 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Non-invasive Self-attention for Side Information Fusion in Sequential Recommendation
Mar 05, 2021
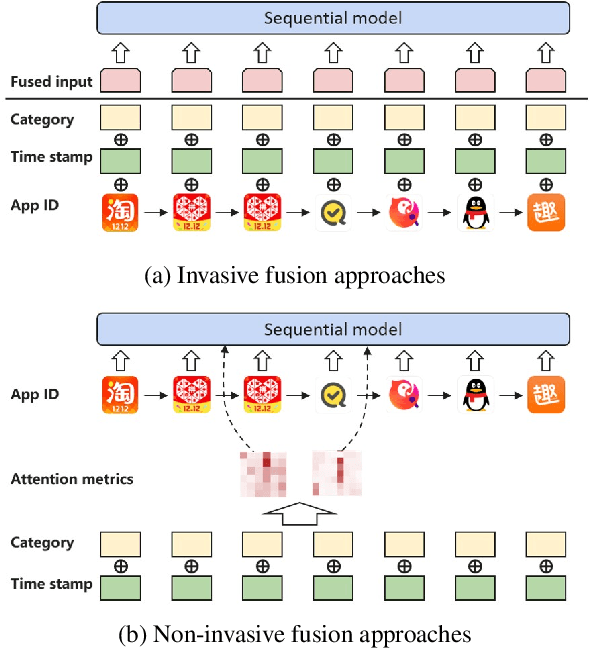


Sequential recommender systems aim to model users' evolving interests from their historical behaviors, and hence make customized time-relevant recommendations. Compared with traditional models, deep learning approaches such as CNN and RNN have achieved remarkable advancements in recommendation tasks. Recently, the BERT framework also emerges as a promising method, benefited from its self-attention mechanism in processing sequential data. However, one limitation of the original BERT framework is that it only considers one input source of the natural language tokens. It is still an open question to leverage various types of information under the BERT framework. Nonetheless, it is intuitively appealing to utilize other side information, such as item category or tag, for more comprehensive depictions and better recommendations. In our pilot experiments, we found naive approaches, which directly fuse types of side information into the item embeddings, usually bring very little or even negative effects. Therefore, in this paper, we propose the NOninVasive self-attention mechanism (NOVA) to leverage side information effectively under the BERT framework. NOVA makes use of side information to generate better attention distribution, rather than directly altering the item embedding, which may cause information overwhelming. We validate the NOVA-BERT model on both public and commercial datasets, and our method can stably outperform the state-of-the-art models with negligible computational overheads.
Light Field Raindrop Removal via 4D Re-sampling
May 26, 2022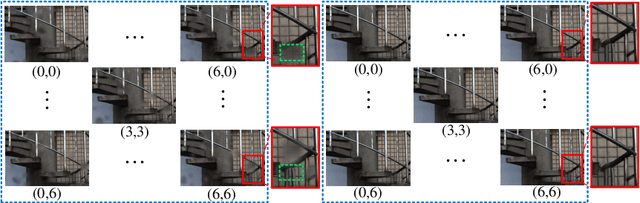


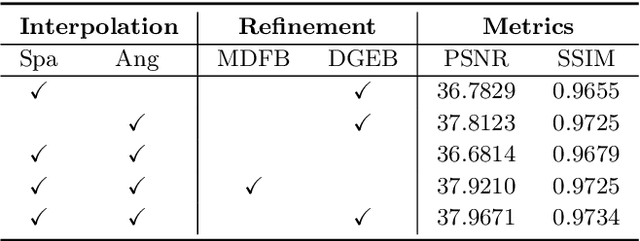
The Light Field Raindrop Removal (LFRR) aims to restore the background areas obscured by raindrops in the Light Field (LF). Compared with single image, the LF provides more abundant information by regularly and densely sampling the scene. Since raindrops have larger disparities than the background in the LF, the majority of texture details occluded by raindrops are visible in other views. In this paper, we propose a novel LFRR network by directly utilizing the complementary pixel information of raindrop-free areas in the input raindrop LF, which consists of the re-sampling module and the refinement module. Specifically, the re-sampling module generates a new LF which is less polluted by raindrops through re-sampling position predictions and the proposed 4D interpolation. The refinement module improves the restoration of the completely occluded background areas and corrects the pixel error caused by 4D interpolation. Furthermore, we carefully build the first real scene LFRR dataset for model training and validation. Experiments demonstrate that the proposed method can effectively remove raindrops and achieves state-of-the-art performance in both background restoration and view consistency maintenance.
Data-aided Active User Detection with a User Activity Extraction Network for Grant-free SCMA Systems
May 22, 2022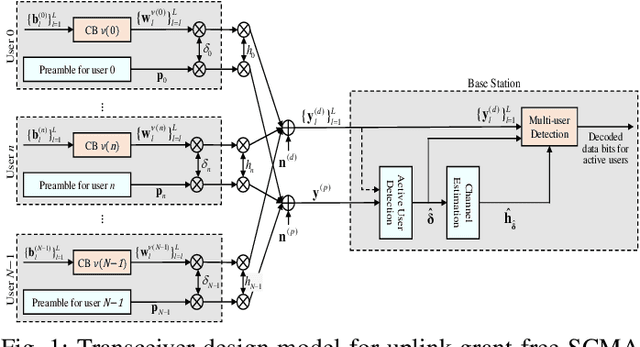
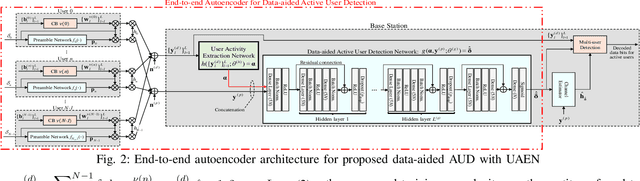
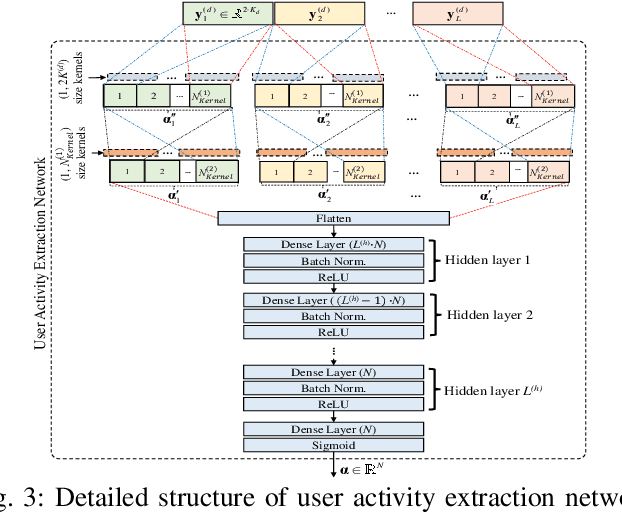
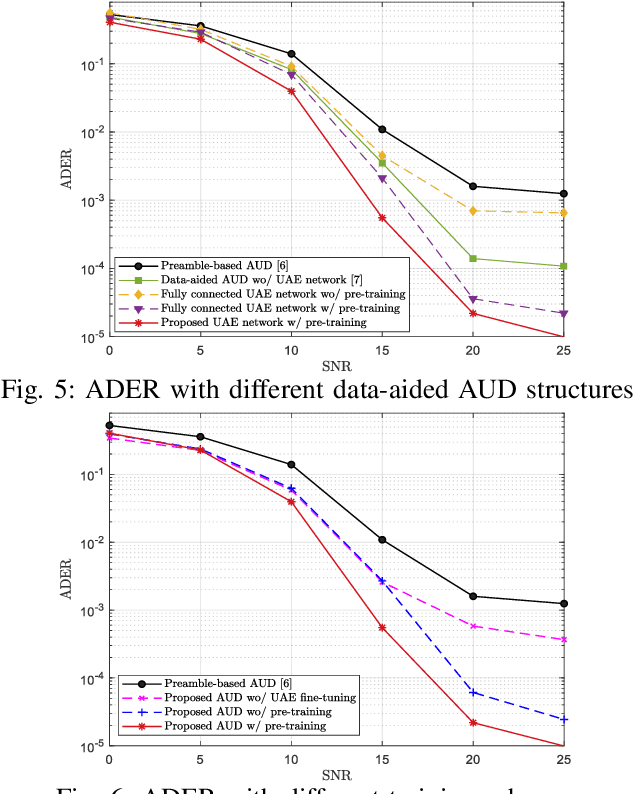
In grant-free sparse code multiple access system, joint optimization of contention resources for users and active user detection (AUD) at the receiver is a complex combinatorial problem. To this end, we propose a deep learning-based data-aided AUD scheme which extracts a priori user activity information via a novel user activity extraction network (UAEN). This is enabled by an end-to-end training of an autoencoder (AE), which simultaneously optimizes the contention resources, i.e., preamble sequences, each associated with one of the codebooks, and extraction of user activity information from both preamble and data transmission. Furthermore, we propose self-supervised pre-training scheme for the UAEN, which ensures the convergence of offline end-to-end training. Simulation results demonstrated that the proposed AUD scheme achieved 3 to 5dB gain at a target activity detection error rate of ${{10}^{-3}}$ compared to the state-of-the-art DL-based AUD schemes.
Set Norm and Equivariant Skip Connections: Putting the Deep in Deep Sets
Jun 23, 2022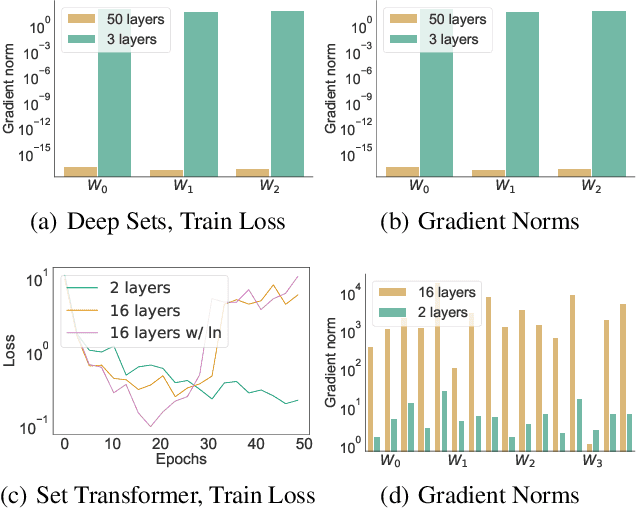
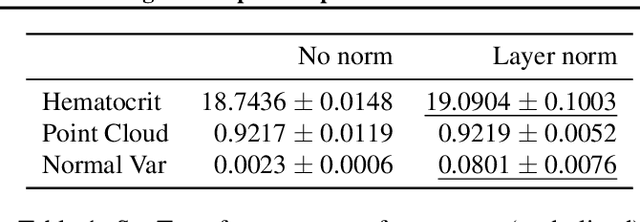
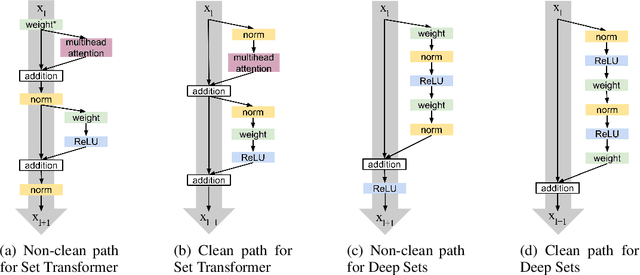
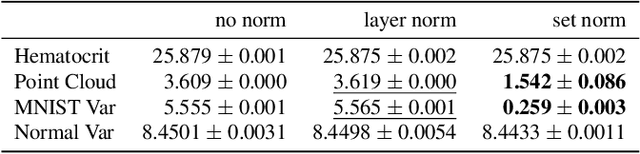
Permutation invariant neural networks are a promising tool for making predictions from sets. However, we show that existing permutation invariant architectures, Deep Sets and Set Transformer, can suffer from vanishing or exploding gradients when they are deep. Additionally, layer norm, the normalization of choice in Set Transformer, can hurt performance by removing information useful for prediction. To address these issues, we introduce the clean path principle for equivariant residual connections and develop set norm, a normalization tailored for sets. With these, we build Deep Sets++ and Set Transformer++, models that reach high depths with comparable or better performance than their original counterparts on a diverse suite of tasks. We additionally introduce Flow-RBC, a new single-cell dataset and real-world application of permutation invariant prediction. We open-source our data and code here: https://github.com/rajesh-lab/deep_permutation_invariant.
Multi-scale Network with Attentional Multi-resolution Fusion for Point Cloud Semantic Segmentation
Jun 27, 2022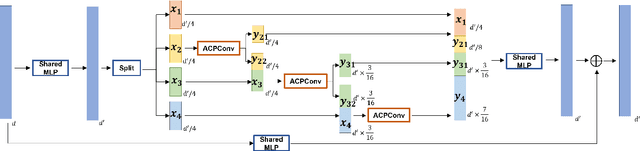
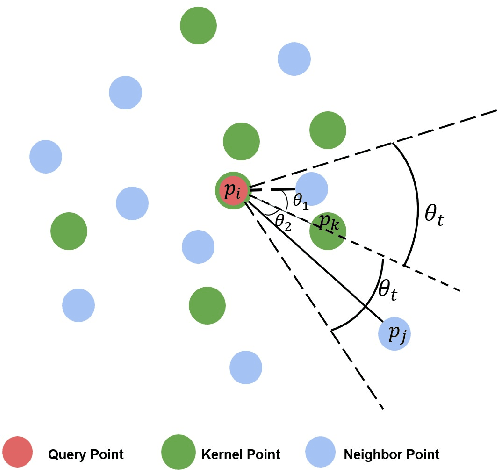
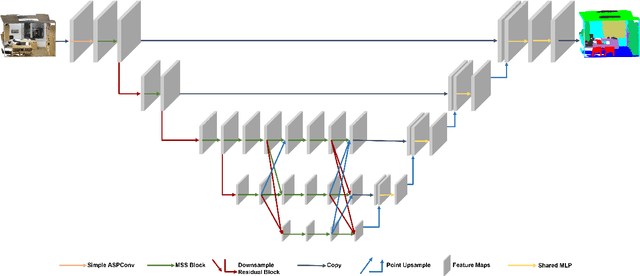
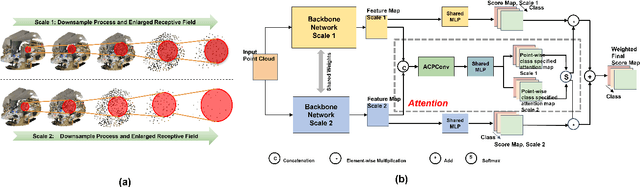
In this paper, we present a comprehensive point cloud semantic segmentation network that aggregates both local and global multi-scale information. First, we propose an Angle Correlation Point Convolution (ACPConv) module to effectively learn the local shapes of points. Second, based upon ACPConv, we introduce a local multi-scale split (MSS) block that hierarchically connects features within one single block and gradually enlarges the receptive field which is beneficial for exploiting the local context. Third, inspired by HRNet which has excellent performance on 2D image vision tasks, we build an HRNet customized for point cloud to learn global multi-scale context. Lastly, we introduce a point-wise attention fusion approach that fuses multi-resolution predictions and further improves point cloud semantic segmentation performance. Our experimental results and ablations on several benchmark datasets show that our proposed method is effective and able to achieve state-of-the-art performances compared to existing methods.
Time-aware Dynamic Graph Embedding for Asynchronous Structural Evolution
Jul 01, 2022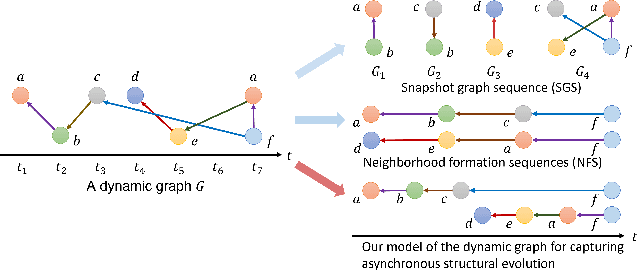

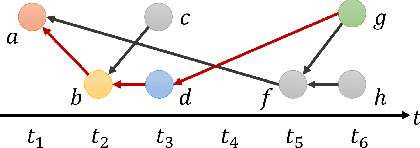
Dynamic graphs refer to graphs whose structure dynamically changes over time. Despite the benefits of learning vertex representations (i.e., embeddings) for dynamic graphs, existing works merely view a dynamic graph as a sequence of changes within the vertex connections, neglecting the crucial asynchronous nature of such dynamics where the evolution of each local structure starts at different times and lasts for various durations. To maintain asynchronous structural evolutions within the graph, we innovatively formulate dynamic graphs as temporal edge sequences associated with joining time of vertices (ToV) and timespan of edges (ToE). Then, a time-aware Transformer is proposed to embed vertices' dynamic connections and ToEs into the learned vertex representations. Meanwhile, we treat each edge sequence as a whole and embed its ToV of the first vertex to further encode the time-sensitive information. Extensive evaluations on several datasets show that our approach outperforms the state-of-the-art in a wide range of graph mining tasks. At the same time, it is very efficient and scalable for embedding large-scale dynamic graphs.
Information-Preserving Contrastive Learning for Self-Supervised Representations
Dec 17, 2020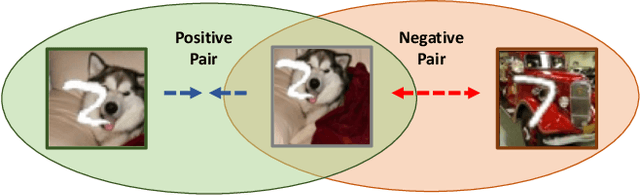
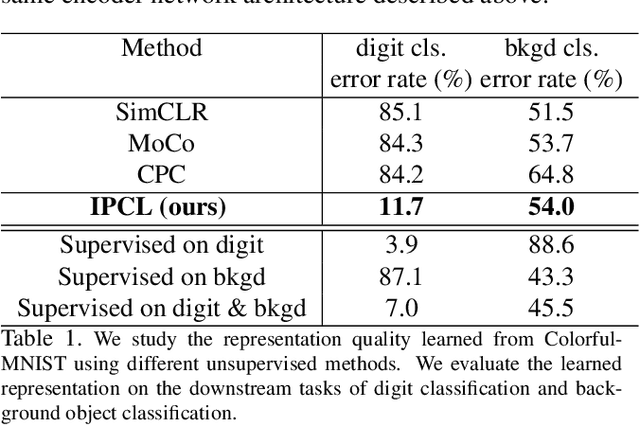
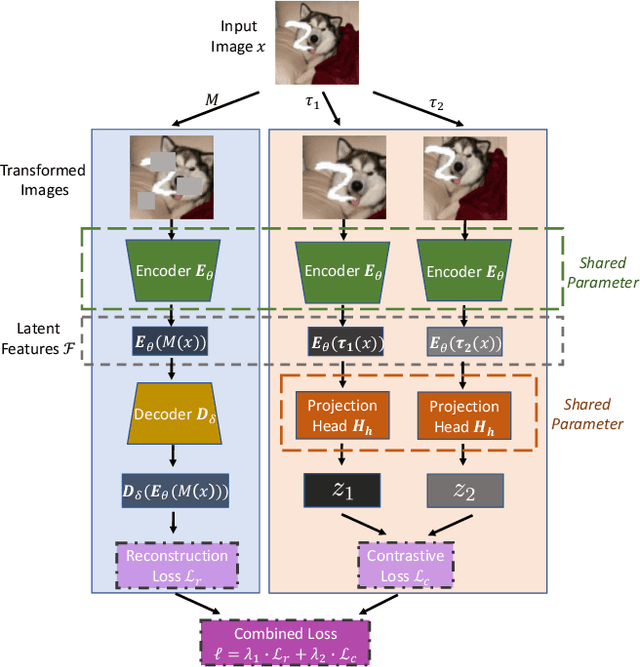
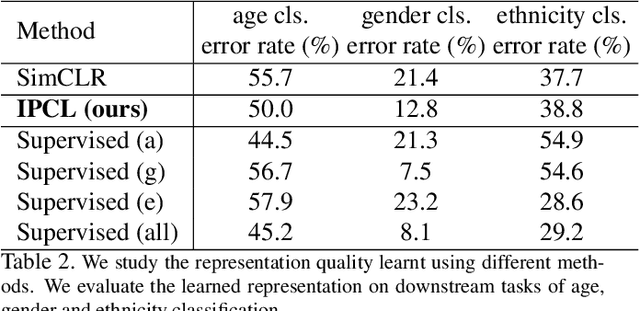
Contrastive learning is very effective at learning useful representations without supervision. Yet contrastive learning has its limitations. It can learn a shortcut that is irrelevant to the downstream task, and discard relevant information. Past work has addressed this limitation via custom data augmentations that eliminate the shortcut. This solution however does not work for data modalities that are not interpretable by humans, e.g., radio signals. For such modalities, it is hard for a human to guess which shortcuts may exist in the signal, or how to alter the radio signals to eliminate the shortcuts. Even for visual data, sometimes eliminating the shortcut may be undesirable. The shortcut may be irrelevant to one downstream task but important to another. In this case, it is desirable to learn a representation that captures both the shortcut information and the information relevant to the other downstream task. This paper presents information-preserving contrastive learning (IPCL), a new framework for unsupervised representation learning that preserves relevant information even in the presence of shortcuts. We empirically show that IPCL addresses the above problems and outperforms contrastive learning on radio signals and learning RGB data representation with different features that support different downstream tasks.
Ptychographic reconstruction with wavefront initialization
May 22, 2022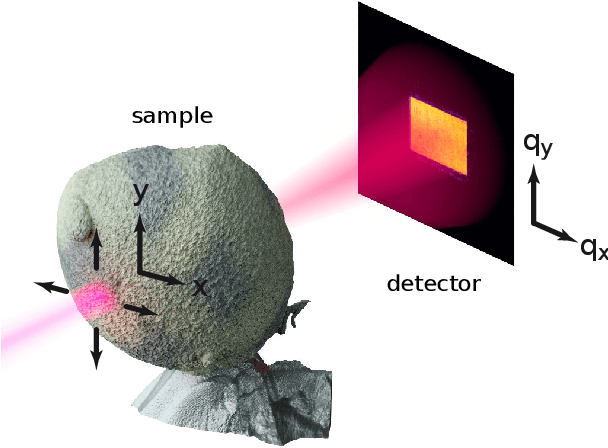
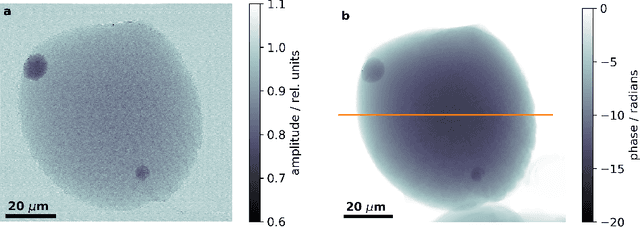
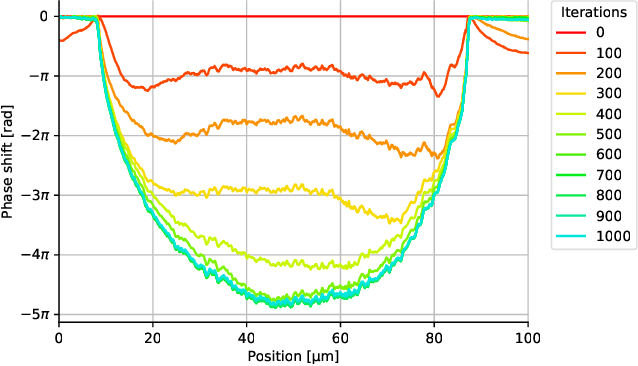

X-ray ptychography is a cutting edge imaging technique providing ultra-high spatial resolutions. In ptychography, phase retrieval, i.e., the recovery of a complex valued signal from intensity-only measurements, is enabled by exploiting a redundancy of information contained in diffraction patterns measured with overlapping illuminations. For samples that are considerably larger than the probe we show that during the iteration the bulk information has to propagate from the sample edges to the center. This constitutes an inherent limitation of reconstruction speed for algorithms that use a flat initialization. Here, we experimentally demonstrate that a considerable improvement of computational speed can be achieved by utilizing a low resolution sample wavefront retrieved from measured diffraction patterns as initialization. In addition, we show that this approach avoids phase singularity artifacts due to strong phase gradients. Wavefront initialization is computationally fast and compatible with non-bulky samples. Therefore, the presented approach is readily adaptable with established ptychographic reconstruction algorithms implying a wide spread use.
Agent with Tangent-based Formulation and Anatomical Perception for Standard Plane Localization in 3D Ultrasound
Jul 01, 2022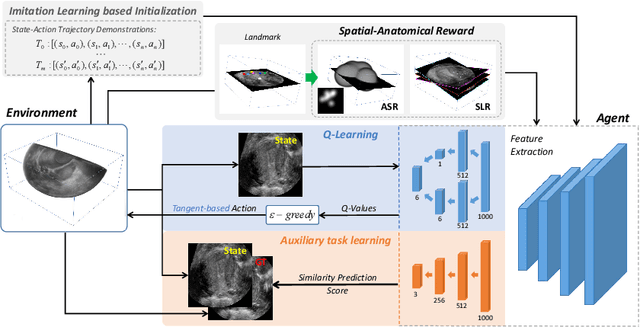
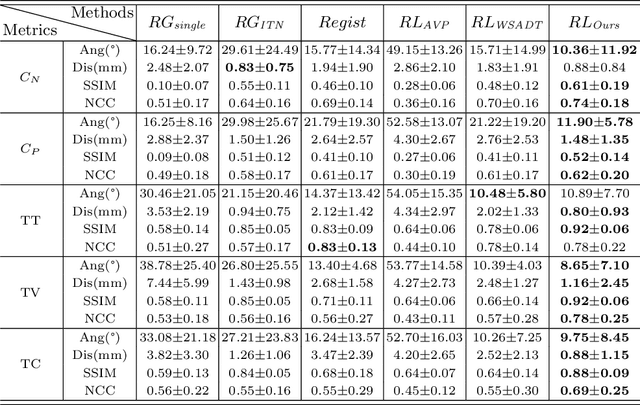
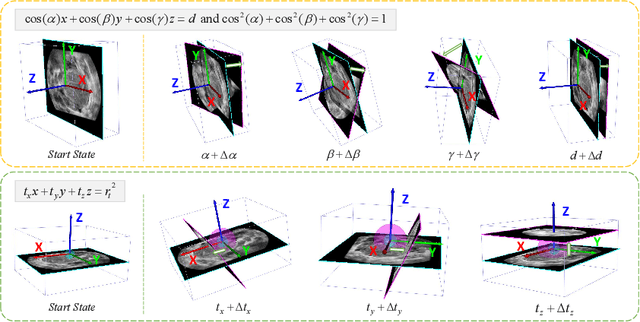
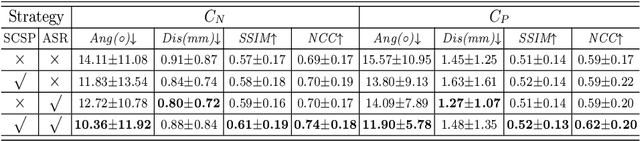
Standard plane (SP) localization is essential in routine clinical ultrasound (US) diagnosis. Compared to 2D US, 3D US can acquire multiple view planes in one scan and provide complete anatomy with the addition of coronal plane. However, manually navigating SPs in 3D US is laborious and biased due to the orientation variability and huge search space. In this study, we introduce a novel reinforcement learning (RL) framework for automatic SP localization in 3D US. Our contribution is three-fold. First, we formulate SP localization in 3D US as a tangent-point-based problem in RL to restructure the action space and significantly reduce the search space. Second, we design an auxiliary task learning strategy to enhance the model's ability to recognize subtle differences crossing Non-SPs and SPs in plane search. Finally, we propose a spatial-anatomical reward to effectively guide learning trajectories by exploiting spatial and anatomical information simultaneously. We explore the efficacy of our approach on localizing four SPs on uterus and fetal brain datasets. The experiments indicate that our approach achieves a high localization accuracy as well as robust performance.
Modeling Beats and Downbeats with a Time-Frequency Transformer
May 29, 2022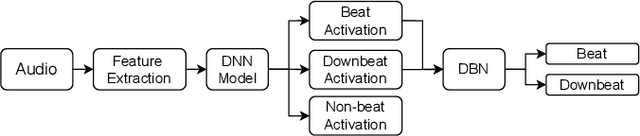
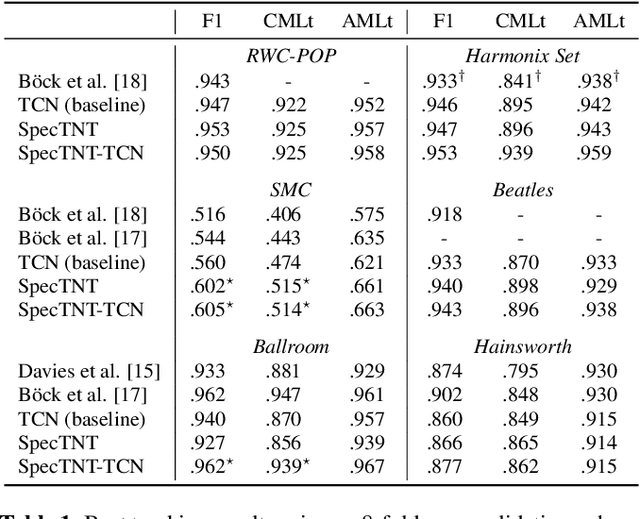
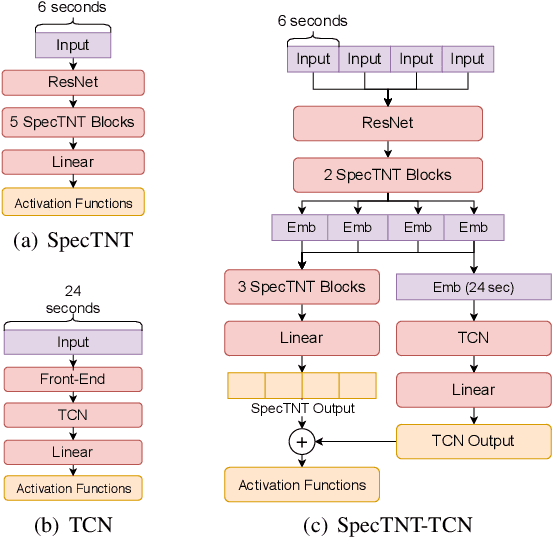
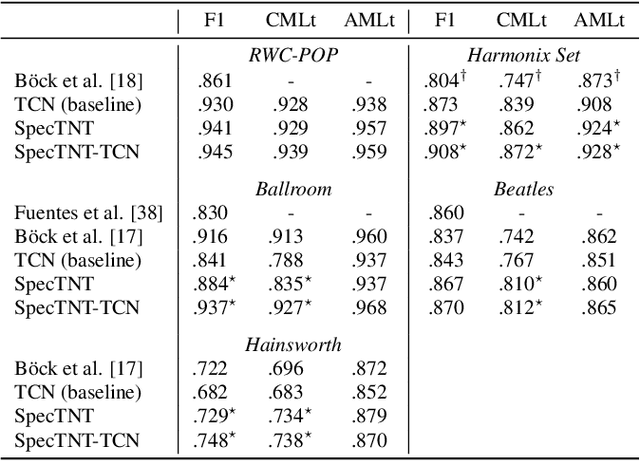
Transformer is a successful deep neural network (DNN) architecture that has shown its versatility not only in natural language processing but also in music information retrieval (MIR). In this paper, we present a novel Transformer-based approach to tackle beat and downbeat tracking. This approach employs SpecTNT (Spectral-Temporal Transformer in Transformer), a variant of Transformer that models both spectral and temporal dimensions of a time-frequency input of music audio. A SpecTNT model uses a stack of blocks, where each consists of two levels of Transformer encoders. The lower-level (or spectral) encoder handles the spectral features and enables the model to pay attention to harmonic components of each frame. Since downbeats indicate bar boundaries and are often accompanied by harmonic changes, this step may help downbeat modeling. The upper-level (or temporal) encoder aggregates useful local spectral information to pay attention to beat/downbeat positions. We also propose an architecture that combines SpecTNT with a state-of-the-art model, Temporal Convolutional Networks (TCN), to further improve the performance. Extensive experiments demonstrate that our approach can significantly outperform TCN in downbeat tracking while maintaining comparable result in beat tracking.