 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Computer-aided Tuberculosis Diagnosis with Attribute Reasoning Assistance
Jul 01, 2022
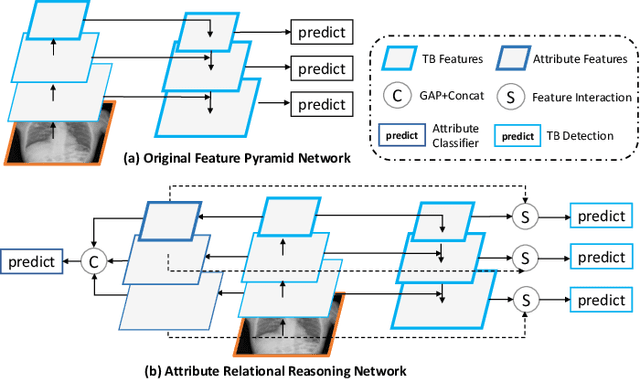
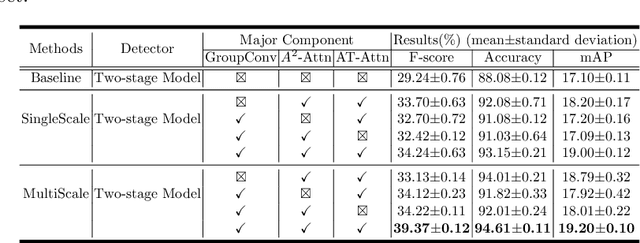
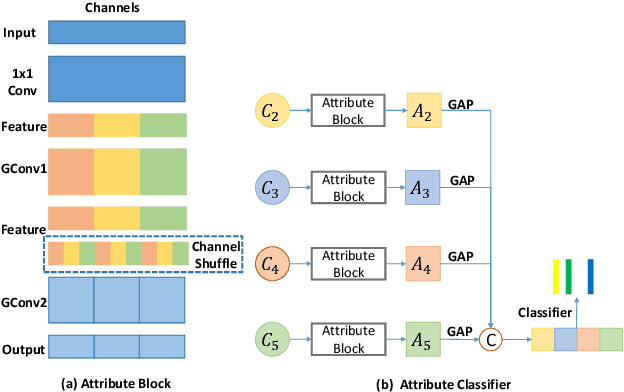
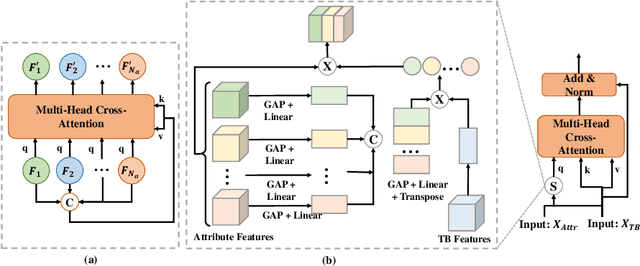
Although deep learning algorithms have been intensively developed for computer-aided tuberculosis diagnosis (CTD), they mainly depend on carefully annotated datasets, leading to much time and resource consumption. Weakly supervised learning (WSL), which leverages coarse-grained labels to accomplish fine-grained tasks, has the potential to solve this problem. In this paper, we first propose a new large-scale tuberculosis (TB) chest X-ray dataset, namely the tuberculosis chest X-ray attribute dataset (TBX-Att), and then establish an attribute-assisted weakly-supervised framework to classify and localize TB by leveraging the attribute information to overcome the insufficiency of supervision in WSL scenarios. Specifically, first, the TBX-Att dataset contains 2000 X-ray images with seven kinds of attributes for TB relational reasoning, which are annotated by experienced radiologists. It also includes the public TBX11K dataset with 11200 X-ray images to facilitate weakly supervised detection. Second, we exploit a multi-scale feature interaction model for TB area classification and detection with attribute relational reasoning. The proposed model is evaluated on the TBX-Att dataset and will serve as a solid baseline for future research. The code and data will be available at https://github.com/GangmingZhao/tb-attribute-weak-localization.
Image deblurring based on lightweight multi-information fusion network
Jan 14, 2021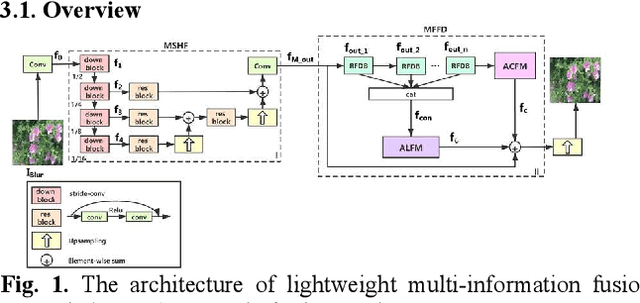
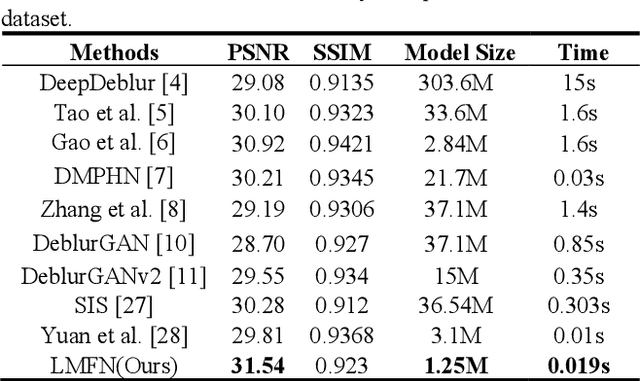
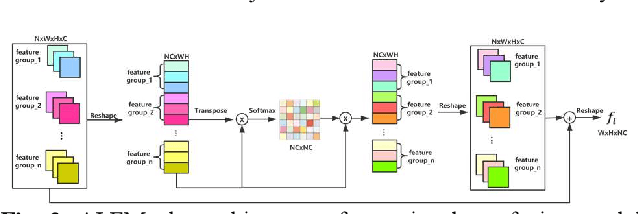

Recently, deep learning based image deblurring has been well developed. However, exploiting the detailed image features in a deep learning framework always requires a mass of parameters, which inevitably makes the network suffer from high computational burden. To solve this problem, we propose a lightweight multiinformation fusion network (LMFN) for image deblurring. The proposed LMFN is designed as an encoder-decoder architecture. In the encoding stage, the image feature is reduced to various smallscale spaces for multi-scale information extraction and fusion without a large amount of information loss. Then, a distillation network is used in the decoding stage, which allows the network benefit the most from residual learning while remaining sufficiently lightweight. Meanwhile, an information fusion strategy between distillation modules and feature channels is also carried out by attention mechanism. Through fusing different information in the proposed approach, our network can achieve state-of-the-art image deblurring result with smaller number of parameters and outperforms existing methods in model complexity.
Partial Shape Similarity via Alignment of Multi-Metric Hamiltonian Spectra
Jul 07, 2022
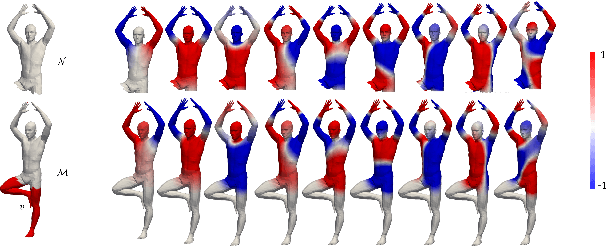


Evaluating the similarity of non-rigid shapes with significant partiality is a fundamental task in numerous computer vision applications. Here, we propose a novel axiomatic method to match similar regions across shapes. Matching similar regions is formulated as the alignment of the spectra of operators closely related to the Laplace-Beltrami operator (LBO). The main novelty of the proposed approach is the consideration of differential operators defined on a manifold with multiple metrics. The choice of a metric relates to fundamental shape properties while considering the same manifold under different metrics can thus be viewed as analyzing the underlying manifold from different perspectives. Specifically, we examine the scale-invariant metric and the corresponding scale-invariant Laplace-Beltrami operator (SI-LBO) along with the regular metric and the regular LBO. We demonstrate that the scale-invariant metric emphasizes the locations of important semantic features in articulated shapes. A truncated spectrum of the SI-LBO consequently better captures locally curved regions and complements the global information encapsulated in the truncated spectrum of the regular LBO. We show that matching these dual spectra outperforms competing axiomatic frameworks when tested on standard benchmarks. We introduced a new dataset and compare the proposed method with the state-of-the-art learning based approach in a cross-database configuration. Specifically, we show that, when trained on one data set and tested on another, the proposed axiomatic approach which does not involve training, outperforms the deep learning alternative.
CSI-Based Localization with CNNs Exploiting Phase Information
Jan 22, 2021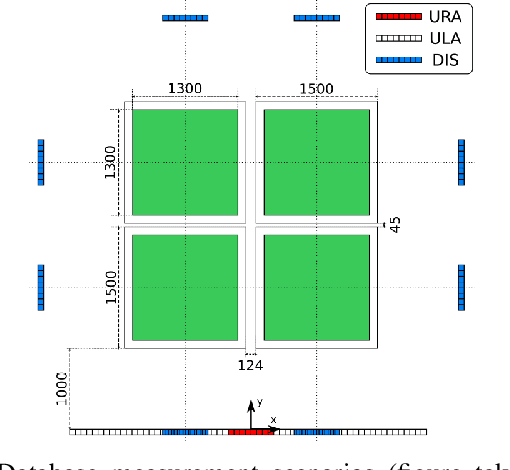
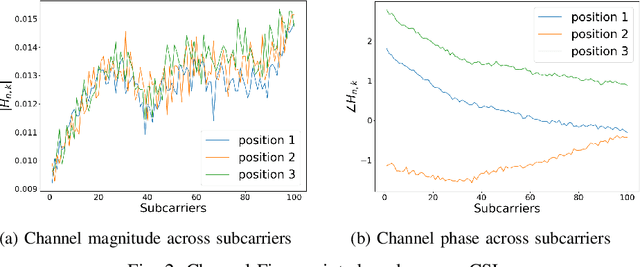
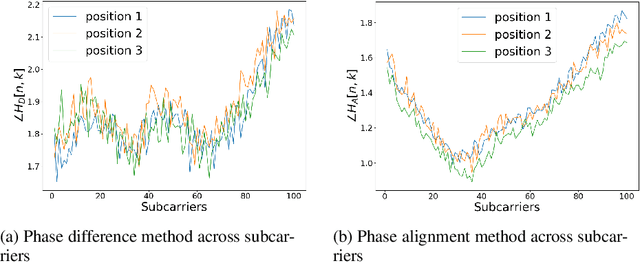
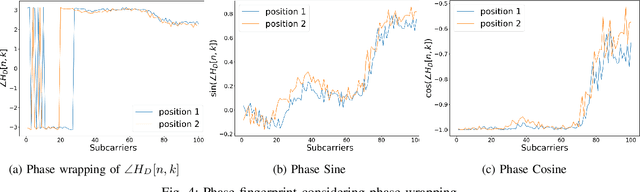
In this paper we study the use of the Channel State Information (CSI) as fingerprint inputs of a Convolutional Neural Network (CNN) for localization. We examine whether the CSI can be used as a distinct fingerprint corresponding to a single position by considering the inconsistencies with its raw phase that cause the CSI to be unreliable. We propose two methods to produce reliable fingerprints including the phase information. Furthermore, we examine the structure of the CNN and more specifically the impact of pooling on the positioning performance, and show that pooling over the subcarriers can be more beneficial than over the antennas.
AI-based Clinical Assessment of Optic Nerve Head Robustness Superseding Biomechanical Testing
Jun 09, 2022
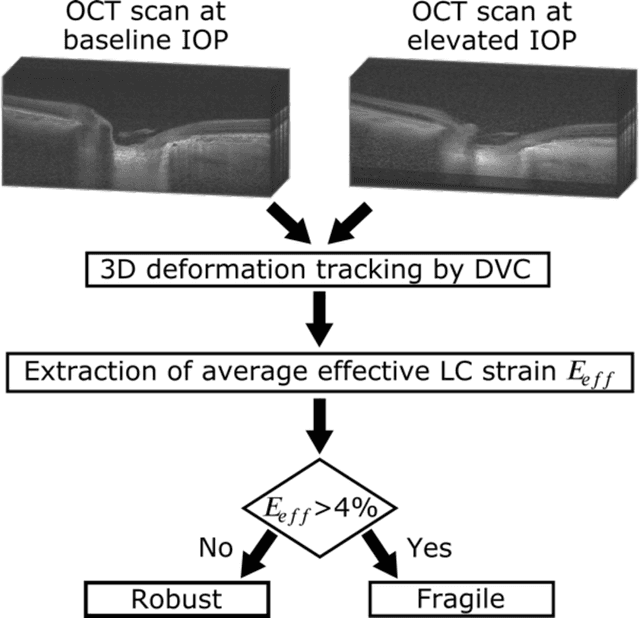
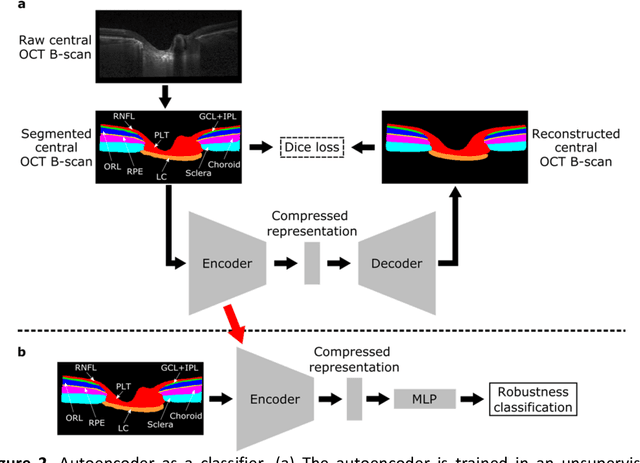
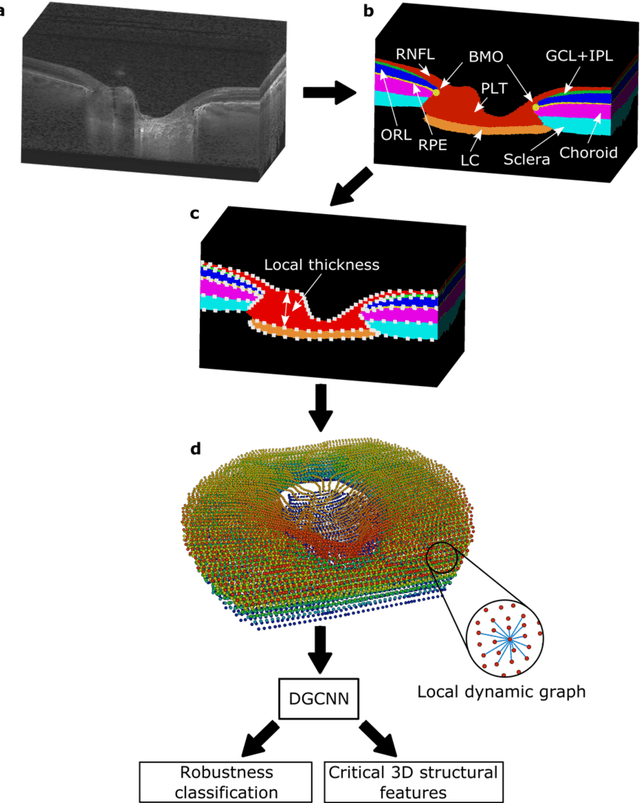
$\mathbf{Purpose}$: To use artificial intelligence (AI) to: (1) exploit biomechanical knowledge of the optic nerve head (ONH) from a relatively large population; (2) assess ONH robustness from a single optical coherence tomography (OCT) scan of the ONH; (3) identify what critical three-dimensional (3D) structural features make a given ONH robust. $\mathbf{Design}$: Retrospective cross-sectional study. $\mathbf{Methods}$: 316 subjects had their ONHs imaged with OCT before and after acute intraocular pressure (IOP) elevation through ophthalmo-dynamometry. IOP-induced lamina-cribrosa deformations were then mapped in 3D and used to classify ONHs. Those with LC deformations superior to 4% were considered fragile, while those with deformations inferior to 4% robust. Learning from these data, we compared three AI algorithms to predict ONH robustness strictly from a baseline (undeformed) OCT volume: (1) a random forest classifier; (2) an autoencoder; and (3) a dynamic graph CNN (DGCNN). The latter algorithm also allowed us to identify what critical 3D structural features make a given ONH robust. $\mathbf{Results}$: All 3 methods were able to predict ONH robustness from 3D structural information alone and without the need to perform biomechanical testing. The DGCNN (area under the receiver operating curve [AUC]: 0.76 $\pm$ 0.08) outperformed the autoencoder (AUC: 0.70 $\pm$ 0.07) and the random forest classifier (AUC: 0.69 $\pm$ 0.05). Interestingly, to assess ONH robustness, the DGCNN mainly used information from the scleral canal and the LC insertion sites. $\mathbf{Conclusions}$: We propose an AI-driven approach that can assess the robustness of a given ONH solely from a single OCT scan of the ONH, and without the need to perform biomechanical testing. Longitudinal studies should establish whether ONH robustness could help us identify fast visual field loss progressors.
Interaction-Grounded Learning with Action-inclusive Feedback
Jun 16, 2022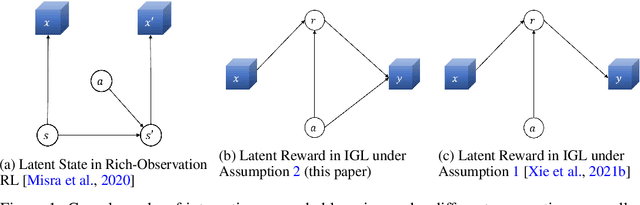

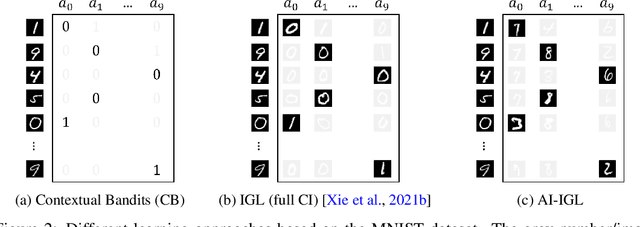

Consider the problem setting of Interaction-Grounded Learning (IGL), in which a learner's goal is to optimally interact with the environment with no explicit reward to ground its policies. The agent observes a context vector, takes an action, and receives a feedback vector, using this information to effectively optimize a policy with respect to a latent reward function. Prior analyzed approaches fail when the feedback vector contains the action, which significantly limits IGL's success in many potential scenarios such as Brain-computer interface (BCI) or Human-computer interface (HCI) applications. We address this by creating an algorithm and analysis which allows IGL to work even when the feedback vector contains the action, encoded in any fashion. We provide theoretical guarantees and large-scale experiments based on supervised datasets to demonstrate the effectiveness of the new approach.
Towards Understanding How Machines Can Learn Causal Overhypotheses
Jun 16, 2022
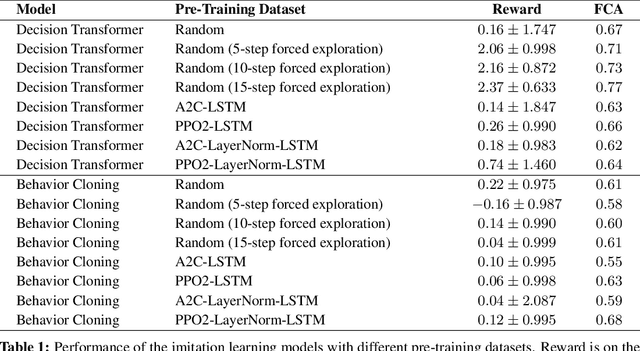

Recent work in machine learning and cognitive science has suggested that understanding causal information is essential to the development of intelligence. The extensive literature in cognitive science using the ``blicket detector'' environment shows that children are adept at many kinds of causal inference and learning. We propose to adapt that environment for machine learning agents. One of the key challenges for current machine learning algorithms is modeling and understanding causal overhypotheses: transferable abstract hypotheses about sets of causal relationships. In contrast, even young children spontaneously learn and use causal overhypotheses. In this work, we present a new benchmark -- a flexible environment which allows for the evaluation of existing techniques under variable causal overhypotheses -- and demonstrate that many existing state-of-the-art methods have trouble generalizing in this environment. The code and resources for this benchmark are available at https://github.com/CannyLab/casual_overhypotheses.
Collaborative Uncertainty Benefits Multi-Agent Multi-Modal Trajectory Forecasting
Jul 11, 2022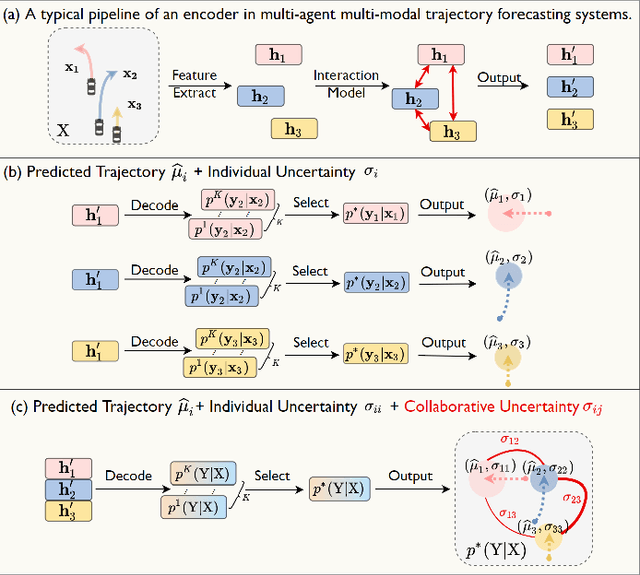

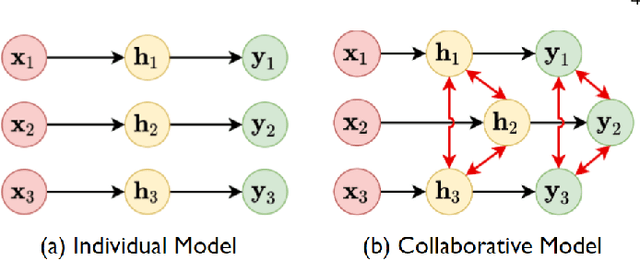
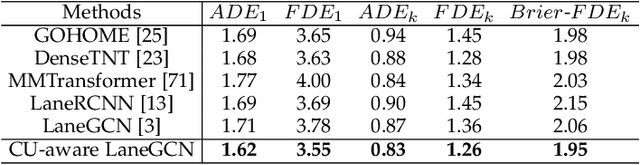
In multi-modal multi-agent trajectory forecasting, two major challenges have not been fully tackled: 1) how to measure the uncertainty brought by the interaction module that causes correlations among the predicted trajectories of multiple agents; 2) how to rank the multiple predictions and select the optimal predicted trajectory. In order to handle these challenges, this work first proposes a novel concept, collaborative uncertainty (CU), which models the uncertainty resulting from interaction modules. Then we build a general CU-aware regression framework with an original permutation-equivariant uncertainty estimator to do both tasks of regression and uncertainty estimation. Further, we apply the proposed framework to current SOTA multi-agent multi-modal forecasting systems as a plugin module, which enables the SOTA systems to 1) estimate the uncertainty in the multi-agent multi-modal trajectory forecasting task; 2) rank the multiple predictions and select the optimal one based on the estimated uncertainty. We conduct extensive experiments on a synthetic dataset and two public large-scale multi-agent trajectory forecasting benchmarks. Experiments show that: 1) on the synthetic dataset, the CU-aware regression framework allows the model to appropriately approximate the ground-truth Laplace distribution; 2) on the multi-agent trajectory forecasting benchmarks, the CU-aware regression framework steadily helps SOTA systems improve their performances. Specially, the proposed framework helps VectorNet improve by 262 cm regarding the Final Displacement Error of the chosen optimal prediction on the nuScenes dataset; 3) for multi-agent multi-modal trajectory forecasting systems, prediction uncertainty is positively correlated with future stochasticity; and 4) the estimated CU values are highly related to the interactive information among agents.
Machine Learning Based Cyber Attacks Targeting on Controlled Information: A Survey
Feb 16, 2021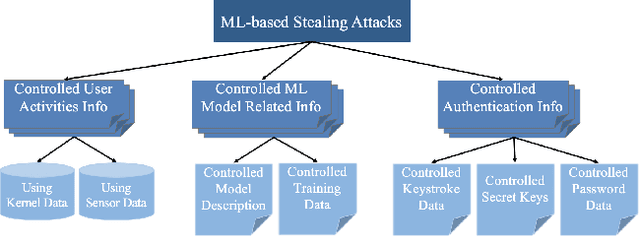

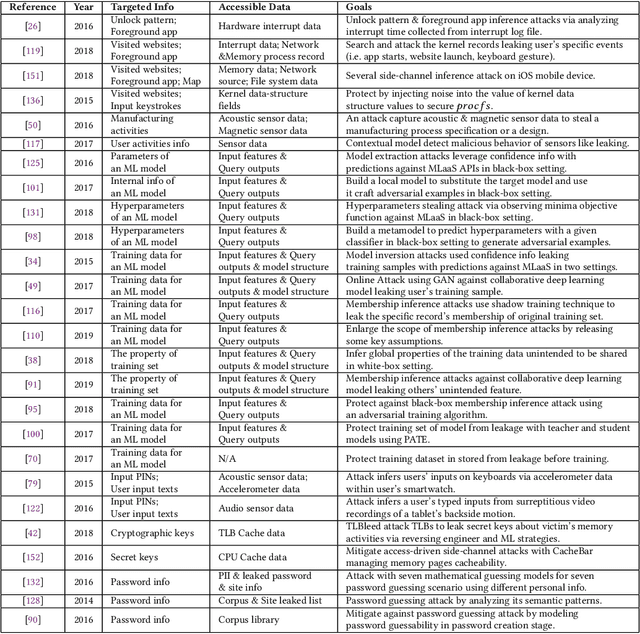
Stealing attack against controlled information, along with the increasing number of information leakage incidents, has become an emerging cyber security threat in recent years. Due to the booming development and deployment of advanced analytics solutions, novel stealing attacks utilize machine learning (ML) algorithms to achieve high success rate and cause a lot of damage. Detecting and defending against such attacks is challenging and urgent so that governments, organizations, and individuals should attach great importance to the ML-based stealing attacks. This survey presents the recent advances in this new type of attack and corresponding countermeasures. The ML-based stealing attack is reviewed in perspectives of three categories of targeted controlled information, including controlled user activities, controlled ML model-related information, and controlled authentication information. Recent publications are summarized to generalize an overarching attack methodology and to derive the limitations and future directions of ML-based stealing attacks. Furthermore, countermeasures are proposed towards developing effective protections from three aspects -- detection, disruption, and isolation.
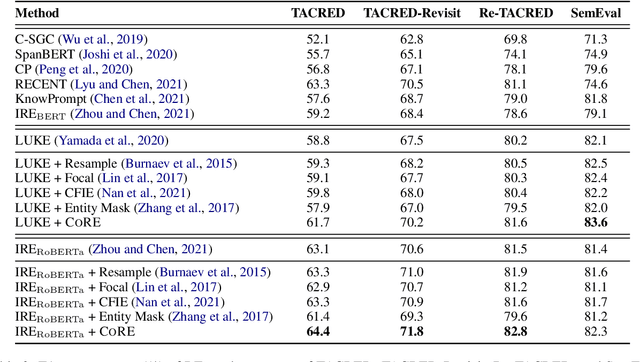
Should We Rely on Entity Mentions for Relation Extraction? Debiasing Relation Extraction with Counterfactual Analysis
May 08, 2022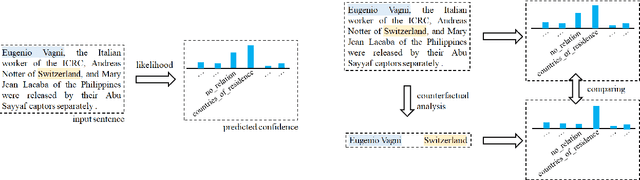
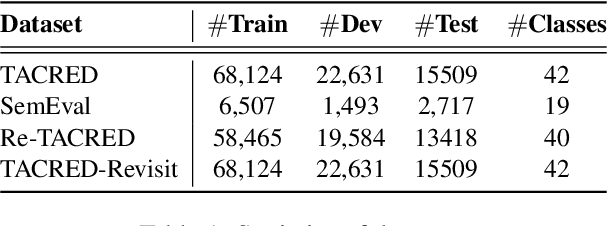
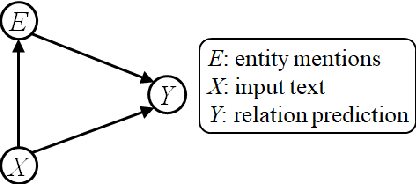
Recent literature focuses on utilizing the entity information in the sentence-level relation extraction (RE), but this risks leaking superficial and spurious clues of relations. As a result, RE still suffers from unintended entity bias, i.e., the spurious correlation between entity mentions (names) and relations. Entity bias can mislead the RE models to extract the relations that do not exist in the text. To combat this issue, some previous work masks the entity mentions to prevent the RE models from overfitting entity mentions. However, this strategy degrades the RE performance because it loses the semantic information of entities. In this paper, we propose the CORE (Counterfactual Analysis based Relation Extraction) debiasing method that guides the RE models to focus on the main effects of textual context without losing the entity information. We first construct a causal graph for RE, which models the dependencies between variables in RE models. Then, we propose to conduct counterfactual analysis on our causal graph to distill and mitigate the entity bias, that captures the causal effects of specific entity mentions in each instance. Note that our CORE method is model-agnostic to debias existing RE systems during inference without changing their training processes. Extensive experimental results demonstrate that our CORE yields significant gains on both effectiveness and generalization for RE. The source code is provided at: https://github.com/vanoracai/CoRE.