 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Provably Convergent Information Bottleneck Solution via ADMM
Feb 09, 2021
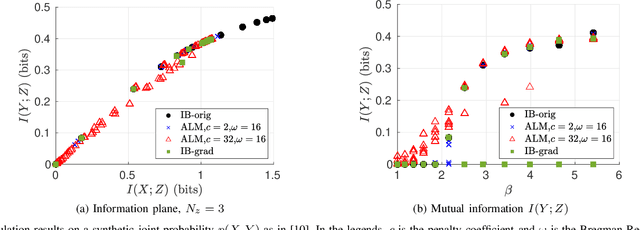
The Information bottleneck (IB) method enables optimizing over the trade-off between compression of data and prediction accuracy of learned representations, and has successfully and robustly been applied to both supervised and unsupervised representation learning problems. However, IB has several limitations. First, the IB problem is hard to optimize. The IB Lagrangian $\mathcal{L}_{IB}:=I(X;Z)-\beta I(Y;Z)$ is non-convex and existing solutions guarantee only local convergence. As a result, the obtained solutions depend on initialization. Second, the evaluation of a solution is also a challenging task. Conventionally, it resorts to characterizing the information plane, that is, plotting $I(Y;Z)$ versus $I(X;Z)$ for all solutions obtained from different initial points. Furthermore, the IB Lagrangian has phase transitions while varying the multiplier $\beta$. At phase transitions, both $I(X;Z)$ and $I(Y;Z)$ increase abruptly and the rate of convergence becomes significantly slow for existing solutions. Recent works with IB adopt variational surrogate bounds to the IB Lagrangian. Although allowing efficient optimization, how close are these surrogates to the IB Lagrangian is not clear. In this work, we solve the IB Lagrangian using augmented Lagrangian methods. With augmented variables, we show that the IB objective can be solved with the alternating direction method of multipliers (ADMM). Different from prior works, we prove that the proposed algorithm is consistently convergent, regardless of the value of $\beta$. Empirically, our gradient-descent-based method results in information plane points that are denser and comparable to those obtained through the conventional Blahut-Arimoto-based solvers.
Constructing Cross-lingual Consumer Health Vocabulary with Word-Embedding from Comparable User Generated Content
Jun 23, 2022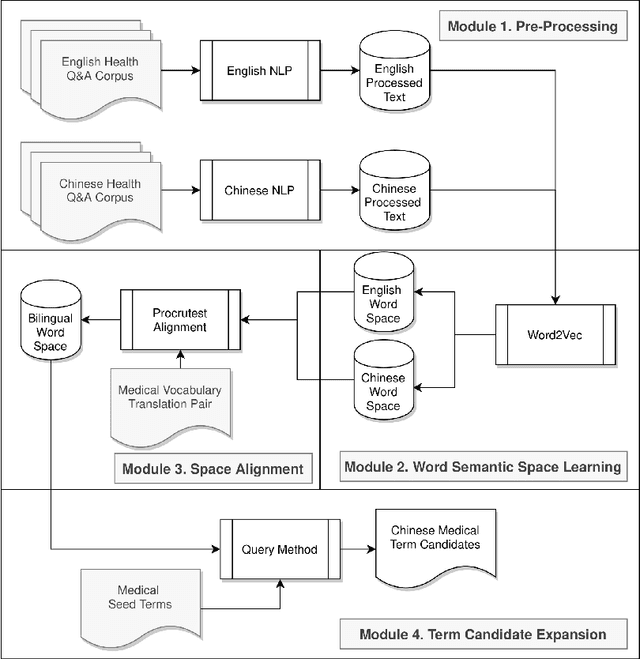

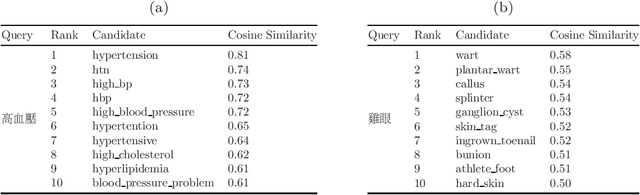
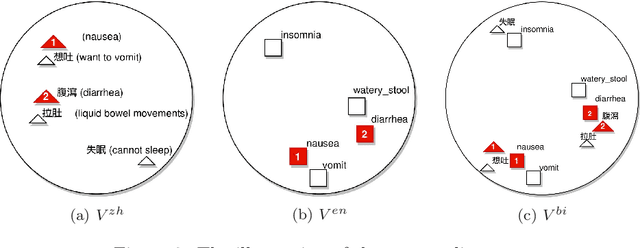
The online health community (OHC) is the primary channel for laypeople to share health information. To analyze the health consumer-generated content (HCGC) from the OHCs, identifying the colloquial medical expressions used by laypeople is a critical challenge. The open-access and collaborative consumer health vocabulary (OAC CHV) is the controlled vocabulary for addressing such a challenge. Nevertheless, OAC CHV is only available in English, limiting the applicability to other languages. This research aims to propose a cross-lingual automatic term recognition framework for extending the English OAC CHV into a cross-lingual one. Our framework requires an English HCGC corpus and a non-English (i.e., Chinese in this study) HCGC corpus as inputs. Two monolingual word vector spaces are determined using skip-gram algorithm so that each space encodes common word associations from laypeople within a language. Based on isometry assumption, the framework align two monolingual spaces into a bilingual word vector space, where we employ cosine similarity as a metric for identifying semantically similar words across languages. In the experiments, our framework demonstrates that it can effectively retrieve similar medical terms, including colloquial expressions, across languages and further facilitate compilation of cross-lingual CHV.
CONVIQT: Contrastive Video Quality Estimator
Jun 29, 2022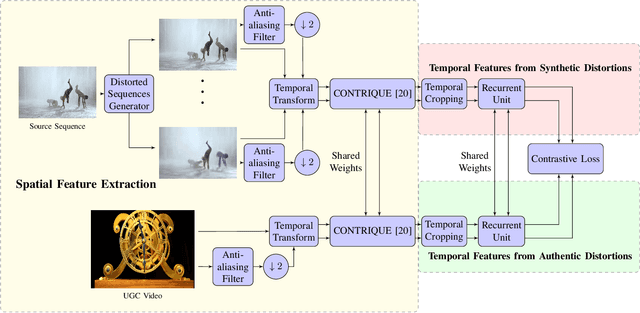
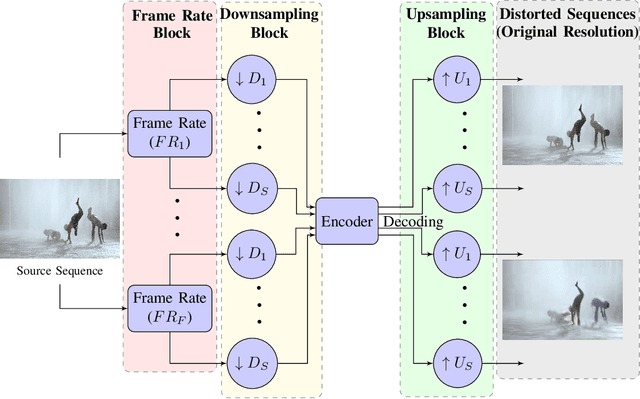


Perceptual video quality assessment (VQA) is an integral component of many streaming and video sharing platforms. Here we consider the problem of learning perceptually relevant video quality representations in a self-supervised manner. Distortion type identification and degradation level determination is employed as an auxiliary task to train a deep learning model containing a deep Convolutional Neural Network (CNN) that extracts spatial features, as well as a recurrent unit that captures temporal information. The model is trained using a contrastive loss and we therefore refer to this training framework and resulting model as CONtrastive VIdeo Quality EstimaTor (CONVIQT). During testing, the weights of the trained model are frozen, and a linear regressor maps the learned features to quality scores in a no-reference (NR) setting. We conduct comprehensive evaluations of the proposed model on multiple VQA databases by analyzing the correlations between model predictions and ground-truth quality ratings, and achieve competitive performance when compared to state-of-the-art NR-VQA models, even though it is not trained on those databases. Our ablation experiments demonstrate that the learned representations are highly robust and generalize well across synthetic and realistic distortions. Our results indicate that compelling representations with perceptual bearing can be obtained using self-supervised learning. The implementations used in this work have been made available at https://github.com/pavancm/CONVIQT.
Learning Cross-Image Object Semantic Relation in Transformer for Few-Shot Fine-Grained Image Classification
Jul 02, 2022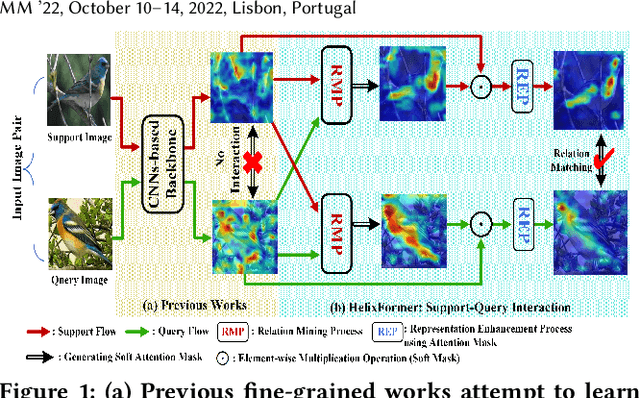
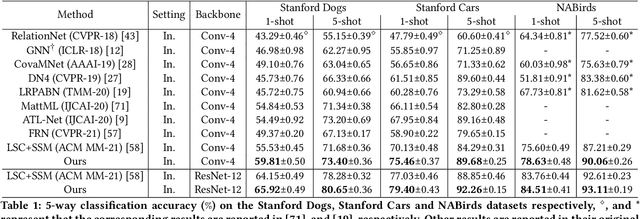
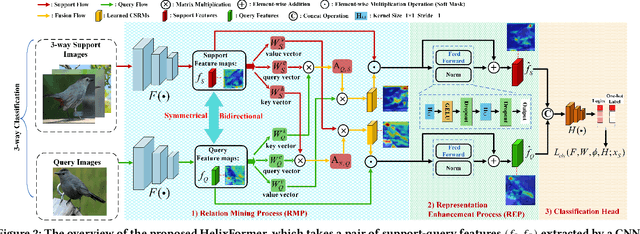
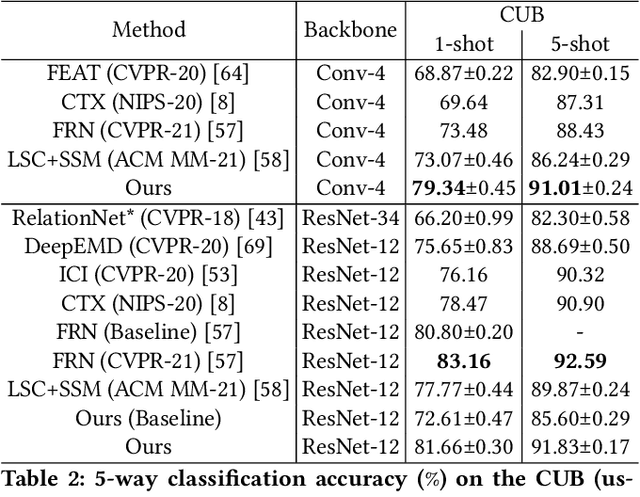
Few-shot fine-grained learning aims to classify a query image into one of a set of support categories with fine-grained differences. Although learning different objects' local differences via Deep Neural Networks has achieved success, how to exploit the query-support cross-image object semantic relations in Transformer-based architecture remains under-explored in the few-shot fine-grained scenario. In this work, we propose a Transformer-based double-helix model, namely HelixFormer, to achieve the cross-image object semantic relation mining in a bidirectional and symmetrical manner. The HelixFormer consists of two steps: 1) Relation Mining Process (RMP) across different branches, and 2) Representation Enhancement Process (REP) within each individual branch. By the designed RMP, each branch can extract fine-grained object-level Cross-image Semantic Relation Maps (CSRMs) using information from the other branch, ensuring better cross-image interaction in semantically related local object regions. Further, with the aid of CSRMs, the developed REP can strengthen the extracted features for those discovered semantically-related local regions in each branch, boosting the model's ability to distinguish subtle feature differences of fine-grained objects. Extensive experiments conducted on five public fine-grained benchmarks demonstrate that HelixFormer can effectively enhance the cross-image object semantic relation matching for recognizing fine-grained objects, achieving much better performance over most state-of-the-art methods under 1-shot and 5-shot scenarios. Our code is available at: https://github.com/JiakangYuan/HelixFormer
Connecting a French Dictionary from the Beginning of the 20th Century to Wikidata
Jun 26, 2022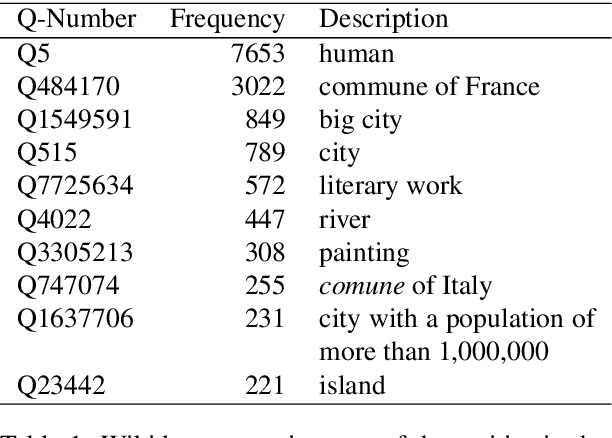
The \textit{Petit Larousse illustr\'e} is a French dictionary first published in 1905. Its division in two main parts on language and on history and geography corresponds to a major milestone in French lexicography as well as a repository of general knowledge from this period. Although the value of many entries from 1905 remains intact, some descriptions now have a dimension that is more historical than contemporary. They are nonetheless significant to analyze and understand cultural representations from this time. A comparison with more recent information or a verification of these entries would require a tedious manual work. In this paper, we describe a new lexical resource, where we connected all the dictionary entries of the history and geography part to current data sources. For this, we linked each of these entries to a wikidata identifier. Using the wikidata links, we can automate more easily the identification, comparison, and verification of historically-situated representations. We give a few examples on how to process wikidata identifiers and we carried out a small analysis of the entities described in the dictionary to outline possible applications. The resource, i.e. the annotation of 20,245 dictionary entries with wikidata links, is available from GitHub url{https://github.com/pnugues/petit_larousse_1905/
Hammer PDF: An Intelligent PDF Reader for Scientific Papers
Apr 06, 2022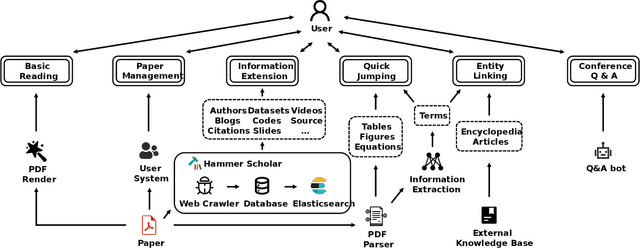
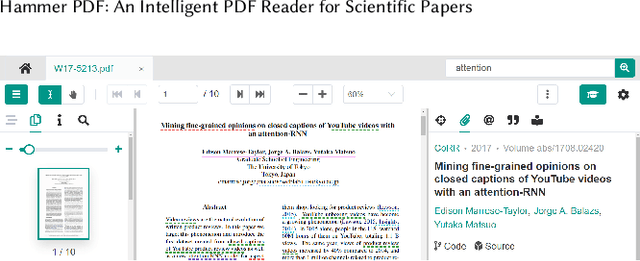


Reading scientific papers has been an essential way for researchers to acquire academic knowledge, and most papers are in PDF format. However, existing PDF Readers only support reading, editing, annotating and other basic functions, and lack of multi-granularity analysis for academic papers. Specifically, taking a paper as a whole, these PDF Readers cannot access extended information of the paper, such as related videos, blogs, codes, etc.; meanwhile, for the content of a paper, these PDF Readers also cannot extract and display academic details of the paper, such as terms, authors, citations, etc. In this paper, we introduce Hammer PDF, a novel intelligent PDF Reader for scientific papers. Beyond basic reading functions, Hammer PDF comes with four innovative features: (1) locate, mark and interact with spans (e.g., terms) obtained by information extraction; (2) citation, reference, code, video, blog, and other extended information are displayed with a paper; (3) built-in Hammer Scholar, an academic search engine that uses academic information collected from major academic databases; (4) built-in Q\&A bot to support asking for interested conference information. Our product helps researchers, especially those who study computer science, to improve the efficiency and experience of reading scientific papers. We release Hammer PDF, available for download at https://pdf.hammerscholar.net/face.
Context-Driven Detection of Invertebrate Species in Deep-Sea Video
Jun 01, 2022

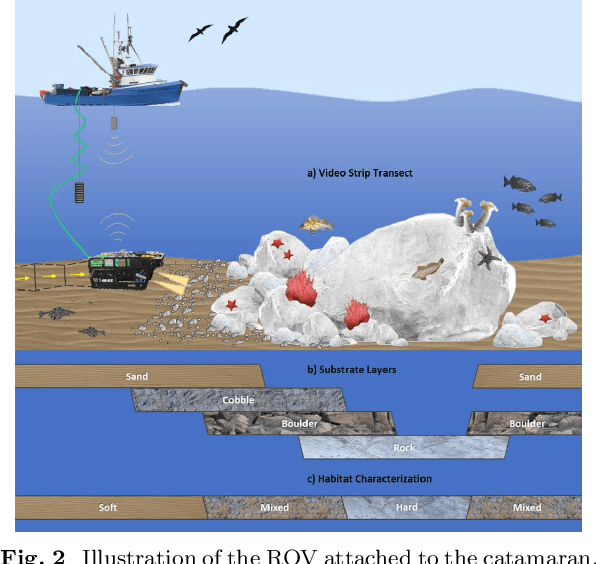
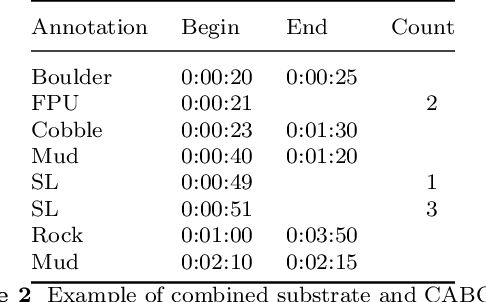
Each year, underwater remotely operated vehicles (ROVs) collect thousands of hours of video of unexplored ocean habitats revealing a plethora of information regarding biodiversity on Earth. However, fully utilizing this information remains a challenge as proper annotations and analysis require trained scientists time, which is both limited and costly. To this end, we present a Dataset for Underwater Substrate and Invertebrate Analysis (DUSIA), a benchmark suite and growing large-scale dataset to train, validate, and test methods for temporally localizing four underwater substrates as well as temporally and spatially localizing 59 underwater invertebrate species. DUSIA currently includes over ten hours of footage across 25 videos captured in 1080p at 30 fps by an ROV following pre planned transects across the ocean floor near the Channel Islands of California. Each video includes annotations indicating the start and end times of substrates across the video in addition to counts of species of interest. Some frames are annotated with precise bounding box locations for invertebrate species of interest, as seen in Figure 1. To our knowledge, DUSIA is the first dataset of its kind for deep sea exploration, with video from a moving camera, that includes substrate annotations and invertebrate species that are present at significant depths where sunlight does not penetrate. Additionally, we present the novel context-driven object detector (CDD) where we use explicit substrate classification to influence an object detection network to simultaneously predict a substrate and species class influenced by that substrate. We also present a method for improving training on partially annotated bounding box frames. Finally, we offer a baseline method for automating the counting of invertebrate species of interest.
FisheyeDistill: Self-Supervised Monocular Depth Estimation with Ordinal Distillation for Fisheye Cameras
May 05, 2022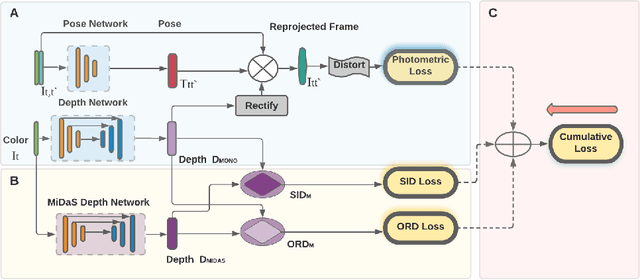



In this paper, we deal with the problem of monocular depth estimation for fisheye cameras in a self-supervised manner. A known issue of self-supervised depth estimation is that it suffers in low-light/over-exposure conditions and in large homogeneous regions. To tackle this issue, we propose a novel ordinal distillation loss that distills the ordinal information from a large teacher model. Such a teacher model, since having been trained on a large amount of diverse data, can capture the depth ordering information well, but lacks in preserving accurate scene geometry. Combined with self-supervised losses, we show that our model can not only generate reasonable depth maps in challenging environments but also better recover the scene geometry. We further leverage the fisheye cameras of an AR-Glasses device to collect an indoor dataset to facilitate evaluation.
Predicting Opinion Dynamics via Sociologically-Informed Neural Networks
Jul 07, 2022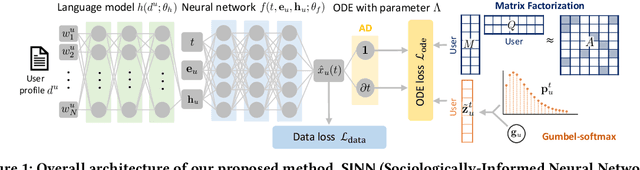

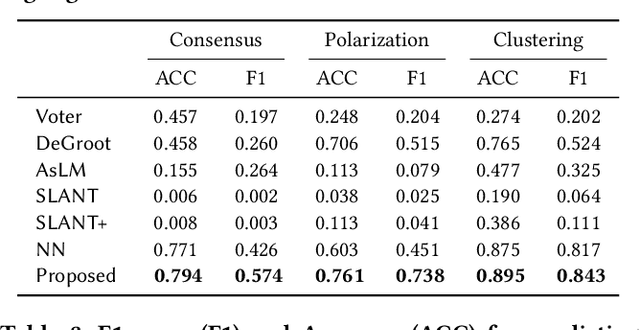
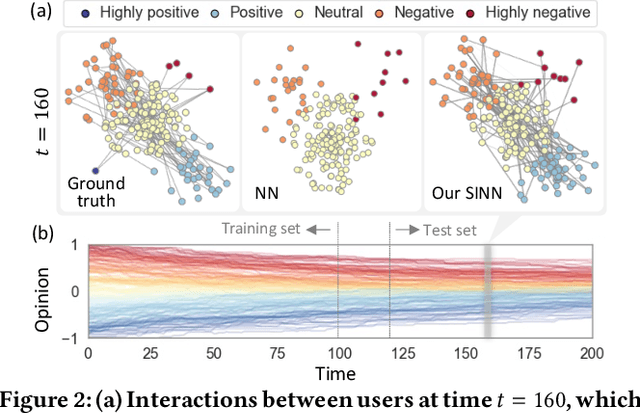
Opinion formation and propagation are crucial phenomena in social networks and have been extensively studied across several disciplines. Traditionally, theoretical models of opinion dynamics have been proposed to describe the interactions between individuals (i.e., social interaction) and their impact on the evolution of collective opinions. Although these models can incorporate sociological and psychological knowledge on the mechanisms of social interaction, they demand extensive calibration with real data to make reliable predictions, requiring much time and effort. Recently, the widespread use of social media platforms provides new paradigms to learn deep learning models from a large volume of social media data. However, these methods ignore any scientific knowledge about the mechanism of social interaction. In this work, we present the first hybrid method called Sociologically-Informed Neural Network (SINN), which integrates theoretical models and social media data by transporting the concepts of physics-informed neural networks (PINNs) from natural science (i.e., physics) into social science (i.e., sociology and social psychology). In particular, we recast theoretical models as ordinary differential equations (ODEs). Then we train a neural network that simultaneously approximates the data and conforms to the ODEs that represent the social scientific knowledge. In addition, we extend PINNs by integrating matrix factorization and a language model to incorporate rich side information (e.g., user profiles) and structural knowledge (e.g., cluster structure of the social interaction network). Moreover, we develop an end-to-end training procedure for SINN, which involves Gumbel-Softmax approximation to include stochastic mechanisms of social interaction. Extensive experiments on real-world and synthetic datasets show SINN outperforms six baseline methods in predicting opinion dynamics.
Can Foundation Models Help Us Achieve Perfect Secrecy?
May 27, 2022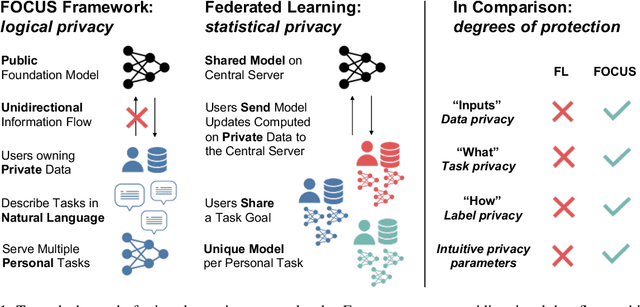
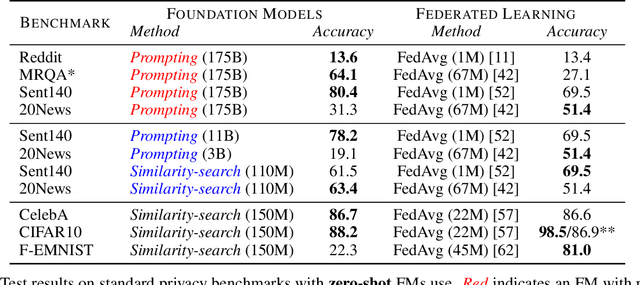
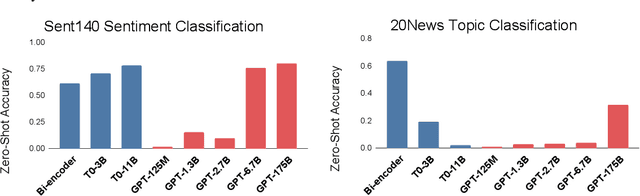

A key promise of machine learning is the ability to assist users with personal tasks. Because the personal context required to make accurate predictions is often sensitive, we require systems that protect privacy. A gold standard privacy-preserving system will satisfy perfect secrecy, meaning that interactions with the system provably reveal no additional private information to adversaries. This guarantee should hold even as we perform multiple personal tasks over the same underlying data. However, privacy and quality appear to be in tension in existing systems for personal tasks. Neural models typically require lots of training to perform well, while individual users typically hold a limited scale of data, so the systems propose to learn from the aggregate data of multiple users. This violates perfect secrecy and instead, in the last few years, academics have defended these solutions using statistical notions of privacy -- i.e., the probability of learning private information about a user should be reasonably low. Given the vulnerabilities of these solutions, we explore whether the strong perfect secrecy guarantee can be achieved using recent zero-to-few sample adaptation techniques enabled by foundation models. In response, we propose FOCUS, a framework for personal tasks. Evaluating on popular privacy benchmarks, we find the approach, satisfying perfect secrecy, competes with strong collaborative learning baselines on 6 of 7 tasks. We empirically analyze the proposal, highlighting the opportunities and limitations across task types, and model inductive biases and sizes.