 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Approach for Automatic Construction of an Algorithmic Knowledge Graph from Textual Resources
May 13, 2022
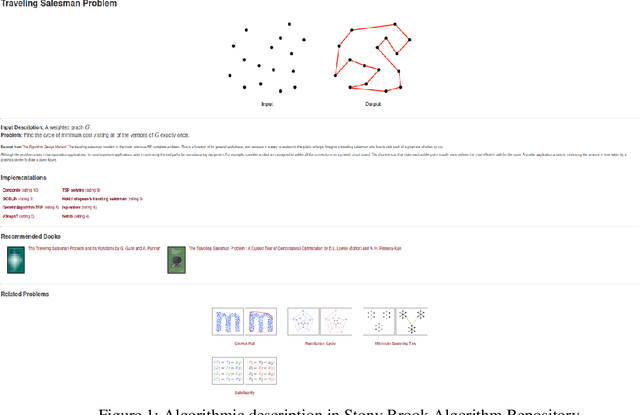



There is enormous growth in various fields of research. This development is accompanied by new problems. To solve these problems efficiently and in an optimized manner, algorithms are created and described by researchers in the scientific literature. Scientific algorithms are vital for understanding and reusing existing work in numerous domains. However, algorithms are generally challenging to find. Also, the comparison among similar algorithms is difficult because of the disconnected documentation. Information about algorithms is mostly present in websites, code comments, and so on. There is an absence of structured metadata to portray algorithms. As a result, sometimes redundant or similar algorithms are published, and the researchers build them from scratch instead of reusing or expanding upon the already existing algorithm. In this paper, we introduce an approach for automatically developing a knowledge graph (KG) for algorithmic problems from unstructured data. Because it captures information more clearly and extensively, an algorithm KG will give additional context and explainability to the algorithm metadata.
Learning quantum symmetries with interactive quantum-classical variational algorithms
Jun 23, 2022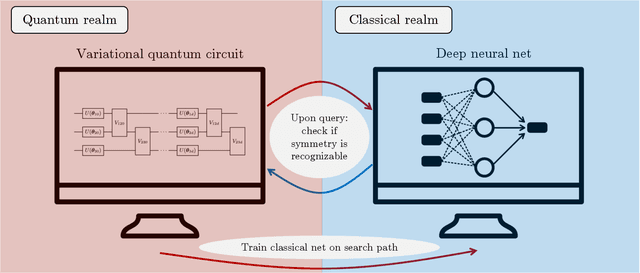
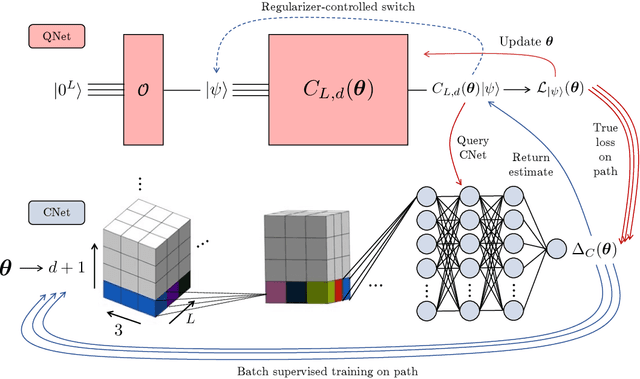
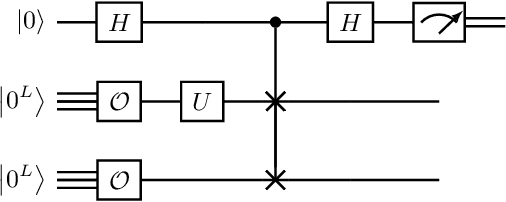
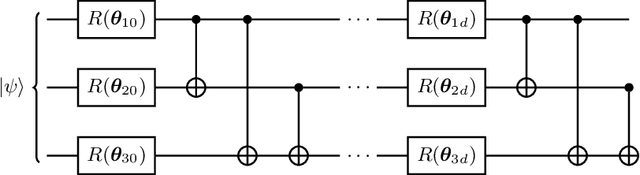
A symmetry of a state $\lvert \psi \rangle$ is a unitary operator of which $\lvert \psi \rangle$ is an eigenvector. When $\lvert \psi \rangle$ is an unknown state supplied by a black-box oracle, the state's symmetries serve to characterize it, and often relegate much of the desired information about $\lvert \psi \rangle$. In this paper, we develop a variational hybrid quantum-classical learning scheme to systematically probe for symmetries of $\lvert \psi \rangle$ with no a priori assumptions about the state. This procedure can be used to learn various symmetries at the same time. In order to avoid re-learning already known symmetries, we introduce an interactive protocol with a classical deep neural net. The classical net thereby regularizes against repetitive findings and allows our algorithm to terminate empirically with all possible symmetries found. Our scheme can be implemented efficiently on average with non-local SWAP gates; we also give a less efficient algorithm with only local operations, which may be more appropriate for current noisy quantum devices. We demonstrate our algorithm on representative families of states.
FAST-VQA: Efficient End-to-end Video Quality Assessment with Fragment Sampling
Jul 06, 2022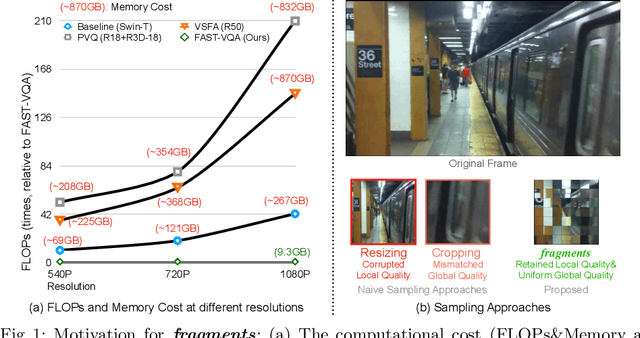
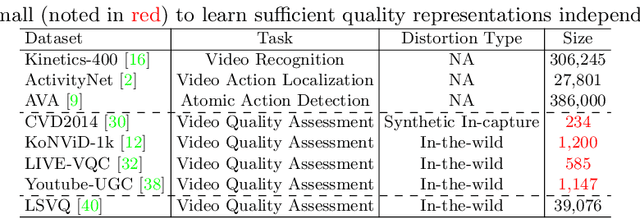


Current deep video quality assessment (VQA) methods are usually with high computational costs when evaluating high-resolution videos. This cost hinders them from learning better video-quality-related representations via end-to-end training. Existing approaches typically consider naive sampling to reduce the computational cost, such as resizing and cropping. However, they obviously corrupt quality-related information in videos and are thus not optimal for learning good representations for VQA. Therefore, there is an eager need to design a new quality-retained sampling scheme for VQA. In this paper, we propose Grid Mini-patch Sampling (GMS), which allows consideration of local quality by sampling patches at their raw resolution and covers global quality with contextual relations via mini-patches sampled in uniform grids. These mini-patches are spliced and aligned temporally, named as fragments. We further build the Fragment Attention Network (FANet) specially designed to accommodate fragments as inputs. Consisting of fragments and FANet, the proposed FrAgment Sample Transformer for VQA (FAST-VQA) enables efficient end-to-end deep VQA and learns effective video-quality-related representations. It improves state-of-the-art accuracy by around 10% while reducing 99.5% FLOPs on 1080P high-resolution videos. The newly learned video-quality-related representations can also be transferred into smaller VQA datasets, boosting performance in these scenarios. Extensive experiments show that FAST-VQA has good performance on inputs of various resolutions while retaining high efficiency. We publish our code at https://github.com/timothyhtimothy/FAST-VQA.
* Will appear on ECCV 2022. 14 Pages
Similarity-aware Positive Instance Sampling for Graph Contrastive Pre-training
Jun 23, 2022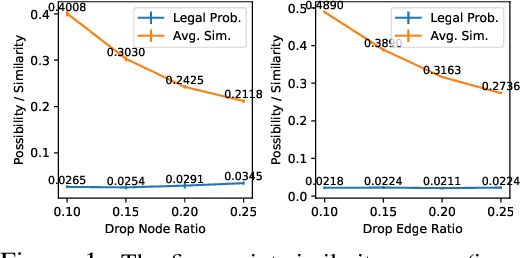
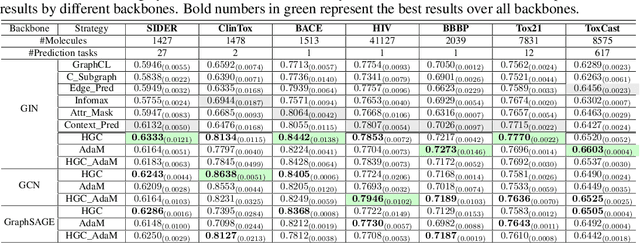

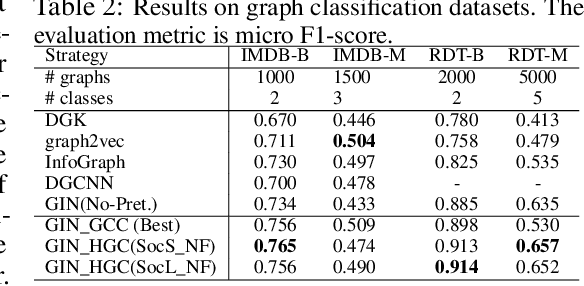
Graph instance contrastive learning has been proved as an effective task for Graph Neural Network (GNN) pre-training. However, one key issue may seriously impede the representative power in existing works: Positive instances created by current methods often miss crucial information of graphs or even yield illegal instances (such as non-chemically-aware graphs in molecular generation). To remedy this issue, we propose to select positive graph instances directly from existing graphs in the training set, which ultimately maintains the legality and similarity to the target graphs. Our selection is based on certain domain-specific pair-wise similarity measurements as well as sampling from a hierarchical graph encoding similarity relations among graphs. Besides, we develop an adaptive node-level pre-training method to dynamically mask nodes to distribute them evenly in the graph. We conduct extensive experiments on $13$ graph classification and node classification benchmark datasets from various domains. The results demonstrate that the GNN models pre-trained by our strategies can outperform those trained-from-scratch models as well as the variants obtained by existing methods.
Difficulty in estimating visual information from randomly sampled images
Dec 16, 2020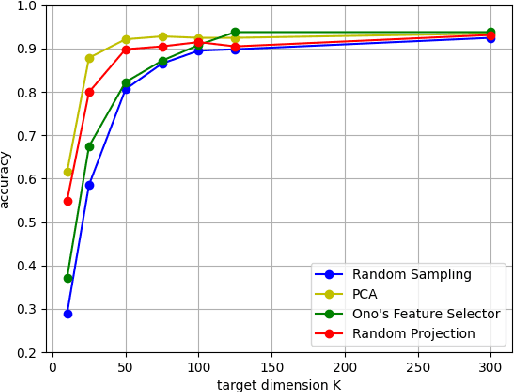
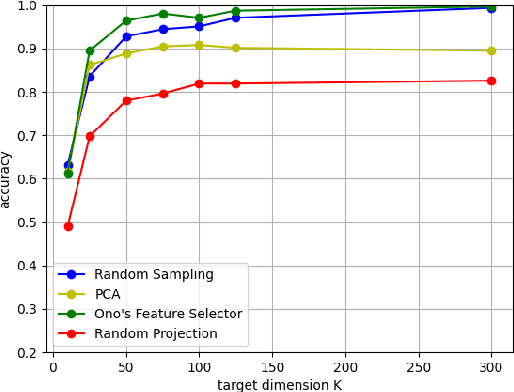
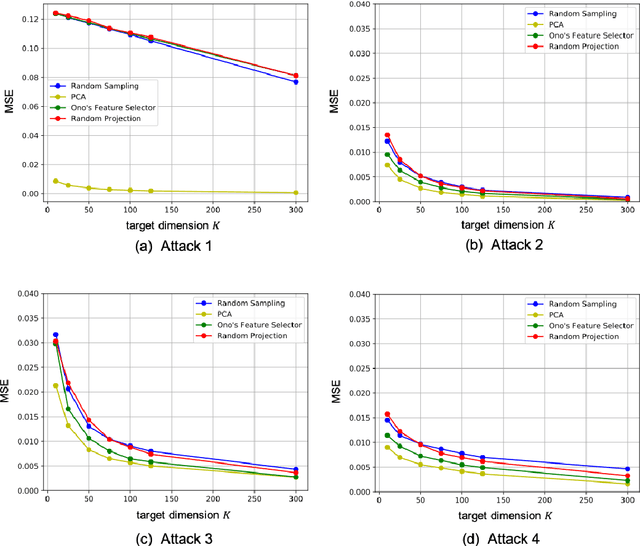
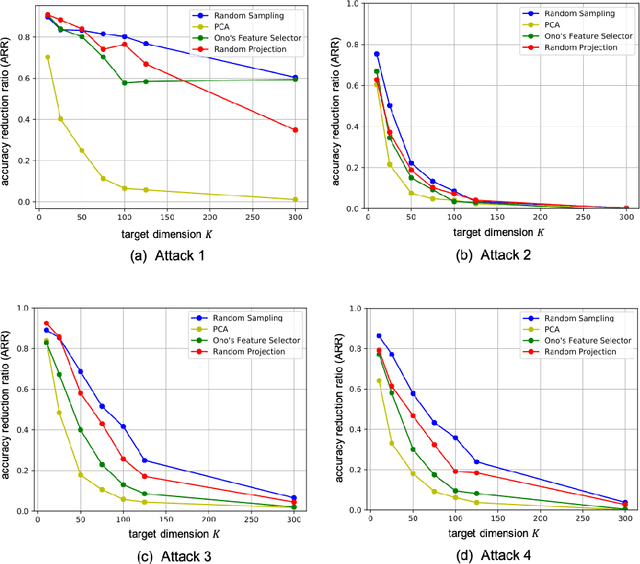
In this paper, we evaluate dimensionality reduction methods in terms of difficulty in estimating visual information on original images from dimensionally reduced ones. Recently, dimensionality reduction has been receiving attention as the process of not only reducing the number of random variables, but also protecting visual information for privacy-preserving machine learning. For such a reason, difficulty in estimating visual information is discussed. In particular, the random sampling method that was proposed for privacy-preserving machine learning, is compared with typical dimensionality reduction methods. In an image classification experiment, the random sampling method is demonstrated not only to have high difficulty, but also to be comparable to other dimensionality reduction methods, while maintaining the property of spatial information invariant.
SARNet: Semantic Augmented Registration of Large-Scale Urban Point Clouds
Jun 27, 2022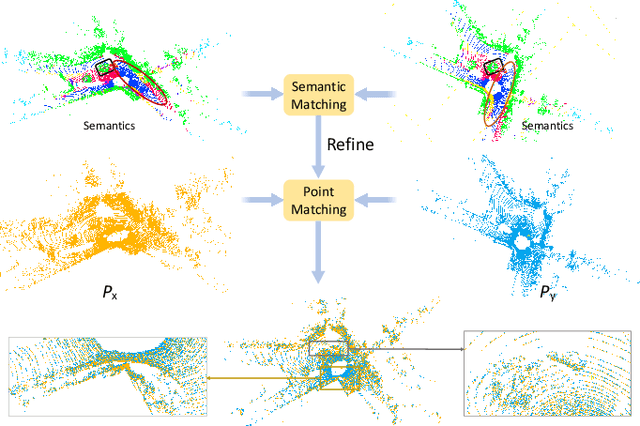
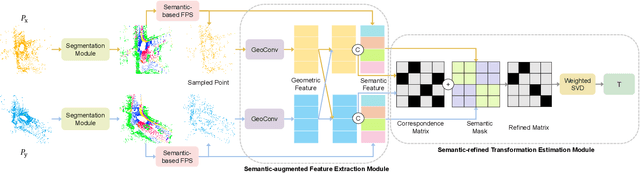
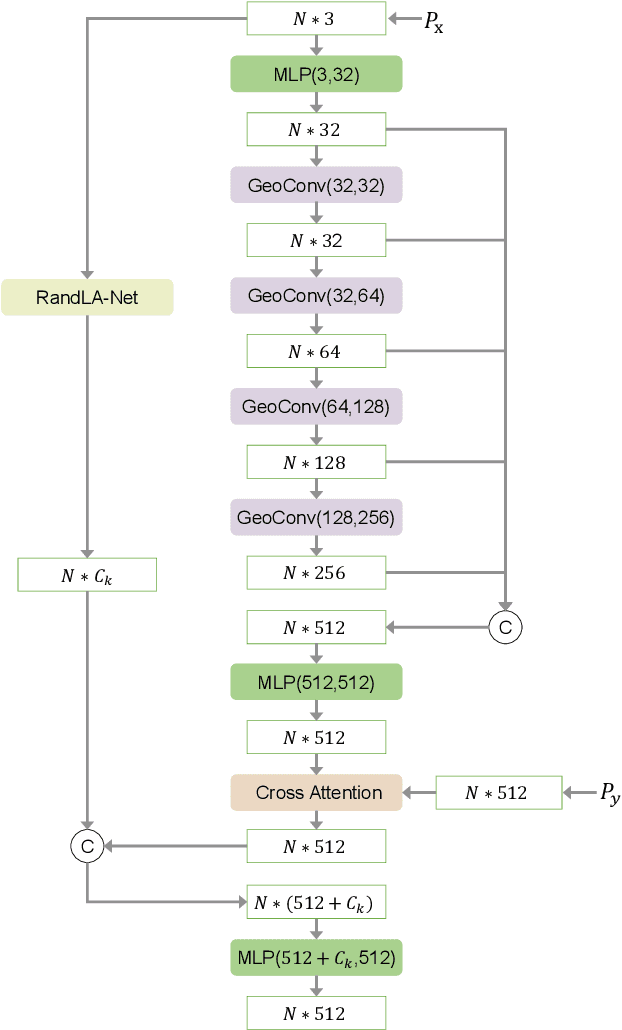
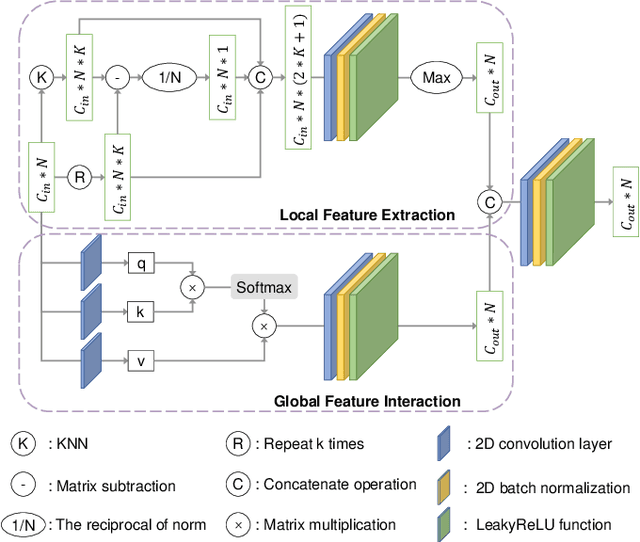
Registering urban point clouds is a quite challenging task due to the large-scale, noise and data incompleteness of LiDAR scanning data. In this paper, we propose SARNet, a novel semantic augmented registration network aimed at achieving efficient registration of urban point clouds at city scale. Different from previous methods that construct correspondences only in the point-level space, our approach fully exploits semantic features as assistance to improve registration accuracy. Specifically, we extract per-point semantic labels with advanced semantic segmentation networks and build a prior semantic part-to-part correspondence. Then we incorporate the semantic information into a learning-based registration pipeline, consisting of three core modules: a semantic-based farthest point sampling module to efficiently filter out outliers and dynamic objects; a semantic-augmented feature extraction module for learning more discriminative point descriptors; a semantic-refined transformation estimation module that utilizes prior semantic matching as a mask to refine point correspondences by reducing false matching for better convergence. We evaluate the proposed SARNet extensively by using real-world data from large regions of urban scenes and comparing it with alternative methods. The code is available at https://github.com/WinterCodeForEverything/SARNet.
GLOBUS: GLObal Building heights for Urban Studies
May 24, 2022
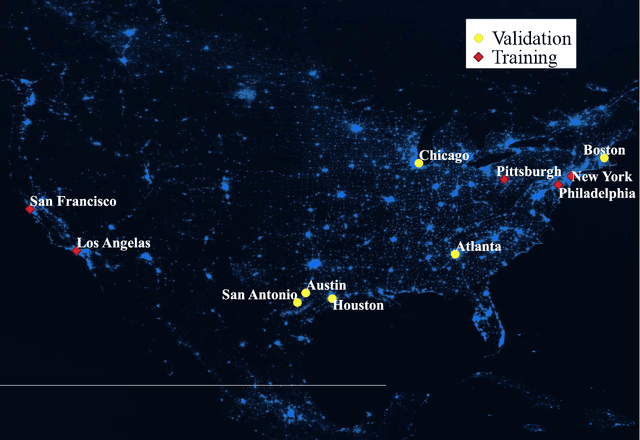
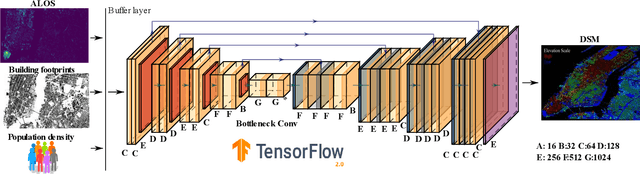
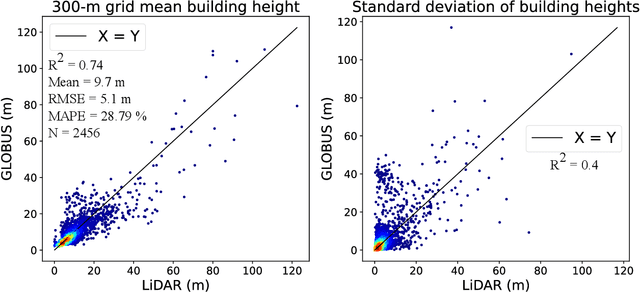
Urban weather and climate studies continue to be important as extreme events cause economic loss and impact public health. Weather models seek to represent urban areas but are oversimplified due to data availability, especially building information. This paper introduces a novel Level of Detail-1 (LoD-1) building dataset derived from a Deep Neural Network (DNN) called GLObal Building heights for Urban Studies (GLOBUS). GLOBUS uses open-source datasets as predictors: Advanced Land Observation Satellite (ALOS) Digital Surface Model (DSM) normalized using Shuttle Radar Topography Mission (SRTM) Digital Elevation Model (DEM), Landscan population density, and building footprints. The building information from GLOBUS can be ingested in Numerical Weather Prediction (NWP) and urban energy-water balance models to study localized phenomena such as the Urban Heat Island (UHI) effect. GLOBUS has been trained and validated using the United States Geological Survey (USGS) 3DEP Light Detection and Ranging (LiDAR) data. We used data from 5 US cities for training and the model was validated over 6 cities. Performance metrics are computed at a spatial resolution of 300-meter. The Root Mean Squared Error (RMSE) and Mean Absolute Percentage Error (MAPE) were 5.15 meters and 28.8 %, respectively. The standard deviation and histogram of building heights over a 300-meter grid are well represented using GLOBUS.
Conditional Permutation Invariant Flows
Jun 17, 2022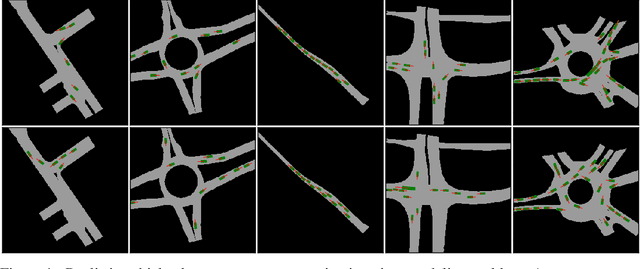
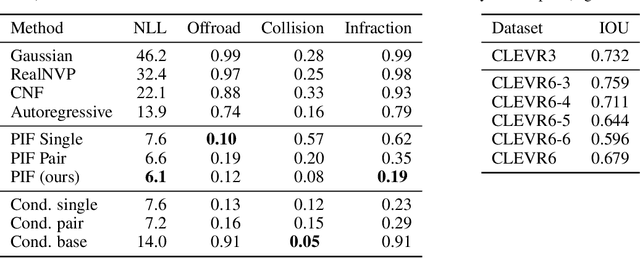
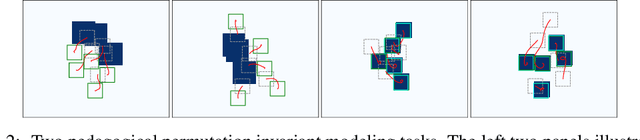
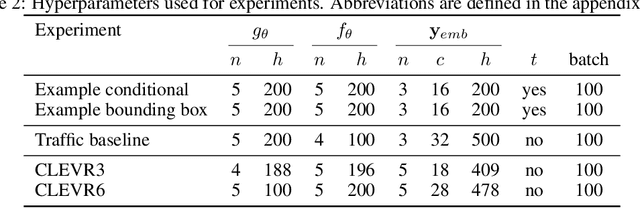
We present a novel, conditional generative probabilistic model of set-valued data with a tractable log density. This model is a continuous normalizing flow governed by permutation equivariant dynamics. These dynamics are driven by a learnable per-set-element term and pairwise interactions, both parametrized by deep neural networks. We illustrate the utility of this model via applications including (1) complex traffic scene generation conditioned on visually specified map information, and (2) object bounding box generation conditioned directly on images. We train our model by maximizing the expected likelihood of labeled conditional data under our flow, with the aid of a penalty that ensures the dynamics are smooth and hence efficiently solvable. Our method significantly outperforms non-permutation invariant baselines in terms of log likelihood and domain-specific metrics (offroad, collision, and combined infractions), yielding realistic samples that are difficult to distinguish from real data.
Multi-Fingered In-Hand Manipulation with Various Object Properties Using Graph Convolutional Networks and Distributed Tactile Sensors
May 09, 2022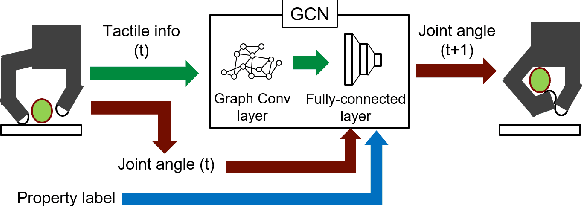
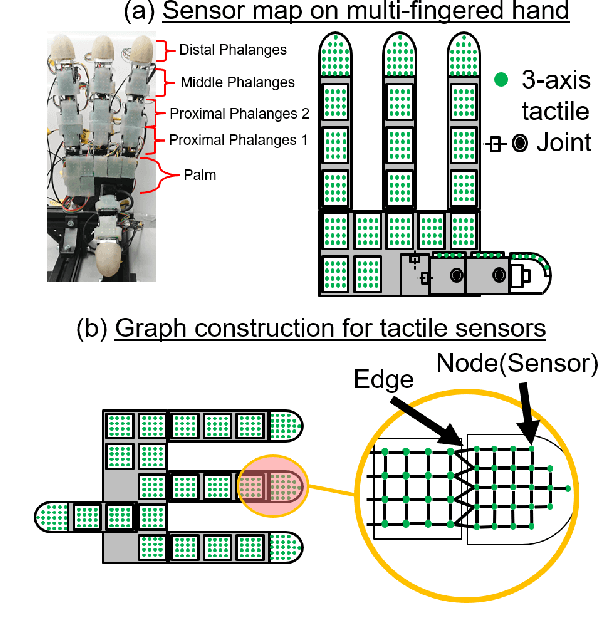
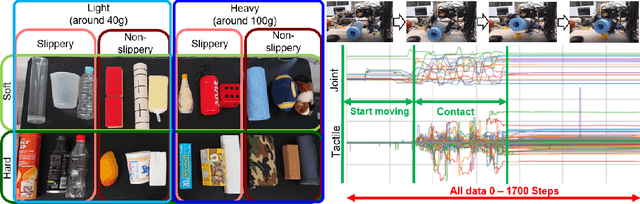

Multi-fingered hands could be used to achieve many dexterous manipulation tasks, similarly to humans, and tactile sensing could enhance the manipulation stability for a variety of objects. However, tactile sensors on multi-fingered hands have a variety of sizes and shapes. Convolutional neural networks (CNN) can be useful for processing tactile information, but the information from multi-fingered hands needs an arbitrary pre-processing, as CNNs require a rectangularly shaped input, which may lead to unstable results. Therefore, how to process such complex shaped tactile information and utilize it for achieving manipulation skills is still an open issue. This paper presents a control method based on a graph convolutional network (GCN) which extracts geodesical features from the tactile data with complicated sensor alignments. Moreover, object property labels are provided to the GCN to adjust in-hand manipulation motions. Distributed tri-axial tactile sensors are mounted on the fingertips, finger phalanges and palm of an Allegro hand, resulting in 1152 tactile measurements. Training data is collected with a data-glove to transfer human dexterous manipulation directly to the robot hand. The GCN achieved high success rates for in-hand manipulation. We also confirmed that fragile objects were deformed less when correct object labels were provided to the GCN. When visualizing the activation of the GCN with a PCA, we verified that the network acquired geodesical features. Our method achieved stable manipulation even when an experimenter pulled a grasped object and for untrained objects.
PlanarRecon: Real-time 3D Plane Detection and Reconstruction from Posed Monocular Videos
Jun 15, 2022
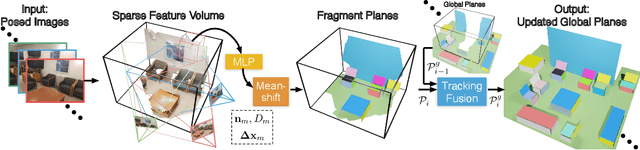
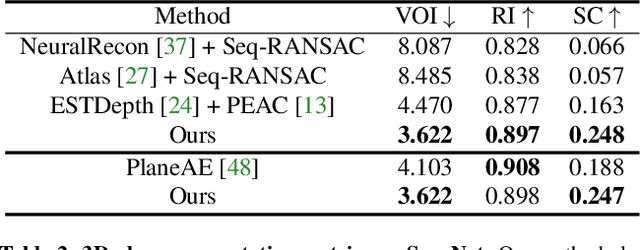
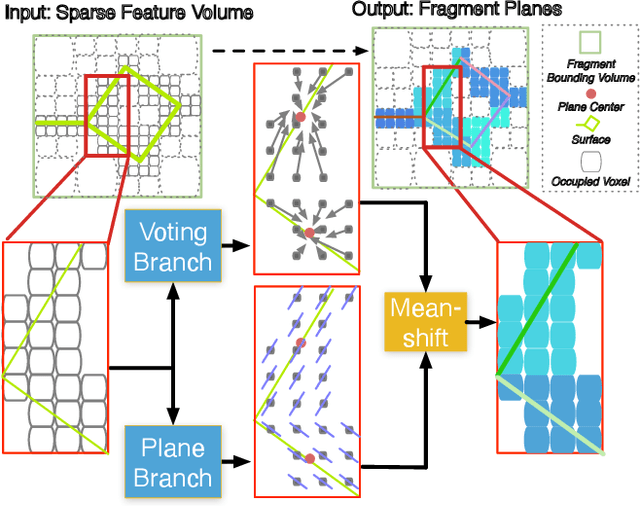
We present PlanarRecon -- a novel framework for globally coherent detection and reconstruction of 3D planes from a posed monocular video. Unlike previous works that detect planes in 2D from a single image, PlanarRecon incrementally detects planes in 3D for each video fragment, which consists of a set of key frames, from a volumetric representation of the scene using neural networks. A learning-based tracking and fusion module is designed to merge planes from previous fragments to form a coherent global plane reconstruction. Such design allows PlanarRecon to integrate observations from multiple views within each fragment and temporal information across different ones, resulting in an accurate and coherent reconstruction of the scene abstraction with low-polygonal geometry. Experiments show that the proposed approach achieves state-of-the-art performances on the ScanNet dataset while being real-time.