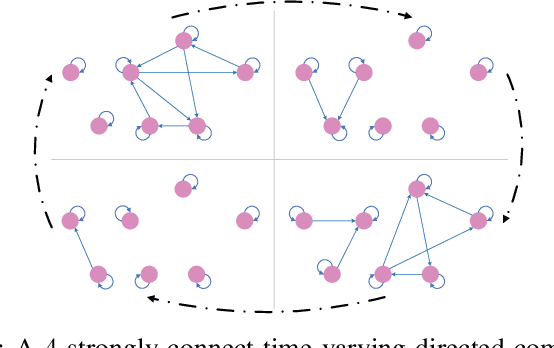
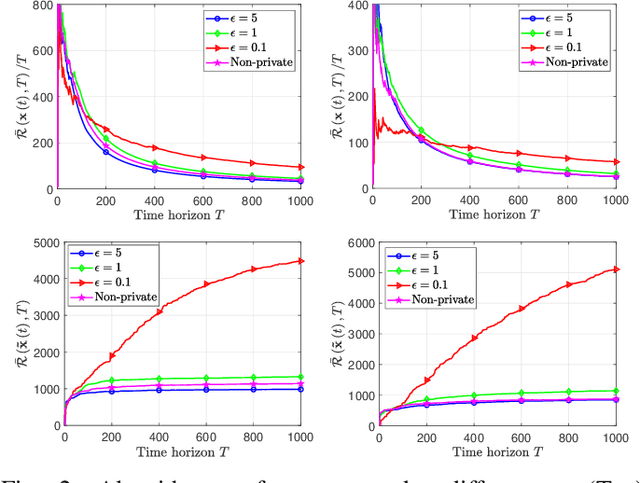
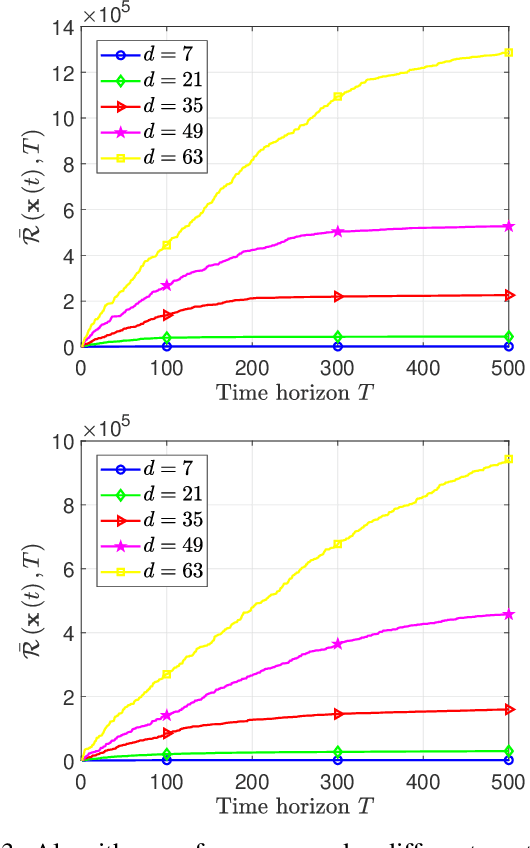
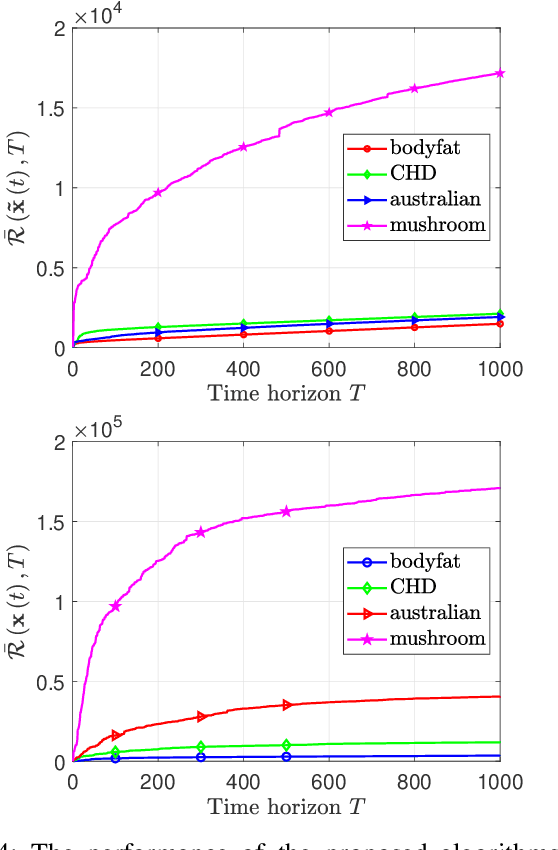
In this paper, we deal with a general distributed constrained online learning problem with privacy over time-varying networks, where a class of nondecomposable objective functions are considered. Under this setting, each node only controls a part of the global decision variable, and the goal of all nodes is to collaboratively minimize the global objective over a time horizon $T$ while guarantees the security of the transmitted information. For such problems, we first design a novel generic algorithm framework, named as DPSDA, of differentially private distributed online learning using the Laplace mechanism and the stochastic variants of dual averaging method. Then, we propose two algorithms, named as DPSDA-C and DPSDA-PS, under this framework. Theoretical results show that both algorithms attain an expected regret upper bound in $\mathcal{O}( \sqrt{T} )$ when the objective function is convex, which matches the best utility achievable by cutting-edge algorithms. Finally, numerical experiment results on both real-world and randomly generated datasets verify the effectiveness of our algorithms.
Automatic Generation of Product-Image Sequence in E-commerce
Jun 26, 2022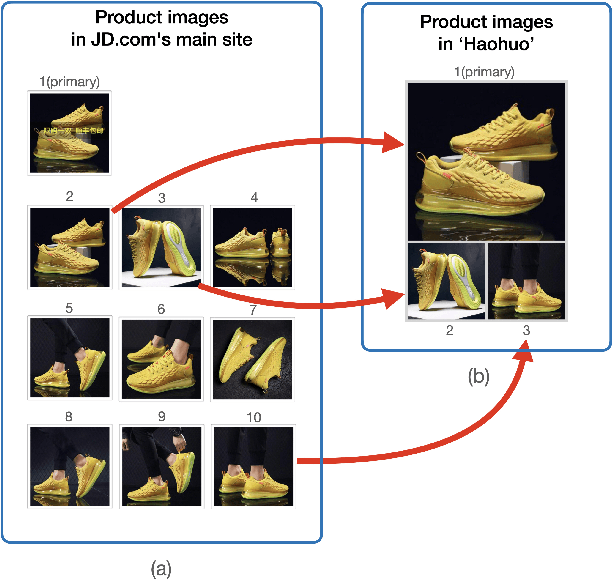

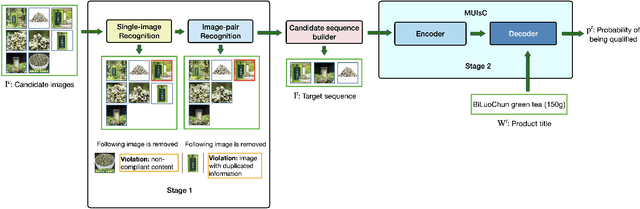
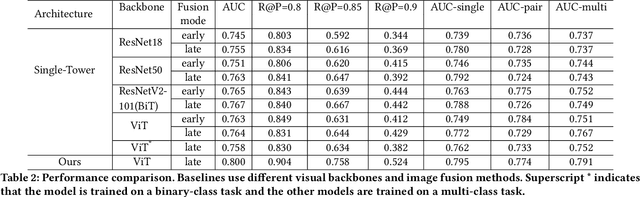
Product images are essential for providing desirable user experience in an e-commerce platform. For a platform with billions of products, it is extremely time-costly and labor-expensive to manually pick and organize qualified images. Furthermore, there are the numerous and complicated image rules that a product image needs to comply in order to be generated/selected. To address these challenges, in this paper, we present a new learning framework in order to achieve Automatic Generation of Product-Image Sequence (AGPIS) in e-commerce. To this end, we propose a Multi-modality Unified Image-sequence Classifier (MUIsC), which is able to simultaneously detect all categories of rule violations through learning. MUIsC leverages textual review feedback as the additional training target and utilizes product textual description to provide extra semantic information. Based on offline evaluations, we show that the proposed MUIsC significantly outperforms various baselines. Besides MUIsC, we also integrate some other important modules in the proposed framework, such as primary image selection, noncompliant content detection, and image deduplication. With all these modules, our framework works effectively and efficiently in JD.com recommendation platform. By Dec 2021, our AGPIS framework has generated high-standard images for about 1.5 million products and achieves 13.6% in reject rate.
Can Foundation Models Help Us Achieve Perfect Secrecy?
May 27, 2022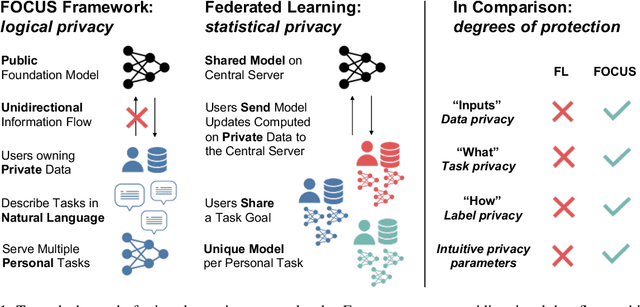
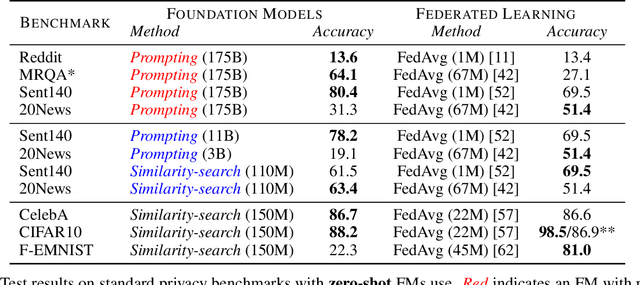
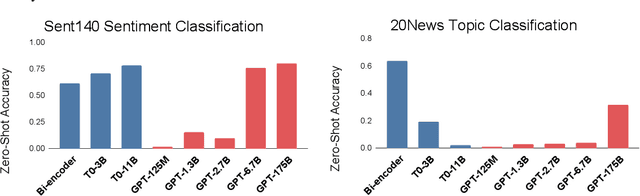

A key promise of machine learning is the ability to assist users with personal tasks. Because the personal context required to make accurate predictions is often sensitive, we require systems that protect privacy. A gold standard privacy-preserving system will satisfy perfect secrecy, meaning that interactions with the system provably reveal no additional private information to adversaries. This guarantee should hold even as we perform multiple personal tasks over the same underlying data. However, privacy and quality appear to be in tension in existing systems for personal tasks. Neural models typically require lots of training to perform well, while individual users typically hold a limited scale of data, so the systems propose to learn from the aggregate data of multiple users. This violates perfect secrecy and instead, in the last few years, academics have defended these solutions using statistical notions of privacy -- i.e., the probability of learning private information about a user should be reasonably low. Given the vulnerabilities of these solutions, we explore whether the strong perfect secrecy guarantee can be achieved using recent zero-to-few sample adaptation techniques enabled by foundation models. In response, we propose FOCUS, a framework for personal tasks. Evaluating on popular privacy benchmarks, we find the approach, satisfying perfect secrecy, competes with strong collaborative learning baselines on 6 of 7 tasks. We empirically analyze the proposal, highlighting the opportunities and limitations across task types, and model inductive biases and sizes.
Lane-GNN: Integrating GNN for Predicting Drivers' Lane Change Intention
Jul 05, 2022
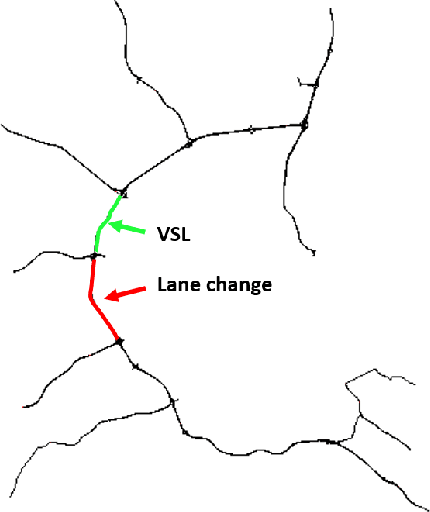
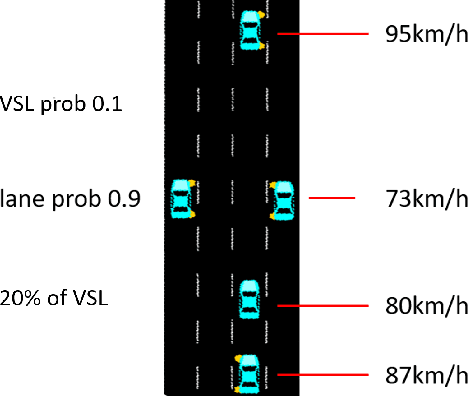
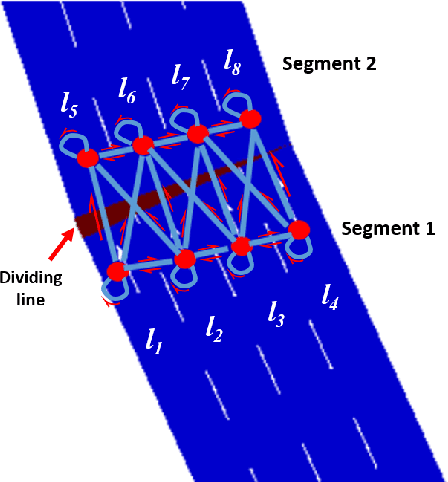
Nowadays, intelligent highway traffic network is playing an important role in modern transportation infrastructures. A variable speed limit (VSL) system can be facilitated in the highway traffic network to provide useful and dynamic speed limit information for drivers to travel with enhanced safety. Such system is usually designed with a steady advisory speed in mind so that traffic can move smoothly when drivers follow the speed, rather than speeding up whenever there is a gap and slowing down at congestion. However, little attention has been given to the research of vehicles' behaviours when drivers left the road network governed by a VSL system, which may largely involve unexpected acceleration, deceleration and frequent lane changes, resulting in chaos for the subsequent highway road users. In this paper, we focus on the detection of traffic flow anomaly due to drivers' lane change intention on the highway traffic networks after a VSL system. More specifically, we apply graph modelling on the traffic flow data generated by a popular mobility simulator, SUMO, at road segment levels. We then evaluate the performance of lane changing detection using the proposed Lane-GNN scheme, an attention temporal graph convolutional neural network, and compare its performance with a temporal convolutional neural network (TCNN) as our baseline. Our experimental results show that the proposed Lane-GNN can detect drivers' lane change intention within 90 seconds with an accuracy of 99.42% under certain assumptions. Finally, some interpretation methods are applied to the trained models with a view to further illustrate our findings.
Heterformer: A Transformer Architecture for Node Representation Learning on Heterogeneous Text-Rich Networks
May 20, 2022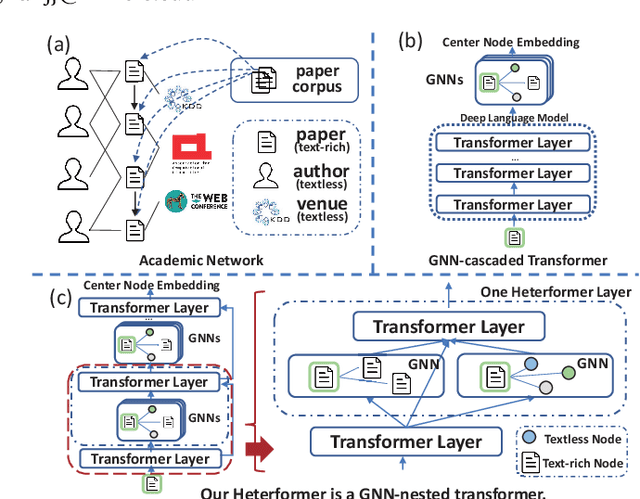
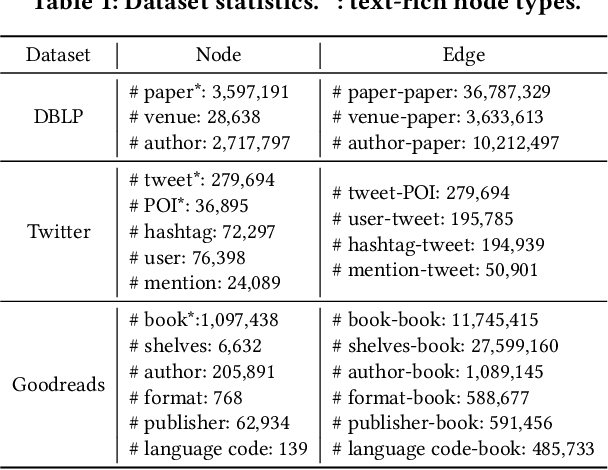

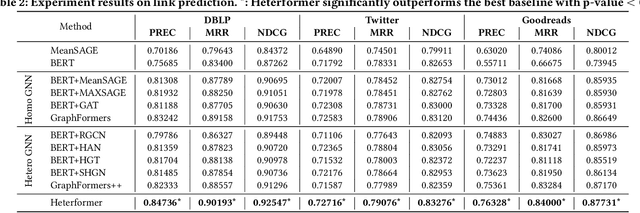
We study node representation learning on heterogeneous text-rich networks, where nodes and edges are multi-typed and some types of nodes are associated with text information. Although recent studies on graph neural networks (GNNs) and pretrained language models (PLMs) have demonstrated their power in encoding network and text signals, respectively, less focus has been given to delicately coupling these two types of models on heterogeneous text-rich networks. Specifically, existing GNNs rarely model text in each node in a contextualized way; existing PLMs can hardly be applied to characterize graph structures due to their sequence architecture. In this paper, we propose Heterformer, a Heterogeneous GNN-nested transformer that blends GNNs and PLMs into a unified model. Different from previous "cascaded architectures" that directly add GNN layers upon a PLM, our Heterformer alternately stacks two modules - a graph-attention-based neighbor aggregation module and a transformer-based text and neighbor joint encoding module - to facilitate thorough mutual enhancement between network and text signals. Meanwhile, Heterformer is capable of characterizing network heterogeneity and nodes without text information. Comprehensive experiments on three large-scale datasets from different domains demonstrate the superiority of Heterformer over state-of-the-art baselines in link prediction, transductive/inductive node classification, node clustering, and semantics-based retrieval.
Explainable and High-Performance Hate and Offensive Speech Detection
Jun 26, 2022



The spread of information through social media platforms can create environments possibly hostile to vulnerable communities and silence certain groups in society. To mitigate such instances, several models have been developed to detect hate and offensive speech. Since detecting hate and offensive speech in social media platforms could incorrectly exclude individuals from social media platforms, which can reduce trust, there is a need to create explainable and interpretable models. Thus, we build an explainable and interpretable high performance model based on the XGBoost algorithm, trained on Twitter data. For unbalanced Twitter data, XGboost outperformed the LSTM, AutoGluon, and ULMFiT models on hate speech detection with an F1 score of 0.75 compared to 0.38 and 0.37, and 0.38 respectively. When we down-sampled the data to three separate classes of approximately 5000 tweets, XGBoost performed better than LSTM, AutoGluon, and ULMFiT; with F1 scores for hate speech detection of 0.79 vs 0.69, 0.77, and 0.66 respectively. XGBoost also performed better than LSTM, AutoGluon, and ULMFiT in the down-sampled version for offensive speech detection with F1 score of 0.83 vs 0.88, 0.82, and 0.79 respectively. We use Shapley Additive Explanations (SHAP) on our XGBoost models' outputs to makes it explainable and interpretable compared to LSTM, AutoGluon and ULMFiT that are black-box models.
Reference Vector Adaptation and Mating Selection Strategy via Adaptive Resonance Theory-based Clustering for Many-objective Optimization
Apr 22, 2022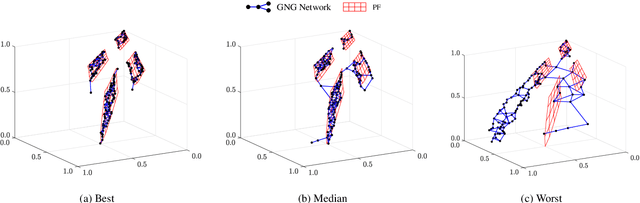
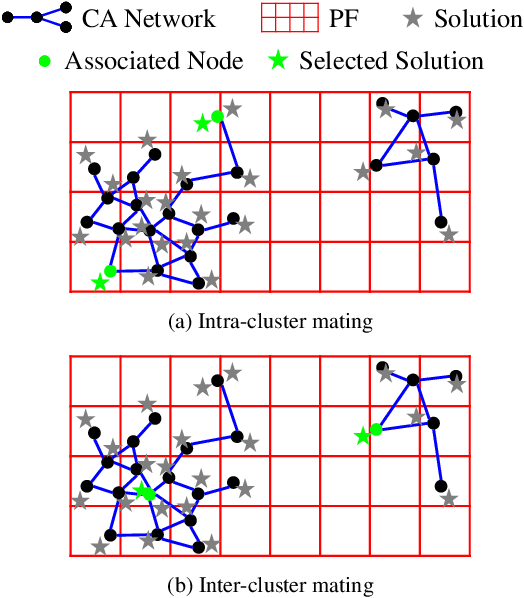

Decomposition-based multiobjective evolutionary algorithms (MOEAs) with clustering-based reference vector adaptation show good optimization performance for many-objective optimization problems (MaOPs). Especially, algorithms that employ a clustering algorithm with a topological structure (i.e., a network composed of nodes and edges) show superior optimization performance to other MOEAs for MaOPs with irregular Pareto optimal fronts (PFs). These algorithms, however, do not effectively utilize information of the topological structure in the search process. Moreover, the clustering algorithms typically used in conventional studies have limited clustering performance, inhibiting the ability to extract useful information for the search process. This paper proposes an adaptive reference vector-guided evolutionary algorithm using an adaptive resonance theory-based clustering with a topological structure. The proposed algorithm utilizes the information of the topological structure not only for reference vector adaptation but also for mating selection. The proposed algorithm is compared with 8 state-of-the-art MOEAs on 78 test problems. Experimental results reveal the outstanding optimization performance of the proposed algorithm over the others on MaOPs with various properties.
Context-Driven Detection of Invertebrate Species in Deep-Sea Video
Jun 01, 2022

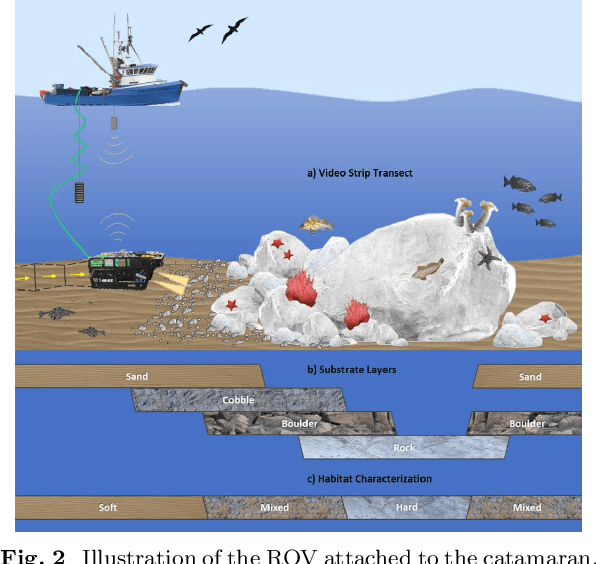
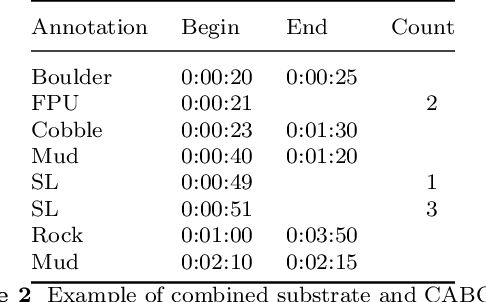
Each year, underwater remotely operated vehicles (ROVs) collect thousands of hours of video of unexplored ocean habitats revealing a plethora of information regarding biodiversity on Earth. However, fully utilizing this information remains a challenge as proper annotations and analysis require trained scientists time, which is both limited and costly. To this end, we present a Dataset for Underwater Substrate and Invertebrate Analysis (DUSIA), a benchmark suite and growing large-scale dataset to train, validate, and test methods for temporally localizing four underwater substrates as well as temporally and spatially localizing 59 underwater invertebrate species. DUSIA currently includes over ten hours of footage across 25 videos captured in 1080p at 30 fps by an ROV following pre planned transects across the ocean floor near the Channel Islands of California. Each video includes annotations indicating the start and end times of substrates across the video in addition to counts of species of interest. Some frames are annotated with precise bounding box locations for invertebrate species of interest, as seen in Figure 1. To our knowledge, DUSIA is the first dataset of its kind for deep sea exploration, with video from a moving camera, that includes substrate annotations and invertebrate species that are present at significant depths where sunlight does not penetrate. Additionally, we present the novel context-driven object detector (CDD) where we use explicit substrate classification to influence an object detection network to simultaneously predict a substrate and species class influenced by that substrate. We also present a method for improving training on partially annotated bounding box frames. Finally, we offer a baseline method for automating the counting of invertebrate species of interest.