 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hippocluster: an efficient, hippocampus-inspired algorithm for graph clustering
May 19, 2022
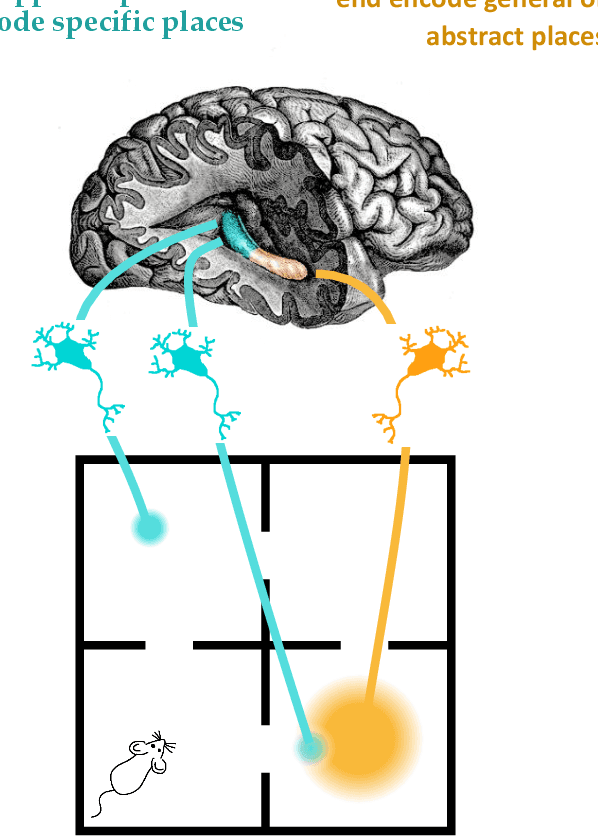
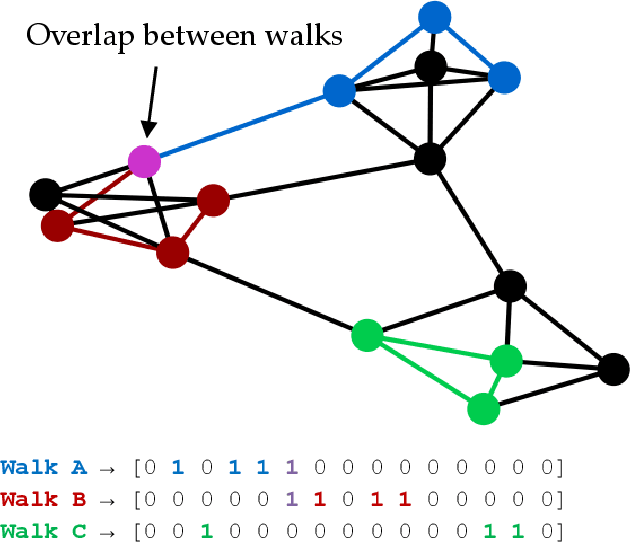
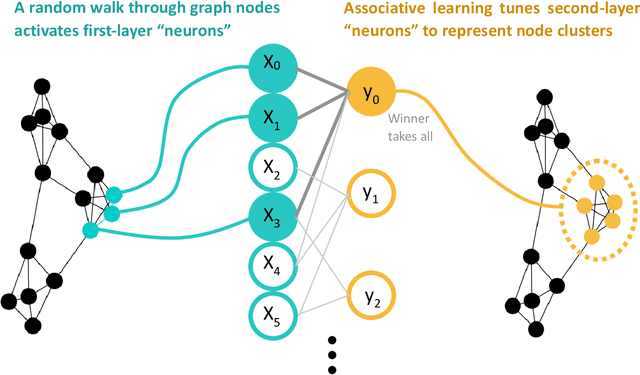
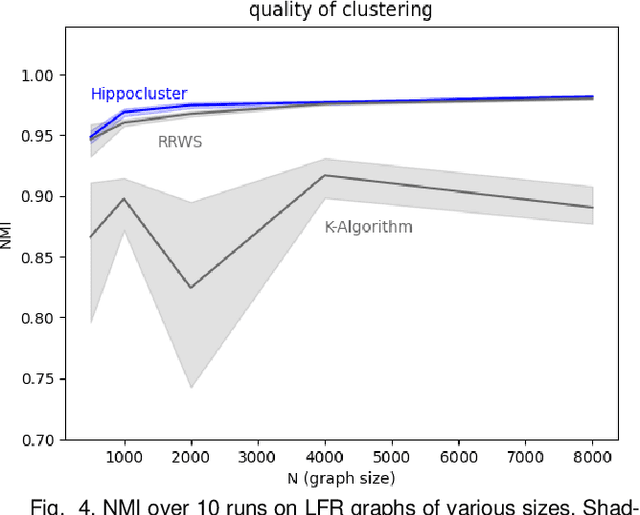
Random walks can reveal communities or clusters in networks, because they are more likely to stay within a cluster than leave it. Thus, one family of community detection algorithms uses random walks to measure distance between pairs of nodes in various ways, and then applies K-Means or other generic clustering methods to these distances. Interestingly, information processing in the brain may suggest a simpler method of learning clusters directly from random walks. Drawing inspiration from the hippocampus, we describe a simple two-layer neural learning framework. Neurons in one layer are associated with graph nodes and simulate random walks. These simulations cause neurons in the second layer to become tuned to graph clusters through simple associative learning. We show that if these neuronal interactions are modelled a particular way, the system is essentially a variant of K-Means clustering applied directly in the walk-space, bypassing the usual step of computing node distances/similarities. The result is an efficient graph clustering method. Biological information processing systems are known for high efficiency and adaptability. In tests on benchmark graphs, our framework demonstrates this high data-efficiency, low memory use, low complexity, and real-time adaptation to graph changes, while still achieving clustering quality comparable to other algorithms.
GD-VAEs: Geometric Dynamic Variational Autoencoders for Learning Nonlinear Dynamics and Dimension Reductions
Jun 10, 2022
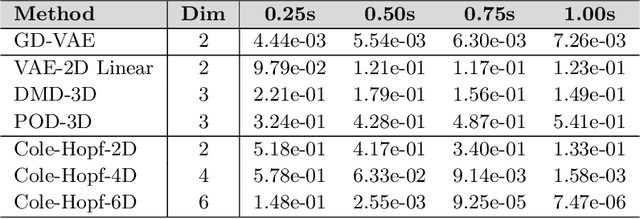
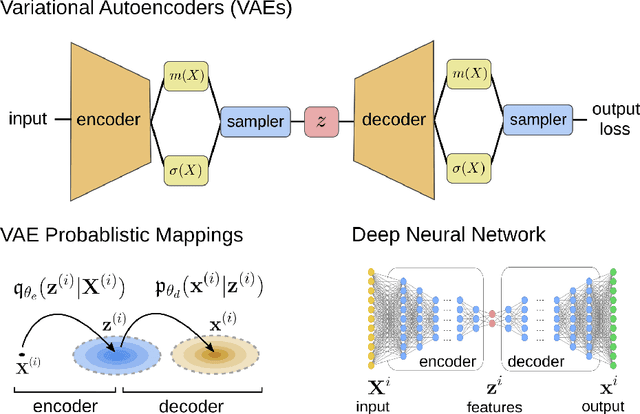
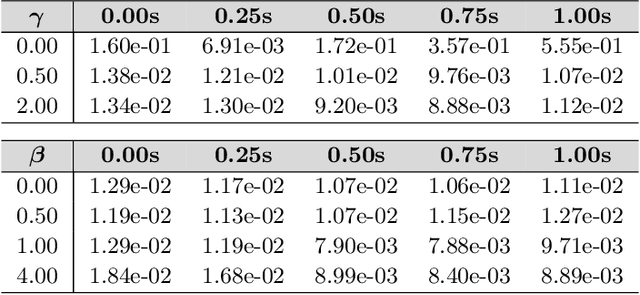
We develop data-driven methods incorporating geometric and topological information to learn parsimonious representations of nonlinear dynamics from observations. We develop approaches for learning nonlinear state space models of the dynamics for general manifold latent spaces using training strategies related to Variational Autoencoders (VAEs). Our methods are referred to as Geometric Dynamic (GD) Variational Autoencoders (GD-VAEs). We learn encoders and decoders for the system states and evolution based on deep neural network architectures that include general Multilayer Perceptrons (MLPs), Convolutional Neural Networks (CNNs), and Transpose CNNs (T-CNNs). Motivated by problems arising in parameterized PDEs and physics, we investigate the performance of our methods on tasks for learning low dimensional representations of the nonlinear Burgers equations, constrained mechanical systems, and spatial fields of reaction-diffusion systems. GD-VAEs provide methods for obtaining representations for use in learning tasks involving dynamics.
Multi-faceted Graph Attention Network for Radar Target Recognition in Heterogeneous Radar Network
Jun 10, 2022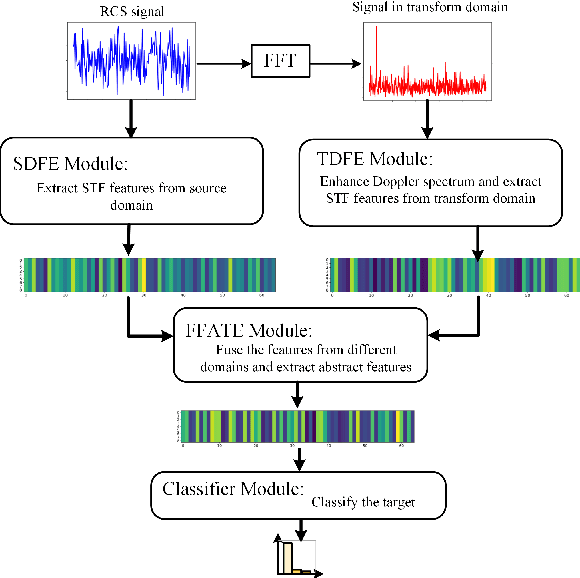

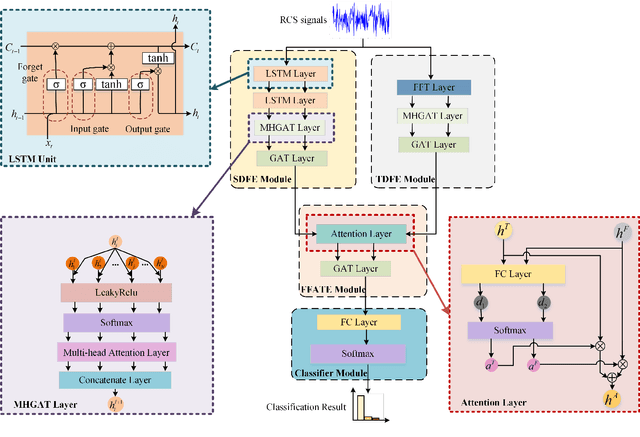
Radar target recognition (RTR), as a key technology of intelligent radar systems, has been well investigated. Accurate RTR at low signal-to-noise ratios (SNRs) still remains an open challenge. Most existing methods are based on a single radar or the homogeneous radar network, which do not fully exploit frequency-dimensional information. In this paper, a two-stream semantic feature fusion model, termed Multi-faceted Graph Attention Network (MF-GAT), is proposed to greatly improve the accuracy in the low SNR region of the heterogeneous radar network. By fusing the features extracted from the source domain and transform domain via a graph attention network model, the MF-GAT model distills higher-level semantic features before classification in a unified framework. Extensive experiments are presented to demonstrate that the proposed model can greatly improve the RTR performance at low SNRs.
* 6 pages, 4 figures
Collaboration-Aware Graph Convolutional Networks for Recommendation Systems
Jul 03, 2022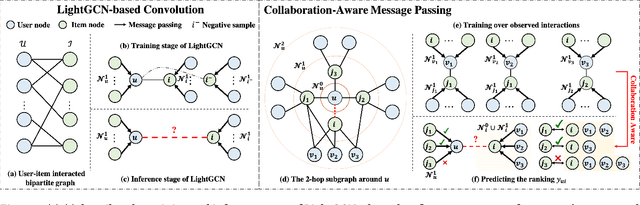
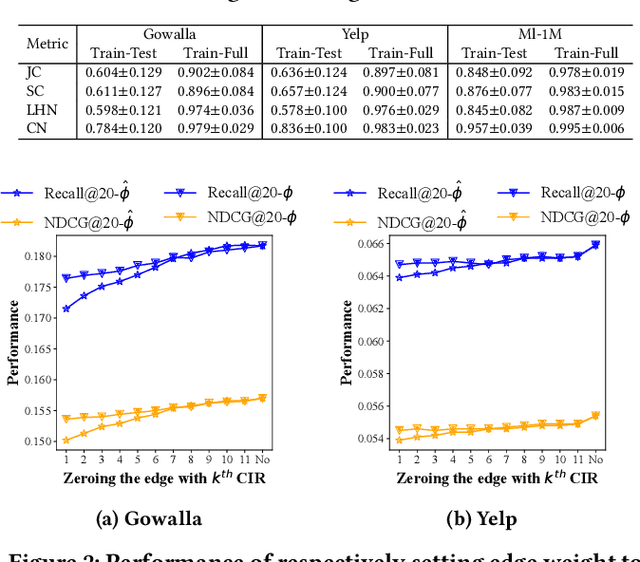
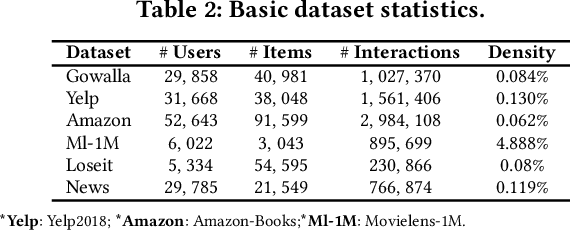
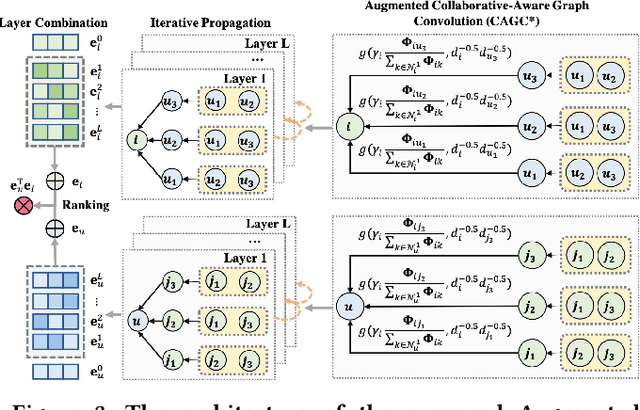
By virtue of the message-passing that implicitly injects collaborative effect into the embedding process, Graph Neural Networks (GNNs) have been successfully adopted in recommendation systems. Nevertheless, most of existing message-passing mechanisms in recommendation are directly inherited from GNNs without any recommendation-tailored modification. Although some efforts have been made towards simplifying GNNs to improve the performance/efficiency of recommendation, no study has comprehensively scrutinized how message-passing captures collaborative effect and whether the captured effect would benefit the prediction of user preferences over items. Therefore, in this work we aim to demystify the collaborative effect captured by message-passing in GNNs and develop new insights towards customizing message-passing for recommendation. First, we theoretically analyze how message-passing captures and leverages the collaborative effect in predicting user preferences. Then, to determine whether the captured collaborative effect would benefit the prediction of user preferences, we propose a recommendation-oriented topological metric, Common Interacted Ratio (CIR), which measures the level of interaction between a specific neighbor of a node with the rest of its neighborhood set. Inspired by our theoretical and empirical analysis, we propose a recommendation-tailored GNN, Augmented Collaboration-Aware Graph Convolutional Network (CAGCN*), that extends upon the LightGCN framework and is able to selectively pass information of neighbors based on their CIR via the Collaboration-Aware Graph Convolution. Experimental results on six benchmark datasets show that CAGCN* outperforms the most representative GNN-based recommendation model, LightGCN, by 9% in Recall@20 and also achieves more than 79% speedup. Our code is publicly available at https://github.com/YuWVandy/CAGCN.
Self-Constrained Inference Optimization on Structural Groups for Human Pose Estimation
Jul 06, 2022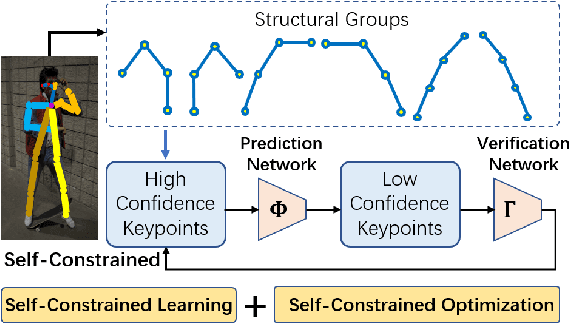
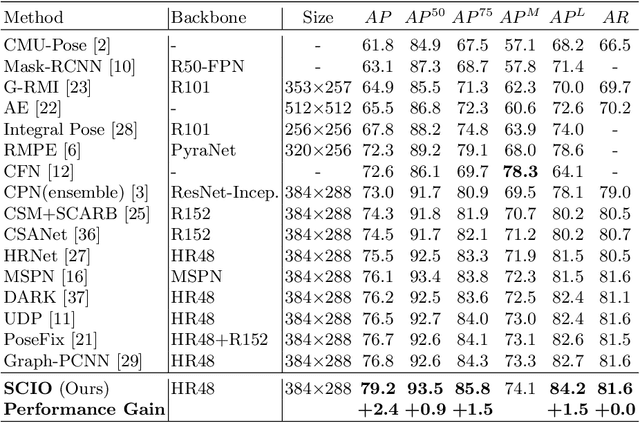
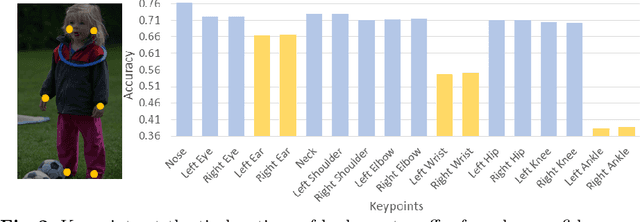
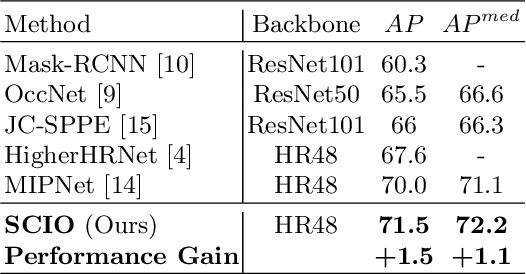
We observe that human poses exhibit strong group-wise structural correlation and spatial coupling between keypoints due to the biological constraints of different body parts. This group-wise structural correlation can be explored to improve the accuracy and robustness of human pose estimation. In this work, we develop a self-constrained prediction-verification network to characterize and learn the structural correlation between keypoints during training. During the inference stage, the feedback information from the verification network allows us to perform further optimization of pose prediction, which significantly improves the performance of human pose estimation. Specifically, we partition the keypoints into groups according to the biological structure of human body. Within each group, the keypoints are further partitioned into two subsets, high-confidence base keypoints and low-confidence terminal keypoints. We develop a self-constrained prediction-verification network to perform forward and backward predictions between these keypoint subsets. One fundamental challenge in pose estimation, as well as in generic prediction tasks, is that there is no mechanism for us to verify if the obtained pose estimation or prediction results are accurate or not, since the ground truth is not available. Once successfully learned, the verification network serves as an accuracy verification module for the forward pose prediction. During the inference stage, it can be used to guide the local optimization of the pose estimation results of low-confidence keypoints with the self-constrained loss on high-confidence keypoints as the objective function. Our extensive experimental results on benchmark MS COCO and CrowdPose datasets demonstrate that the proposed method can significantly improve the pose estimation results.
Write It Like You See It: Detectable Differences in Clinical Notes By Race Lead To Differential Model Recommendations
May 08, 2022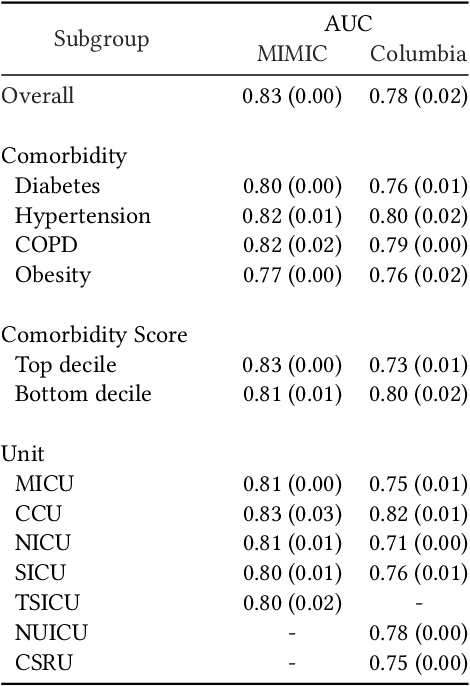
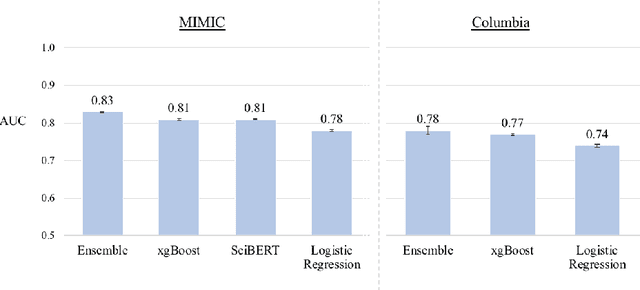


Clinical notes are becoming an increasingly important data source for machine learning (ML) applications in healthcare. Prior research has shown that deploying ML models can perpetuate existing biases against racial minorities, as bias can be implicitly embedded in data. In this study, we investigate the level of implicit race information available to ML models and human experts and the implications of model-detectable differences in clinical notes. Our work makes three key contributions. First, we find that models can identify patient self-reported race from clinical notes even when the notes are stripped of explicit indicators of race. Second, we determine that human experts are not able to accurately predict patient race from the same redacted clinical notes. Finally, we demonstrate the potential harm of this implicit information in a simulation study, and show that models trained on these race-redacted clinical notes can still perpetuate existing biases in clinical treatment decisions.
Asking for Knowledge: Training RL Agents to Query External Knowledge Using Language
May 12, 2022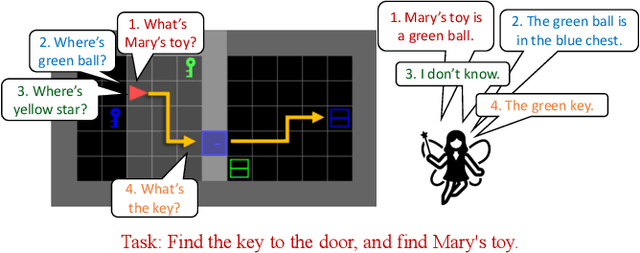
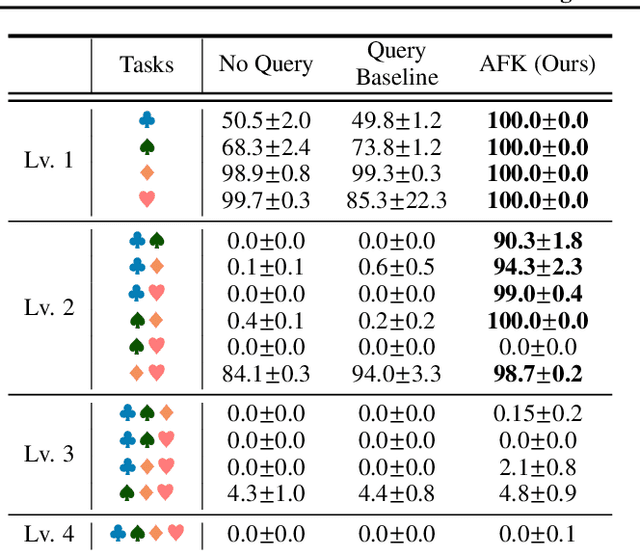


To solve difficult tasks, humans ask questions to acquire knowledge from external sources. In contrast, classical reinforcement learning agents lack such an ability and often resort to exploratory behavior. This is exacerbated as few present-day environments support querying for knowledge. In order to study how agents can be taught to query external knowledge via language, we first introduce two new environments: the grid-world-based Q-BabyAI and the text-based Q-TextWorld. In addition to physical interactions, an agent can query an external knowledge source specialized for these environments to gather information. Second, we propose the "Asking for Knowledge" (AFK) agent, which learns to generate language commands to query for meaningful knowledge that helps solve the tasks. AFK leverages a non-parametric memory, a pointer mechanism and an episodic exploration bonus to tackle (1) a large query language space, (2) irrelevant information, (3) delayed reward for making meaningful queries. Extensive experiments demonstrate that the AFK agent outperforms recent baselines on the challenging Q-BabyAI and Q-TextWorld environments.
Jointist: Joint Learning for Multi-instrument Transcription and Its Applications
Jun 22, 2022
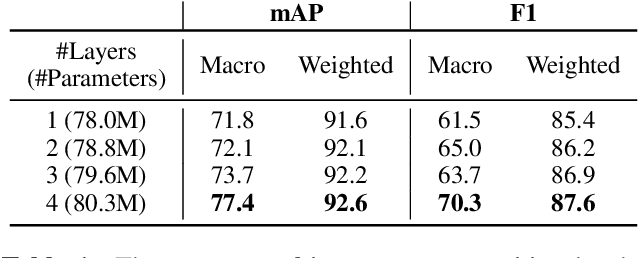
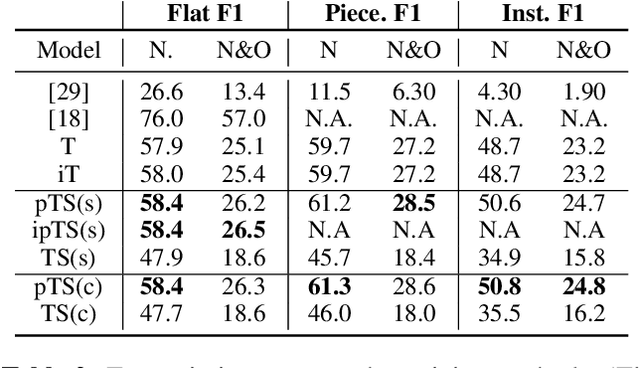
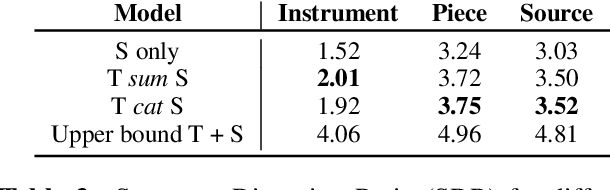
In this paper, we introduce Jointist, an instrument-aware multi-instrument framework that is capable of transcribing, recognizing, and separating multiple musical instruments from an audio clip. Jointist consists of the instrument recognition module that conditions the other modules: the transcription module that outputs instrument-specific piano rolls, and the source separation module that utilizes instrument information and transcription results. The instrument conditioning is designed for an explicit multi-instrument functionality while the connection between the transcription and source separation modules is for better transcription performance. Our challenging problem formulation makes the model highly useful in the real world given that modern popular music typically consists of multiple instruments. However, its novelty necessitates a new perspective on how to evaluate such a model. During the experiment, we assess the model from various aspects, providing a new evaluation perspective for multi-instrument transcription. We also argue that transcription models can be utilized as a preprocessing module for other music analysis tasks. In the experiment on several downstream tasks, the symbolic representation provided by our transcription model turned out to be helpful to spectrograms in solving downbeat detection, chord recognition, and key estimation.
Improve Discourse Dependency Parsing with Contextualized Representations
May 04, 2022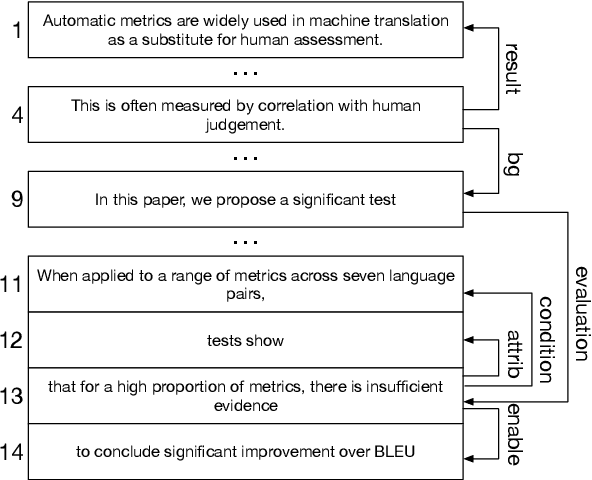
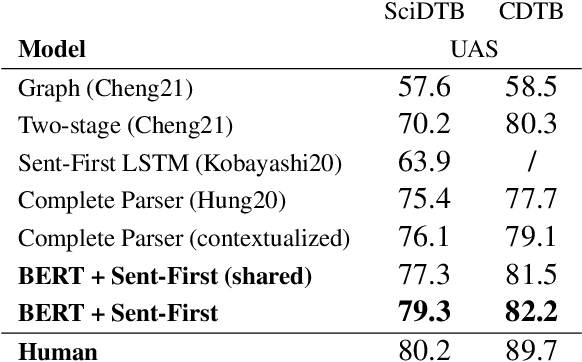
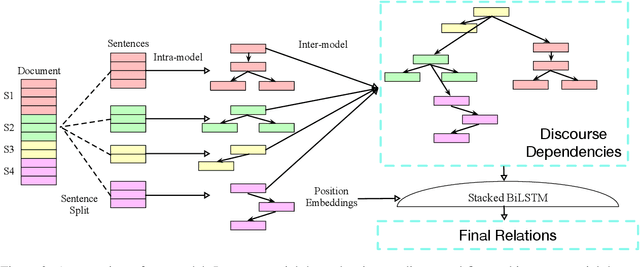
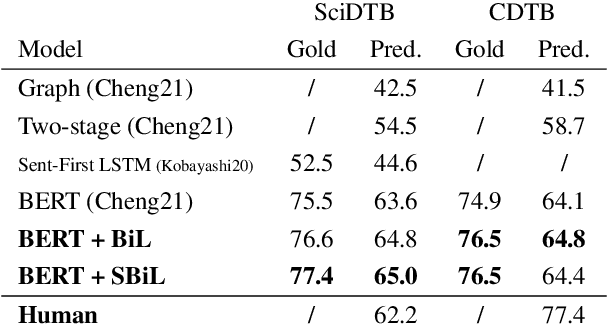
Recent works show that discourse analysis benefits from modeling intra- and inter-sentential levels separately, where proper representations for text units of different granularities are desired to capture both the meaning of text units and their relations to the context. In this paper, we propose to take advantage of transformers to encode contextualized representations of units of different levels to dynamically capture the information required for discourse dependency analysis on intra- and inter-sentential levels. Motivated by the observation of writing patterns commonly shared across articles, we propose a novel method that treats discourse relation identification as a sequence labelling task, which takes advantage of structural information from the context of extracted discourse trees, and substantially outperforms traditional direct-classification methods. Experiments show that our model achieves state-of-the-art results on both English and Chinese datasets.
Chirp-Based Over-the-Air Computation for Long-Range Federated Edge Learning
Jun 22, 2022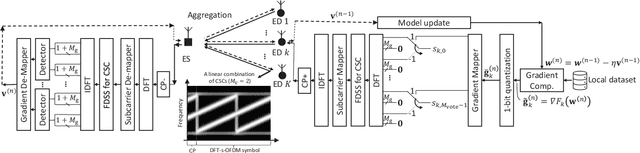
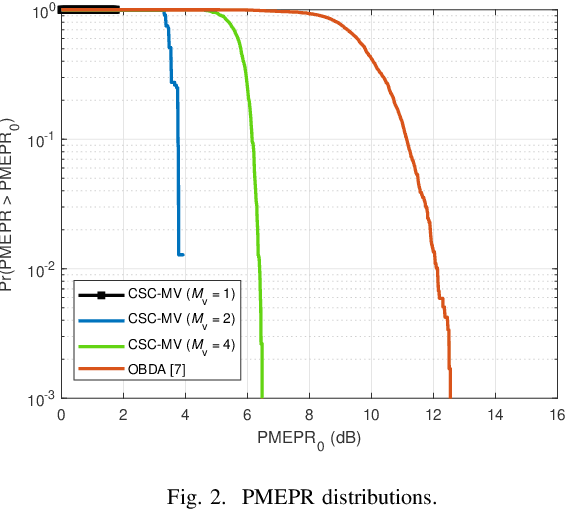
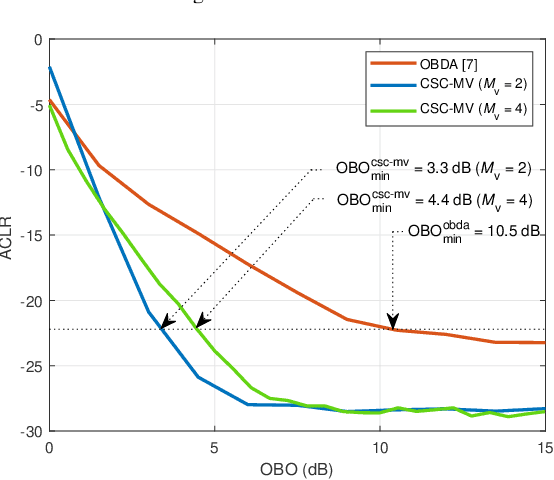
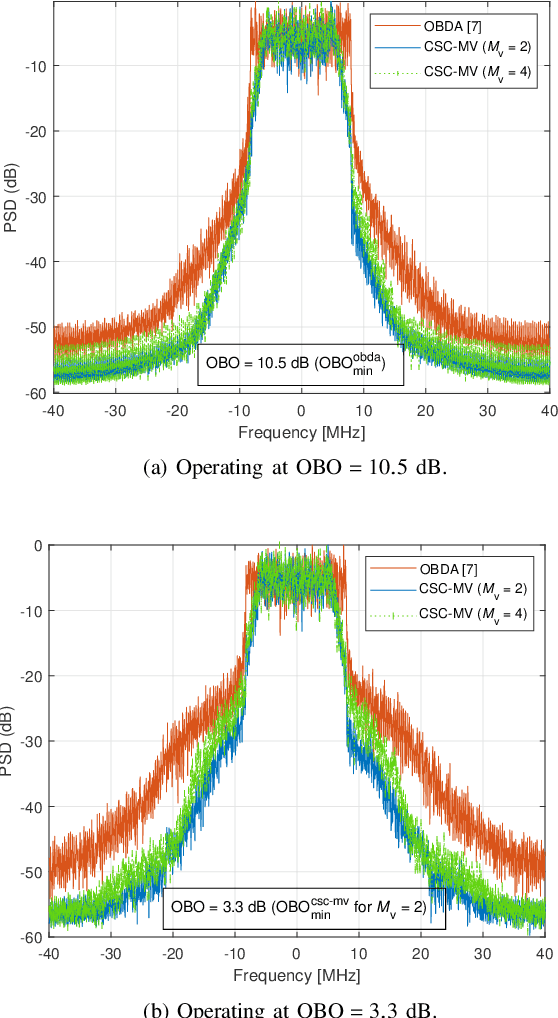
In this study, we propose circularly-shifted chirp (CSC)-based majority vote (MV) (CSC-MV), a power-efficient over-the-air computation (OAC) scheme, to achieve long-range federated edge learning (FEEL). The proposed approach maps the votes (i.e., the sign of the local gradients) from the edge devices (EDs) to the linear CSCs constructed with a discrete Fourier transform-spread orthogonal frequency division multiplexing (DFT-s-OFDM) transmitter. At the edge server (ES), the MV is calculated with an energy detector. We compare our proposed scheme with one-bit broadband digital aggregation (OBDA) and show that the output-power back-off (OBO) requirement of the transmitters with an adjacent-channel-leakage ratio (ACLR) constraint for CSC-MV is lower than the one with OBDA. For example, with an ACLR constraint of -22 dB, CSC-MV can have an OBO requirement of 6-7 dB less than the one with OBDA. When the power amplifier (PA) non-linearity is considered, we demonstrate that CSC-MV outperforms OBDA in terms of test accuracy for both homogeneous and heterogeneous data distributions, without using channel state information (CSI) at the ES and EDs.