 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
H-EMD: A Hierarchical Earth Mover's Distance Method for Instance Segmentation
Jun 02, 2022
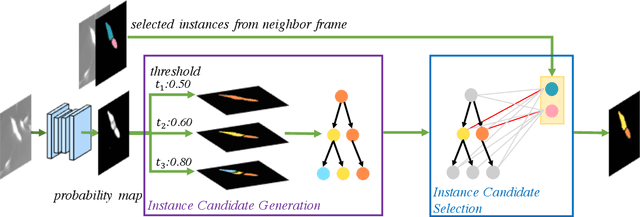
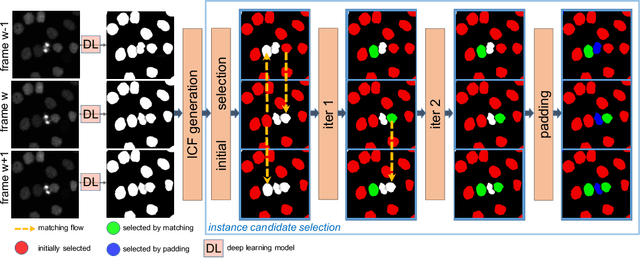
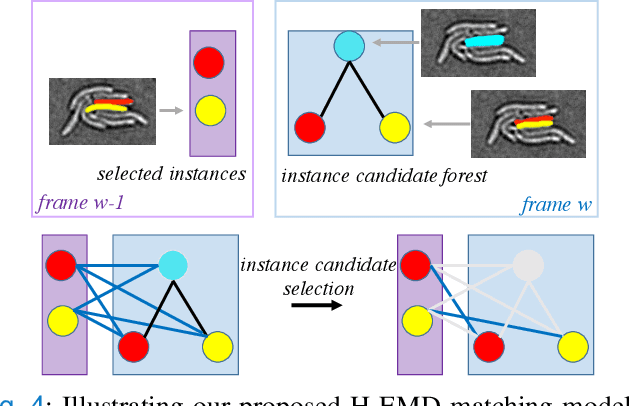

Deep learning (DL) based semantic segmentation methods have achieved excellent performance in biomedical image segmentation, producing high quality probability maps to allow extraction of rich instance information to facilitate good instance segmentation. While numerous efforts were put into developing new DL semantic segmentation models, less attention was paid to a key issue of how to effectively explore their probability maps to attain the best possible instance segmentation. We observe that probability maps by DL semantic segmentation models can be used to generate many possible instance candidates, and accurate instance segmentation can be achieved by selecting from them a set of "optimized" candidates as output instances. Further, the generated instance candidates form a well-behaved hierarchical structure (a forest), which allows selecting instances in an optimized manner. Hence, we propose a novel framework, called hierarchical earth mover's distance (H-EMD), for instance segmentation in biomedical 2D+time videos and 3D images, which judiciously incorporates consistent instance selection with semantic-segmentation-generated probability maps. H-EMD contains two main stages. (1) Instance candidate generation: capturing instance-structured information in probability maps by generating many instance candidates in a forest structure. (2) Instance candidate selection: selecting instances from the candidate set for final instance segmentation. We formulate a key instance selection problem on the instance candidate forest as an optimization problem based on the earth mover's distance (EMD), and solve it by integer linear programming. Extensive experiments on eight biomedical video or 3D datasets demonstrate that H-EMD consistently boosts DL semantic segmentation models and is highly competitive with state-of-the-art methods.
Downlink Massive MU-MIMO with Successively-Regularized Zero Forcing Precoding
Jun 17, 2022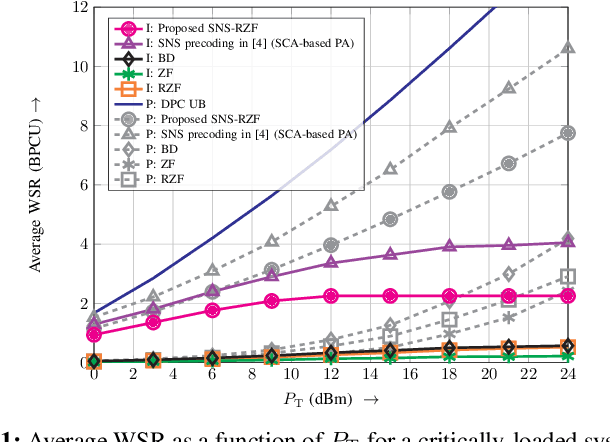
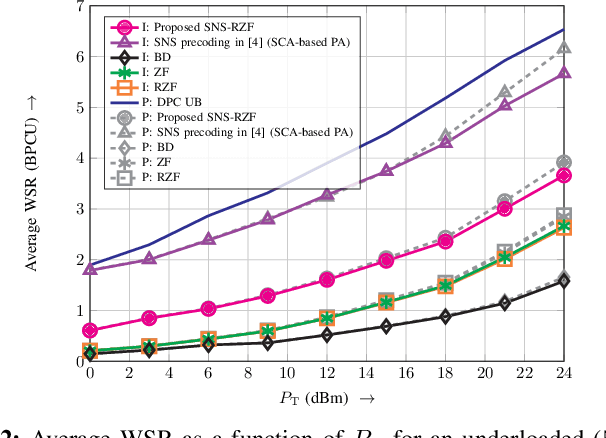
In this letter, we consider linear precoding for downlink massive multi-user (MU) multiple-input multiple-output (MIMO) systems. We propose the novel successively-regularized zero forcing (SRZF) precoding, which exploits successive null spaces of the MIMO channels of the users, along with regularization, to control the inter-user interference and to enhance performance and robustness to imperfect channel state information (CSI) at the base station (BS). We compare the weighted sum rate of the proposed SRZF precoding with those of block diagonalization and conventional and regularized zero forcing precoding for fixed and locally-optimal power allocation strategies as well as for perfect and imperfect CSI via computer simulations. Our simulation results reveal that for both underloaded and critically-loaded systems and perfect and imperfect CSI at the BS, the proposed SRZF precoding significantly outperforms the considered baseline schemes, making it an attractive option for downlink massive MU-MIMO systems.
All-Photonic Artificial Neural Network Processor Via Non-linear Optics
May 17, 2022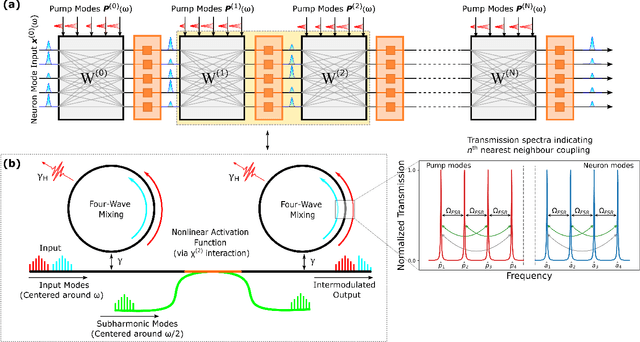
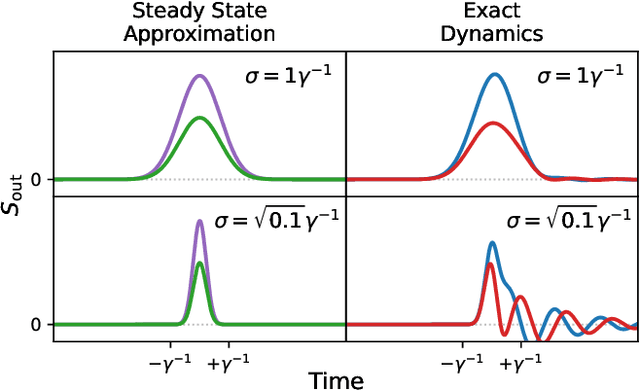
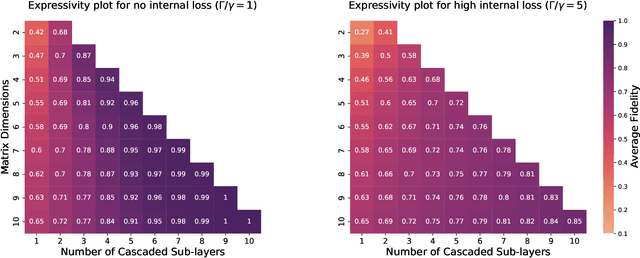
Optics and photonics has recently captured interest as a platform to accelerate linear matrix processing, that has been deemed as a bottleneck in traditional digital electronic architectures. In this paper, we propose an all-photonic artificial neural network processor wherein information is encoded in the amplitudes of frequency modes that act as neurons. The weights among connected layers are encoded in the amplitude of controlled frequency modes that act as pumps. Interaction among these modes for information processing is enabled by non-linear optical processes. Both the matrix multiplication and element-wise activation functions are performed through coherent processes, enabling the direct representation of negative and complex numbers without the use of detectors or digital electronics. Via numerical simulations, we show that our design achieves a performance commensurate with present-day state-of-the-art computational networks on image-classification benchmarks. Our architecture is unique in providing a completely unitary, reversible mode of computation. Additionally, the computational speed increases with the power of the pumps to arbitrarily high rates, as long as the circuitry can sustain the higher optical power.
Learning to Refactor Action and Co-occurrence Features for Temporal Action Localization
Jun 23, 2022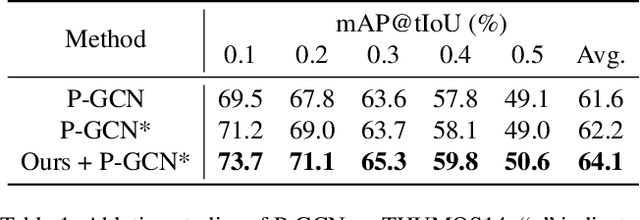
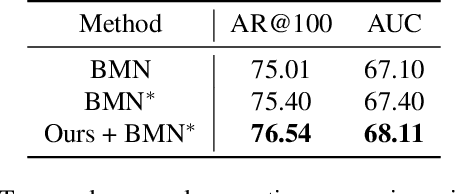
The main challenge of Temporal Action Localization is to retrieve subtle human actions from various co-occurring ingredients, e.g., context and background, in an untrimmed video. While prior approaches have achieved substantial progress through devising advanced action detectors, they still suffer from these co-occurring ingredients which often dominate the actual action content in videos. In this paper, we explore two orthogonal but complementary aspects of a video snippet, i.e., the action features and the co-occurrence features. Especially, we develop a novel auxiliary task by decoupling these two types of features within a video snippet and recombining them to generate a new feature representation with more salient action information for accurate action localization. We term our method RefactorNet, which first explicitly factorizes the action content and regularizes its co-occurrence features, and then synthesizes a new action-dominated video representation. Extensive experimental results and ablation studies on THUMOS14 and ActivityNet v1.3 demonstrate that our new representation, combined with a simple action detector, can significantly improve the action localization performance.
GLOBUS: GLObal Building heights for Urban Studies
May 24, 2022
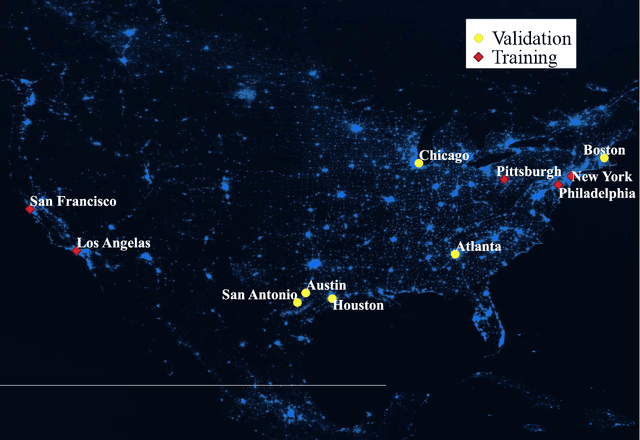
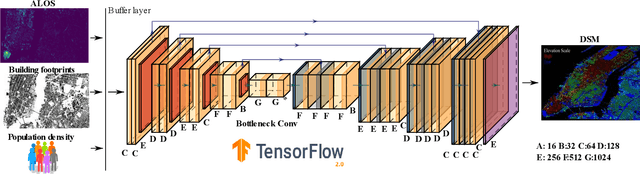
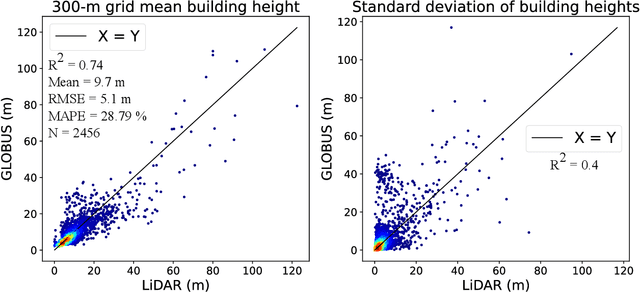
Urban weather and climate studies continue to be important as extreme events cause economic loss and impact public health. Weather models seek to represent urban areas but are oversimplified due to data availability, especially building information. This paper introduces a novel Level of Detail-1 (LoD-1) building dataset derived from a Deep Neural Network (DNN) called GLObal Building heights for Urban Studies (GLOBUS). GLOBUS uses open-source datasets as predictors: Advanced Land Observation Satellite (ALOS) Digital Surface Model (DSM) normalized using Shuttle Radar Topography Mission (SRTM) Digital Elevation Model (DEM), Landscan population density, and building footprints. The building information from GLOBUS can be ingested in Numerical Weather Prediction (NWP) and urban energy-water balance models to study localized phenomena such as the Urban Heat Island (UHI) effect. GLOBUS has been trained and validated using the United States Geological Survey (USGS) 3DEP Light Detection and Ranging (LiDAR) data. We used data from 5 US cities for training and the model was validated over 6 cities. Performance metrics are computed at a spatial resolution of 300-meter. The Root Mean Squared Error (RMSE) and Mean Absolute Percentage Error (MAPE) were 5.15 meters and 28.8 %, respectively. The standard deviation and histogram of building heights over a 300-meter grid are well represented using GLOBUS.
Propagation with Adaptive Mask then Training for Node Classification on Attributed Networks
Jun 23, 2022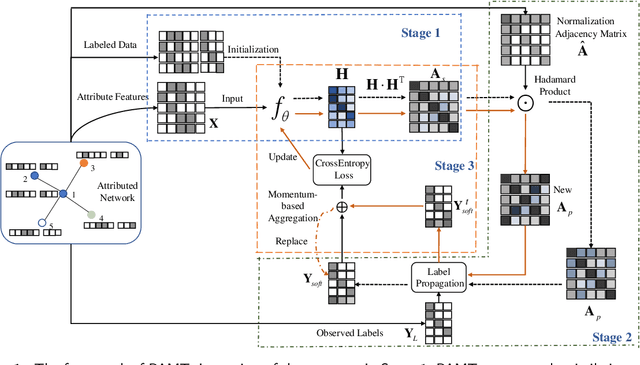
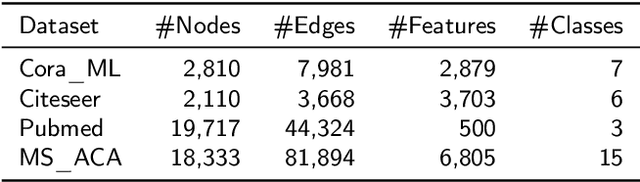
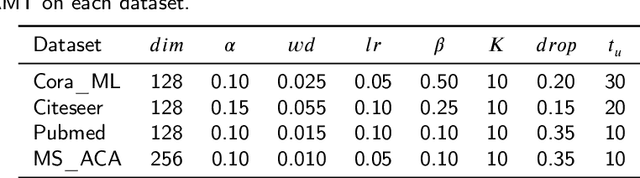
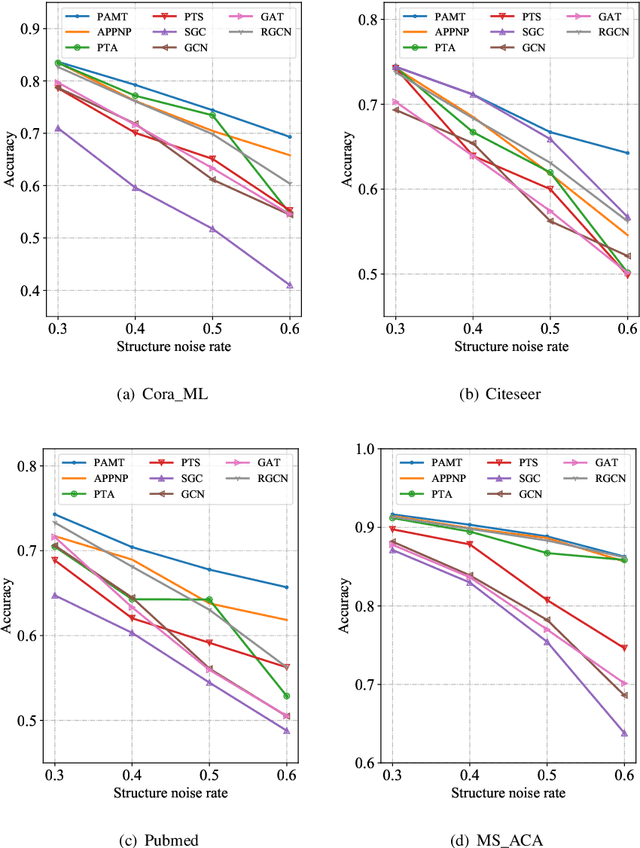
Node classification on attributed networks is a semi-supervised task that is crucial for network analysis. By decoupling two critical operations in Graph Convolutional Networks (GCNs), namely feature transformation and neighborhood aggregation, some recent works of decoupled GCNs could support the information to propagate deeper and achieve advanced performance. However, they follow the traditional structure-aware propagation strategy of GCNs, making it hard to capture the attribute correlation of nodes and sensitive to the structure noise described by edges whose two endpoints belong to different categories. To address these issues, we propose a new method called the itshape Propagation with Adaptive Mask then Training (PAMT). The key idea is to integrate the attribute similarity mask into the structure-aware propagation process. In this way, PAMT could preserve the attribute correlation of adjacent nodes during the propagation and effectively reduce the influence of structure noise. Moreover, we develop an iterative refinement mechanism to update the similarity mask during the training process for improving the training performance. Extensive experiments on four real-world datasets demonstrate the superior performance and robustness of PAMT.
VGSwarm: A Vision-based Gene Regulation Network for UAVs Swarm Behavior Emergence
Jun 17, 2022
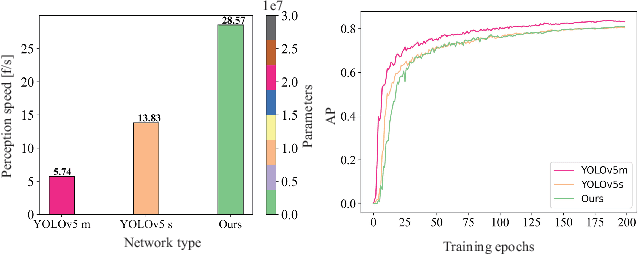
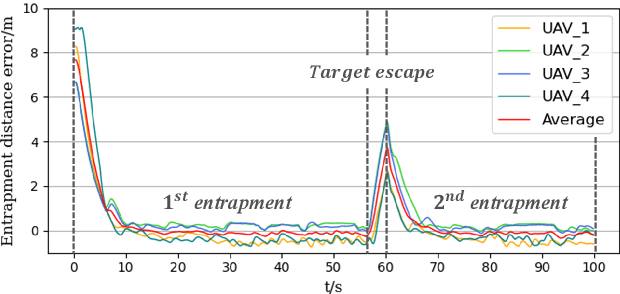

UAVs (Unmanned Aerial Vehicles) dynamic encirclement is an emerging field with great potential. Researchers often get inspirations from biological systems, either from macro-world like fish schools or bird flocks etc, or from micro-world like gene regulatory networks. However, most swarm control algorithms rely on centralized control, global information acquisition, or communication between neighboring agents. In this work, we propose a distributed swarm control method based purely on vision without any direct communications, in which swarm agents of e.g. UAVs can generate an entrapping pattern to encircle an escaping target of UAV based purly on their installed omnidirectional vision sensors. A finite-state-machine describing the behavior model of each individual drone is also designed so that a swarm of drones can accomplish searching and entrapping of the target collectively. We verify the effectiveness and efficiency of the proposed method in various simulation and real-world experiments.
A Computational Model for Logical Analysis of Data
Jul 12, 2022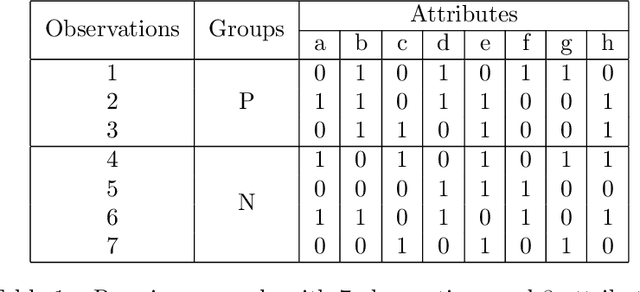
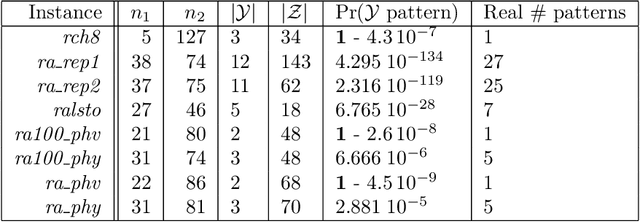
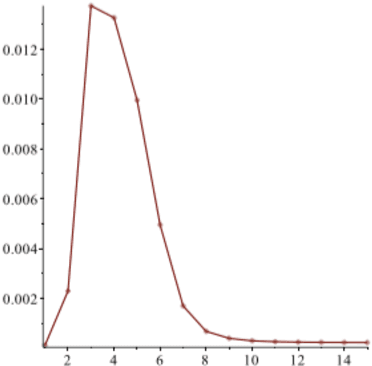
Initially introduced by Peter Hammer, Logical Analysis of Data is a methodology that aims at computing a logical justification for dividing a group of data in two groups of observations, usually called the positive and negative groups. Consider this partition into positive and negative groups as the description of a partially defined Boolean function; the data is then processed to identify a subset of attributes, whose values may be used to characterize the observations of the positive groups against those of the negative group. LAD constitutes an interesting rule-based learning alternative to classic statistical learning techniques and has many practical applications. Nevertheless, the computation of group characterization may be costly, depending on the properties of the data instances. A major aim of our work is to provide effective tools for speeding up the computations, by computing some \emph{a priori} probability that a given set of attributes does characterize the positive and negative groups. To this effect, we propose several models for representing the data set of observations, according to the information we have on it. These models, and the probabilities they allow us to compute, are also helpful for quickly assessing some properties of the real data at hand; furthermore they may help us to better analyze and understand the computational difficulties encountered by solving methods. Once our models have been established, the mathematical tools for computing probabilities come from Analytic Combinatorics. They allow us to express the desired probabilities as ratios of generating functions coefficients, which then provide a quick computation of their numerical values. A further, long-range goal of this paper is to show that the methods of Analytic Combinatorics can help in analyzing the performance of various algorithms in LAD and related fields.
Entropy-driven Sampling and Training Scheme for Conditional Diffusion Generation
Jun 23, 2022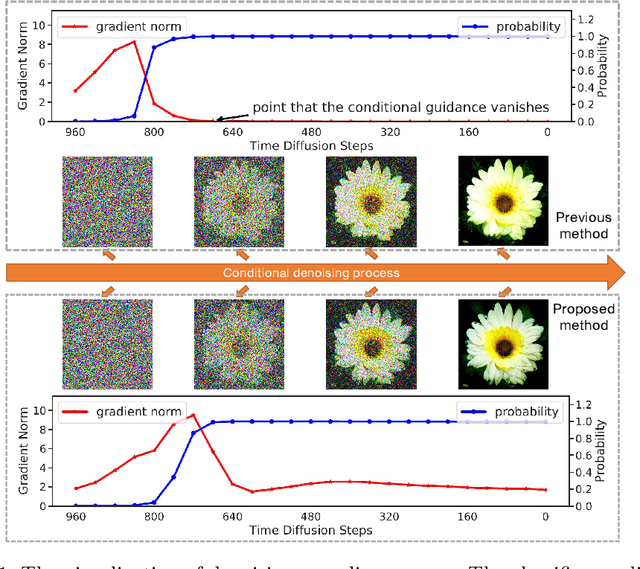
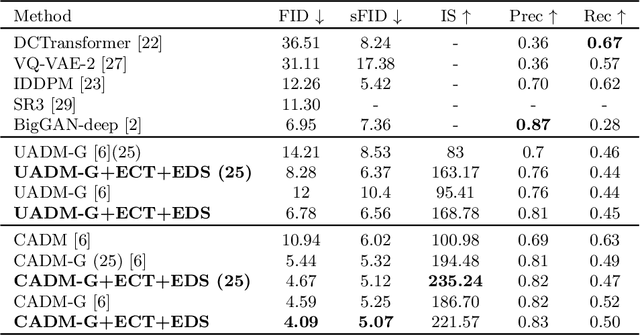
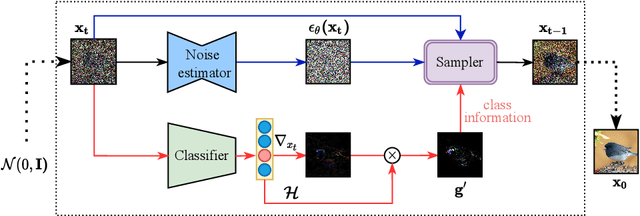
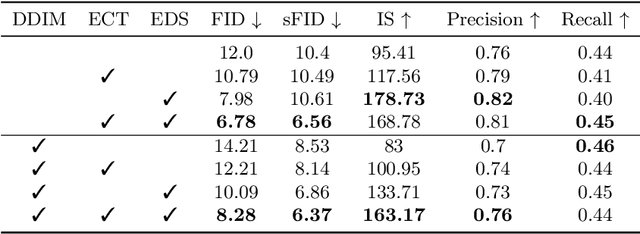
Denoising Diffusion Probabilistic Model (DDPM) is able to make flexible conditional image generation from prior noise to real data, by introducing an independent noise-aware classifier to provide conditional gradient guidance at each time step of denoising process. However, due to the ability of classifier to easily discriminate an incompletely generated image only with high-level structure, the gradient, which is a kind of class information guidance, tends to vanish early, leading to the collapse from conditional generation process into the unconditional process. To address this problem, we propose two simple but effective approaches from two perspectives. For sampling procedure, we introduce the entropy of predicted distribution as the measure of guidance vanishing level and propose an entropy-aware scaling method to adaptively recover the conditional semantic guidance. % for each generated sample. For training stage, we propose the entropy-aware optimization objectives to alleviate the overconfident prediction for noisy data.On ImageNet1000 256x256, with our proposed sampling scheme and trained classifier, the pretrained conditional and unconditional DDPM model can achieve 10.89% (4.59 to 4.09) and 43.5% (12 to 6.78) FID improvement respectively.
Hiding Your Signals: A Security Analysis of PPG-based Biometric Authentication
Jul 10, 2022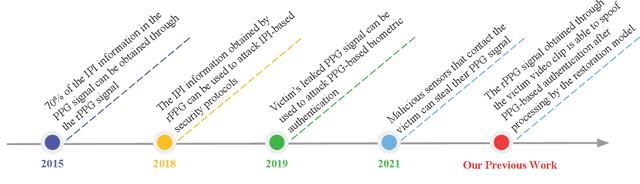
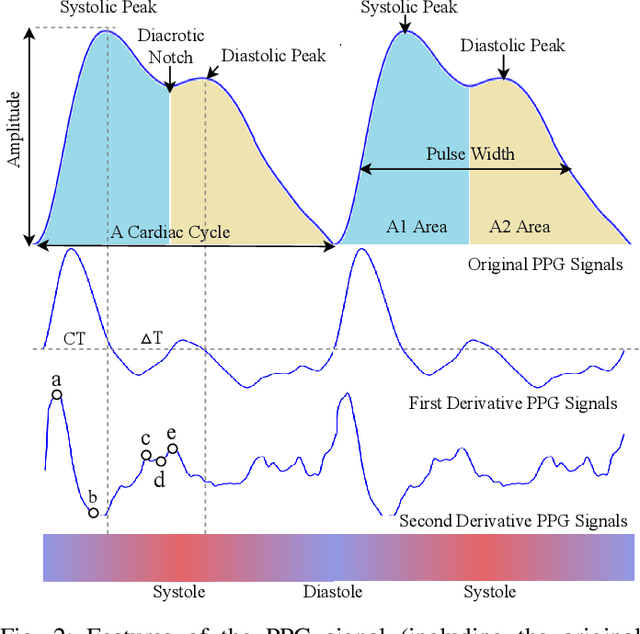
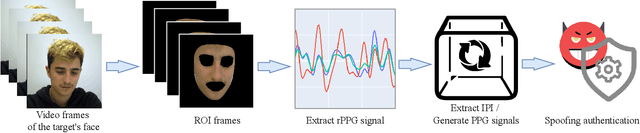
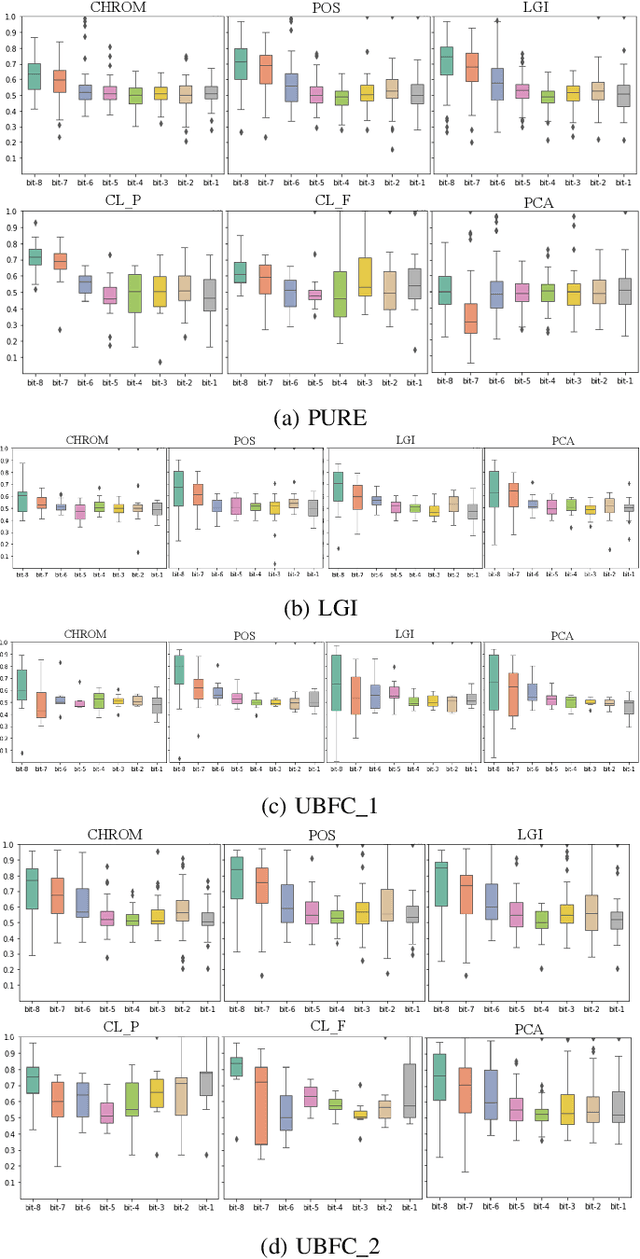
Recently, physiological signal-based biometric systems have received wide attention. Unlike traditional biometric features, physiological signals can not be easily compromised (usually unobservable to human eyes). Photoplethysmography (PPG) signal is easy to measure, making it more attractive than many other physiological signals for biometric authentication. However, with the advent of remote PPG (rPPG), unobservability has been challenged when the attacker can remotely steal the rPPG signals by monitoring the victim's face, subsequently posing a threat to PPG-based biometrics. In PPG-based biometric authentication, current attack approaches mandate the victim's PPG signal, making rPPG-based attacks neglected. In this paper, we firstly analyze the security of PPG-based biometrics, including user authentication and communication protocols. We evaluate the signal waveforms, heart rate and inter-pulse-interval information extracted by five rPPG methods, including four traditional optical computing methods (CHROM, POS, LGI, PCA) and one deep learning method (CL_rPPG). We conducted experiments on five datasets (PURE, UBFC_rPPG, UBFC_Phys, LGI_PPGI, and COHFACE) to collect a comprehensive set of results. Our empirical studies show that rPPG poses a serious threat to the authentication system. The success rate of the rPPG signal spoofing attack in the user authentication system reached 0.35. The bit hit rate is 0.6 in inter-pulse-interval-based security protocols. Further, we propose an active defence strategy to hide the physiological signals of the face to resist the attack. It reduces the success rate of rPPG spoofing attacks in user authentication to 0.05. The bit hit rate was reduced to 0.5, which is at the level of a random guess. Our strategy effectively prevents the exposure of PPG signals to protect users' sensitive physiological data.