 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information-theoretic Classification Accuracy: A Criterion that Guides Data-driven Combination of Ambiguous Outcome Labels in Multi-class Classification
Sep 17, 2021
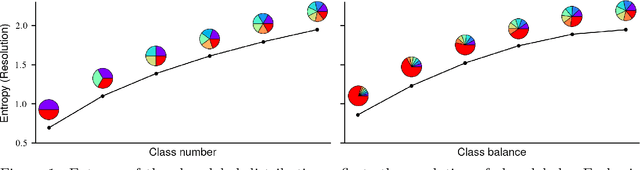
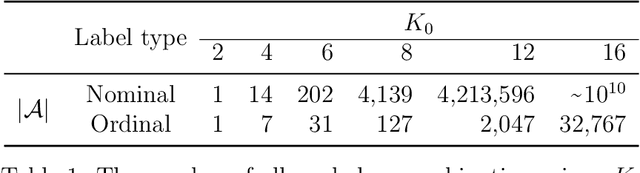
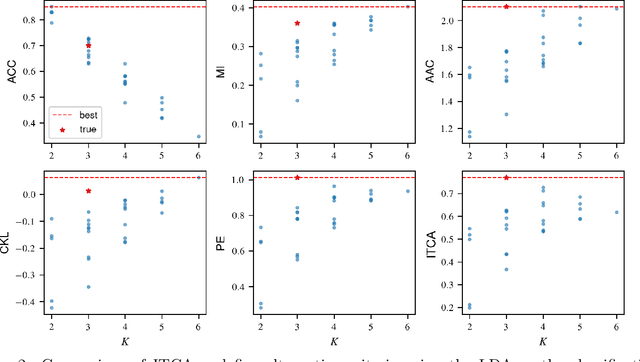
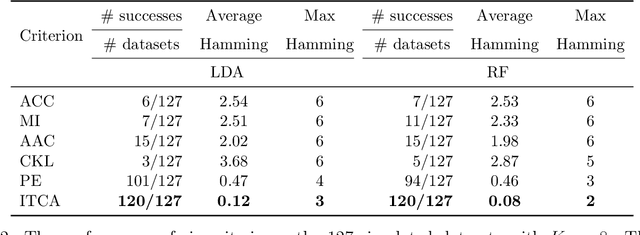
Outcome labeling ambiguity and subjectivity are ubiquitous in real-world datasets. While practitioners commonly combine ambiguous outcome labels in an ad hoc way to improve the accuracy of multi-class classification, there lacks a principled approach to guide label combination by any optimality criterion. To address this problem, we propose the information-theoretic classification accuracy (ITCA), a criterion of outcome "information" conditional on outcome prediction, to guide practitioners on how to combine ambiguous outcome labels. ITCA indicates a balance in the trade-off between prediction accuracy (how well do predicted labels agree with actual labels) and prediction resolution (how many labels are predictable). To find the optimal label combination indicated by ITCA, we develop two search strategies: greedy search and breadth-first search. Notably, ITCA and the two search strategies are adaptive to all machine-learning classification algorithms. Coupled with a classification algorithm and a search strategy, ITCA has two uses: to improve prediction accuracy and to identify ambiguous labels. We first verify that ITCA achieves high accuracy with both search strategies in finding the correct label combinations on synthetic and real data. Then we demonstrate the effectiveness of ITCA in diverse applications including medical prognosis, cancer survival prediction, user demographics prediction, and cell type classification.
AI-based Clinical Assessment of Optic Nerve Head Robustness Superseding Biomechanical Testing
Jun 09, 2022
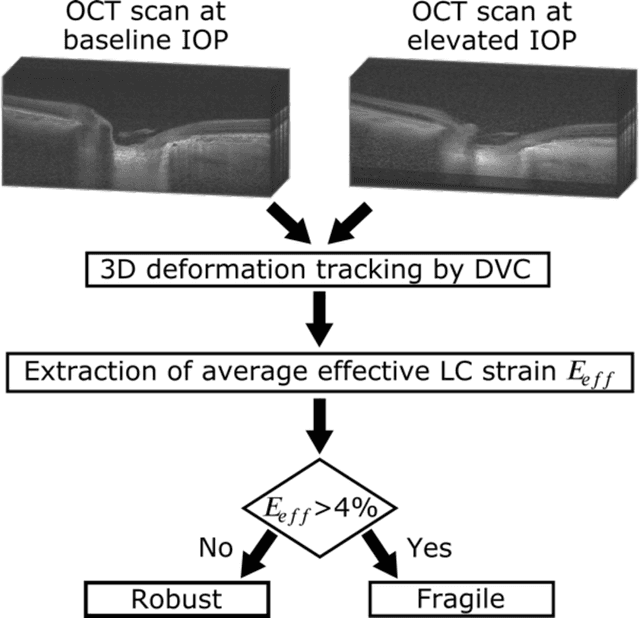
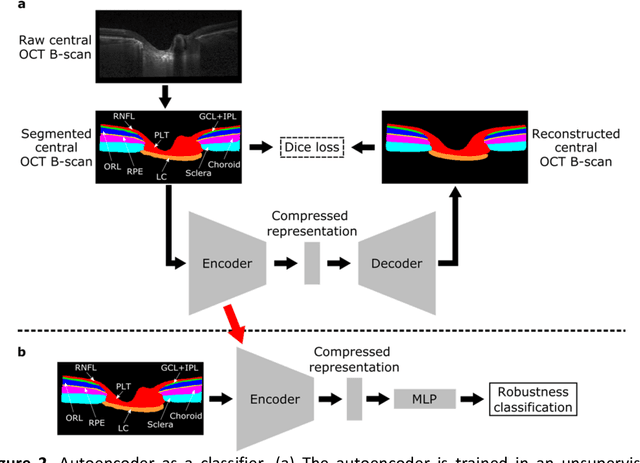
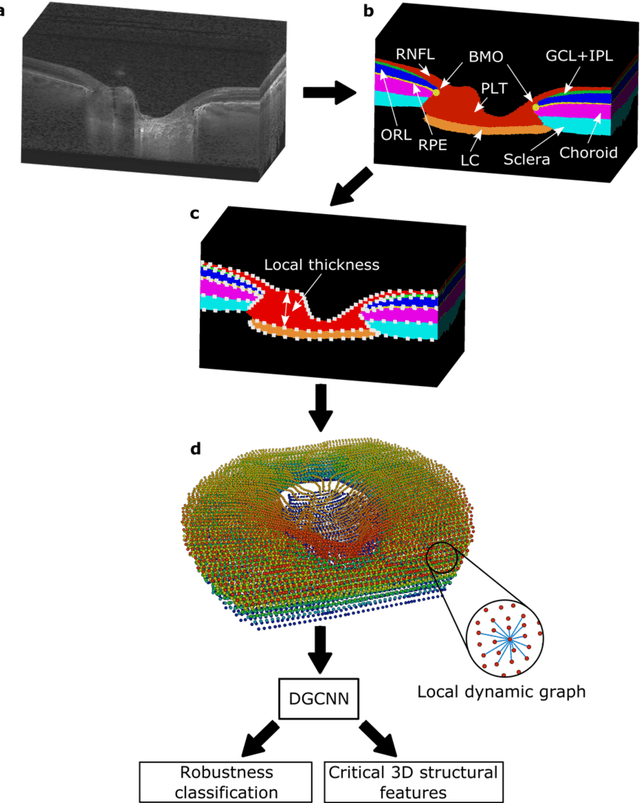
$\mathbf{Purpose}$: To use artificial intelligence (AI) to: (1) exploit biomechanical knowledge of the optic nerve head (ONH) from a relatively large population; (2) assess ONH robustness from a single optical coherence tomography (OCT) scan of the ONH; (3) identify what critical three-dimensional (3D) structural features make a given ONH robust. $\mathbf{Design}$: Retrospective cross-sectional study. $\mathbf{Methods}$: 316 subjects had their ONHs imaged with OCT before and after acute intraocular pressure (IOP) elevation through ophthalmo-dynamometry. IOP-induced lamina-cribrosa deformations were then mapped in 3D and used to classify ONHs. Those with LC deformations superior to 4% were considered fragile, while those with deformations inferior to 4% robust. Learning from these data, we compared three AI algorithms to predict ONH robustness strictly from a baseline (undeformed) OCT volume: (1) a random forest classifier; (2) an autoencoder; and (3) a dynamic graph CNN (DGCNN). The latter algorithm also allowed us to identify what critical 3D structural features make a given ONH robust. $\mathbf{Results}$: All 3 methods were able to predict ONH robustness from 3D structural information alone and without the need to perform biomechanical testing. The DGCNN (area under the receiver operating curve [AUC]: 0.76 $\pm$ 0.08) outperformed the autoencoder (AUC: 0.70 $\pm$ 0.07) and the random forest classifier (AUC: 0.69 $\pm$ 0.05). Interestingly, to assess ONH robustness, the DGCNN mainly used information from the scleral canal and the LC insertion sites. $\mathbf{Conclusions}$: We propose an AI-driven approach that can assess the robustness of a given ONH solely from a single OCT scan of the ONH, and without the need to perform biomechanical testing. Longitudinal studies should establish whether ONH robustness could help us identify fast visual field loss progressors.
Comparison of Speech Representations for the MOS Prediction System
Jun 28, 2022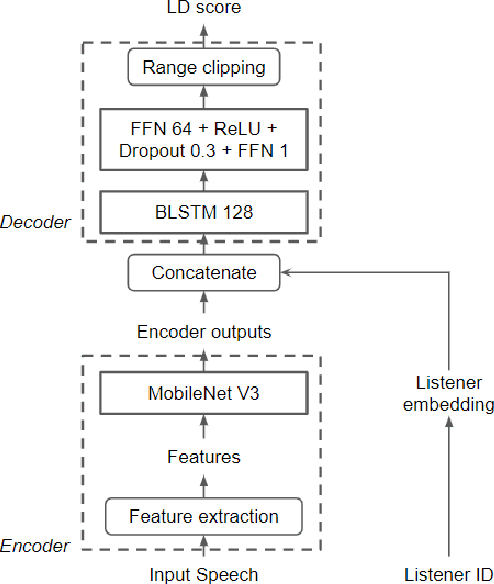
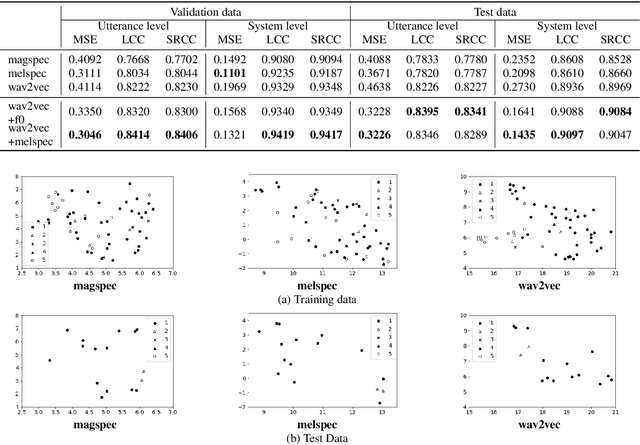
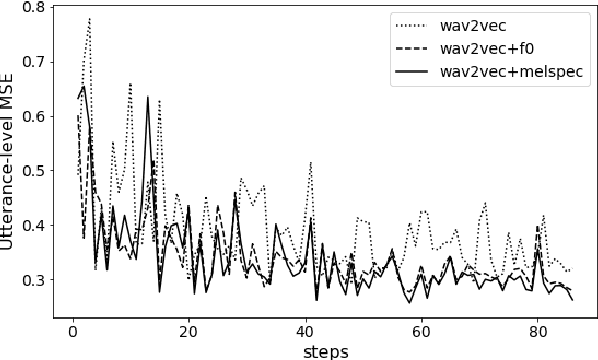
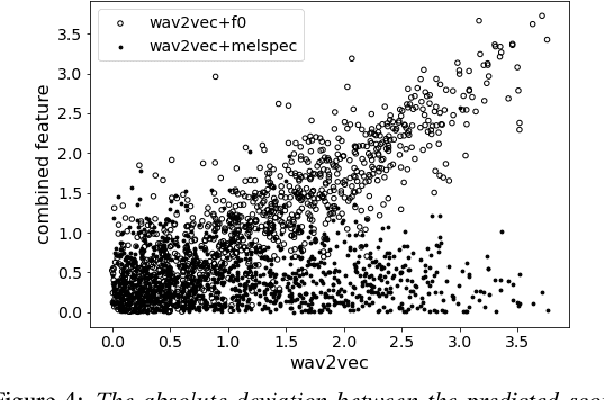
Automatic methods to predict Mean Opinion Score (MOS) of listeners have been researched to assure the quality of Text-to-Speech systems. Many previous studies focus on architectural advances (e.g. MBNet, LDNet, etc.) to capture relations between spectral features and MOS in a more effective way and achieved high accuracy. However, the optimal representation in terms of generalization capability still largely remains unknown. To this end, we compare the performance of Self-Supervised Learning (SSL) features obtained by the wav2vec framework to that of spectral features such as magnitude of spectrogram and melspectrogram. Moreover, we propose to combine the SSL features and features which we believe to retain essential information to the automatic MOS to compensate each other for their drawbacks. We conduct comprehensive experiments on a large-scale listening test corpus collected from past Blizzard and Voice Conversion Challenges. We found that the wav2vec feature set showed the best generalization even though the given ground-truth was not always reliable. Furthermore, we found that the combinations performed the best and analyzed how they bridged the gap between spectral and the wav2vec feature sets.
BiTAT: Neural Network Binarization with Task-dependent Aggregated Transformation
Jul 04, 2022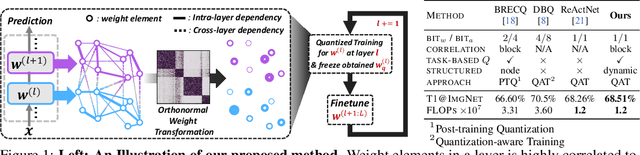
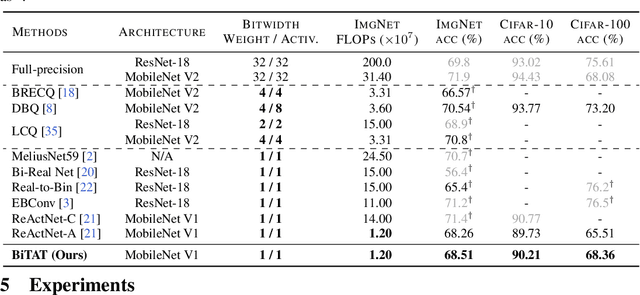
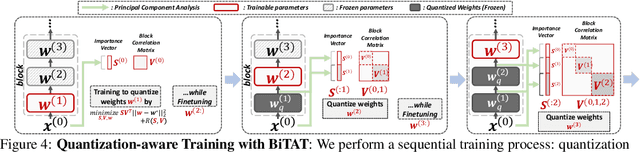
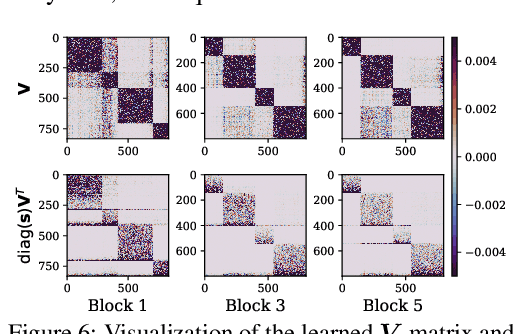
Neural network quantization aims to transform high-precision weights and activations of a given neural network into low-precision weights/activations for reduced memory usage and computation, while preserving the performance of the original model. However, extreme quantization (1-bit weight/1-bit activations) of compactly-designed backbone architectures (e.g., MobileNets) often used for edge-device deployments results in severe performance degeneration. This paper proposes a novel Quantization-Aware Training (QAT) method that can effectively alleviate performance degeneration even with extreme quantization by focusing on the inter-weight dependencies, between the weights within each layer and across consecutive layers. To minimize the quantization impact of each weight on others, we perform an orthonormal transformation of the weights at each layer by training an input-dependent correlation matrix and importance vector, such that each weight is disentangled from the others. Then, we quantize the weights based on their importance to minimize the loss of the information from the original weights/activations. We further perform progressive layer-wise quantization from the bottom layer to the top, so that quantization at each layer reflects the quantized distributions of weights and activations at previous layers. We validate the effectiveness of our method on various benchmark datasets against strong neural quantization baselines, demonstrating that it alleviates the performance degeneration on ImageNet and successfully preserves the full-precision model performance on CIFAR-100 with compact backbone networks.
Interaction-Grounded Learning with Action-inclusive Feedback
Jun 16, 2022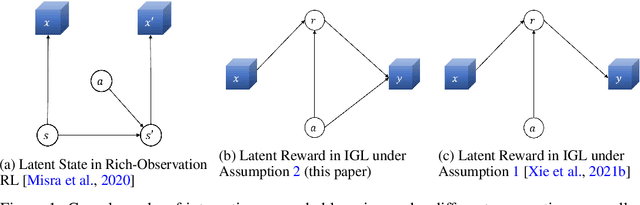

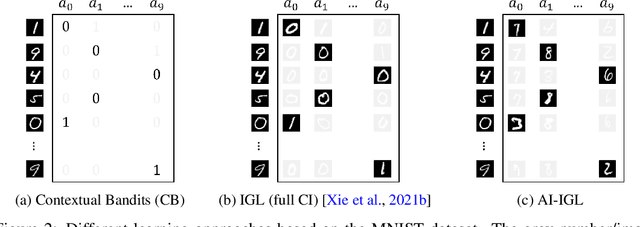

Consider the problem setting of Interaction-Grounded Learning (IGL), in which a learner's goal is to optimally interact with the environment with no explicit reward to ground its policies. The agent observes a context vector, takes an action, and receives a feedback vector, using this information to effectively optimize a policy with respect to a latent reward function. Prior analyzed approaches fail when the feedback vector contains the action, which significantly limits IGL's success in many potential scenarios such as Brain-computer interface (BCI) or Human-computer interface (HCI) applications. We address this by creating an algorithm and analysis which allows IGL to work even when the feedback vector contains the action, encoded in any fashion. We provide theoretical guarantees and large-scale experiments based on supervised datasets to demonstrate the effectiveness of the new approach.
Transfer Meta-Learning: Information-Theoretic Bounds and Information Meta-Risk Minimization
Nov 06, 2020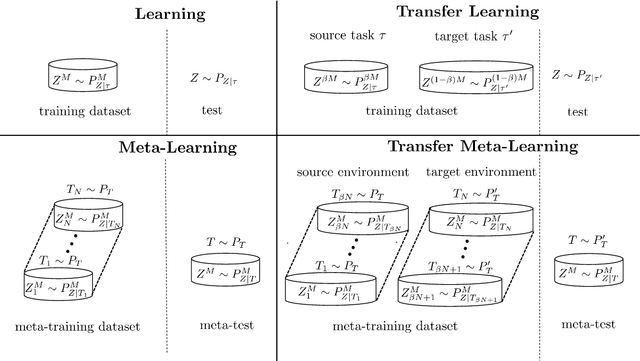
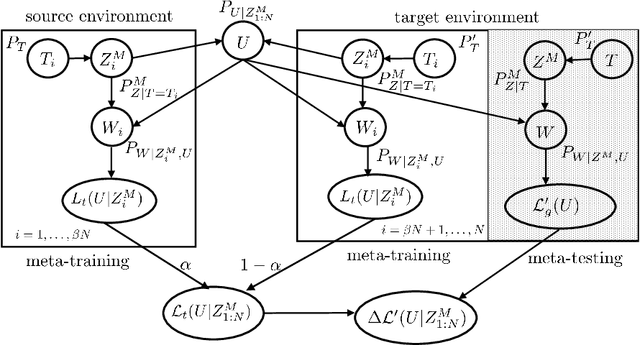
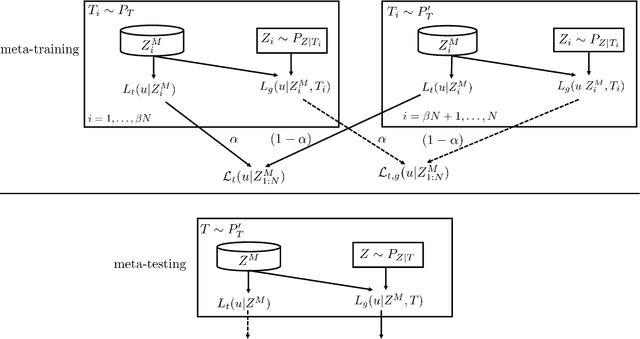
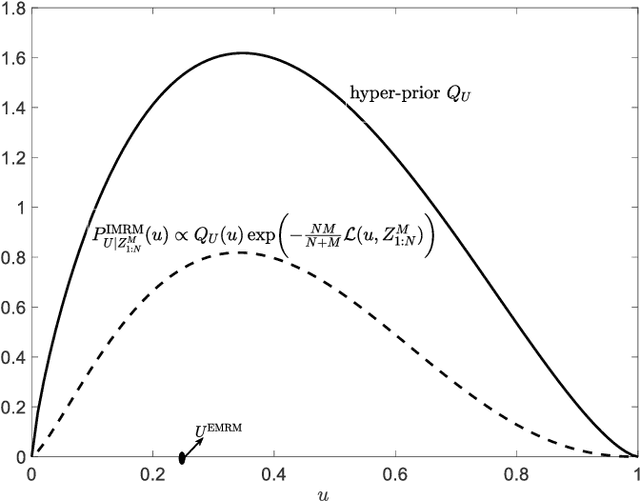
Meta-learning automatically infers an inductive bias by observing data from a number of related tasks. The inductive bias is encoded by hyperparameters that determine aspects of the model class or training algorithm, such as initialization or learning rate. Meta-learning assumes that the learning tasks belong to a task environment, and that tasks are drawn from the same task environment both during meta-training and meta-testing. This, however, may not hold true in practice. In this paper, we introduce the problem of transfer meta-learning, in which tasks are drawn from a target task environment during meta-testing that may differ from the source task environment observed during meta-training. Novel information-theoretic upper bounds are obtained on the transfer meta-generalization gap, which measures the difference between the meta-training loss, available at the meta-learner, and the average loss on meta-test data from a new, randomly selected, task in the target task environment. The first bound, on the average transfer meta-generalization gap, captures the meta-environment shift between source and target task environments via the KL divergence between source and target data distributions. The second, PAC-Bayesian bound, and the third, single-draw bound, account for this shift via the log-likelihood ratio between source and target task distributions. Furthermore, two transfer meta-learning solutions are introduced. For the first, termed Empirical Meta-Risk Minimization (EMRM), we derive bounds on the average optimality gap. The second, referred to as Information Meta-Risk Minimization (IMRM), is obtained by minimizing the PAC-Bayesian bound. IMRM is shown via experiments to potentially outperform EMRM.
Towards Understanding How Machines Can Learn Causal Overhypotheses
Jun 16, 2022
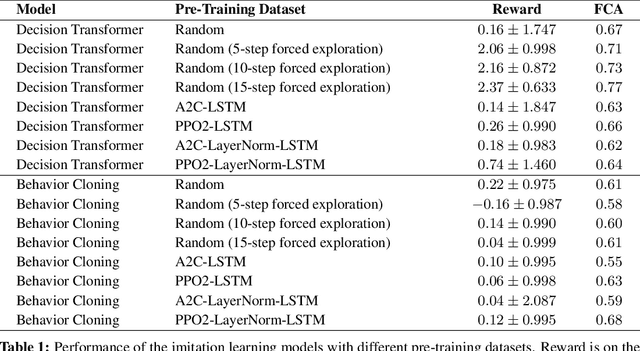

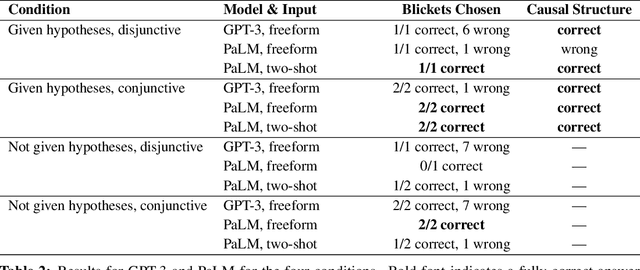
Recent work in machine learning and cognitive science has suggested that understanding causal information is essential to the development of intelligence. The extensive literature in cognitive science using the ``blicket detector'' environment shows that children are adept at many kinds of causal inference and learning. We propose to adapt that environment for machine learning agents. One of the key challenges for current machine learning algorithms is modeling and understanding causal overhypotheses: transferable abstract hypotheses about sets of causal relationships. In contrast, even young children spontaneously learn and use causal overhypotheses. In this work, we present a new benchmark -- a flexible environment which allows for the evaluation of existing techniques under variable causal overhypotheses -- and demonstrate that many existing state-of-the-art methods have trouble generalizing in this environment. The code and resources for this benchmark are available at https://github.com/CannyLab/casual_overhypotheses.
Conversations Are Not Flat: Modeling the Dynamic Information Flow across Dialogue Utterances
Jun 04, 2021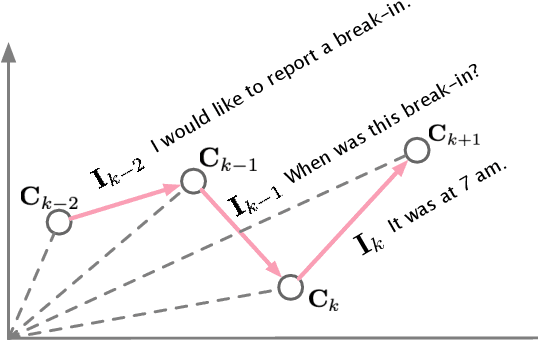
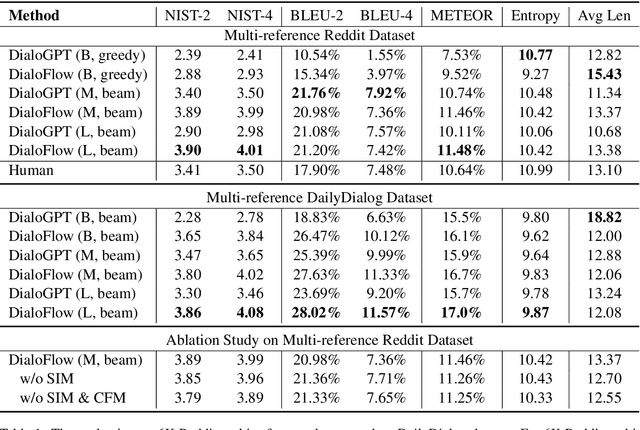
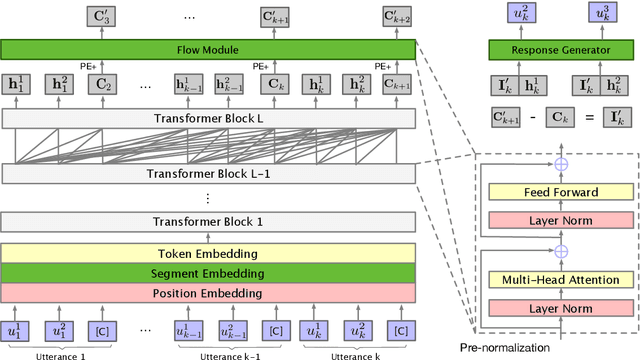
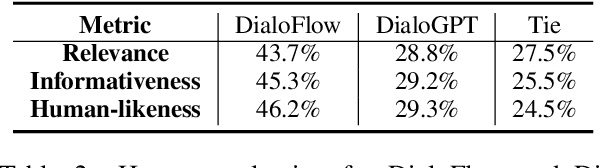
Nowadays, open-domain dialogue models can generate acceptable responses according to the historical context based on the large-scale pre-trained language models. However, they generally concatenate the dialogue history directly as the model input to predict the response, which we named as the flat pattern and ignores the dynamic information flow across dialogue utterances. In this work, we propose the DialoFlow model, in which we introduce a dynamic flow mechanism to model the context flow, and design three training objectives to capture the information dynamics across dialogue utterances by addressing the semantic influence brought about by each utterance in large-scale pre-training. Experiments on the multi-reference Reddit Dataset and DailyDialog Dataset demonstrate that our DialoFlow significantly outperforms the DialoGPT on the dialogue generation task. Besides, we propose the Flow score, an effective automatic metric for evaluating interactive human-bot conversation quality based on the pre-trained DialoFlow, which presents high chatbot-level correlation ($r=0.9$) with human ratings among 11 chatbots. Code and pre-trained models will be public. \footnote{\url{https://github.com/ictnlp/DialoFlow}}
AKI-BERT: a Pre-trained Clinical Language Model for Early Prediction of Acute Kidney Injury
May 07, 2022
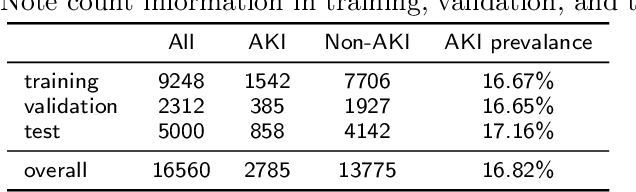
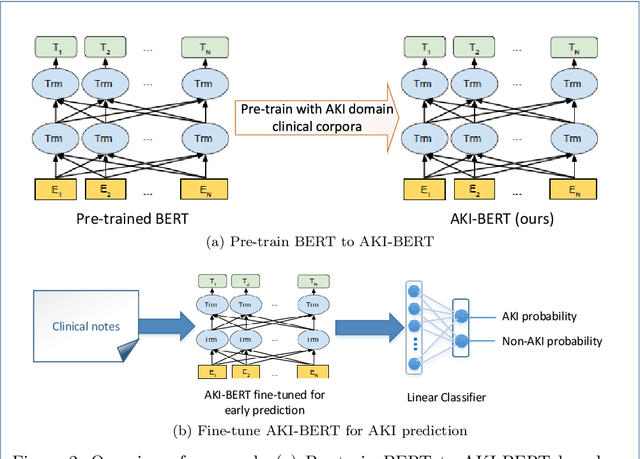
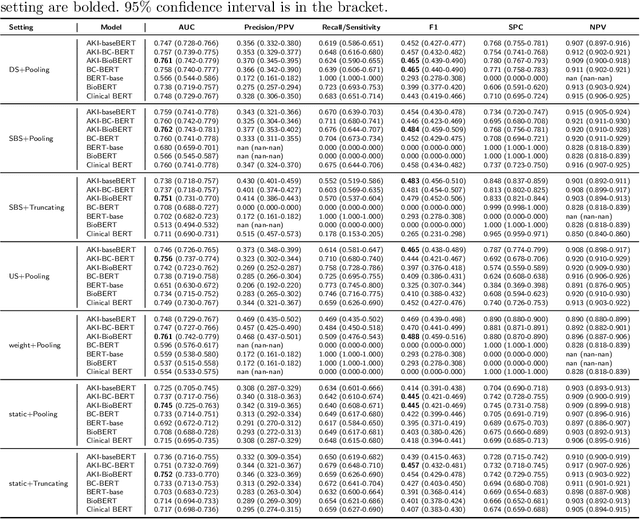
Acute kidney injury (AKI) is a common clinical syndrome characterized by a sudden episode of kidney failure or kidney damage within a few hours or a few days. Accurate early prediction of AKI for patients in ICU who are more likely than others to have AKI can enable timely interventions, and reduce the complications of AKI. Much of the clinical information relevant to AKI is captured in clinical notes that are largely unstructured text and requires advanced natural language processing (NLP) for useful information extraction. On the other hand, pre-trained contextual language models such as Bidirectional Encoder Representations from Transformers (BERT) have improved performances for many NLP tasks in general domain recently. However, few have explored BERT on disease-specific medical domain tasks such as AKI early prediction. In this paper, we try to apply BERT to specific diseases and present an AKI domain-specific pre-trained language model based on BERT (AKI-BERT) that could be used to mine the clinical notes for early prediction of AKI. AKI-BERT is a BERT model pre-trained on the clinical notes of patients having risks for AKI. Our experiments on Medical Information Mart for Intensive Care III (MIMIC-III) dataset demonstrate that AKI-BERT can yield performance improvements for early AKI prediction, thus expanding the utility of the BERT model from general clinical domain to disease-specific domain.
Structure-aware Protein Self-supervised Learning
Apr 06, 2022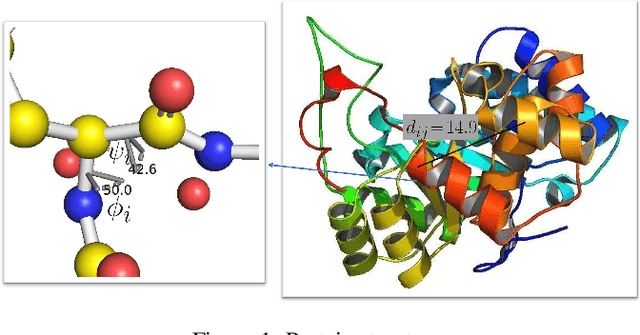
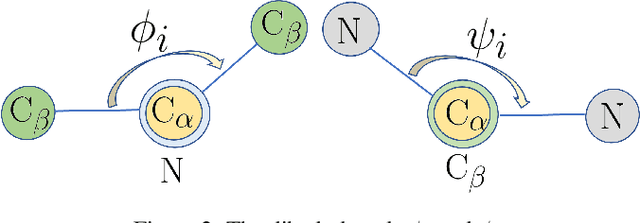
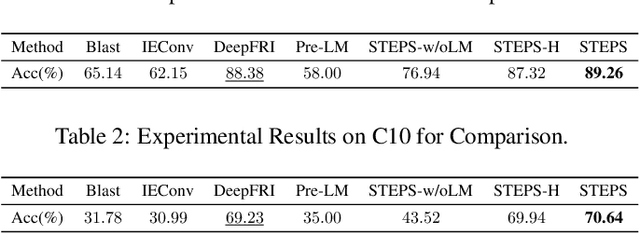
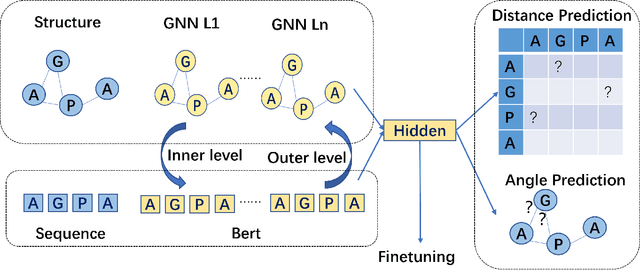
Protein representation learning methods have shown great potential to yield useful representation for many downstream tasks, especially on protein classification. Moreover, a few recent studies have shown great promise in addressing insufficient labels of proteins with self-supervised learning methods. However, existing protein language models are usually pretrained on protein sequences without considering the important protein structural information. To this end, we propose a novel structure-aware protein self-supervised learning method to effectively capture structural information of proteins. In particular, a well-designed graph neural network (GNN) model is pretrained to preserve the protein structural information with self-supervised tasks from a pairwise residue distance perspective and a dihedral angle perspective, respectively. Furthermore, we propose to leverage the available protein language model pretrained on protein sequences to enhance the self-supervised learning. Specifically, we identify the relation between the sequential information in the protein language model and the structural information in the specially designed GNN model via a novel pseudo bi-level optimization scheme. Experiments on several supervised downstream tasks verify the effectiveness of our proposed method.