 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reinforced Inverse Scattering
Jun 08, 2022
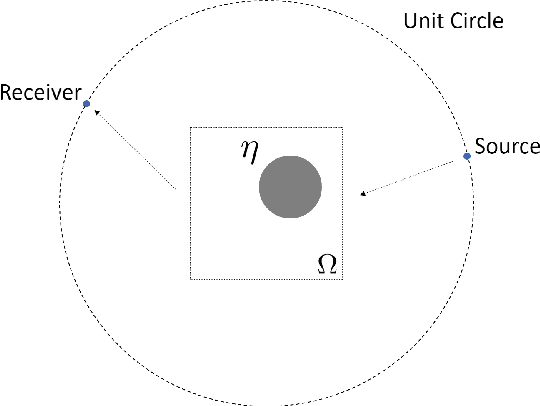



Inverse wave scattering aims at determining the properties of an object using data on how the object scatters incoming waves. In order to collect information, sensors are put in different locations to send and receive waves from each other. The choice of sensor positions and incident wave frequencies determines the reconstruction quality of scatterer properties. This paper introduces reinforcement learning to develop precision imaging that decides sensor positions and wave frequencies adaptive to different scatterers in an intelligent way, thus obtaining a significant improvement in reconstruction quality with limited imaging resources. Extensive numerical results will be provided to demonstrate the superiority of the proposed method over existing methods.
FingerGAN: A Constrained Fingerprint Generation Scheme for Latent Fingerprint Enhancement
Jun 26, 2022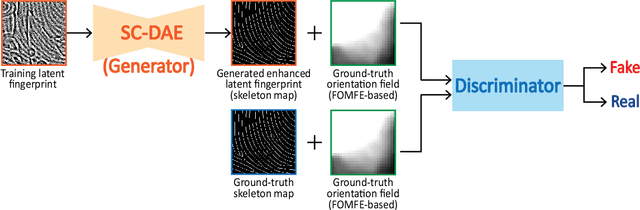
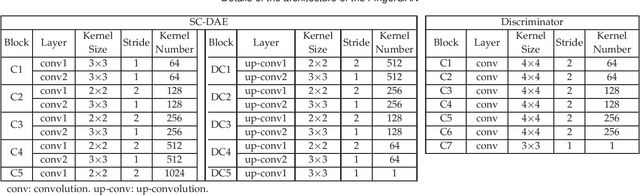
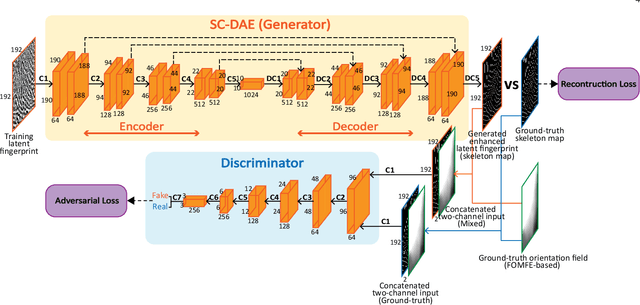
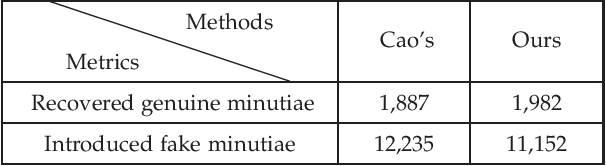
Latent fingerprint enhancement is an essential pre-processing step for latent fingerprint identification. Most latent fingerprint enhancement methods try to restore corrupted gray ridges/valleys. In this paper, we propose a new method that formulates the latent fingerprint enhancement as a constrained fingerprint generation problem within a generative adversarial network (GAN) framework. We name the proposed network as FingerGAN. It can enforce its generated fingerprint (i.e, enhanced latent fingerprint) indistinguishable from the corresponding ground-truth instance in terms of the fingerprint skeleton map weighted by minutia locations and the orientation field regularized by the FOMFE model. Because minutia is the primary feature for fingerprint recognition and minutia can be retrieved directly from the fingerprint skeleton map, we offer a holistic framework which can perform latent fingerprint enhancement in the context of directly optimizing minutia information. This will help improve latent fingerprint identification performance significantly. Experimental results on two public latent fingerprint databases demonstrate that our method outperforms the state of the arts significantly. The codes will be available for non-commercial purposes from \url{https://github.com/HubYZ/LatentEnhancement}.
GODEL: Large-Scale Pre-Training for Goal-Directed Dialog
Jun 22, 2022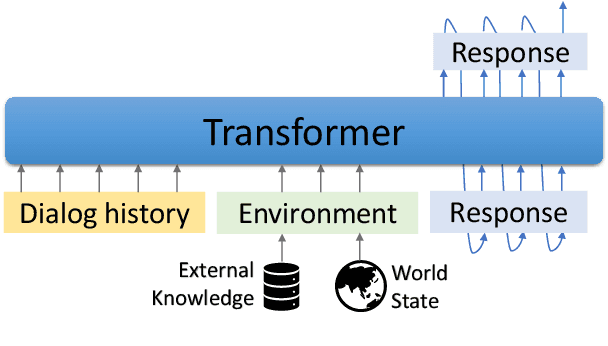
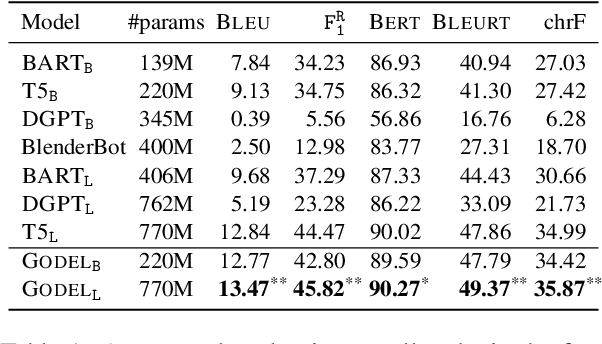

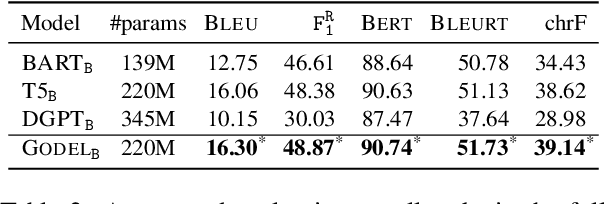
We introduce GODEL (Grounded Open Dialogue Language Model), a large pre-trained language model for dialog. In contrast with earlier models such as DialoGPT, GODEL leverages a new phase of grounded pre-training designed to better support adapting GODEL to a wide range of downstream dialog tasks that require information external to the current conversation (e.g., a database or document) to produce good responses. Experiments against an array of benchmarks that encompass task-oriented dialog, conversational QA, and grounded open-domain dialog show that GODEL outperforms state-of-the-art pre-trained dialog models in few-shot fine-tuning setups, in terms of both human and automatic evaluation. A novel feature of our evaluation methodology is the introduction of a notion of utility that assesses the usefulness of responses (extrinsic evaluation) in addition to their communicative features (intrinsic evaluation). We show that extrinsic evaluation offers improved inter-annotator agreement and correlation with automated metrics. Code and data processing scripts are publicly available.
Efficient Forecasting of Large Scale Hierarchical Time Series via Multilevel Clustering
May 27, 2022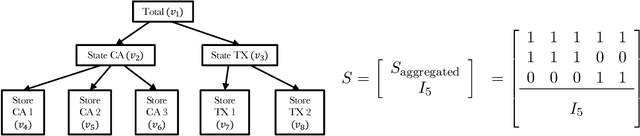
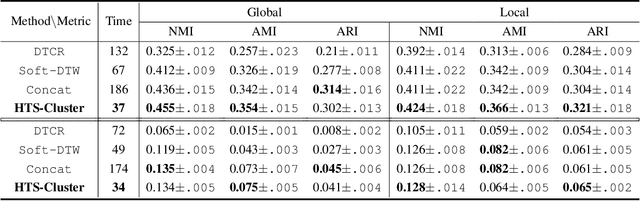
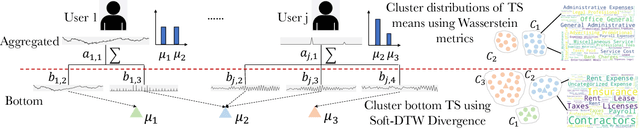
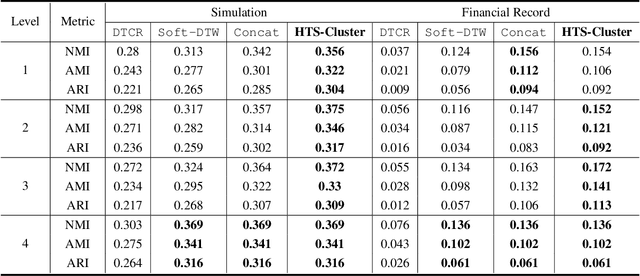
We propose a novel approach to the problem of clustering hierarchically aggregated time-series data, which has remained an understudied problem though it has several commercial applications. We first group time series at each aggregated level, while simultaneously leveraging local and global information. The proposed method can cluster hierarchical time series (HTS) with different lengths and structures. For common two-level hierarchies, we employ a combined objective for local and global clustering over spaces of discrete probability measures, using Wasserstein distance coupled with Soft-DTW divergence. For multi-level hierarchies, we present a bottom-up procedure that progressively leverages lower-level information for higher-level clustering. Our final goal is to improve both the accuracy and speed of forecasts for a larger number of HTS needed for a real-world application. To attain this goal, each time series is first assigned the forecast for its cluster representative, which can be considered as a "shrinkage prior" for the set of time series it represents. Then this base forecast can be quickly fine-tuned to adjust to the specifics of that time series. We empirically show that our method substantially improves performance in terms of both speed and accuracy for large-scale forecasting tasks involving much HTS.
Model-Based and Graph-Based Priors for Group Testing
May 24, 2022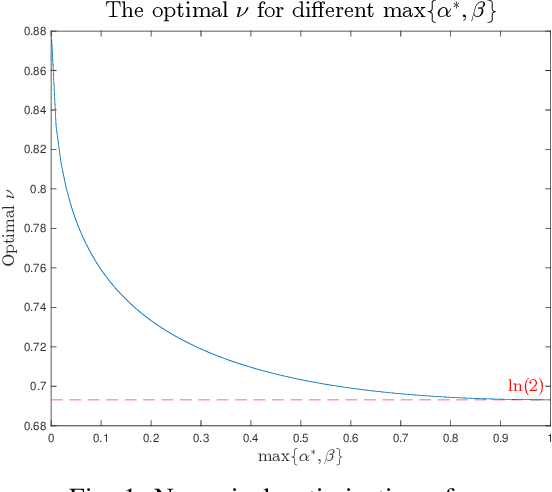
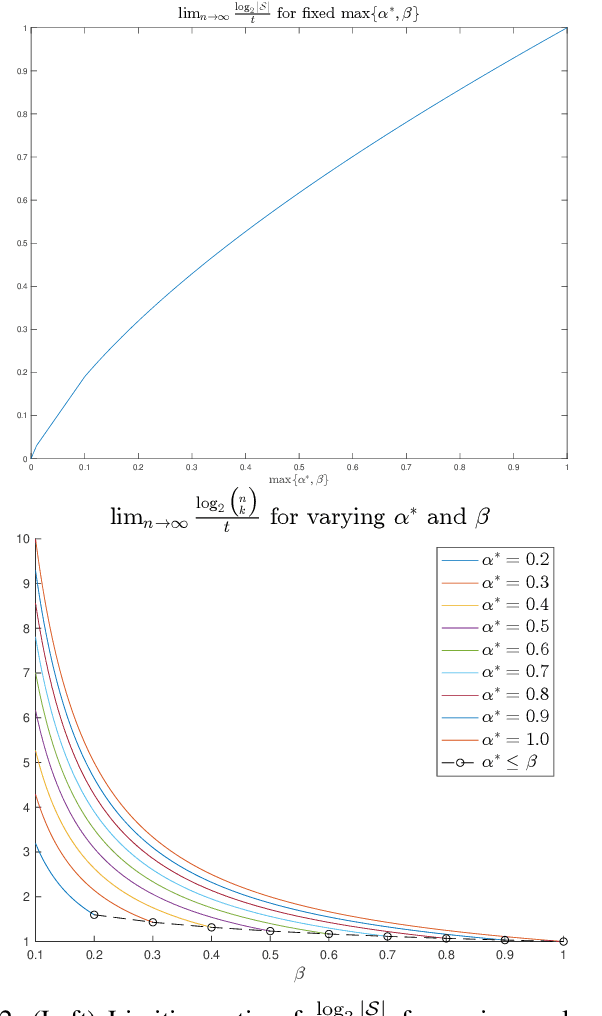
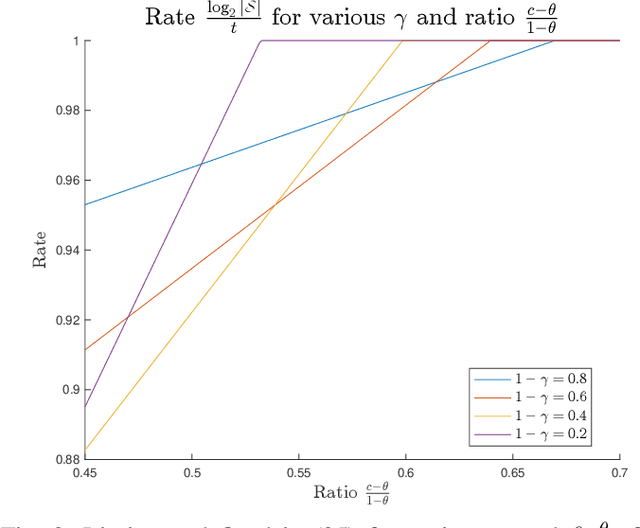
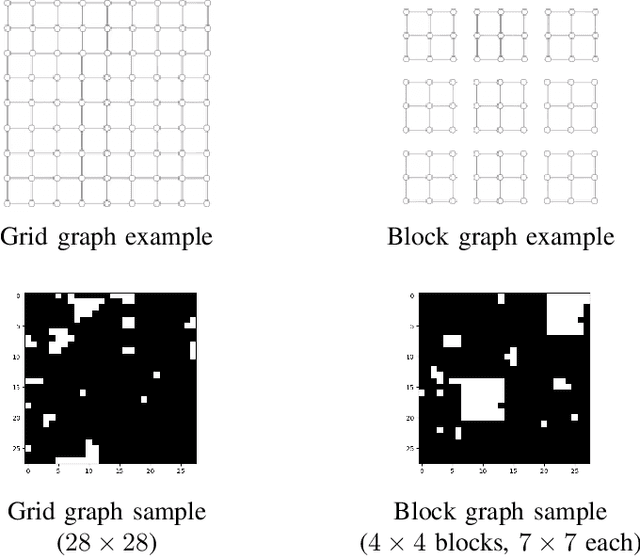
The goal of the group testing problem is to identify a set of defective items within a larger set of items, using suitably-designed tests whose outcomes indicate whether any defective item is present. In this paper, we study how the number of tests can be significantly decreased by leveraging the structural dependencies between the items, i.e., by incorporating prior information. To do so, we pursue two different perspectives: (i) As a generalization of the uniform combinatorial prior, we consider the case that the defective set is uniform over a \emph{subset} of all possible sets of a given size, and study how this impacts the information-theoretic limits on the number of tests for approximate recovery; (ii) As a generalization of the i.i.d.~prior, we introduce a new class of priors based on the Ising model, where the associated graph represents interactions between items. We show that this naturally leads to an Integer Quadratic Program decoder, which can be converted to an Integer Linear Program and/or relaxed to a non-integer variant for improved computational complexity, while maintaining strong empirical recovery performance.
Trichomonas Vaginalis Segmentation in Microscope Images
Jul 03, 2022

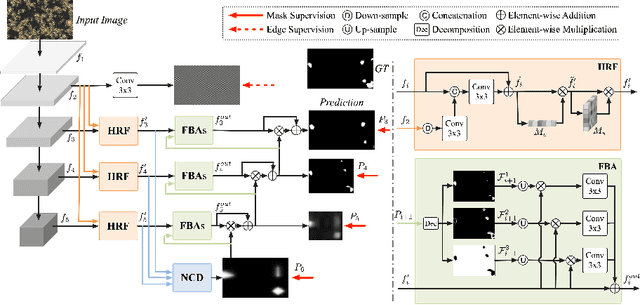
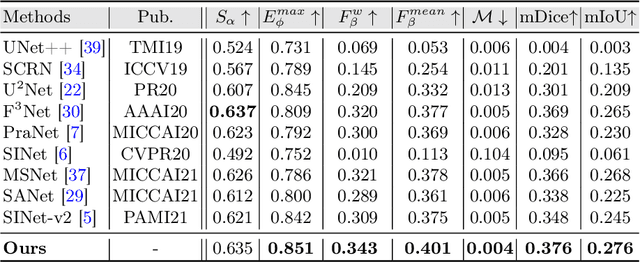
Trichomoniasis is a common infectious disease with high incidence caused by the parasite Trichomonas vaginalis, increasing the risk of getting HIV in humans if left untreated. Automated detection of Trichomonas vaginalis from microscopic images can provide vital information for the diagnosis of trichomoniasis. However, accurate Trichomonas vaginalis segmentation (TVS) is a challenging task due to the high appearance similarity between the Trichomonas and other cells (e.g., leukocyte), the large appearance variation caused by their motility, and, most importantly, the lack of large-scale annotated data for deep model training. To address these challenges, we elaborately collected the first large-scale Microscopic Image dataset of Trichomonas Vaginalis, named TVMI3K, which consists of 3,158 images covering Trichomonas of various appearances in diverse backgrounds, with high-quality annotations including object-level mask labels, object boundaries, and challenging attributes. Besides, we propose a simple yet effective baseline, termed TVNet, to automatically segment Trichomonas from microscopic images, including high-resolution fusion and foreground-background attention modules. Extensive experiments demonstrate that our model achieves superior segmentation performance and outperforms various cutting-edge object detection models both quantitatively and qualitatively, making it a promising framework to promote future research in TVS tasks. The dataset and results will be publicly available at: https://github.com/CellRecog/cellRecog.
* Accepted by MICCAI2022
Efficient exact computation of the conjunctive and disjunctive decompositions of D-S Theory for information fusion: Translation and extension
Jul 13, 2021Dempster-Shafer Theory (DST) generalizes Bayesian probability theory, offering useful additional information, but suffers from a high computational burden. A lot of work has been done to reduce the complexity of computations used in information fusion with Dempster's rule. Yet, few research had been conducted to reduce the complexity of computations for the conjunctive and disjunctive decompositions of evidence, which are at the core of other important methods of information fusion. In this paper, we propose a method designed to exploit the actual evidence (information) contained in these decompositions in order to compute them. It is based on a new notion that we call focal point, derived from the notion of focal set. With it, we are able to reduce these computations up to a linear complexity in the number of focal sets in some cases. In a broader perspective, our formulas have the potential to be tractable when the size of the frame of discernment exceeds a few dozen possible states, contrary to the existing litterature. This article extends (and translates) our work published at the french conference GRETSI in 2019.
Cycle-Interactive Generative Adversarial Network for Robust Unsupervised Low-Light Enhancement
Jul 03, 2022
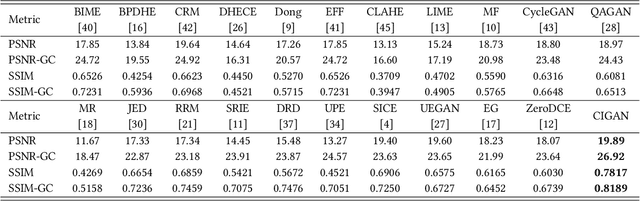
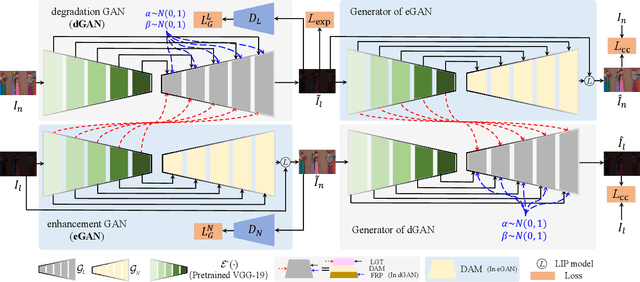
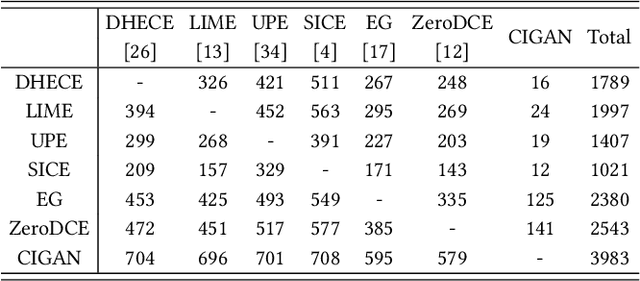
Getting rid of the fundamental limitations in fitting to the paired training data, recent unsupervised low-light enhancement methods excel in adjusting illumination and contrast of images. However, for unsupervised low light enhancement, the remaining noise suppression issue due to the lacking of supervision of detailed signal largely impedes the wide deployment of these methods in real-world applications. Herein, we propose a novel Cycle-Interactive Generative Adversarial Network (CIGAN) for unsupervised low-light image enhancement, which is capable of not only better transferring illumination distributions between low/normal-light images but also manipulating detailed signals between two domains, e.g., suppressing/synthesizing realistic noise in the cyclic enhancement/degradation process. In particular, the proposed low-light guided transformation feed-forwards the features of low-light images from the generator of enhancement GAN (eGAN) into the generator of degradation GAN (dGAN). With the learned information of real low-light images, dGAN can synthesize more realistic diverse illumination and contrast in low-light images. Moreover, the feature randomized perturbation module in dGAN learns to increase the feature randomness to produce diverse feature distributions, persuading the synthesized low-light images to contain realistic noise. Extensive experiments demonstrate both the superiority of the proposed method and the effectiveness of each module in CIGAN.
Tracing Knowledge in Language Models Back to the Training Data
May 24, 2022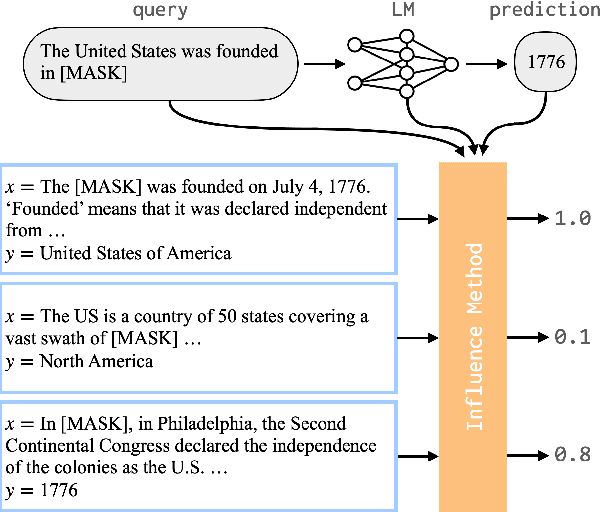
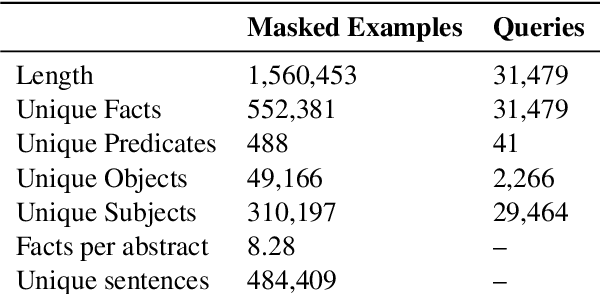
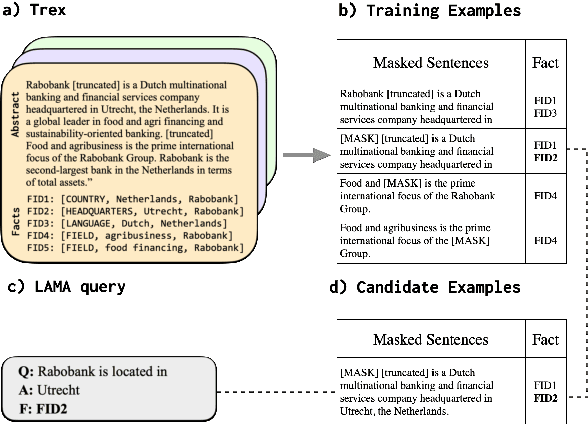
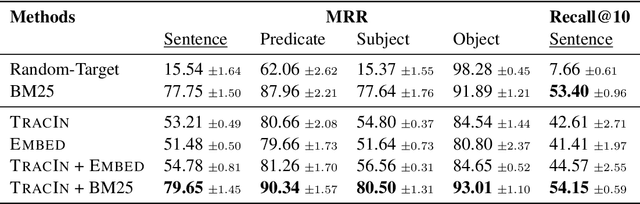
Neural language models (LMs) have been shown to memorize a great deal of factual knowledge. But when an LM generates an assertion, it is often difficult to determine where it learned this information and whether it is true. In this paper, we introduce a new benchmark for fact tracing: tracing language models' assertions back to the training examples that provided evidence for those predictions. Prior work has suggested that dataset-level influence methods might offer an effective framework for tracing predictions back to training data. However, such methods have not been evaluated for fact tracing, and researchers primarily have studied them through qualitative analysis or as a data cleaning technique for classification/regression tasks. We present the first experiments that evaluate influence methods for fact tracing, using well-understood information retrieval (IR) metrics. We compare two popular families of influence methods -- gradient-based and embedding-based -- and show that neither can fact-trace reliably; indeed, both methods fail to outperform an IR baseline (BM25) that does not even access the LM. We explore why this occurs (e.g., gradient saturation) and demonstrate that existing influence methods must be improved significantly before they can reliably attribute factual predictions in LMs.
Sharing pattern submodels for prediction with missing values
Jun 22, 2022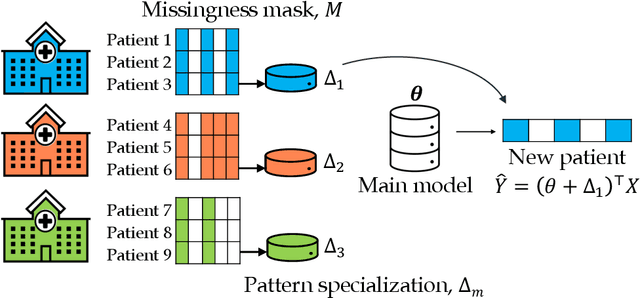
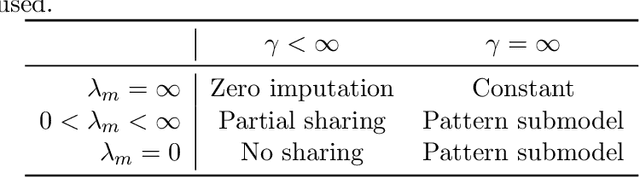
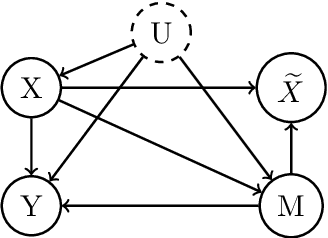
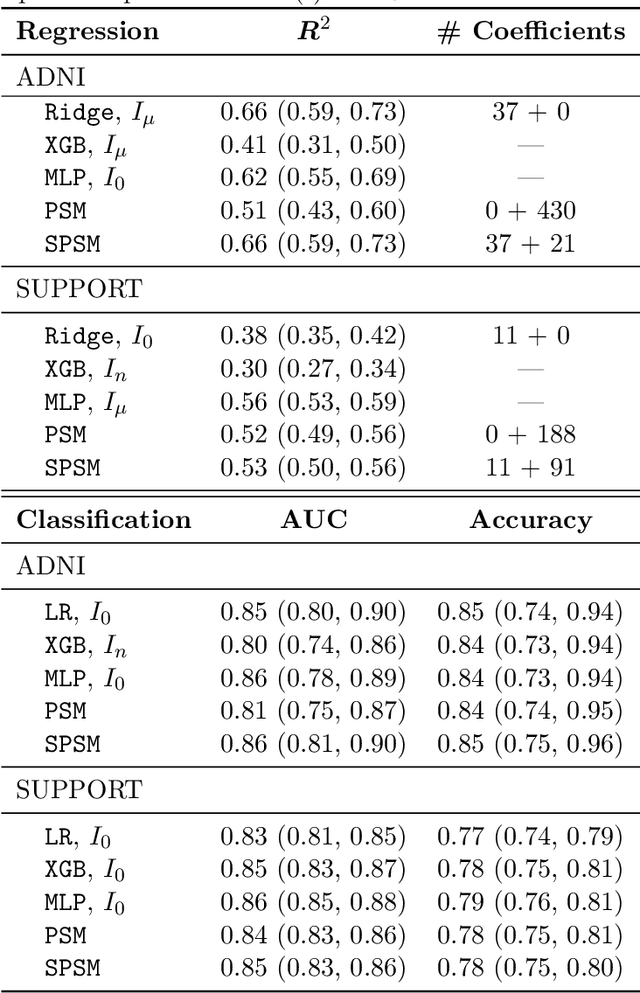
Missing values are unavoidable in many applications of machine learning and present a challenge both during training and at test time. When variables are missing in recurring patterns, fitting separate pattern submodels have been proposed as a solution. However, independent models do not make efficient use of all available data. Conversely, fitting a shared model to the full data set typically relies on imputation which may be suboptimal when missingness depends on unobserved factors. We propose an alternative approach, called sharing pattern submodels, which make predictions that are a) robust to missing values at test time, b) maintains or improves the predictive power of pattern submodels, and c) has a short description enabling improved interpretability. We identify cases where sharing is provably optimal, even when missingness itself is predictive and when the prediction target depends on unobserved variables. Classification and regression experiments on synthetic data and two healthcare data sets demonstrate that our models achieve a favorable trade-off between pattern specialization and information sharing.