 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Deterministic Information Bottleneck with Matrix-based Entropy Functional
Jan 31, 2021
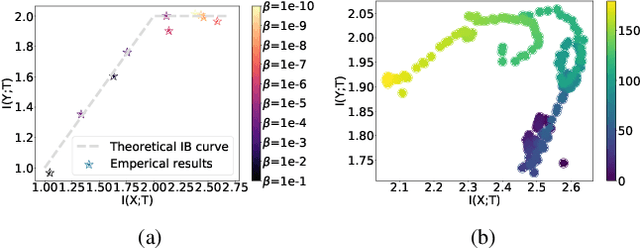



We introduce the matrix-based Renyi's $\alpha$-order entropy functional to parameterize Tishby et al. information bottleneck (IB) principle with a neural network. We term our methodology Deep Deterministic Information Bottleneck (DIB), as it avoids variational inference and distribution assumption. We show that deep neural networks trained with DIB outperform the variational objective counterpart and those that are trained with other forms of regularization, in terms of generalization performance and robustness to adversarial attack.Code available at https://github.com/yuxi120407/DIB
Information Prediction using Knowledge Graphs for Contextual Malware Threat Intelligence
Feb 10, 2021
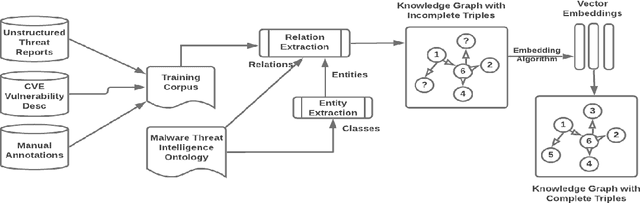
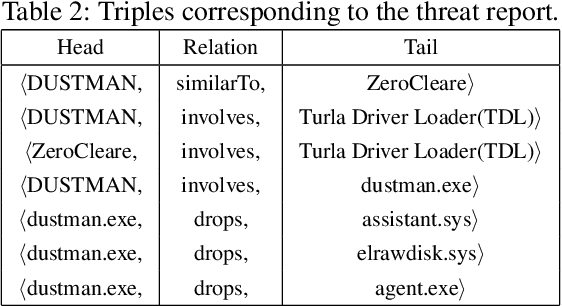

Large amounts of threat intelligence information about mal-ware attacks are available in disparate, typically unstructured, formats. Knowledge graphs can capture this information and its context using RDF triples represented by entities and relations. Sparse or inaccurate threat information, however, leads to challenges such as incomplete or erroneous triples. Named entity recognition (NER) and relation extraction (RE) models used to populate the knowledge graph cannot fully guaran-tee accurate information retrieval, further exacerbating this problem. This paper proposes an end-to-end approach to generate a Malware Knowledge Graph called MalKG, the first open-source automated knowledge graph for malware threat intelligence. MalKG dataset called MT40K1 contains approximately 40,000 triples generated from 27,354 unique entities and 34 relations. We demonstrate the application of MalKGin predicting missing malware threat intelligence information in the knowledge graph. For ground truth, we manually curate a knowledge graph called MT3K, with 3,027 triples generated from 5,741 unique entities and 22 relations. For entity prediction via a state-of-the-art entity prediction model(TuckER), our approach achieves 80.4 for the hits@10 metric (predicts the top 10 options for missing entities in the knowledge graph), and 0.75 for the MRR (mean reciprocal rank). We also propose a framework to automate the extraction of thousands of entities and relations into RDF triples, both manually and automatically, at the sentence level from1,100 malware threat intelligence reports and from the com-mon vulnerabilities and exposures (CVE) database.
Knowledge-aware Neural Collective Matrix Factorization for Cross-domain Recommendation
Jun 27, 2022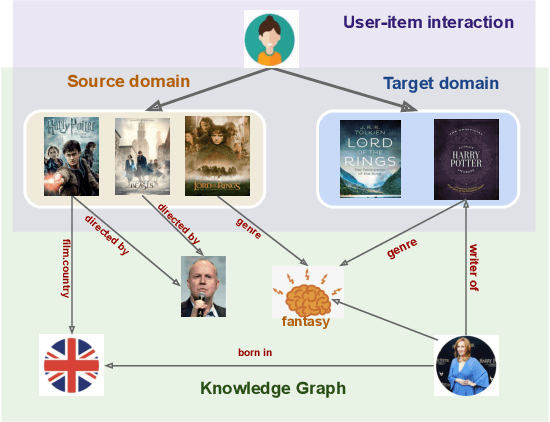
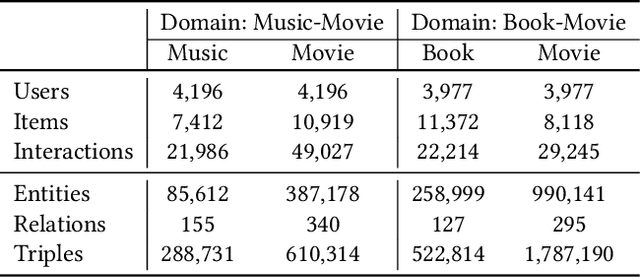
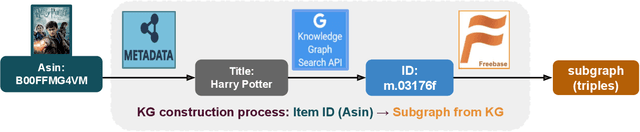
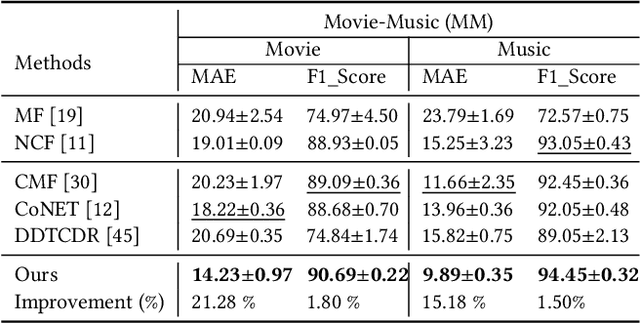
Cross-domain recommendation (CDR) can help customers find more satisfying items in different domains. Existing CDR models mainly use common users or mapping functions as bridges between domains but have very limited exploration in fully utilizing extra knowledge across domains. In this paper, we propose to incorporate the knowledge graph (KG) for CDR, which enables items in different domains to share knowledge. To this end, we first construct a new dataset AmazonKG4CDR from the Freebase KG and a subset (two domain pairs: movies-music, movie-book) of Amazon Review Data. This new dataset facilitates linking knowledge to bridge within- and cross-domain items for CDR. Then we propose a new framework, KG-aware Neural Collective Matrix Factorization (KG-NeuCMF), leveraging KG to enrich item representations. It first learns item embeddings by graph convolutional autoencoder to capture both domain-specific and domain-general knowledge from adjacent and higher-order neighbours in the KG. Then, we maximize the mutual information between item embeddings learned from the KG and user-item matrix to establish cross-domain relationships for better CDR. Finally, we conduct extensive experiments on the newly constructed dataset and demonstrate that our model significantly outperforms the best-performing baselines.
All-Photonic Artificial Neural Network Processor Via Non-linear Optics
May 17, 2022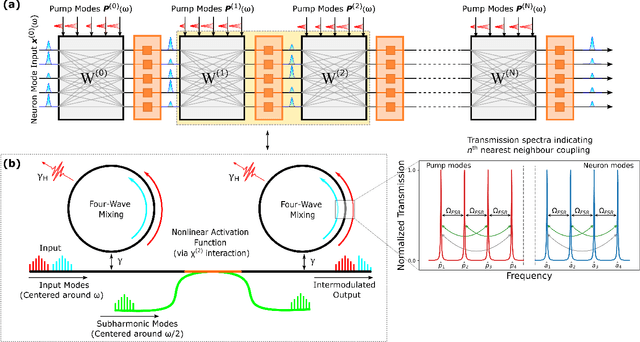
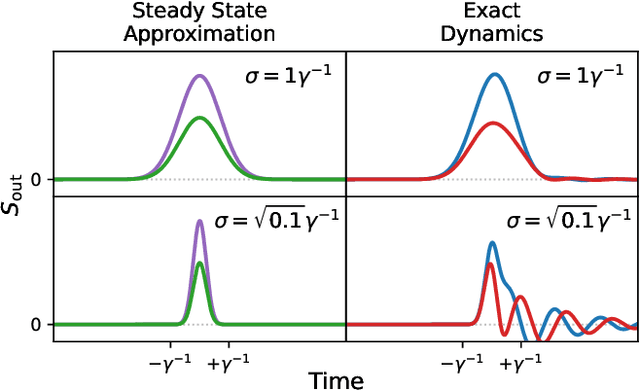
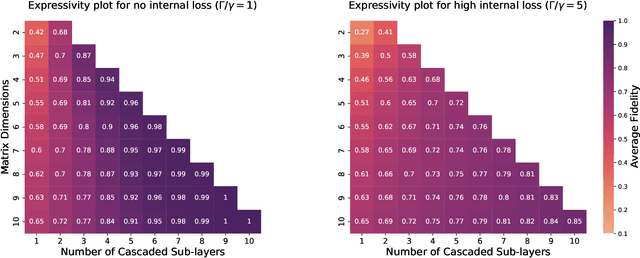
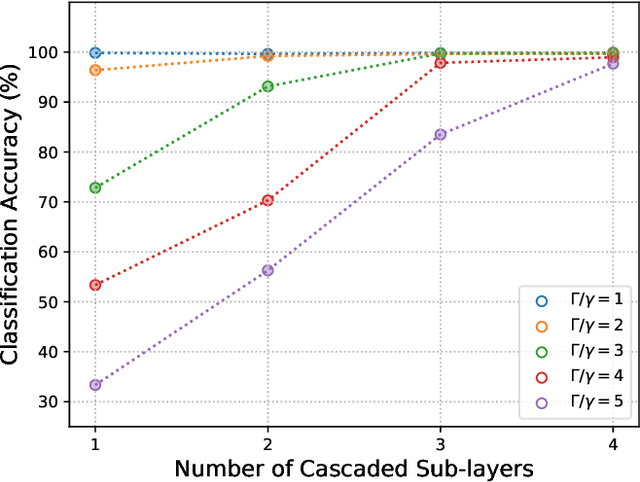
Optics and photonics has recently captured interest as a platform to accelerate linear matrix processing, that has been deemed as a bottleneck in traditional digital electronic architectures. In this paper, we propose an all-photonic artificial neural network processor wherein information is encoded in the amplitudes of frequency modes that act as neurons. The weights among connected layers are encoded in the amplitude of controlled frequency modes that act as pumps. Interaction among these modes for information processing is enabled by non-linear optical processes. Both the matrix multiplication and element-wise activation functions are performed through coherent processes, enabling the direct representation of negative and complex numbers without the use of detectors or digital electronics. Via numerical simulations, we show that our design achieves a performance commensurate with present-day state-of-the-art computational networks on image-classification benchmarks. Our architecture is unique in providing a completely unitary, reversible mode of computation. Additionally, the computational speed increases with the power of the pumps to arbitrarily high rates, as long as the circuitry can sustain the higher optical power.
Mathematical Foundations of Graph-Based Bayesian Semi-Supervised Learning
Jul 03, 2022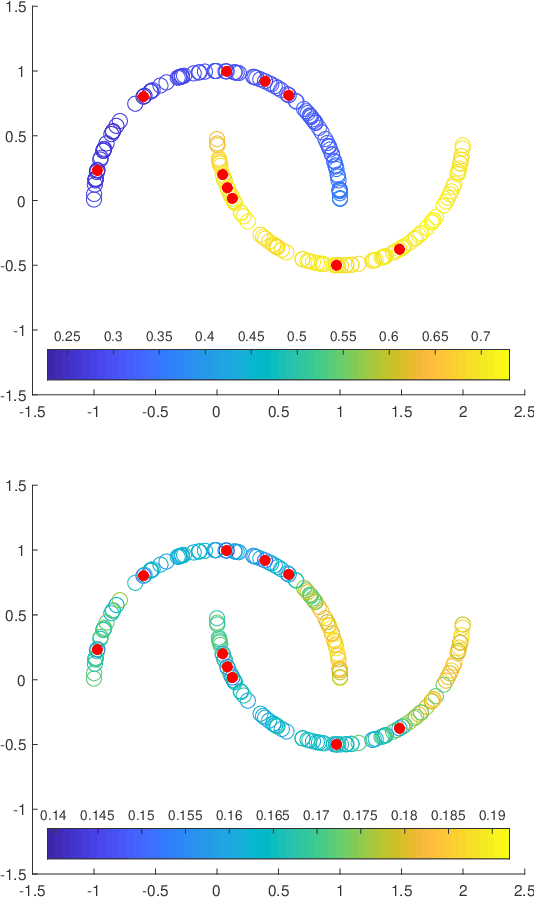
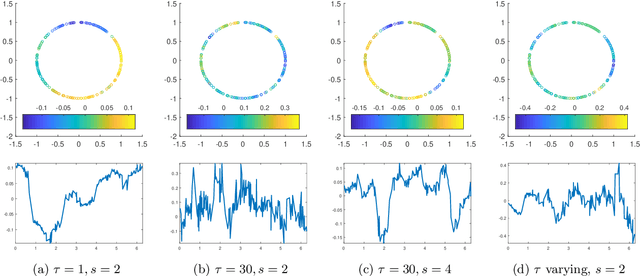
In recent decades, science and engineering have been revolutionized by a momentous growth in the amount of available data. However, despite the unprecedented ease with which data are now collected and stored, labeling data by supplementing each feature with an informative tag remains to be challenging. Illustrative tasks where the labeling process requires expert knowledge or is tedious and time-consuming include labeling X-rays with a diagnosis, protein sequences with a protein type, texts by their topic, tweets by their sentiment, or videos by their genre. In these and numerous other examples, only a few features may be manually labeled due to cost and time constraints. How can we best propagate label information from a small number of expensive labeled features to a vast number of unlabeled ones? This is the question addressed by semi-supervised learning (SSL). This article overviews recent foundational developments on graph-based Bayesian SSL, a probabilistic framework for label propagation using similarities between features. SSL is an active research area and a thorough review of the extant literature is beyond the scope of this article. Our focus will be on topics drawn from our own research that illustrate the wide range of mathematical tools and ideas that underlie the rigorous study of the statistical accuracy and computational efficiency of graph-based Bayesian SSL.
Efficient Federated Learning with Spike Neural Networks for Traffic Sign Recognition
May 28, 2022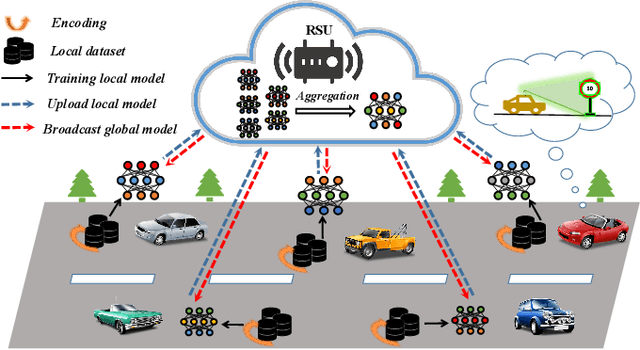
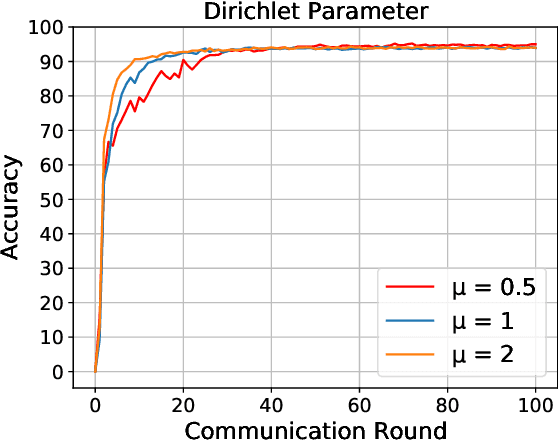
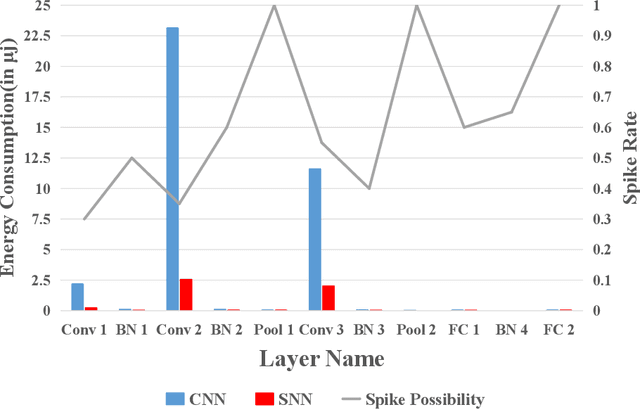
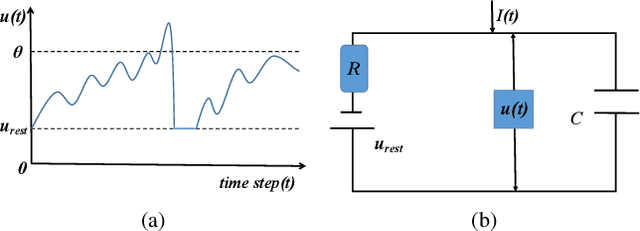
With the gradual popularization of self-driving, it is becoming increasingly important for vehicles to smartly make the right driving decisions and autonomously obey traffic rules by correctly recognizing traffic signs. However, for machine learning-based traffic sign recognition on the Internet of Vehicles (IoV), a large amount of traffic sign data from distributed vehicles is needed to be gathered in a centralized server for model training, which brings serious privacy leakage risk because of traffic sign data containing lots of location privacy information. To address this issue, we first exploit privacy-preserving federated learning to perform collaborative training for accurate recognition models without sharing raw traffic sign data. Nevertheless, due to the limited computing and energy resources of most devices, it is hard for vehicles to continuously undertake complex artificial intelligence tasks. Therefore, we introduce powerful Spike Neural Networks (SNNs) into traffic sign recognition for energy-efficient and fast model training, which is the next generation of neural networks and is practical and well-fitted to IoV scenarios. Furthermore, we design a novel encoding scheme for SNNs based on neuron receptive fields to extract information from the pixel and spatial dimensions of traffic signs to achieve high-accuracy training. Numerical results indicate that the proposed federated SNN outperforms traditional federated convolutional neural networks in terms of accuracy, noise immunity, and energy efficiency as well.
Learn To Remember: Transformer with Recurrent Memory for Document-Level Machine Translation
May 03, 2022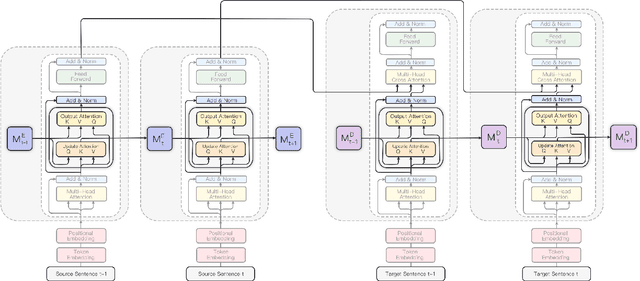
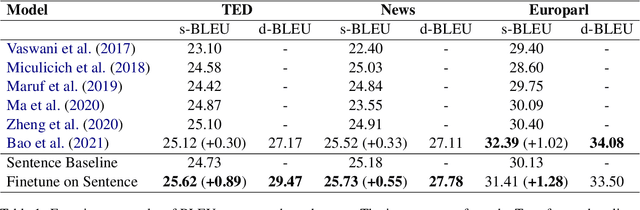

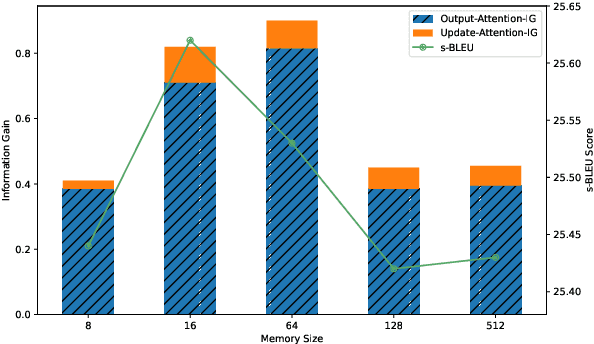
The Transformer architecture has led to significant gains in machine translation. However, most studies focus on only sentence-level translation without considering the context dependency within documents, leading to the inadequacy of document-level coherence. Some recent research tried to mitigate this issue by introducing an additional context encoder or translating with multiple sentences or even the entire document. Such methods may lose the information on the target side or have an increasing computational complexity as documents get longer. To address such problems, we introduce a recurrent memory unit to the vanilla Transformer, which supports the information exchange between the sentence and previous context. The memory unit is recurrently updated by acquiring information from sentences, and passing the aggregated knowledge back to subsequent sentence states. We follow a two-stage training strategy, in which the model is first trained at the sentence level and then finetuned for document-level translation. We conduct experiments on three popular datasets for document-level machine translation and our model has an average improvement of 0.91 s-BLEU over the sentence-level baseline. We also achieve state-of-the-art results on TED and News, outperforming the previous work by 0.36 s-BLEU and 1.49 d-BLEU on average.
Bi-VLDoc: Bidirectional Vision-Language Modeling for Visually-Rich Document Understanding
Jun 27, 2022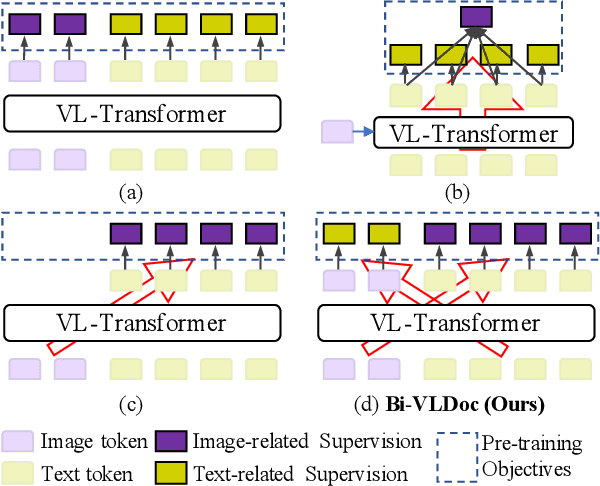
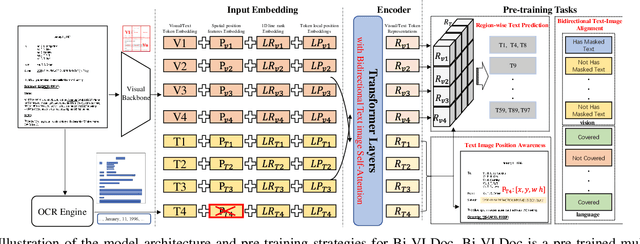
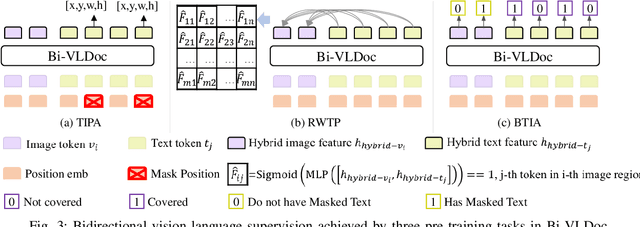
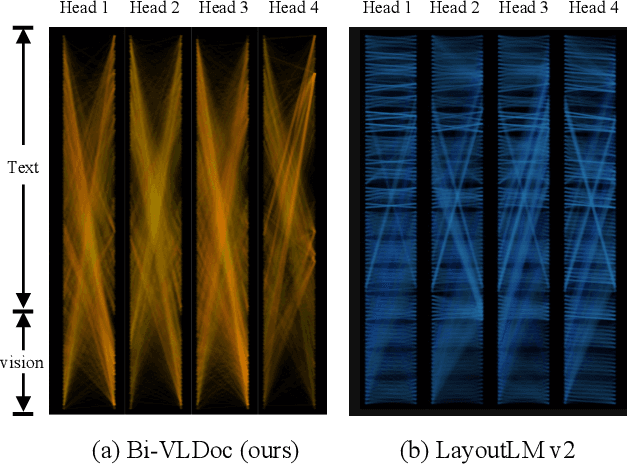
Multi-modal document pre-trained models have proven to be very effective in a variety of visually-rich document understanding (VrDU) tasks. Though existing document pre-trained models have achieved excellent performance on standard benchmarks for VrDU, the way they model and exploit the interactions between vision and language on documents has hindered them from better generalization ability and higher accuracy. In this work, we investigate the problem of vision-language joint representation learning for VrDU mainly from the perspective of supervisory signals. Specifically, a pre-training paradigm called Bi-VLDoc is proposed, in which a bidirectional vision-language supervision strategy and a vision-language hybrid-attention mechanism are devised to fully explore and utilize the interactions between these two modalities, to learn stronger cross-modal document representations with richer semantics. Benefiting from the learned informative cross-modal document representations, Bi-VLDoc significantly advances the state-of-the-art performance on three widely-used document understanding benchmarks, including Form Understanding (from 85.14% to 93.44%), Receipt Information Extraction (from 96.01% to 97.84%), and Document Classification (from 96.08% to 97.12%). On Document Visual QA, Bi-VLDoc achieves the state-of-the-art performance compared to previous single model methods.
Visual grounding of abstract and concrete words: A response to Günther et al. (2020)
Jun 30, 2022

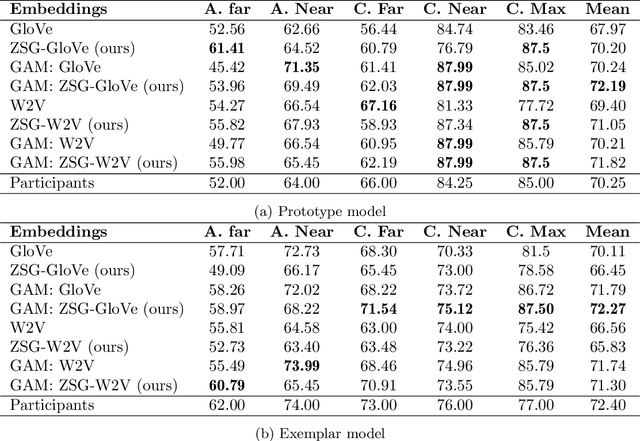

Current computational models capturing words' meaning mostly rely on textual corpora. While these approaches have been successful over the last decades, their lack of grounding in the real world is still an ongoing problem. In this paper, we focus on visual grounding of word embeddings and target two important questions. First, how can language benefit from vision in the process of visual grounding? And second, is there a link between visual grounding and abstract concepts? We investigate these questions by proposing a simple yet effective approach where language benefits from vision specifically with respect to the modeling of both concrete and abstract words. Our model aligns word embeddings with their corresponding visual representation without deteriorating the knowledge captured by textual distributional information. We apply our model to a behavioral experiment reported by G\"unther et al. (2020), which addresses the plausibility of having visual mental representations for abstract words. Our evaluation results show that: (1) It is possible to predict human behaviour to a large degree using purely textual embeddings. (2) Our grounded embeddings model human behavior better compared to their textual counterparts. (3) Abstract concepts benefit from visual grounding implicitly through their connections to concrete concepts, rather than from having corresponding visual representations.
FAST-VQA: Efficient End-to-end Video Quality Assessment with Fragment Sampling
Jul 06, 2022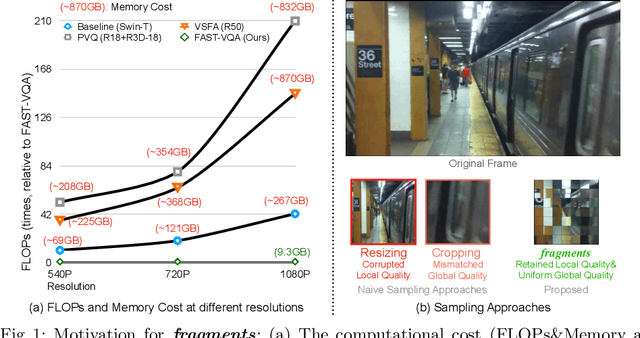
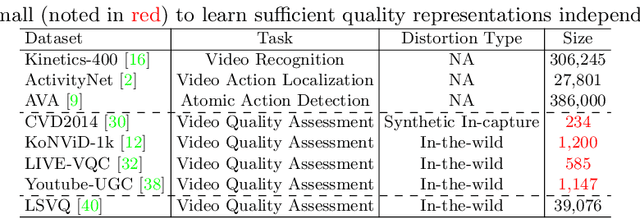


Current deep video quality assessment (VQA) methods are usually with high computational costs when evaluating high-resolution videos. This cost hinders them from learning better video-quality-related representations via end-to-end training. Existing approaches typically consider naive sampling to reduce the computational cost, such as resizing and cropping. However, they obviously corrupt quality-related information in videos and are thus not optimal for learning good representations for VQA. Therefore, there is an eager need to design a new quality-retained sampling scheme for VQA. In this paper, we propose Grid Mini-patch Sampling (GMS), which allows consideration of local quality by sampling patches at their raw resolution and covers global quality with contextual relations via mini-patches sampled in uniform grids. These mini-patches are spliced and aligned temporally, named as fragments. We further build the Fragment Attention Network (FANet) specially designed to accommodate fragments as inputs. Consisting of fragments and FANet, the proposed FrAgment Sample Transformer for VQA (FAST-VQA) enables efficient end-to-end deep VQA and learns effective video-quality-related representations. It improves state-of-the-art accuracy by around 10% while reducing 99.5% FLOPs on 1080P high-resolution videos. The newly learned video-quality-related representations can also be transferred into smaller VQA datasets, boosting performance in these scenarios. Extensive experiments show that FAST-VQA has good performance on inputs of various resolutions while retaining high efficiency. We publish our code at https://github.com/timothyhtimothy/FAST-VQA.
* Will appear on ECCV 2022. 14 Pages