 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Only Tails Matter: Average-Case Universality and Robustness in the Convex Regime
Jun 22, 2022
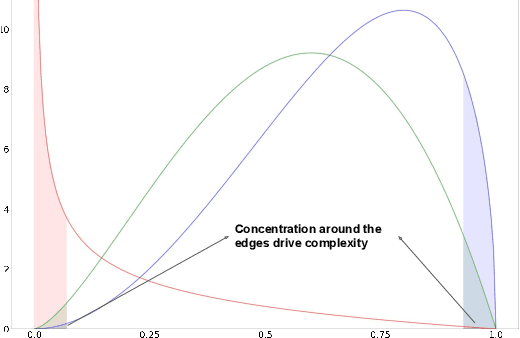

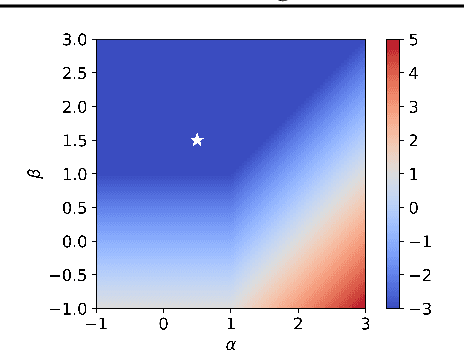

The recently developed average-case analysis of optimization methods allows a more fine-grained and representative convergence analysis than usual worst-case results. In exchange, this analysis requires a more precise hypothesis over the data generating process, namely assuming knowledge of the expected spectral distribution (ESD) of the random matrix associated with the problem. This work shows that the concentration of eigenvalues near the edges of the ESD determines a problem's asymptotic average complexity. This a priori information on this concentration is a more grounded assumption than complete knowledge of the ESD. This approximate concentration is effectively a middle ground between the coarseness of the worst-case scenario convergence and the restrictive previous average-case analysis. We also introduce the Generalized Chebyshev method, asymptotically optimal under a hypothesis on this concentration and globally optimal when the ESD follows a Beta distribution. We compare its performance to classical optimization algorithms, such as gradient descent or Nesterov's scheme, and we show that, in the average-case context, Nesterov's method is universally nearly optimal asymptotically.
Optimal Dynamic Regret in LQR Control
Jun 18, 2022


We consider the problem of nonstochastic control with a sequence of quadratic losses, i.e., LQR control. We provide an efficient online algorithm that achieves an optimal dynamic (policy) regret of $\tilde{O}(\text{max}\{n^{1/3} \mathcal{TV}(M_{1:n})^{2/3}, 1\})$, where $\mathcal{TV}(M_{1:n})$ is the total variation of any oracle sequence of Disturbance Action policies parameterized by $M_1,...,M_n$ -- chosen in hindsight to cater to unknown nonstationarity. The rate improves the best known rate of $\tilde{O}(\sqrt{n (\mathcal{TV}(M_{1:n})+1)} )$ for general convex losses and we prove that it is information-theoretically optimal for LQR. Main technical components include the reduction of LQR to online linear regression with delayed feedback due to Foster and Simchowitz (2020), as well as a new proper learning algorithm with an optimal $\tilde{O}(n^{1/3})$ dynamic regret on a family of ``minibatched'' quadratic losses, which could be of independent interest.
Mode hunting through active information
Nov 10, 2020
We propose a new method to find modes based on active information. We develop an algorithm that, when applied to the whole space, will say whether there are any modes present \textit{and} where they are; this algorithm will reduce the dimensionality without resorting to Principal Components; and more importantly, population-wise, will not detect modes when they are not present.
* 12 pages
Estimating $α$-Rank by Maximizing Information Gain
Jan 22, 2021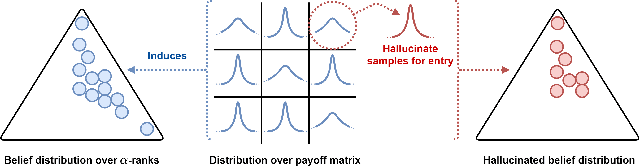
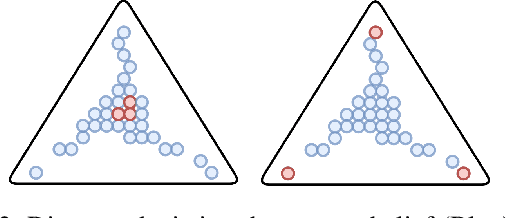
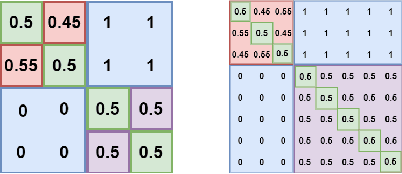
Game theory has been increasingly applied in settings where the game is not known outright, but has to be estimated by sampling. For example, meta-games that arise in multi-agent evaluation can only be accessed by running a succession of expensive experiments that may involve simultaneous deployment of several agents. In this paper, we focus on $\alpha$-rank, a popular game-theoretic solution concept designed to perform well in such scenarios. We aim to estimate the $\alpha$-rank of the game using as few samples as possible. Our algorithm maximizes information gain between an epistemic belief over the $\alpha$-ranks and the observed payoff. This approach has two main benefits. First, it allows us to focus our sampling on the entries that matter the most for identifying the $\alpha$-rank. Second, the Bayesian formulation provides a facility to build in modeling assumptions by using a prior over game payoffs. We show the benefits of using information gain as compared to the confidence interval criterion of ResponseGraphUCB (Rowland et al. 2019), and provide theoretical results justifying our method.
License Plate Privacy in Collaborative Visual Analysis of Traffic Scenes
May 03, 2022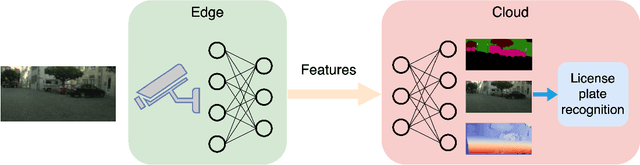
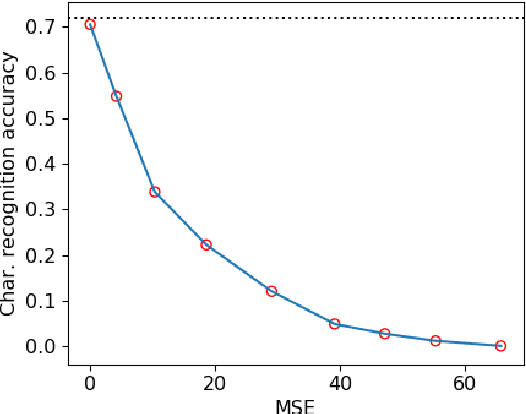
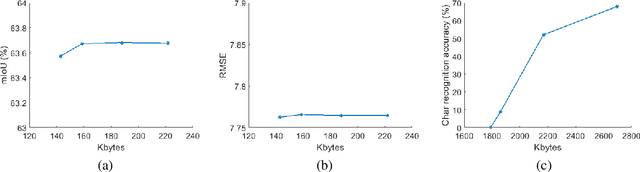

Traffic scene analysis is important for emerging technologies such as smart traffic management and autonomous vehicles. However, such analysis also poses potential privacy threats. For example, a system that can recognize license plates may construct patterns of behavior of the corresponding vehicles' owners and use that for various illegal purposes. In this paper we present a system that enables traffic scene analysis while at the same time preserving license plate privacy. The system is based on a multi-task model whose latent space is selectively compressed depending on the amount of information the specific features carry about analysis tasks and private information. Effectiveness of the proposed method is illustrated by experiments on the Cityscapes dataset, for which we also provide license plate annotations.
A deep cascade of ensemble of dual domain networks with gradient-based T1 assistance and perceptual refinement for fast MRI reconstruction
Jul 05, 2022
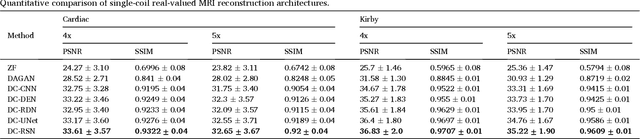
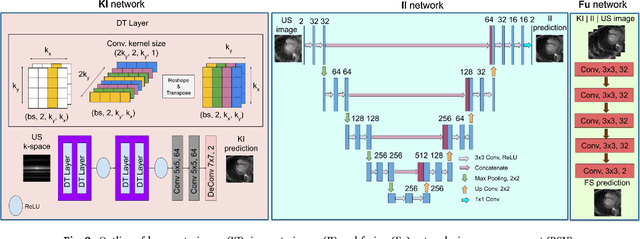
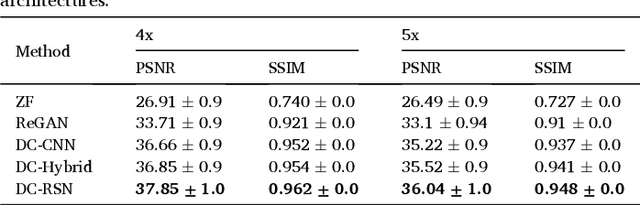
Deep learning networks have shown promising results in fast magnetic resonance imaging (MRI) reconstruction. In our work, we develop deep networks to further improve the quantitative and the perceptual quality of reconstruction. To begin with, we propose reconsynergynet (RSN), a network that combines the complementary benefits of independently operating on both the image and the Fourier domain. For a single-coil acquisition, we introduce deep cascade RSN (DC-RSN), a cascade of RSN blocks interleaved with data fidelity (DF) units. Secondly, we improve the structure recovery of DC-RSN for T2 weighted Imaging (T2WI) through assistance of T1 weighted imaging (T1WI), a sequence with short acquisition time. T1 assistance is provided to DC-RSN through a gradient of log feature (GOLF) fusion. Furthermore, we propose perceptual refinement network (PRN) to refine the reconstructions for better visual information fidelity (VIF), a metric highly correlated to radiologists opinion on the image quality. Lastly, for multi-coil acquisition, we propose variable splitting RSN (VS-RSN), a deep cascade of blocks, each block containing RSN, multi-coil DF unit, and a weighted average module. We extensively validate our models DC-RSN and VS-RSN for single-coil and multi-coil acquisitions and report the state-of-the-art performance. We obtain a SSIM of 0.768, 0.923, 0.878 for knee single-coil-4x, multi-coil-4x, and multi-coil-8x in fastMRI. We also conduct experiments to demonstrate the efficacy of GOLF based T1 assistance and PRN.
Auto-Encoding Adversarial Imitation Learning
Jun 22, 2022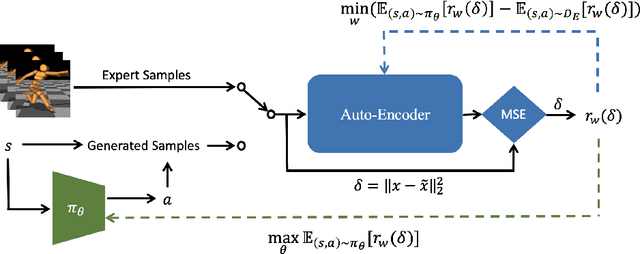
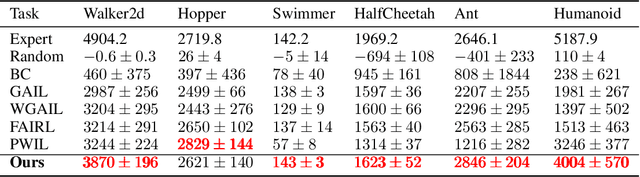
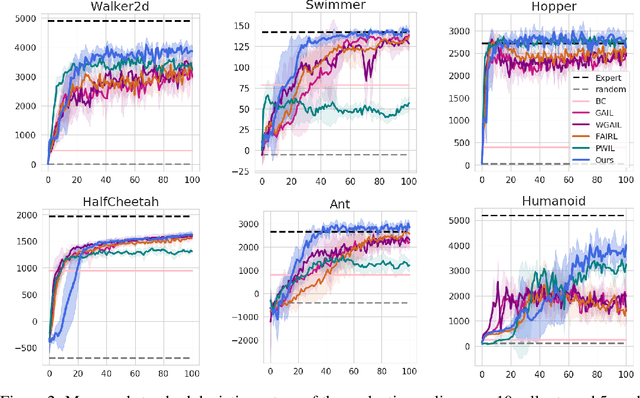

Reinforcement learning (RL) provides a powerful framework for decision-making, but its application in practice often requires a carefully designed reward function. Adversarial Imitation Learning (AIL) sheds light on automatic policy acquisition without access to the reward signal from the environment. In this work, we propose Auto-Encoding Adversarial Imitation Learning (AEAIL), a robust and scalable AIL framework. To induce expert policies from demonstrations, AEAIL utilizes the reconstruction error of an auto-encoder as a reward signal, which provides more information for optimizing policies than the prior discriminator-based ones. Subsequently, we use the derived objective functions to train the auto-encoder and the agent policy. Experiments show that our AEAIL performs superior compared to state-of-the-art methods in the MuJoCo environments. More importantly, AEAIL shows much better robustness when the expert demonstrations are noisy. Specifically, our method achieves $16.4\%$ and $47.2\%$ relative improvement overall compared to the best baseline FAIRL and PWIL on clean and noisy expert data, respectively. Video results, open-source code and dataset are available in https://sites.google.com/view/auto-encoding-imitation.
Adversarial Privacy Protection on Speech Enhancement
Jun 16, 2022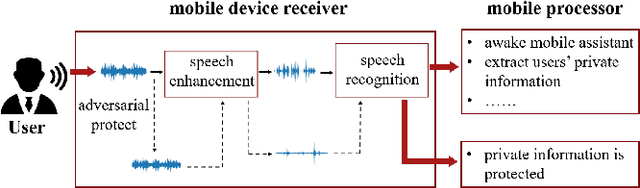

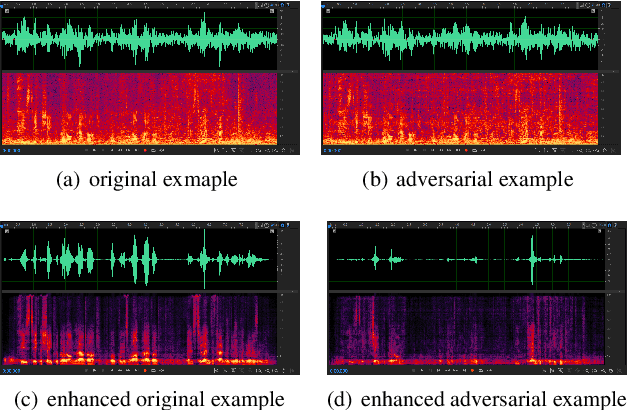

Speech is easily leaked imperceptibly, such as being recorded by mobile phones in different situations. Private content in speech may be maliciously extracted through speech enhancement technology. Speech enhancement technology has developed rapidly along with deep neural networks (DNNs), but adversarial examples can cause DNNs to fail. In this work, we propose an adversarial method to degrade speech enhancement systems. Experimental results show that generated adversarial examples can erase most content information in original examples or replace it with target speech content through speech enhancement. The word error rate (WER) between an enhanced original example and enhanced adversarial example recognition result can reach 89.0%. WER of target attack between enhanced adversarial example and target example is low to 33.75% . Adversarial perturbation can bring the rate of change to the original example to more than 1.4430. This work can prevent the malicious extraction of speech.
How Powerful are K-hop Message Passing Graph Neural Networks
May 26, 2022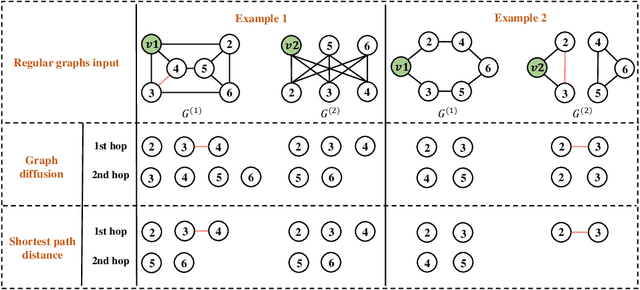
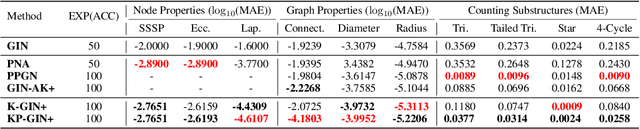
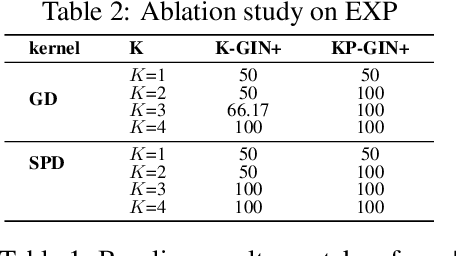
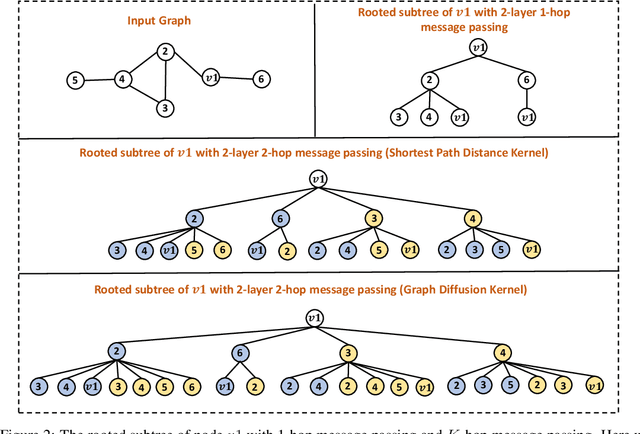
The most popular design paradigm for Graph Neural Networks (GNNs) is 1-hop message passing -- aggregating features from 1-hop neighbors repeatedly. However, the expressive power of 1-hop message passing is bounded by the Weisfeiler-Lehman (1-WL) test. Recently, researchers extended 1-hop message passing to K-hop message passing by aggregating information from K-hop neighbors of nodes simultaneously. However, there is no work on analyzing the expressive power of K-hop message passing. In this work, we theoretically characterize the expressive power of K-hop message passing. Specifically, we first formally differentiate two kinds of kernels of K-hop message passing which are often misused in previous works. We then characterize the expressive power of K-hop message passing by showing that it is more powerful than 1-hop message passing. Despite the higher expressive power, we show that K-hop message passing still cannot distinguish some simple regular graphs. To further enhance its expressive power, we introduce a KP-GNN framework, which improves K-hop message passing by leveraging the peripheral subgraph information in each hop. We prove that KP-GNN can distinguish almost all regular graphs including some distance regular graphs which could not be distinguished by previous distance encoding methods. Experimental results verify the expressive power and effectiveness of KP-GNN. KP-GNN achieves competitive results across all benchmark datasets.
Weakly-Supervised Action Detection Guided by Audio Narration
May 12, 2022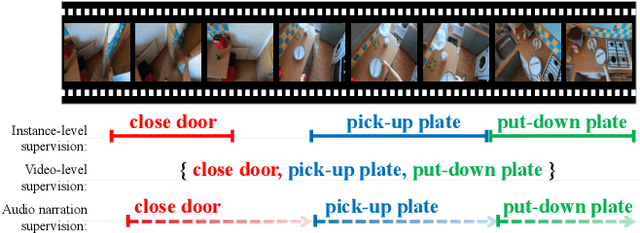
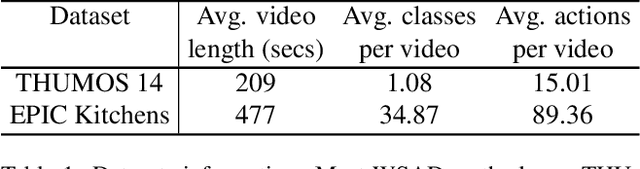
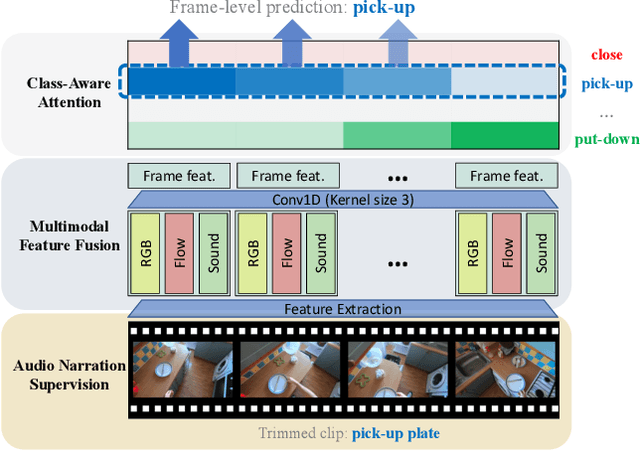

Videos are more well-organized curated data sources for visual concept learning than images. Unlike the 2-dimensional images which only involve the spatial information, the additional temporal dimension bridges and synchronizes multiple modalities. However, in most video detection benchmarks, these additional modalities are not fully utilized. For example, EPIC Kitchens is the largest dataset in first-person (egocentric) vision, yet it still relies on crowdsourced information to refine the action boundaries to provide instance-level action annotations. We explored how to eliminate the expensive annotations in video detection data which provide refined boundaries. We propose a model to learn from the narration supervision and utilize multimodal features, including RGB, motion flow, and ambient sound. Our model learns to attend to the frames related to the narration label while suppressing the irrelevant frames from being used. Our experiments show that noisy audio narration suffices to learn a good action detection model, thus reducing annotation expenses.