 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Extended U-Net for Speaker Verification in Noisy Environments
Jun 27, 2022




Background noise is a well-known factor that deteriorates the accuracy and reliability of speaker verification (SV) systems by blurring speech intelligibility. Various studies have used separate pretrained enhancement models as the front-end module of the SV system in noisy environments, and these methods effectively remove noises. However, the denoising process of independent enhancement models not tailored to the SV task can also distort the speaker information included in utterances. We argue that the enhancement network and speaker embedding extractor should be fully jointly trained for SV tasks under noisy conditions to alleviate this issue. Therefore, we proposed a U-Net-based integrated framework that simultaneously optimizes speaker identification and feature enhancement losses. Moreover, we analyzed the structural limitations of using U-Net directly for noise SV tasks and further proposed Extended U-Net to reduce these drawbacks. We evaluated the models on the noise-synthesized VoxCeleb1 test set and VOiCES development set recorded in various noisy scenarios. The experimental results demonstrate that the U-Net-based fully joint training framework is more effective than the baseline, and the extended U-Net exhibited state-of-the-art performance versus the recently proposed compensation systems.
Rate-Region Characterization and Channel Estimation for Cell-Free Symbiotic Radio Communications
May 17, 2022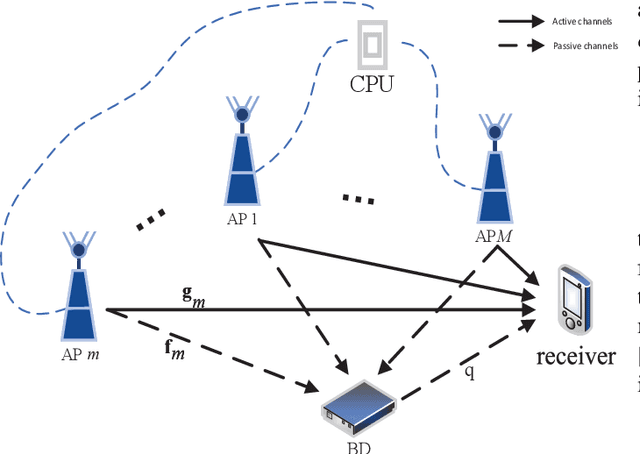
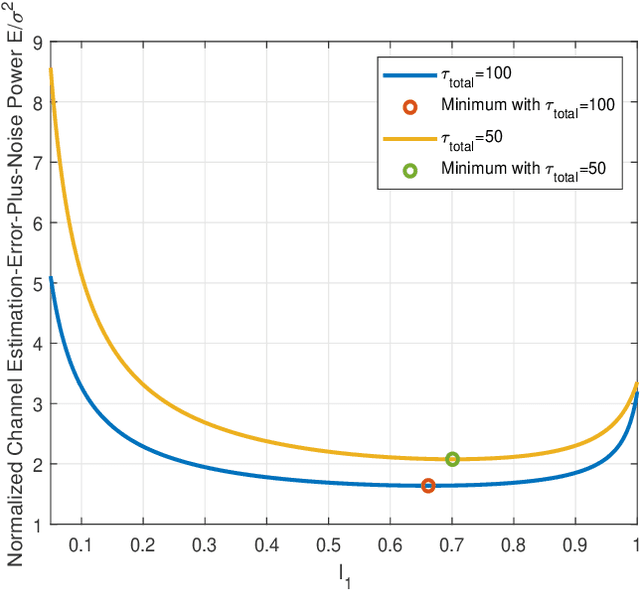
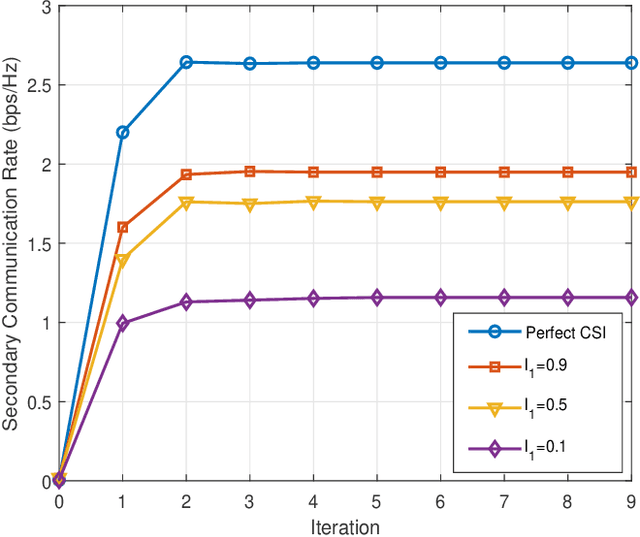
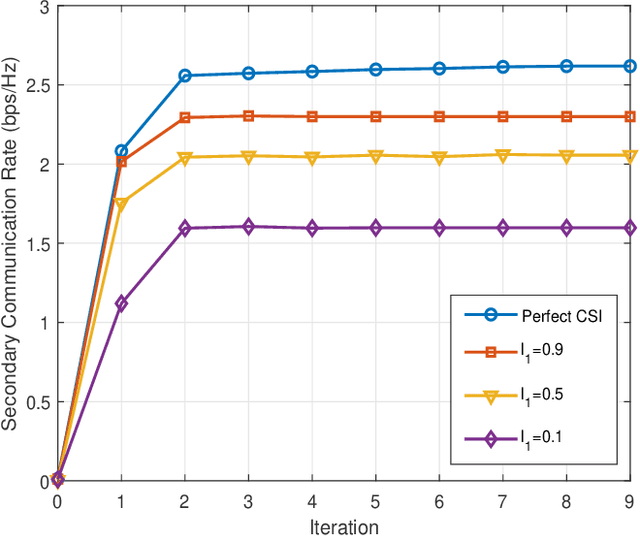
Cell-free massive MIMO and symbiotic radio communication have been recently proposed as the promising beyond fifth-generation (B5G) networking architecture and transmission technology, respectively. To reap the benefits of both, this paper studies cell-free symbiotic radio communication systems, where a number of cell-free access points (APs) cooperatively send primary information to a receiver, and simultaneously support the passive backscattering communication of the secondary backscatter device (BD). We first derive the achievable communication rates of the active primary user and passive secondary user under the assumption of perfect channel state information (CSI), based on which the transmit beamforming of the cellfree APs is optimized to characterize the achievable rate-region of cell-free symbiotic communication systems. Furthermore, to practically acquire the CSI of the active and passive channels, we propose an efficient channel estimation method based on two-phase uplink-training, and the achievable rate-region taking into account CSI estimation errors are further characterized. Simulation results are provided to show the effectiveness of our proposed beamforming and channel estimation methods.
Semi-Supervised Subspace Clustering via Tensor Low-Rank Representation
May 21, 2022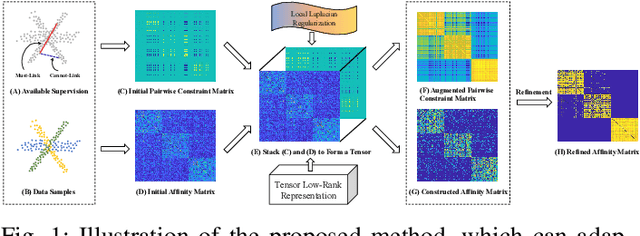
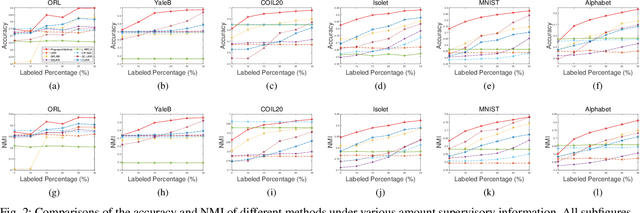
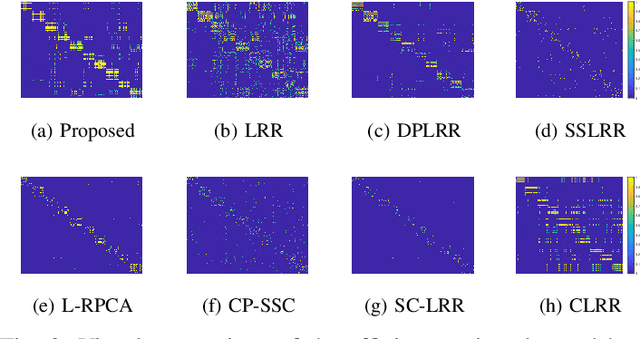
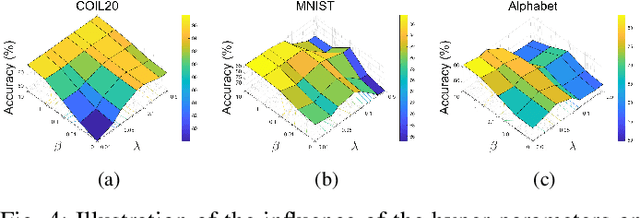
In this letter, we propose a novel semi-supervised subspace clustering method, which is able to simultaneously augment the initial supervisory information and construct a discriminative affinity matrix. By representing the limited amount of supervisory information as a pairwise constraint matrix, we observe that the ideal affinity matrix for clustering shares the same low-rank structure as the ideal pairwise constraint matrix. Thus, we stack the two matrices into a 3-D tensor, where a global low-rank constraint is imposed to promote the affinity matrix construction and augment the initial pairwise constraints synchronously. Besides, we use the local geometry structure of input samples to complement the global low-rank prior to achieve better affinity matrix learning. The proposed model is formulated as a Laplacian graph regularized convex low-rank tensor representation problem, which is further solved with an alternative iterative algorithm. In addition, we propose to refine the affinity matrix with the augmented pairwise constraints. Comprehensive experimental results on six commonly-used benchmark datasets demonstrate the superiority of our method over state-of-the-art methods. The code is publicly available at https://github.com/GuanxingLu/Subspace-Clustering.
Referring Expression Comprehension via Cross-Level Multi-Modal Fusion
Apr 21, 2022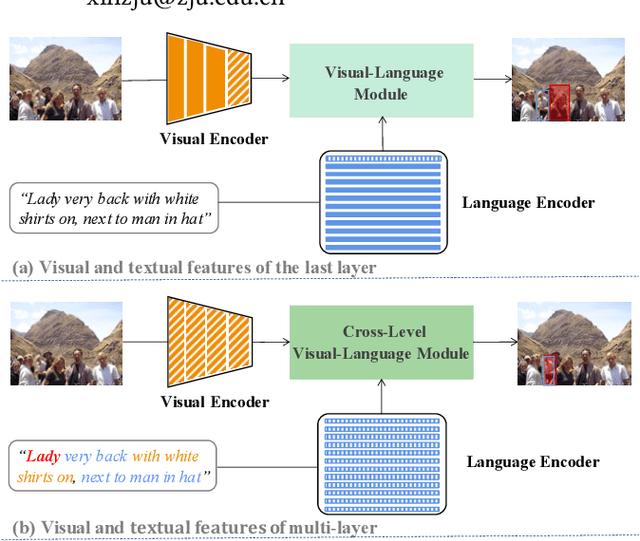
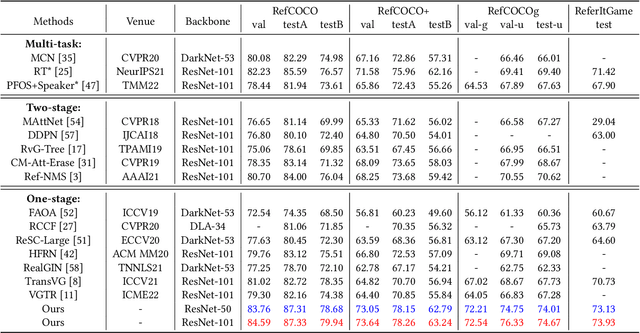
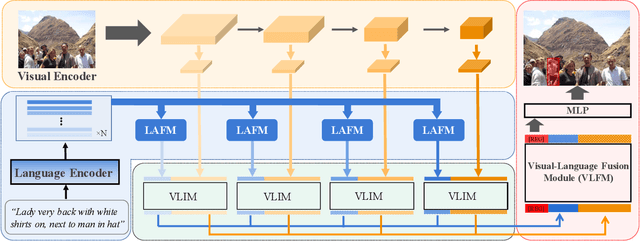

As an important and challenging problem in vision-language tasks, referring expression comprehension (REC) aims to localize the target object specified by a given referring expression. Recently, most of the state-of-the-art REC methods mainly focus on multi-modal fusion while overlooking the inherent hierarchical information contained in visual and language encoders. Considering that REC requires visual and textual hierarchical information for accurate target localization, and encoders inherently extract features in a hierarchical fashion, we propose to effectively utilize the rich hierarchical information contained in different layers of visual and language encoders. To this end, we design a Cross-level Multi-modal Fusion (CMF) framework, which gradually integrates visual and textual features of multi-layer through intra- and inter-modal. Experimental results on RefCOCO, RefCOCO+, RefCOCOg, and ReferItGame datasets demonstrate the proposed framework achieves significant performance improvements over state-of-the-art methods.
A Survey on the Fairness of Recommender Systems
Jun 19, 2022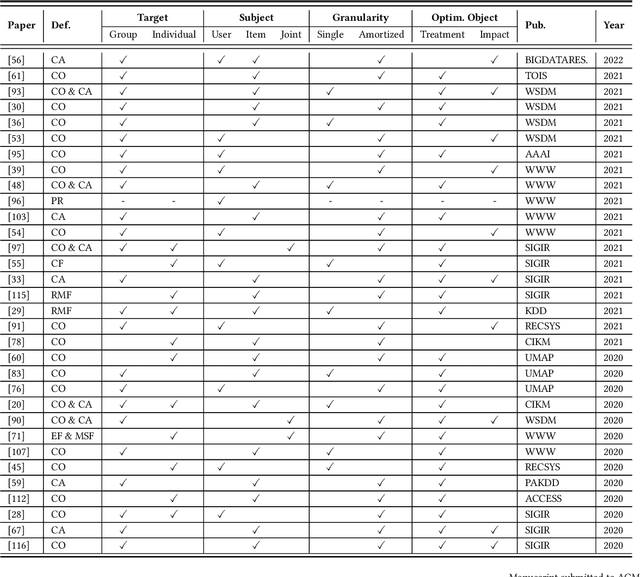
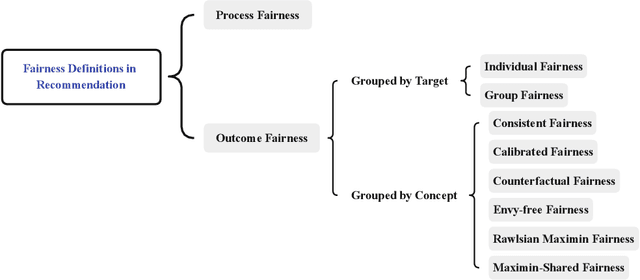
Recommender systems are an essential tool to relieve the information overload challenge and play an important role in people's daily lives. Since recommendations involve allocations of social resources (e.g., job recommendation), an important issue is whether recommendations are fair. Unfair recommendations are not only unethical but also harm the long-term interests of the recommender system itself. As a result, fairness issues in recommender systems have recently attracted increasing attention. However, due to multiple complex resource allocation processes and various fairness definitions, the research on fairness in recommendation is scattered. To fill this gap, we review over 60 papers published in top conferences/journals, including TOIS, SIGIR, and WWW. First, we summarize fairness definitions in the recommendation and provide several views to classify fairness issues. Then, we review recommendation datasets and measurements in fairness studies and provide an elaborate taxonomy of fairness methods in the recommendation. Finally, we conclude this survey by outlining some promising future directions.
Computable Artificial General Intelligence
May 31, 2022
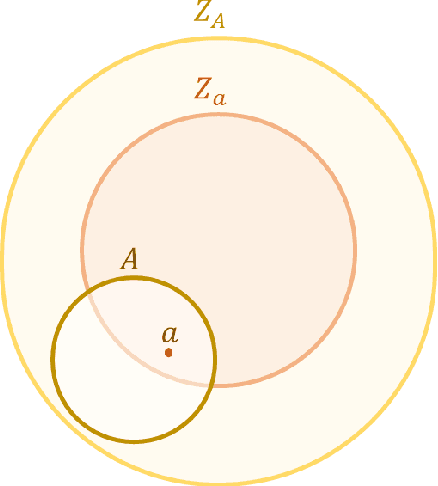
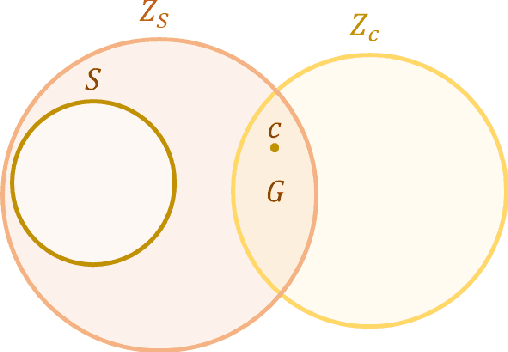
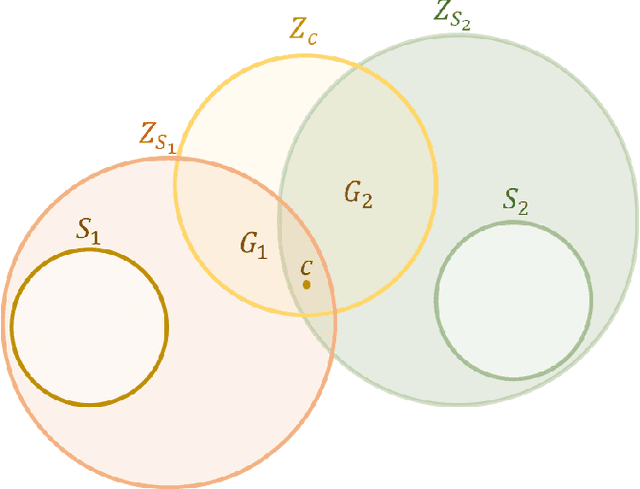
An artificial general intelligence (AGI), by one definition, is an agent that requires less information than any other to make an accurate prediction. It is arguable that the general reinforcement learning agent AIXI not only met this definition, but was the only mathematical formalism to do so. Though a significant result, AIXI was incomputable and its performance subjective. This paper proposes an alternative formalism of AGI which overcomes both problems. Formal proof of its performance is given, along with a simple implementation and experimental results that support these claims.
Downlink Massive MU-MIMO with Successively-Regularized Zero Forcing Precoding
Jun 17, 2022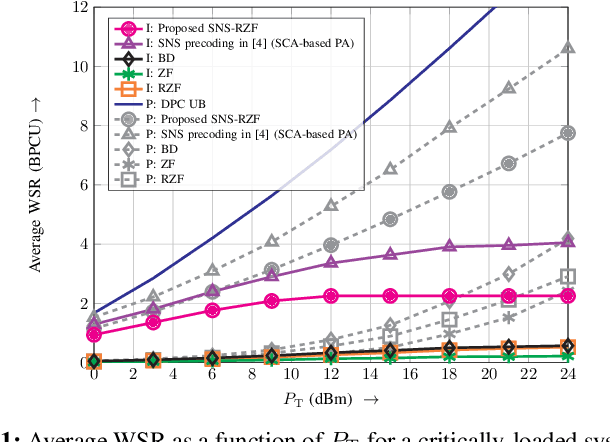
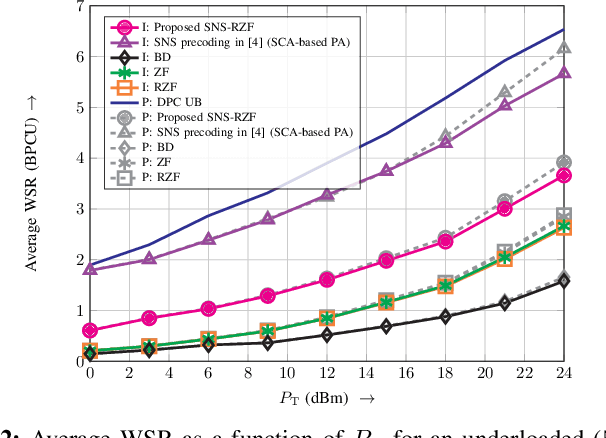
In this letter, we consider linear precoding for downlink massive multi-user (MU) multiple-input multiple-output (MIMO) systems. We propose the novel successively-regularized zero forcing (SRZF) precoding, which exploits successive null spaces of the MIMO channels of the users, along with regularization, to control the inter-user interference and to enhance performance and robustness to imperfect channel state information (CSI) at the base station (BS). We compare the weighted sum rate of the proposed SRZF precoding with those of block diagonalization and conventional and regularized zero forcing precoding for fixed and locally-optimal power allocation strategies as well as for perfect and imperfect CSI via computer simulations. Our simulation results reveal that for both underloaded and critically-loaded systems and perfect and imperfect CSI at the BS, the proposed SRZF precoding significantly outperforms the considered baseline schemes, making it an attractive option for downlink massive MU-MIMO systems.
Robust Event Detection based on Spatio-Temporal Latent Action Unit using Skeletal Information
Sep 06, 2021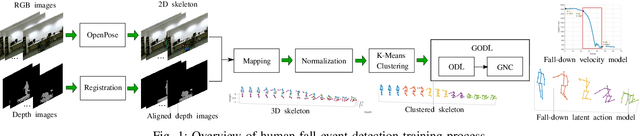
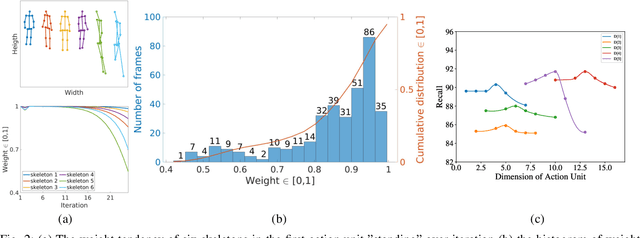
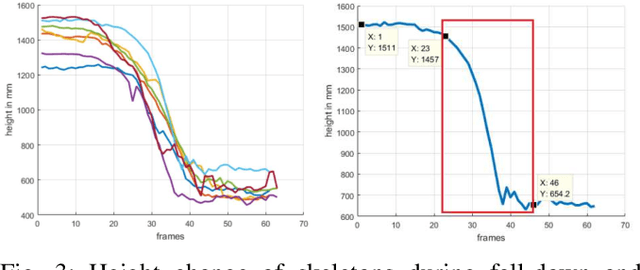
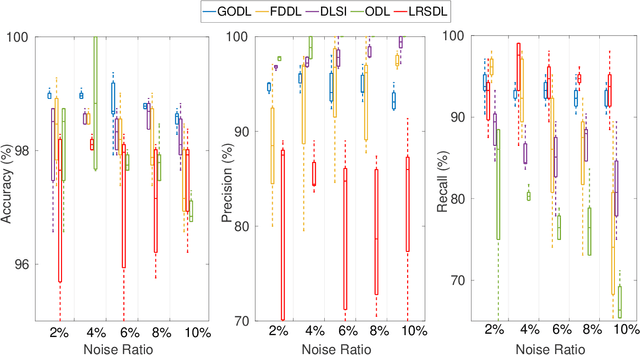
This paper propose a novel dictionary learning approach to detect event action using skeletal information extracted from RGBD video. The event action is represented as several latent atoms and composed of latent spatial and temporal attributes. We perform the method at the example of fall event detection. The skeleton frames are clustered by an initial K-means method. Each skeleton frame is assigned with a varying weight parameter and fed into our Gradual Online Dictionary Learning (GODL) algorithm. During the training process, outlier frames will be gradually filtered by reducing the weight that is inversely proportional to a cost. In order to strictly distinguish the event action from similar actions and robustly acquire its action unit, we build a latent unit temporal structure for each sub-action. We evaluate the proposed method on parts of the NTURGB+D dataset, which includes 209 fall videos, 405 ground-lift videos, 420 sit-down videos, and 280 videos of 46 otheractions. We present the experimental validation of the achieved accuracy, recall and precision. Our approach achieves the bestperformance on precision and accuracy of human fall event detection, compared with other existing dictionary learning methods. With increasing noise ratio, our method remains the highest accuracy and the lowest variance.
Subband-based Generative Adversarial Network for Non-parallel Many-to-many Voice Conversion
Jul 13, 2022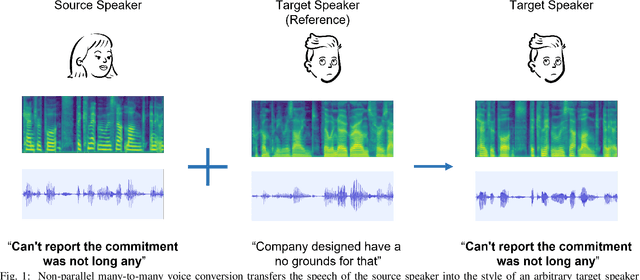
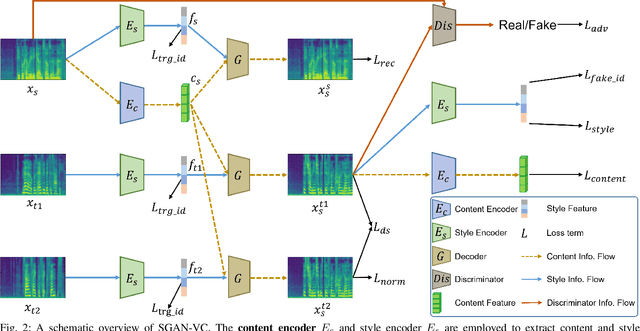
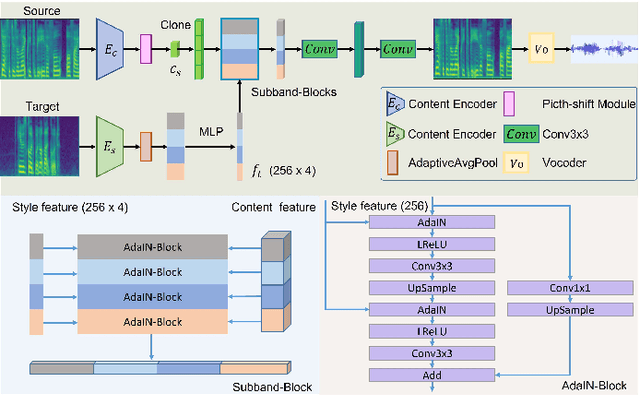
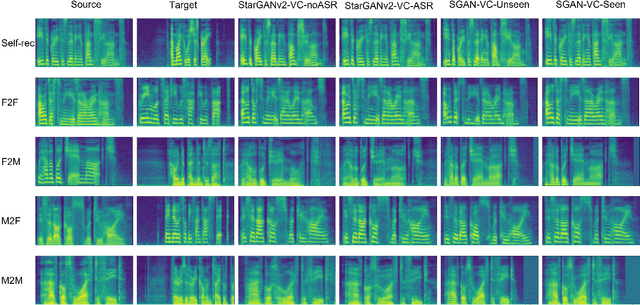
Voice conversion is to generate a new speech with the source content and a target voice style. In this paper, we focus on one general setting, i.e., non-parallel many-to-many voice conversion, which is close to the real-world scenario. As the name implies, non-parallel many-to-many voice conversion does not require the paired source and reference speeches and can be applied to arbitrary voice transfer. In recent years, Generative Adversarial Networks (GANs) and other techniques such as Conditional Variational Autoencoders (CVAEs) have made considerable progress in this field. However, due to the sophistication of voice conversion, the style similarity of the converted speech is still unsatisfactory. Inspired by the inherent structure of mel-spectrogram, we propose a new voice conversion framework, i.e., Subband-based Generative Adversarial Network for Voice Conversion (SGAN-VC). SGAN-VC converts each subband content of the source speech separately by explicitly utilizing the spatial characteristics between different subbands. SGAN-VC contains one style encoder, one content encoder, and one decoder. In particular, the style encoder network is designed to learn style codes for different subbands of the target speaker. The content encoder network can capture the content information on the source speech. Finally, the decoder generates particular subband content. In addition, we propose a pitch-shift module to fine-tune the pitch of the source speaker, making the converted tone more accurate and explainable. Extensive experiments demonstrate that the proposed approach achieves state-of-the-art performance on VCTK Corpus and AISHELL3 datasets both qualitatively and quantitatively, whether on seen or unseen data. Furthermore, the content intelligibility of SGAN-VC on unseen data even exceeds that of StarGANv2-VC with ASR network assistance.
DocReader: Bounding-Box Free Training of a Document Information Extraction Model
May 10, 2021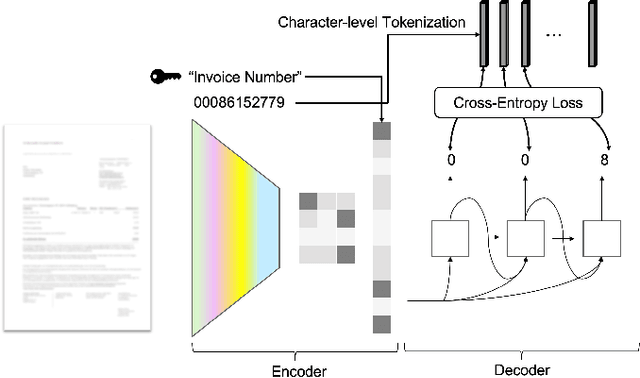

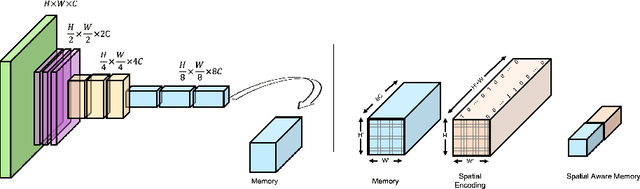
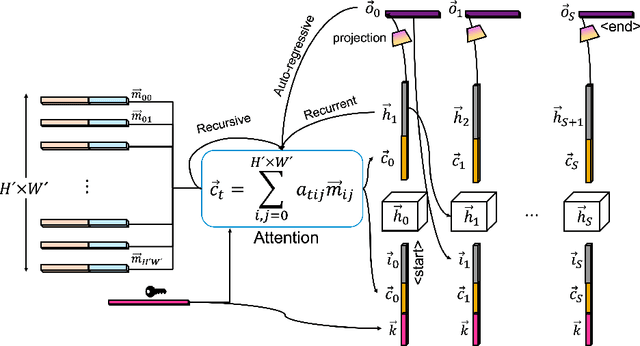
Information extraction from documents is a ubiquitous first step in many business applications. During this step, the entries of various fields must first be read from the images of scanned documents before being further processed and inserted into the corresponding databases. While many different methods have been developed over the past years in order to automate the above extraction step, they all share the requirement of bounding-box or text segment annotations of their training documents. In this work we present DocReader, an end-to-end neural-network-based information extraction solution which can be trained using solely the images and the target values that need to be read. The DocReader can thus leverage existing historical extraction data, completely eliminating the need for any additional annotations beyond what is naturally available in existing human-operated service centres. We demonstrate that the DocReader can reach and surpass other methods which require bounding-boxes for training, as well as provide a clear path for continual learning during its deployment in production.