 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Comparing feature fusion strategies for Deep Learning-based kidney stone identification
May 31, 2022
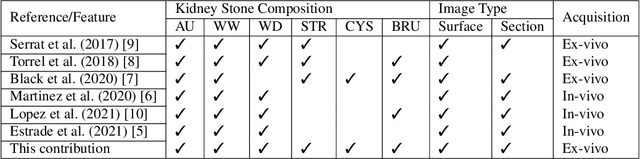
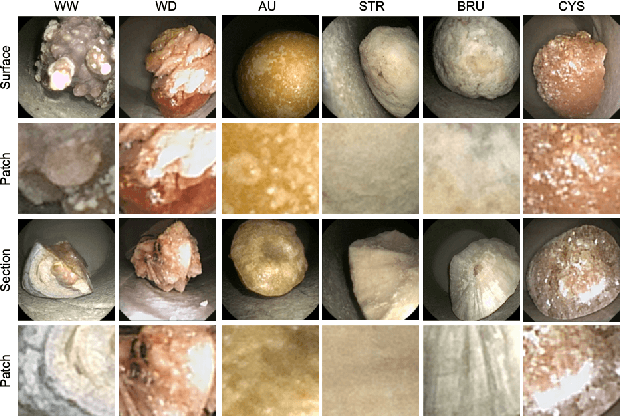
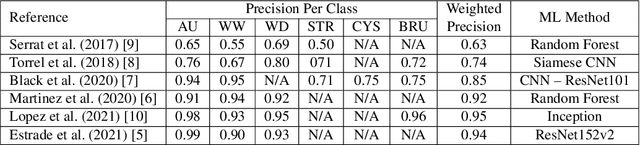
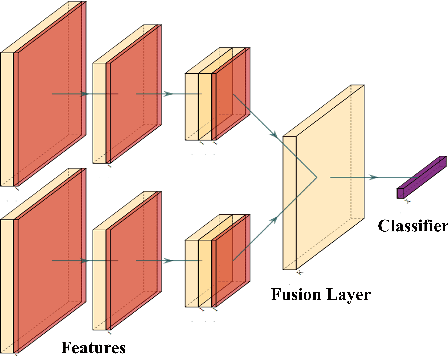
This contribution presents a deep-learning method for extracting and fusing image information acquired from different viewpoints with the aim to produce more discriminant object features. Our approach was specifically designed to mimic the morpho-constitutional analysis used by urologists to visually classify kidney stones by inspecting the sections and surfaces of their fragments. Deep feature fusion strategies improved the results of single view extraction backbone models by more than 10\% in terms of precision of the kidney stones classification.
Learning While Dissipating Information: Understanding the Generalization Capability of SGLD
Feb 05, 2021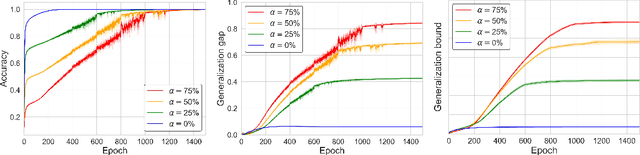
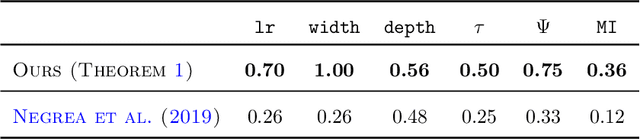
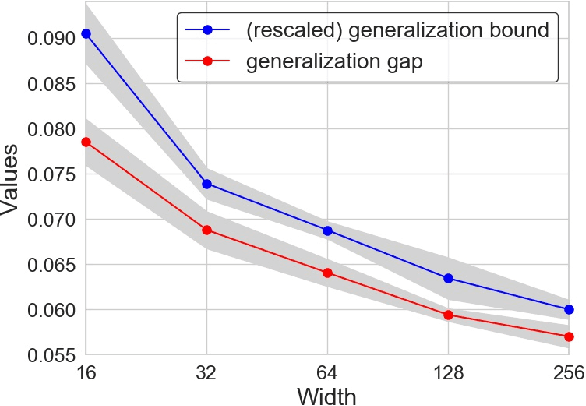
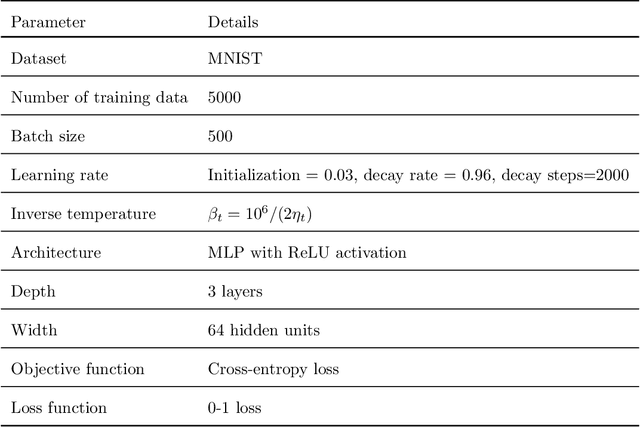
Understanding the generalization capability of learning algorithms is at the heart of statistical learning theory. In this paper, we investigate the generalization gap of stochastic gradient Langevin dynamics (SGLD), a widely used optimizer for training deep neural networks (DNNs). We derive an algorithm-dependent generalization bound by analyzing SGLD through an information-theoretic lens. Our analysis reveals an intricate trade-off between learning and information dissipation: SGLD learns from data by updating parameters at each iteration while dissipating information from early training stages. Our bound also involves the variance of gradients which captures a particular kind of "sharpness" of the loss landscape. The main proof techniques in this paper rely on strong data processing inequalities -- a fundamental concept in information theory -- and Otto-Villani's HWI inequality. Finally, we demonstrate our bound through numerical experiments, showing that it can predict the behavior of the true generalization gap.
You Are What You Write: Preserving Privacy in the Era of Large Language Models
Apr 20, 2022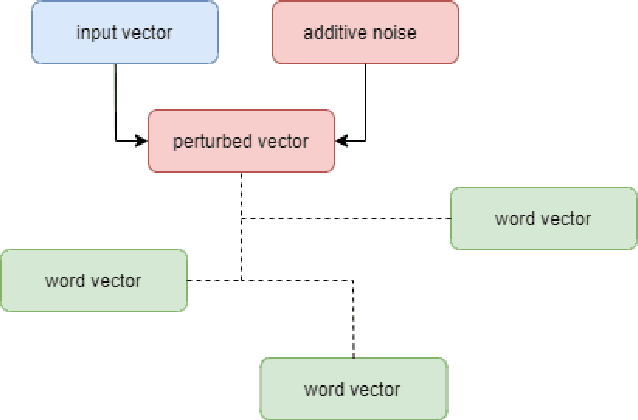

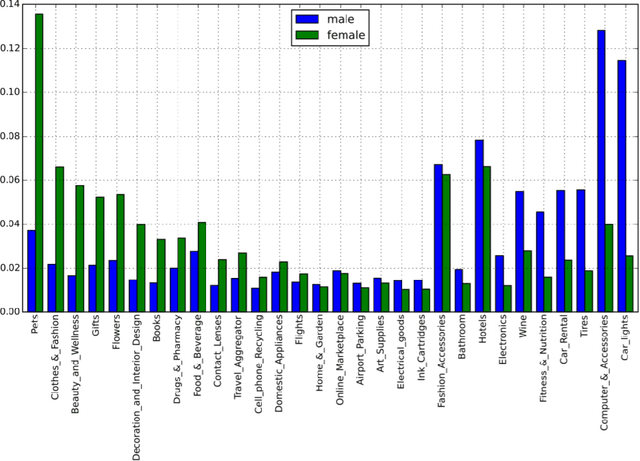
Large scale adoption of large language models has introduced a new era of convenient knowledge transfer for a slew of natural language processing tasks. However, these models also run the risk of undermining user trust by exposing unwanted information about the data subjects, which may be extracted by a malicious party, e.g. through adversarial attacks. We present an empirical investigation into the extent of the personal information encoded into pre-trained representations by a range of popular models, and we show a positive correlation between the complexity of a model, the amount of data used in pre-training, and data leakage. In this paper, we present the first wide coverage evaluation and comparison of some of the most popular privacy-preserving algorithms, on a large, multi-lingual dataset on sentiment analysis annotated with demographic information (location, age and gender). The results show since larger and more complex models are more prone to leaking private information, use of privacy-preserving methods is highly desirable. We also find that highly privacy-preserving technologies like differential privacy (DP) can have serious model utility effects, which can be ameliorated using hybrid or metric-DP techniques.
Planning through Workspace Constraint Satisfaction and Optimization
Jun 16, 2022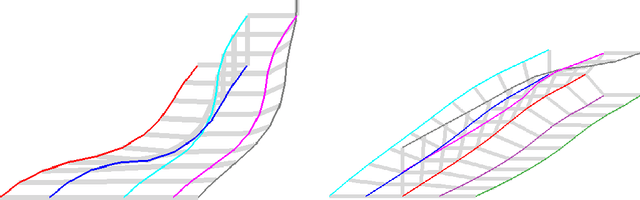
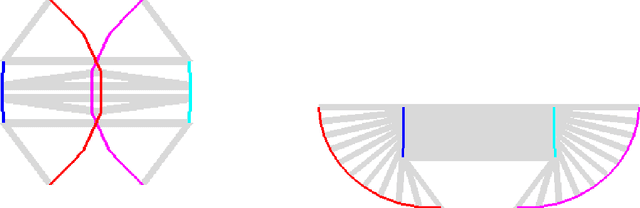
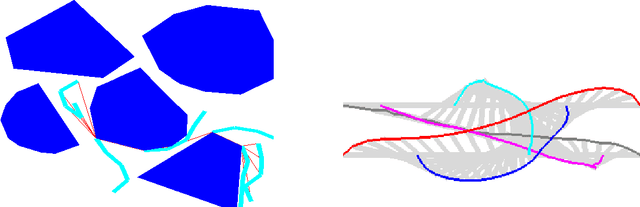
In this work, we present a workspace-based planning framework, which though using redundant workspace key-points to represent robot states, can take advantage of the interpretable geometric information to derive good quality collision-free paths for even complex robots. Using workspace geometries, we first find collision-free piece-wise linear paths for each key point so that at the endpoints of each segment, the distance constraints are satisfied among the key points. Using these piece-wise linear paths as initial conditions, we can perform optimization steps to quickly find paths that satisfy various constraints and piece together all segments to obtain a valid path. We show that these adjusted paths are unlikely to create a collision, and the proposed approach is fast and can produce good quality results.
InfoVAEGAN : learning joint interpretable representations by information maximization and maximum likelihood
Jul 09, 2021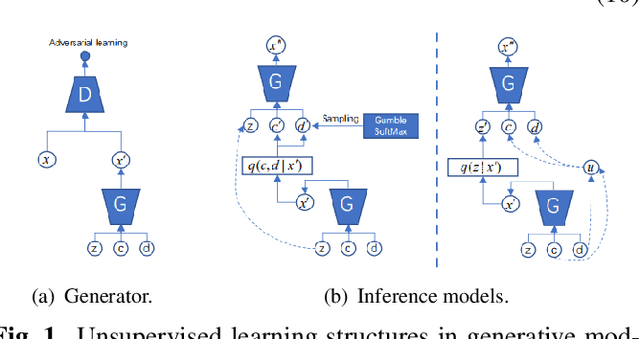
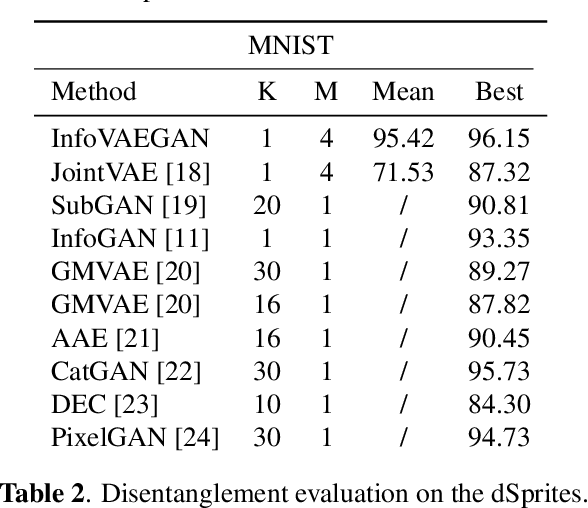

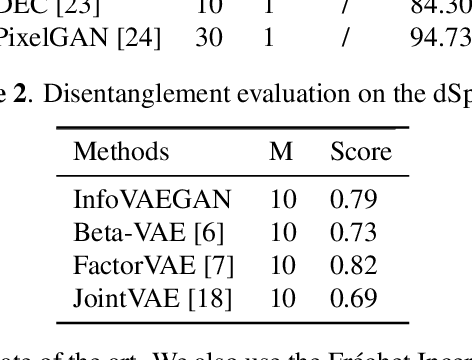
Learning disentangled and interpretable representations is an important step towards accomplishing comprehensive data representations on the manifold. In this paper, we propose a novel representation learning algorithm which combines the inference abilities of Variational Autoencoders (VAE) with the generalization capability of Generative Adversarial Networks (GAN). The proposed model, called InfoVAEGAN, consists of three networks~: Encoder, Generator and Discriminator. InfoVAEGAN aims to jointly learn discrete and continuous interpretable representations in an unsupervised manner by using two different data-free log-likelihood functions onto the variables sampled from the generator's distribution. We propose a two-stage algorithm for optimizing the inference network separately from the generator training. Moreover, we enforce the learning of interpretable representations through the maximization of the mutual information between the existing latent variables and those created through generative and inference processes.
Variational Deep Image Restoration
Jul 03, 2022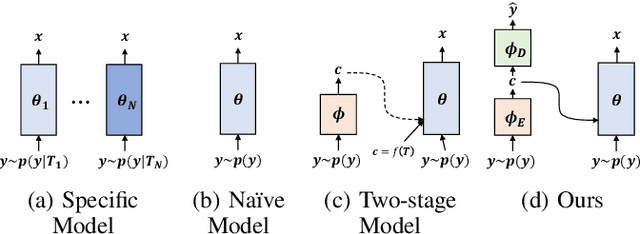
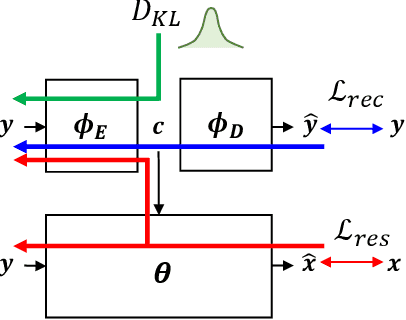
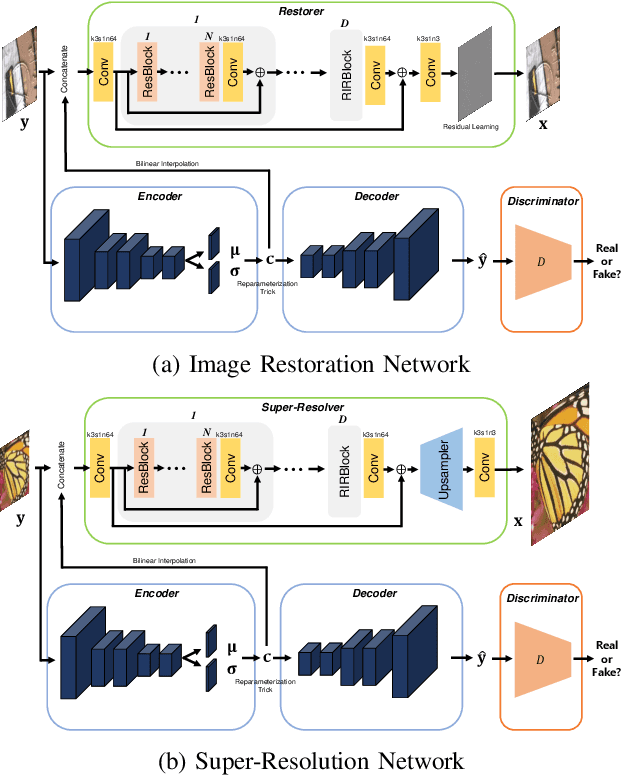
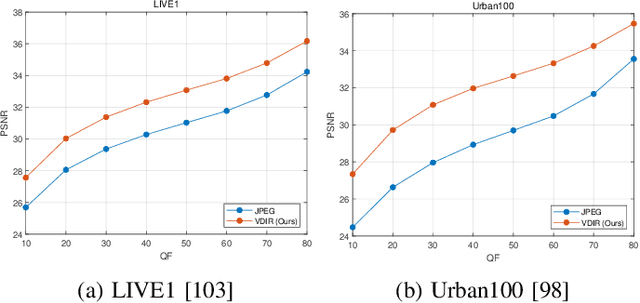
This paper presents a new variational inference framework for image restoration and a convolutional neural network (CNN) structure that can solve the restoration problems described by the proposed framework. Earlier CNN-based image restoration methods primarily focused on network architecture design or training strategy with non-blind scenarios where the degradation models are known or assumed. For a step closer to real-world applications, CNNs are also blindly trained with the whole dataset, including diverse degradations. However, the conditional distribution of a high-quality image given a diversely degraded one is too complicated to be learned by a single CNN. Therefore, there have also been some methods that provide additional prior information to train a CNN. Unlike previous approaches, we focus more on the objective of restoration based on the Bayesian perspective and how to reformulate the objective. Specifically, our method relaxes the original posterior inference problem to better manageable sub-problems and thus behaves like a divide-and-conquer scheme. As a result, the proposed framework boosts the performance of several restoration problems compared to the previous ones. Specifically, our method delivers state-of-the-art performance on Gaussian denoising, real-world noise reduction, blind image super-resolution, and JPEG compression artifacts reduction.
Explore Spatio-temporal Aggregation for Insubstantial Object Detection: Benchmark Dataset and Baseline
Jun 23, 2022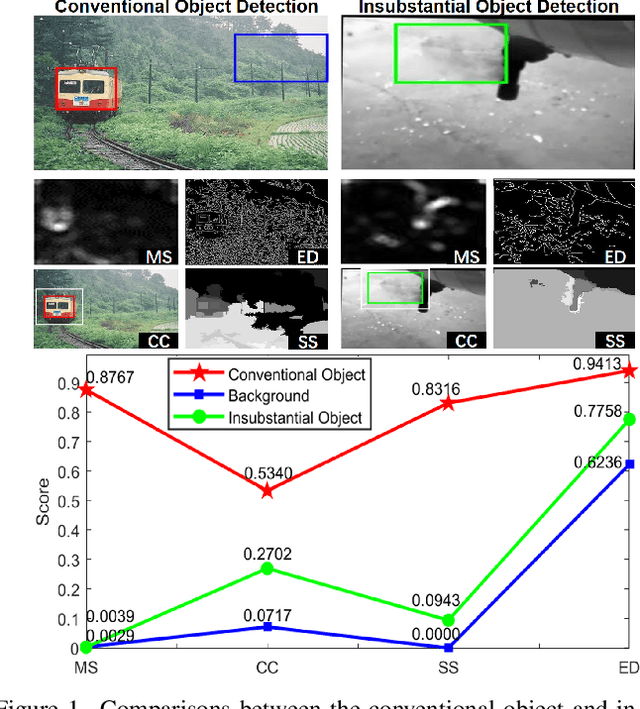
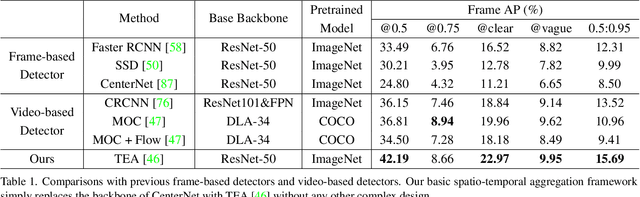
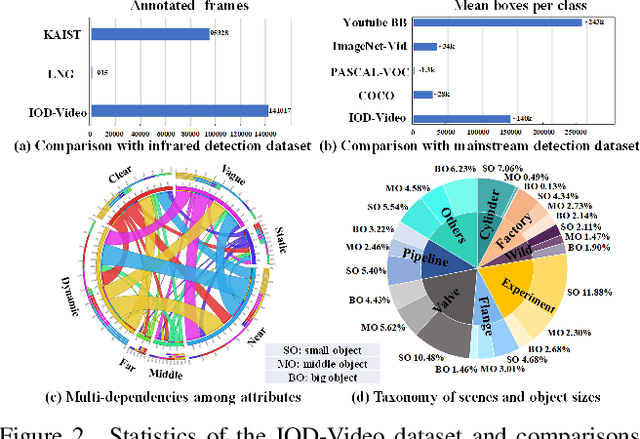
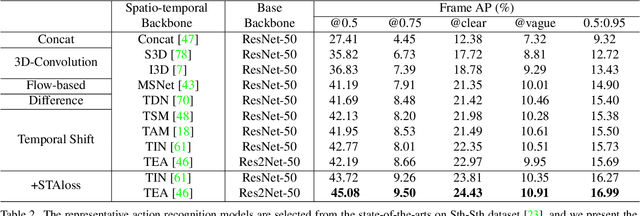
We endeavor on a rarely explored task named Insubstantial Object Detection (IOD), which aims to localize the object with following characteristics: (1) amorphous shape with indistinct boundary; (2) similarity to surroundings; (3) absence in color. Accordingly, it is far more challenging to distinguish insubstantial objects in a single static frame and the collaborative representation of spatial and temporal information is crucial. Thus, we construct an IOD-Video dataset comprised of 600 videos (141,017 frames) covering various distances, sizes, visibility, and scenes captured by different spectral ranges. In addition, we develop a spatio-temporal aggregation framework for IOD, in which different backbones are deployed and a spatio-temporal aggregation loss (STAloss) is elaborately designed to leverage the consistency along the time axis. Experiments conducted on IOD-Video dataset demonstrate that spatio-temporal aggregation can significantly improve the performance of IOD. We hope our work will attract further researches into this valuable yet challenging task. The code will be available at: \url{https://github.com/CalayZhou/IOD-Video}.
LiDAR-as-Camera for End-to-End Driving
Jun 30, 2022


The core task of any autonomous driving system is to transform sensory inputs into driving commands. In end-to-end driving, this is achieved via a neural network, with one or multiple cameras as the most commonly used input and low-level driving command, e.g. steering angle, as output. However, depth-sensing has been shown in simulation to make the end-to-end driving task easier. On a real car, combining depth and visual information can be challenging, due to the difficulty of obtaining good spatial and temporal alignment of the sensors. To alleviate alignment problems, Ouster LiDARs can output surround-view LiDAR-images with depth, intensity, and ambient radiation channels. These measurements originate from the same sensor, rendering them perfectly aligned in time and space. We demonstrate that such LiDAR-images are sufficient for the real-car road-following task and perform at least equally to camera-based models in the tested conditions, with the difference increasing when needing to generalize to new weather conditions. In the second direction of study, we reveal that the temporal smoothness of off-policy prediction sequences correlates equally well with actual on-policy driving ability as the commonly used mean absolute error.
Regulating Facial Processing Technologies: Tensions Between Legal and Technical Considerations in the Application of Illinois BIPA
May 15, 2022Harms resulting from the development and deployment of facial processing technologies (FPT) have been met with increasing controversy. Several states and cities in the U.S. have banned the use of facial recognition by law enforcement and governments, but FPT are still being developed and used in a wide variety of contexts where they primarily are regulated by state biometric information privacy laws. Among these laws, the 2008 Illinois Biometric Information Privacy Act (BIPA) has generated a significant amount of litigation. Yet, with most BIPA lawsuits reaching settlements before there have been meaningful clarifications of relevant technical intricacies and legal definitions, there remains a great degree of uncertainty as to how exactly this law applies to FPT. What we have found through applications of BIPA in FPT litigation so far, however, points to potential disconnects between technical and legal communities. This paper analyzes what we know based on BIPA court proceedings and highlights these points of tension: areas where the technical operationalization of BIPA may create unintended and undesirable incentives for FPT development, as well as areas where BIPA litigation can bring to light the limitations of solely technical methods in achieving legal privacy values. These factors are relevant for (i) reasoning about biometric information privacy laws as a governing mechanism for FPT, (ii) assessing the potential harms of FPT, and (iii) providing incentives for the mitigation of these harms. By illuminating these considerations, we hope to empower courts and lawmakers to take a more nuanced approach to regulating FPT and developers to better understand privacy values in the current U.S. legal landscape.
So3krates -- Self-attention for higher-order geometric interactions on arbitrary length-scales
May 28, 2022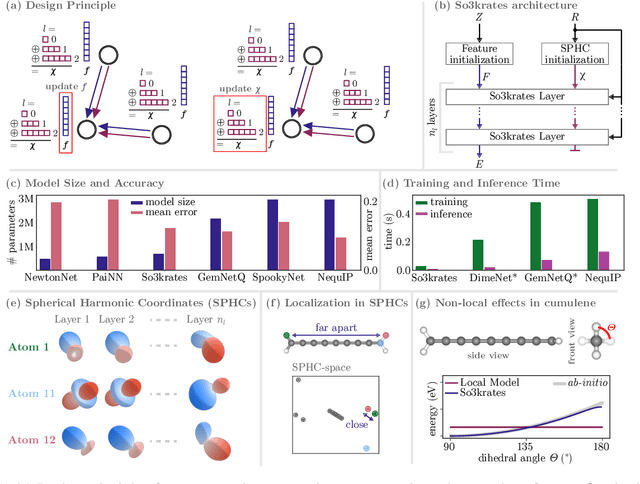
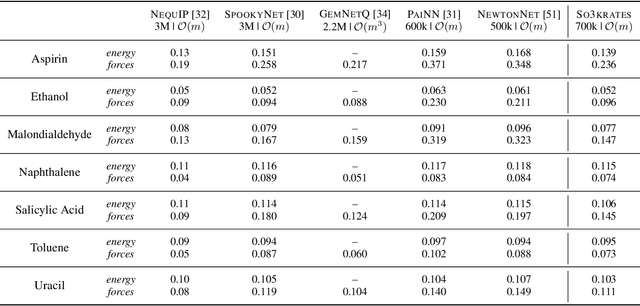
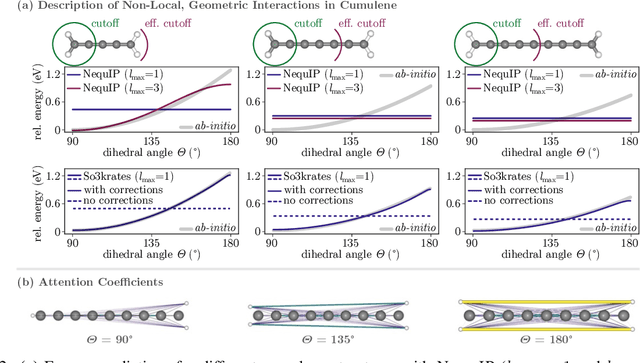

The application of machine learning methods in quantum chemistry has enabled the study of numerous chemical phenomena, which are computationally intractable with traditional ab-initio methods. However, some quantum mechanical properties of molecules and materials depend on non-local electronic effects, which are often neglected due to the difficulty of modeling them efficiently. This work proposes a modified attention mechanism adapted to the underlying physics, which allows to recover the relevant non-local effects. Namely, we introduce spherical harmonic coordinates (SPHCs) to reflect higher-order geometric information for each atom in a molecule, enabling a non-local formulation of attention in the SPHC space. Our proposed model So3krates -- a self-attention based message passing neural network -- uncouples geometric information from atomic features, making them independently amenable to attention mechanisms. We show that in contrast to other published methods, So3krates is able to describe non-local quantum mechanical effects over arbitrary length scales. Further, we find evidence that the inclusion of higher-order geometric correlations increases data efficiency and improves generalization. So3krates matches or exceeds state-of-the-art performance on popular benchmarks, notably, requiring a significantly lower number of parameters (0.25--0.4x) while at the same time giving a substantial speedup (6--14x for training and 2--11x for inference) compared to other models.