 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FL-Defender: Combating Targeted Attacks in Federated Learning
Jul 02, 2022
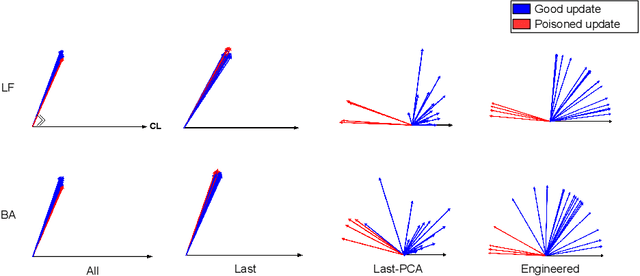
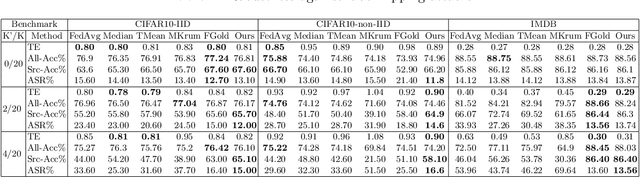
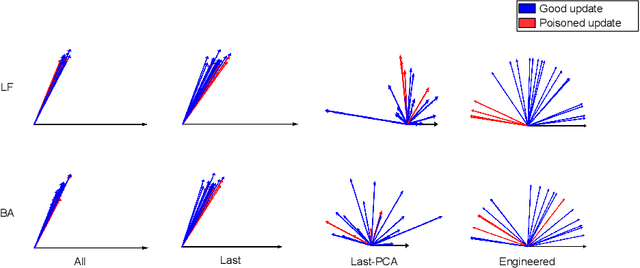
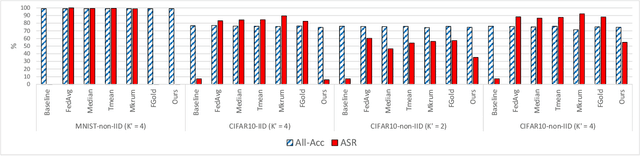
Federated learning (FL) enables learning a global machine learning model from local data distributed among a set of participating workers. This makes it possible i) to train more accurate models due to learning from rich joint training data, and ii) to improve privacy by not sharing the workers' local private data with others. However, the distributed nature of FL makes it vulnerable to targeted poisoning attacks that negatively impact the integrity of the learned model while, unfortunately, being difficult to detect. Existing defenses against those attacks are limited by assumptions on the workers' data distribution, may degrade the global model performance on the main task and/or are ill-suited to high-dimensional models. In this paper, we analyze targeted attacks against FL and find that the neurons in the last layer of a deep learning (DL) model that are related to the attacks exhibit a different behavior from the unrelated neurons, making the last-layer gradients valuable features for attack detection. Accordingly, we propose \textit{FL-Defender} as a method to combat FL targeted attacks. It consists of i) engineering more robust discriminative features by calculating the worker-wise angle similarity for the workers' last-layer gradients, ii) compressing the resulting similarity vectors using PCA to reduce redundant information, and iii) re-weighting the workers' updates based on their deviation from the centroid of the compressed similarity vectors. Experiments on three data sets with different DL model sizes and data distributions show the effectiveness of our method at defending against label-flipping and backdoor attacks. Compared to several state-of-the-art defenses, FL-Defender achieves the lowest attack success rates, maintains the performance of the global model on the main task and causes minimal computational overhead on the server.
Spiking Graph Convolutional Networks
May 05, 2022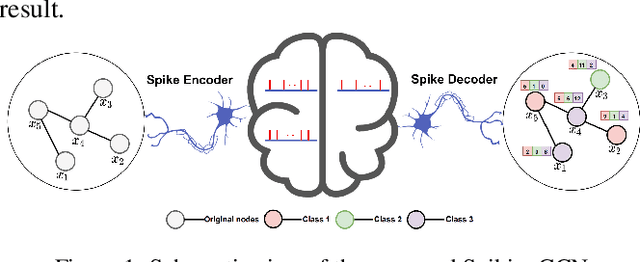
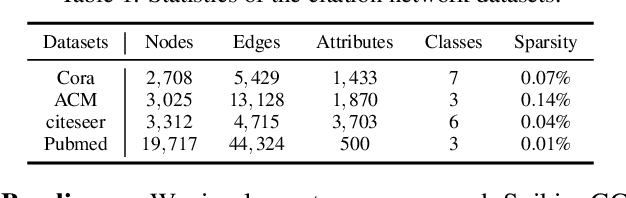
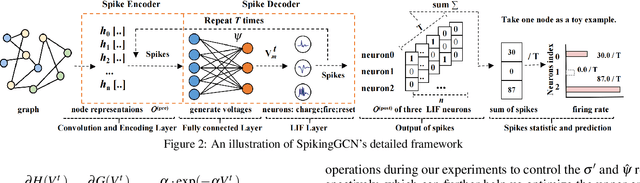
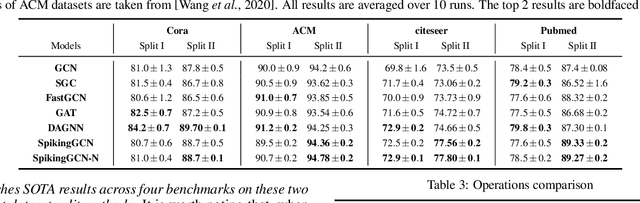
Graph Convolutional Networks (GCNs) achieve an impressive performance due to the remarkable representation ability in learning the graph information. However, GCNs, when implemented on a deep network, require expensive computation power, making them difficult to be deployed on battery-powered devices. In contrast, Spiking Neural Networks (SNNs), which perform a bio-fidelity inference process, offer an energy-efficient neural architecture. In this work, we propose SpikingGCN, an end-to-end framework that aims to integrate the embedding of GCNs with the biofidelity characteristics of SNNs. The original graph data are encoded into spike trains based on the incorporation of graph convolution. We further model biological information processing by utilizing a fully connected layer combined with neuron nodes. In a wide range of scenarios (e.g. citation networks, image graph classification, and recommender systems), our experimental results show that the proposed method could gain competitive performance against state-of-the-art approaches. Furthermore, we show that SpikingGCN on a neuromorphic chip can bring a clear advantage of energy efficiency into graph data analysis, which demonstrates its great potential to construct environment-friendly machine learning models.
Less is More: Learning to Refine Dialogue History for Personalized Dialogue Generation
Apr 18, 2022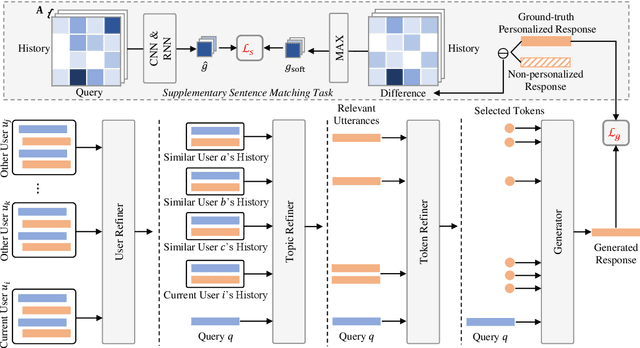
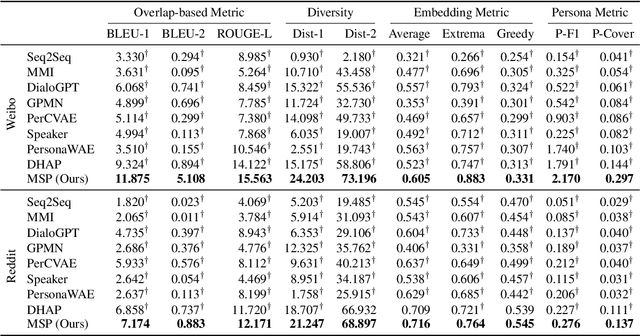
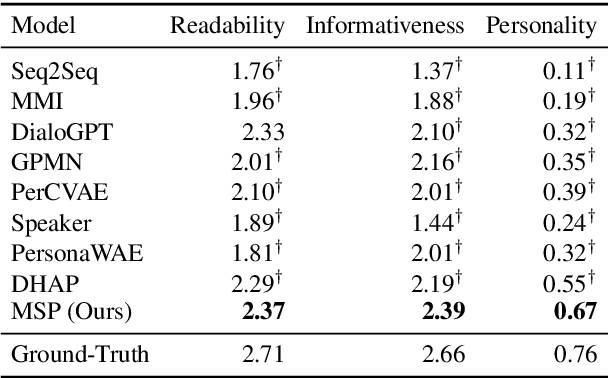
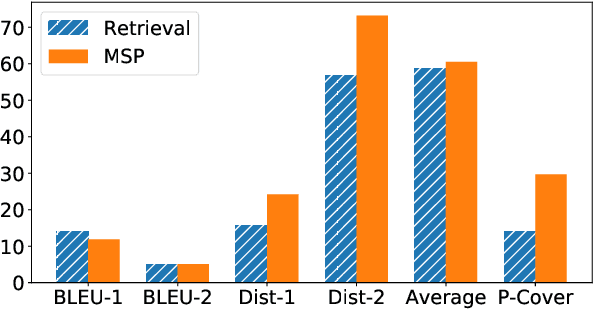
Personalized dialogue systems explore the problem of generating responses that are consistent with the user's personality, which has raised much attention in recent years. Existing personalized dialogue systems have tried to extract user profiles from dialogue history to guide personalized response generation. Since the dialogue history is usually long and noisy, most existing methods truncate the dialogue history to model the user's personality. Such methods can generate some personalized responses, but a large part of dialogue history is wasted, leading to sub-optimal performance of personalized response generation. In this work, we propose to refine the user dialogue history on a large scale, based on which we can handle more dialogue history and obtain more abundant and accurate persona information. Specifically, we design an MSP model which consists of three personal information refiners and a personalized response generator. With these multi-level refiners, we can sparsely extract the most valuable information (tokens) from the dialogue history and leverage other similar users' data to enhance personalization. Experimental results on two real-world datasets demonstrate the superiority of our model in generating more informative and personalized responses.
SIENet: Spatial Information Enhancement Network for 3D Object Detection from Point Cloud
Apr 01, 2021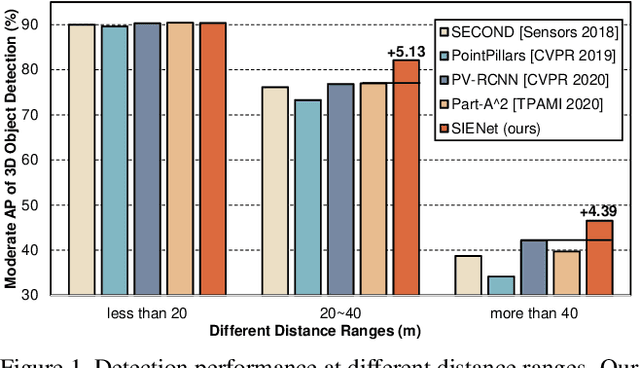
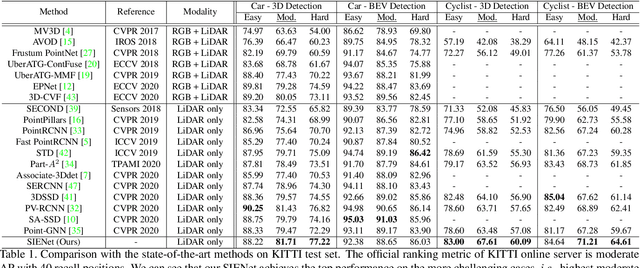
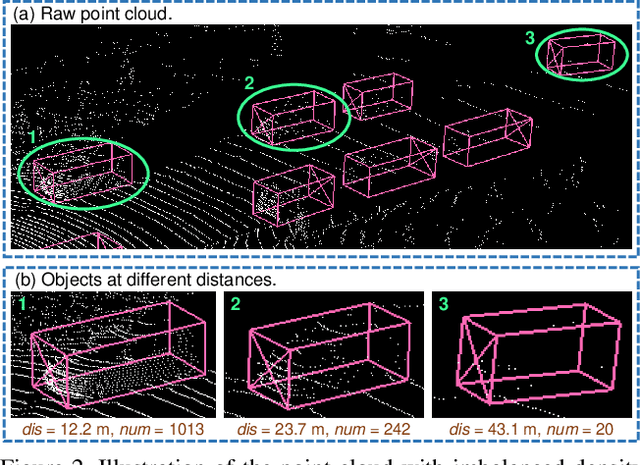
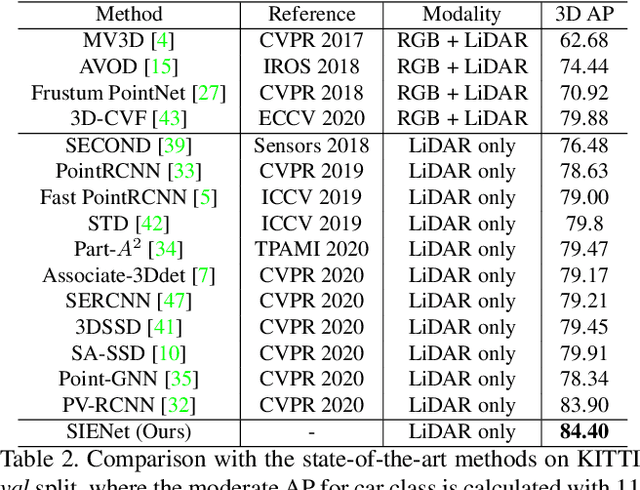
LiDAR-based 3D object detection pushes forward an immense influence on autonomous vehicles. Due to the limitation of the intrinsic properties of LiDAR, fewer points are collected at the objects farther away from the sensor. This imbalanced density of point clouds degrades the detection accuracy but is generally neglected by previous works. To address the challenge, we propose a novel two-stage 3D object detection framework, named SIENet. Specifically, we design the Spatial Information Enhancement (SIE) module to predict the spatial shapes of the foreground points within proposals, and extract the structure information to learn the representative features for further box refinement. The predicted spatial shapes are complete and dense point sets, thus the extracted structure information contains more semantic representation. Besides, we design the Hybrid-Paradigm Region Proposal Network (HP-RPN) which includes multiple branches to learn discriminate features and generate accurate proposals for the SIE module. Extensive experiments on the KITTI 3D object detection benchmark show that our elaborately designed SIENet outperforms the state-of-the-art methods by a large margin.
Graph-based Spatial Transformer with Memory Replay for Multi-future Pedestrian Trajectory Prediction
Jun 12, 2022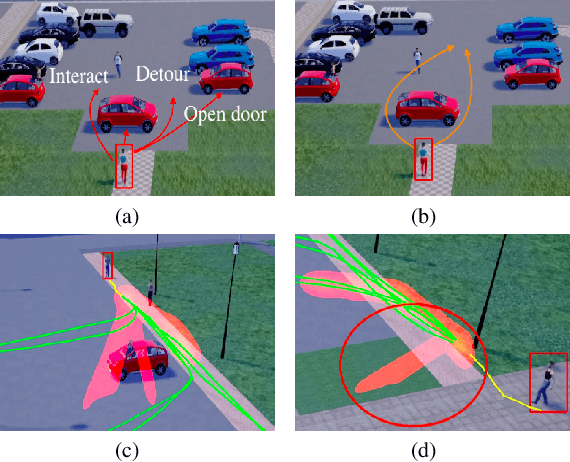
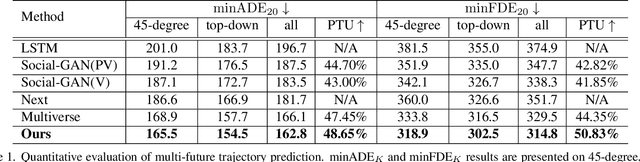
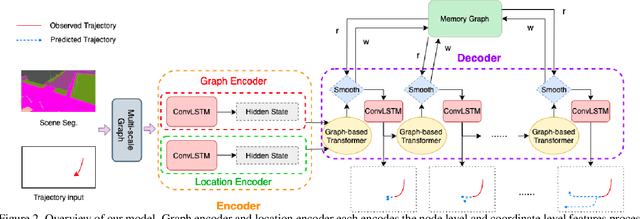
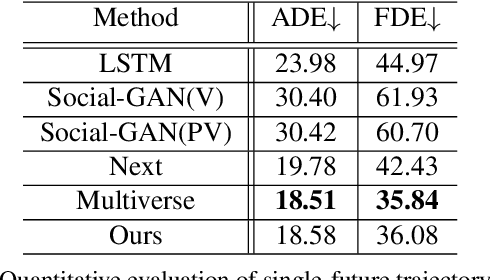
Pedestrian trajectory prediction is an essential and challenging task for a variety of real-life applications such as autonomous driving and robotic motion planning. Besides generating a single future path, predicting multiple plausible future paths is becoming popular in some recent work on trajectory prediction. However, existing methods typically emphasize spatial interactions between pedestrians and surrounding areas but ignore the smoothness and temporal consistency of predictions. Our model aims to forecast multiple paths based on a historical trajectory by modeling multi-scale graph-based spatial transformers combined with a trajectory smoothing algorithm named ``Memory Replay'' utilizing a memory graph. Our method can comprehensively exploit the spatial information as well as correct the temporally inconsistent trajectories (e.g., sharp turns). We also propose a new evaluation metric named ``Percentage of Trajectory Usage'' to evaluate the comprehensiveness of diverse multi-future predictions. Our extensive experiments show that the proposed model achieves state-of-the-art performance on multi-future prediction and competitive results for single-future prediction. Code released at https://github.com/Jacobieee/ST-MR.
LFPS-Net: a lightweight fast pulse simulation network for BVP estimation
Jun 25, 2022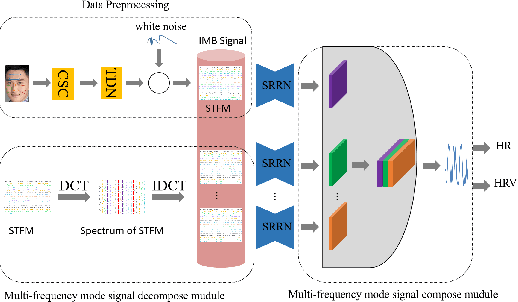
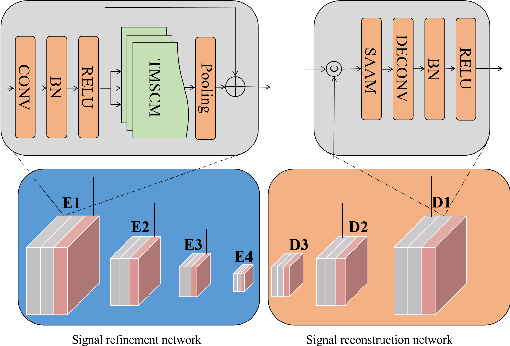

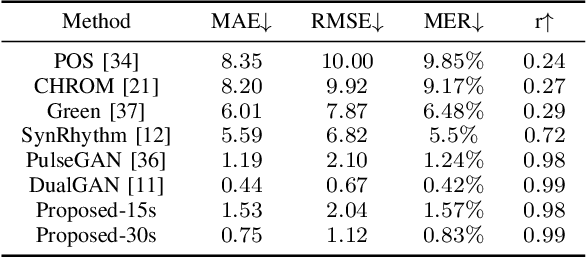
Heart rate estimation based on remote photoplethysmography plays an important role in several specific scenarios, such as health monitoring and fatigue detection. Existing well-established methods are committed to taking the average of the predicted HRs of multiple overlapping video clips as the final results for the 30-second facial video. Although these methods with hundreds of layers and thousands of channels are highly accurate and robust, they require enormous computational budget and a 30-second wait time, which greatly limits the application of the algorithms to scale. Under these cicumstacnces, We propose a lightweight fast pulse simulation network (LFPS-Net), pursuing the best accuracy within a very limited computational and time budget, focusing on common mobile platforms, such as smart phones. In order to suppress the noise component and get stable pulse in a short time, we design a multi-frequency modal signal fusion mechanism, which exploits the theory of time-frequency domain analysis to separate multi-modal information from complex signals. It helps proceeding network learn the effective fetures more easily without adding any parameter. In addition, we design a oversampling training strategy to solve the problem caused by the unbalanced distribution of dataset. For the 30-second facial videos, our proposed method achieves the best results on most of the evaluation metrics for estimating heart rate or heart rate variability compared to the best available papers. The proposed method can still obtain very competitive results by using a short-time (~15-second) facail video.
Using depth information and colour space variations for improving outdoor robustness for instance segmentation of cabbage
Mar 31, 2021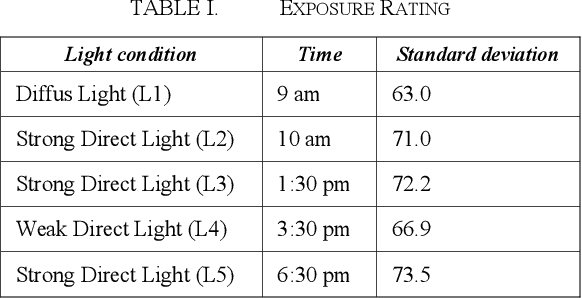
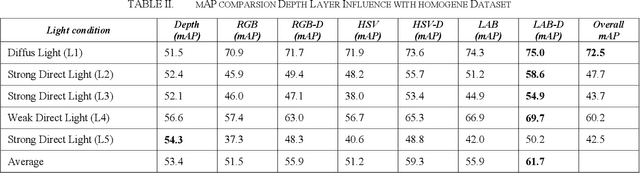
Image-based yield detection in agriculture could raiseharvest efficiency and cultivation performance of farms. Following this goal, this research focuses on improving instance segmentation of field crops under varying environmental conditions. Five data sets of cabbage plants were recorded under varying lighting outdoor conditions. The images were acquired using a commercial mono camera. Additionally, depth information was generated out of the image stream with Structure-from-Motion (SfM). A Mask R-CNN was used to detect and segment the cabbage heads. The influence of depth information and different colour space representations were analysed. The results showed that depth combined with colour information leads to a segmentation accuracy increase of 7.1%. By describing colour information by colour spaces using light and saturation information combined with depth information, additional segmentation improvements of 16.5% could be reached. The CIELAB colour space combined with a depth information layer showed the best results achieving a mean average precision of 75.
GOF-TTE: Generative Online Federated Learning Framework for Travel Time Estimation
Jul 02, 2022
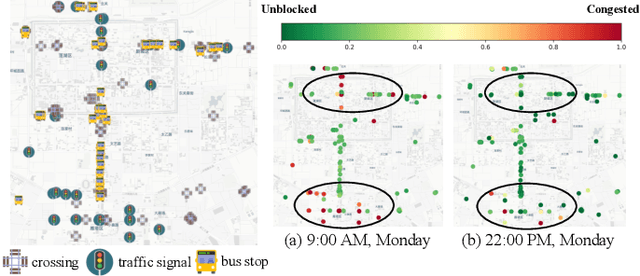
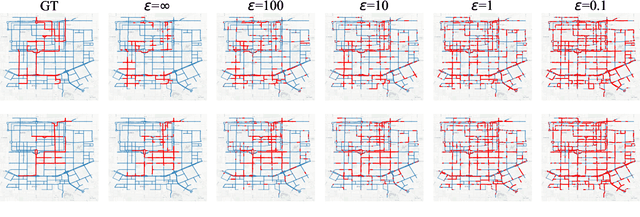
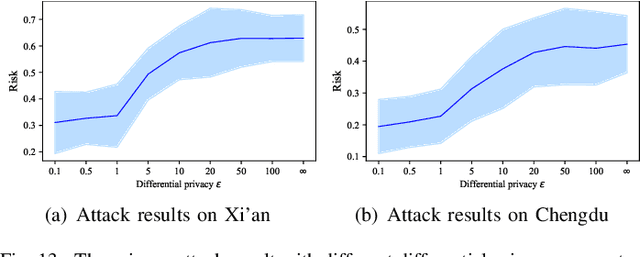
Estimating the travel time of a path is an essential topic for intelligent transportation systems. It serves as the foundation for real-world applications, such as traffic monitoring, route planning, and taxi dispatching. However, building a model for such a data-driven task requires a large amount of users' travel information, which directly relates to their privacy and thus is less likely to be shared. The non-Independent and Identically Distributed (non-IID) trajectory data across data owners also make a predictive model extremely challenging to be personalized if we directly apply federated learning. Finally, previous work on travel time estimation does not consider the real-time traffic state of roads, which we argue can significantly influence the prediction. To address the above challenges, we introduce GOF-TTE for the mobile user group, Generative Online Federated Learning Framework for Travel Time Estimation, which I) utilizes the federated learning approach, allowing private data to be kept on client devices while training, and designs the global model as an online generative model shared by all clients to infer the real-time road traffic state. II) apart from sharing a base model at the server, adapts a fine-tuned personalized model for every client to study their personal driving habits, making up for the residual error made by localized global model prediction. % III) designs the global model as an online generative model shared by all clients to infer the real-time road traffic state. We also employ a simple privacy attack to our framework and implement the differential privacy mechanism to further guarantee privacy safety. Finally, we conduct experiments on two real-world public taxi datasets of DiDi Chengdu and Xi'an. The experimental results demonstrate the effectiveness of our proposed framework.
Quantifying Language Variation Acoustically with Few Resources
May 05, 2022
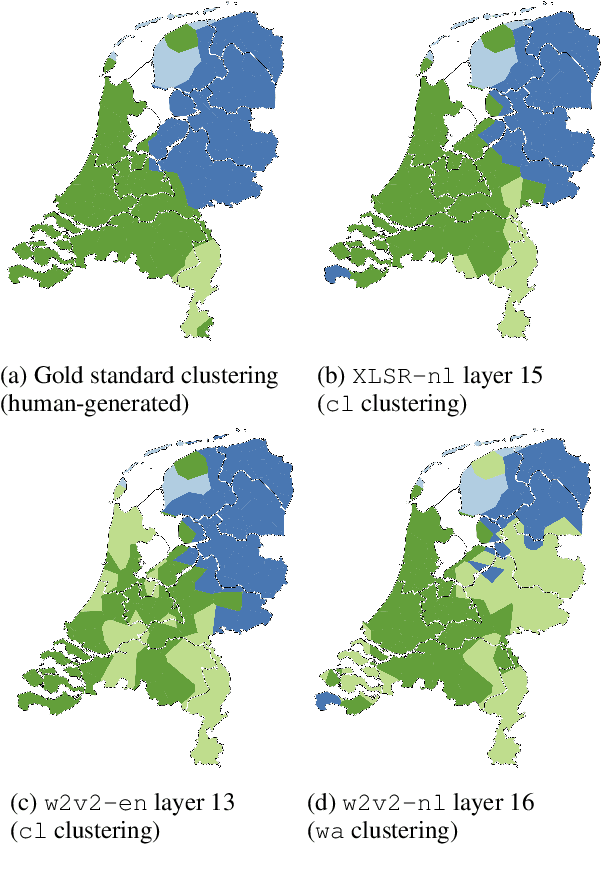
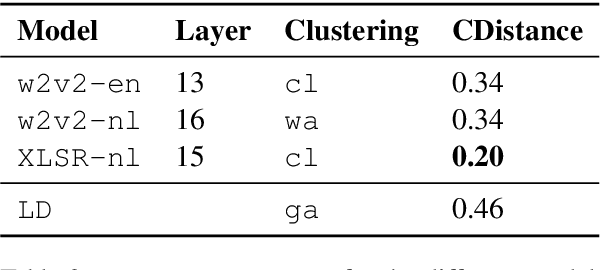
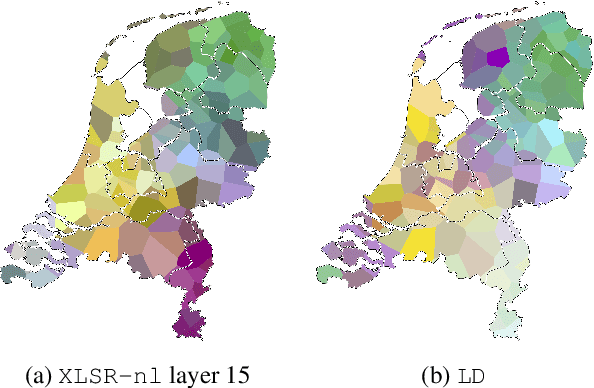
Deep acoustic models represent linguistic information based on massive amounts of data. Unfortunately, for regional languages and dialects such resources are mostly not available. However, deep acoustic models might have learned linguistic information that transfers to low-resource languages. In this study, we evaluate whether this is the case through the task of distinguishing low-resource (Dutch) regional varieties. By extracting embeddings from the hidden layers of various wav2vec 2.0 models (including new models which are pre-trained and/or fine-tuned on Dutch) and using dynamic time warping, we compute pairwise pronunciation differences averaged over 10 words for over 100 individual dialects from four (regional) languages. We then cluster the resulting difference matrix in four groups and compare these to a gold standard, and a partitioning on the basis of comparing phonetic transcriptions. Our results show that acoustic models outperform the (traditional) transcription-based approach without requiring phonetic transcriptions, with the best performance achieved by the multilingual XLSR-53 model fine-tuned on Dutch. On the basis of only six seconds of speech, the resulting clustering closely matches the gold standard.
Predictive Rate Selection for Ultra-Reliable Communication using Statistical Radio Maps
May 30, 2022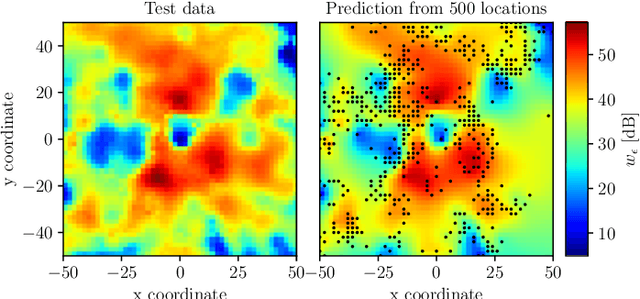
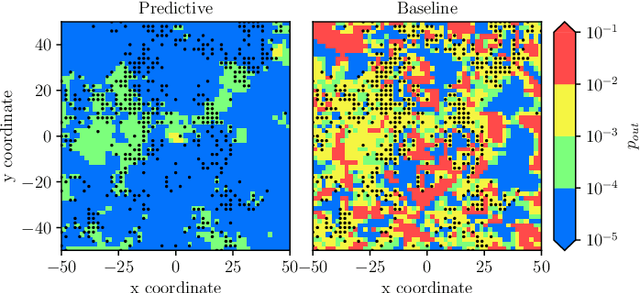
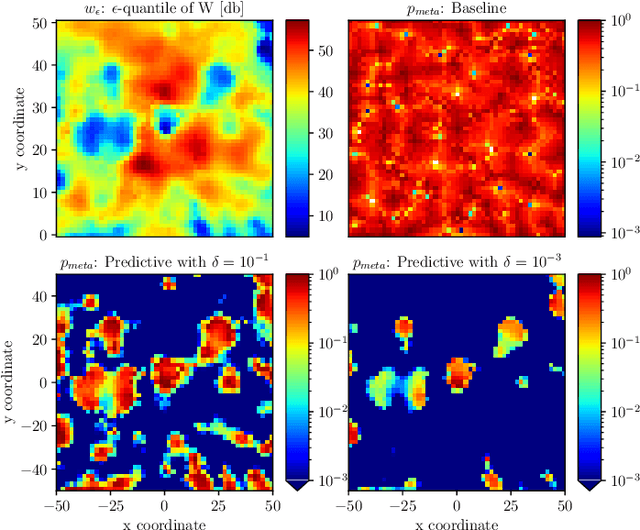
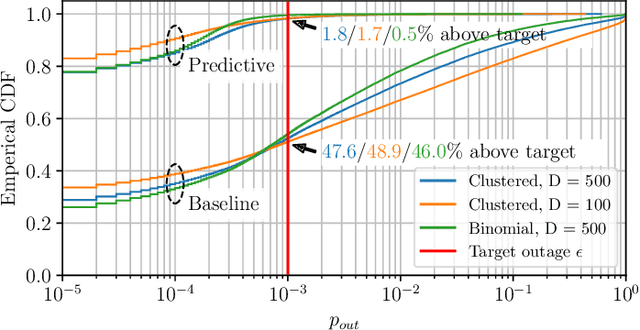
This paper proposes exploiting the spatial correlation of wireless channel statistics beyond the conventional received signal strength maps by constructing statistical radio maps to predict any relevant channel statistics to assist communications. Specifically, from stored channel samples acquired by previous users in the network, we use Gaussian processes (GPs) to estimate quantiles of the channel distribution at a new position using a non-parametric model. This prior information is then used to select the transmission rate for some target level of reliability. The approach is tested with synthetic data, simulated from urban micro-cell environments, highlighting how the proposed solution helps to reduce the training estimation phase, which is especially attractive for the tight latency constraints inherent to ultra-reliable low-latency (URLLC) deployments.