 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PaECTER: Patent-level Representation Learning using Citation-informed Transformers
Feb 29, 2024
PaECTER is a publicly available, open-source document-level encoder specific for patents. We fine-tune BERT for Patents with examiner-added citation information to generate numerical representations for patent documents. PaECTER performs better in similarity tasks than current state-of-the-art models used in the patent domain. More specifically, our model outperforms the next-best patent specific pre-trained language model (BERT for Patents) on our patent citation prediction test dataset on two different rank evaluation metrics. PaECTER predicts at least one most similar patent at a rank of 1.32 on average when compared against 25 irrelevant patents. Numerical representations generated by PaECTER from patent text can be used for downstream tasks such as classification, tracing knowledge flows, or semantic similarity search. Semantic similarity search is especially relevant in the context of prior art search for both inventors and patent examiners. PaECTER is available on Hugging Face.
Beyond Language Models: Byte Models are Digital World Simulators
Feb 29, 2024Traditional deep learning often overlooks bytes, the basic units of the digital world, where all forms of information and operations are encoded and manipulated in binary format. Inspired by the success of next token prediction in natural language processing, we introduce bGPT, a model with next byte prediction to simulate the digital world. bGPT matches specialized models in performance across various modalities, including text, audio, and images, and offers new possibilities for predicting, simulating, and diagnosing algorithm or hardware behaviour. It has almost flawlessly replicated the process of converting symbolic music data, achieving a low error rate of 0.0011 bits per byte in converting ABC notation to MIDI format. In addition, bGPT demonstrates exceptional capabilities in simulating CPU behaviour, with an accuracy exceeding 99.99% in executing various operations. Leveraging next byte prediction, models like bGPT can directly learn from vast binary data, effectively simulating the intricate patterns of the digital world.
TEncDM: Understanding the Properties of Diffusion Model in the Space of Language Model Encodings
Feb 29, 2024Drawing inspiration from the success of diffusion models in various domains, numerous research papers proposed methods for adapting them to text data. Despite these efforts, none of them has managed to achieve the quality of the large language models. In this paper, we conduct a comprehensive analysis of key components of the text diffusion models and introduce a novel approach named Text Encoding Diffusion Model (TEncDM). Instead of the commonly used token embedding space, we train our model in the space of the language model encodings. Additionally, we propose to use a Transformer-based decoder that utilizes contextual information for text reconstruction. We also analyse self-conditioning and find that it increases the magnitude of the model outputs, allowing the reduction of the number of denoising steps at the inference stage. Evaluation of TEncDM on two downstream text generation tasks, QQP and XSum, demonstrates its superiority over existing non-autoregressive models.
Solving Hierarchical Information-Sharing Dec-POMDPs: An Extensive-Form Game Approach
Feb 09, 2024A recent theory shows that a multi-player decentralized partially observable Markov decision process can be transformed into an equivalent single-player game, enabling the application of \citeauthor{bellman}'s principle of optimality to solve the single-player game by breaking it down into single-stage subgames. However, this approach entangles the decision variables of all players at each single-stage subgame, resulting in backups with a double-exponential complexity. This paper demonstrates how to disentangle these decision variables while maintaining optimality under hierarchical information sharing, a prominent management style in our society. To achieve this, we apply the principle of optimality to solve any single-stage subgame by breaking it down further into smaller subgames, enabling us to make single-player decisions at a time. Our approach reveals that extensive-form games always exist with solutions to a single-stage subgame, significantly reducing time complexity. Our experimental results show that the algorithms leveraging these findings can scale up to much larger multi-player games without compromising optimality.
DRSI-Net: Dual-Residual Spatial Interaction Network for Multi-Person Pose Estimation
Feb 26, 2024Multi-person pose estimation (MPPE), which aims to locate keypoints for all persons in the frames, is an active research branch of computer vision. Variable human poses and complex scenes make MPPE dependent on both local details and global structures, and the absence of them may cause keypoint feature misalignment. In this case, high-order spatial interactions that can effectively link the local and global information of features are particularly important. However, most methods do not have spatial interactions, and a few methods have low-order spatial interactions but they are difficult to achieve a good balance between accuracy and complexity. To address the above problems, a Dual-Residual Spatial Interaction Network (DRSI-Net) for MPPE with high accuracy and low complexity is proposed in this paper. DRSI-Net recursively performs residual spatial information interactions on neighbor features, so that more useful spatial information can be retained and more similarities can be obtained between shallow and deep extracted features. The channel and spatial dual attention mechanism introduced in the multi-scale feature fusion also helps the network to adaptively focus on features relevant to target keypoints and further refine generated poses. At the same time, by optimizing interactive channel dimensions and dividing gradient flow, the spatial interaction module is designed to be lightweight, which reduces the complexity of the network. According to the experimental results on the COCO dataset, the proposed DRSI-Net outperforms other state-of-the-art methods in both accuracy and complexity.
Decompose-and-Compose: A Compositional Approach to Mitigating Spurious Correlation
Mar 02, 2024While standard Empirical Risk Minimization (ERM) training is proven effective for image classification on in-distribution data, it fails to perform well on out-of-distribution samples. One of the main sources of distribution shift for image classification is the compositional nature of images. Specifically, in addition to the main object or component(s) determining the label, some other image components usually exist, which may lead to the shift of input distribution between train and test environments. More importantly, these components may have spurious correlations with the label. To address this issue, we propose Decompose-and-Compose (DaC), which improves robustness to correlation shift by a compositional approach based on combining elements of images. Based on our observations, models trained with ERM usually highly attend to either the causal components or the components having a high spurious correlation with the label (especially in datapoints on which models have a high confidence). In fact, according to the amount of spurious correlation and the easiness of classification based on the causal or non-causal components, the model usually attends to one of these more (on samples with high confidence). Following this, we first try to identify the causal components of images using class activation maps of models trained with ERM. Afterward, we intervene on images by combining them and retraining the model on the augmented data, including the counterfactual ones. Along with its high interpretability, this work proposes a group-balancing method by intervening on images without requiring group labels or information regarding the spurious features during training. The method has an overall better worst group accuracy compared to previous methods with the same amount of supervision on the group labels in correlation shift.
Evaluating Large Language Models as Virtual Annotators for Time-series Physical Sensing Data
Mar 02, 2024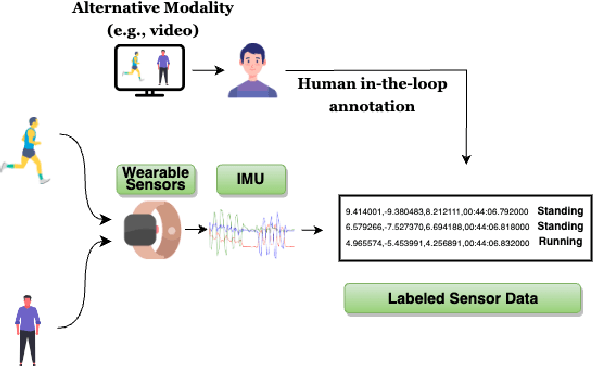

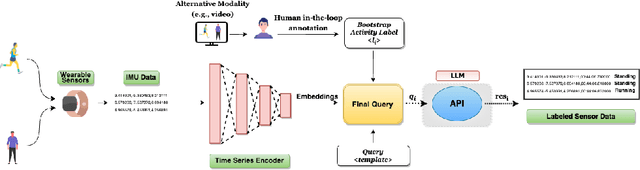

Traditional human-in-the-loop-based annotation for time-series data like inertial data often requires access to alternate modalities like video or audio from the environment. These alternate sources provide the necessary information to the human annotator, as the raw numeric data is often too obfuscated even for an expert. However, this traditional approach has many concerns surrounding overall cost, efficiency, storage of additional modalities, time, scalability, and privacy. Interestingly, recent large language models (LLMs) are also trained with vast amounts of publicly available alphanumeric data, which allows them to comprehend and perform well on tasks beyond natural language processing. Naturally, this opens up a potential avenue to explore LLMs as virtual annotators where the LLMs will be directly provided the raw sensor data for annotation instead of relying on any alternate modality. Naturally, this could mitigate the problems of the traditional human-in-the-loop approach. Motivated by this observation, we perform a detailed study in this paper to assess whether the state-of-the-art (SOTA) LLMs can be used as virtual annotators for labeling time-series physical sensing data. To perform this in a principled manner, we segregate the study into two major phases. In the first phase, we investigate the challenges an LLM like GPT-4 faces in comprehending raw sensor data. Considering the observations from phase 1, in the next phase, we investigate the possibility of encoding the raw sensor data using SOTA SSL approaches and utilizing the projected time-series data to get annotations from the LLM. Detailed evaluation with four benchmark HAR datasets shows that SSL-based encoding and metric-based guidance allow the LLM to make more reasonable decisions and provide accurate annotations without requiring computationally expensive fine-tuning or sophisticated prompt engineering.
Investigating the Effectiveness of HyperTuning via Gisting
Feb 26, 2024Gisting (Mu et al., 2023) is a simple method for training models to compress information into fewer token representations using a modified attention mask, and can serve as an economical approach to training Transformer-based hypernetworks. We introduce HyperLlama, a set of Gisting-based hypernetworks built on Llama-2 models that generates task-specific soft prefixes based on few-shot inputs. In experiments across P3, Super-NaturalInstructions and Symbol Tuning datasets, we show that HyperLlama models can effectively compress information from few-shot examples into soft prefixes. However, they still underperform multi-task fine-tuned language models with full attention over few-shot in-context examples. We also show that HyperLlama-generated soft prefixes can serve as better initializations for further prefix tuning. Overall, Gisting-based hypernetworks are economical and easy to implement, but have mixed empirical performance.
Multi-FAct: Assessing Multilingual LLMs' Multi-Regional Knowledge using FActScore
Feb 28, 2024Large Language Models (LLMs) are prone to factuality hallucination, generating text that contradicts established knowledge. While extensive research has addressed this in English, little is known about multilingual LLMs. This paper systematically evaluates multilingual LLMs' factual accuracy across languages and geographic regions. We introduce a novel pipeline for multilingual factuality evaluation, adapting FActScore(Min et al., 2023) for diverse languages. Our analysis across nine languages reveals that English consistently outperforms others in factual accuracy and quantity of generated facts. Furthermore, multilingual models demonstrate a bias towards factual information from Western continents. These findings highlight the need for improved multilingual factuality assessment and underscore geographical biases in LLMs' fact generation.
Extending RAIM with a Gaussian Mixture of Opportunistic Information
Feb 05, 2024GNSS are indispensable for various applications, but they are vulnerable to spoofing attacks. The original receiver autonomous integrity monitoring (RAIM) was not designed for securing GNSS. In this context, RAIM was extended with wireless signals, termed signals of opportunity (SOPs), or onboard sensors, typically assumed benign. However, attackers might also manipulate wireless networks, raising the need for a solution that considers untrustworthy SOPs. To address this, we extend RAIM by incorporating all opportunistic information, i.e., measurements from terrestrial infrastructures and onboard sensors, culminating in one function for robust GNSS spoofing detection. The objective is to assess the likelihood of GNSS spoofing by analyzing locations derived from extended RAIM solutions, which include location solutions from GNSS pseudorange subsets and wireless signal subsets of untrusted networks. Our method comprises two pivotal components: subset generation and location fusion. Subsets of ranging information are created and processed through positioning algorithms, producing temporary locations. Onboard sensors provide speed, acceleration, and attitude data, aiding in location filtering based on motion constraints. The filtered locations, modeled with uncertainty, are fused into a composite likelihood function normalized for GNSS spoofing detection. Theoretical assessments of GNSS-only and multi-infrastructure scenarios under uncoordinated and coordinated attacks are conducted. The detection of these attacks is feasible when the number of benign subsets exceeds a specific threshold. A real-world dataset from the Kista area is used for experimental validation. Comparative analysis against baseline methods shows a significant improvement in detection accuracy achieved by our Gaussian Mixture RAIM approach. Moreover, we discuss leveraging RAIM results for plausible location recovery.