 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information Extraction From Co-Occurring Similar Entities
Feb 11, 2021

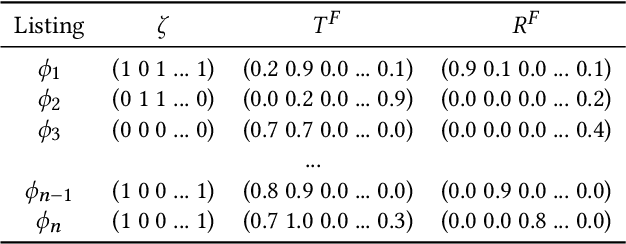
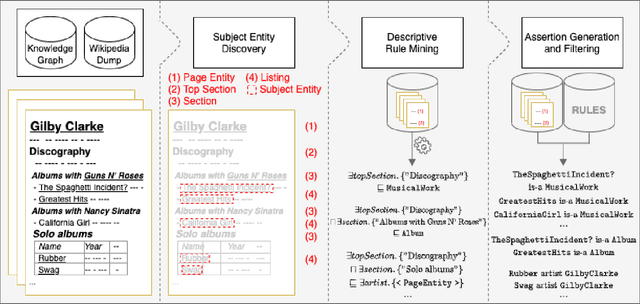
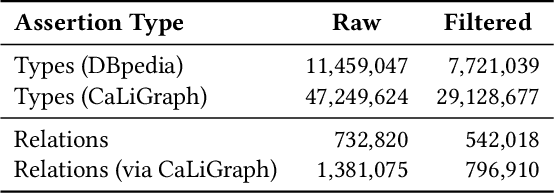
Knowledge about entities and their interrelations is a crucial factor of success for tasks like question answering or text summarization. Publicly available knowledge graphs like Wikidata or DBpedia are, however, far from being complete. In this paper, we explore how information extracted from similar entities that co-occur in structures like tables or lists can help to increase the coverage of such knowledge graphs. In contrast to existing approaches, we do not focus on relationships within a listing (e.g., between two entities in a table row) but on the relationship between a listing's subject entities and the context of the listing. To that end, we propose a descriptive rule mining approach that uses distant supervision to derive rules for these relationships based on a listing's context. Extracted from a suitable data corpus, the rules can be used to extend a knowledge graph with novel entities and assertions. In our experiments we demonstrate that the approach is able to extract up to 3M novel entities and 30M additional assertions from listings in Wikipedia. We find that the extracted information is of high quality and thus suitable to extend Wikipedia-based knowledge graphs like DBpedia, YAGO, and CaLiGraph. For the case of DBpedia, this would result in an increase of covered entities by roughly 50%.
Leveraging Acoustic Contextual Representation by Audio-textual Cross-modal Learning for Conversational ASR
Jul 03, 2022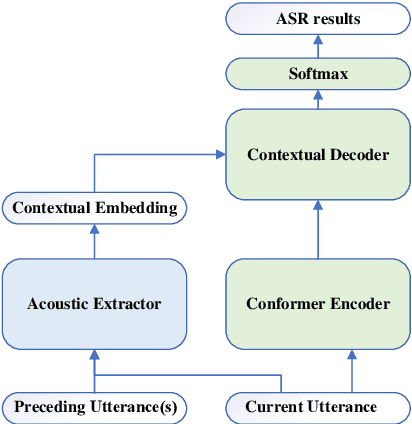
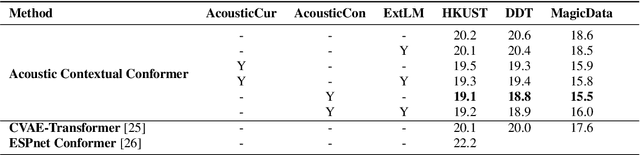
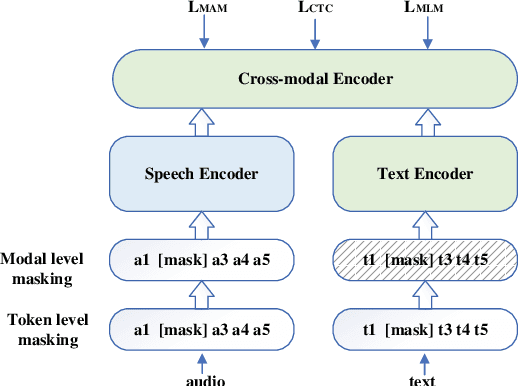

Leveraging context information is an intuitive idea to improve performance on conversational automatic speech recognition(ASR). Previous works usually adopt recognized hypotheses of historical utterances as preceding context, which may bias the current recognized hypothesis due to the inevitable historicalrecognition errors. To avoid this problem, we propose an audio-textual cross-modal representation extractor to learn contextual representations directly from preceding speech. Specifically, it consists of two modal-related encoders, extracting high-level latent features from speech and the corresponding text, and a cross-modal encoder, which aims to learn the correlation between speech and text. We randomly mask some input tokens and input sequences of each modality. Then a token-missing or modal-missing prediction with a modal-level CTC loss on the cross-modal encoder is performed. Thus, the model captures not only the bi-directional context dependencies in a specific modality but also relationships between different modalities. Then, during the training of the conversational ASR system, the extractor will be frozen to extract the textual representation of preceding speech, while such representation is used as context fed to the ASR decoder through attention mechanism. The effectiveness of the proposed approach is validated on several Mandarin conversation corpora and the highest character error rate (CER) reduction up to 16% is achieved on the MagicData dataset.
Dynamic Bank Learning for Semi-supervised Federated Image Diagnosis with Class Imbalance
Jun 27, 2022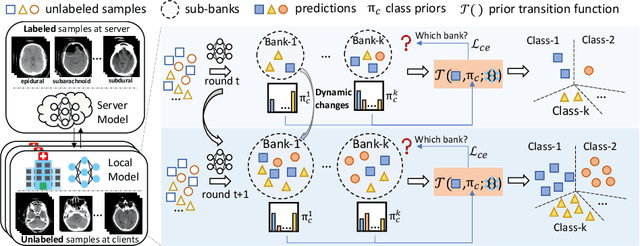
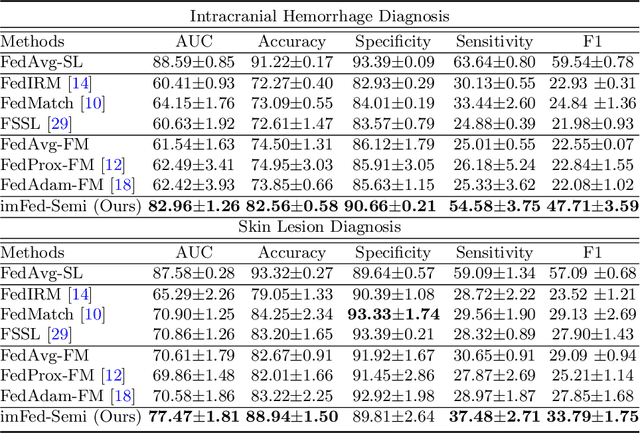
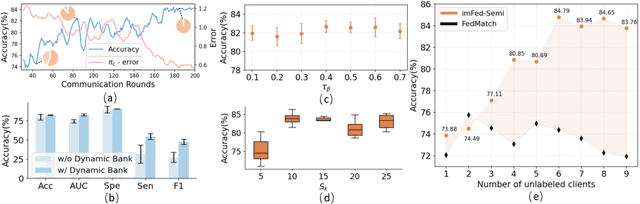
Despite recent progress on semi-supervised federated learning (FL) for medical image diagnosis, the problem of imbalanced class distributions among unlabeled clients is still unsolved for real-world use. In this paper, we study a practical yet challenging problem of class imbalanced semi-supervised FL (imFed-Semi), which allows all clients to have only unlabeled data while the server just has a small amount of labeled data. This imFed-Semi problem is addressed by a novel dynamic bank learning scheme, which improves client training by exploiting class proportion information. This scheme consists of two parts, i.e., the dynamic bank construction to distill various class proportions for each local client, and the sub-bank classification to impose the local model to learn different class proportions. We evaluate our approach on two public real-world medical datasets, including the intracranial hemorrhage diagnosis with 25,000 CT slices and skin lesion diagnosis with 10,015 dermoscopy images. The effectiveness of our method has been validated with significant performance improvements (7.61% and 4.69%) compared with the second-best on the accuracy, as well as comprehensive analytical studies. Code is available at https://github.com/med-air/imFedSemi.
Remote Sensing Change Detection (Segmentation) using Denoising Diffusion Probabilistic Models
Jun 23, 2022
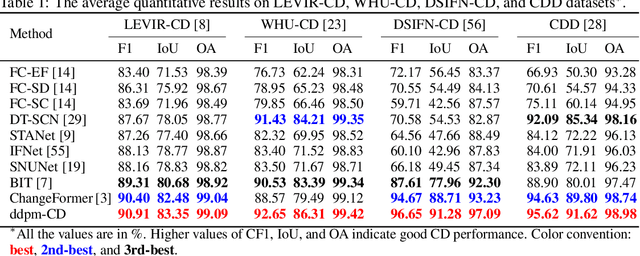

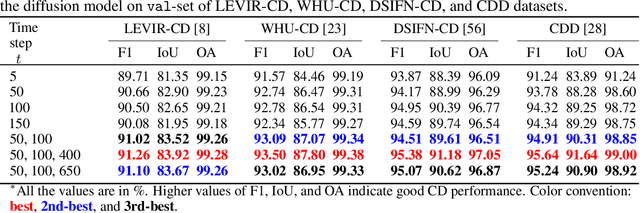
Human civilization has an increasingly powerful influence on the earth system, and earth observations are an invaluable tool for assessing and mitigating the negative impacts. To this end, observing precisely defined changes on Earth's surface is essential, and we propose an effective way to achieve this goal. Notably, our change detection (CD)/ segmentation method proposes a novel way to incorporate the millions of off-the-shelf, unlabeled, remote sensing images available through different earth observation programs into the training process through denoising diffusion probabilistic models. We first leverage the information from these off-the-shelf, uncurated, and unlabeled remote sensing images by using a pre-trained denoising diffusion probabilistic model and then employ the multi-scale feature representations from the diffusion model decoder to train a lightweight CD classifier to detect precise changes. The experiments performed on four publically available CD datasets show that the proposed approach achieves remarkably better results than the state-of-the-art methods in F1, IoU, and overall accuracy. Code and pre-trained models are available at: https://github.com/wgcban/ddpm-cd
H-EMD: A Hierarchical Earth Mover's Distance Method for Instance Segmentation
Jun 02, 2022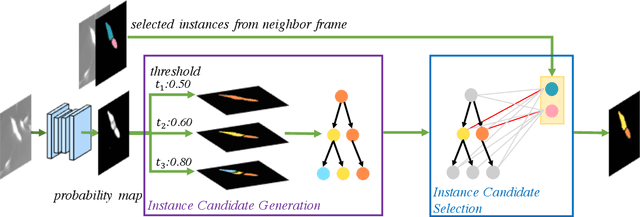
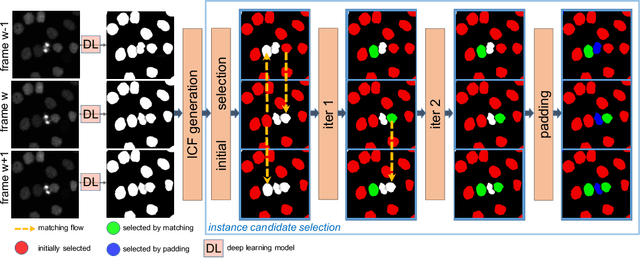
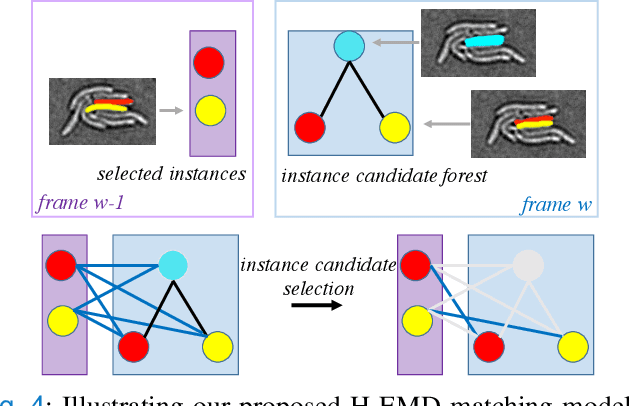

Deep learning (DL) based semantic segmentation methods have achieved excellent performance in biomedical image segmentation, producing high quality probability maps to allow extraction of rich instance information to facilitate good instance segmentation. While numerous efforts were put into developing new DL semantic segmentation models, less attention was paid to a key issue of how to effectively explore their probability maps to attain the best possible instance segmentation. We observe that probability maps by DL semantic segmentation models can be used to generate many possible instance candidates, and accurate instance segmentation can be achieved by selecting from them a set of "optimized" candidates as output instances. Further, the generated instance candidates form a well-behaved hierarchical structure (a forest), which allows selecting instances in an optimized manner. Hence, we propose a novel framework, called hierarchical earth mover's distance (H-EMD), for instance segmentation in biomedical 2D+time videos and 3D images, which judiciously incorporates consistent instance selection with semantic-segmentation-generated probability maps. H-EMD contains two main stages. (1) Instance candidate generation: capturing instance-structured information in probability maps by generating many instance candidates in a forest structure. (2) Instance candidate selection: selecting instances from the candidate set for final instance segmentation. We formulate a key instance selection problem on the instance candidate forest as an optimization problem based on the earth mover's distance (EMD), and solve it by integer linear programming. Extensive experiments on eight biomedical video or 3D datasets demonstrate that H-EMD consistently boosts DL semantic segmentation models and is highly competitive with state-of-the-art methods.
On the Complexity of Adversarial Decision Making
Jun 27, 2022A central problem in online learning and decision making -- from bandits to reinforcement learning -- is to understand what modeling assumptions lead to sample-efficient learning guarantees. We consider a general adversarial decision making framework that encompasses (structured) bandit problems with adversarial rewards and reinforcement learning problems with adversarial dynamics. Our main result is to show -- via new upper and lower bounds -- that the Decision-Estimation Coefficient, a complexity measure introduced by Foster et al. in the stochastic counterpart to our setting, is necessary and sufficient to obtain low regret for adversarial decision making. However, compared to the stochastic setting, one must apply the Decision-Estimation Coefficient to the convex hull of the class of models (or, hypotheses) under consideration. This establishes that the price of accommodating adversarial rewards or dynamics is governed by the behavior of the model class under convexification, and recovers a number of existing results -- both positive and negative. En route to obtaining these guarantees, we provide new structural results that connect the Decision-Estimation Coefficient to variants of other well-known complexity measures, including the Information Ratio of Russo and Van Roy and the Exploration-by-Optimization objective of Lattimore and Gy\"{o}rgy.
Distributed and Joint Optimization of Precoding and Power for User-Centric Cell-Free Massive MIMO
May 09, 2022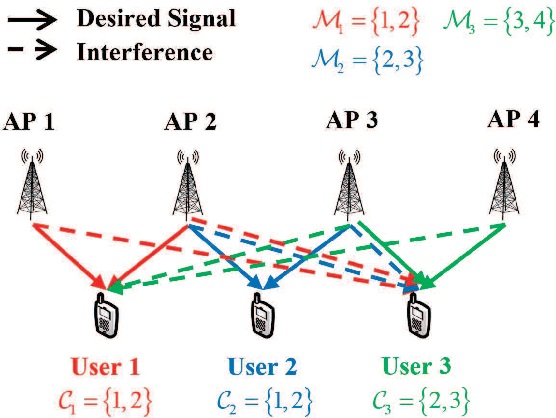
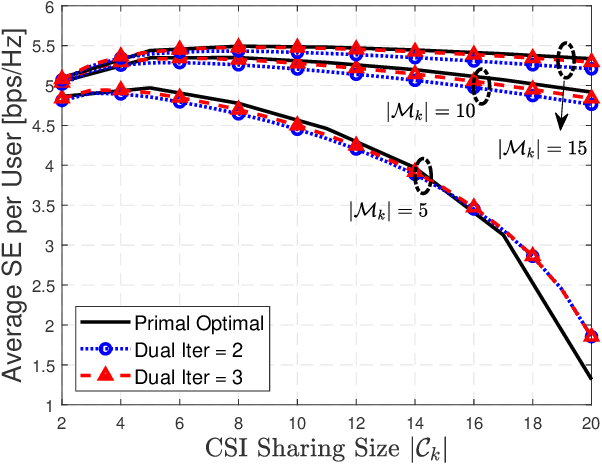
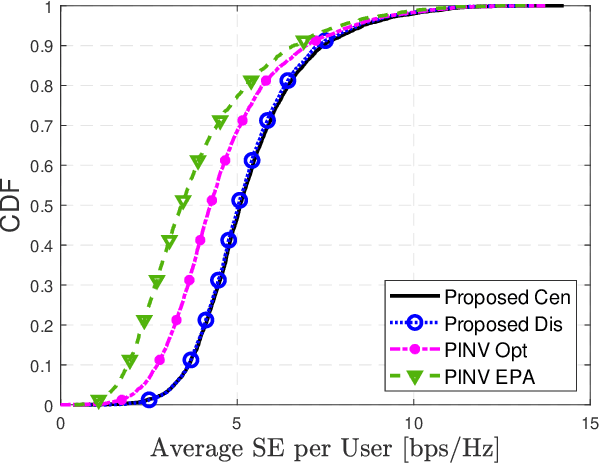
In the cell-free massive multiple-input multiple-output (CF mMIMO) system, the centralized transmission scheme is widely adopted to manage the inter-user interference. Unfortunately, its implementation is limited by the extensive signaling overhead between the central process unit (CPU) and the access points (APs). In this letter, we study the downlink transmission scheme in a distributed approach. First, we propose a reduced channel state information (CSI) exchange mechanism, where only the CSI of a portion of users is shared among neighboring APs. Base on this, the dual decomposition method is adopted to jointly optimize the precoder and power control. The precoding vector can be independently calculated by each AP cluster with closed-form expression. With very few iterations, the proposed distributed scheme achieves the same performance as the centralized one. Moreover, it significantly reduces the information exchange to the CPU.
Difficulty in estimating visual information from randomly sampled images
Dec 16, 2020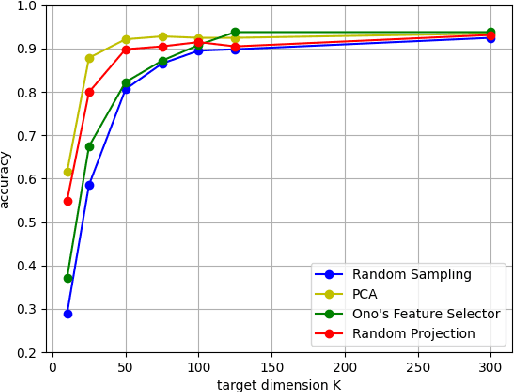
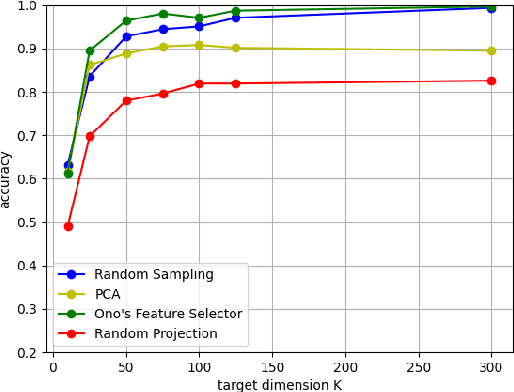
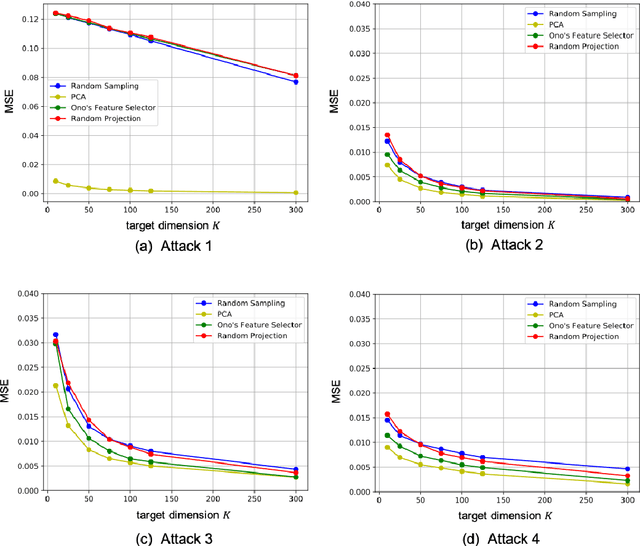
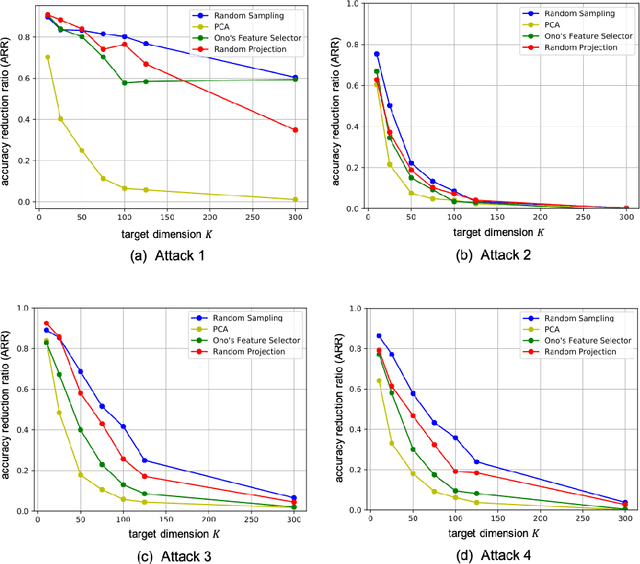
In this paper, we evaluate dimensionality reduction methods in terms of difficulty in estimating visual information on original images from dimensionally reduced ones. Recently, dimensionality reduction has been receiving attention as the process of not only reducing the number of random variables, but also protecting visual information for privacy-preserving machine learning. For such a reason, difficulty in estimating visual information is discussed. In particular, the random sampling method that was proposed for privacy-preserving machine learning, is compared with typical dimensionality reduction methods. In an image classification experiment, the random sampling method is demonstrated not only to have high difficulty, but also to be comparable to other dimensionality reduction methods, while maintaining the property of spatial information invariant.
The Effectiveness of Temporal Dependency in Deepfake Video Detection
May 13, 2022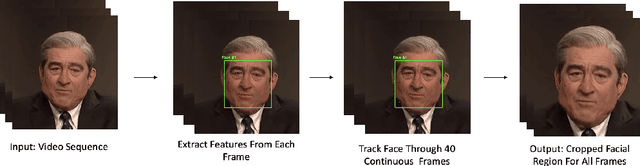
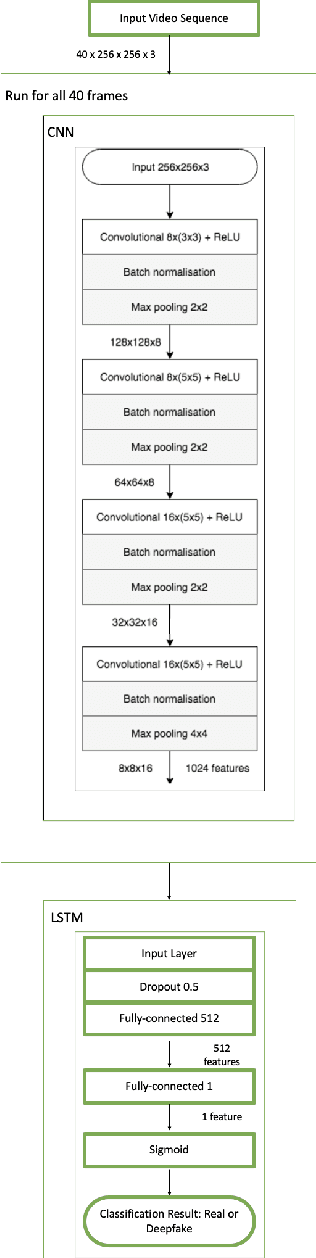
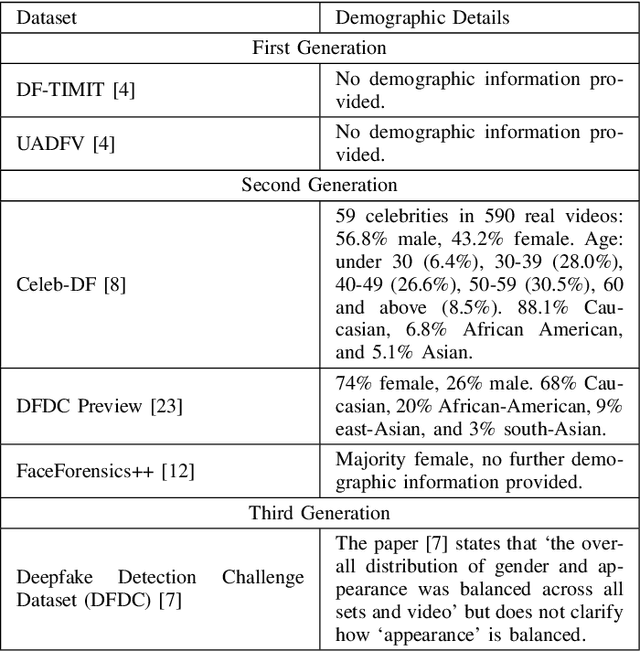
Deepfakes are a form of synthetic image generation used to generate fake videos of individuals for malicious purposes. The resulting videos may be used to spread misinformation, reduce trust in media, or as a form of blackmail. These threats necessitate automated methods of deepfake video detection. This paper investigates whether temporal information can improve the deepfake detection performance of deep learning models. To investigate this, we propose a framework that classifies new and existing approaches by their defining characteristics. These are the types of feature extraction: automatic or manual, and the temporal relationship between frames: dependent or independent. We apply this framework to investigate the effect of temporal dependency on a model's deepfake detection performance. We find that temporal dependency produces a statistically significant (p < 0.05) increase in performance in classifying real images for the model using automatic feature selection, demonstrating that spatio-temporal information can increase the performance of deepfake video detection models.
Extended U-Net for Speaker Verification in Noisy Environments
Jun 27, 2022



Background noise is a well-known factor that deteriorates the accuracy and reliability of speaker verification (SV) systems by blurring speech intelligibility. Various studies have used separate pretrained enhancement models as the front-end module of the SV system in noisy environments, and these methods effectively remove noises. However, the denoising process of independent enhancement models not tailored to the SV task can also distort the speaker information included in utterances. We argue that the enhancement network and speaker embedding extractor should be fully jointly trained for SV tasks under noisy conditions to alleviate this issue. Therefore, we proposed a U-Net-based integrated framework that simultaneously optimizes speaker identification and feature enhancement losses. Moreover, we analyzed the structural limitations of using U-Net directly for noise SV tasks and further proposed Extended U-Net to reduce these drawbacks. We evaluated the models on the noise-synthesized VoxCeleb1 test set and VOiCES development set recorded in various noisy scenarios. The experimental results demonstrate that the U-Net-based fully joint training framework is more effective than the baseline, and the extended U-Net exhibited state-of-the-art performance versus the recently proposed compensation systems.