 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Provably Convergent Information Bottleneck Solution via ADMM
Feb 09, 2021
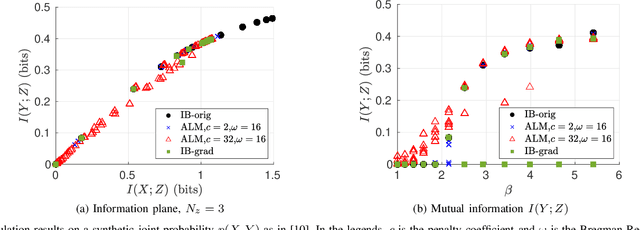
The Information bottleneck (IB) method enables optimizing over the trade-off between compression of data and prediction accuracy of learned representations, and has successfully and robustly been applied to both supervised and unsupervised representation learning problems. However, IB has several limitations. First, the IB problem is hard to optimize. The IB Lagrangian $\mathcal{L}_{IB}:=I(X;Z)-\beta I(Y;Z)$ is non-convex and existing solutions guarantee only local convergence. As a result, the obtained solutions depend on initialization. Second, the evaluation of a solution is also a challenging task. Conventionally, it resorts to characterizing the information plane, that is, plotting $I(Y;Z)$ versus $I(X;Z)$ for all solutions obtained from different initial points. Furthermore, the IB Lagrangian has phase transitions while varying the multiplier $\beta$. At phase transitions, both $I(X;Z)$ and $I(Y;Z)$ increase abruptly and the rate of convergence becomes significantly slow for existing solutions. Recent works with IB adopt variational surrogate bounds to the IB Lagrangian. Although allowing efficient optimization, how close are these surrogates to the IB Lagrangian is not clear. In this work, we solve the IB Lagrangian using augmented Lagrangian methods. With augmented variables, we show that the IB objective can be solved with the alternating direction method of multipliers (ADMM). Different from prior works, we prove that the proposed algorithm is consistently convergent, regardless of the value of $\beta$. Empirically, our gradient-descent-based method results in information plane points that are denser and comparable to those obtained through the conventional Blahut-Arimoto-based solvers.
Where Was COVID-19 First Discovered? Designing a Question-Answering System for Pandemic Situations
Apr 19, 2022

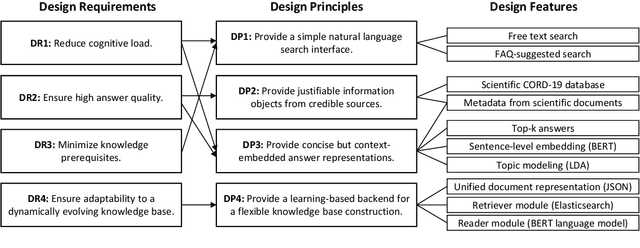

The COVID-19 pandemic is accompanied by a massive "infodemic" that makes it hard to identify concise and credible information for COVID-19-related questions, like incubation time, infection rates, or the effectiveness of vaccines. As a novel solution, our paper is concerned with designing a question-answering system based on modern technologies from natural language processing to overcome information overload and misinformation in pandemic situations. To carry out our research, we followed a design science research approach and applied Ingwersen's cognitive model of information retrieval interaction to inform our design process from a socio-technical lens. On this basis, we derived prescriptive design knowledge in terms of design requirements and design principles, which we translated into the construction of a prototypical instantiation. Our implementation is based on the comprehensive CORD-19 dataset, and we demonstrate our artifact's usefulness by evaluating its answer quality based on a sample of COVID-19 questions labeled by biomedical experts.
Semantic Room Wireframe Detection from a Single View
Jun 01, 2022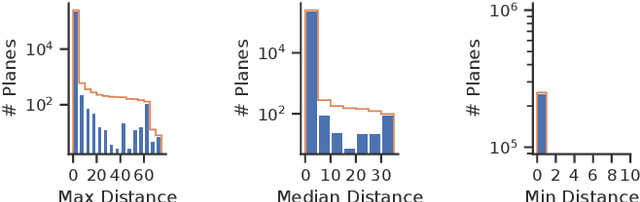
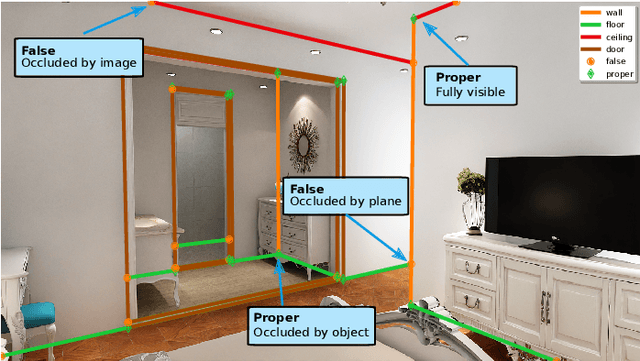
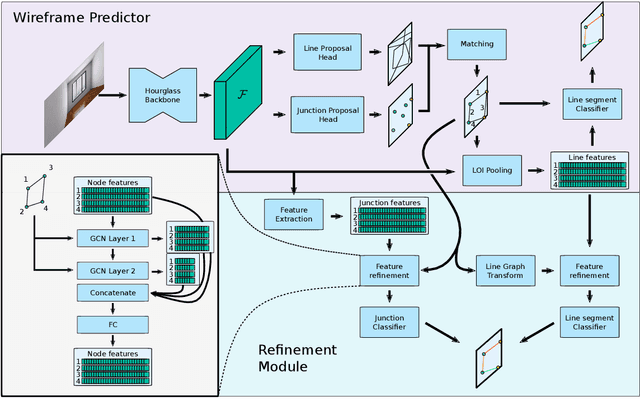
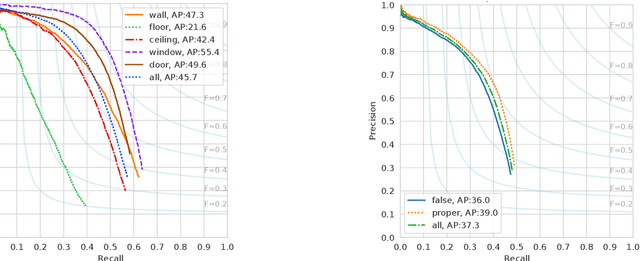
Reconstruction of indoor surfaces with limited texture information or with repeated textures, a situation common in walls and ceilings, may be difficult with a monocular Structure from Motion system. We propose a Semantic Room Wireframe Detection task to predict a Semantic Wireframe from a single perspective image. Such predictions may be used with shape priors to estimate the Room Layout and aid reconstruction. To train and test the proposed algorithm we create a new set of annotations from the simulated Structured3D dataset. We show qualitatively that the SRW-Net handles complex room geometries better than previous Room Layout Estimation algorithms while quantitatively out-performing the baseline in non-semantic Wireframe Detection.
Channel Estimation in RIS-Assisted MIMO Systems Operating Under Imperfections
Jul 06, 2022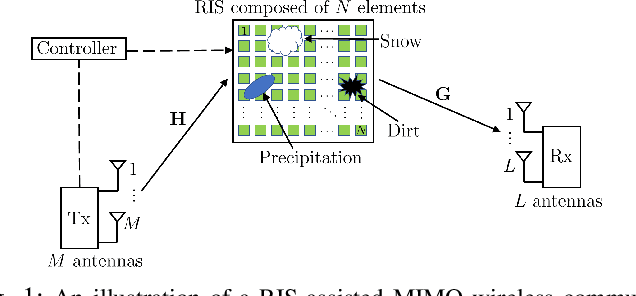
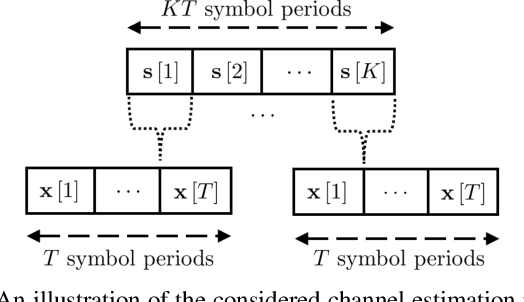
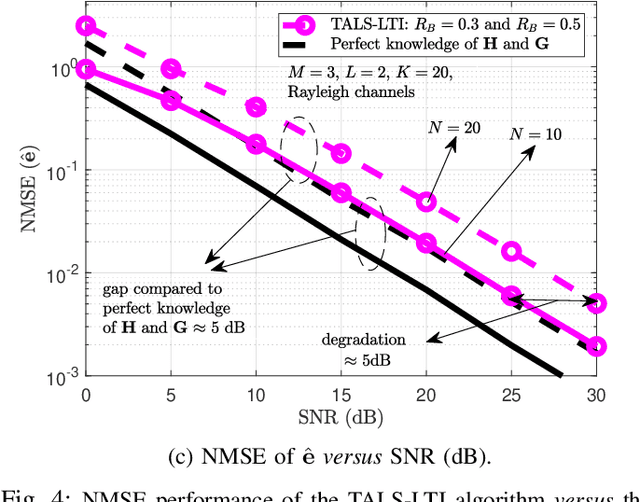
Reconfigurable intelligent surface is a potential technology component of future wireless networks due to its capability of shaping the wireless environment. The promising MIMO systems in terms of extended coverage and enhanced capacity are, however, critically dependent on the accuracy of the channel state information. However, traditional channel estimation schemes are not applicable in RIS-assisted MIMO networks, since passive RISs typically lack the signal processing capabilities that are assumed by channel estimation algorithms. This becomes most problematic when physical imperfections or electronic impairments affect the RIS due to its exposition to different environmental effects or caused by hardware limitations from the circuitry. While these real-world effects are typically ignored in the literature, in this paper we propose efficient channel estimation schemes for RIS-assisted MIMO systems taking different imperfections into account. Specifically, we propose two sets of tensor-based algorithms, based on the parallel factor analysis decomposition schemes. First, by assuming a long-term model in which the RIS imperfections, modeled as unknown phase shifts, are static within the channel coherence time we formulate an iterative alternating least squares (ALS)-based algorithm for the joint estimation of the communication channels and the unknown phase deviations. Next, we develop the short-term imperfection model, which allows both amplitude and phase RIS imperfections to be non-static with respect to the channel coherence time. We propose two iterative ALS-based and closed-form higher order singular value decomposition-based algorithms for the joint estimation of the channels and the unknown impairments. Moreover, we analyze the identifiability and computational complexity of the proposed algorithms and study the effects of various imperfections on the channel estimation quality.
SD-LayerNet: Semi-supervised retinal layer segmentation in OCT using disentangled representation with anatomical priors
Jul 01, 2022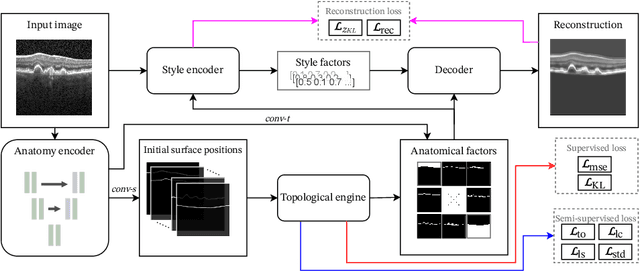
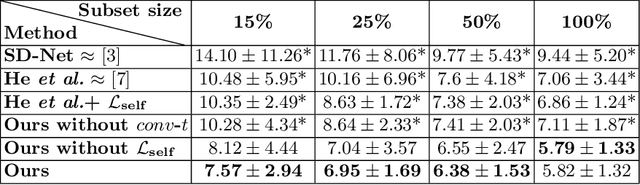
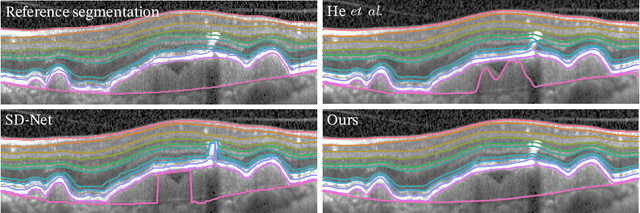

Optical coherence tomography (OCT) is a non-invasive 3D modality widely used in ophthalmology for imaging the retina. Achieving automated, anatomically coherent retinal layer segmentation on OCT is important for the detection and monitoring of different retinal diseases, like Age-related Macular Disease (AMD) or Diabetic Retinopathy. However, the majority of state-of-the-art layer segmentation methods are based on purely supervised deep-learning, requiring a large amount of pixel-level annotated data that is expensive and hard to obtain. With this in mind, we introduce a semi-supervised paradigm into the retinal layer segmentation task that makes use of the information present in large-scale unlabeled datasets as well as anatomical priors. In particular, a novel fully differentiable approach is used for converting surface position regression into a pixel-wise structured segmentation, allowing to use both 1D surface and 2D layer representations in a coupled fashion to train the model. In particular, these 2D segmentations are used as anatomical factors that, together with learned style factors, compose disentangled representations used for reconstructing the input image. In parallel, we propose a set of anatomical priors to improve network training when a limited amount of labeled data is available. We demonstrate on the real-world dataset of scans with intermediate and wet-AMD that our method outperforms state-of-the-art when using our full training set, but more importantly largely exceeds state-of-the-art when it is trained with a fraction of the labeled data.
EHRKit: A Python Natural Language Processing Toolkit for Electronic Health Record Texts
Apr 13, 2022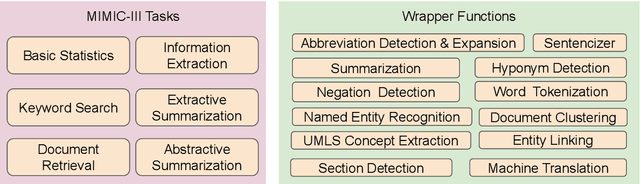

The Electronic Health Record (EHR) is an essential part of the modern medical system and impacts healthcare delivery, operations, and research. Unstructured text is attracting much attention despite structured information in the EHRs and has become an exciting research field. The success of the recent neural Natural Language Processing (NLP) method has led to a new direction for processing unstructured clinical notes. In this work, we create a python library for clinical texts, EHRKit. This library contains two main parts: MIMIC-III-specific functions and tasks specific functions. The first part introduces a list of interfaces for accessing MIMIC-III NOTEEVENTS data, including basic search, information retrieval, and information extraction. The second part integrates many third-party libraries for up to 12 off-shelf NLP tasks such as named entity recognition, summarization, machine translation, etc.
INSTA-BNN: Binary Neural Network with INSTAnce-aware Threshold
Apr 15, 2022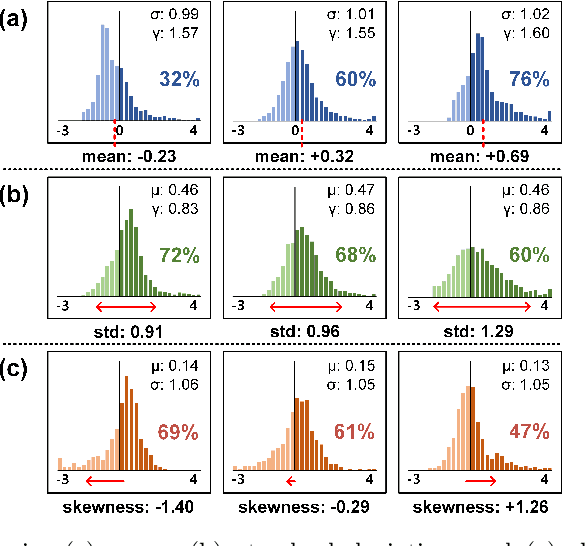
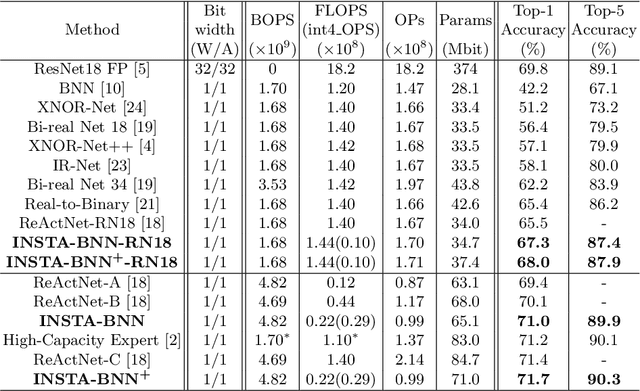
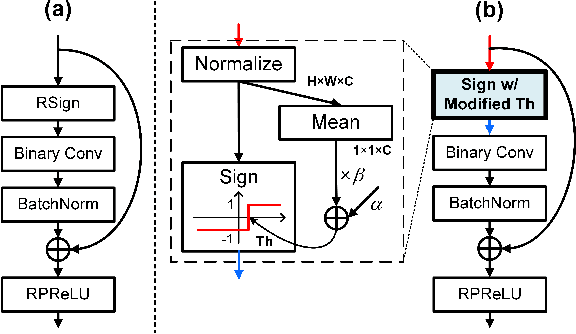

Binary Neural Networks (BNNs) have emerged as a promising solution for reducing the memory footprint and compute costs of deep neural networks. BNNs, on the other hand, suffer from information loss because binary activations are limited to only two values, resulting in reduced accuracy. To improve the accuracy, previous studies have attempted to control the distribution of binary activation by manually shifting the threshold of the activation function or making the shift amount trainable. During the process, they usually depended on statistical information computed from a batch. We argue that using statistical data from a batch fails to capture the crucial information for each input instance in BNN computations, and the differences between statistical information computed from each instance need to be considered when determining the binary activation threshold of each instance. Based on the concept, we propose the Binary Neural Network with INSTAnce-aware threshold (INSTA-BNN), which decides the activation threshold value considering the difference between statistical data computed from a batch and each instance. The proposed INSTA-BNN outperforms the baseline by 2.5% and 2.3% on the ImageNet classification task with comparable computing cost, achieving 68.0% and 71.7% top-1 accuracy on ResNet-18 and MobileNetV1 based models, respectively.
Semantic Segmentation for Thermal Images: A Comparative Survey
May 26, 2022
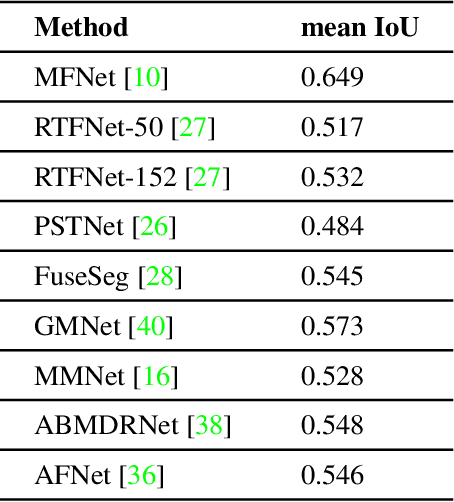


Semantic segmentation is a challenging task since it requires excessively more low-level spatial information of the image compared to other computer vision problems. The accuracy of pixel-level classification can be affected by many factors, such as imaging limitations and the ambiguity of object boundaries in an image. Conventional methods exploit three-channel RGB images captured in the visible spectrum with deep neural networks (DNN). Thermal images can significantly contribute during the segmentation since thermal imaging cameras are capable of capturing details despite the weather and illumination conditions. Using infrared spectrum in semantic segmentation has many real-world use cases, such as autonomous driving, medical imaging, agriculture, defense industry, etc. Due to this wide range of use cases, designing accurate semantic segmentation algorithms with the help of infrared spectrum is an important challenge. One approach is to use both visible and infrared spectrum images as inputs. These methods can accomplish higher accuracy due to enriched input information, with the cost of extra effort for the alignment and processing of multiple inputs. Another approach is to use only thermal images, enabling less hardware cost for smaller use cases. Even though there are multiple surveys on semantic segmentation methods, the literature lacks a comprehensive survey centered explicitly around semantic segmentation using infrared spectrum. This work aims to fill this gap by presenting algorithms in the literature and categorizing them by their input images.
Generating Full Length Wikipedia Biographies: The Impact of Gender Bias on the Retrieval-Based Generation of Women Biographies
Apr 12, 2022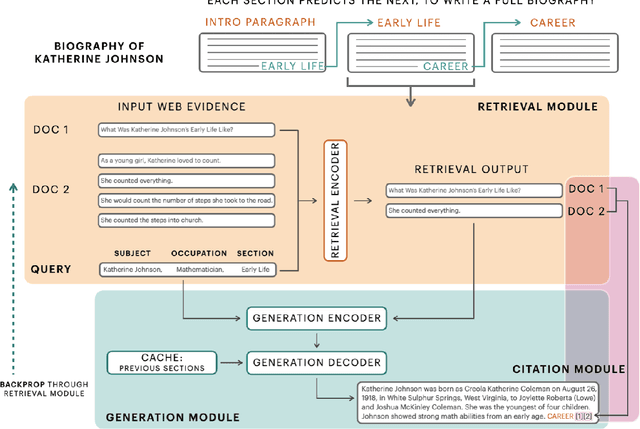

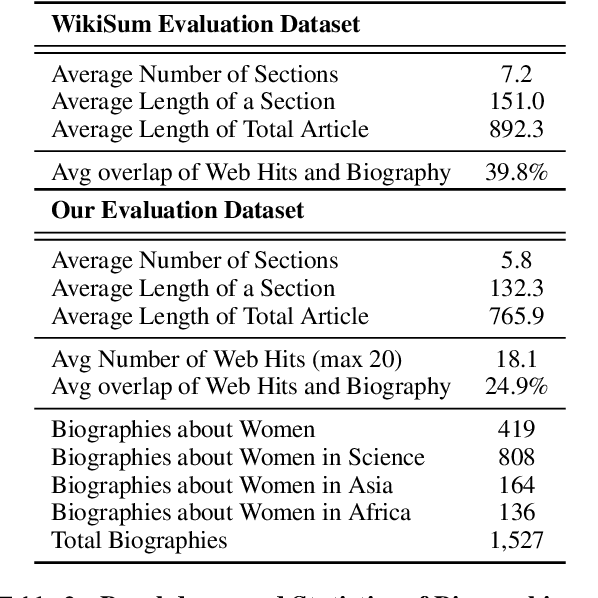

Generating factual, long-form text such as Wikipedia articles raises three key challenges: how to gather relevant evidence, how to structure information into well-formed text, and how to ensure that the generated text is factually correct. We address these by developing a model for English text that uses a retrieval mechanism to identify relevant supporting information on the web and a cache-based pre-trained encoder-decoder to generate long-form biographies section by section, including citation information. To assess the impact of available web evidence on the output text, we compare the performance of our approach when generating biographies about women (for which less information is available on the web) vs. biographies generally. To this end, we curate a dataset of 1,500 biographies about women. We analyze our generated text to understand how differences in available web evidence data affect generation. We evaluate the factuality, fluency, and quality of the generated texts using automatic metrics and human evaluation. We hope that these techniques can be used as a starting point for human writers, to aid in reducing the complexity inherent in the creation of long-form, factual text.
Enhanced Knowledge Selection for Grounded Dialogues via Document Semantic Graphs
Jun 15, 2022
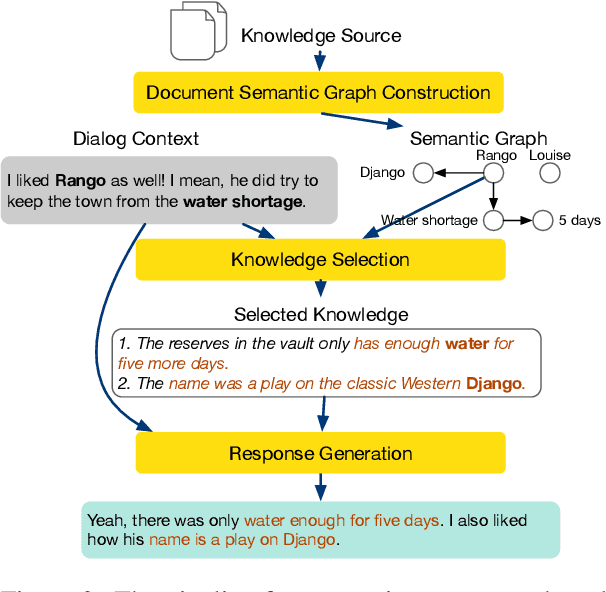
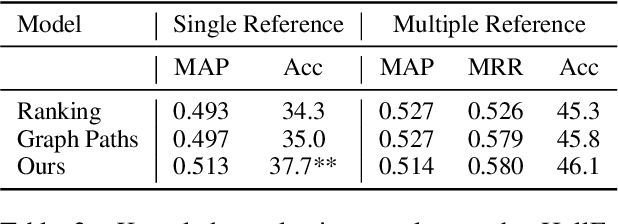
Providing conversation models with background knowledge has been shown to make open-domain dialogues more informative and engaging. Existing models treat knowledge selection as a sentence ranking or classification problem where each sentence is handled individually, ignoring the internal semantic connection among sentences in the background document. In this work, we propose to automatically convert the background knowledge documents into document semantic graphs and then perform knowledge selection over such graphs. Our document semantic graphs preserve sentence-level information through the use of sentence nodes and provide concept connections between sentences. We jointly apply multi-task learning for sentence-level and concept-level knowledge selection and show that it improves sentence-level selection. Our experiments show that our semantic graph-based knowledge selection improves over sentence selection baselines for both the knowledge selection task and the end-to-end response generation task on HollE and improves generalization on unseen topics in WoW.