 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hyperspectral image reconstruction for spectral camera based on ghost imaging via sparsity constraints using V-DUnet
Jun 28, 2022
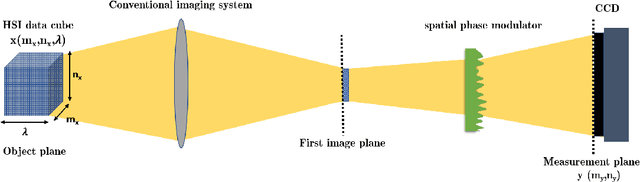
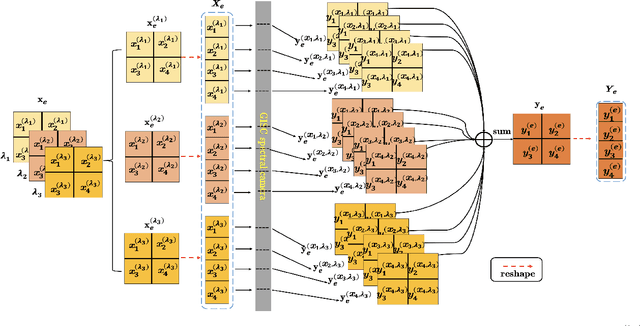
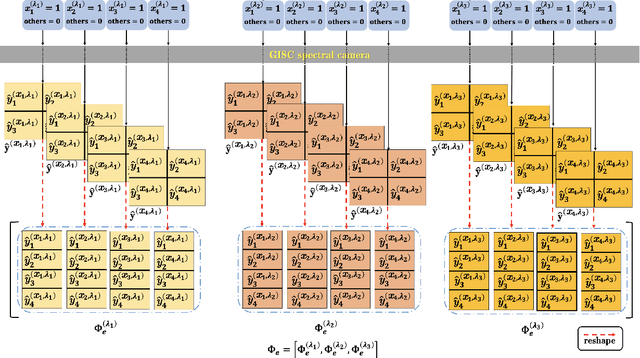
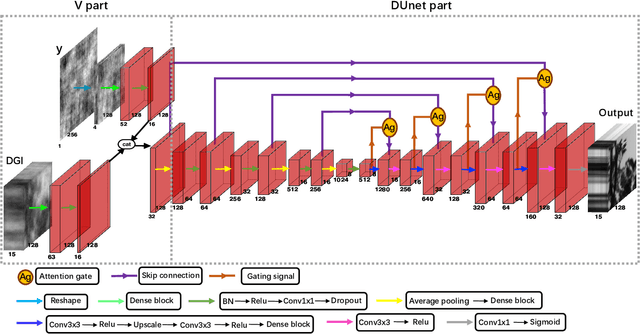
Spectral camera based on ghost imaging via sparsity constraints (GISC spectral camera) obtains three-dimensional (3D) hyperspectral information with two-dimensional (2D) compressive measurements in a single shot, which has attracted much attention in recent years. However, its imaging quality and real-time performance of reconstruction still need to be further improved. Recently, deep learning has shown great potential in improving the reconstruction quality and reconstruction speed for computational imaging. When applying deep learning into GISC spectral camera, there are several challenges need to be solved: 1) how to deal with the large amount of 3D hyperspectral data, 2) how to reduce the influence caused by the uncertainty of the random reference measurements, 3) how to improve the reconstructed image quality as far as possible. In this paper, we present an end-to-end V-DUnet for the reconstruction of 3D hyperspectral data in GISC spectral camera. To reduce the influence caused by the uncertainty of the measurement matrix and enhance the reconstructed image quality, both differential ghost imaging results and the detected measurements are sent into the network's inputs. Compared with compressive sensing algorithm, such as PICHCS and TwIST, it not only significantly improves the imaging quality with high noise immunity, but also speeds up the reconstruction time by more than two orders of magnitude.
Few-Shot Fine-Grained Entity Typing with Automatic Label Interpretation and Instance Generation
Jun 28, 2022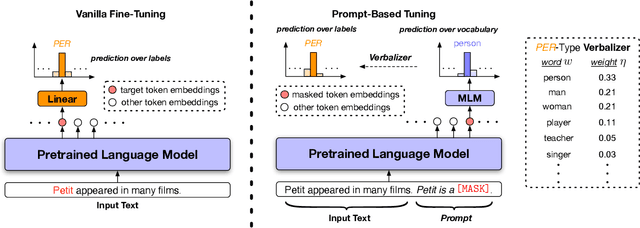
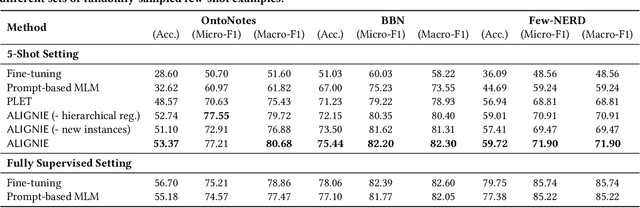
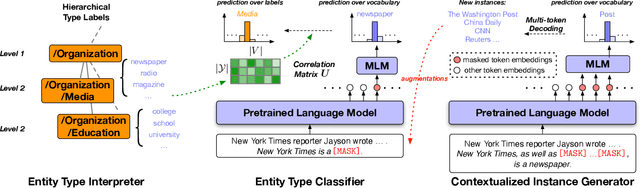
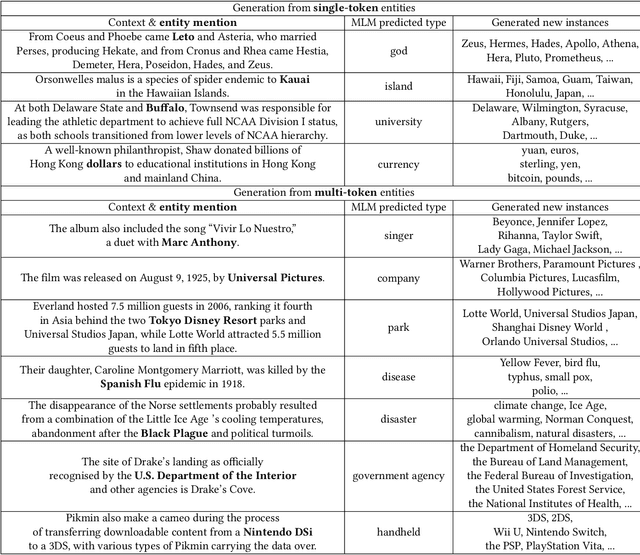
We study the problem of few-shot Fine-grained Entity Typing (FET), where only a few annotated entity mentions with contexts are given for each entity type. Recently, prompt-based tuning has demonstrated superior performance to standard fine-tuning in few-shot scenarios by formulating the entity type classification task as a ''fill-in-the-blank'' problem. This allows effective utilization of the strong language modeling capability of Pre-trained Language Models (PLMs). Despite the success of current prompt-based tuning approaches, two major challenges remain: (1) the verbalizer in prompts is either manually designed or constructed from external knowledge bases, without considering the target corpus and label hierarchy information, and (2) current approaches mainly utilize the representation power of PLMs, but have not explored their generation power acquired through extensive general-domain pre-training. In this work, we propose a novel framework for few-shot FET consisting of two modules: (1) an entity type label interpretation module automatically learns to relate type labels to the vocabulary by jointly leveraging few-shot instances and the label hierarchy, and (2) a type-based contextualized instance generator produces new instances based on given instances to enlarge the training set for better generalization. On three benchmark datasets, our model outperforms existing methods by significant margins. Code can be found at https://github.com/teapot123/Fine-Grained-Entity-Typing.
Learning Feature Fusion for Unsupervised Domain Adaptive Person Re-identification
May 19, 2022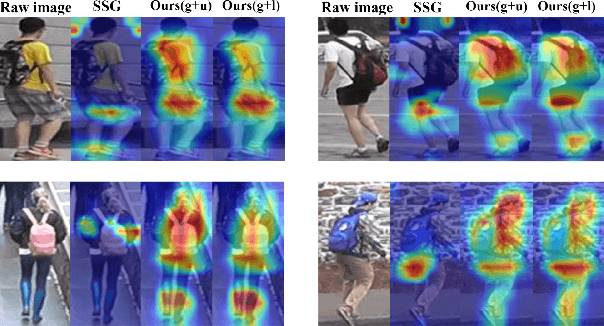
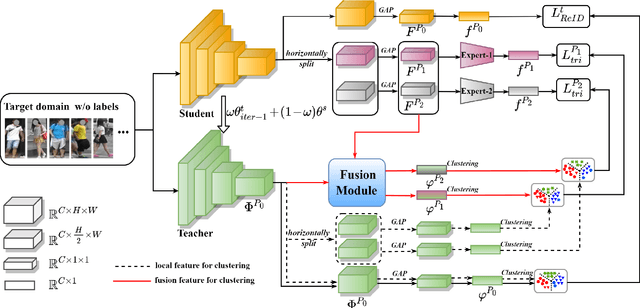
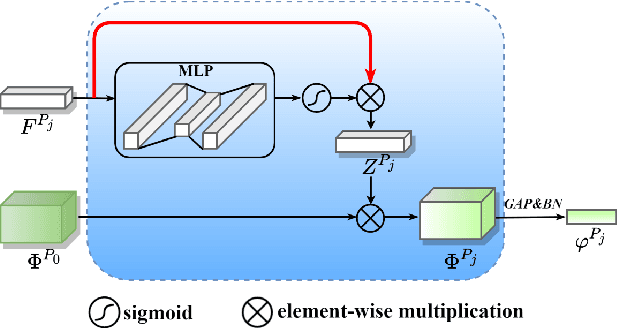
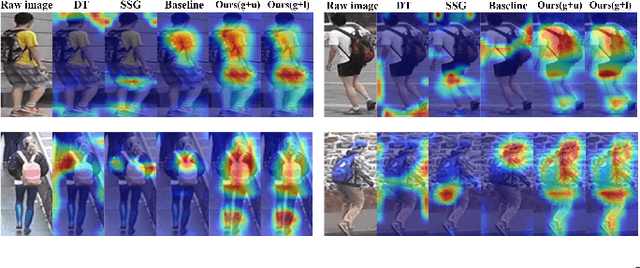
Unsupervised domain adaptive (UDA) person re-identification (ReID) has gained increasing attention for its effectiveness on the target domain without manual annotations. Most fine-tuning based UDA person ReID methods focus on encoding global features for pseudo labels generation, neglecting the local feature that can provide for the fine-grained information. To handle this issue, we propose a Learning Feature Fusion (LF2) framework for adaptively learning to fuse global and local features to obtain a more comprehensive fusion feature representation. Specifically, we first pre-train our model within a source domain, then fine-tune the model on unlabeled target domain based on the teacher-student training strategy. The average weighting teacher network is designed to encode global features, while the student network updating at each iteration is responsible for fine-grained local features. By fusing these multi-view features, multi-level clustering is adopted to generate diverse pseudo labels. In particular, a learnable Fusion Module (FM) for giving prominence to fine-grained local information within the global feature is also proposed to avoid obscure learning of multiple pseudo labels. Experiments show that our proposed LF2 framework outperforms the state-of-the-art with 73.5% mAP and 83.7% Rank1 on Market1501 to DukeMTMC-ReID, and achieves 83.2% mAP and 92.8% Rank1 on DukeMTMC-ReID to Market1501.
Heterogeneous Information Network-based Interest Composition with Graph Neural Network for Recommendation
Mar 11, 2021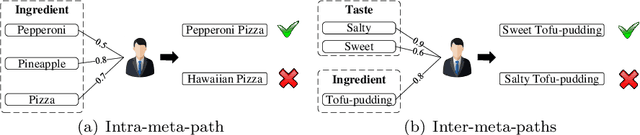
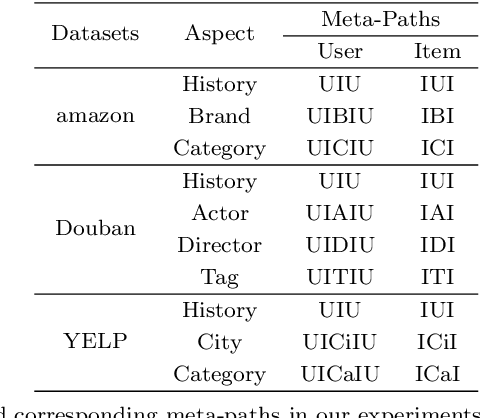
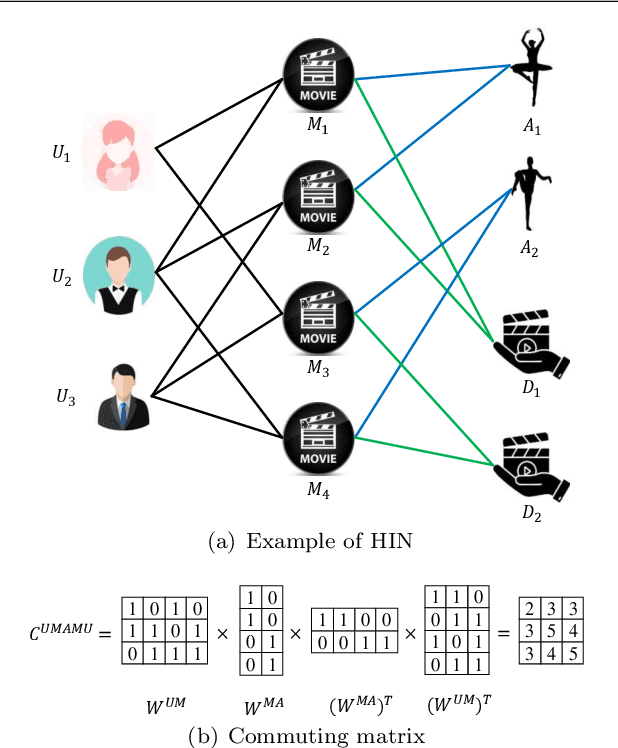
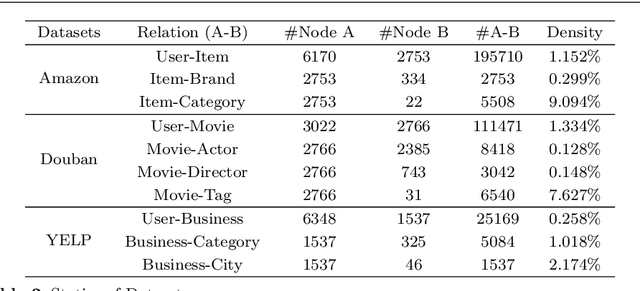
Recommendation systems (RSs) are skilled at capturing users' preferences according to their history interactions with items, while the RSs usually suffer from the sparsity of user-item interactions. Thus, various auxiliary information is introduced to alleviate this problem. Due to powerful ability in modeling auxiliary information, the heterogeneous information network (HIN) is widely applied to the RSs. However, in existing methods, the process of information extraction from various meta-paths takes no consideration of graph structure and user/item features simultaneously. Moreover, existing models usually fuse the information from various meta-paths through simply weighted summation, while ingore the interest compositions intra- and inter-meta-paths which is capable of applying abundant high-order composition interests to RSs. Therefore, we propose a HIN-based Interest Compositions model with graph neural network for Recommendation (short for HicRec). Above all, our model learns users and items representations from various graphs corresponding to the meta-paths with the help of the graph convolution network (GCN). Then, the representations of users and items are transformed into users' interests on items. Lastly, the interests intra- and inter-meta-paths are composed and applied to recommendation. Extensive experiments are conducted on three real-world datasets and the results show that the HicRec outperforms various baselines.
Changepoint Detection for Real-Time Spectrum Sharing Radar
Jun 30, 2022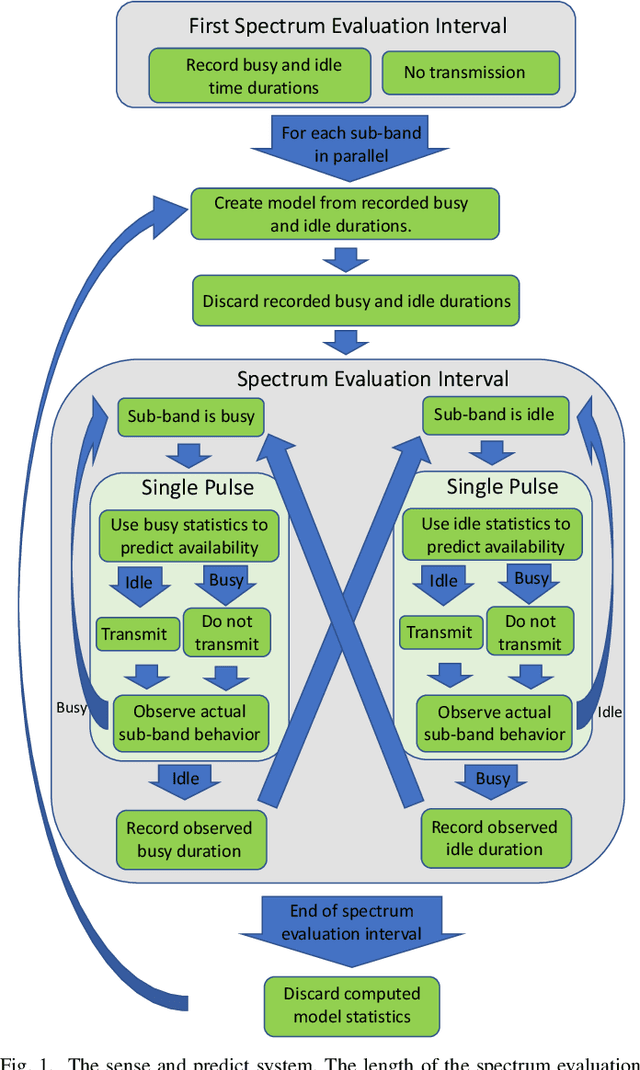
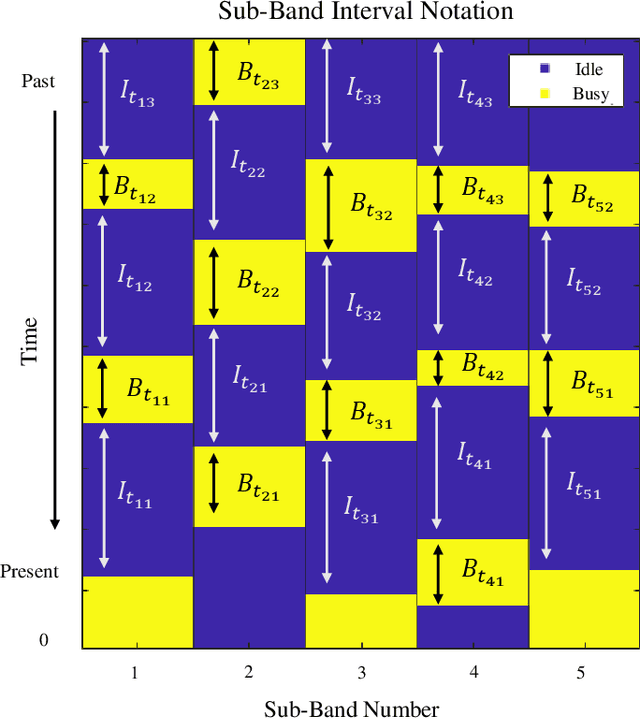
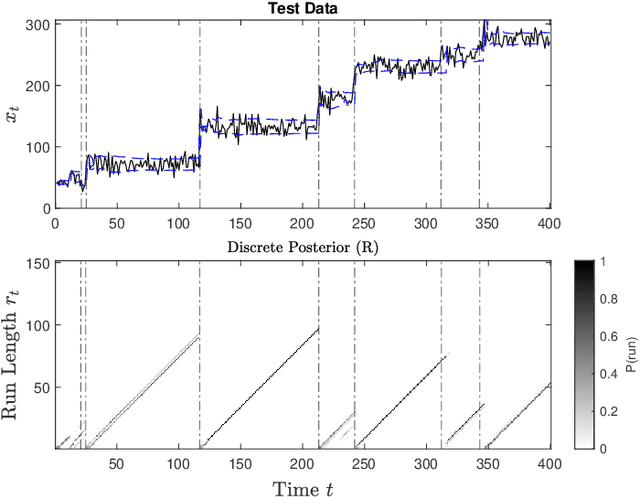
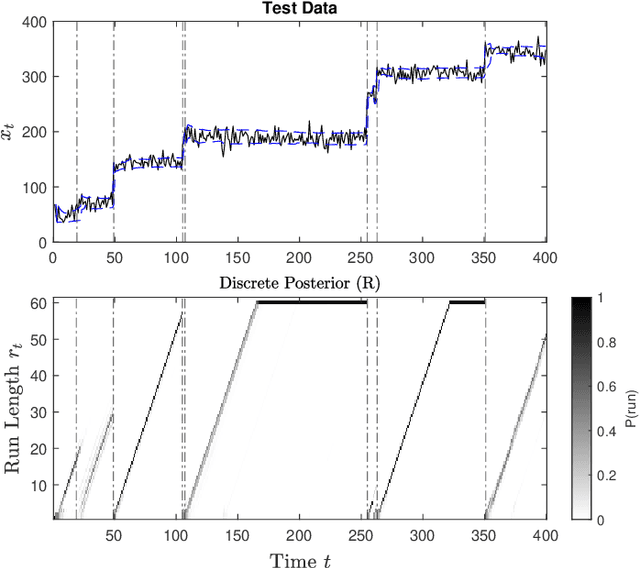
Radar must adapt to changing environments, and we propose changepoint detection as a method to do so. In the world of increasingly congested radio frequencies, radars must adapt to avoid interference. Many radar systems employ the prediction action cycle to proactively determine transmission mode while spectrum sharing. This method constructs and implements a model of the environment to predict unused frequencies, and then transmits in this predicted availability. For these selection strategies, performance is directly reliant on the quality of the underlying environmental models. In order to keep up with a changing environment, these models can employ changepoint detection. Changepoint detection is the identification of sudden changes, or changepoints, in the distribution from which data is drawn. This information allows the models to discard "garbage" data from a previous distribution, which has no relation to the current state of the environment. In this work, bayesian online changepoint detection (BOCD) is applied to the sense and predict algorithm to increase the accuracy of its models and improve its performance. In the context of spectrum sharing, these changepoints represent interferers leaving and entering the spectral environment. The addition of changepoint detection allows for dynamic and robust spectrum sharing even as interference patterns change dramatically. BOCD is especially advantageous because it enables online changepoint detection, allowing models to be updated continuously as data are collected. This strategy can also be applied to many other predictive algorithms that create models in a changing environment.
Coexistence between Task- and Data-Oriented Communications: A Whittle's Index Guided Multi-Agent Reinforcement Learning Approach
May 19, 2022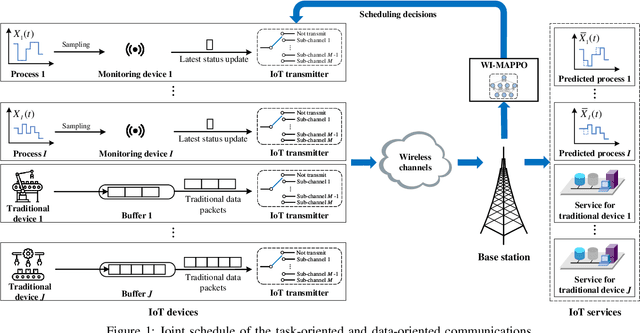
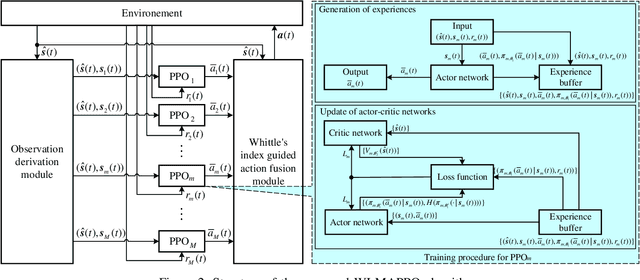
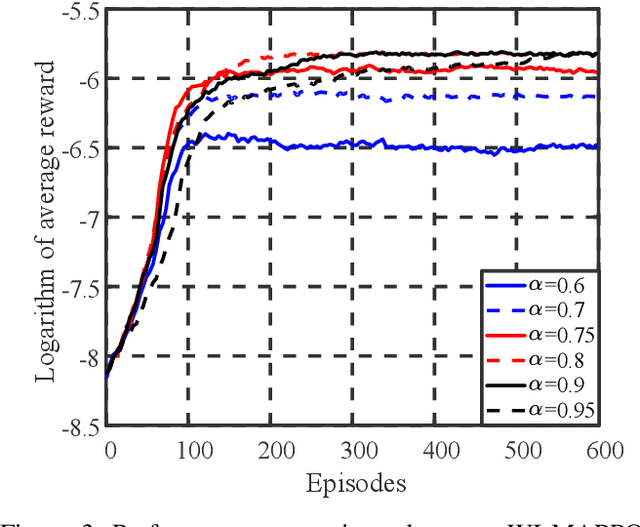
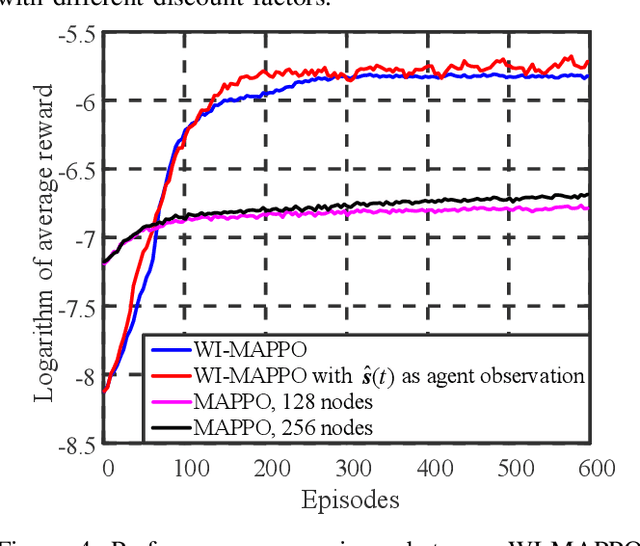
We investigate the coexistence of task-oriented and data-oriented communications in a IoT system that shares a group of channels, and study the scheduling problem to jointly optimize the weighted age of incorrect information (AoII) and throughput, which are the performance metrics of the two types of communications, respectively. This problem is formulated as a Markov decision problem, which is difficult to solve due to the large discrete action space and the time-varying action constraints induced by the stochastic availability of channels. By exploiting the intrinsic properties of this problem and reformulating the reward function based on channel statistics, we first simplify the solution space, state space, and optimality criteria, and convert it to an equivalent Markov game, for which the large discrete action space issue is greatly relieved. Then, we propose a Whittle's index guided multi-agent proximal policy optimization (WI-MAPPO) algorithm to solve the considered game, where the embedded Whittle's index module further shrinks the action space, and the proposed offline training algorithm extends the training kernel of conventional MAPPO to address the issue of time-varying constraints. Finally, numerical results validate that the proposed algorithm significantly outperforms state-of-the-art age of information (AoI) based algorithms under scenarios with insufficient channel resources.
Diversity Matters: Fully Exploiting Depth Clues for Reliable Monocular 3D Object Detection
May 19, 2022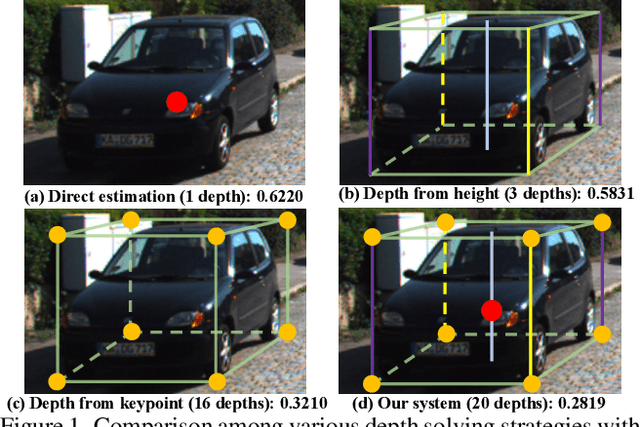
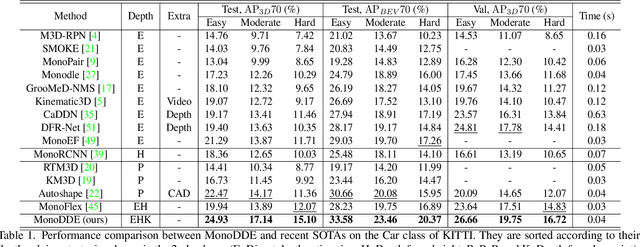
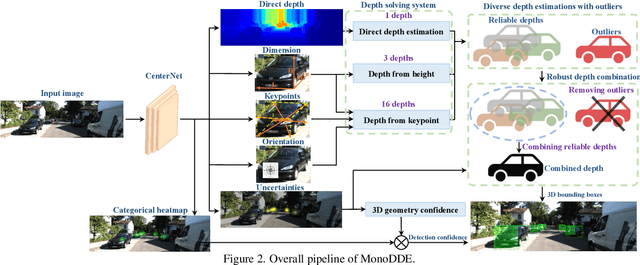
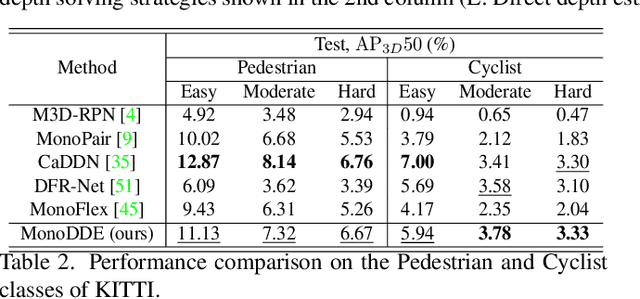
As an inherently ill-posed problem, depth estimation from single images is the most challenging part of monocular 3D object detection (M3OD). Many existing methods rely on preconceived assumptions to bridge the missing spatial information in monocular images, and predict a sole depth value for every object of interest. However, these assumptions do not always hold in practical applications. To tackle this problem, we propose a depth solving system that fully explores the visual clues from the subtasks in M3OD and generates multiple estimations for the depth of each target. Since the depth estimations rely on different assumptions in essence, they present diverse distributions. Even if some assumptions collapse, the estimations established on the remaining assumptions are still reliable. In addition, we develop a depth selection and combination strategy. This strategy is able to remove abnormal estimations caused by collapsed assumptions, and adaptively combine the remaining estimations into a single one. In this way, our depth solving system becomes more precise and robust. Exploiting the clues from multiple subtasks of M3OD and without introducing any extra information, our method surpasses the current best method by more than 20% relatively on the Moderate level of test split in the KITTI 3D object detection benchmark, while still maintaining real-time efficiency.
Accurate Fruit Localisation for Robotic Harvesting using High Resolution LiDAR-Camera Fusion
May 01, 2022
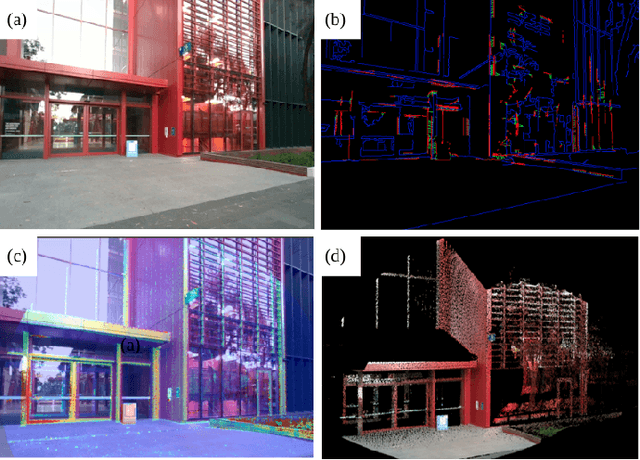


Accurate depth-sensing plays a crucial role in securing a high success rate of robotic harvesting in natural orchard environments. Solid-state LiDAR (SSL), a recently introduced LiDAR technique, can perceive high-resolution geometric information of the scenes, which can be potential utilised to receive accurate depth information. Meanwhile, the fusion of the sensory information from LiDAR and camera can significantly enhance the sensing ability of the harvesting robots. This work introduces a LiDAR-camera fusion-based visual sensing and perception strategy to perform accurate fruit localisation for a harvesting robot in the apple orchards. Two SOTA extrinsic calibration methods, target-based and targetless-based, are applied and evaluated to obtain the accurate extrinsic matrix between the LiDAR and camera. With the extrinsic calibration, the point clouds and color images are fused to perform fruit localisation using a one-stage instance segmentation network. Experimental shows that LiDAR-camera achieves better quality on visual sensing in the natural environments. Meanwhile, introducing the LiDAR-camera fusion largely improves the accuracy and robustness of the fruit localisation. Specifically, the standard deviations of fruit localisation by using LiDAR-camera at 0.5 m, 1.2 m, and 1.8 m are 0.245, 0.227, and 0.275 cm respectively. These measurement error is only one one fifth of that from Realsense D455. Lastly, we have attached our visualised point cloud to demonstrate the highly accurate sensing method.
A Survey of Deep Fake Detection for Trial Courts
May 31, 2022
Recently, image manipulation has achieved rapid growth due to the advancement of sophisticated image editing tools. A recent surge of generated fake imagery and videos using neural networks is DeepFake. DeepFake algorithms can create fake images and videos that humans cannot distinguish from authentic ones. (GANs) have been extensively used for creating realistic images without accessing the original images. Therefore, it is become essential to detect fake videos to avoid spreading false information. This paper presents a survey of methods used to detect DeepFakes and datasets available for detecting DeepFakes in the literature to date. We present extensive discussions and research trends related to DeepFake technologies.
Islander: A Real-Time News Monitoring and Analysis System
Apr 25, 2022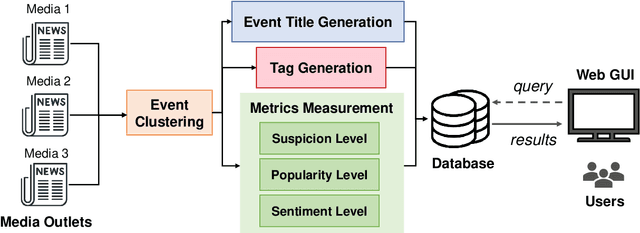
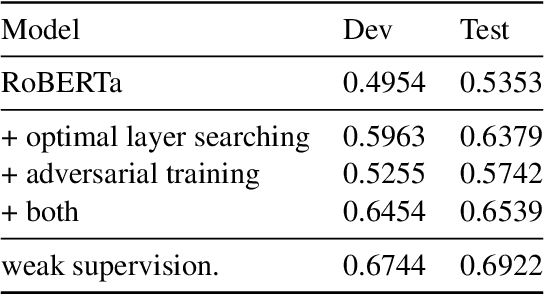
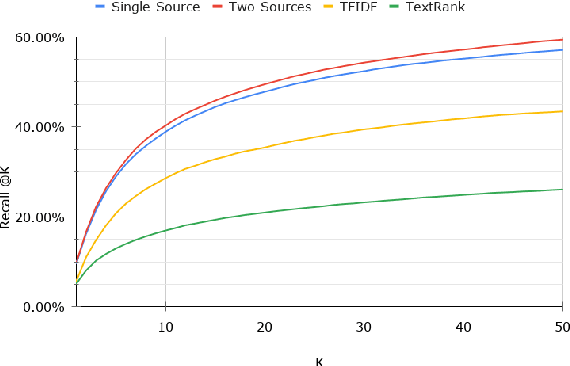
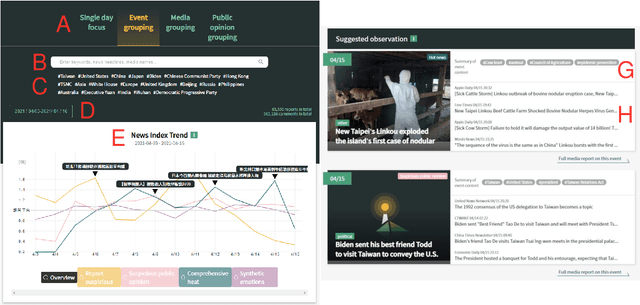
With thousands of news articles from hundreds of sources distributed and shared every day, news consumption and information acquisition have been increasingly difficult for readers. Additionally, the content of news articles is becoming catchy or even inciting to attract readership, harming the accuracy of news reporting. We present Islander, an online news analyzing system. The system allows users to browse trending topics with articles from multiple sources and perspectives. We define several metrics as proxies for news quality, and develop algorithms for automatic estimation. The quality estimation results are delivered through a web interface to newsreaders for easy access to news and information. The website is publicly available at https://islander.cc/