 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Open vs Closed-ended questions in attitudinal surveys -- comparing, combining, and interpreting using natural language processing
May 03, 2022

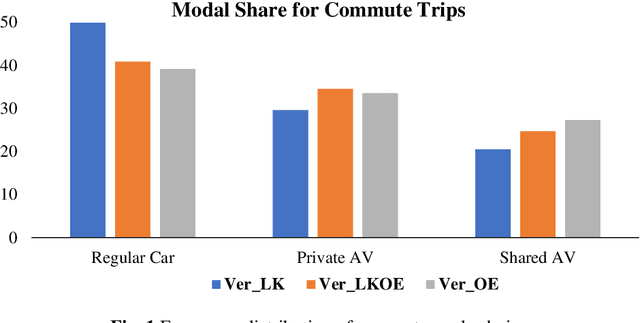
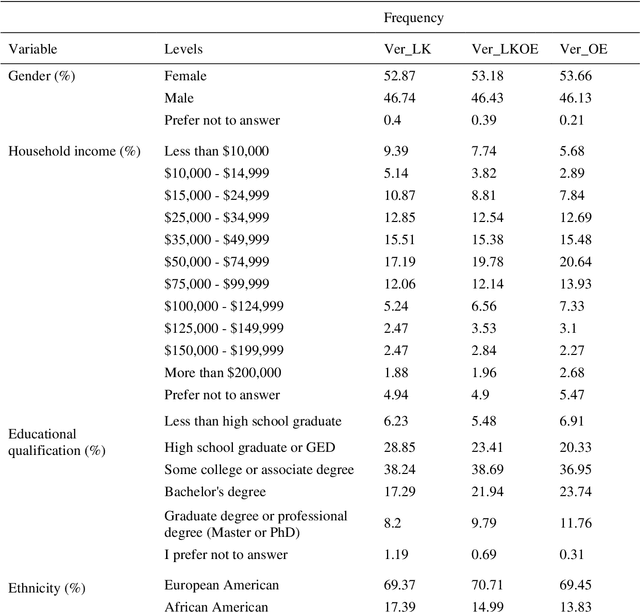
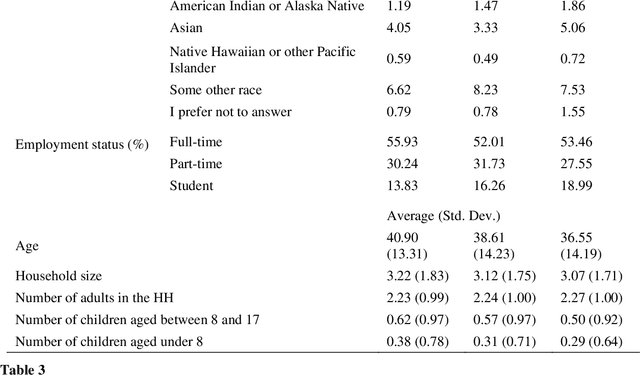
To improve the traveling experience, researchers have been analyzing the role of attitudes in travel behavior modeling. Although most researchers use closed-ended surveys, the appropriate method to measure attitudes is debatable. Topic Modeling could significantly reduce the time to extract information from open-ended responses and eliminate subjective bias, thereby alleviating analyst concerns. Our research uses Topic Modeling to extract information from open-ended questions and compare its performance with closed-ended responses. Furthermore, some respondents might prefer answering questions using their preferred questionnaire type. So, we propose a modeling framework that allows respondents to use their preferred questionnaire type to answer the survey and enable analysts to use the modeling frameworks of their choice to predict behavior. We demonstrate this using a dataset collected from the USA that measures the intention to use Autonomous Vehicles for commute trips. Respondents were presented with alternative questionnaire versions (open- and closed- ended). Since our objective was also to compare the performance of alternative questionnaire versions, the survey was designed to eliminate influences resulting from statements, behavioral framework, and the choice experiment. Results indicate the suitability of using Topic Modeling to extract information from open-ended responses; however, the models estimated using the closed-ended questions perform better compared to them. Besides, the proposed model performs better compared to the models used currently. Furthermore, our proposed framework will allow respondents to choose the questionnaire type to answer, which could be particularly beneficial to them when using voice-based surveys.
Satellite-based high-resolution maps of cocoa planted area for Côte d'Ivoire and Ghana
Jun 13, 2022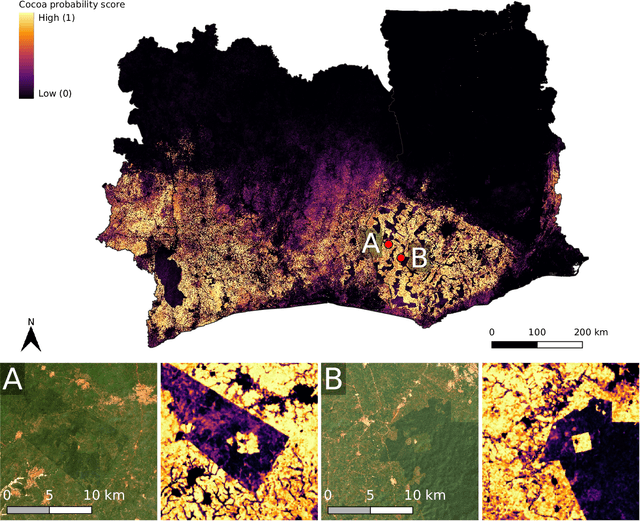
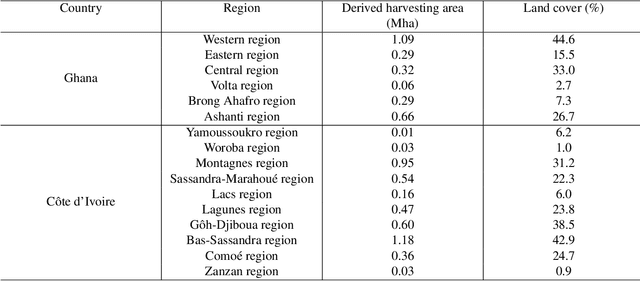
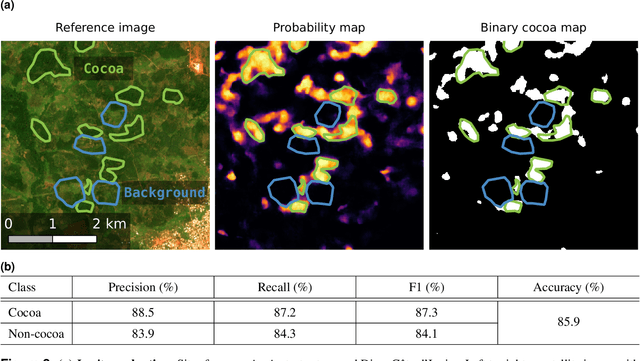
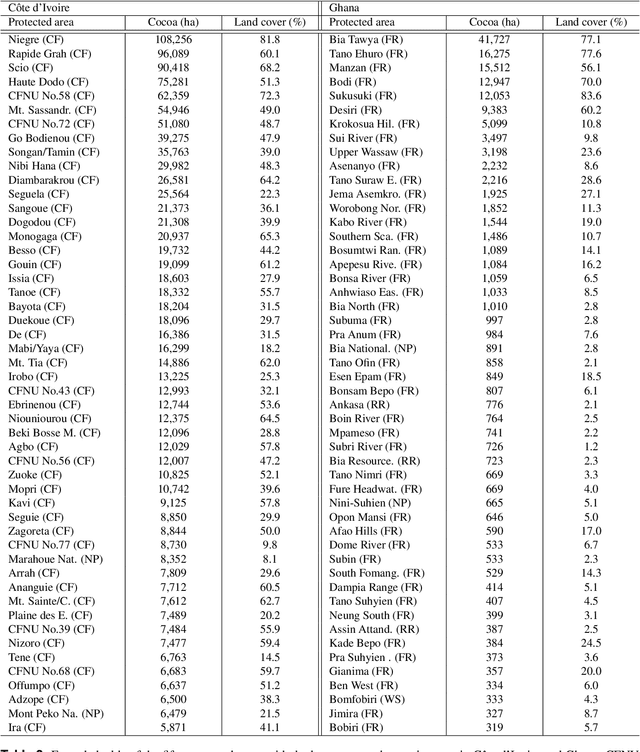
C\^ote d'Ivoire and Ghana, the world's largest producers of cocoa, account for two thirds of the global cocoa production. In both countries, cocoa is the primary perennial crop, providing income to almost two million farmers. Yet precise maps of cocoa planted area are missing, hindering accurate quantification of expansion in protected areas, production and yields, and limiting information available for improved sustainability governance. Here, we combine cocoa plantation data with publicly available satellite imagery in a deep learning framework and create high-resolution maps of cocoa plantations for both countries, validated in situ. Our results suggest that cocoa cultivation is an underlying driver of over 37% and 13% of forest loss in protected areas in C\^ote d'Ivoire and Ghana, respectively, and that official reports substantially underestimate the planted area, up to 40% in Ghana. These maps serve as a crucial building block to advance understanding of conservation and economic development in cocoa producing regions.
Learning to Look Inside: Augmenting Token-Based Encoders with Character-Level Information
Aug 01, 2021
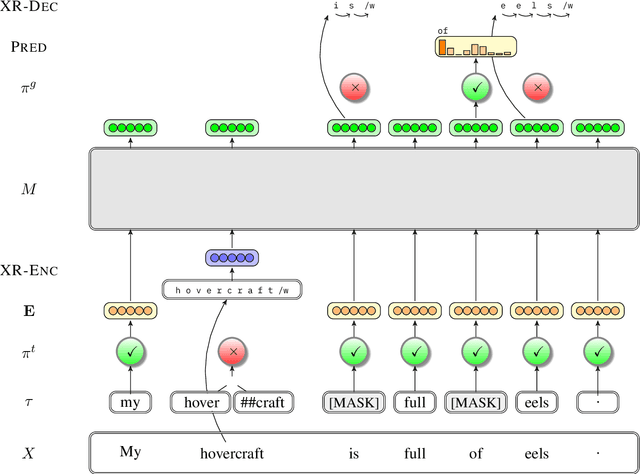

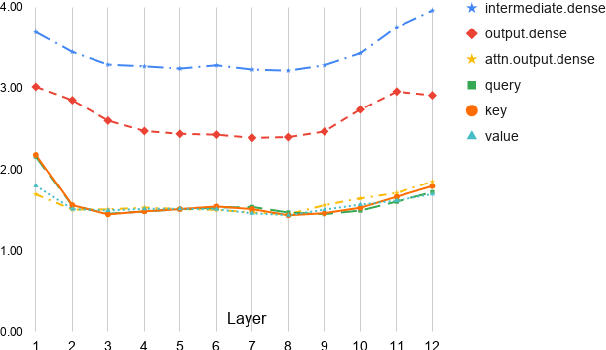
Commonly-used transformer language models depend on a tokenization schema which sets an unchangeable subword vocabulary prior to pre-training, destined to be applied to all downstream tasks regardless of domain shift, novel word formations, or other sources of vocabulary mismatch. Recent work has shown that "token-free" models can be trained directly on characters or bytes, but training these models from scratch requires substantial computational resources, and this implies discarding the many domain-specific models that were trained on tokens. In this paper, we present XRayEmb, a method for retrofitting existing token-based models with character-level information. XRayEmb is composed of a character-level "encoder" that computes vector representations of character sequences, and a generative component that decodes from the internal representation to a character sequence. We show that incorporating XRayEmb's learned vectors into sequences of pre-trained token embeddings helps performance on both autoregressive and masked pre-trained transformer architectures and on both sequence-level and sequence tagging tasks, particularly on non-standard English text.
OptWedge: Cognitive Optimized Guidance toward Off-screen POIs
Jun 09, 2022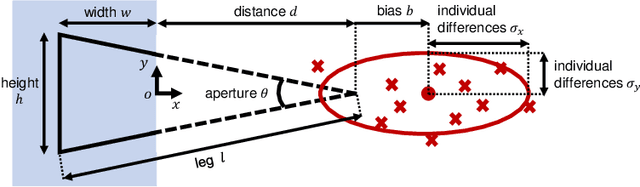


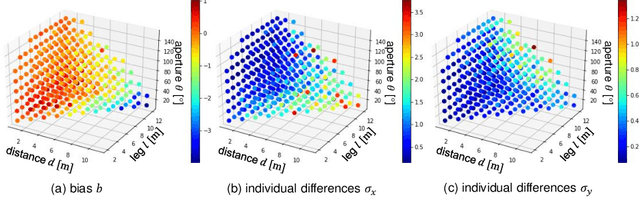
Guiding off-screen points of interest (POIs) is a practical way of providing additional information to users of small-screen devices, such as smart devices and head-mounted displays. Popular previous methods involve displaying a primitive figure referred to as Wedge on the screen for users to estimate off-screen POI on the invisible vertex. Because they utilize a cognitive process referred to as amodal completion, where users can imagine the entire figure even when a part of it is occluded, localization accuracy is influenced by bias and individual differences. To improve the accuracy, we propose to optimize the figure using a cognitive cost that considers the influence. We also design two types of optimizations with different parameters: unbiased OptWedge (UOW) and biased OptWedge (BOW). Experimental results indicate that OptWedge achieves more accurate guidance for a close distance compared to heuristics approach.
Interpretable Self-supervised Multi-task Learning for COVID-19 Information Retrieval and Extraction
Jun 15, 2021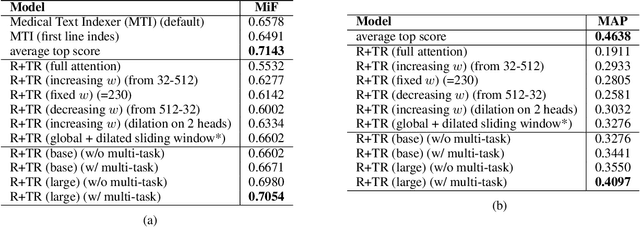


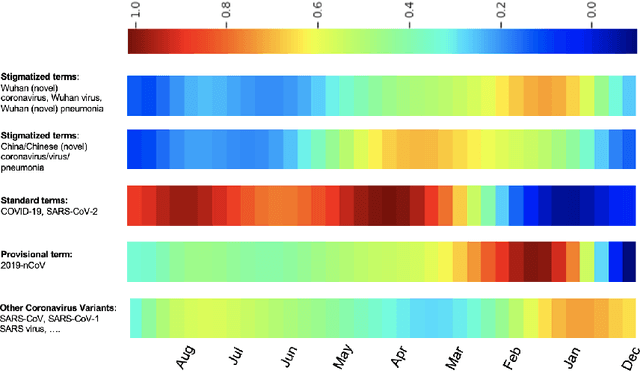
The rapidly evolving literature of COVID-19 related articles makes it challenging for NLP models to be effectively trained for information retrieval and extraction with the corresponding labeled data that follows the current distribution of the pandemic. On the other hand, due to the uncertainty of the situation, human experts' supervision would always be required to double check the decision making of these models highlighting the importance of interpretability. In the light of these challenges, this study proposes an interpretable self-supervised multi-task learning model to jointly and effectively tackle the tasks of information retrieval (IR) and extraction (IE) during the current emergency health crisis situation. Our results show that our model effectively leverage the multi-task and self-supervised learning to improve generalization, data efficiency and robustness to the ongoing dataset shift problem. Our model outperforms baselines in IE and IR tasks, respectively by micro-f score of 0.08 (LCA-F score of 0.05), and MAP of 0.05 on average. In IE the zero- and few-shot learning performances are on average 0.32 and 0.19 micro-f score higher than those of the baselines.
Strategic Representation
Jun 17, 2022
Humans have come to rely on machines for reducing excessive information to manageable representations. But this reliance can be abused -- strategic machines might craft representations that manipulate their users. How can a user make good choices based on strategic representations? We formalize this as a learning problem, and pursue algorithms for decision-making that are robust to manipulation. In our main setting of interest, the system represents attributes of an item to the user, who then decides whether or not to consume. We model this interaction through the lens of strategic classification (Hardt et al. 2016), reversed: the user, who learns, plays first; and the system, which responds, plays second. The system must respond with representations that reveal `nothing but the truth' but need not reveal the entire truth. Thus, the user faces the problem of learning set functions under strategic subset selection, which presents distinct algorithmic and statistical challenges. Our main result is a learning algorithm that minimizes error despite strategic representations, and our theoretical analysis sheds light on the trade-off between learning effort and susceptibility to manipulation.
Resonant Tunnelling Diode Nano-Optoelectronic Spiking Nodes For Neuromorphic Information Processing
Jul 14, 2021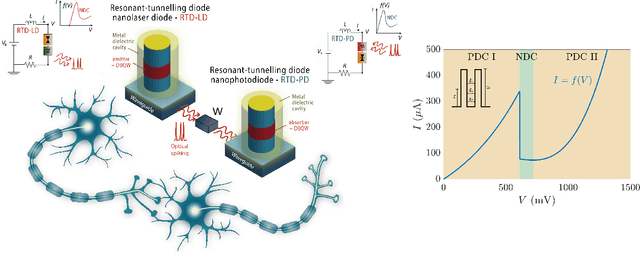
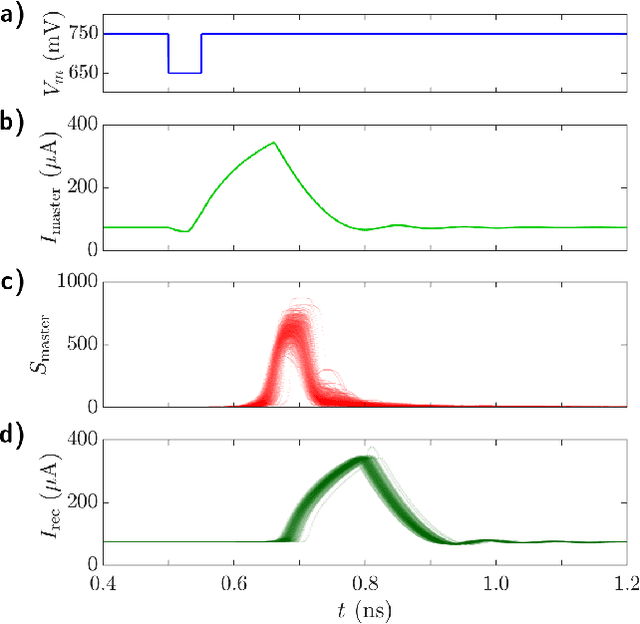
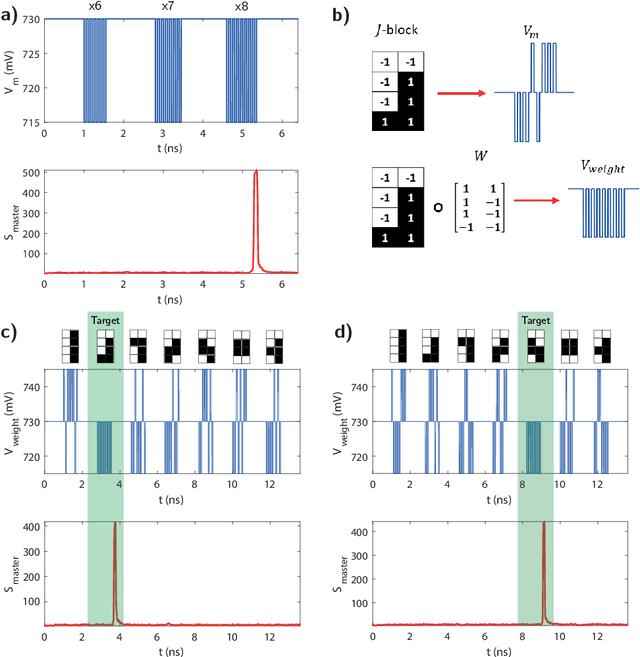
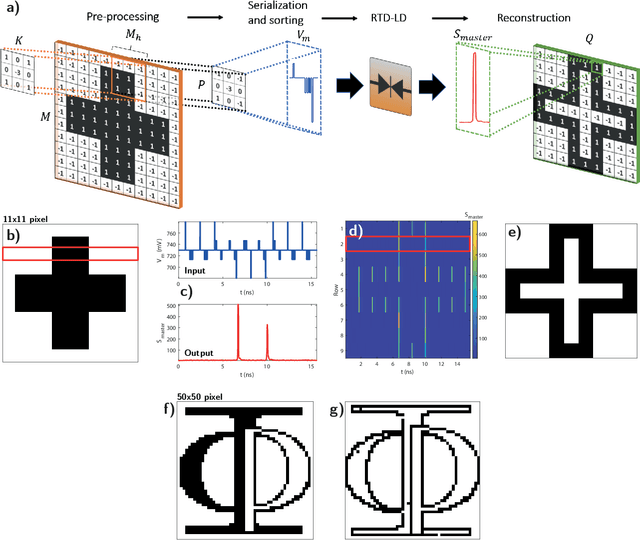
In this work, we introduce an optoelectronic spiking artificial neuron capable of operating at ultrafast rates ($\approx$ 100 ps/optical spike) and with low energy consumption ($<$ pJ/spike). The proposed system combines an excitable resonant tunnelling diode (RTD) element exhibiting negative differential conductance, coupled to a nanoscale light source (forming a master node) or a photodetector (forming a receiver node). We study numerically the spiking dynamical responses and information propagation functionality of an interconnected master-receiver RTD node system. Using the key functionality of pulse thresholding and integration, we utilize a single node to classify sequential pulse patterns and perform convolutional functionality for image feature (edge) recognition. We also demonstrate an optically-interconnected spiking neural network model for processing of spatiotemporal data at over 10 Gbps with high inference accuracy. Finally, we demonstrate an off-chip supervised learning approach utilizing spike-timing dependent plasticity for the RTD-enabled photonic spiking neural network. These results demonstrate the potential and viability of RTD spiking nodes for low footprint, low energy, high-speed optoelectronic realization of neuromorphic hardware.
Multiformer: A Head-Configurable Transformer-Based Model for Direct Speech Translation
May 14, 2022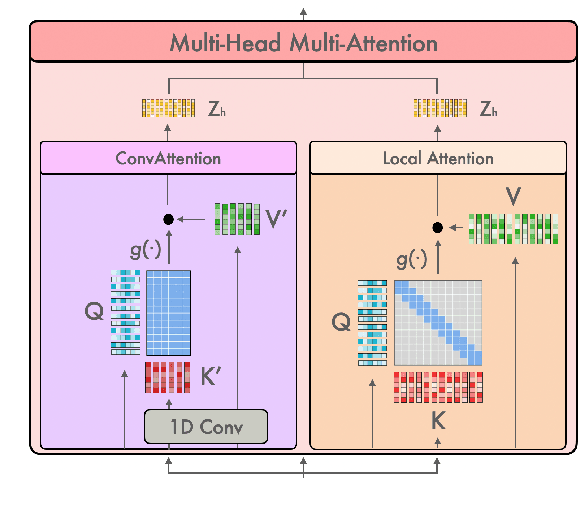
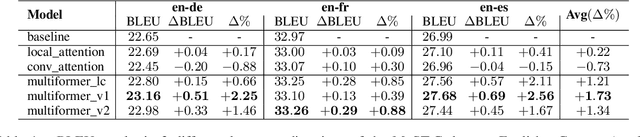
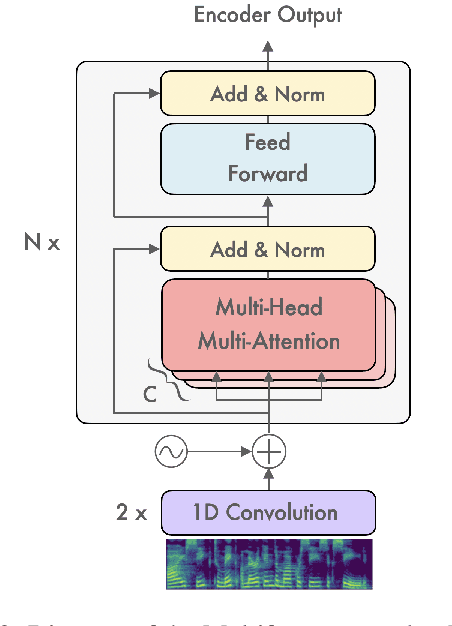
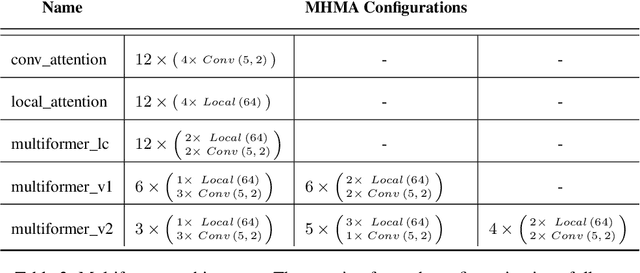
Transformer-based models have been achieving state-of-the-art results in several fields of Natural Language Processing. However, its direct application to speech tasks is not trivial. The nature of this sequences carries problems such as long sequence lengths and redundancy between adjacent tokens. Therefore, we believe that regular self-attention mechanism might not be well suited for it. Different approaches have been proposed to overcome these problems, such as the use of efficient attention mechanisms. However, the use of these methods usually comes with a cost, which is a performance reduction caused by information loss. In this study, we present the Multiformer, a Transformer-based model which allows the use of different attention mechanisms on each head. By doing this, the model is able to bias the self-attention towards the extraction of more diverse token interactions, and the information loss is reduced. Finally, we perform an analysis of the head contributions, and we observe that those architectures where all heads relevance is uniformly distributed obtain better results. Our results show that mixing attention patterns along the different heads and layers outperforms our baseline by up to 0.7 BLEU.
Efficient and Accurate Top-$K$ Recovery from Choice Data
Jun 23, 2022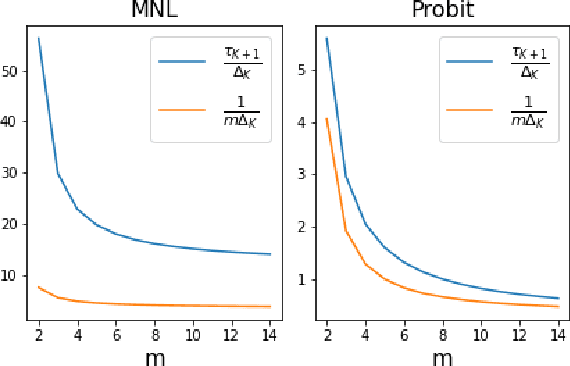
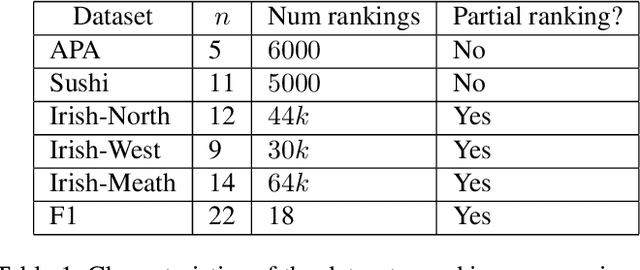
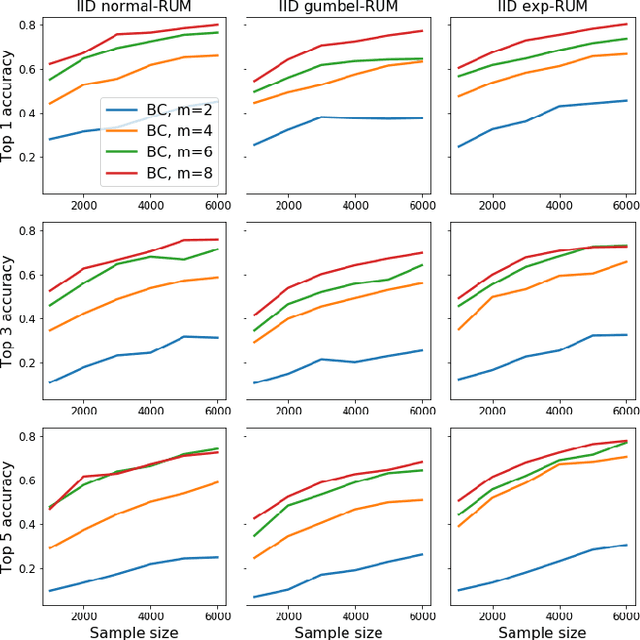
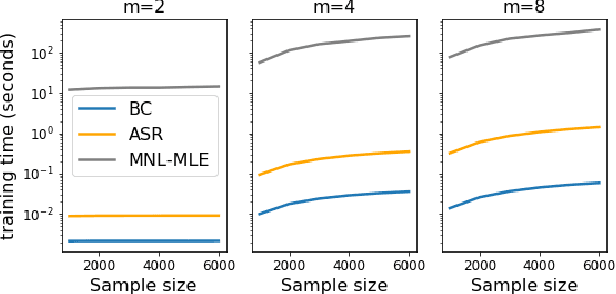
The intersection of learning to rank and choice modeling is an active area of research with applications in e-commerce, information retrieval and the social sciences. In some applications such as recommendation systems, the statistician is primarily interested in recovering the set of the top ranked items from a large pool of items as efficiently as possible using passively collected discrete choice data, i.e., the user picks one item from a set of multiple items. Motivated by this practical consideration, we propose the choice-based Borda count algorithm as a fast and accurate ranking algorithm for top $K$-recovery i.e., correctly identifying all of the top $K$ items. We show that the choice-based Borda count algorithm has optimal sample complexity for top-$K$ recovery under a broad class of random utility models. We prove that in the limit, the choice-based Borda count algorithm produces the same top-$K$ estimate as the commonly used Maximum Likelihood Estimate method but the former's speed and simplicity brings considerable advantages in practice. Experiments on both synthetic and real datasets show that the counting algorithm is competitive with commonly used ranking algorithms in terms of accuracy while being several orders of magnitude faster.
Detecting Schizophrenia with 3D Structural Brain MRI Using Deep Learning
Jun 26, 2022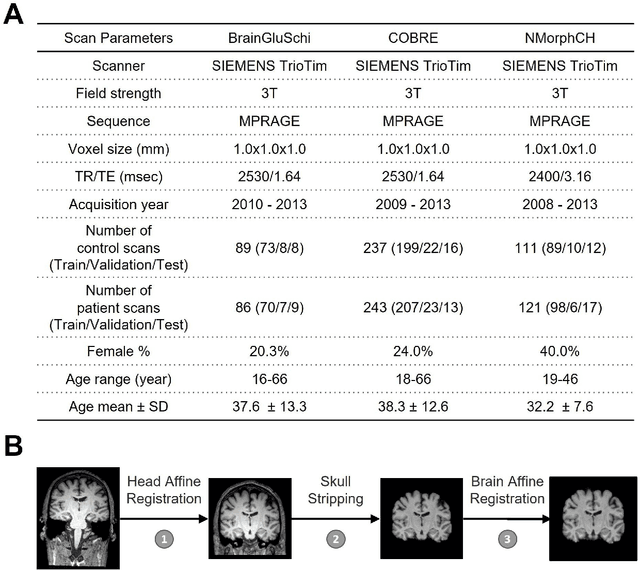
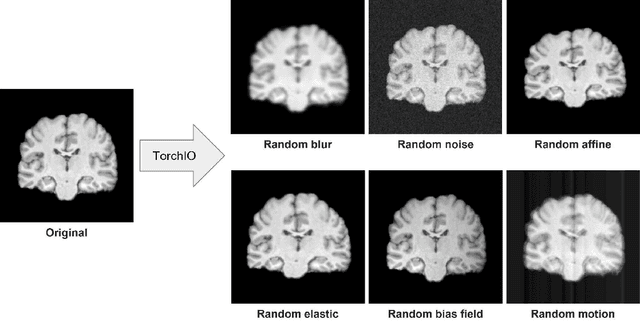
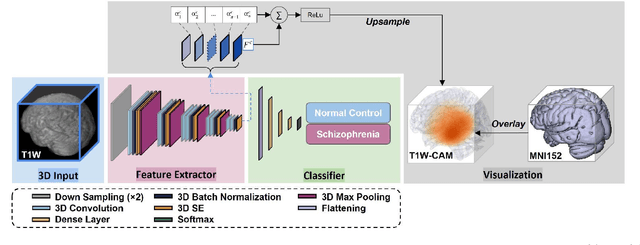
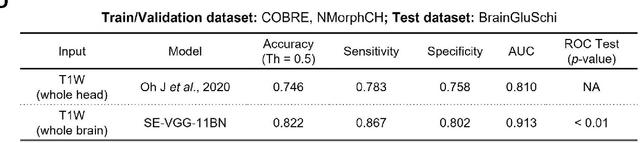
Schizophrenia is a chronic neuropsychiatric disorder that causes distinct structural alterations within the brain. We hypothesize that deep learning applied to a structural neuroimaging dataset could detect disease-related alteration and improve classification and diagnostic accuracy. We tested this hypothesis using a single, widely available, and conventional T1-weighted MRI scan, from which we extracted the 3D whole-brain structure using standard post-processing methods. A deep learning model was then developed, optimized, and evaluated on three open datasets with T1-weighted MRI scans of patients with schizophrenia. Our proposed model outperformed the benchmark model, which was also trained with structural MR images using a 3D CNN architecture. Our model is capable of almost perfectly (area under the ROC curve = 0.987) distinguishing schizophrenia patients from healthy controls on unseen structural MRI scans. Regional analysis localized subcortical regions and ventricles as the most predictive brain regions. Subcortical structures serve a pivotal role in cognitive, affective, and social functions in humans, and structural abnormalities of these regions have been associated with schizophrenia. Our finding corroborates that schizophrenia is associated with widespread alterations in subcortical brain structure and the subcortical structural information provides prominent features in diagnostic classification. Together, these results further demonstrate the potential of deep learning to improve schizophrenia diagnosis and identify its structural neuroimaging signatures from a single, standard T1-weighted brain MRI.