 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EigenNoise: A Contrastive Prior to Warm-Start Representations
May 09, 2022
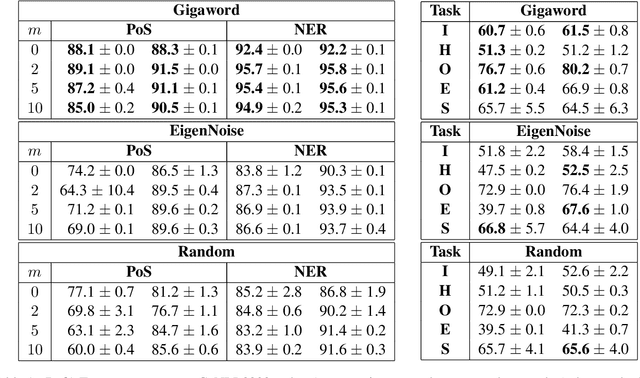
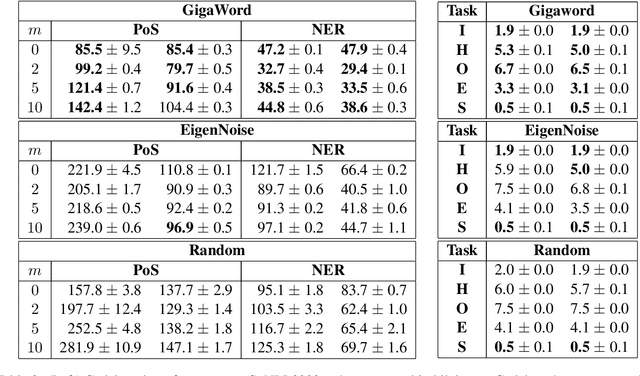
In this work, we present a naive initialization scheme for word vectors based on a dense, independent co-occurrence model and provide preliminary results that suggest it is competitive and warrants further investigation. Specifically, we demonstrate through information-theoretic minimum description length (MDL) probing that our model, EigenNoise, can approach the performance of empirically trained GloVe despite the lack of any pre-training data (in the case of EigenNoise). We present these preliminary results with interest to set the stage for further investigations into how this competitive initialization works without pre-training data, as well as to invite the exploration of more intelligent initialization schemes informed by the theory of harmonic linguistic structure. Our application of this theory likewise contributes a novel (and effective) interpretation of recent discoveries which have elucidated the underlying distributional information that linguistic representations capture from data and contrast distributions.
Precise Affordance Annotation for Egocentric Action Video Datasets
Jun 11, 2022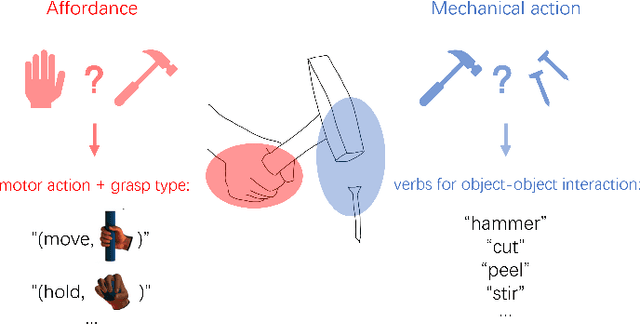


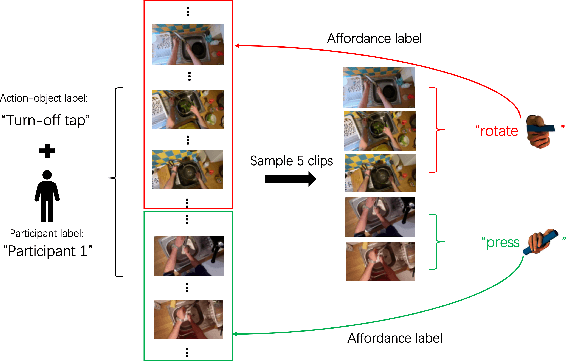
Object affordance is an important concept in human-object interaction, providing information on action possibilities based on human motor capacity and objects' physical property thus benefiting tasks such as action anticipation and robot imitation learning. However, existing datasets often: 1) mix up affordance with object functionality; 2) confuse affordance with goal-related action; and 3) ignore human motor capacity. This paper proposes an efficient annotation scheme to address these issues by combining goal-irrelevant motor actions and grasp types as affordance labels and introducing the concept of mechanical action to represent the action possibilities between two objects. We provide new annotations by applying this scheme to the EPIC-KITCHENS dataset and test our annotation with tasks such as affordance recognition. We qualitatively verify that models trained with our annotation can distinguish affordance and mechanical actions.
QGNN: Value Function Factorisation with Graph Neural Networks
May 25, 2022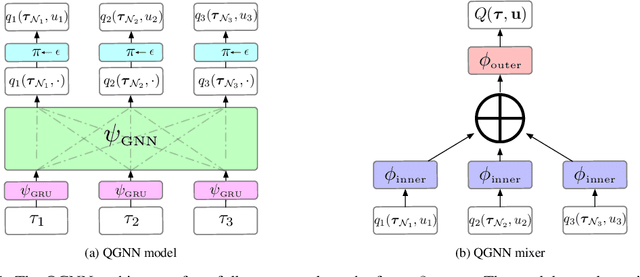
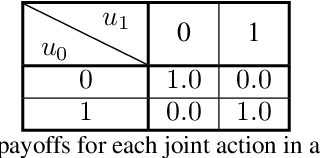
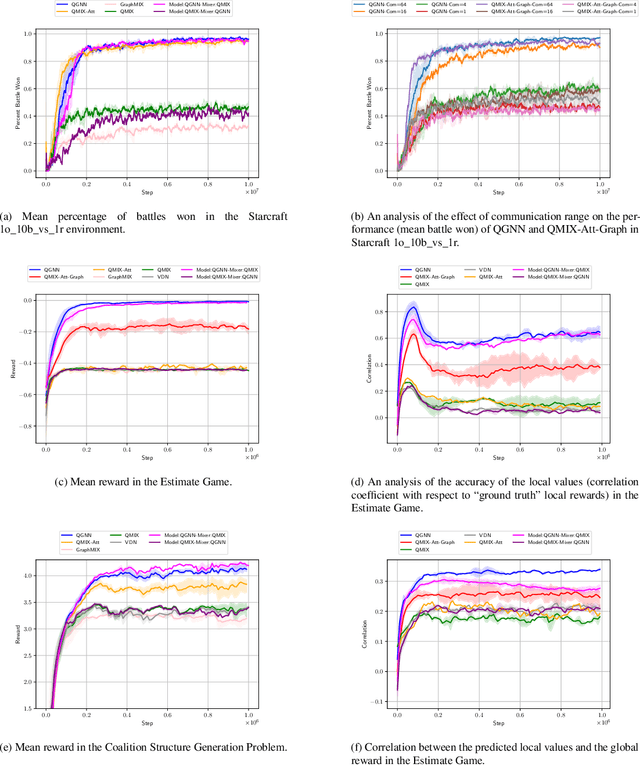
In multi-agent reinforcement learning, the use of a global objective is a powerful tool for incentivising cooperation. Unfortunately, it is not sample-efficient to train individual agents with a global reward, because it does not necessarily correlate with an agent's individual actions. This problem can be solved by factorising the global value function into local value functions. Early work in this domain performed factorisation by conditioning local value functions purely on local information. Recently, it has been shown that providing both local information and an encoding of the global state can promote cooperative behaviour. In this paper we propose QGNN, the first value factorisation method to use a graph neural network (GNN) based model. The multi-layer message passing architecture of QGNN provides more representational complexity than models in prior work, allowing it to produce a more effective factorisation. QGNN also introduces a permutation invariant mixer which is able to match the performance of other methods, even with significantly fewer parameters. We evaluate our method against several baselines, including QMIX-Att, GraphMIX, QMIX, VDN, and hybrid architectures. Our experiments include Starcraft, the standard benchmark for credit assignment; Estimate Game, a custom environment that explicitly models inter-agent dependencies; and Coalition Structure Generation, a foundational problem with real-world applications. The results show that QGNN outperforms state-of-the-art value factorisation baselines consistently.
Black Box Optimization Using QUBO and the Cross Entropy Method
Jun 24, 2022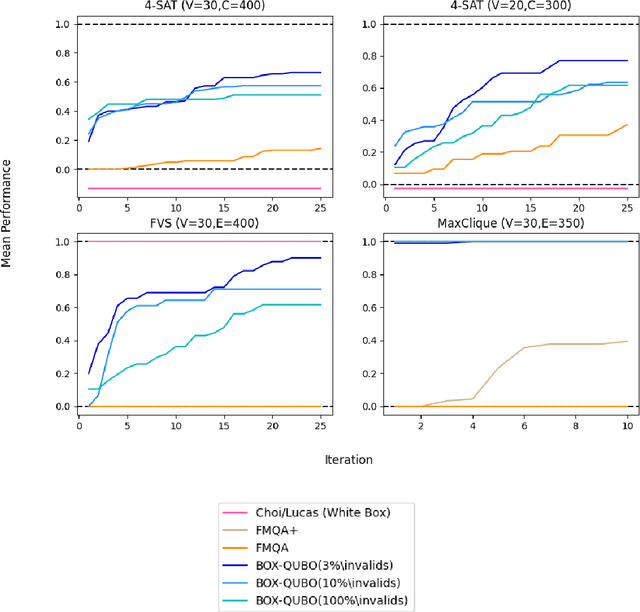
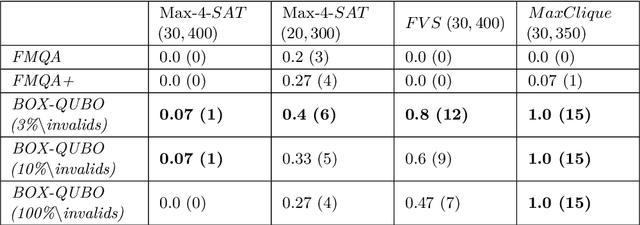
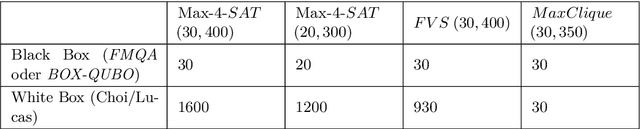
Black box optimization (BBO) can be used to optimize functions whose analytic form is unknown. A common approach to realize BBO is to learn a surrogate model which approximates the target black box function which can then be solved via white box optimization methods. In this paper we present our approach BOX-QUBO, where the surrogate model is a QUBO matrix. However, unlike in previous state-of-the-art approaches, this matrix is not trained entirely by regression, but mostly by classification between 'good' and 'bad' solutions. This better accounts for the low capacity of the QUBO matrix, resulting in significantly better solutions overall. We tested our approach against the state-of-the-art on four domains and in all of them BOX-QUBO showed significantly better results. A second contribution of this paper is the idea to also solve white box problems, i.e. problems which could be directly formulated as QUBO, by means of black box optimization in order to reduce the size of the QUBOs to their information-theoretic minimum. The experiments show that this significantly improves the results for MAX-$k$-SAT.
Representing `how you say' with `what you say': English corpus of focused speech and text reflecting corresponding implications
Mar 29, 2022
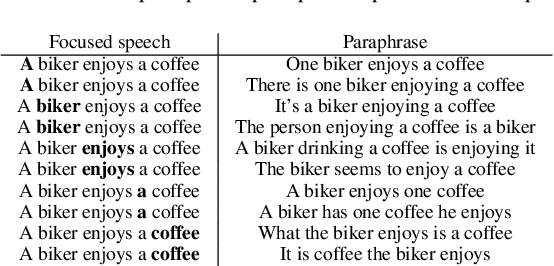
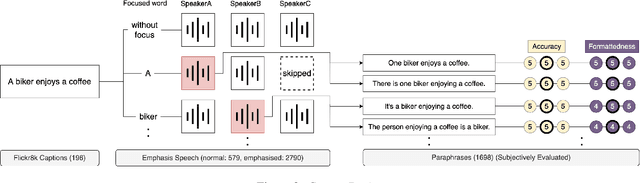
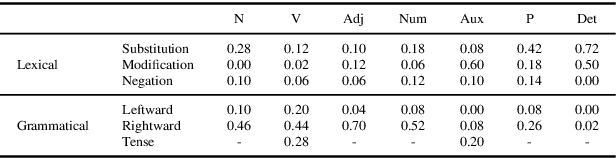
In speech communication, how something is said (paralinguistic information) is as crucial as what is said (linguistic information). As a type of paralinguistic information, English speech uses sentence stress, the heaviest prominence within a sentence, to convey emphasis. While different placements of sentence stress communicate different emphatic implications, current speech translation systems return the same translations if the utterances are linguistically identical, losing paralinguistic information. Concentrating on focus, a type of emphasis, we propose mapping paralinguistic information into the linguistic domain within the source language using lexical and grammatical devices. This method enables us to translate the paraphrased text representations instead of the transcription of the original speech and obtain translations that preserve paralinguistic information. As a first step, we present the collection of an English corpus containing speech that differed in the placement of focus along with the corresponding text, which was designed to reflect the implied meaning of the speech. Also, analyses of our corpus demonstrated that mapping of focus from the paralinguistic domain into the linguistic domain involved various lexical and grammatical methods. The data and insights from our analysis will further advance research into paralinguistic translation. The corpus will be published via LDC.
Secure Forward Aggregation for Vertical Federated Neural Networks
Jun 28, 2022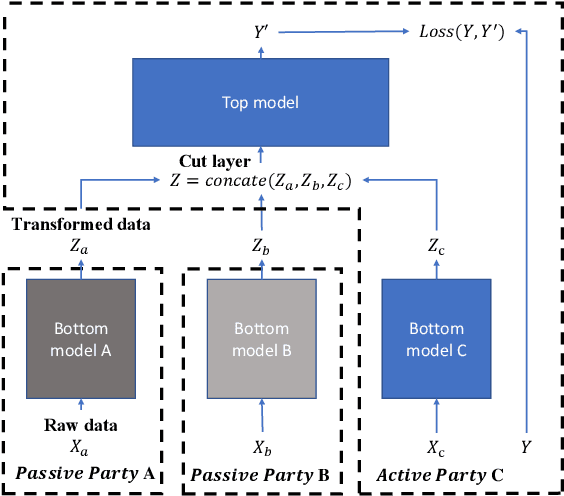


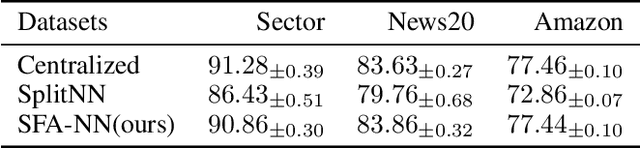
Vertical federated learning (VFL) is attracting much attention because it enables cross-silo data cooperation in a privacy-preserving manner. While most research works in VFL focus on linear and tree models, deep models (e.g., neural networks) are not well studied in VFL. In this paper, we focus on SplitNN, a well-known neural network framework in VFL, and identify a trade-off between data security and model performance in SplitNN. Briefly, SplitNN trains the model by exchanging gradients and transformed data. On the one hand, SplitNN suffers from the loss of model performance since multiply parties jointly train the model using transformed data instead of raw data, and a large amount of low-level feature information is discarded. On the other hand, a naive solution of increasing the model performance through aggregating at lower layers in SplitNN (i.e., the data is less transformed and more low-level feature is preserved) makes raw data vulnerable to inference attacks. To mitigate the above trade-off, we propose a new neural network protocol in VFL called Security Forward Aggregation (SFA). It changes the way of aggregating the transformed data and adopts removable masks to protect the raw data. Experiment results show that networks with SFA achieve both data security and high model performance.
MIMO Symbiotic Radio with Massive Passive Devices: Asymptotic Analysis and Precoding Optimization
Jun 28, 2022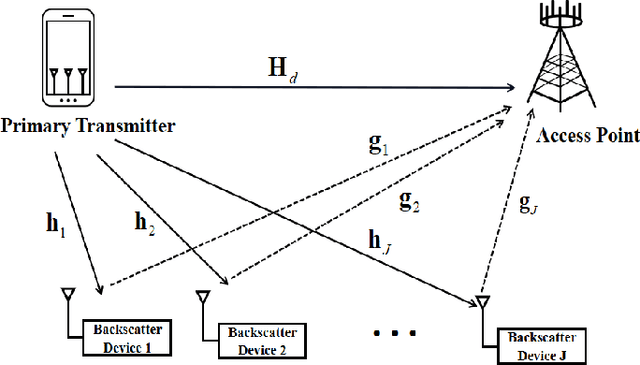
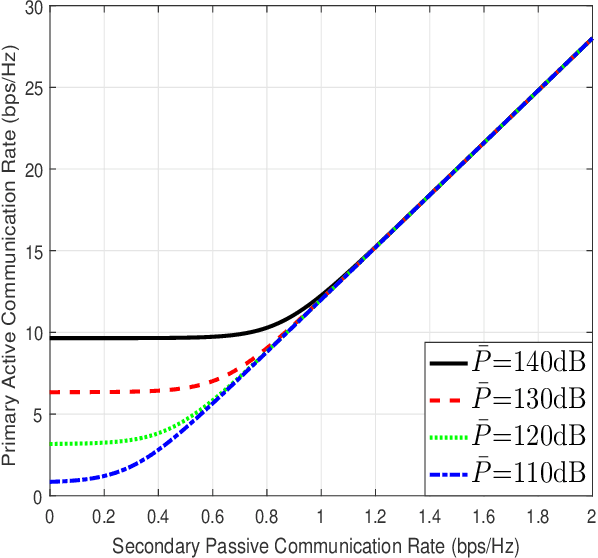
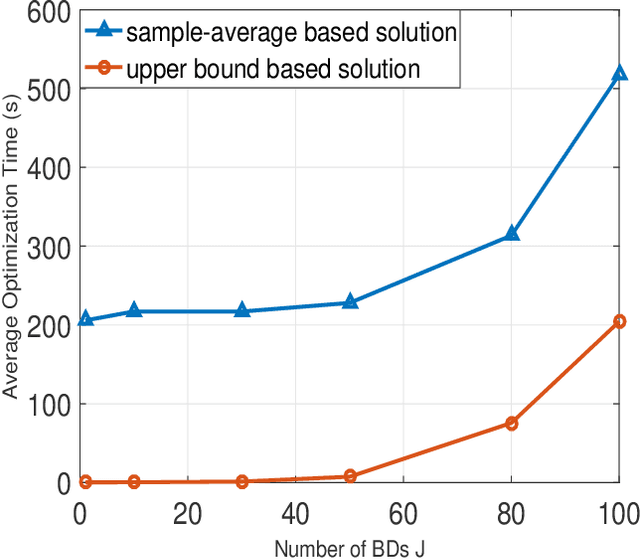
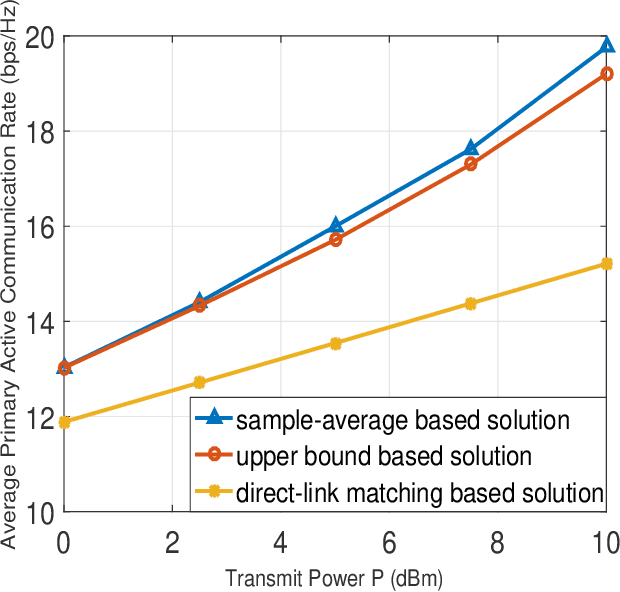
Symbiotic radio has emerged as a promising technology for spectrum- and energy-efficient wireless communications, where the passive secondary backscatter devices (BDs) reuse not only the spectrum but also the power of the active primary users to transmit their own information. In return, the primary communication links can be enhanced by the additional multipaths created by the BDs. This is known as the mutualism relationship of symbiotic radio. However, due to the severe double-fading attenuation of the passive backscattering links, the enhancement of the primary link provided by one single BD is extremely limited. To address this issue and enable full mutualism of symbiotic radio, in this paper, we study multiple-input multiple output (MIMO) symbiotic radio communication systems with massive BDs. We first derive the achievable rates of the primary active communication and secondary passive communication, and then consider the asymptotic regime as the number of BDs goes large, for which closed-form expressions are derived to reveal the relationship between the primary and secondary communication rates. Furthermore, the precoding optimization problem is studied to maximize the primary communication rate while guaranteeing that the secondary communication rate is no smaller than a certain threshold. Simulation results are provided to validate our theoretical studies.
TCJA-SNN: Temporal-Channel Joint Attention for Spiking Neural Networks
Jun 21, 2022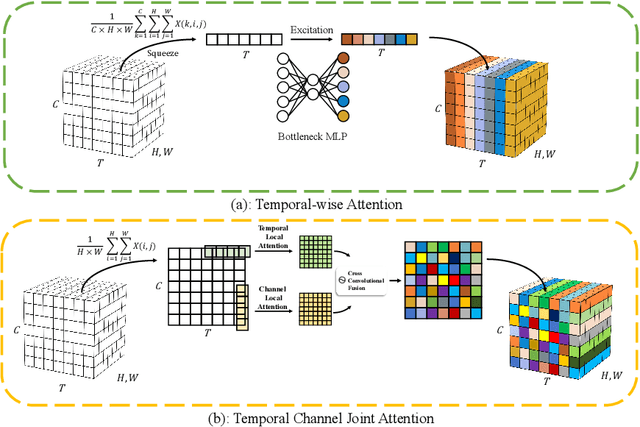
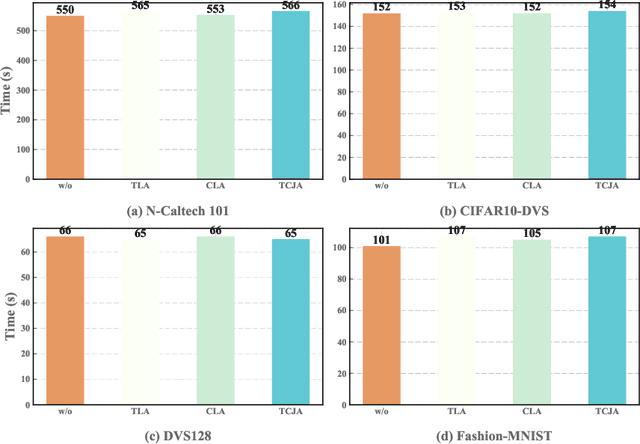
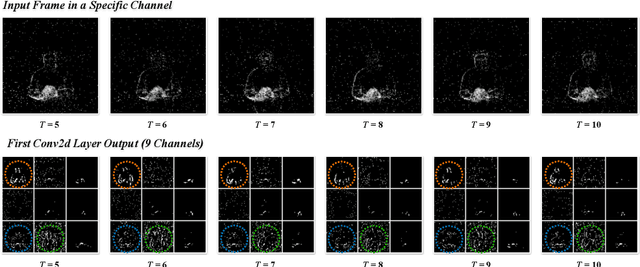

Spiking Neural Networks (SNNs) is a practical approach toward more data-efficient deep learning by simulating neurons leverage on temporal information. In this paper, we propose the Temporal-Channel Joint Attention (TCJA) architectural unit, an efficient SNN technique that depends on attention mechanisms, by effectively enforcing the relevance of spike sequence along both spatial and temporal dimensions. Our essential technical contribution lies on: 1) compressing the spike stream into an average matrix by employing the squeeze operation, then using two local attention mechanisms with an efficient 1-D convolution to establish temporal-wise and channel-wise relations for feature extraction in a flexible fashion. 2) utilizing the Cross Convolutional Fusion (CCF) layer for modeling inter-dependencies between temporal and channel scope, which breaks the independence of the two dimensions and realizes the interaction between features. By virtue of jointly exploring and recalibrating data stream, our method outperforms the state-of-the-art (SOTA) by up to 15.7% in terms of top-1 classification accuracy on all tested mainstream static and neuromorphic datasets, including Fashion-MNIST, CIFAR10-DVS, N-Caltech 101, and DVS128 Gesture.
Nested Named Entity Recognition as Holistic Structure Parsing
Apr 17, 2022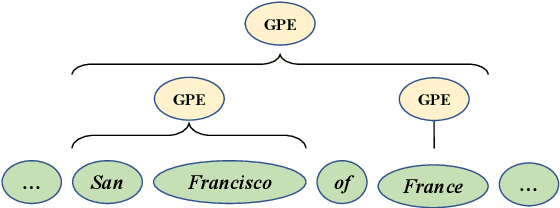
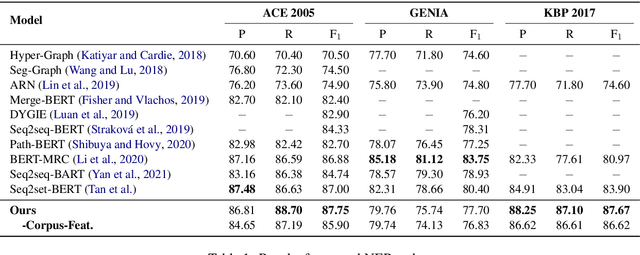
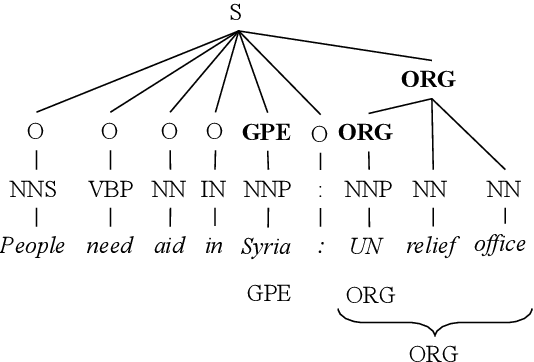
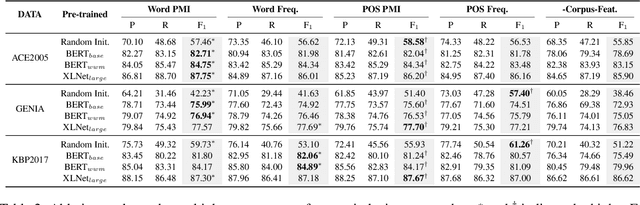
As a fundamental natural language processing task and one of core knowledge extraction techniques, named entity recognition (NER) is widely used to extract information from texts for downstream tasks. Nested NER is a branch of NER in which the named entities (NEs) are nested with each other. However, most of the previous studies on nested NER usually apply linear structure to model the nested NEs which are actually accommodated in a hierarchical structure. Thus in order to address this mismatch, this work models the full nested NEs in a sentence as a holistic structure, then we propose a holistic structure parsing algorithm to disclose the entire NEs once for all. Besides, there is no research on applying corpus-level information to NER currently. To make up for the loss of this information, we introduce Point-wise Mutual Information (PMI) and other frequency features from corpus-aware statistics for even better performance by holistic modeling from sentence-level to corpus-level. Experiments show that our model yields promising results on widely-used benchmarks which approach or even achieve state-of-the-art. Further empirical studies show that our proposed corpus-aware features can substantially improve NER domain adaptation, which demonstrates the surprising advantage of our proposed corpus-level holistic structure modeling.
Attention-based conditioning methods using variable frame rate for style-robust speaker verification
Jun 28, 2022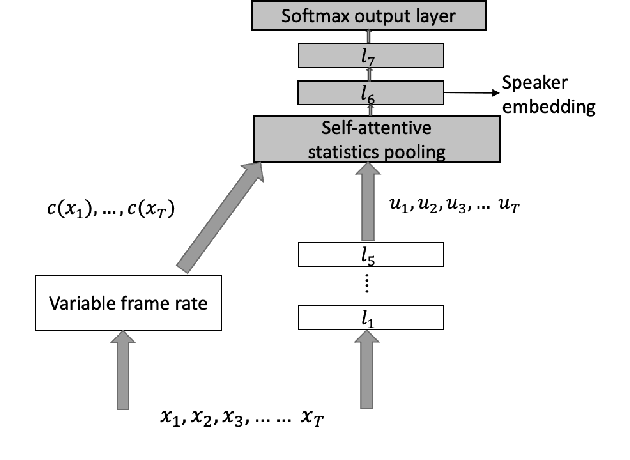
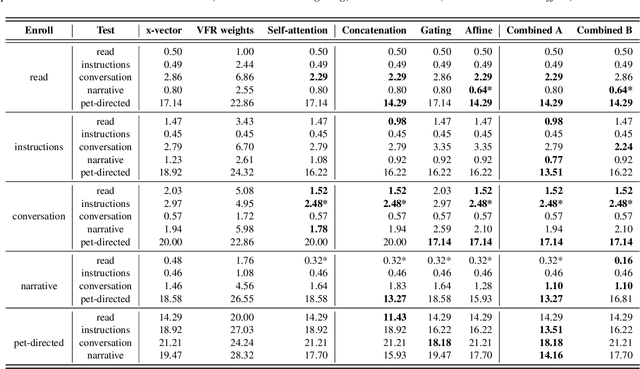
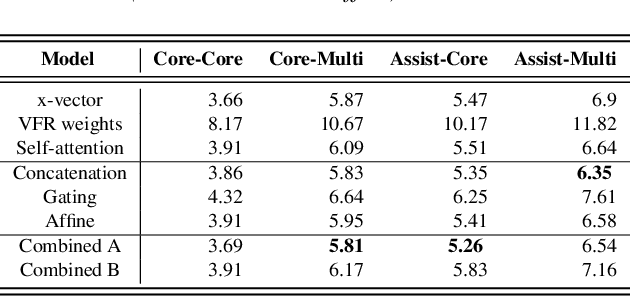
We propose an approach to extract speaker embeddings that are robust to speaking style variations in text-independent speaker verification. Typically, speaker embedding extraction includes training a DNN for speaker classification and using the bottleneck features as speaker representations. Such a network has a pooling layer to transform frame-level to utterance-level features by calculating statistics over all utterance frames, with equal weighting. However, self-attentive embeddings perform weighted pooling such that the weights correspond to the importance of the frames in a speaker classification task. Entropy can capture acoustic variability due to speaking style variations. Hence, an entropy-based variable frame rate vector is proposed as an external conditioning vector for the self-attention layer to provide the network with information that can address style effects. This work explores five different approaches to conditioning. The best conditioning approach, concatenation with gating, provided statistically significant improvements over the x-vector baseline in 12/23 tasks and was the same as the baseline in 11/23 tasks when using the UCLA speaker variability database. It also significantly outperformed self-attention without conditioning in 9/23 tasks and was worse in 1/23. The method also showed significant improvements in multi-speaker scenarios of SITW.