 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Lottery Ticket Hypothesis for Spiking Neural Networks
Jul 04, 2022
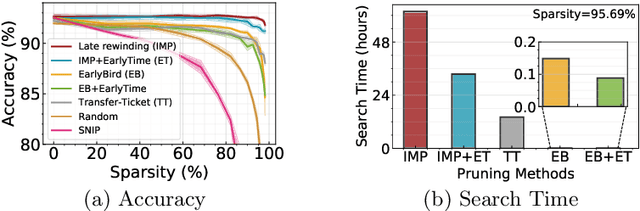
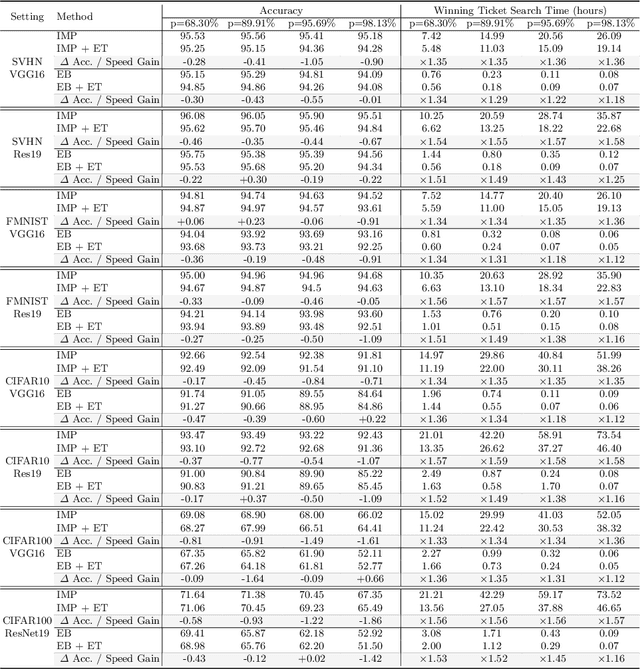
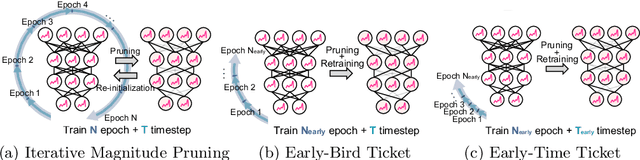
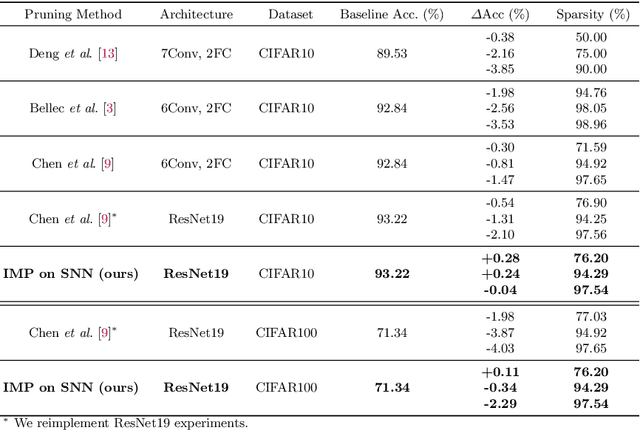
Spiking Neural Networks (SNNs) have recently emerged as a new generation of low-power deep neural networks where binary spikes convey information across multiple timesteps. Pruning for SNNs is highly important as they become deployed on a resource-constraint mobile/edge device. The previous SNN pruning works focus on shallow SNNs (2~6 layers), however, deeper SNNs (>16 layers) are proposed by state-of-the-art SNN works, which is difficult to be compatible with the current pruning work. To scale up a pruning technique toward deep SNNs, we investigate Lottery Ticket Hypothesis (LTH) which states that dense networks contain smaller subnetworks (i.e., winning tickets) that achieve comparable performance to the dense networks. Our studies on LTH reveal that the winning tickets consistently exist in deep SNNs across various datasets and architectures, providing up to 97% sparsity without huge performance degradation. However, the iterative searching process of LTH brings a huge training computational cost when combined with the multiple timesteps of SNNs. To alleviate such heavy searching cost, we propose Early-Time (ET) ticket where we find the important weight connectivity from a smaller number of timesteps. The proposed ET ticket can be seamlessly combined with common pruning techniques for finding winning tickets, such as Iterative Magnitude Pruning (IMP) and Early-Bird (EB) tickets. Our experiment results show that the proposed ET ticket reduces search time by up to 38% compared to IMP or EB methods.
Generative Anomaly Detection for Time Series Datasets
Jun 28, 2022
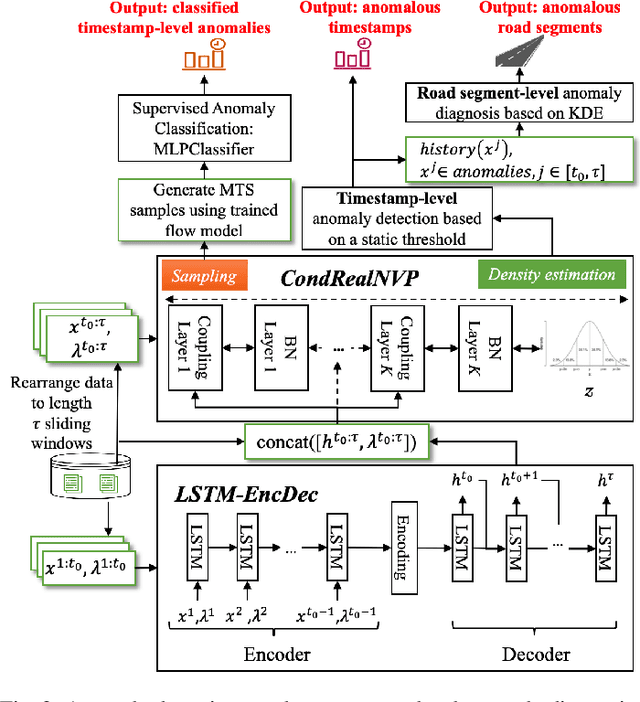

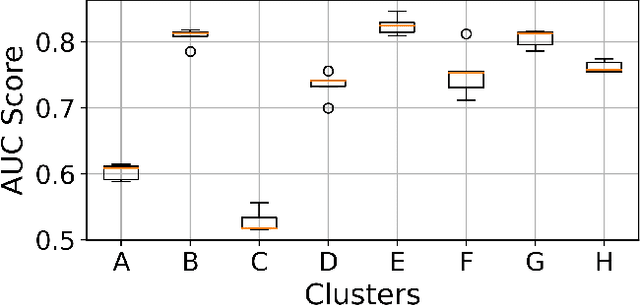
Traffic congestion anomaly detection is of paramount importance in intelligent traffic systems. The goals of transportation agencies are two-fold: to monitor the general traffic conditions in the area of interest and to locate road segments under abnormal congestion states. Modeling congestion patterns can achieve these goals for citywide roadways, which amounts to learning the distribution of multivariate time series (MTS). However, existing works are either not scalable or unable to capture the spatial-temporal information in MTS simultaneously. To this end, we propose a principled and comprehensive framework consisting of a data-driven generative approach that can perform tractable density estimation for detecting traffic anomalies. Our approach first clusters segments in the feature space and then uses conditional normalizing flow to identify anomalous temporal snapshots at the cluster level in an unsupervised setting. Then, we identify anomalies at the segment level by using a kernel density estimator on the anomalous cluster. Extensive experiments on synthetic datasets show that our approach significantly outperforms several state-of-the-art congestion anomaly detection and diagnosis methods in terms of Recall and F1-Score. We also use the generative model to sample labeled data, which can train classifiers in a supervised setting, alleviating the lack of labeled data for anomaly detection in sparse settings.
EigenNoise: A Contrastive Prior to Warm-Start Representations
May 09, 2022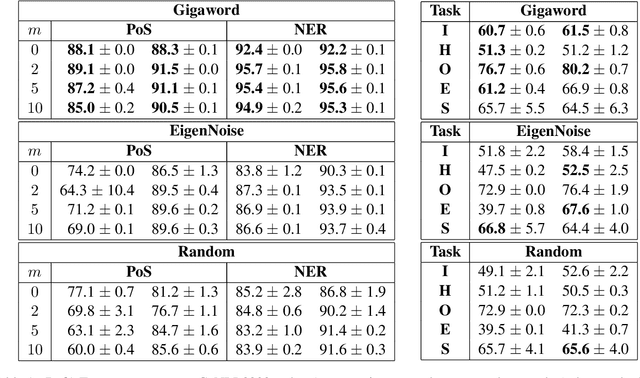
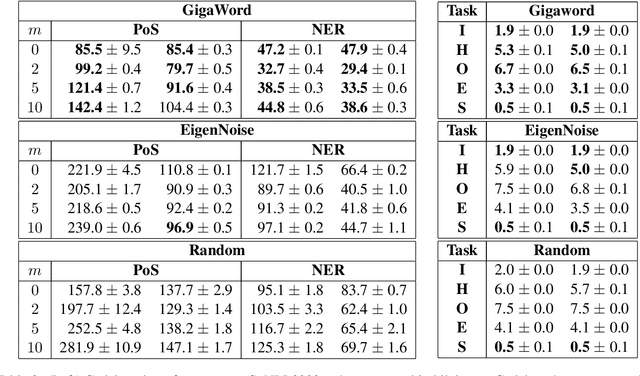
In this work, we present a naive initialization scheme for word vectors based on a dense, independent co-occurrence model and provide preliminary results that suggest it is competitive and warrants further investigation. Specifically, we demonstrate through information-theoretic minimum description length (MDL) probing that our model, EigenNoise, can approach the performance of empirically trained GloVe despite the lack of any pre-training data (in the case of EigenNoise). We present these preliminary results with interest to set the stage for further investigations into how this competitive initialization works without pre-training data, as well as to invite the exploration of more intelligent initialization schemes informed by the theory of harmonic linguistic structure. Our application of this theory likewise contributes a novel (and effective) interpretation of recent discoveries which have elucidated the underlying distributional information that linguistic representations capture from data and contrast distributions.
A Pre-Computing Solution for Online Advertising Serving
Jul 04, 2022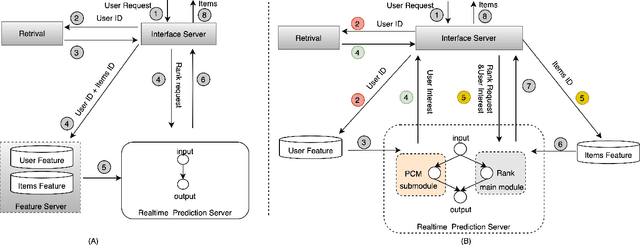

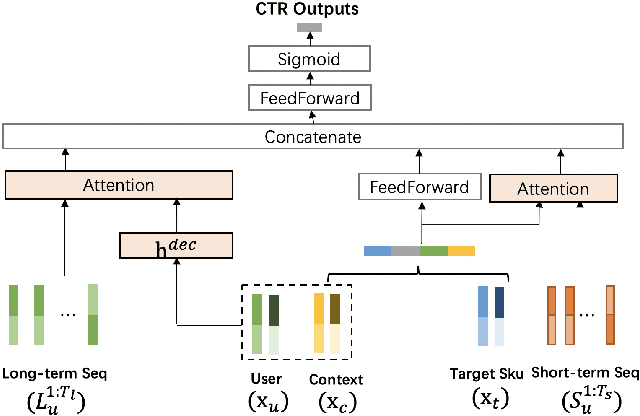
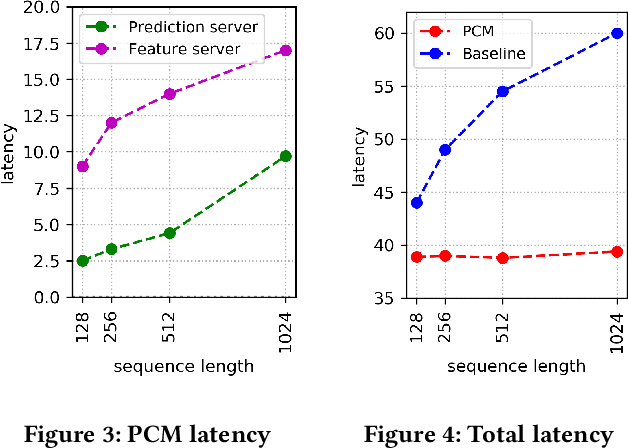
Click-Through Rate (CTR) prediction plays a key role in online advertising systems and online advertising. Constrained by strict requirements on online inference efficiency, it is often difficult to deploy useful but computationally intensive modules such as long-term behaviors modeling. Most recent works attempt to mitigate the online calculation issue of long historical behaviors by adopting two-stage methods to balance online efficiency and effectiveness. However, the information gaps caused by two-stage modeling may result in a diminished performance gain. In this work, we propose a novel framework called PCM to address this challenge in the view of system deployment. By deploying a pre-computing sub-module parallel to the retrieval stage, our PCM effectively reduces overall inference time which enables complex modeling in the ranking stage. Comprehensive offline and online experiments are conducted on the long-term user behaviors module to validate the effectiveness of our solution for the complex models. Moreover, our framework has been deployed into a large-scale real-world E-commerce system serving the main interface of hundreds of millions of active users, by deploying long sequential user behavior model in PCM. We achieved a 3\% CTR gain, with almost no increase in the ranking latency, compared to the base framework demonstrated from the online A/B test. To our knowledge, we are the first to propose an end-to-end solution for online training and deployment on complex CTR models from the system framework side.
Nested Named Entity Recognition as Holistic Structure Parsing
Apr 17, 2022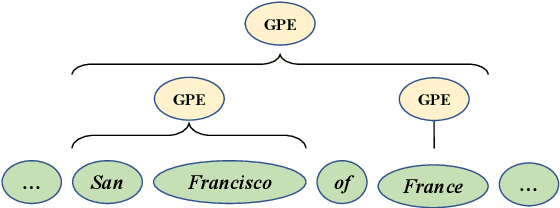
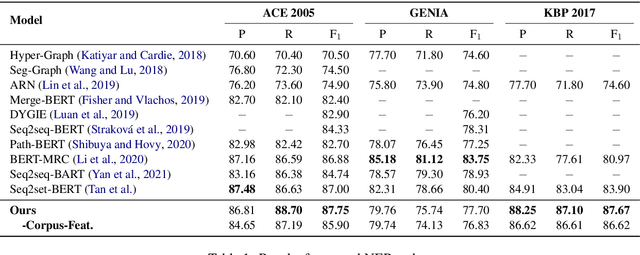
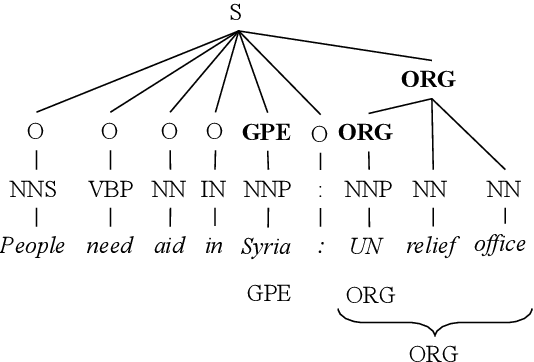
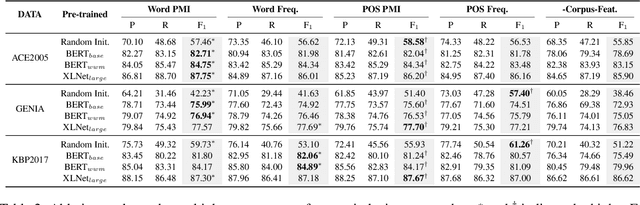
As a fundamental natural language processing task and one of core knowledge extraction techniques, named entity recognition (NER) is widely used to extract information from texts for downstream tasks. Nested NER is a branch of NER in which the named entities (NEs) are nested with each other. However, most of the previous studies on nested NER usually apply linear structure to model the nested NEs which are actually accommodated in a hierarchical structure. Thus in order to address this mismatch, this work models the full nested NEs in a sentence as a holistic structure, then we propose a holistic structure parsing algorithm to disclose the entire NEs once for all. Besides, there is no research on applying corpus-level information to NER currently. To make up for the loss of this information, we introduce Point-wise Mutual Information (PMI) and other frequency features from corpus-aware statistics for even better performance by holistic modeling from sentence-level to corpus-level. Experiments show that our model yields promising results on widely-used benchmarks which approach or even achieve state-of-the-art. Further empirical studies show that our proposed corpus-aware features can substantially improve NER domain adaptation, which demonstrates the surprising advantage of our proposed corpus-level holistic structure modeling.
Report: EPOC Emotiv EEG Basics
Jun 17, 2022

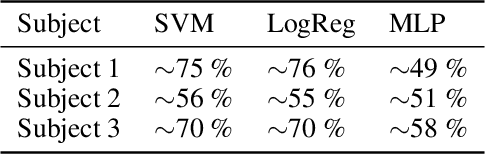
This document provides some basic guidance to start working with the EPOC Emotiv neuroheadset device and describes how to use it to perform basic Brain-Computer Interface (BCI) research. A brief tutorial on how to set up the device, from its electrophysiological point of view, as well as a description and practical code to perform some basic analysis, is explained. A basic experiment is introduced to detect one of the oldest and, indeed, quite still valuable electrophysiological correlate, visual occipital alpha waves, or Berger Rhythm. An additional experiment is expounded where the power spectrum of alpha waves is reduced when a subject is affected by background cognitive disturbances. This document also briefs about the extraction of information by using the EPOC Emotiv library and also with python Emokit package. This report presents a basic guide on how to use EEGLAB and MATLAB, as well as python stack to perform the neurophysiological analysis. Finally, a basic analysis on different feature extraction and classification methods is provided.
Variable Functioning and Its Application to Large Scale Steel Frame Design Optimization
May 15, 2022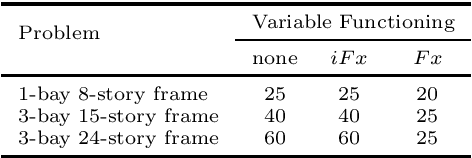
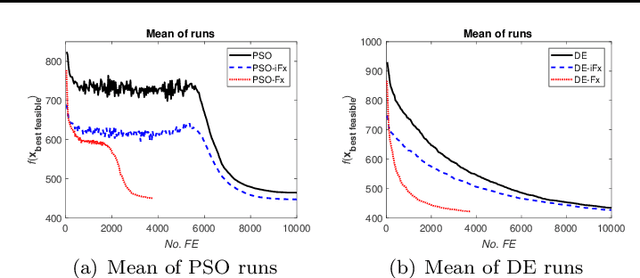
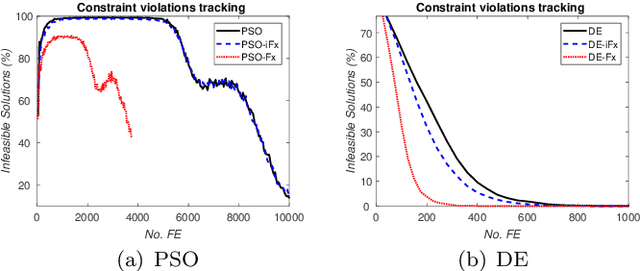
To solve complex real-world problems, heuristics and concept-based approaches can be used in order to incorporate information into the problem. In this study, a concept-based approach called variable functioning Fx is introduced to reduce the optimization variables and narrow down the search space. In this method, the relationships among one or more subset of variables are defined with functions using information prior to optimization; thus, instead of modifying the variables in the search process, the function variables are optimized. By using problem structure analysis technique and engineering expert knowledge, the $Fx$ method is used to enhance the steel frame design optimization process as a complex real-world problem. The proposed approach is coupled with particle swarm optimization and differential evolution algorithms and used for three case studies. The algorithms are applied to optimize the case studies by considering the relationships among column cross-section areas. The results show that $Fx$ can significantly improve both the convergence rate and the final design of a frame structure, even if it is only used for seeding.
Blind Orthogonal Least Squares based Compressive Spectrum Sensing
Apr 11, 2022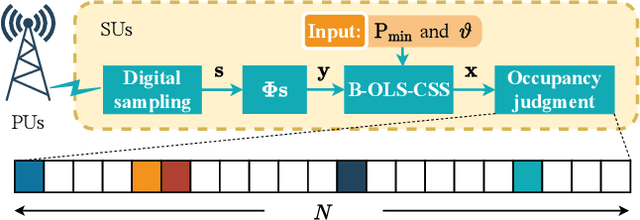
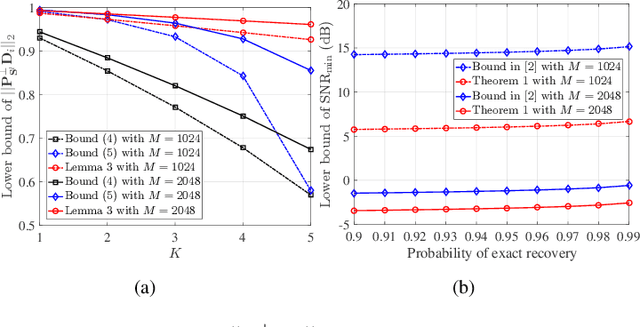
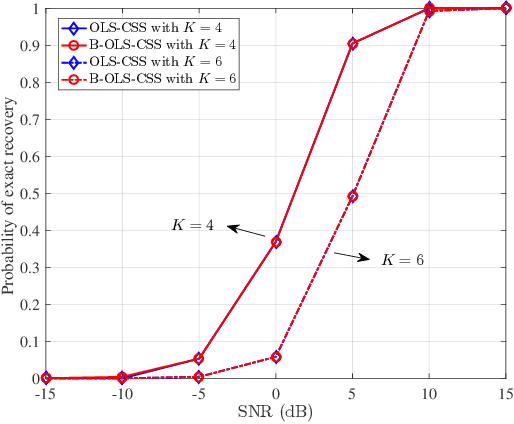
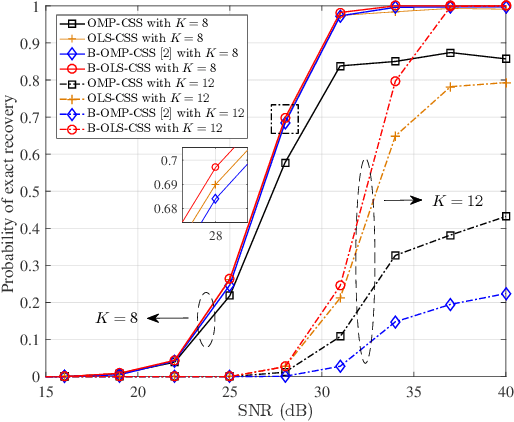
Compressive spectrum sensing (CSS) has been widely studied in wideband cognitive radios, benefiting from the reduction of sampling rate via compressive sensing (CS) technology. However, the sensing performance of most existing CSS excessively relies on the prior information such as spectrum sparsity or noise variance. Thus, a key challenge in practical CSS is how to work effectively even in the absence of such information. In this paper, we propose a blind orthogonal least squares based CSS algorithm (B-OLS-CSS), which functions properly without the requirement of prior information. Specifically, we develop a novel blind stopping rule for the OLS algorithm based on its probabilistic recovery condition. This innovative rule gets rid of the need of the spectrum sparsity or noise information, but only requires the computational-feasible mutual incoherence property of the given measurement matrix. Our theoretical analysis indicates that the signal-to-noise ratio required by the proposed B-OLS-CSS for achieving a certain sensing accuracy is relaxed than that by the benchmark CSS using the OMP algorithm, which is verified by extensive simulation results.
BOSS: A Benchmark for Human Belief Prediction in Object-context Scenarios
Jun 21, 2022

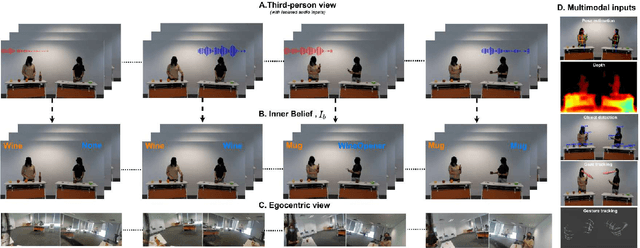

Humans with an average level of social cognition can infer the beliefs of others based solely on the nonverbal communication signals (e.g. gaze, gesture, pose and contextual information) exhibited during social interactions. This social cognitive ability to predict human beliefs and intentions is more important than ever for ensuring safe human-robot interaction and collaboration. This paper uses the combined knowledge of Theory of Mind (ToM) and Object-Context Relations to investigate methods for enhancing collaboration between humans and autonomous systems in environments where verbal communication is prohibited. We propose a novel and challenging multimodal video dataset for assessing the capability of artificial intelligence (AI) systems in predicting human belief states in an object-context scenario. The proposed dataset consists of precise labelling of human belief state ground-truth and multimodal inputs replicating all nonverbal communication inputs captured by human perception. We further evaluate our dataset with existing deep learning models and provide new insights into the effects of the various input modalities and object-context relations on the performance of the baseline models.
Clothes-Changing Person Re-identification with RGB Modality Only
Apr 14, 2022
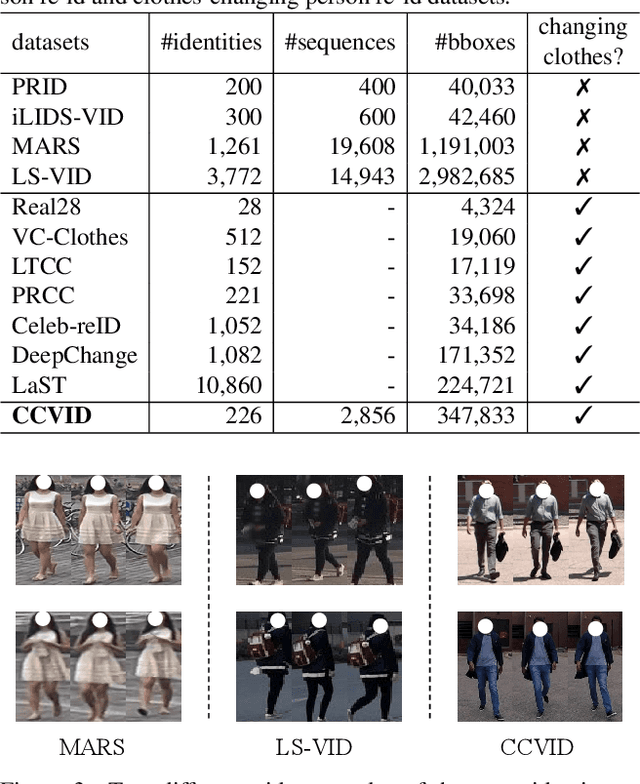
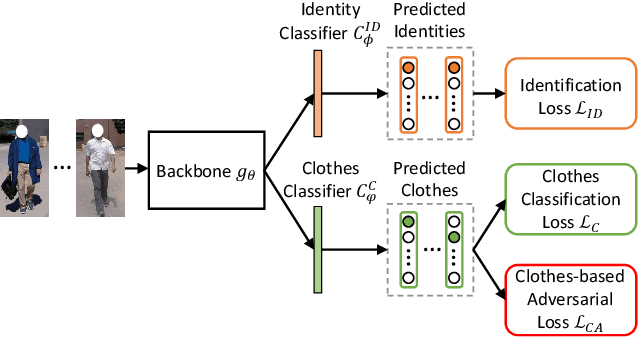
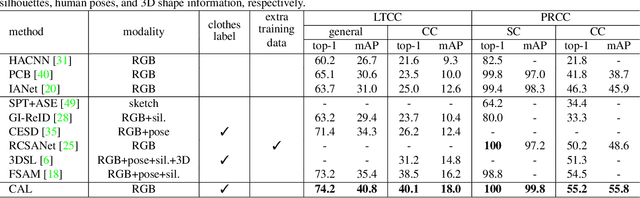
The key to address clothes-changing person re-identification (re-id) is to extract clothes-irrelevant features, e.g., face, hairstyle, body shape, and gait. Most current works mainly focus on modeling body shape from multi-modality information (e.g., silhouettes and sketches), but do not make full use of the clothes-irrelevant information in the original RGB images. In this paper, we propose a Clothes-based Adversarial Loss (CAL) to mine clothes-irrelevant features from the original RGB images by penalizing the predictive power of re-id model w.r.t. clothes. Extensive experiments demonstrate that using RGB images only, CAL outperforms all state-of-the-art methods on widely-used clothes-changing person re-id benchmarks. Besides, compared with images, videos contain richer appearance and additional temporal information, which can be used to model proper spatiotemporal patterns to assist clothes-changing re-id. Since there is no publicly available clothes-changing video re-id dataset, we contribute a new dataset named CCVID and show that there exists much room for improvement in modeling spatiotemporal information. The code and new dataset are available at: https://github.com/guxinqian/Simple-CCReID.