 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Modelling and Mining of Patient Pathways: A Scoping Review
Jun 04, 2022
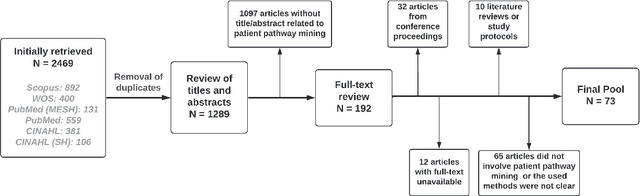

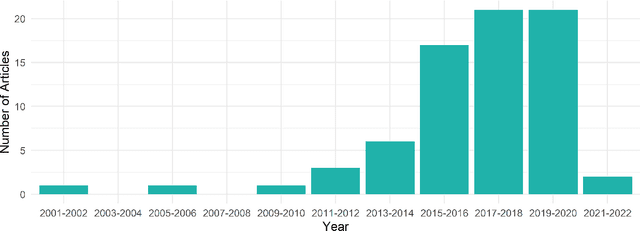
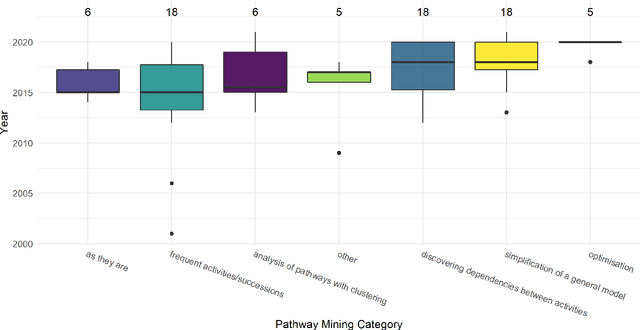
The sequence of visits and procedures performed by the patient in the health system, also known as the patient's pathway or trajectory, can reveal important information about the clinical treatment adopted and the health service provided. The rise of electronic health data availability made it possible to assess the pathways of a large number of patients. Nevertheless, some challenges also arose concerning how to synthesize these pathways and how to mine them from the data, fostering a new field of research. The objective of this review is to survey this new field of research, highlighting representation models, mining techniques, methods of analysis, and examples of case studies.
A Pre-Computing Solution for Online Advertising Serving
Jul 04, 2022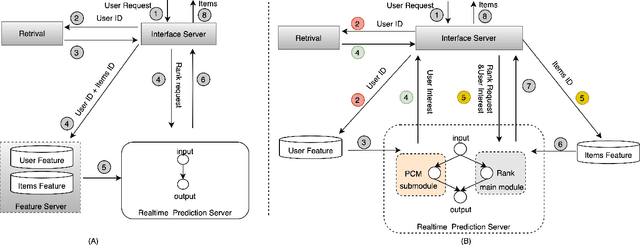

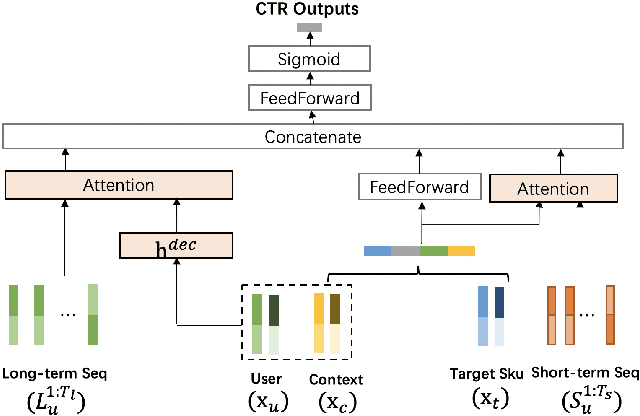
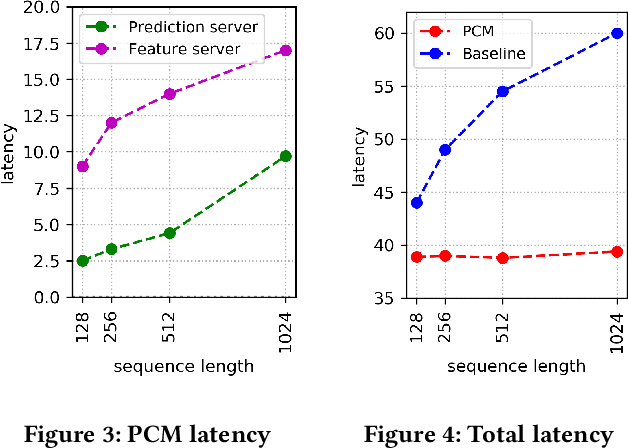
Click-Through Rate (CTR) prediction plays a key role in online advertising systems and online advertising. Constrained by strict requirements on online inference efficiency, it is often difficult to deploy useful but computationally intensive modules such as long-term behaviors modeling. Most recent works attempt to mitigate the online calculation issue of long historical behaviors by adopting two-stage methods to balance online efficiency and effectiveness. However, the information gaps caused by two-stage modeling may result in a diminished performance gain. In this work, we propose a novel framework called PCM to address this challenge in the view of system deployment. By deploying a pre-computing sub-module parallel to the retrieval stage, our PCM effectively reduces overall inference time which enables complex modeling in the ranking stage. Comprehensive offline and online experiments are conducted on the long-term user behaviors module to validate the effectiveness of our solution for the complex models. Moreover, our framework has been deployed into a large-scale real-world E-commerce system serving the main interface of hundreds of millions of active users, by deploying long sequential user behavior model in PCM. We achieved a 3\% CTR gain, with almost no increase in the ranking latency, compared to the base framework demonstrated from the online A/B test. To our knowledge, we are the first to propose an end-to-end solution for online training and deployment on complex CTR models from the system framework side.
Optical character recognition quality affects perceived usefulness of historical newspaper clippings
Jun 01, 2022

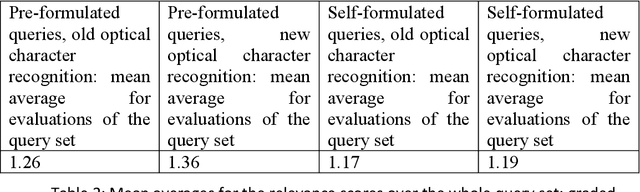
Introduction. We study effect of different quality optical character recognition in interactive information retrieval with a collection of one digitized historical Finnish newspaper. Method. This study is based on the simulated interactive information retrieval work task model. Thirty-two users made searches to an article collection of Finnish newspaper Uusi Suometar 1869-1918 with ca. 1.45 million auto segmented articles. Our article search database had two versions of each article with different quality optical character recognition. Each user performed six pre-formulated and six self-formulated short queries and evaluated subjectively the top-10 results using graded relevance scale of 0-3 without knowing about the optical character recognition quality differences of the otherwise identical articles. Analysis. Analysis of the user evaluations was performed by comparing mean averages of evaluations scores in user sessions. Differences of query results were detected by analysing lengths of returned articles in pre-formulated and self-formulated queries and number of different documents retrieved overall in these two sessions. Results. The main result of the study is that improved optical character recognition quality affects perceived usefulness of historical newspaper articles positively. Conclusions. We were able to show that improvement in optical character recognition quality of documents leads to higher mean relevance evaluation scores of query results in our historical newspaper collection. To the best of our knowledge this simulated interactive user-task is the first one showing empirically that users' subjective relevance assessments are affected by a change in the quality of optically read text.
View-labels Are Indispensable: A Multifacet Complementarity Study of Multi-view Clustering
May 05, 2022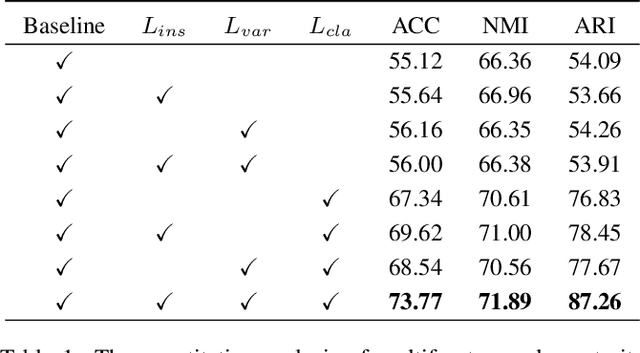
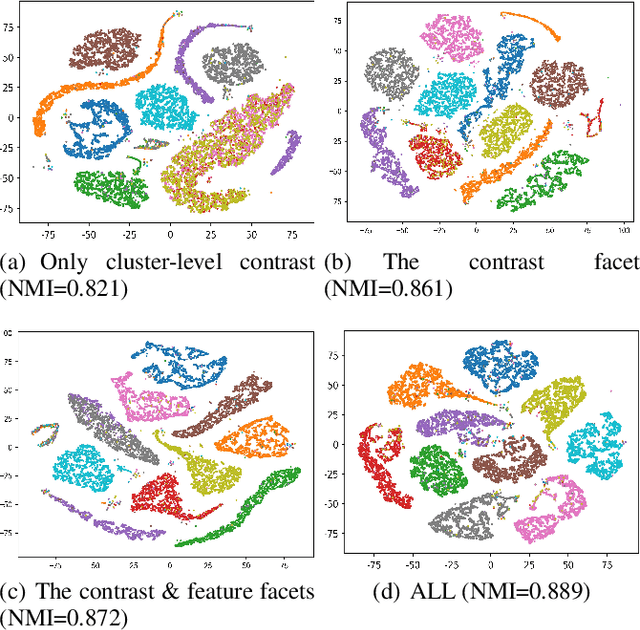
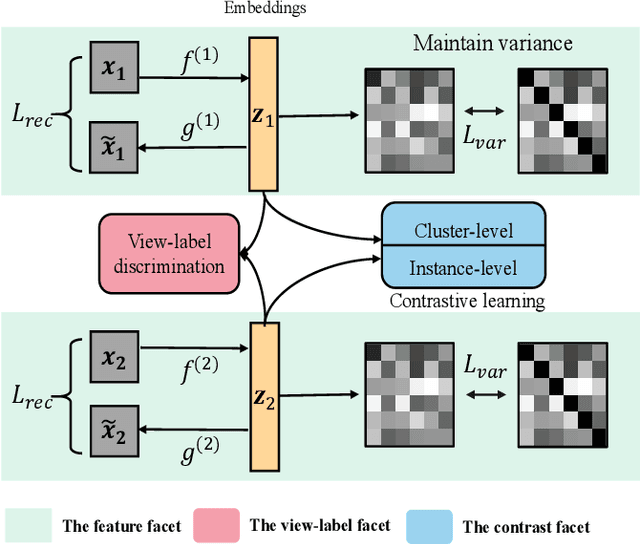
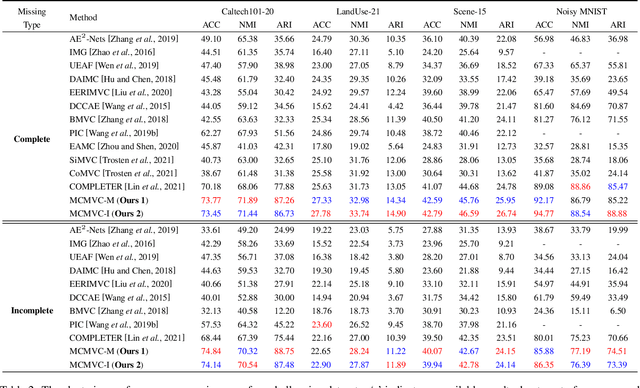
Consistency and complementarity are two key ingredients for boosting multi-view clustering (MVC). Recently with the introduction of popular contrastive learning, the consistency learning of views has been further enhanced in MVC, leading to promising performance. However, by contrast, the complementarity has not received sufficient attention except just in the feature facet, where the Hilbert Schmidt Independence Criterion (HSIC) term or the independent encoder-decoder network is usually adopted to capture view-specific information. This motivates us to reconsider the complementarity learning of views comprehensively from multiple facets including the feature-, view-label- and contrast- facets, while maintaining the view consistency. We empirically find that all the facets contribute to the complementarity learning, especially the view-label facet, which is usually neglected by existing methods. Based on this, we develop a novel \underline{M}ultifacet \underline{C}omplementarity learning framework for \underline{M}ulti-\underline{V}iew \underline{C}lustering (MCMVC), which fuses multifacet complementarity information, especially explicitly embedding the view-label information. To our best knowledge, it is the first time to use view-labels explicitly to guide the complementarity learning of views. Compared with the SOTA baseline, MCMVC achieves remarkable improvements, e.g., by average margins over $5.00\%$ and $7.00\%$ respectively in complete and incomplete MVC settings on Caltech101-20 in terms of three evaluation metrics.
Generative Anomaly Detection for Time Series Datasets
Jun 28, 2022
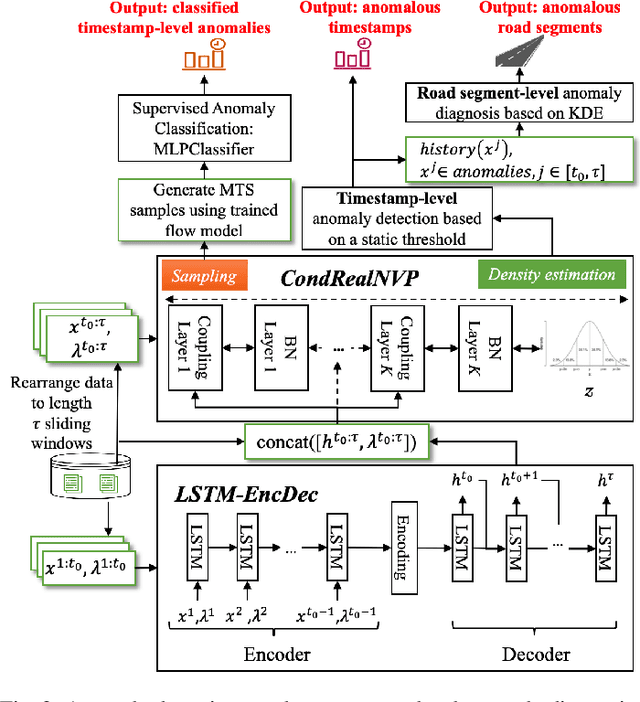

Traffic congestion anomaly detection is of paramount importance in intelligent traffic systems. The goals of transportation agencies are two-fold: to monitor the general traffic conditions in the area of interest and to locate road segments under abnormal congestion states. Modeling congestion patterns can achieve these goals for citywide roadways, which amounts to learning the distribution of multivariate time series (MTS). However, existing works are either not scalable or unable to capture the spatial-temporal information in MTS simultaneously. To this end, we propose a principled and comprehensive framework consisting of a data-driven generative approach that can perform tractable density estimation for detecting traffic anomalies. Our approach first clusters segments in the feature space and then uses conditional normalizing flow to identify anomalous temporal snapshots at the cluster level in an unsupervised setting. Then, we identify anomalies at the segment level by using a kernel density estimator on the anomalous cluster. Extensive experiments on synthetic datasets show that our approach significantly outperforms several state-of-the-art congestion anomaly detection and diagnosis methods in terms of Recall and F1-Score. We also use the generative model to sample labeled data, which can train classifiers in a supervised setting, alleviating the lack of labeled data for anomaly detection in sparse settings.
VIDI: A Video Dataset of Incidents
May 26, 2022
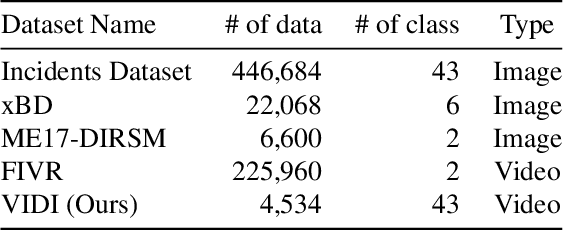
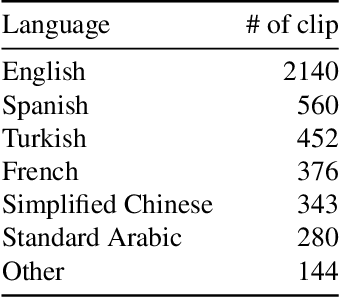
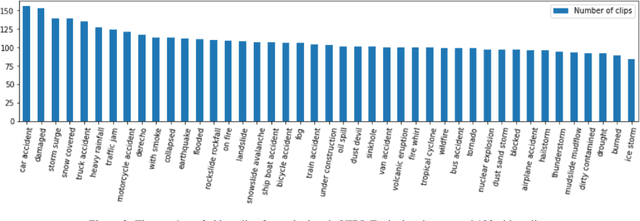
Automatic detection of natural disasters and incidents has become more important as a tool for fast response. There have been many studies to detect incidents using still images and text. However, the number of approaches that exploit temporal information is rather limited. One of the main reasons for this is that a diverse video dataset with various incident types does not exist. To address this need, in this paper we present a video dataset, Video Dataset of Incidents, VIDI, that contains 4,534 video clips corresponding to 43 incident categories. Each incident class has around 100 videos with a duration of ten seconds on average. To increase diversity, the videos have been searched in several languages. To assess the performance of the recent state-of-the-art approaches, Vision Transformer and TimeSformer, as well as to explore the contribution of video-based information for incident classification, we performed benchmark experiments on the VIDI and Incidents Dataset. We have shown that the recent methods improve the incident classification accuracy. We have found that employing video data is very beneficial for the task. By using the video data, the top-1 accuracy is increased to 76.56% from 67.37%, which was obtained using a single frame. VIDI will be made publicly available. Additional materials can be found at the following link: https://github.com/vididataset/VIDI.
INSTA-BNN: Binary Neural Network with INSTAnce-aware Threshold
Apr 18, 2022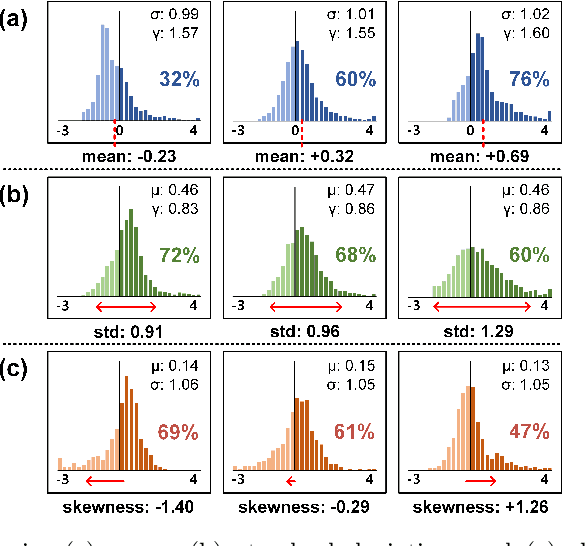
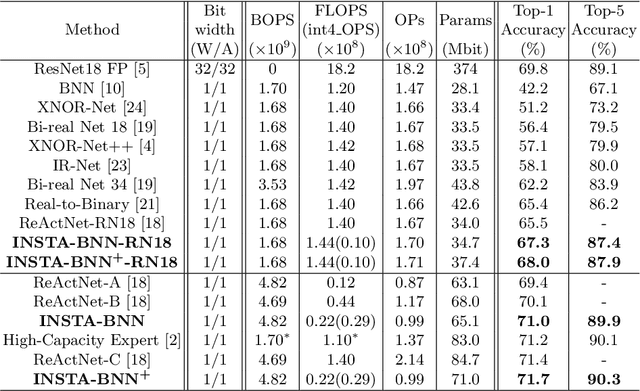
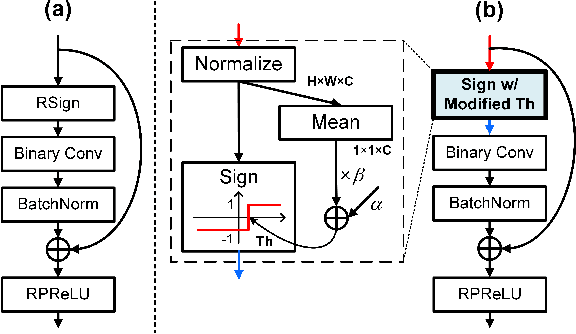

Binary Neural Networks (BNNs) have emerged as a promising solution for reducing the memory footprint and compute costs of deep neural networks. BNNs, on the other hand, suffer from information loss because binary activations are limited to only two values, resulting in reduced accuracy. To improve the accuracy, previous studies have attempted to control the distribution of binary activation by manually shifting the threshold of the activation function or making the shift amount trainable. During the process, they usually depended on statistical information computed from a batch. We argue that using statistical data from a batch fails to capture the crucial information for each input instance in BNN computations, and the differences between statistical information computed from each instance need to be considered when determining the binary activation threshold of each instance. Based on the concept, we propose the Binary Neural Network with INSTAnce-aware threshold (INSTA-BNN), which decides the activation threshold value considering the difference between statistical data computed from a batch and each instance. The proposed INSTA-BNN outperforms the baseline by 2.5% and 2.3% on the ImageNet classification task with comparable computing cost, achieving 68.0% and 71.7% top-1 accuracy on ResNet-18 and MobileNetV1 based models, respectively.
Deep Deterministic Information Bottleneck with Matrix-based Entropy Functional
Jan 31, 2021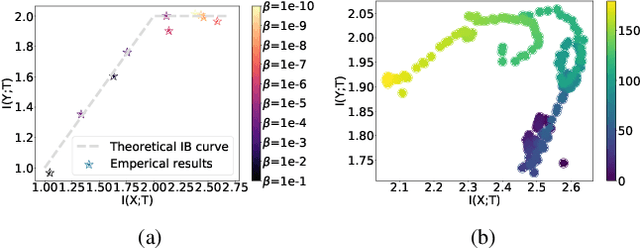



We introduce the matrix-based Renyi's $\alpha$-order entropy functional to parameterize Tishby et al. information bottleneck (IB) principle with a neural network. We term our methodology Deep Deterministic Information Bottleneck (DIB), as it avoids variational inference and distribution assumption. We show that deep neural networks trained with DIB outperform the variational objective counterpart and those that are trained with other forms of regularization, in terms of generalization performance and robustness to adversarial attack.Code available at https://github.com/yuxi120407/DIB
Information Prediction using Knowledge Graphs for Contextual Malware Threat Intelligence
Feb 10, 2021
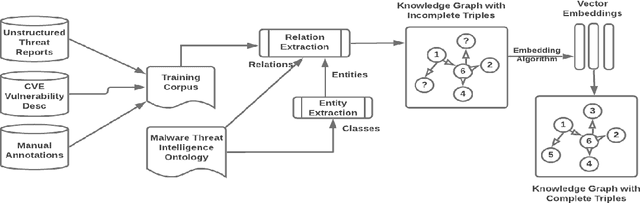
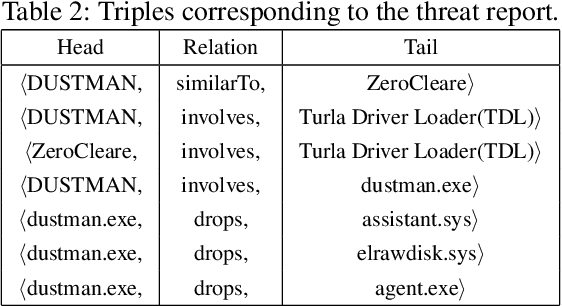

Large amounts of threat intelligence information about mal-ware attacks are available in disparate, typically unstructured, formats. Knowledge graphs can capture this information and its context using RDF triples represented by entities and relations. Sparse or inaccurate threat information, however, leads to challenges such as incomplete or erroneous triples. Named entity recognition (NER) and relation extraction (RE) models used to populate the knowledge graph cannot fully guaran-tee accurate information retrieval, further exacerbating this problem. This paper proposes an end-to-end approach to generate a Malware Knowledge Graph called MalKG, the first open-source automated knowledge graph for malware threat intelligence. MalKG dataset called MT40K1 contains approximately 40,000 triples generated from 27,354 unique entities and 34 relations. We demonstrate the application of MalKGin predicting missing malware threat intelligence information in the knowledge graph. For ground truth, we manually curate a knowledge graph called MT3K, with 3,027 triples generated from 5,741 unique entities and 22 relations. For entity prediction via a state-of-the-art entity prediction model(TuckER), our approach achieves 80.4 for the hits@10 metric (predicts the top 10 options for missing entities in the knowledge graph), and 0.75 for the MRR (mean reciprocal rank). We also propose a framework to automate the extraction of thousands of entities and relations into RDF triples, both manually and automatically, at the sentence level from1,100 malware threat intelligence reports and from the com-mon vulnerabilities and exposures (CVE) database.
Information Extraction From Co-Occurring Similar Entities
Feb 11, 2021
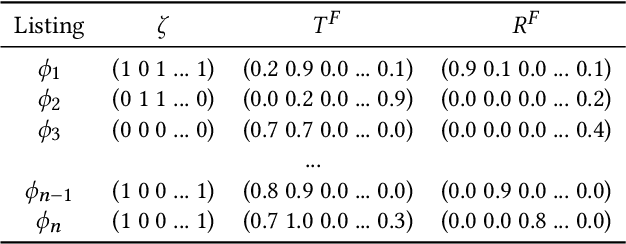
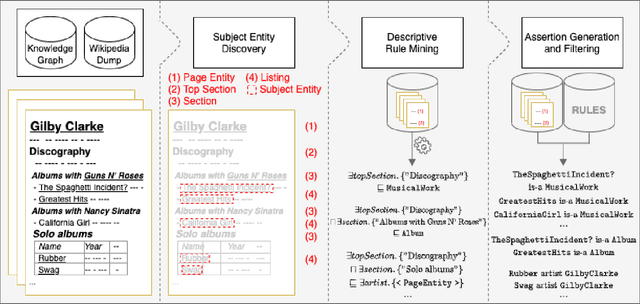
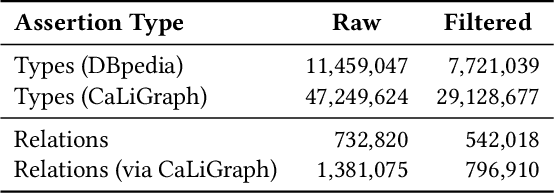
Knowledge about entities and their interrelations is a crucial factor of success for tasks like question answering or text summarization. Publicly available knowledge graphs like Wikidata or DBpedia are, however, far from being complete. In this paper, we explore how information extracted from similar entities that co-occur in structures like tables or lists can help to increase the coverage of such knowledge graphs. In contrast to existing approaches, we do not focus on relationships within a listing (e.g., between two entities in a table row) but on the relationship between a listing's subject entities and the context of the listing. To that end, we propose a descriptive rule mining approach that uses distant supervision to derive rules for these relationships based on a listing's context. Extracted from a suitable data corpus, the rules can be used to extend a knowledge graph with novel entities and assertions. In our experiments we demonstrate that the approach is able to extract up to 3M novel entities and 30M additional assertions from listings in Wikipedia. We find that the extracted information is of high quality and thus suitable to extend Wikipedia-based knowledge graphs like DBpedia, YAGO, and CaLiGraph. For the case of DBpedia, this would result in an increase of covered entities by roughly 50%.