 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
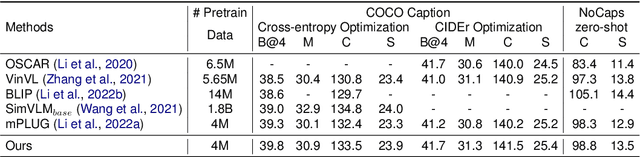
Digital Twin Aided Massive MIMO: CSI Compression and Feedback
Mar 01, 2024
Deep learning (DL) approaches have demonstrated high performance in compressing and reconstructing the channel state information (CSI) and reducing the CSI feedback overhead in massive MIMO systems. One key challenge, however, with the DL approaches is the demand for extensive training data. Collecting this real-world CSI data incurs significant overhead that hinders the DL approaches from scaling to a large number of communication sites. To address this challenge, we propose a novel direction that utilizes site-specific \textit{digital twins} to aid the training of DL models. The proposed digital twin approach generates site-specific synthetic CSI data from the EM 3D model and ray tracing, which can then be used to train the DL model without real-world data collection. To further improve the performance, we adopt online data selection to refine the DL model training with a small real-world CSI dataset. Results show that a DL model trained solely on the digital twin data can achieve high performance when tested in a real-world deployment. Further, leveraging domain adaptation techniques, the proposed approach requires orders of magnitude less real-world data to approach the same performance of the model trained completely on a real-world CSI dataset.
Spatially-Aware Transformer for Embodied Agents
Mar 01, 2024Episodic memory plays a crucial role in various cognitive processes, such as the ability to mentally recall past events. While cognitive science emphasizes the significance of spatial context in the formation and retrieval of episodic memory, the current primary approach to implementing episodic memory in AI systems is through transformers that store temporally ordered experiences, which overlooks the spatial dimension. As a result, it is unclear how the underlying structure could be extended to incorporate the spatial axis beyond temporal order alone and thereby what benefits can be obtained. To address this, this paper explores the use of Spatially-Aware Transformer models that incorporate spatial information. These models enable the creation of place-centric episodic memory that considers both temporal and spatial dimensions. Adopting this approach, we demonstrate that memory utilization efficiency can be improved, leading to enhanced accuracy in various place-centric downstream tasks. Additionally, we propose the Adaptive Memory Allocator, a memory management method based on reinforcement learning that aims to optimize efficiency of memory utilization. Our experiments demonstrate the advantages of our proposed model in various environments and across multiple downstream tasks, including prediction, generation, reasoning, and reinforcement learning. The source code for our models and experiments will be available at https://github.com/junmokane/spatially-aware-transformer.
Data-efficient Event Camera Pre-training via Disentangled Masked Modeling
Mar 01, 2024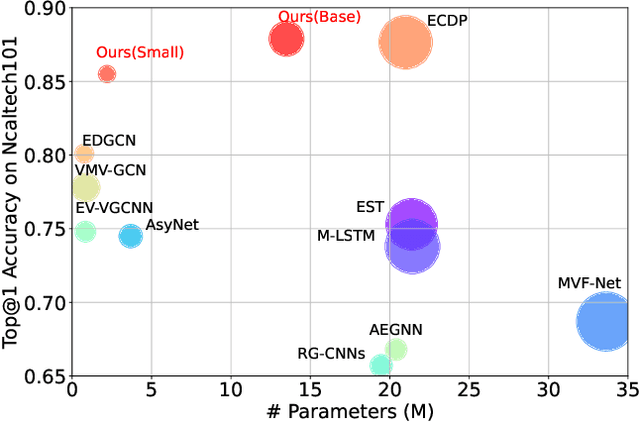


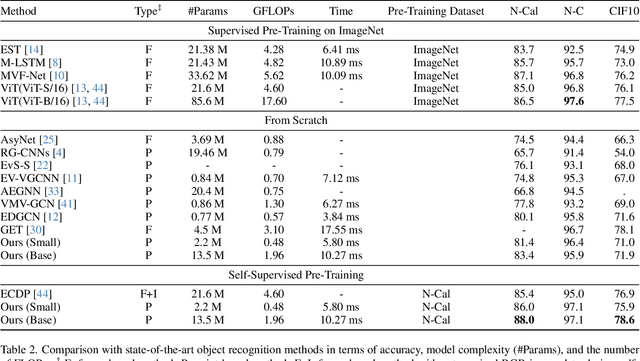
In this paper, we present a new data-efficient voxel-based self-supervised learning method for event cameras. Our pre-training overcomes the limitations of previous methods, which either sacrifice temporal information by converting event sequences into 2D images for utilizing pre-trained image models or directly employ paired image data for knowledge distillation to enhance the learning of event streams. In order to make our pre-training data-efficient, we first design a semantic-uniform masking method to address the learning imbalance caused by the varying reconstruction difficulties of different regions in non-uniform data when using random masking. In addition, we ease the traditional hybrid masked modeling process by explicitly decomposing it into two branches, namely local spatio-temporal reconstruction and global semantic reconstruction to encourage the encoder to capture local correlations and global semantics, respectively. This decomposition allows our selfsupervised learning method to converge faster with minimal pre-training data. Compared to previous approaches, our self-supervised learning method does not rely on paired RGB images, yet enables simultaneous exploration of spatial and temporal cues in multiple scales. It exhibits excellent generalization performance and demonstrates significant improvements across various tasks with fewer parameters and lower computational costs.
Semantics-enhanced Cross-modal Masked Image Modeling for Vision-Language Pre-training
Mar 01, 2024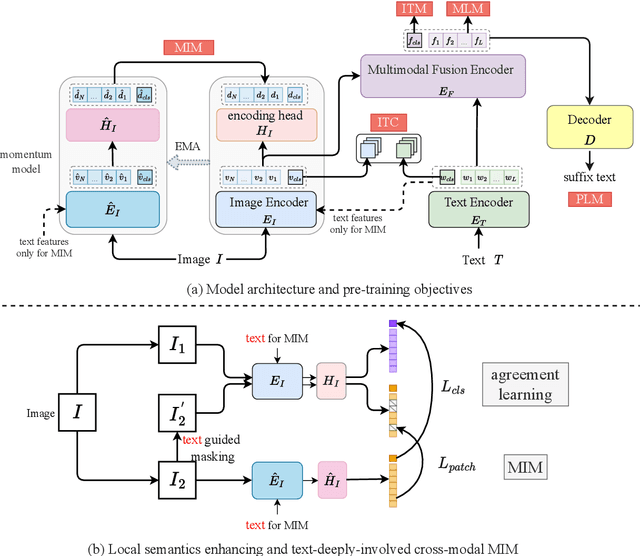
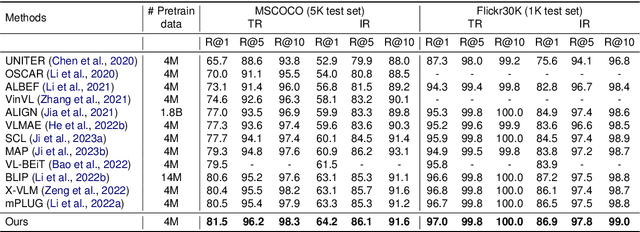

In vision-language pre-training (VLP), masked image modeling (MIM) has recently been introduced for fine-grained cross-modal alignment. However, in most existing methods, the reconstruction targets for MIM lack high-level semantics, and text is not sufficiently involved in masked modeling. These two drawbacks limit the effect of MIM in facilitating cross-modal semantic alignment. In this work, we propose a semantics-enhanced cross-modal MIM framework (SemMIM) for vision-language representation learning. Specifically, to provide more semantically meaningful supervision for MIM, we propose a local semantics enhancing approach, which harvest high-level semantics from global image features via self-supervised agreement learning and transfer them to local patch encodings by sharing the encoding space. Moreover, to achieve deep involvement of text during the entire MIM process, we propose a text-guided masking strategy and devise an efficient way of injecting textual information in both masked modeling and reconstruction target acquisition. Experimental results validate that our method improves the effectiveness of the MIM task in facilitating cross-modal semantic alignment. Compared to previous VLP models with similar model size and data scale, our SemMIM model achieves state-of-the-art or competitive performance on multiple downstream vision-language tasks.
Composite Distributed Learning and Synchronization of Nonlinear Multi-Agent Systems with Complete Uncertain Dynamics
Mar 01, 2024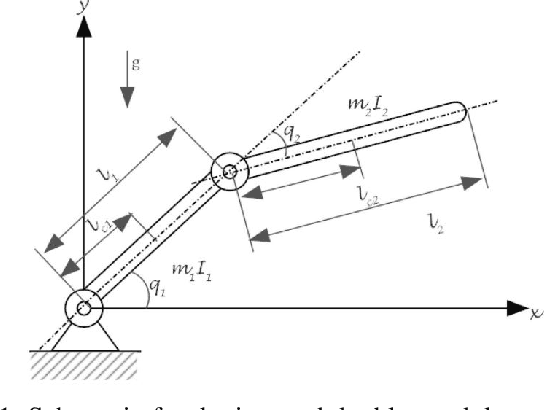
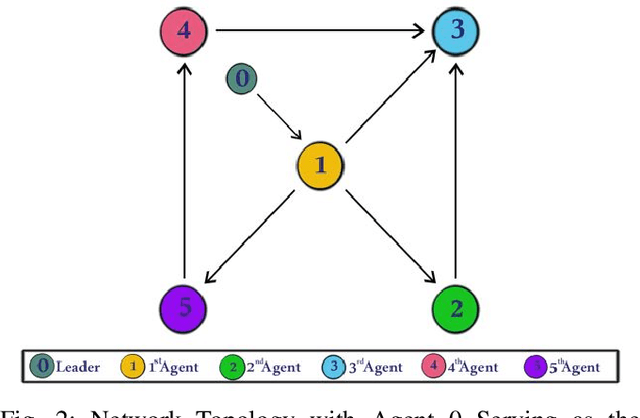
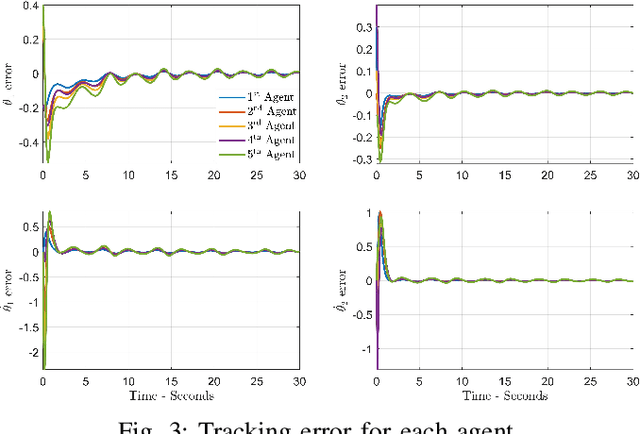
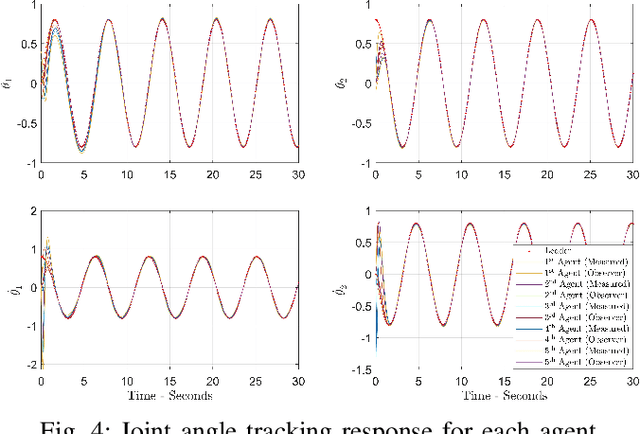
This paper addresses the challenging problem of composite synchronization and learning control in a network of multi-agent robotic manipulator systems operating under heterogeneous nonlinear uncertainties within a leader-follower framework. A novel two-layer distributed adaptive learning control strategy is introduced, comprising a first-layer distributed cooperative estimator and a second-layer decentralized deterministic learning controller. The primary objective of the first layer is to facilitate each robotic agent's estimation of the leader's information. The second layer is responsible for both enabling individual robot agents to track desired reference trajectories and accurately identifying and learning their nonlinear uncertain dynamics. The proposed distributed learning control scheme represents an advancement in the existing literature due to its ability to manage robotic agents with completely uncertain dynamics including uncertain mass matrices. This framework allows the robotic control to be environment-independent which can be used in various settings, from underwater to space where identifying system dynamics parameters is challenging. The stability and parameter convergence of the closed-loop system are rigorously analyzed using the Lyapunov method. Numerical simulations conducted on multi-agent robot manipulators validate the effectiveness of the proposed scheme. The identified nonlinear dynamics can be saved and reused whenever the system restarts.
Abductive Ego-View Accident Video Understanding for Safe Driving Perception
Mar 01, 2024
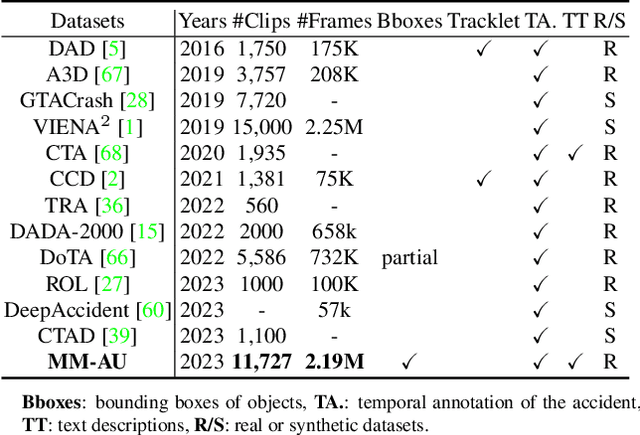
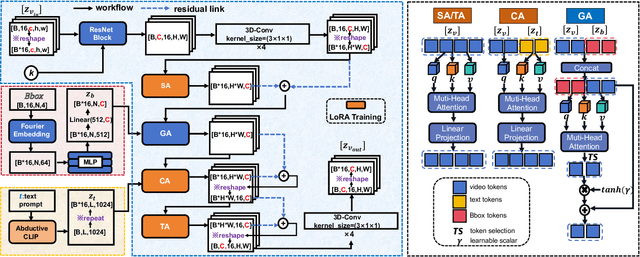
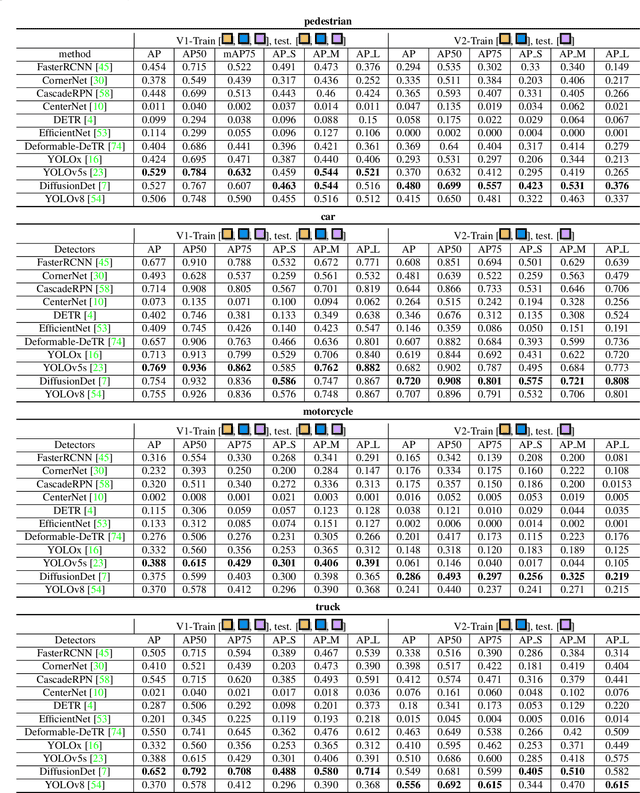
We present MM-AU, a novel dataset for Multi-Modal Accident video Understanding. MM-AU contains 11,727 in-the-wild ego-view accident videos, each with temporally aligned text descriptions. We annotate over 2.23 million object boxes and 58,650 pairs of video-based accident reasons, covering 58 accident categories. MM-AU supports various accident understanding tasks, particularly multimodal video diffusion to understand accident cause-effect chains for safe driving. With MM-AU, we present an Abductive accident Video understanding framework for Safe Driving perception (AdVersa-SD). AdVersa-SD performs video diffusion via an Object-Centric Video Diffusion (OAVD) method which is driven by an abductive CLIP model. This model involves a contrastive interaction loss to learn the pair co-occurrence of normal, near-accident, accident frames with the corresponding text descriptions, such as accident reasons, prevention advice, and accident categories. OAVD enforces the causal region learning while fixing the content of the original frame background in video generation, to find the dominant cause-effect chain for certain accidents. Extensive experiments verify the abductive ability of AdVersa-SD and the superiority of OAVD against the state-of-the-art diffusion models. Additionally, we provide careful benchmark evaluations for object detection and accident reason answering since AdVersa-SD relies on precise object and accident reason information.
Graph Construction with Flexible Nodes for Traffic Demand Prediction
Mar 01, 2024Graph neural networks (GNNs) have been widely applied in traffic demand prediction, and transportation modes can be divided into station-based mode and free-floating traffic mode. Existing research in traffic graph construction primarily relies on map matching to construct graphs based on the road network. However, the complexity and inhomogeneity of data distribution in free-floating traffic demand forecasting make road network matching inflexible. To tackle these challenges, this paper introduces a novel graph construction method tailored to free-floating traffic mode. We propose a novel density-based clustering algorithm (HDPC-L) to determine the flexible positioning of nodes in the graph, overcoming the computational bottlenecks of traditional clustering algorithms and enabling effective handling of large-scale datasets. Furthermore, we extract valuable information from ridership data to initialize the edge weights of GNNs. Comprehensive experiments on two real-world datasets, the Shenzhen bike-sharing dataset and the Haikou ride-hailing dataset, show that the method significantly improves the performance of the model. On average, our models show an improvement in accuracy of around 25\% and 19.5\% on the two datasets. Additionally, it significantly enhances computational efficiency, reducing training time by approximately 12% and 32.5% on the two datasets. We make our code available at https://github.com/houjinyan/HDPC-L-ODInit.
Resolution of Simpson's paradox via the common cause principle
Mar 01, 2024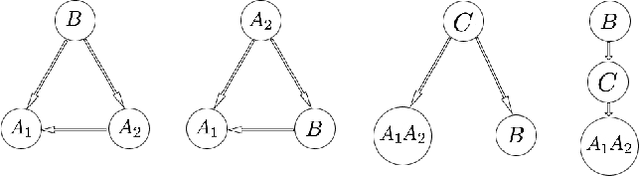
Simpson's paradox is an obstacle to establishing a probabilistic association between two events $a_1$ and $a_2$, given the third (lurking) random variable $B$. We focus on scenarios when the random variables $A$ (which combines $a_1$, $a_2$, and their complements) and $B$ have a common cause $C$ that need not be observed. Alternatively, we can assume that $C$ screens out $A$ from $B$. For such cases, the correct association between $a_1$ and $a_2$ is to be defined via conditioning over $C$. This set-up generalizes the original Simpson's paradox. Now its two contradicting options simply refer to two particular and different causes $C$. We show that if $B$ and $C$ are binary and $A$ is quaternary (the minimal and the most widespread situation for valid Simpson's paradox), the conditioning over any binary common cause $C$ establishes the same direction of the association between $a_1$ and $a_2$ as the conditioning over $B$ in the original formulation of the paradox. Thus, for the minimal common cause, one should choose the option of Simpson's paradox that assumes conditioning over $B$ and not its marginalization. For tertiary (unobserved) common causes $C$ all three options of Simpson's paradox become possible (i.e. marginalized, conditional, and none of them), and one needs prior information on $C$ to choose the right option.
AdaBoost-Based Efficient Channel Estimation and Data Detection in One-Bit Massive MIMO
Mar 01, 2024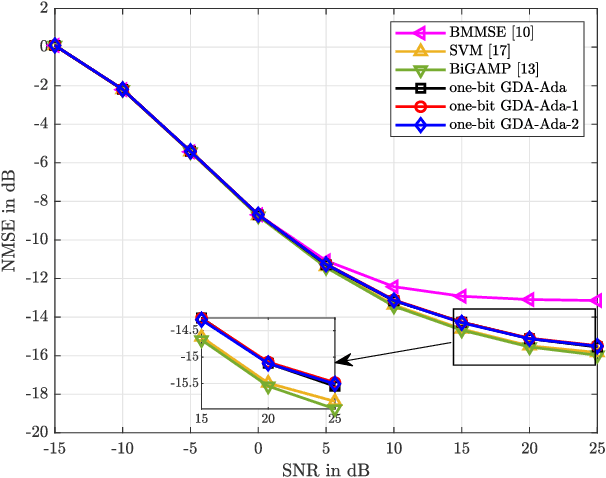
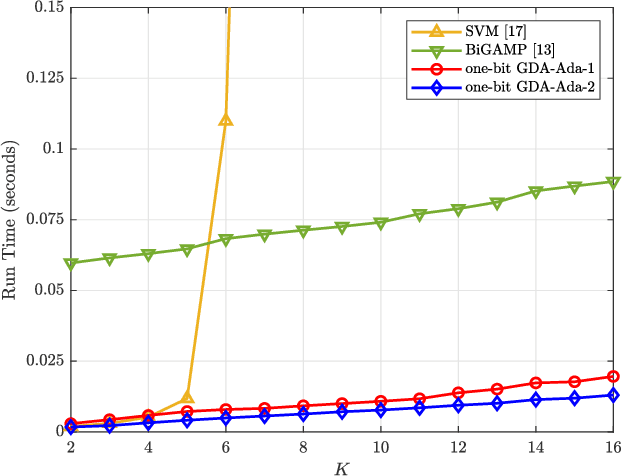
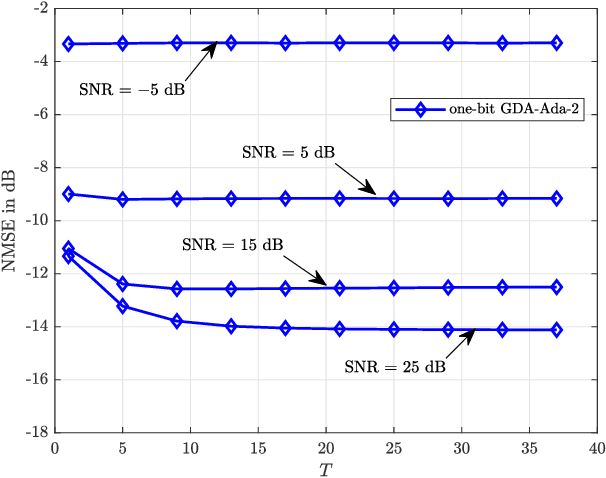
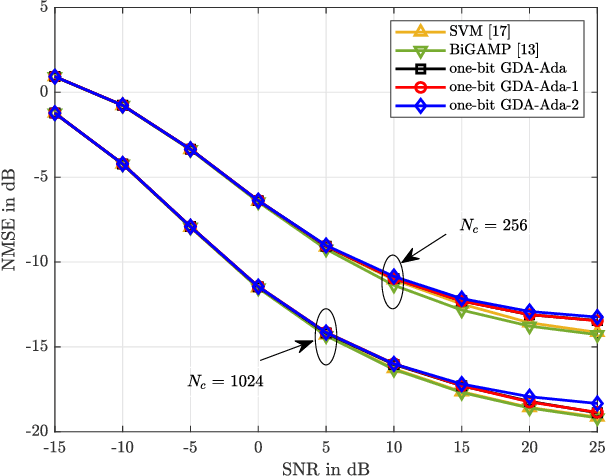
The use of one-bit analog-to-digital converter (ADC) has been considered as a viable alternative to high resolution counterparts in realizing and commercializing massive multiple-input multiple-output (MIMO) systems. However, the issue of discarding the amplitude information by one-bit quantizers has to be compensated. Thus, carefully tailored methods need to be developed for one-bit channel estimation and data detection as the conventional ones cannot be used. To address these issues, the problems of one-bit channel estimation and data detection for MIMO orthogonal frequency division multiplexing (OFDM) system that operates over uncorrelated frequency selective channels are investigated here. We first develop channel estimators that exploit Gaussian discriminant analysis (GDA) classifier and approximated versions of it as the so-called weak classifiers in an adaptive boosting (AdaBoost) approach. Particularly, the combination of the approximated GDA classifiers with AdaBoost offers the benefit of scalability with the linear order of computations, which is critical in massive MIMO-OFDM systems. We then take advantage of the same idea for proposing the data detectors. Numerical results validate the efficiency of the proposed channel estimators and data detectors compared to other methods. They show comparable/better performance to that of the state-of-the-art methods, but require dramatically lower computational complexities and run times.
Radar Anti-jamming Strategy Learning via Domain-knowledge Enhanced Online Convex Optimization
Feb 29, 2024The dynamic competition between radar and jammer systems presents a significant challenge for modern Electronic Warfare (EW), as current active learning approaches still lack sample efficiency and fail to exploit jammer's characteristics. In this paper, the competition between a frequency agile radar and a Digital Radio Frequency Memory (DRFM)-based intelligent jammer is considered. We introduce an Online Convex Optimization (OCO) framework designed to illustrate this adversarial interaction. Notably, traditional OCO algorithms exhibit suboptimal sample efficiency due to the limited information obtained per round. To address the limitations, two refined algorithms are proposed, utilizing unbiased gradient estimators that leverage the unique attributes of the jammer system. Sub-linear theoretical results on both static regret and universal regret are provided, marking a significant improvement in OCO performance. Furthermore, simulation results reveal that the proposed algorithms outperform common OCO baselines, suggesting the potential for effective deployment in real-world scenarios.