 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Scalable Multi-Agent Model-Based Reinforcement Learning
May 25, 2022
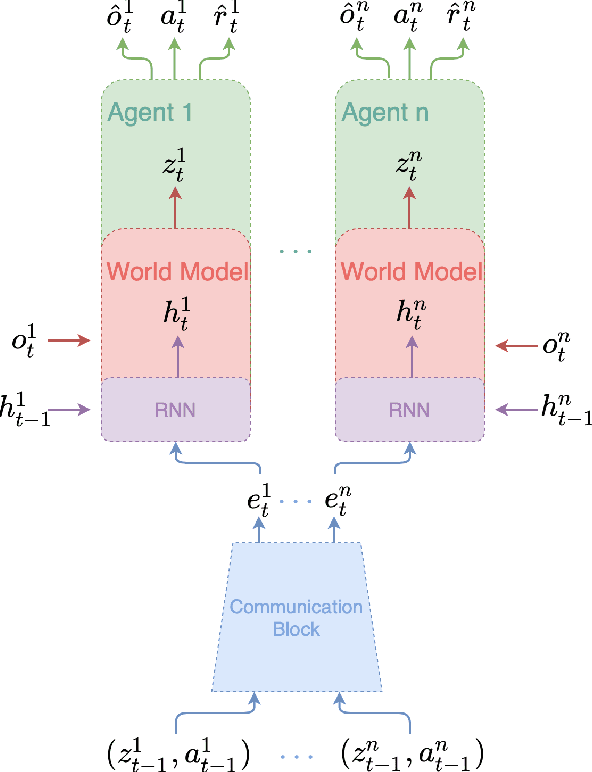
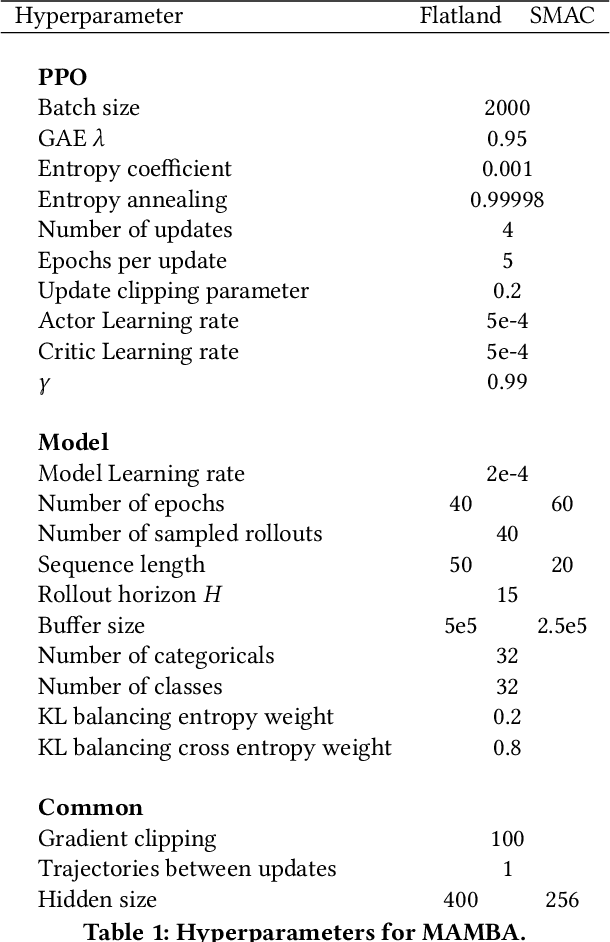
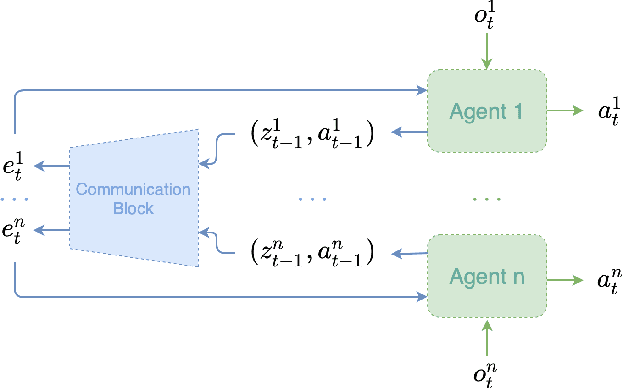
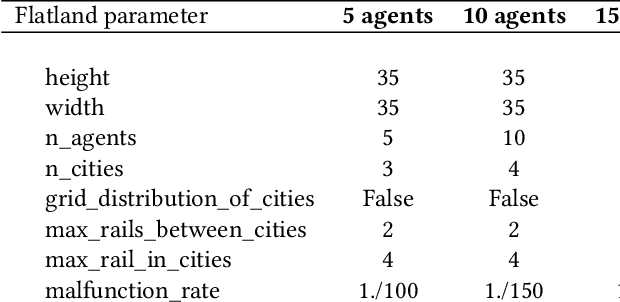
Recent Multi-Agent Reinforcement Learning (MARL) literature has been largely focused on Centralized Training with Decentralized Execution (CTDE) paradigm. CTDE has been a dominant approach for both cooperative and mixed environments due to its capability to efficiently train decentralized policies. While in mixed environments full autonomy of the agents can be a desirable outcome, cooperative environments allow agents to share information to facilitate coordination. Approaches that leverage this technique are usually referred as communication methods, as full autonomy of agents is compromised for better performance. Although communication approaches have shown impressive results, they do not fully leverage this additional information during training phase. In this paper, we propose a new method called MAMBA which utilizes Model-Based Reinforcement Learning (MBRL) to further leverage centralized training in cooperative environments. We argue that communication between agents is enough to sustain a world model for each agent during execution phase while imaginary rollouts can be used for training, removing the necessity to interact with the environment. These properties yield sample efficient algorithm that can scale gracefully with the number of agents. We empirically confirm that MAMBA achieves good performance while reducing the number of interactions with the environment up to an orders of magnitude compared to Model-Free state-of-the-art approaches in challenging domains of SMAC and Flatland.
Meta Optimal Transport
Jun 10, 2022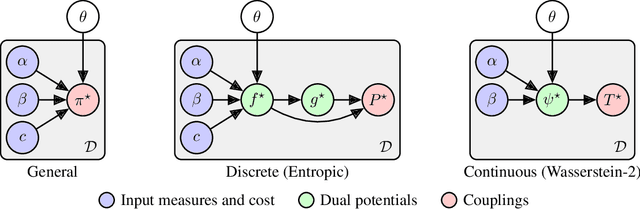


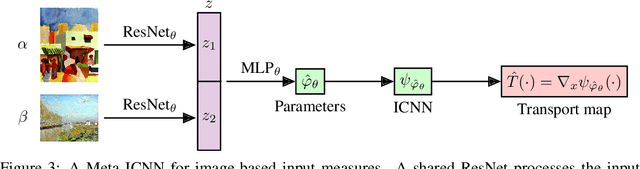
We study the use of amortized optimization to predict optimal transport (OT) maps from the input measures, which we call Meta OT. This helps repeatedly solve similar OT problems between different measures by leveraging the knowledge and information present from past problems to rapidly predict and solve new problems. Otherwise, standard methods ignore the knowledge of the past solutions and suboptimally re-solve each problem from scratch. Meta OT models surpass the standard convergence rates of log-Sinkhorn solvers in the discrete setting and convex potentials in the continuous setting. We improve the computational time of standard OT solvers by multiple orders of magnitude in discrete and continuous transport settings between images, spherical data, and color palettes. Our source code is available at http://github.com/facebookresearch/meta-ot.
Comparative Analysis of Non-Blind Deblurring Methods for Noisy Blurred Images
May 06, 2022

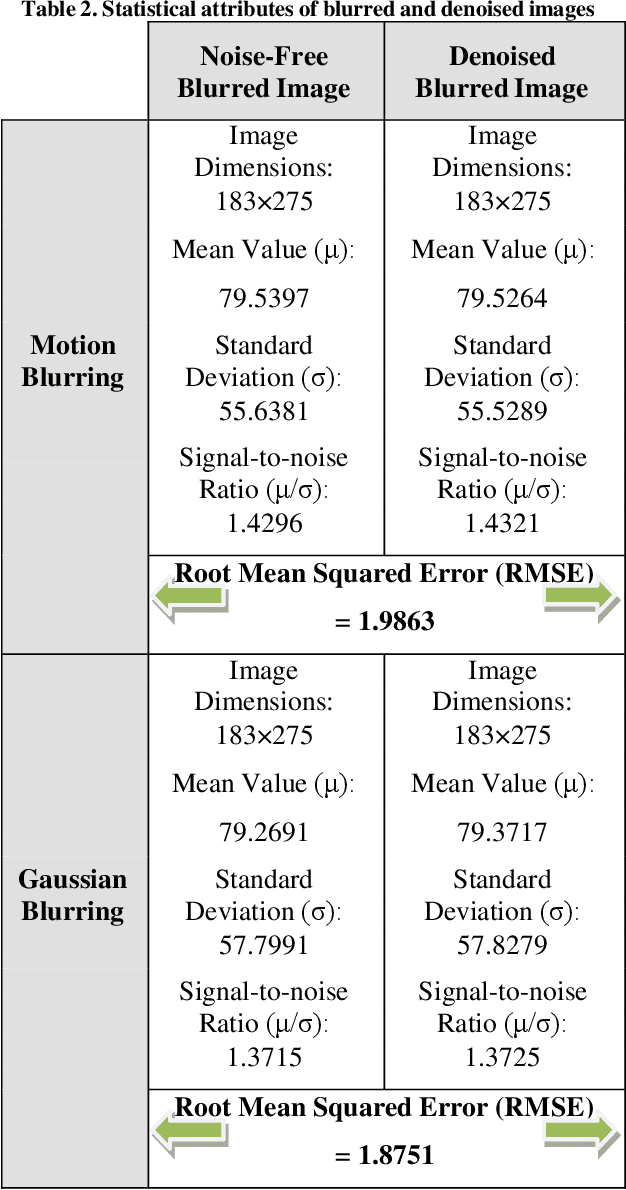
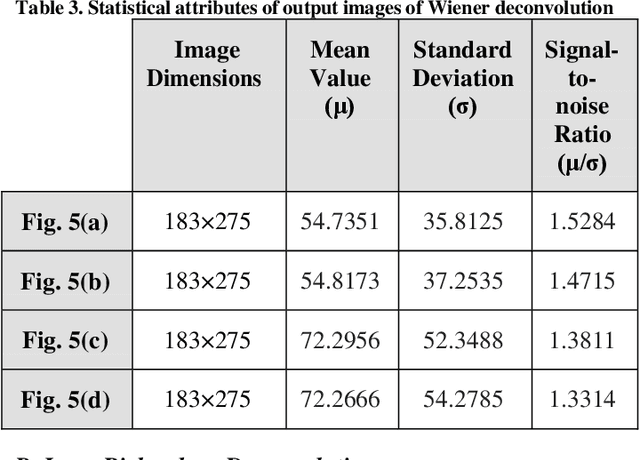
Image blurring refers to the degradation of an image wherein the image's overall sharpness decreases. Image blurring is caused by several factors. Additionally, during the image acquisition process, noise may get added to the image. Such a noisy and blurred image can be represented as the image resulting from the convolution of the original image with the associated point spread function, along with additive noise. However, the blurred image often contains inadequate information to uniquely determine the plausible original image. Based on the availability of blurring information, image deblurring methods can be classified as blind and non-blind. In non-blind image deblurring, some prior information is known regarding the corresponding point spread function and the added noise. The objective of this study is to determine the effectiveness of non-blind image deblurring methods with respect to the identification and elimination of noise present in blurred images. In this study, three non-blind image deblurring methods, namely Wiener deconvolution, Lucy-Richardson deconvolution, and regularized deconvolution were comparatively analyzed for noisy images featuring salt-and-pepper noise. Two types of blurring effects were simulated, namely motion blurring and Gaussian blurring. The said three non-blind deblurring methods were applied under two scenarios: direct deblurring of noisy blurred images and deblurring of images after denoising through the application of the adaptive median filter. The obtained results were then compared for each scenario to determine the best approach for deblurring noisy images.
Variational Autoencoder Assisted Neural Network Likelihood RSRP Prediction Model
Jun 27, 2022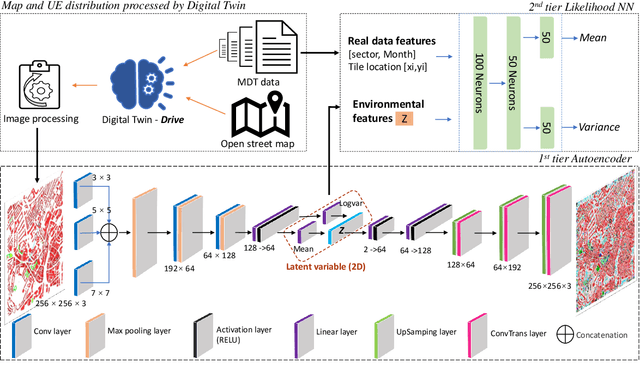
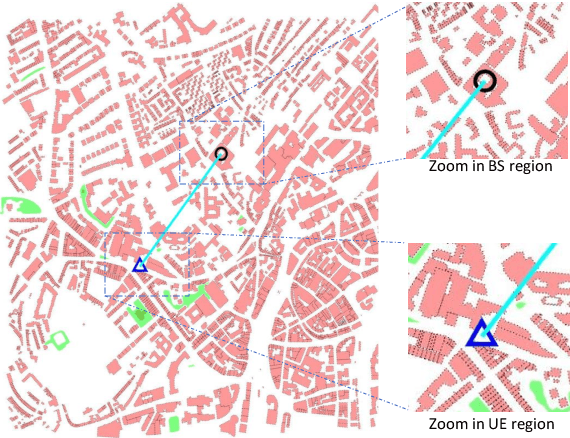
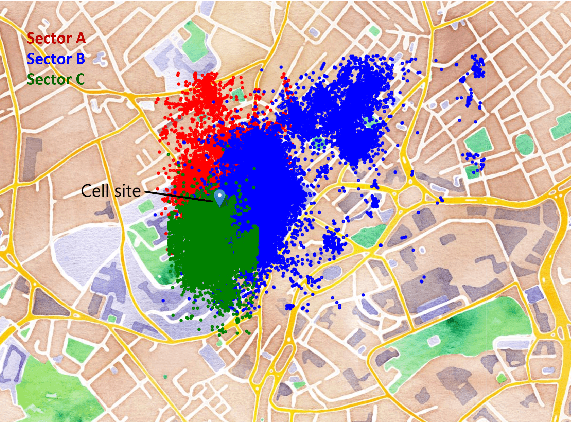
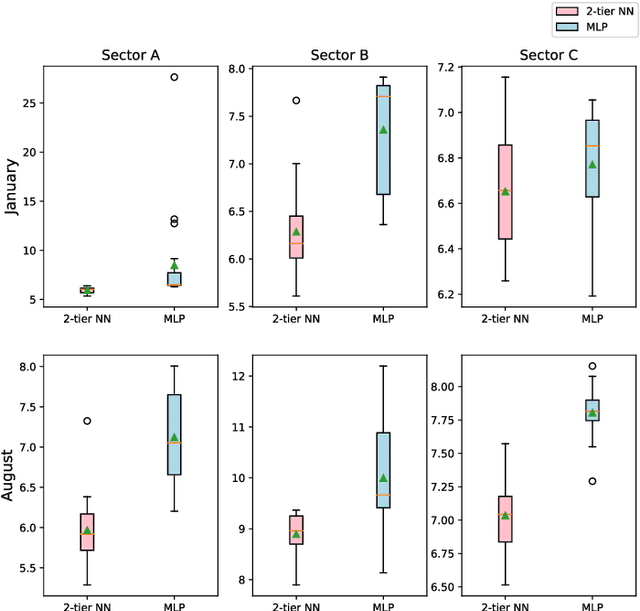
Measuring customer experience on mobile data is of utmost importance for global mobile operators. The reference signal received power (RSRP) is one of the important indicators for current mobile network management, evaluation and monitoring. Radio data gathered through the minimization of drive test (MDT), a 3GPP standard technique, is commonly used for radio network analysis. Collecting MDT data in different geographical areas is inefficient and constrained by the terrain conditions and user presence, hence is not an adequate technique for dynamic radio environments. In this paper, we study a generative model for RSRP prediction, exploiting MDT data and a digital twin (DT), and propose a data-driven, two-tier neural network (NN) model. In the first tier, environmental information related to user equipment (UE), base stations (BS) and network key performance indicators (KPI) are extracted through a variational autoencoder (VAE). The second tier is designed as a likelihood model. Here, the environmental features and real MDT data features are adopted, formulating an integrated training process. On validation, our proposed model that uses real-world data demonstrates an accuracy improvement of about 20% or more compared with the empirical model and about 10% when compared with a fully connected prediction network.
Integrated Sensing and Communication with Reconfigurable Intelligent Surfaces: Opportunities, Applications, and Future Directions
Jun 17, 2022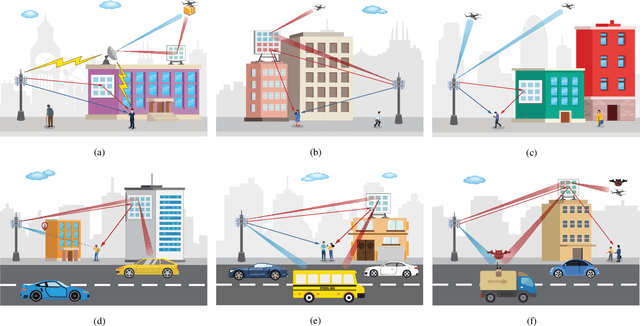
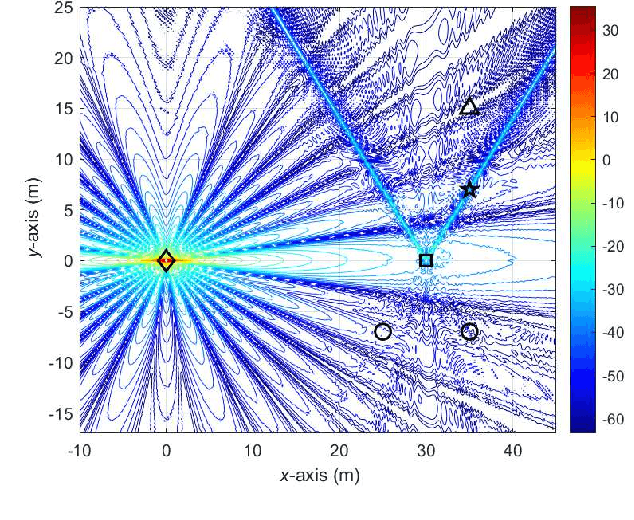
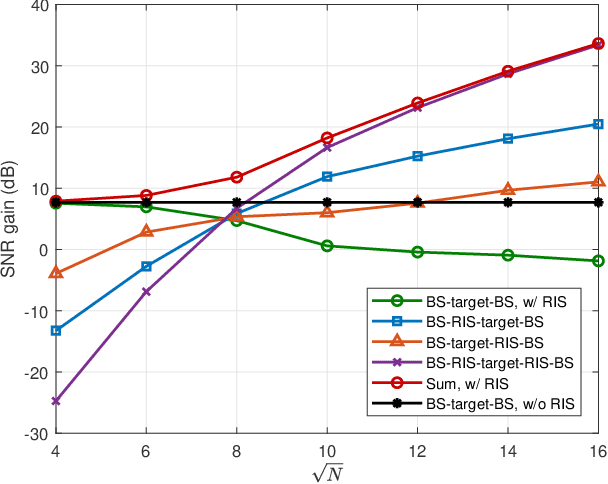
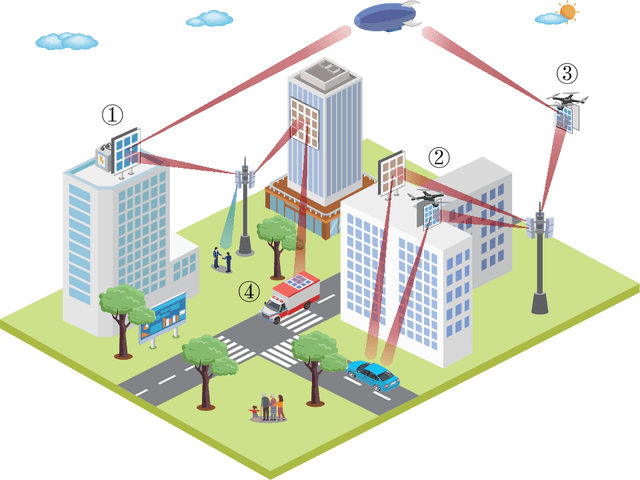
Integrated sensing and communication (ISAC) is emerging as a key enabler to address the growing spectrum congestion problem and satisfy increasing demands for ubiquitous sensing and communication. By sharing various resources and information, ISAC achieves much higher spectral, energy, hardware, and economic efficiencies. Concurrently, reconfigurable intelligent surface (RIS) technology has been deemed as a promising approach due to its capability of intelligently manipulating the wireless propagation environment in an energy and hardware efficient manner. In this article, we analyze the potential of deploying RIS to improve communication and sensing performance in ISAC systems. We first describe the fundamentals of RIS and its applications in traditional communication and sensing systems, then introduce the principles of ISAC and overview existing explorations on RIS-assisted ISAC, followed by one case study to verify the advantages of deploying RIS in ISAC systems. Finally, open challenges and research directions are discussed to stimulate this line of research and pave the way for practical applications.
Zeroth-Order Topological Insights into Iterative Magnitude Pruning
Jun 17, 2022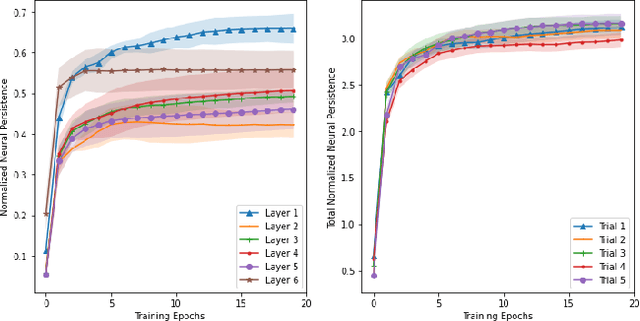
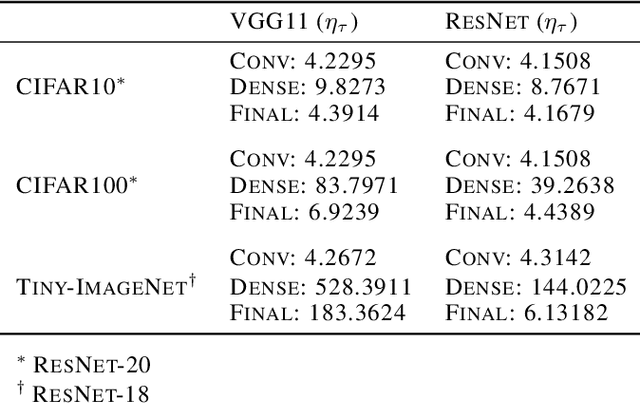
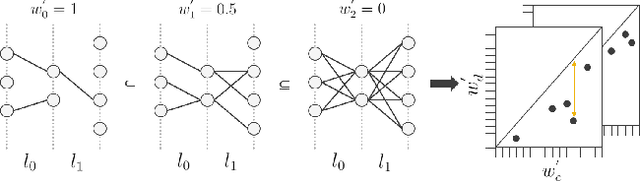
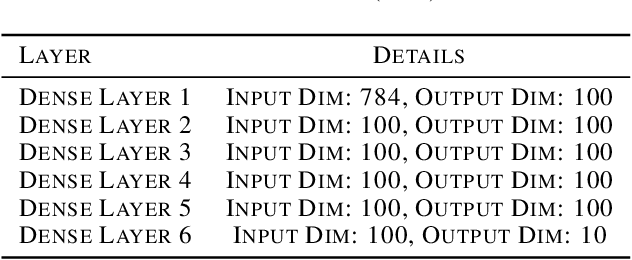
Modern-day neural networks are famously large, yet also highly redundant and compressible; there exist numerous pruning strategies in the deep learning literature that yield over 90% sparser sub-networks of fully-trained, dense architectures while still maintaining their original accuracies. Amongst these many methods though -- thanks to its conceptual simplicity, ease of implementation, and efficacy -- Iterative Magnitude Pruning (IMP) dominates in practice and is the de facto baseline to beat in the pruning community. However, theoretical explanations as to why a simplistic method such as IMP works at all are few and limited. In this work, we leverage the notion of persistent homology to gain insights into the workings of IMP and show that it inherently encourages retention of those weights which preserve topological information in a trained network. Subsequently, we also provide bounds on how much different networks can be pruned while perfectly preserving their zeroth order topological features, and present a modified version of IMP to do the same.
SynWMD: Syntax-aware Word Mover's Distance for Sentence Similarity Evaluation
Jun 20, 2022
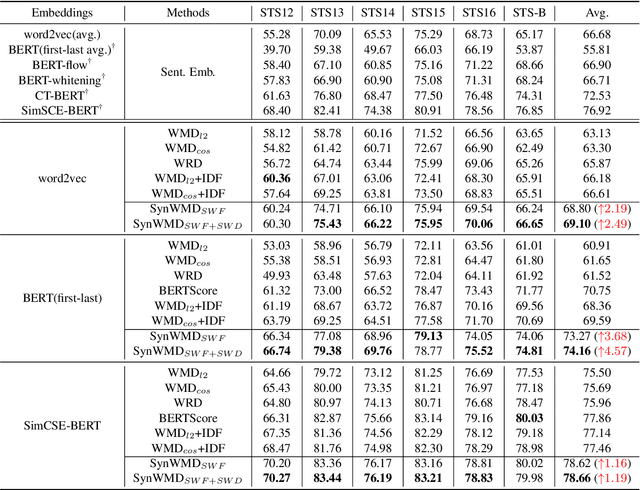
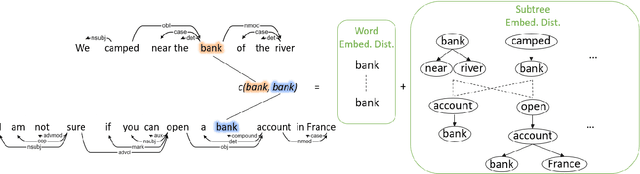
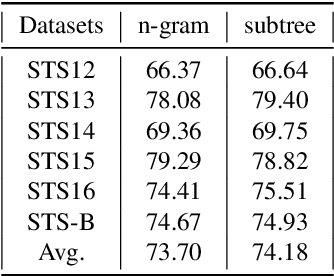
Word Mover's Distance (WMD) computes the distance between words and models text similarity with the moving cost between words in two text sequences. Yet, it does not offer good performance in sentence similarity evaluation since it does not incorporate word importance and fails to take inherent contextual and structural information in a sentence into account. An improved WMD method using the syntactic parse tree, called Syntax-aware Word Mover's Distance (SynWMD), is proposed to address these two shortcomings in this work. First, a weighted graph is built upon the word co-occurrence statistics extracted from the syntactic parse trees of sentences. The importance of each word is inferred from graph connectivities. Second, the local syntactic parsing structure of words is considered in computing the distance between words. To demonstrate the effectiveness of the proposed SynWMD, we conduct experiments on 6 textual semantic similarity (STS) datasets and 4 sentence classification datasets. Experimental results show that SynWMD achieves state-of-the-art performance on STS tasks. It also outperforms other WMD-based methods on sentence classification tasks.
A Numerical Reasoning Question Answering System with Fine-grained Retriever and the Ensemble of Multiple Generators for FinQA
Jun 17, 2022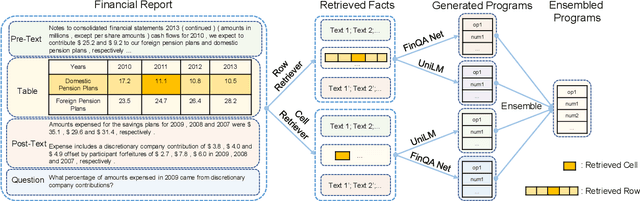
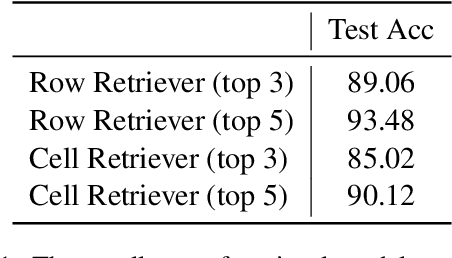
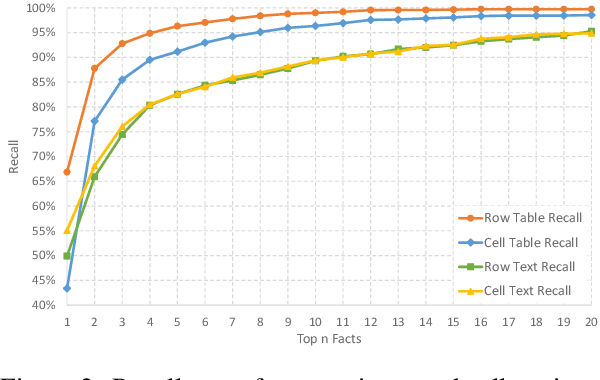
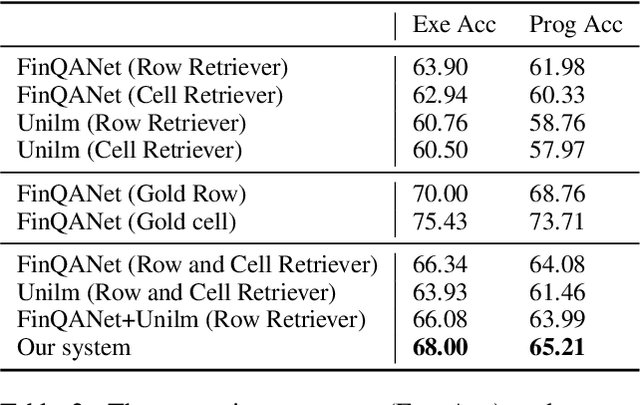
The numerical reasoning in the financial domain -- performing quantitative analysis and summarizing the information from financial reports -- can greatly increase business efficiency and reduce costs of billions of dollars. Here, we propose a numerical reasoning question answering system to answer numerical reasoning questions among financial text and table data sources, consisting of a retriever module, a generator module, and an ensemble module. Specifically, in the retriever module, in addition to retrieving the whole row data, we innovatively design a cell retriever that retrieves the gold cells to avoid bringing unrelated and similar cells in the same row to the inputs of the generator module. In the generator module, we utilize multiple generators to produce programs, which are operation steps to answer the question. Finally, in the ensemble module, we integrate multiple programs to choose the best program as the output of our system. In the final private test set in FinQA Competition, our system obtains 69.79 execution accuracy.
Information Extraction From Co-Occurring Similar Entities
Feb 11, 2021
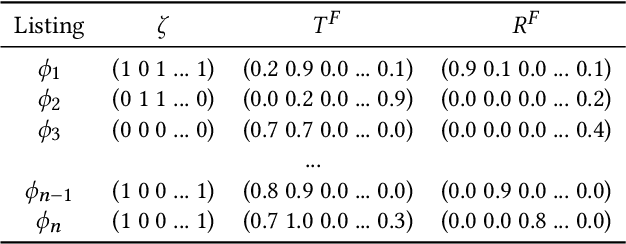
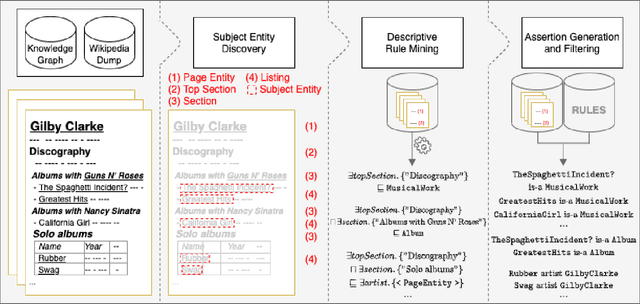
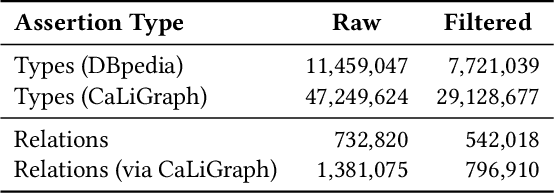
Knowledge about entities and their interrelations is a crucial factor of success for tasks like question answering or text summarization. Publicly available knowledge graphs like Wikidata or DBpedia are, however, far from being complete. In this paper, we explore how information extracted from similar entities that co-occur in structures like tables or lists can help to increase the coverage of such knowledge graphs. In contrast to existing approaches, we do not focus on relationships within a listing (e.g., between two entities in a table row) but on the relationship between a listing's subject entities and the context of the listing. To that end, we propose a descriptive rule mining approach that uses distant supervision to derive rules for these relationships based on a listing's context. Extracted from a suitable data corpus, the rules can be used to extend a knowledge graph with novel entities and assertions. In our experiments we demonstrate that the approach is able to extract up to 3M novel entities and 30M additional assertions from listings in Wikipedia. We find that the extracted information is of high quality and thus suitable to extend Wikipedia-based knowledge graphs like DBpedia, YAGO, and CaLiGraph. For the case of DBpedia, this would result in an increase of covered entities by roughly 50%.
Image Compression and Actionable Intelligence With Deep Neural Networks
Mar 30, 2022
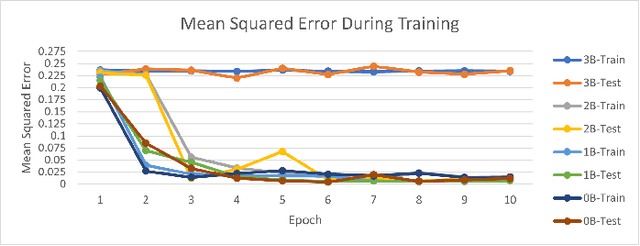

If a unit cannot receive intelligence from a source due to external factors, we consider them disadvantaged users. We categorize this as a preoccupied unit working on a low connectivity device on the edge. This case requires that we use a different approach to deliver intelligence, particularly satellite imagery information, than normally employed. To address this, we propose a survey of information reduction techniques to deliver the information from a satellite image in a smaller package. We investigate four techniques to aid in the reduction of delivered information: traditional image compression, neural network image compression, object detection image cutout, and image to caption. Each of these mechanisms have their benefits and tradeoffs when considered for a disadvantaged user.