 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DeepCPCFG: Deep Learning and Context Free Grammars for End-to-End Information Extraction
Mar 10, 2021
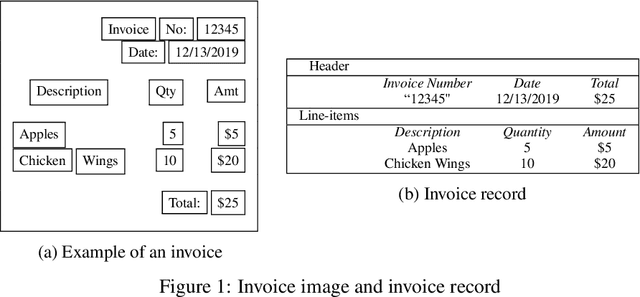
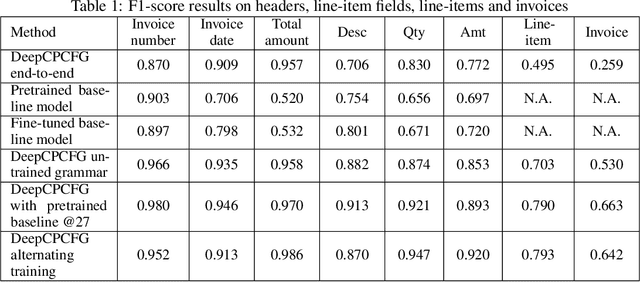

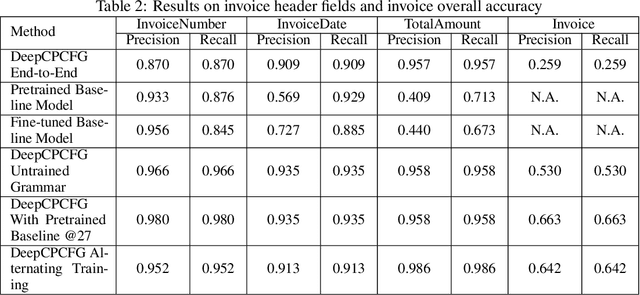
We combine deep learning and Conditional Probabilistic Context Free Grammars (CPCFG) to create an end-to-end system for extracting structured information from complex documents. For each class of documents, we create a CPCFG that describes the structure of the information to be extracted. Conditional probabilities are modeled by deep neural networks. We use this grammar to parse 2-D documents to directly produce structured records containing the extracted information. This system is trained end-to-end with (Document, Record) pairs. We apply this approach to extract information from scanned invoices achieving state-of-the-art results.
Style-Content Disentanglement in Language-Image Pretraining Representations for Zero-Shot Sketch-to-Image Synthesis
Jun 03, 2022
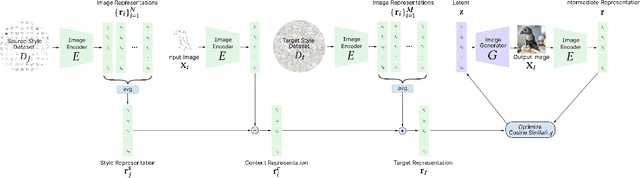


In this work, we propose and validate a framework to leverage language-image pretraining representations for training-free zero-shot sketch-to-image synthesis. We show that disentangled content and style representations can be utilized to guide image generators to employ them as sketch-to-image generators without (re-)training any parameters. Our approach for disentangling style and content entails a simple method consisting of elementary arithmetic assuming compositionality of information in representations of input sketches. Our results demonstrate that this approach is competitive with state-of-the-art instance-level open-domain sketch-to-image models, while only depending on pretrained off-the-shelf models and a fraction of the data.
Structured Light with Redundancy Codes
Jun 18, 2022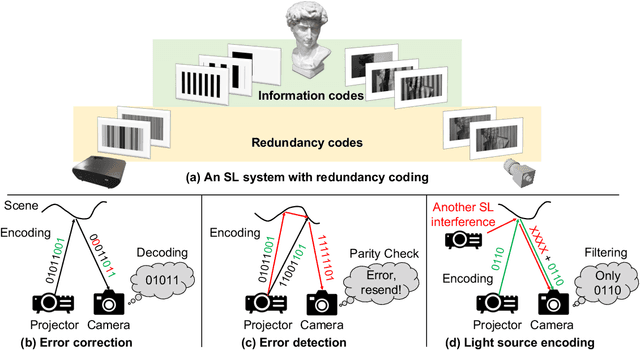
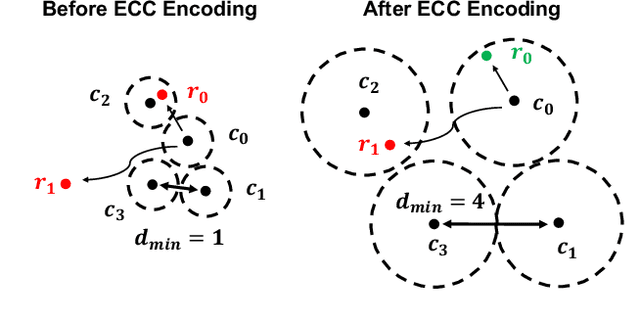
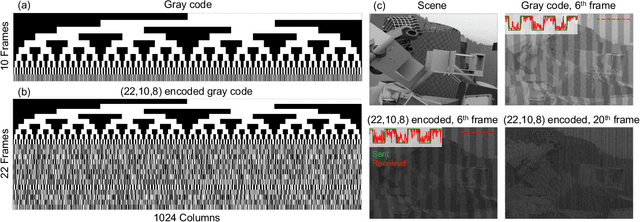
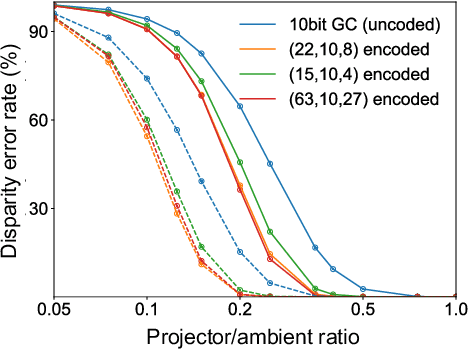
Structured light (SL) systems acquire high-fidelity 3D geometry with active illumination projection. Conventional systems exhibit challenges when working in environments with strong ambient illumination, global illumination and cross-device interference. This paper proposes a general-purposed technique to improve the robustness of SL by projecting redundant optical signals in addition to the native SL patterns. In this way, projected signals become more distinguishable from errors. Thus the geometry information can be more easily recovered using simple signal processing and the ``coding gain" in performance is obtained. We propose three applications using our redundancy codes: (1) Self error-correction for SL imaging under strong ambient light, (2) Error detection for adaptive reconstruction under global illumination, and (3) Interference filtering with device-specific projection sequence encoding, especially for event camera-based SL and light curtain devices. We systematically analyze the design rules and signal processing algorithms in these applications. Corresponding hardware prototypes are built for evaluations on real-world complex scenes. Experimental results on the synthetic and real data demonstrate the significant performance improvements in SL systems with our redundancy codes.
Self-Constrained Inference Optimization on Structural Groups for Human Pose Estimation
Jul 06, 2022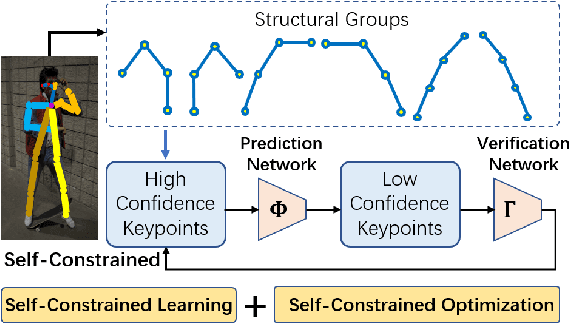
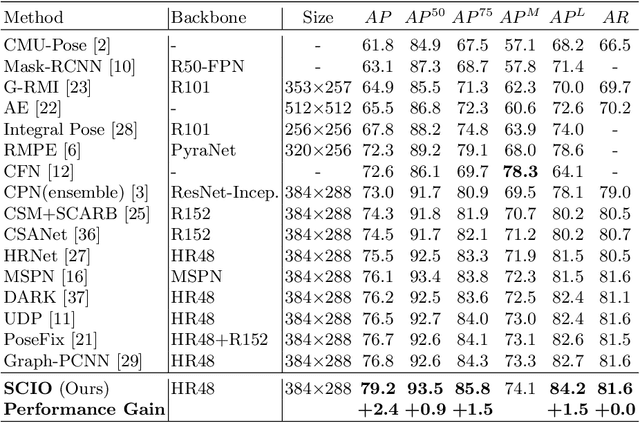
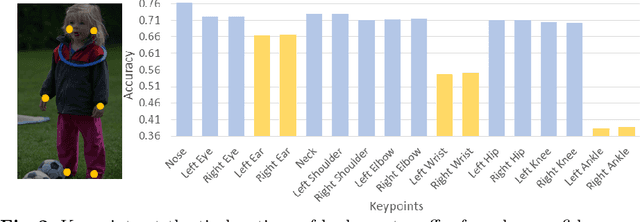
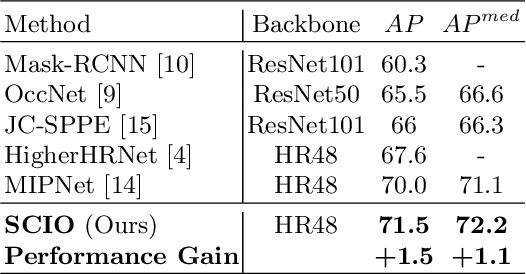
We observe that human poses exhibit strong group-wise structural correlation and spatial coupling between keypoints due to the biological constraints of different body parts. This group-wise structural correlation can be explored to improve the accuracy and robustness of human pose estimation. In this work, we develop a self-constrained prediction-verification network to characterize and learn the structural correlation between keypoints during training. During the inference stage, the feedback information from the verification network allows us to perform further optimization of pose prediction, which significantly improves the performance of human pose estimation. Specifically, we partition the keypoints into groups according to the biological structure of human body. Within each group, the keypoints are further partitioned into two subsets, high-confidence base keypoints and low-confidence terminal keypoints. We develop a self-constrained prediction-verification network to perform forward and backward predictions between these keypoint subsets. One fundamental challenge in pose estimation, as well as in generic prediction tasks, is that there is no mechanism for us to verify if the obtained pose estimation or prediction results are accurate or not, since the ground truth is not available. Once successfully learned, the verification network serves as an accuracy verification module for the forward pose prediction. During the inference stage, it can be used to guide the local optimization of the pose estimation results of low-confidence keypoints with the self-constrained loss on high-confidence keypoints as the objective function. Our extensive experimental results on benchmark MS COCO and CrowdPose datasets demonstrate that the proposed method can significantly improve the pose estimation results.
Collaboration-Aware Graph Convolutional Networks for Recommendation Systems
Jul 03, 2022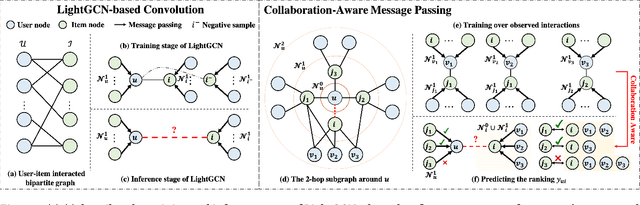
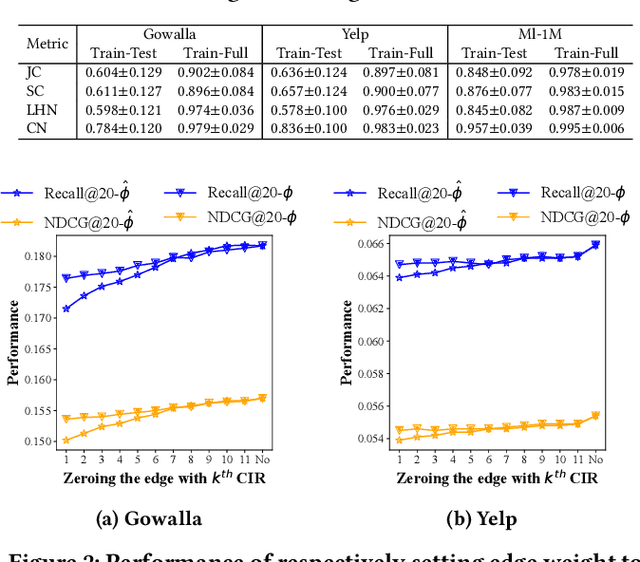
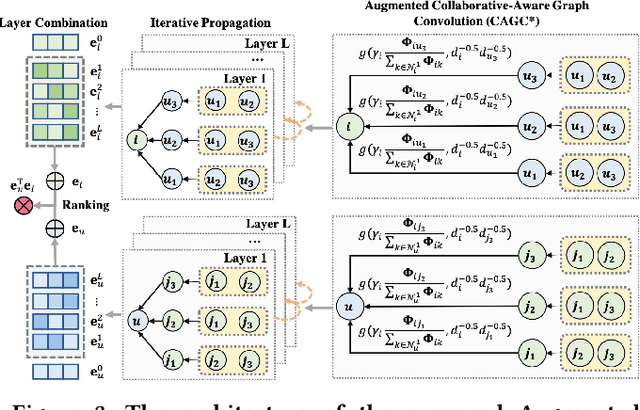
By virtue of the message-passing that implicitly injects collaborative effect into the embedding process, Graph Neural Networks (GNNs) have been successfully adopted in recommendation systems. Nevertheless, most of existing message-passing mechanisms in recommendation are directly inherited from GNNs without any recommendation-tailored modification. Although some efforts have been made towards simplifying GNNs to improve the performance/efficiency of recommendation, no study has comprehensively scrutinized how message-passing captures collaborative effect and whether the captured effect would benefit the prediction of user preferences over items. Therefore, in this work we aim to demystify the collaborative effect captured by message-passing in GNNs and develop new insights towards customizing message-passing for recommendation. First, we theoretically analyze how message-passing captures and leverages the collaborative effect in predicting user preferences. Then, to determine whether the captured collaborative effect would benefit the prediction of user preferences, we propose a recommendation-oriented topological metric, Common Interacted Ratio (CIR), which measures the level of interaction between a specific neighbor of a node with the rest of its neighborhood set. Inspired by our theoretical and empirical analysis, we propose a recommendation-tailored GNN, Augmented Collaboration-Aware Graph Convolutional Network (CAGCN*), that extends upon the LightGCN framework and is able to selectively pass information of neighbors based on their CIR via the Collaboration-Aware Graph Convolution. Experimental results on six benchmark datasets show that CAGCN* outperforms the most representative GNN-based recommendation model, LightGCN, by 9% in Recall@20 and also achieves more than 79% speedup. Our code is publicly available at https://github.com/YuWVandy/CAGCN.
PhD Thesis. Computer-Aided Assessment of Tuberculosis with Radiological Imaging: From rule-based methods to Deep Learning
May 31, 2022
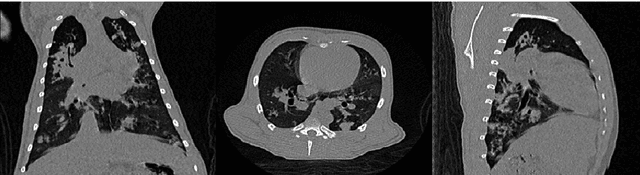
Tuberculosis (TB) is an infectious disease caused by Mycobacterium tuberculosis (Mtb.) that produces pulmonary damage due to its airborne nature. This fact facilitates the disease fast-spreading, which, according to the World Health Organization (WHO), in 2021 caused 1.2 million deaths and 9.9 million new cases. Fortunately, X-Ray Computed Tomography (CT) images enable capturing specific manifestations of TB that are undetectable using regular diagnostic tests. However, this procedure is unfeasible to process the thousands of volume images belonging to the different TB animal models and humans required for a suitable (pre-)clinical trial. To achieve suitable results, automatization of different image analysis processes is a must to quantify TB. Thus, in this thesis, we introduce a set of novel methods based on the state of the art Artificial Intelligence (AI) and Computer Vision (CV). Initially, we present an algorithm to assess Pathological Lung Segmentation (PLS). Next, a Gaussian Mixture Model ruled by an Expectation-Maximization (EM) algorithm is employed to automatically. Chapter 3 introduces a model to automate the identification of TB lesions and the characterization of disease progression. Chapter 4 extends the classification of TB lesions. Namely, we introduce a computational model to infer TB manifestations present in each lung lobe of CT scans by employing the associated radiologist reports as ground truth. In Chapter 5, we present a DL model capable of extracting disentangled information from images of different animal models, as well as information of the mechanisms that generate the CT volumes. To sum up, the thesis presents a collection of valuable tools to automate the quantification of pathological lungs. Chapter 6 elaborates on these conclusions.
GD-VAEs: Geometric Dynamic Variational Autoencoders for Learning Nonlinear Dynamics and Dimension Reductions
Jun 10, 2022
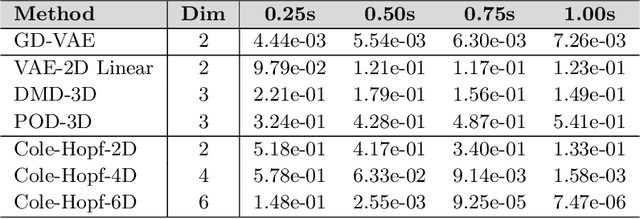
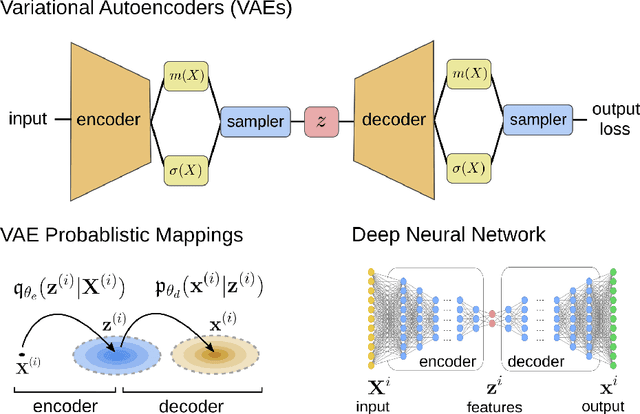
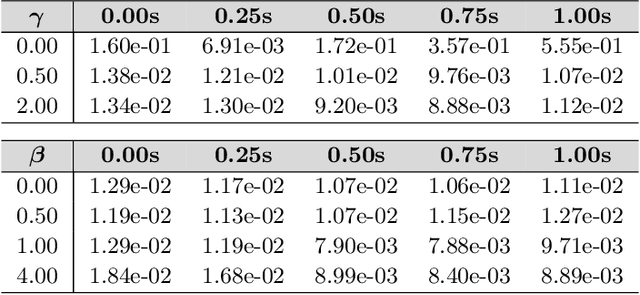
We develop data-driven methods incorporating geometric and topological information to learn parsimonious representations of nonlinear dynamics from observations. We develop approaches for learning nonlinear state space models of the dynamics for general manifold latent spaces using training strategies related to Variational Autoencoders (VAEs). Our methods are referred to as Geometric Dynamic (GD) Variational Autoencoders (GD-VAEs). We learn encoders and decoders for the system states and evolution based on deep neural network architectures that include general Multilayer Perceptrons (MLPs), Convolutional Neural Networks (CNNs), and Transpose CNNs (T-CNNs). Motivated by problems arising in parameterized PDEs and physics, we investigate the performance of our methods on tasks for learning low dimensional representations of the nonlinear Burgers equations, constrained mechanical systems, and spatial fields of reaction-diffusion systems. GD-VAEs provide methods for obtaining representations for use in learning tasks involving dynamics.
Kleister: Key Information Extraction Datasets Involving Long Documents with Complex Layouts
May 12, 2021
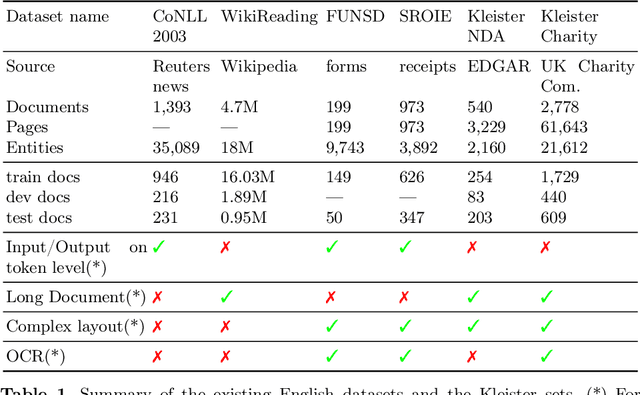
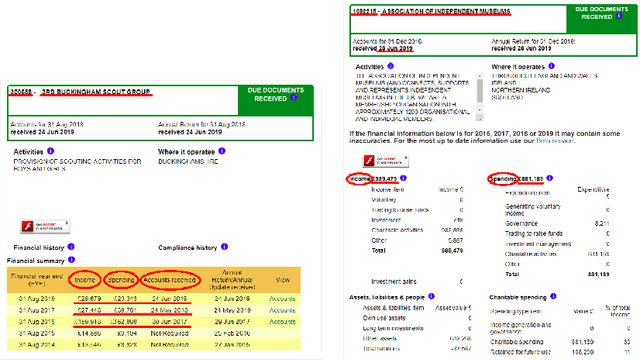
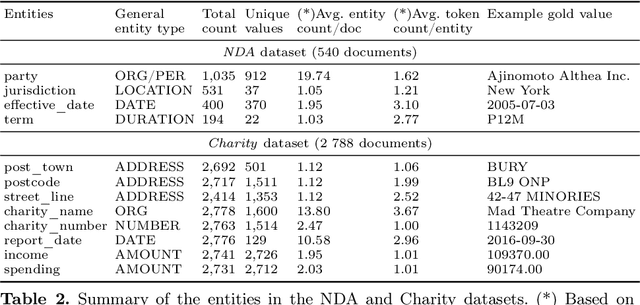
The relevance of the Key Information Extraction (KIE) task is increasingly important in natural language processing problems. But there are still only a few well-defined problems that serve as benchmarks for solutions in this area. To bridge this gap, we introduce two new datasets (Kleister NDA and Kleister Charity). They involve a mix of scanned and born-digital long formal English-language documents. In these datasets, an NLP system is expected to find or infer various types of entities by employing both textual and structural layout features. The Kleister Charity dataset consists of 2,788 annual financial reports of charity organizations, with 61,643 unique pages and 21,612 entities to extract. The Kleister NDA dataset has 540 Non-disclosure Agreements, with 3,229 unique pages and 2,160 entities to extract. We provide several state-of-the-art baseline systems from the KIE domain (Flair, BERT, RoBERTa, LayoutLM, LAMBERT), which show that our datasets pose a strong challenge to existing models. The best model achieved an 81.77% and an 83.57% F1-score on respectively the Kleister NDA and the Kleister Charity datasets. We share the datasets to encourage progress on more in-depth and complex information extraction tasks.
Can deep learning match the efficiency of human visual long-term memory in storing object details?
Apr 28, 2022
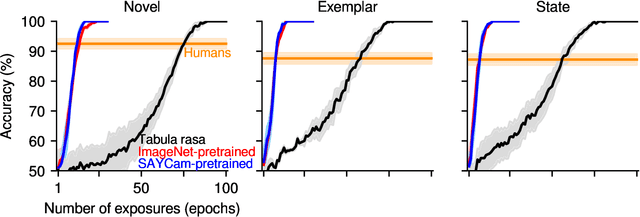
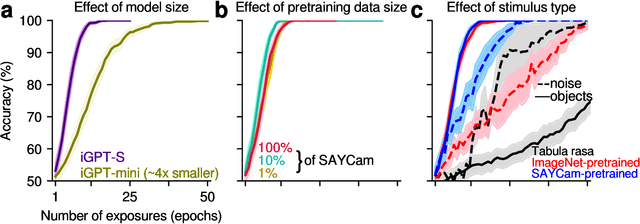
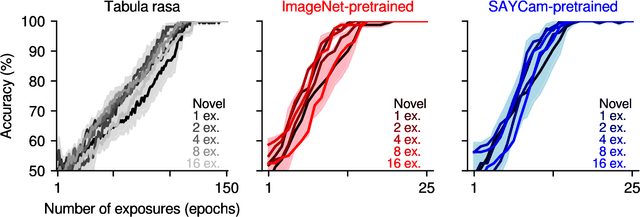
Humans have a remarkably large capacity to store detailed visual information in long-term memory even after a single exposure, as demonstrated by classic experiments in psychology. For example, Standing (1973) showed that humans could recognize with high accuracy thousands of pictures that they had seen only once a few days prior to a recognition test. In deep learning, the primary mode of incorporating new information into a model is through gradient descent in the model's parameter space. This paper asks whether deep learning via gradient descent can match the efficiency of human visual long-term memory to incorporate new information in a rigorous, head-to-head, quantitative comparison. We answer this in the negative: even in the best case, models learning via gradient descent appear to require approximately 10 exposures to the same visual materials in order to reach a recognition memory performance humans achieve after only a single exposure. Prior knowledge induced via pretraining and bigger model sizes improve performance, but these improvements are not very visible after a single exposure (it takes a few exposures for the improvements to become apparent), suggesting that simply scaling up the pretraining data size or model size might not be enough for the model to reach human-level memory efficiency.
Hippocluster: an efficient, hippocampus-inspired algorithm for graph clustering
May 19, 2022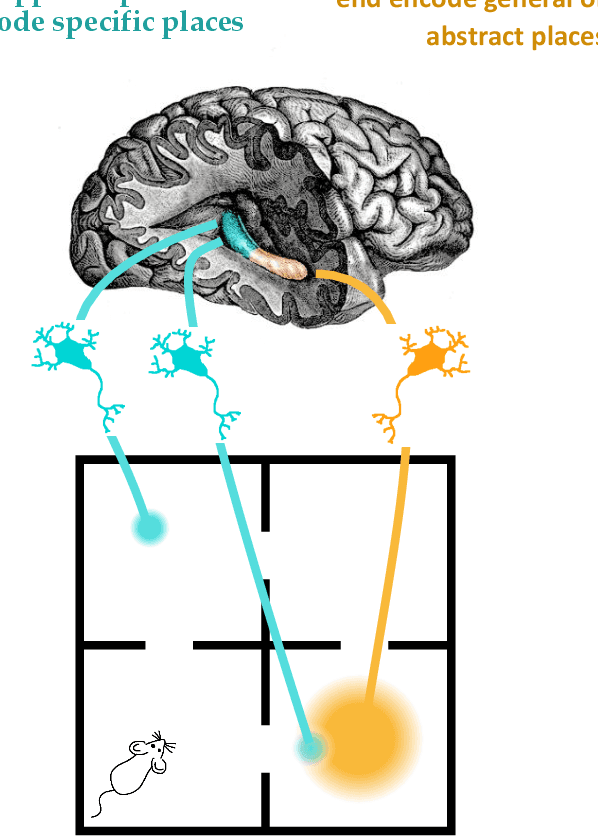
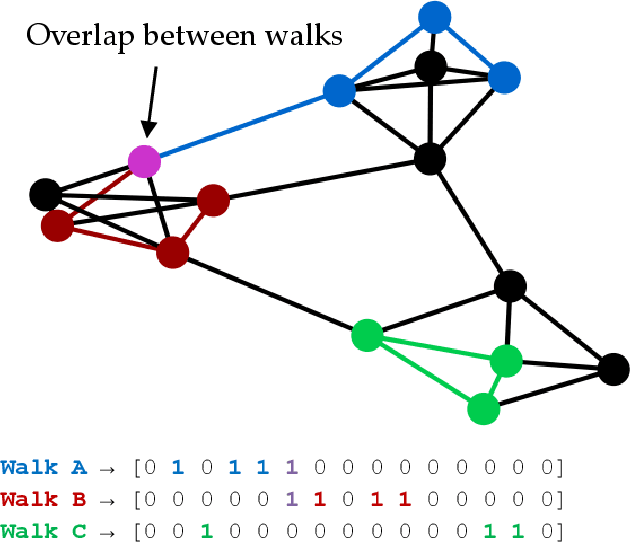
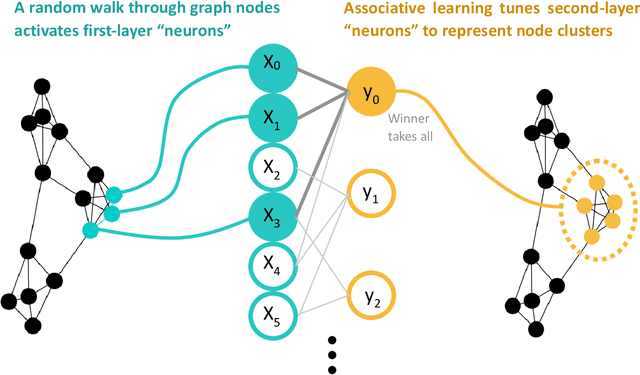
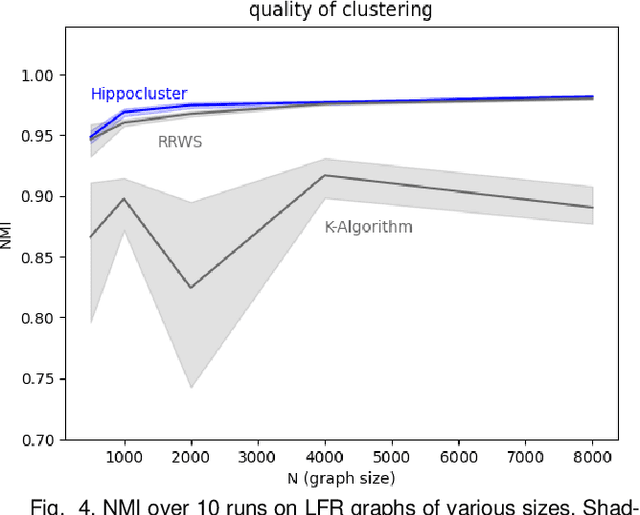
Random walks can reveal communities or clusters in networks, because they are more likely to stay within a cluster than leave it. Thus, one family of community detection algorithms uses random walks to measure distance between pairs of nodes in various ways, and then applies K-Means or other generic clustering methods to these distances. Interestingly, information processing in the brain may suggest a simpler method of learning clusters directly from random walks. Drawing inspiration from the hippocampus, we describe a simple two-layer neural learning framework. Neurons in one layer are associated with graph nodes and simulate random walks. These simulations cause neurons in the second layer to become tuned to graph clusters through simple associative learning. We show that if these neuronal interactions are modelled a particular way, the system is essentially a variant of K-Means clustering applied directly in the walk-space, bypassing the usual step of computing node distances/similarities. The result is an efficient graph clustering method. Biological information processing systems are known for high efficiency and adaptability. In tests on benchmark graphs, our framework demonstrates this high data-efficiency, low memory use, low complexity, and real-time adaptation to graph changes, while still achieving clustering quality comparable to other algorithms.