 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information fusion approach for biomass estimation in a plateau mountainous forest using a synergistic system comprising UAS-based digital camera and LiDAR
Apr 14, 2022
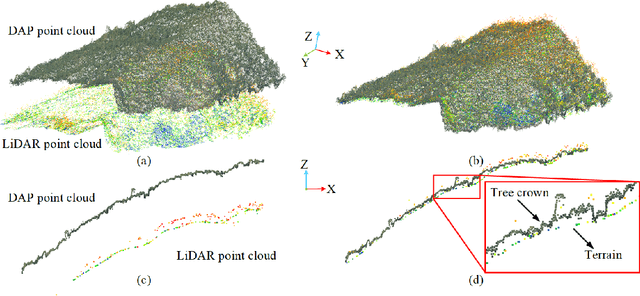
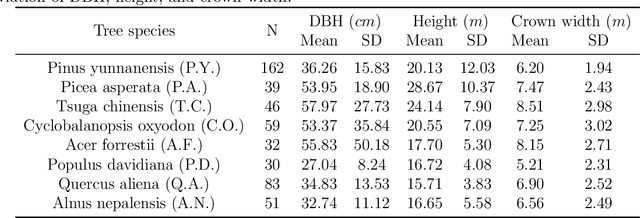
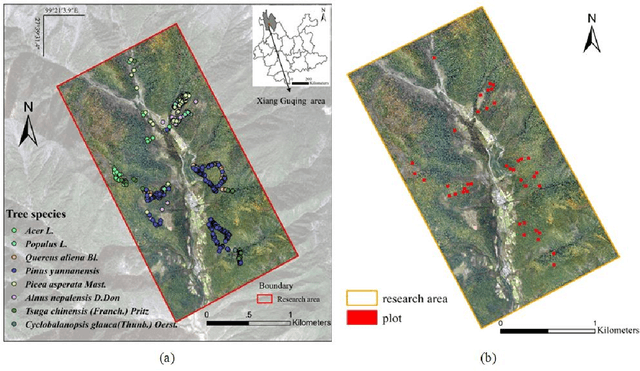

Forest land plays a vital role in global climate, ecosystems, farming and human living environments. Therefore, forest biomass estimation methods are necessary to monitor changes in the forest structure and function, which are key data in natural resources research. Although accurate forest biomass measurements are important in forest inventory and assessments, high-density measurements that involve airborne light detection and ranging (LiDAR) at a low flight height in large mountainous areas are highly expensive. The objective of this study was to quantify the aboveground biomass (AGB) of a plateau mountainous forest reserve using a system that synergistically combines an unmanned aircraft system (UAS)-based digital aerial camera and LiDAR to leverage their complementary advantages. In this study, we utilized digital aerial photogrammetry (DAP), which has the unique advantages of speed, high spatial resolution, and low cost, to compensate for the deficiency of forestry inventory using UAS-based LiDAR that requires terrain-following flight for high-resolution data acquisition. Combined with the sparse LiDAR points acquired by using a high-altitude and high-speed UAS for terrain extraction, dense normalized DAP point clouds can be obtained to produce an accurate and high-resolution canopy height model (CHM). Based on the CHM and spectral attributes obtained from multispectral images, we estimated and mapped the AGB of the region of interest with considerable cost efficiency. Our study supports the development of predictive models for large-scale wall-to-wall AGB mapping by leveraging the complementarity between DAP and LiDAR measurements. This work also reveals the potential of utilizing a UAS-based digital camera and LiDAR synergistically in a plateau mountainous forest area.
Channel Estimation and Signal Detection for MIMO-AFDM under Doubly Selective Channels
Jun 26, 2022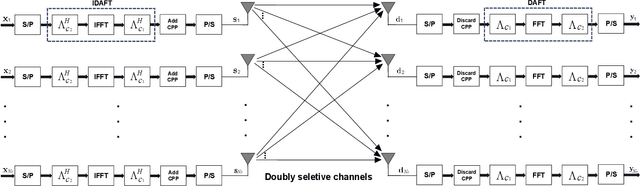
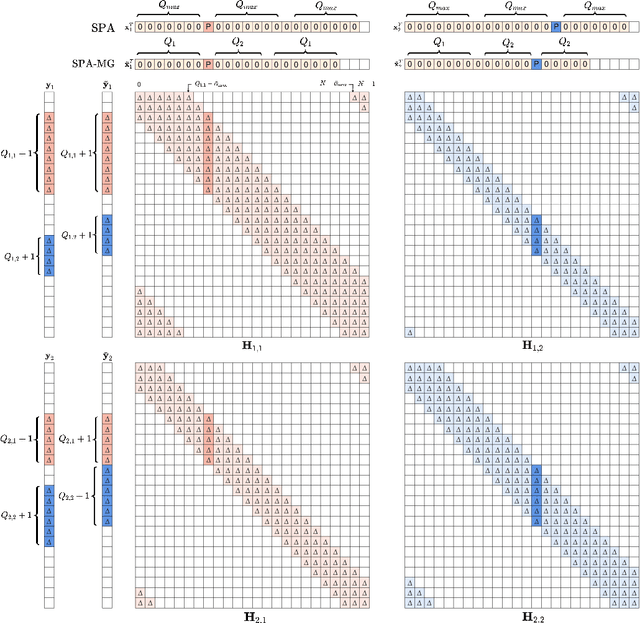
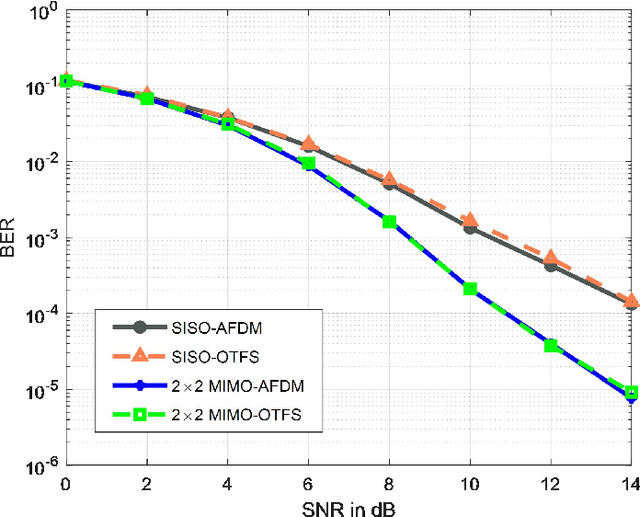
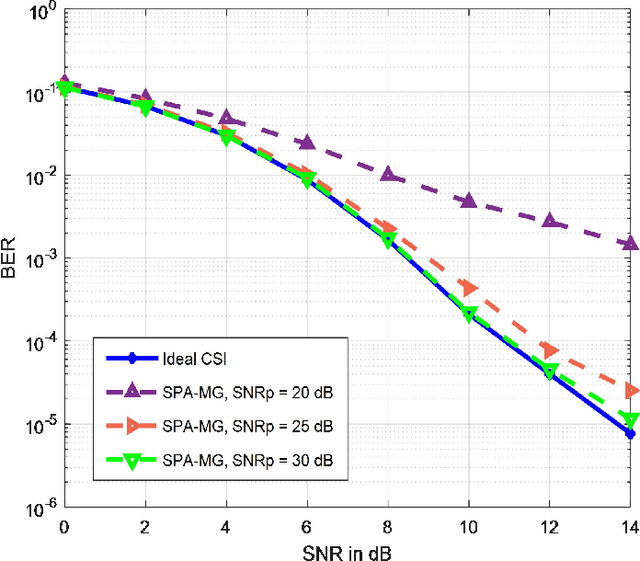
On the heels of orthogonal time frequency space (OTFS) modulation, the recently discovered affine frequency division multiplexing (AFDM) is a promising waveform for the sixth-generation wireless network due to its strong delay-doppler resilience against the double dispersive channels. With the superiorities of high multiplexing and diversity gain of multiple-input multiple-output (MIMO), we derive a vectorized input-output formulation of the MIMO-AFDM system. Correspondingly, we also propose an efficient single pilot aided with minimum guard (SPA-MG) scheme to perform channel estimation in the discrete affine Fourier transform (DAFT) domain. Furthermore, the message passing based iterative detector is explored for signal detection. Finally, the bit error ratio (BER) performances are simulated under doubly selective channels. It is worth emphasizing that the MIMO-AFDM system can achieve outstanding performance similar to MIMO-OTFS. Additionally, compared to ideal channel state information, our proposed SPA-MG scheme is verified to provide marginal difference with the least overhead.
Static Scheduling with Predictions Learned through Efficient Exploration
May 31, 2022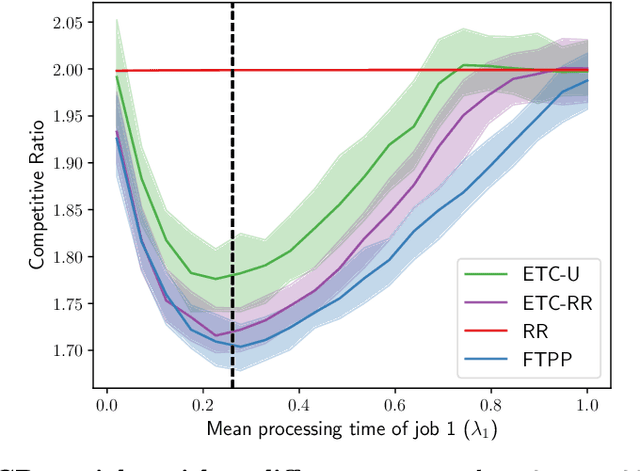
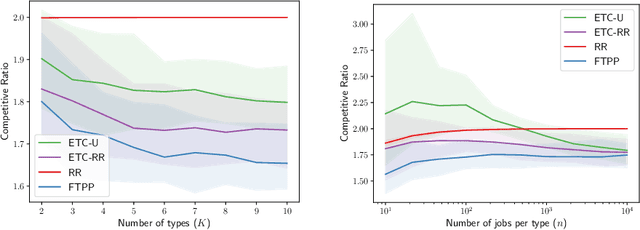
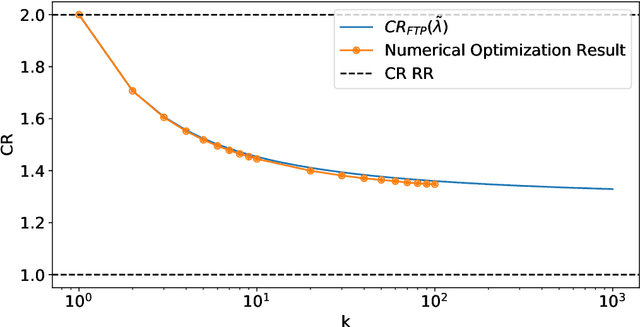
A popular approach to go beyond the worst-case analysis of online algorithms is to assume the existence of predictions that can be leveraged to improve performances. Those predictions are usually given by some external sources that cannot be fully trusted. Instead, we argue that trustful predictions can be built by algorithms, while they run. We investigate this idea in the illustrative context of static scheduling with exponential job sizes. Indeed, we prove that algorithms agnostic to this structure do not perform better than in the worst case. In contrast, when the expected job sizes are known, we show that the best algorithm using this information, called Follow-The-Perfect-Prediction (FTPP), exhibits much better performances. Then, we introduce two adaptive explore-then-commit types of algorithms: they both first (partially) learn expected job sizes and then follow FTPP once their self-predictions are confident enough. On the one hand, ETCU explores in "series", by completing jobs sequentially to acquire information. On the other hand, ETCRR, inspired by the optimal worst-case algorithm Round-Robin (RR), explores efficiently in "parallel". We prove that both of them asymptotically reach the performances of FTPP, with a faster rate for ETCRR. Those findings are empirically evaluated on synthetic data.
Long-term Leap Attention, Short-term Periodic Shift for Video Classification
Jul 12, 2022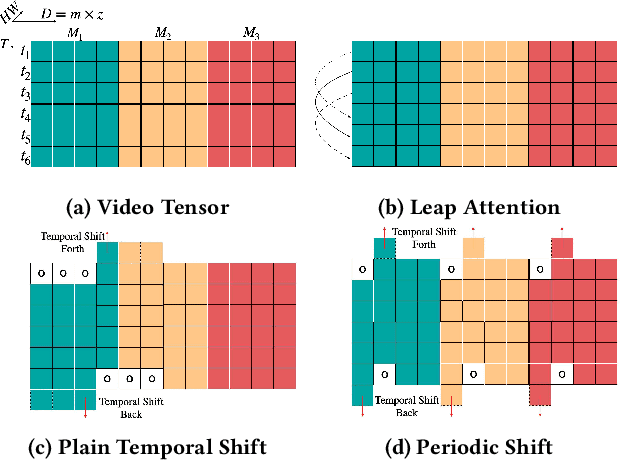
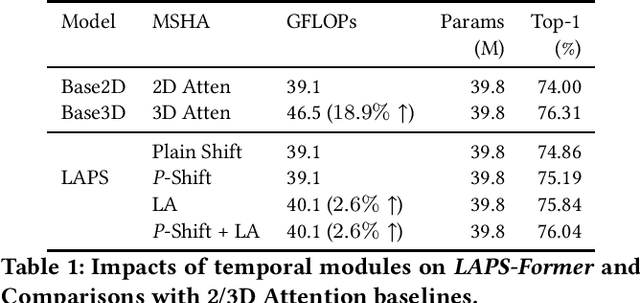
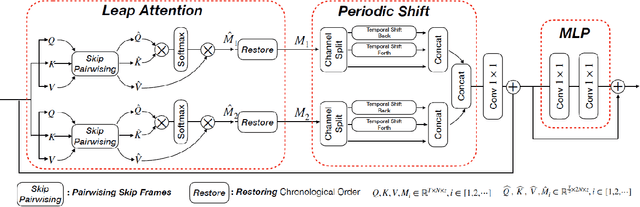

Video transformer naturally incurs a heavier computation burden than a static vision transformer, as the former processes $T$ times longer sequence than the latter under the current attention of quadratic complexity $(T^2N^2)$. The existing works treat the temporal axis as a simple extension of spatial axes, focusing on shortening the spatio-temporal sequence by either generic pooling or local windowing without utilizing temporal redundancy. However, videos naturally contain redundant information between neighboring frames; thereby, we could potentially suppress attention on visually similar frames in a dilated manner. Based on this hypothesis, we propose the LAPS, a long-term ``\textbf{\textit{Leap Attention}}'' (LA), short-term ``\textbf{\textit{Periodic Shift}}'' (\textit{P}-Shift) module for video transformers, with $(2TN^2)$ complexity. Specifically, the ``LA'' groups long-term frames into pairs, then refactors each discrete pair via attention. The ``\textit{P}-Shift'' exchanges features between temporal neighbors to confront the loss of short-term dynamics. By replacing a vanilla 2D attention with the LAPS, we could adapt a static transformer into a video one, with zero extra parameters and neglectable computation overhead ($\sim$2.6\%). Experiments on the standard Kinetics-400 benchmark demonstrate that our LAPS transformer could achieve competitive performances in terms of accuracy, FLOPs, and Params among CNN and transformer SOTAs. We open-source our project in \sloppy \href{https://github.com/VideoNetworks/LAPS-transformer}{\textit{\color{magenta}{https://github.com/VideoNetworks/LAPS-transformer}}} .
Is Lip Region-of-Interest Sufficient for Lipreading?
May 28, 2022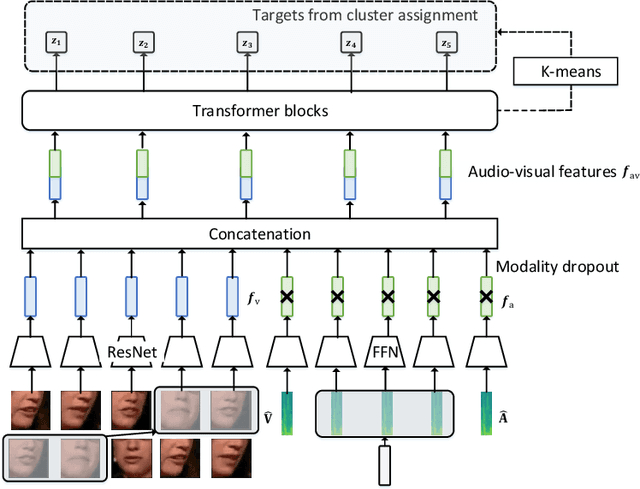
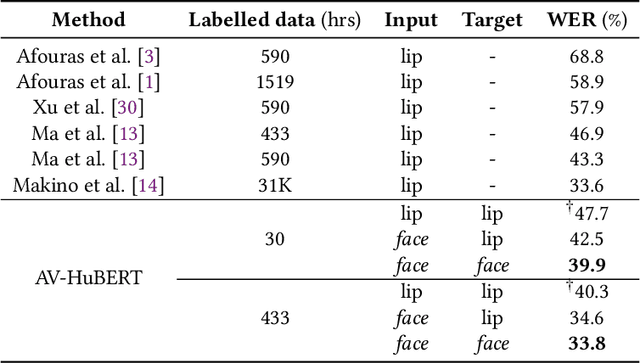

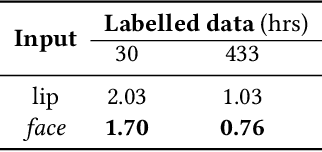
Lip region-of-interest (ROI) is conventionally used for visual input in the lipreading task. Few works have adopted the entire face as visual input because lip-excluded parts of the face are usually considered to be redundant and irrelevant to visual speech recognition. However, faces contain much more detailed information than lips, such as speakers' head pose, emotion, identity etc. We argue that such information might benefit visual speech recognition if a powerful feature extractor employing the entire face is trained. In this work, we propose to adopt the entire face for lipreading with self-supervised learning. AV-HuBERT, an audio-visual multi-modal self-supervised learning framework, was adopted in our experiments. Our experimental results showed that adopting the entire face achieved 16% relative word error rate (WER) reduction on the lipreading task, compared with the baseline method using lip as visual input. Without self-supervised pretraining, the model with face input achieved a higher WER than that using lip input in the case of limited training data (30 hours), while a slightly lower WER when using large amount of training data (433 hours).
Reference Vector Adaptation and Mating Selection Strategy via Adaptive Resonance Theory-based Clustering for Many-objective Optimization
May 04, 2022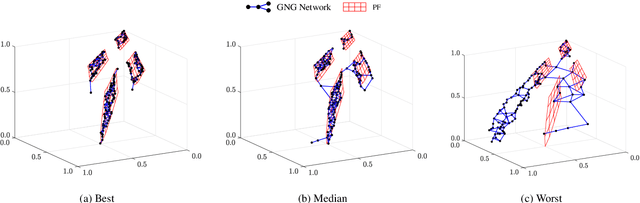
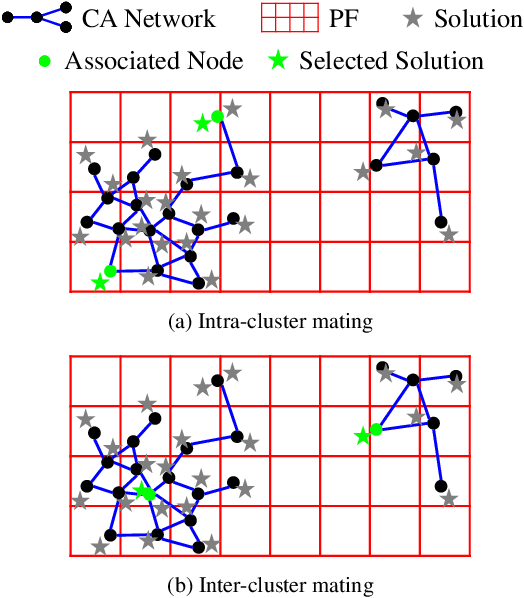

Decomposition-based multiobjective evolutionary algorithms (MOEAs) with clustering-based reference vector adaptation show good optimization performance for many-objective optimization problems (MaOPs). Especially, algorithms that employ a clustering algorithm with a topological structure (i.e., a network composed of nodes and edges) show superior optimization performance to other MOEAs for MaOPs with irregular Pareto optimal fronts (PFs). These algorithms, however, do not effectively utilize information of the topological structure in the search process. Moreover, the clustering algorithms typically used in conventional studies have limited clustering performance, inhibiting the ability to extract useful information for the search process. This paper proposes an adaptive reference vector-guided evolutionary algorithm using an adaptive resonance theory-based clustering with a topological structure. The proposed algorithm utilizes the information of the topological structure not only for reference vector adaptation but also for mating selection. The proposed algorithm is compared with 8 state-of-the-art MOEAs on 78 test problems. Experimental results reveal the outstanding optimization performance of the proposed algorithm over the others on MaOPs with various properties.
Learning Task-relevant Representations for Generalization via Characteristic Functions of Reward Sequence Distributions
May 20, 2022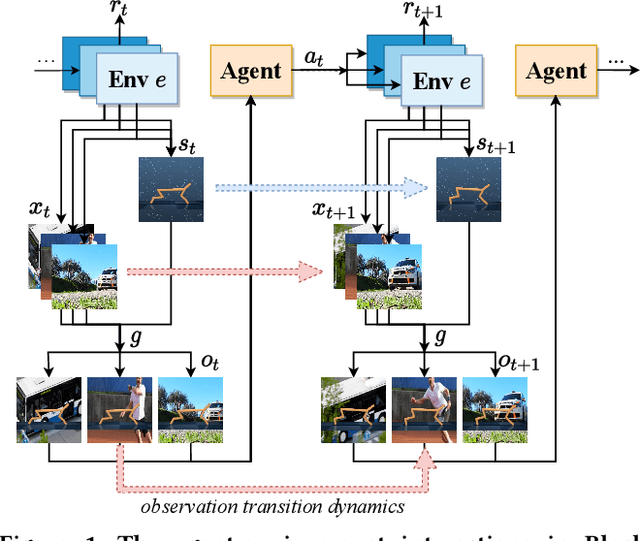
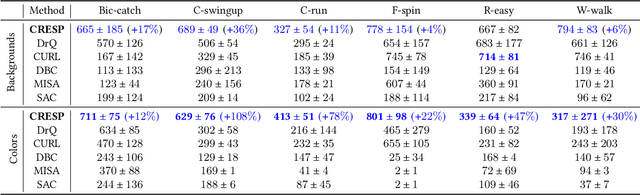
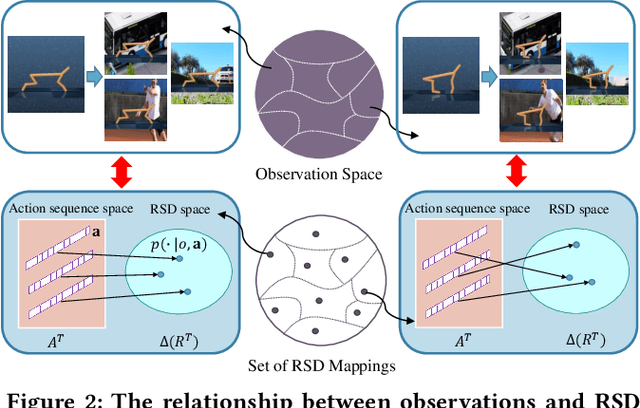
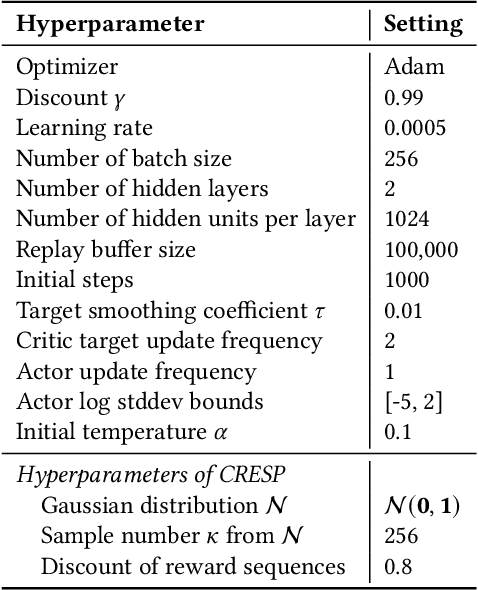
Generalization across different environments with the same tasks is critical for successful applications of visual reinforcement learning (RL) in real scenarios. However, visual distractions -- which are common in real scenes -- from high-dimensional observations can be hurtful to the learned representations in visual RL, thus degrading the performance of generalization. To tackle this problem, we propose a novel approach, namely Characteristic Reward Sequence Prediction (CRESP), to extract the task-relevant information by learning reward sequence distributions (RSDs), as the reward signals are task-relevant in RL and invariant to visual distractions. Specifically, to effectively capture the task-relevant information via RSDs, CRESP introduces an auxiliary task -- that is, predicting the characteristic functions of RSDs -- to learn task-relevant representations, because we can well approximate the high-dimensional distributions by leveraging the corresponding characteristic functions. Experiments demonstrate that CRESP significantly improves the performance of generalization on unseen environments, outperforming several state-of-the-arts on DeepMind Control tasks with different visual distractions.
Multilingual Medical Question Answering and Information Retrieval for Rural Health Intelligence Access
Jun 02, 2021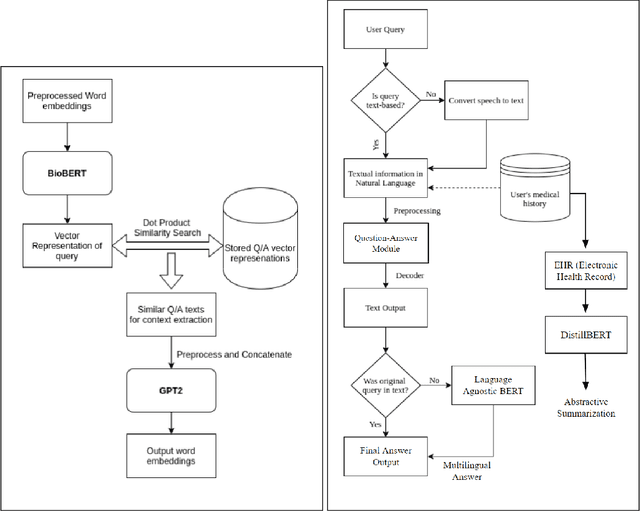

In rural regions of several developing countries, access to quality healthcare, medical infrastructure, and professional diagnosis is largely unavailable. Many of these regions are gradually gaining access to internet infrastructure, although not with a strong enough connection to allow for sustained communication with a medical practitioner. Several deaths resulting from this lack of medical access, absence of patient's previous health records, and the unavailability of information in indigenous languages can be easily prevented. In this paper, we describe an approach leveraging the phenomenal progress in Machine Learning and NLP (Natural Language Processing) techniques to design a model that is low-resource, multilingual, and a preliminary first-point-of-contact medical assistant. Our contribution includes defining the NLP pipeline required for named-entity-recognition, language-agnostic sentence embedding, natural language translation, information retrieval, question answering, and generative pre-training for final query processing. We obtain promising results for this pipeline and preliminary results for EHR (Electronic Health Record) analysis with text summarization for medical practitioners to peruse for their diagnosis. Through this NLP pipeline, we aim to provide preliminary medical information to the user and do not claim to supplant diagnosis from qualified medical practitioners. Using the input from subject matter experts, we have compiled a large corpus to pre-train and fine-tune our BioBERT based NLP model for the specific tasks. We expect recent advances in NLP architectures, several of which are efficient and privacy-preserving models, to further the impact of our solution and improve on individual task performance.
Unified BERT for Few-shot Natural Language Understanding
Jun 24, 2022
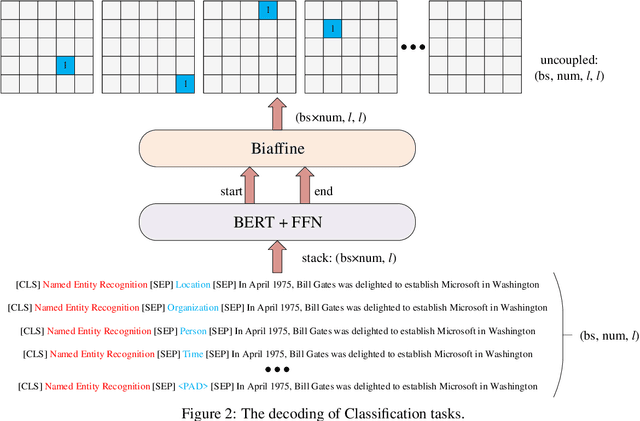
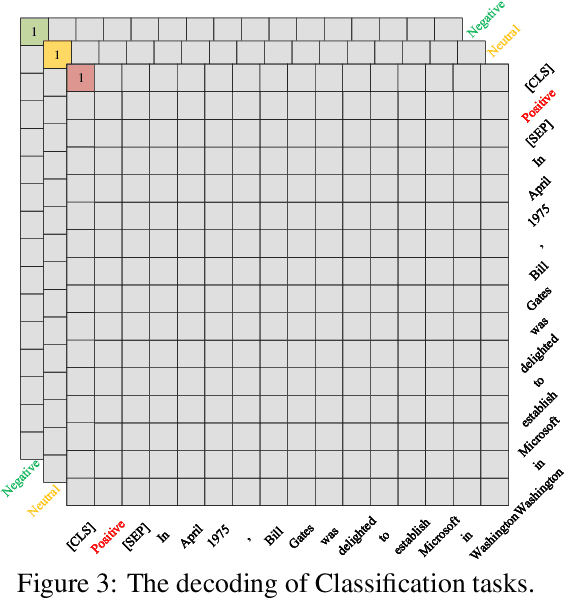

Even as pre-trained language models share a semantic encoder, natural language understanding suffers from a diversity of output schemas. In this paper, we propose UBERT, a unified bidirectional language understanding model based on BERT framework, which can universally model the training objects of different NLU tasks through a biaffine network. Specifically, UBERT encodes prior knowledge from various aspects, uniformly constructing learning representations across multiple NLU tasks, which is conducive to enhancing the ability to capture common semantic understanding. Using the biaffine to model scores pair of the start and end position of the original text, various classification and extraction structures can be converted into a universal, span-decoding approach. Experiments show that UBERT achieves the state-of-the-art performance on 7 NLU tasks, 14 datasets on few-shot and zero-shot setting, and realizes the unification of extensive information extraction and linguistic reasoning tasks.
Visually-Augmented Language Modeling
May 20, 2022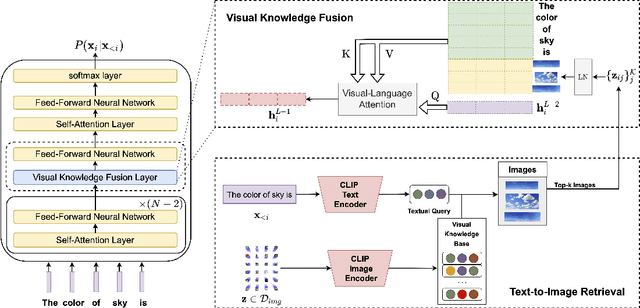

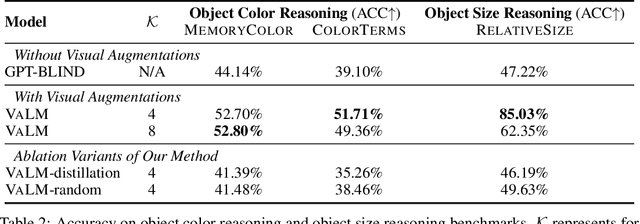
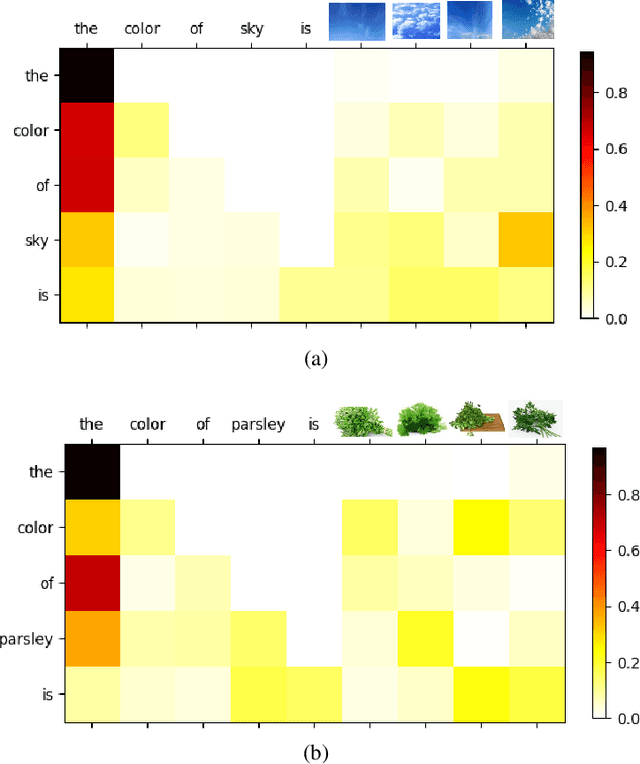
Human language is grounded on multimodal knowledge including visual knowledge like colors, sizes, and shapes. However, current large-scale pre-trained language models rely on the text-only self-supervised training with massive text data, which precludes them from utilizing relevant visual information when necessary. To address this, we propose a novel pre-training framework, named VaLM, to Visually-augment text tokens with retrieved relevant images for Language Modeling. Specifically, VaLM builds on a novel text-vision alignment method via an image retrieval module to fetch corresponding images given a textual context. With the visually-augmented context, VaLM uses a visual knowledge fusion layer to enable multimodal grounded language modeling by attending on both text context and visual knowledge in images. We evaluate the proposed model on various multimodal commonsense reasoning tasks, which require visual information to excel. VaLM outperforms the text-only baseline with substantial gains of +8.66% and +37.81% accuracy on object color and size reasoning, respectively.