 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A deep cascade of ensemble of dual domain networks with gradient-based T1 assistance and perceptual refinement for fast MRI reconstruction
Jul 05, 2022

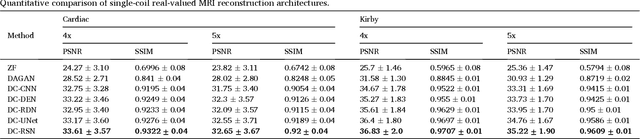
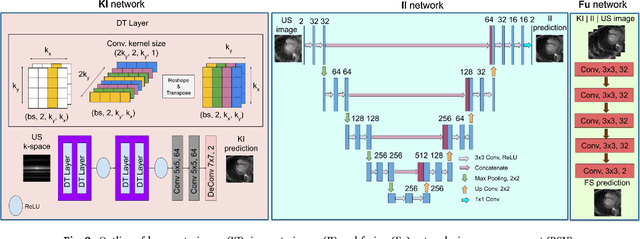
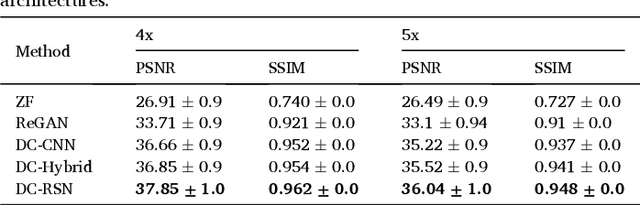
Deep learning networks have shown promising results in fast magnetic resonance imaging (MRI) reconstruction. In our work, we develop deep networks to further improve the quantitative and the perceptual quality of reconstruction. To begin with, we propose reconsynergynet (RSN), a network that combines the complementary benefits of independently operating on both the image and the Fourier domain. For a single-coil acquisition, we introduce deep cascade RSN (DC-RSN), a cascade of RSN blocks interleaved with data fidelity (DF) units. Secondly, we improve the structure recovery of DC-RSN for T2 weighted Imaging (T2WI) through assistance of T1 weighted imaging (T1WI), a sequence with short acquisition time. T1 assistance is provided to DC-RSN through a gradient of log feature (GOLF) fusion. Furthermore, we propose perceptual refinement network (PRN) to refine the reconstructions for better visual information fidelity (VIF), a metric highly correlated to radiologists opinion on the image quality. Lastly, for multi-coil acquisition, we propose variable splitting RSN (VS-RSN), a deep cascade of blocks, each block containing RSN, multi-coil DF unit, and a weighted average module. We extensively validate our models DC-RSN and VS-RSN for single-coil and multi-coil acquisitions and report the state-of-the-art performance. We obtain a SSIM of 0.768, 0.923, 0.878 for knee single-coil-4x, multi-coil-4x, and multi-coil-8x in fastMRI. We also conduct experiments to demonstrate the efficacy of GOLF based T1 assistance and PRN.
How Powerful are K-hop Message Passing Graph Neural Networks
May 26, 2022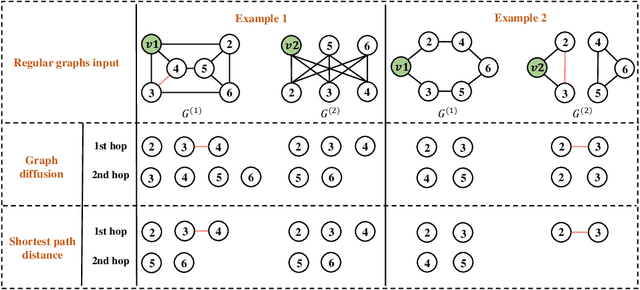
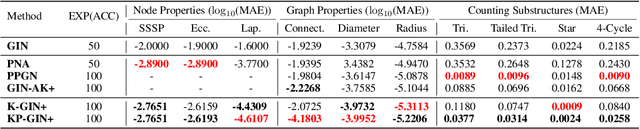
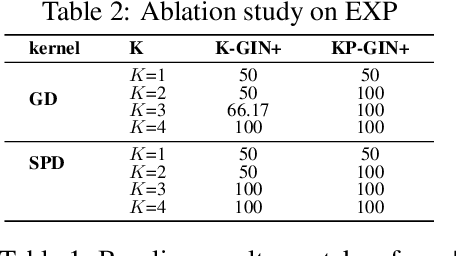
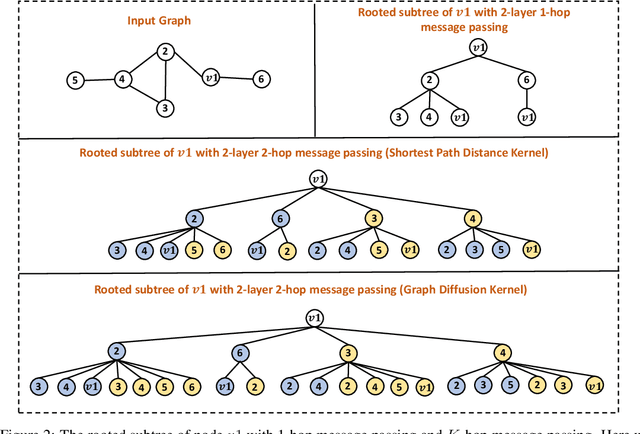
The most popular design paradigm for Graph Neural Networks (GNNs) is 1-hop message passing -- aggregating features from 1-hop neighbors repeatedly. However, the expressive power of 1-hop message passing is bounded by the Weisfeiler-Lehman (1-WL) test. Recently, researchers extended 1-hop message passing to K-hop message passing by aggregating information from K-hop neighbors of nodes simultaneously. However, there is no work on analyzing the expressive power of K-hop message passing. In this work, we theoretically characterize the expressive power of K-hop message passing. Specifically, we first formally differentiate two kinds of kernels of K-hop message passing which are often misused in previous works. We then characterize the expressive power of K-hop message passing by showing that it is more powerful than 1-hop message passing. Despite the higher expressive power, we show that K-hop message passing still cannot distinguish some simple regular graphs. To further enhance its expressive power, we introduce a KP-GNN framework, which improves K-hop message passing by leveraging the peripheral subgraph information in each hop. We prove that KP-GNN can distinguish almost all regular graphs including some distance regular graphs which could not be distinguished by previous distance encoding methods. Experimental results verify the expressive power and effectiveness of KP-GNN. KP-GNN achieves competitive results across all benchmark datasets.
Single Morphing Attack Detection using Siamese Network and Few-shot Learning
Jun 22, 2022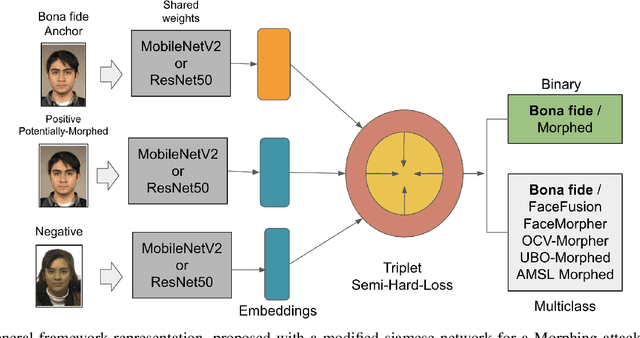


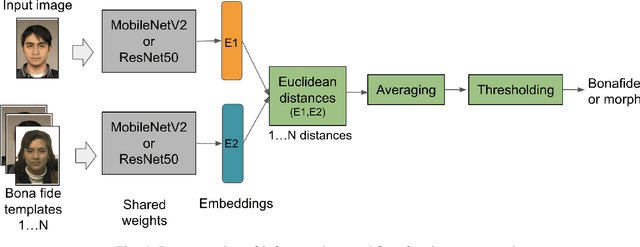
Face morphing attack detection is challenging and presents a concrete and severe threat for face verification systems. Reliable detection mechanisms for such attacks, which have been tested with a robust cross-database protocol and unknown morphing tools still is a research challenge. This paper proposes a framework following the Few-Shot-Learning approach that shares image information based on the siamese network using triplet-semi-hard-loss to tackle the morphing attack detection and boost the clustering classification process. This network compares a bona fide or potentially morphed image with triplets of morphing and bona fide face images. Our results show that this new network cluster the data points, and assigns them to classes in order to obtain a lower equal error rate in a cross-database scenario sharing only small image numbers from an unknown database. Few-shot learning helps to boost the learning process. Experimental results using a cross-datasets trained with FRGCv2 and tested with FERET and the AMSL open-access databases reduced the BPCER10 from 43% to 4.91% using ResNet50 and 5.50% for MobileNetV2.
VIDI: A Video Dataset of Incidents
May 26, 2022
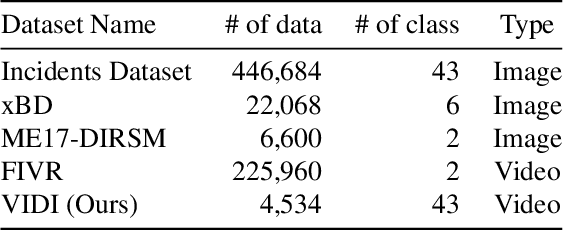
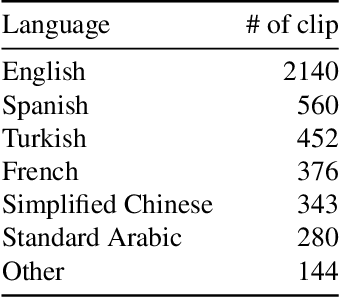
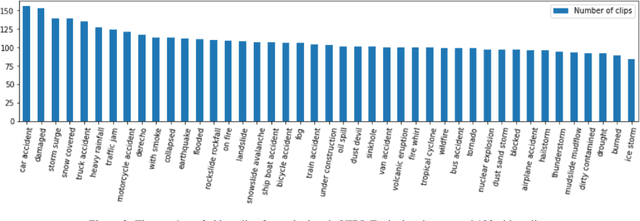
Automatic detection of natural disasters and incidents has become more important as a tool for fast response. There have been many studies to detect incidents using still images and text. However, the number of approaches that exploit temporal information is rather limited. One of the main reasons for this is that a diverse video dataset with various incident types does not exist. To address this need, in this paper we present a video dataset, Video Dataset of Incidents, VIDI, that contains 4,534 video clips corresponding to 43 incident categories. Each incident class has around 100 videos with a duration of ten seconds on average. To increase diversity, the videos have been searched in several languages. To assess the performance of the recent state-of-the-art approaches, Vision Transformer and TimeSformer, as well as to explore the contribution of video-based information for incident classification, we performed benchmark experiments on the VIDI and Incidents Dataset. We have shown that the recent methods improve the incident classification accuracy. We have found that employing video data is very beneficial for the task. By using the video data, the top-1 accuracy is increased to 76.56% from 67.37%, which was obtained using a single frame. VIDI will be made publicly available. Additional materials can be found at the following link: https://github.com/vididataset/VIDI.
Overcoming Language Disparity in Online Content Classification with Multimodal Learning
May 19, 2022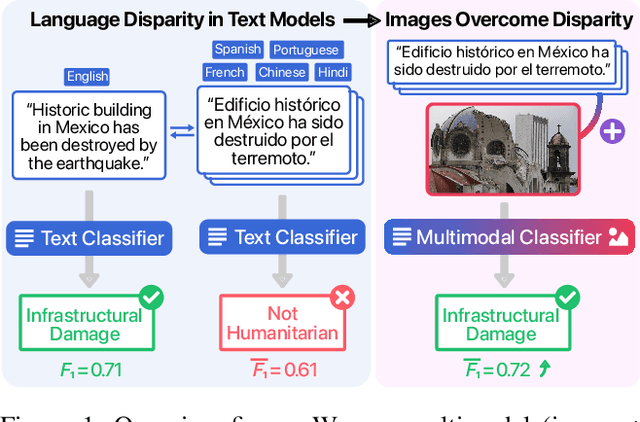
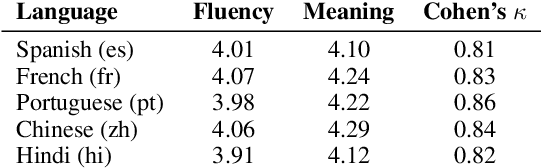

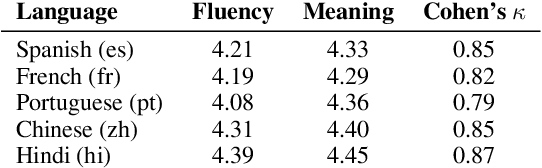
Advances in Natural Language Processing (NLP) have revolutionized the way researchers and practitioners address crucial societal problems. Large language models are now the standard to develop state-of-the-art solutions for text detection and classification tasks. However, the development of advanced computational techniques and resources is disproportionately focused on the English language, sidelining a majority of the languages spoken globally. While existing research has developed better multilingual and monolingual language models to bridge this language disparity between English and non-English languages, we explore the promise of incorporating the information contained in images via multimodal machine learning. Our comparative analyses on three detection tasks focusing on crisis information, fake news, and emotion recognition, as well as five high-resource non-English languages, demonstrate that: (a) detection frameworks based on pre-trained large language models like BERT and multilingual-BERT systematically perform better on the English language compared against non-English languages, and (b) including images via multimodal learning bridges this performance gap. We situate our findings with respect to existing work on the pitfalls of large language models, and discuss their theoretical and practical implications. Resources for this paper are available at https://multimodality-language-disparity.github.io/.
Evaluation of the Effects of Compressive Spectrum Sensing Parameters on Primary User Behavior Estimation
May 19, 2022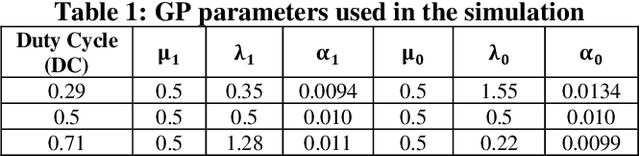
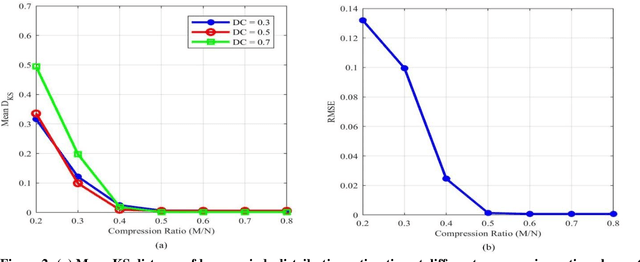
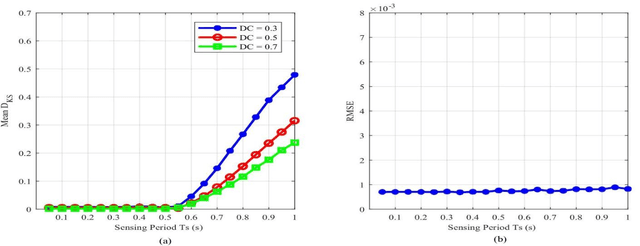
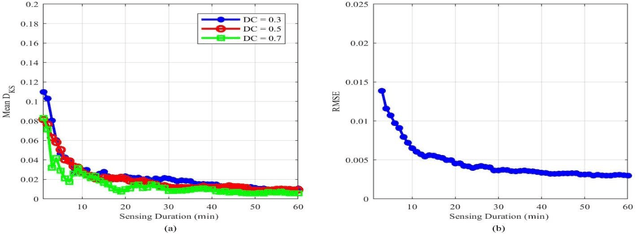
As the Internet of Things (IoT) technology is being deployed, the demand for radio spectrum is increasing. Cognitive radio (CR) is one of the most promising solutions to allow opportunistic spectrum access for IoT secondary users through utilizing spectrum holes resulting from the underutilization of frequency spectrum. A CR needs to frequently sense the spectrum to avoid interference with primary users (PUs). Compressive spectrum sensing techniques have been gaining increasing interest in wideband spectrum sensing, as they reduce the need for high-rate analog-to-digital converters, reducing the complexity and energy requirements of the CR. In order to enhance spectrum sensing performance, researchers proposed to incorporate PU spectrum usage information into the process of spectrum sensing. Spectrum usage information can be obtained through pilot signals, geo-locational databases or through evaluation of previous spectrum sensing results. In this paper, we are studying the effects of compressive sensing parameters namely compression ratio, sensing period, and sensing duration on the estimation of primary user behavior statistics. We achieved an accurate estimation of the primary user's behavior while saving 40% of the sampling rate by using compressive spectrum sensing compared to traditional spectrum sensing with Nyquist rate sampling.
k-strip: A novel segmentation algorithm in k-space for the application of skull stripping
May 19, 2022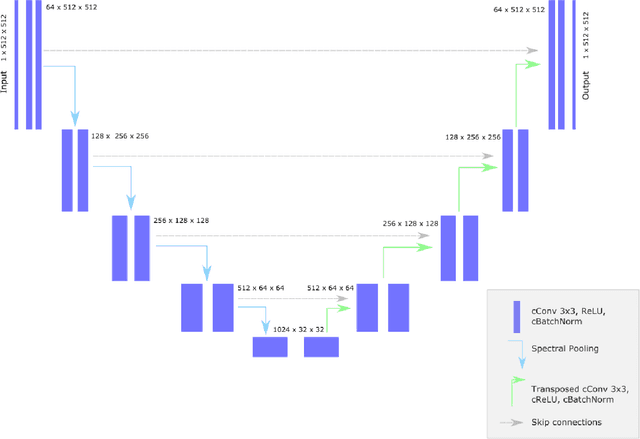
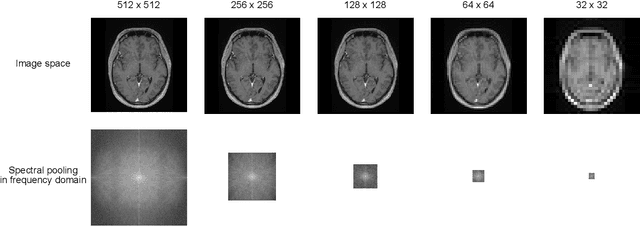
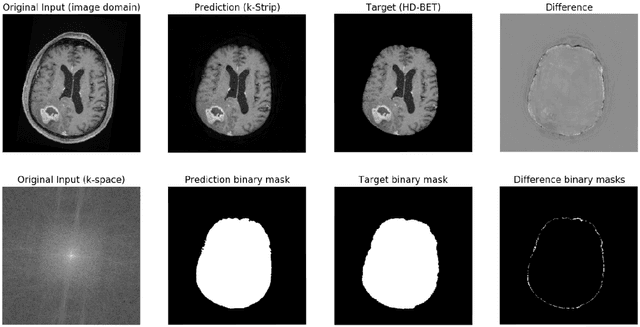
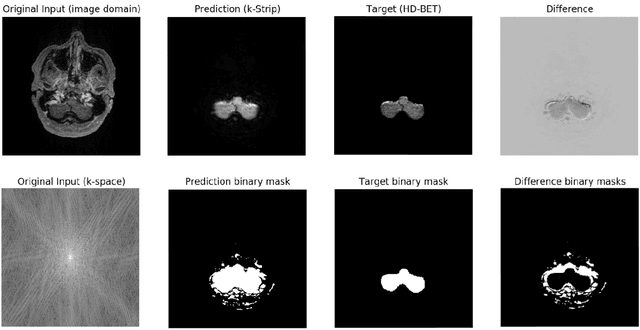
Objectives: Present a novel deep learning-based skull stripping algorithm for magnetic resonance imaging (MRI) that works directly in the information rich k-space. Materials and Methods: Using two datasets from different institutions with a total of 36,900 MRI slices, we trained a deep learning-based model to work directly with the complex raw k-space data. Skull stripping performed by HD-BET (Brain Extraction Tool) in the image domain were used as the ground truth. Results: Both datasets were very similar to the ground truth (DICE scores of 92\%-98\% and Hausdorff distances of under 5.5 mm). Results on slices above the eye-region reach DICE scores of up to 99\%, while the accuracy drops in regions around the eyes and below, with partially blurred output. The output of k-strip often smoothed edges at the demarcation to the skull. Binary masks are created with an appropriate threshold. Conclusion: With this proof-of-concept study, we were able to show the feasibility of working in the k-space frequency domain, preserving phase information, with consistent results. Future research should be dedicated to discovering additional ways the k-space can be used for innovative image analysis and further workflows.
Modelling and Mining of Patient Pathways: A Scoping Review
Jun 04, 2022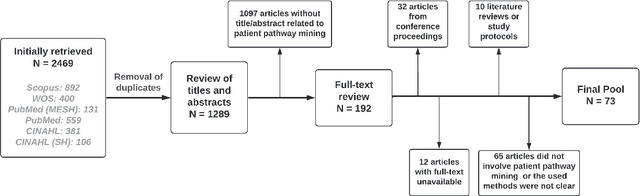

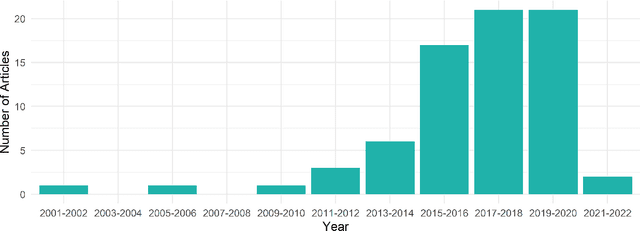
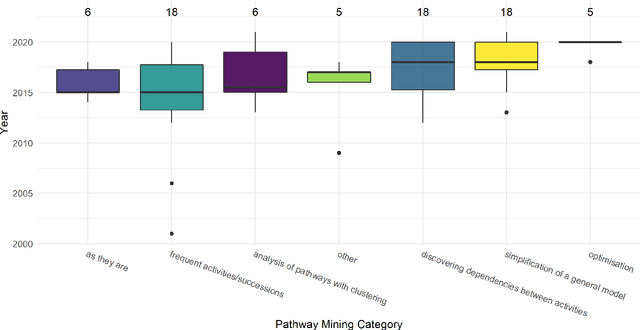
The sequence of visits and procedures performed by the patient in the health system, also known as the patient's pathway or trajectory, can reveal important information about the clinical treatment adopted and the health service provided. The rise of electronic health data availability made it possible to assess the pathways of a large number of patients. Nevertheless, some challenges also arose concerning how to synthesize these pathways and how to mine them from the data, fostering a new field of research. The objective of this review is to survey this new field of research, highlighting representation models, mining techniques, methods of analysis, and examples of case studies.
BFS-Net: Weakly Supervised Cell Instance Segmentation from Bright-Field Microscopy Z-Stacks
Jun 09, 2022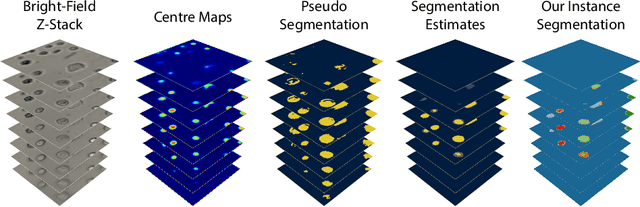
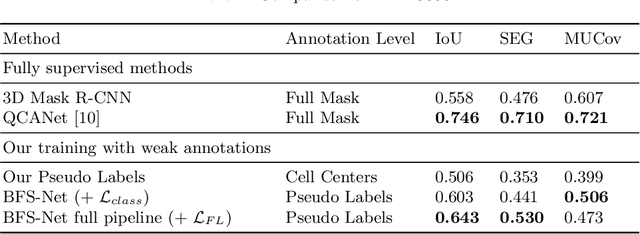
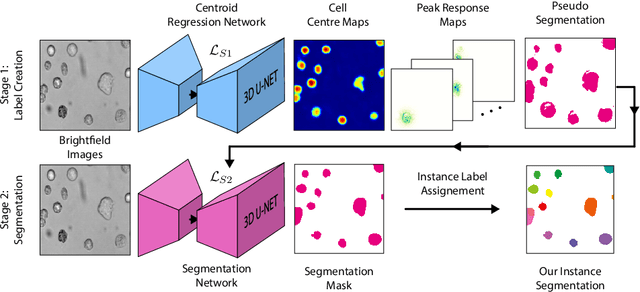

Despite its broad availability, volumetric information acquisition from Bright-Field Microscopy (BFM) is inherently difficult due to the projective nature of the acquisition process. We investigate the prediction of 3D cell instances from a set of BFM Z-Stack images. We propose a novel two-stage weakly supervised method for volumetric instance segmentation of cells which only requires approximate cell centroids annotation. Created pseudo-labels are thereby refined with a novel refinement loss with Z-stack guidance. The evaluations show that our approach can generalize not only to BFM Z-Stack data, but to other 3D cell imaging modalities. A comparison of our pipeline against fully supervised methods indicates that the significant gain in reduced data collection and labelling results in minor performance difference.
Optical character recognition quality affects perceived usefulness of historical newspaper clippings
Jun 01, 2022

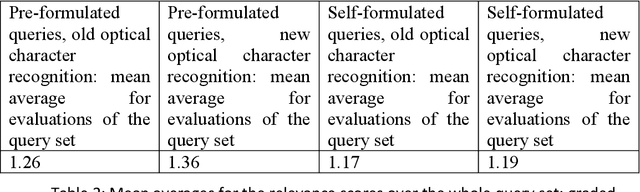
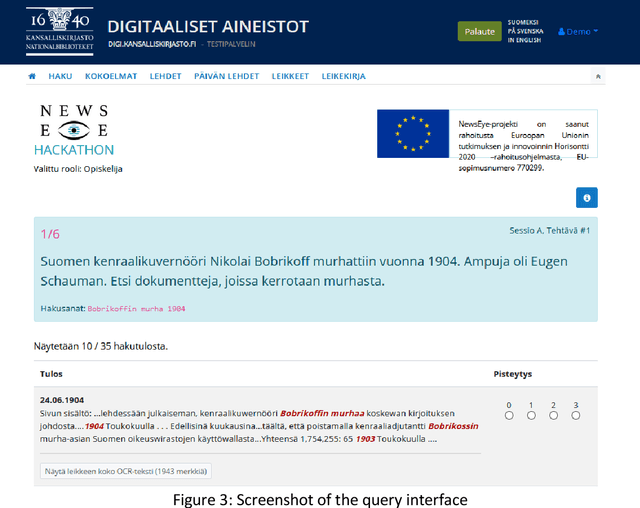
Introduction. We study effect of different quality optical character recognition in interactive information retrieval with a collection of one digitized historical Finnish newspaper. Method. This study is based on the simulated interactive information retrieval work task model. Thirty-two users made searches to an article collection of Finnish newspaper Uusi Suometar 1869-1918 with ca. 1.45 million auto segmented articles. Our article search database had two versions of each article with different quality optical character recognition. Each user performed six pre-formulated and six self-formulated short queries and evaluated subjectively the top-10 results using graded relevance scale of 0-3 without knowing about the optical character recognition quality differences of the otherwise identical articles. Analysis. Analysis of the user evaluations was performed by comparing mean averages of evaluations scores in user sessions. Differences of query results were detected by analysing lengths of returned articles in pre-formulated and self-formulated queries and number of different documents retrieved overall in these two sessions. Results. The main result of the study is that improved optical character recognition quality affects perceived usefulness of historical newspaper articles positively. Conclusions. We were able to show that improvement in optical character recognition quality of documents leads to higher mean relevance evaluation scores of query results in our historical newspaper collection. To the best of our knowledge this simulated interactive user-task is the first one showing empirically that users' subjective relevance assessments are affected by a change in the quality of optically read text.