 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploiting Cross-Session Information for Session-based Recommendation with Graph Neural Networks
Jul 02, 2021

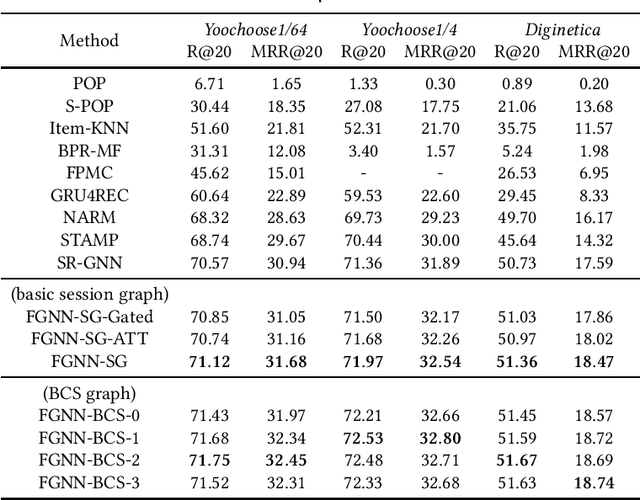
Different from the traditional recommender system, the session-based recommender system introduces the concept of the session, i.e., a sequence of interactions between a user and multiple items within a period, to preserve the user's recent interest. The existing work on the session-based recommender system mainly relies on mining sequential patterns within individual sessions, which are not expressive enough to capture more complicated dependency relationships among items. In addition, it does not consider the cross-session information due to the anonymity of the session data, where the linkage between different sessions is prevented. In this paper, we solve these problems with the graph neural networks technique. First, each session is represented as a graph rather than a linear sequence structure, based on which a novel Full Graph Neural Network (FGNN) is proposed to learn complicated item dependency. To exploit and incorporate cross-session information in the individual session's representation learning, we further construct a Broadly Connected Session (BCS) graph to link different sessions and a novel Mask-Readout function to improve session embedding based on the BCS graph. Extensive experiments have been conducted on two e-commerce benchmark datasets, i.e., Yoochoose and Diginetica, and the experimental results demonstrate the superiority of our proposal through comparisons with state-of-the-art session-based recommender models.
3DG-STFM: 3D Geometric Guided Student-Teacher Feature Matching
Jul 06, 2022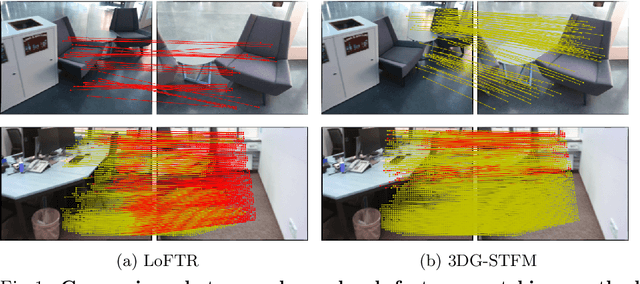
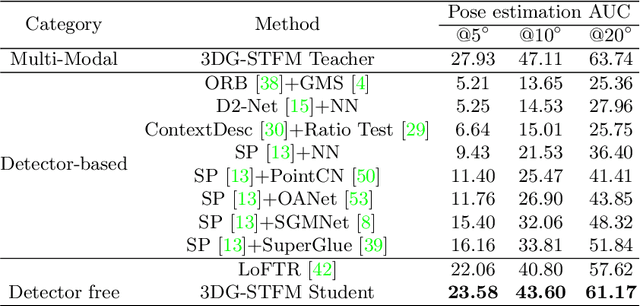
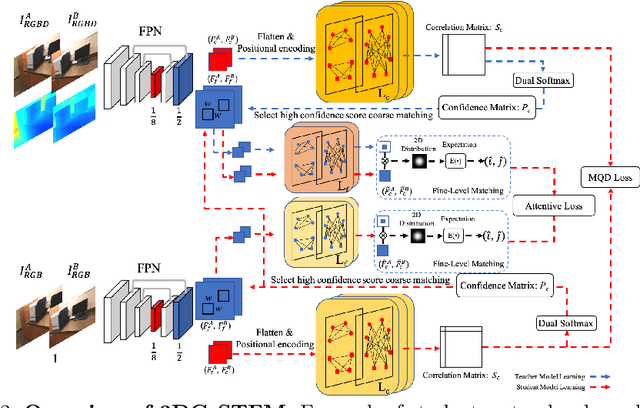
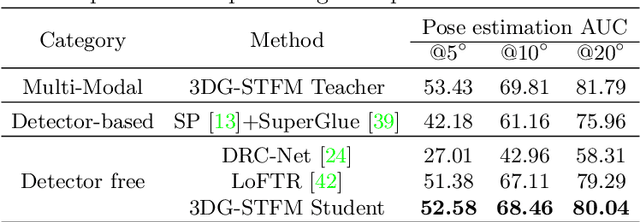
We tackle the essential task of finding dense visual correspondences between a pair of images. This is a challenging problem due to various factors such as poor texture, repetitive patterns, illumination variation, and motion blur in practical scenarios. In contrast to methods that use dense correspondence ground-truths as direct supervision for local feature matching training, we train 3DG-STFM: a multi-modal matching model (Teacher) to enforce the depth consistency under 3D dense correspondence supervision and transfer the knowledge to 2D unimodal matching model (Student). Both teacher and student models consist of two transformer-based matching modules that obtain dense correspondences in a coarse-to-fine manner. The teacher model guides the student model to learn RGB-induced depth information for the matching purpose on both coarse and fine branches. We also evaluate 3DG-STFM on a model compression task. To the best of our knowledge, 3DG-STFM is the first student-teacher learning method for the local feature matching task. The experiments show that our method outperforms state-of-the-art methods on indoor and outdoor camera pose estimations, and homography estimation problems. Code is available at: https://github.com/Ryan-prime/3DG-STFM.
Multi-Camera View Based Proactive BS Selection and Beam Switching for V2X
Jul 12, 2022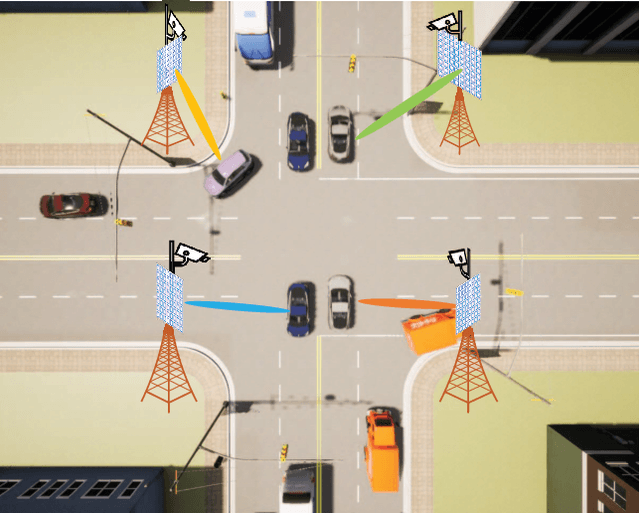
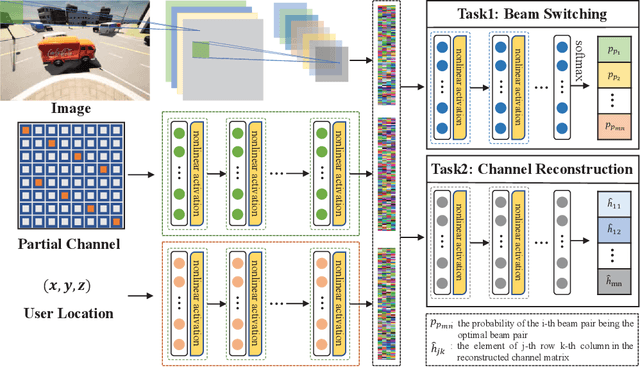
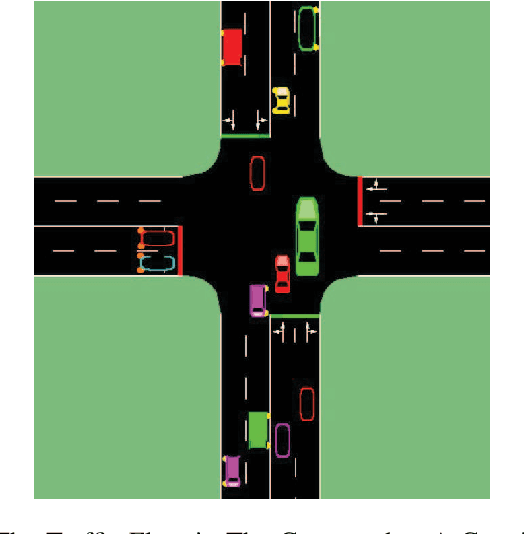

Due to the short wavelength and large attenuation of millimeter-wave (mmWave), mmWave BSs are densely distributed and require beamforming with high directivity. When the user moves out of the coverage of the current BS or is severely blocked, the mmWave BS must be switched to ensure the communication quality. In this paper, we proposed a multi-camera view based proactive BS selection and beam switching that can predict the optimal BS of the user in the future frame and switch the corresponding beam pair. Specifically, we extract the features of multi-camera view images and a small part of channel state information (CSI) in historical frames, and dynamically adjust the weight of each modality feature. Then we design a multi-task learning module to guide the network to better understand the main task, thereby enhancing the accuracy and the robustness of BS selection and beam switching. Using the outputs of all tasks, a prior knowledge based fine tuning network is designed to further increase the BS switching accuracy. After the optimal BS is obtained, a beam pair switching network is proposed to directly predict the optimal beam pair of the corresponding BS. Simulation results in an outdoor intersection environment show the superior performance of our proposed solution under several metrics such as predicting accuracy, achievable rate, harmonic mean of precision and recall.
MetaAge: Meta-Learning Personalized Age Estimators
Jul 12, 2022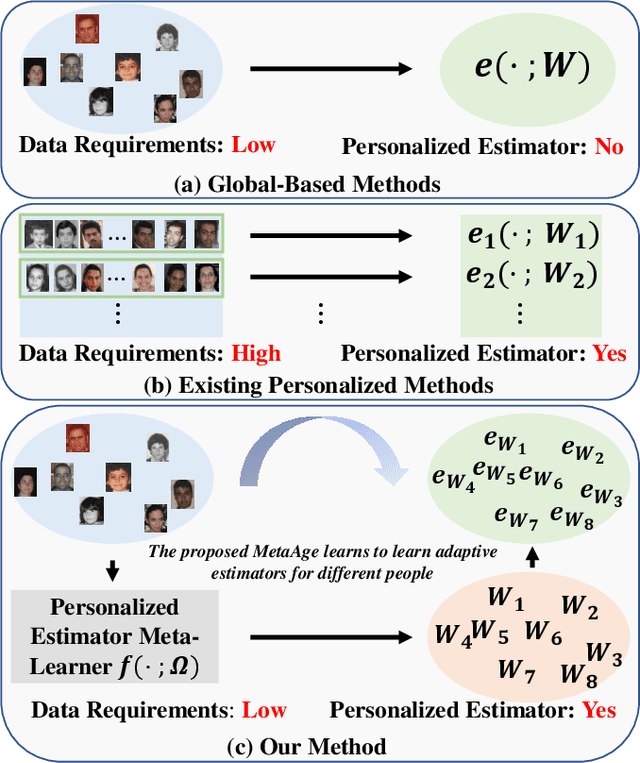
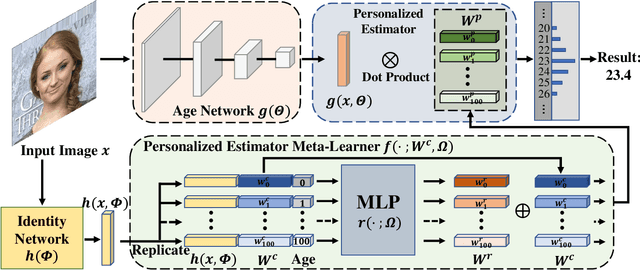
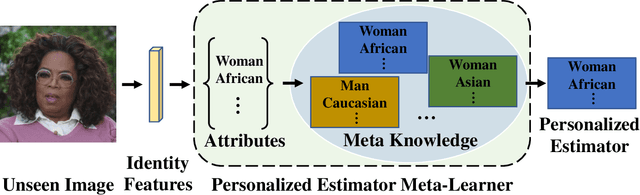
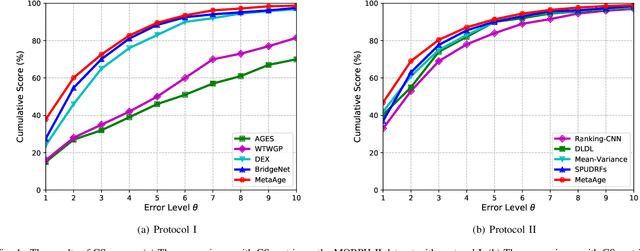
Different people age in different ways. Learning a personalized age estimator for each person is a promising direction for age estimation given that it better models the personalization of aging processes. However, most existing personalized methods suffer from the lack of large-scale datasets due to the high-level requirements: identity labels and enough samples for each person to form a long-term aging pattern. In this paper, we aim to learn personalized age estimators without the above requirements and propose a meta-learning method named MetaAge for age estimation. Unlike most existing personalized methods that learn the parameters of a personalized estimator for each person in the training set, our method learns the mapping from identity information to age estimator parameters. Specifically, we introduce a personalized estimator meta-learner, which takes identity features as the input and outputs the parameters of customized estimators. In this way, our method learns the meta knowledge without the above requirements and seamlessly transfers the learned meta knowledge to the test set, which enables us to leverage the existing large-scale age datasets without any additional annotations. Extensive experimental results on three benchmark datasets including MORPH II, ChaLearn LAP 2015 and ChaLearn LAP 2016 databases demonstrate that our MetaAge significantly boosts the performance of existing personalized methods and outperforms the state-of-the-art approaches.
Pedestrian 3D Bounding Box Prediction
Jun 28, 2022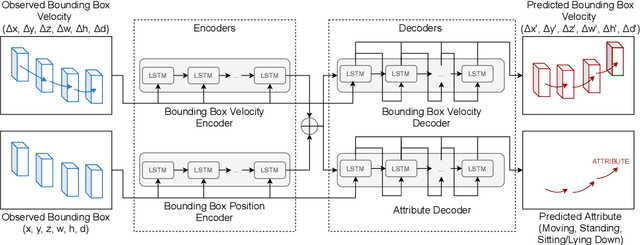
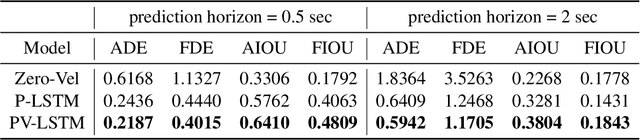


Safety is still the main issue of autonomous driving, and in order to be globally deployed, they need to predict pedestrians' motions sufficiently in advance. While there is a lot of research on coarse-grained (human center prediction) and fine-grained predictions (human body keypoints prediction), we focus on 3D bounding boxes, which are reasonable estimates of humans without modeling complex motion details for autonomous vehicles. This gives the flexibility to predict in longer horizons in real-world settings. We suggest this new problem and present a simple yet effective model for pedestrians' 3D bounding box prediction. This method follows an encoder-decoder architecture based on recurrent neural networks, and our experiments show its effectiveness in both the synthetic (JTA) and real-world (NuScenes) datasets. The learned representation has useful information to enhance the performance of other tasks, such as action anticipation. Our code is available online: https://github.com/vita-epfl/bounding-box-prediction
Less is More: Adaptive Curriculum Learning for Thyroid Nodule Diagnosis
Jul 02, 2022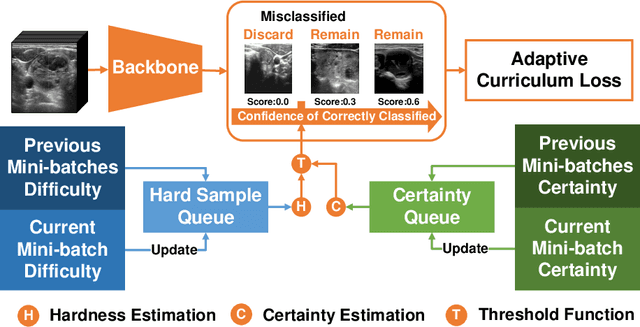
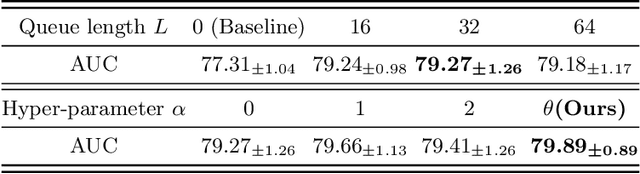
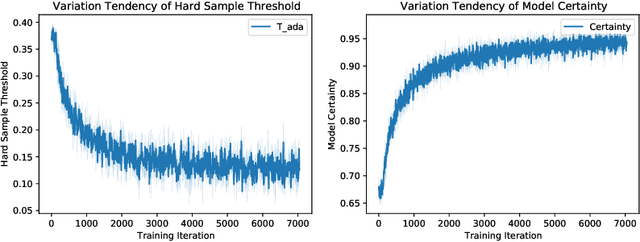
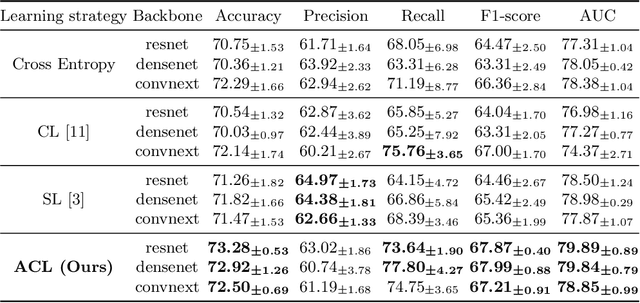
Thyroid nodule classification aims at determining whether the nodule is benign or malignant based on a given ultrasound image. However, the label obtained by the cytological biopsy which is the golden standard in clinical medicine is not always consistent with the ultrasound imaging TI-RADS criteria. The information difference between the two causes the existing deep learning-based classification methods to be indecisive. To solve the Inconsistent Label problem, we propose an Adaptive Curriculum Learning (ACL) framework, which adaptively discovers and discards the samples with inconsistent labels. Specifically, ACL takes both hard sample and model certainty into account, and could accurately determine the threshold to distinguish the samples with Inconsistent Label. Moreover, we contribute TNCD: a Thyroid Nodule Classification Dataset to facilitate future related research on the thyroid nodules. Extensive experimental results on TNCD based on three different backbone networks not only demonstrate the superiority of our method but also prove that the less-is-more principle which strategically discards the samples with Inconsistent Label could yield performance gains. Source code and data are available at https://github.com/chenghui-666/ACL/.
Video Anomaly Detection via Prediction Network with Enhanced Spatio-Temporal Memory Exchange
Jun 26, 2022



Video anomaly detection is a challenging task because most anomalies are scarce and non-deterministic. Many approaches investigate the reconstruction difference between normal and abnormal patterns, but neglect that anomalies do not necessarily correspond to large reconstruction errors. To address this issue, we design a Convolutional LSTM Auto-Encoder prediction framework with enhanced spatio-temporal memory exchange using bi-directionalilty and a higher-order mechanism. The bi-directional structure promotes learning the temporal regularity through forward and backward predictions. The unique higher-order mechanism further strengthens spatial information interaction between the encoder and the decoder. Considering the limited receptive fields in Convolutional LSTMs, we also introduce an attention module to highlight informative features for prediction. Anomalies are eventually identified by comparing the frames with their corresponding predictions. Evaluations on three popular benchmarks show that our framework outperforms most existing prediction-based anomaly detection methods.
Pavlov Learning Machines
Jul 02, 2022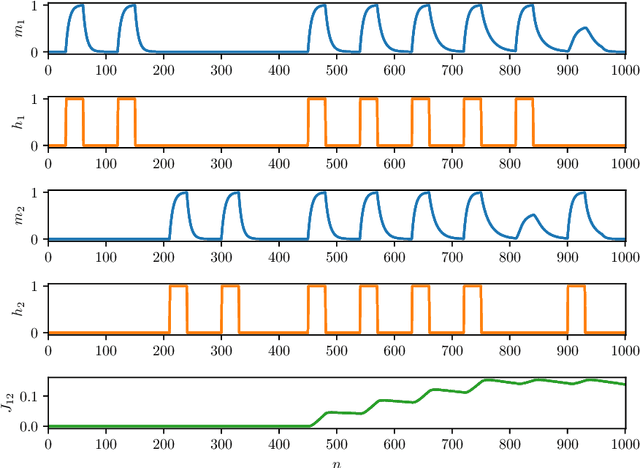
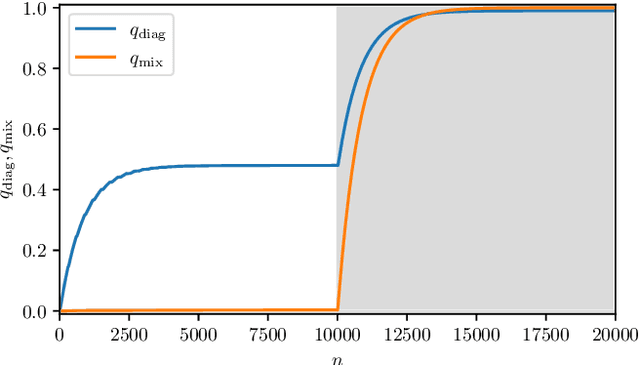

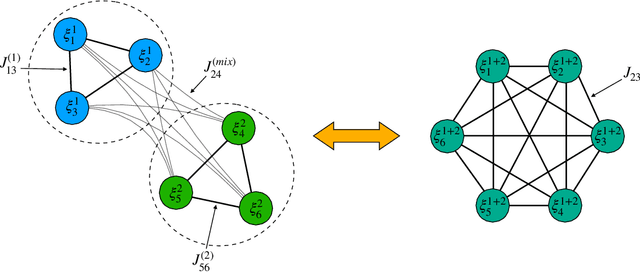
As well known, Hebb's learning traces its origin in Pavlov's Classical Conditioning, however, while the former has been extensively modelled in the past decades (e.g., by Hopfield model and countless variations on theme), as for the latter modelling has remained largely unaddressed so far; further, a bridge between these two pillars is totally lacking. The main difficulty towards this goal lays in the intrinsically different scales of the information involved: Pavlov's theory is about correlations among \emph{concepts} that are (dynamically) stored in the synaptic matrix as exemplified by the celebrated experiment starring a dog and a ring bell; conversely, Hebb's theory is about correlations among pairs of adjacent neurons as summarized by the famous statement {\em neurons that fire together wire together}. In this paper we rely on stochastic-process theory and model neural and synaptic dynamics via Langevin equations, to prove that -- as long as we keep neurons' and synapses' timescales largely split -- Pavlov mechanism spontaneously takes place and ultimately gives rise to synaptic weights that recover the Hebbian kernel.
Biologically-plausible backpropagation through arbitrary timespans via local neuromodulators
Jun 02, 2022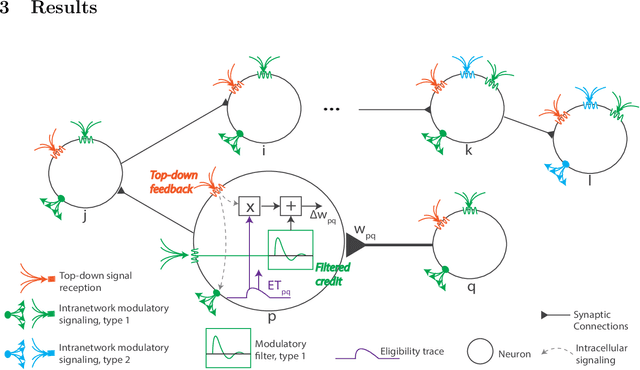
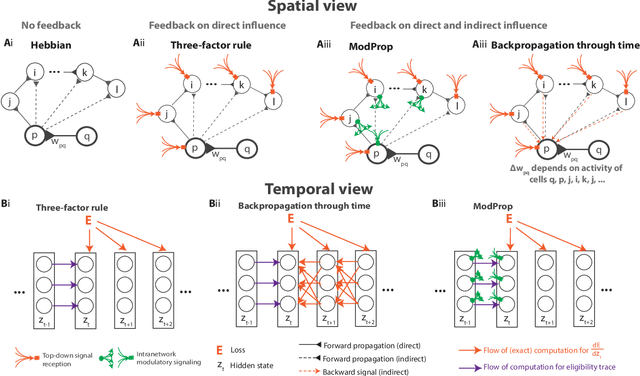
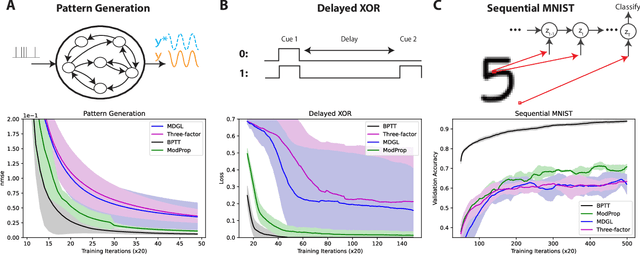
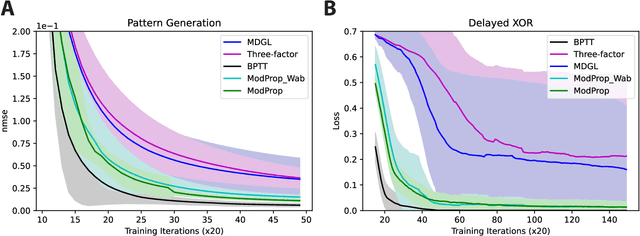
The spectacular successes of recurrent neural network models where key parameters are adjusted via backpropagation-based gradient descent have inspired much thought as to how biological neuronal networks might solve the corresponding synaptic credit assignment problem. There is so far little agreement, however, as to how biological networks could implement the necessary backpropagation through time, given widely recognized constraints of biological synaptic network signaling architectures. Here, we propose that extra-synaptic diffusion of local neuromodulators such as neuropeptides may afford an effective mode of backpropagation lying within the bounds of biological plausibility. Going beyond existing temporal truncation-based gradient approximations, our approximate gradient-based update rule, ModProp, propagates credit information through arbitrary time steps. ModProp suggests that modulatory signals can act on receiving cells by convolving their eligibility traces via causal, time-invariant and synapse-type-specific filter taps. Our mathematical analysis of ModProp learning, together with simulation results on benchmark temporal tasks, demonstrate the advantage of ModProp over existing biologically-plausible temporal credit assignment rules. These results suggest a potential neuronal mechanism for signaling credit information related to recurrent interactions over a longer time horizon. Finally, we derive an in-silico implementation of ModProp that could serve as a low-complexity and causal alternative to backpropagation through time.
Learning Adaptive Propagation for Knowledge Graph Reasoning
May 30, 2022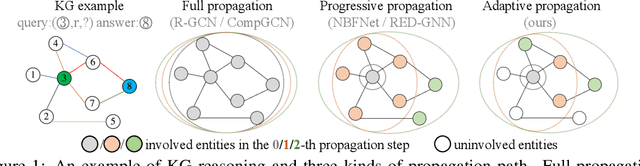

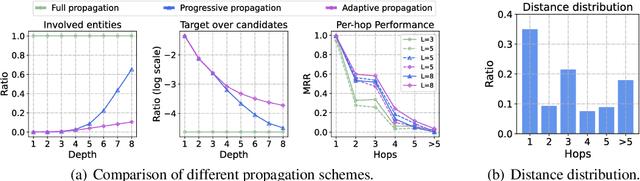
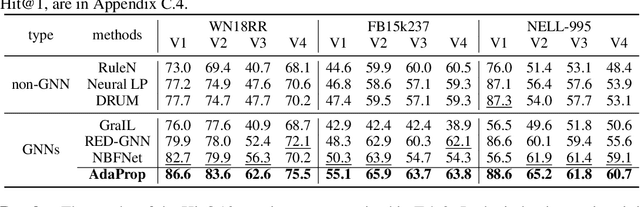
Due to the success of Graph Neural Networks (GNNs) in learning from graph-structured data, various GNN-based methods have been introduced to learn from knowledge graphs (KGs). In this paper, to reveal the key factors underneath existing GNN-based methods, we revisit exemplar works from the lens of the propagation path. We find that the answer entity can be close to queried one, but the information dependency can be long. Thus, better reasoning performance can be obtained by exploring longer propagation paths. However, identifying such a long-range dependency in KG is hard since the number of involved entities grows exponentially. This motivates us to learn an adaptive propagation path that filters out irrelevant entities while preserving promising targets during the propagation. First, we design an incremental sampling mechanism where the close and promising target can be preserved. Second, we design a learning-based sampling distribution to identify the targets with fewer involved entities. In this way, GNN can go deeper to capture long-range information. Extensive experiments show that our method is efficient and achieves state-of-the-art performances in both transductive and inductive reasoning settings, benefiting from the deeper propagation.