 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Knowledge Management System with NLP-Assisted Annotations: A Brief Survey and Outlook
Jun 15, 2022
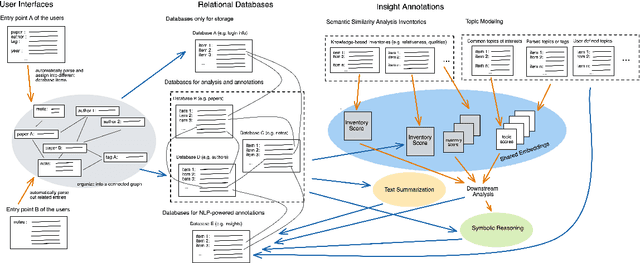
Knowledge management systems are in high demand for industrial researchers, chemical or research enterprises, or evidence-based decision making. However, existing systems have limitations in categorizing and organizing paper insights or relationships. Traditional databases are usually disjoint with logging systems, which limit its utility in generating concise, collated overviews. In this work, we briefly survey existing approaches of this problem space and propose a unified framework that utilizes relational databases to log hierarchical information to facilitate the research and writing process, or generate useful knowledge from references or insights from connected concepts. This framework of knowledge management system enables novel functionalities encompassing improved hierarchical notetaking, AI-assisted brainstorming, and multi-directional relationships. Potential applications include managing inventories and changes for manufacture or research enterprises, or generating analytic reports with evidence-based decision making.
Functional Optimization Reinforcement Learning for Real-Time Bidding
Jun 25, 2022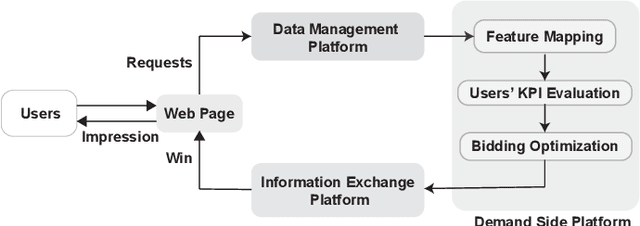
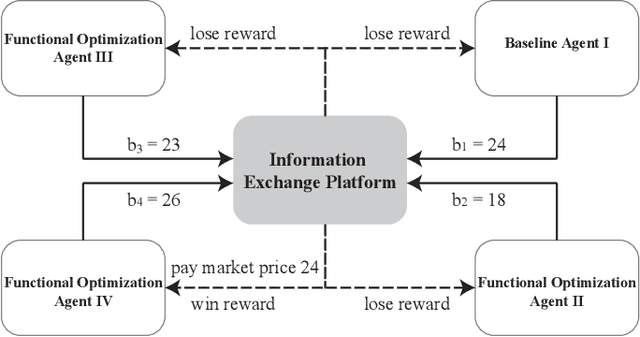
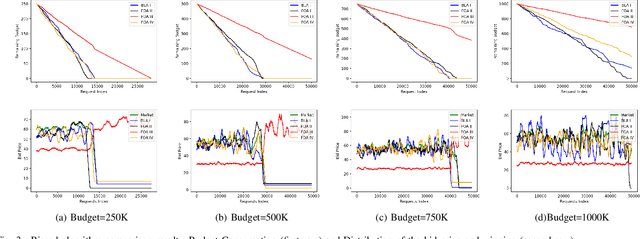
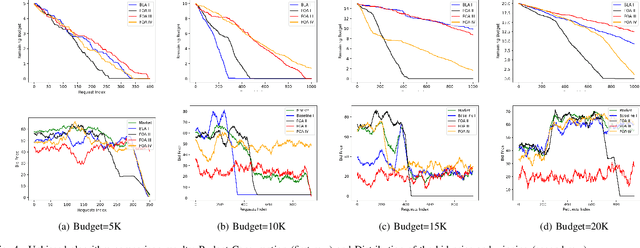
Real-time bidding is the new paradigm of programmatic advertising. An advertiser wants to make the intelligent choice of utilizing a \textbf{Demand-Side Platform} to improve the performance of their ad campaigns. Existing approaches are struggling to provide a satisfactory solution for bidding optimization due to stochastic bidding behavior. In this paper, we proposed a multi-agent reinforcement learning architecture for RTB with functional optimization. We designed four agents bidding environment: three Lagrange-multiplier based functional optimization agents and one baseline agent (without any attribute of functional optimization) First, numerous attributes have been assigned to each agent, including biased or unbiased win probability, Lagrange multiplier, and click-through rate. In order to evaluate the proposed RTB strategy's performance, we demonstrate the results on ten sequential simulated auction campaigns. The results show that agents with functional actions and rewards had the most significant average winning rate and winning surplus, given biased and unbiased winning information respectively. The experimental evaluations show that our approach significantly improve the campaign's efficacy and profitability.
Does your robot know? Enhancing children's information retrieval through spoken conversation with responsible robots
Jun 15, 2021In this paper, we identify challenges in children's current information retrieval process, and propose conversational robots as an opportunity to ease this process in a responsible way. Tools children currently use in this process, such as search engines on a computer or voice agents, do not always meet their specific needs. The conversational robot we propose maintains context, asks clarifying questions, and gives suggestions in order to better meet children's needs. Since children are often too trusting of robots, we propose to have the robot measure, monitor and adapt to the trust the child has in the robot. This way, we hope to induce a critical attitude with the children during their information retrieval process.
Learning Diverse Tone Styles for Image Retouching
Jul 12, 2022


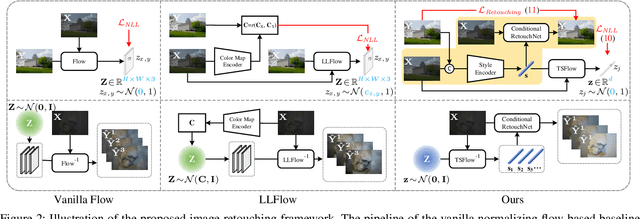
Image retouching, aiming to regenerate the visually pleasing renditions of given images, is a subjective task where the users are with different aesthetic sensations. Most existing methods deploy a deterministic model to learn the retouching style from a specific expert, making it less flexible to meet diverse subjective preferences. Besides, the intrinsic diversity of an expert due to the targeted processing on different images is also deficiently described. To circumvent such issues, we propose to learn diverse image retouching with normalizing flow-based architectures. Unlike current flow-based methods which directly generate the output image, we argue that learning in a style domain could (i) disentangle the retouching styles from the image content, (ii) lead to a stable style presentation form, and (iii) avoid the spatial disharmony effects. For obtaining meaningful image tone style representations, a joint-training pipeline is delicately designed, which is composed of a style encoder, a conditional RetouchNet, and the image tone style normalizing flow (TSFlow) module. In particular, the style encoder predicts the target style representation of an input image, which serves as the conditional information in the RetouchNet for retouching, while the TSFlow maps the style representation vector into a Gaussian distribution in the forward pass. After training, the TSFlow can generate diverse image tone style vectors by sampling from the Gaussian distribution. Extensive experiments on MIT-Adobe FiveK and PPR10K datasets show that our proposed method performs favorably against state-of-the-art methods and is effective in generating diverse results to satisfy different human aesthetic preferences. Source code and pre-trained models are publicly available at https://github.com/SSRHeart/TSFlow.
Stochastic Restoration of Heavily Compressed Musical Audio using Generative Adversarial Networks
Jul 04, 2022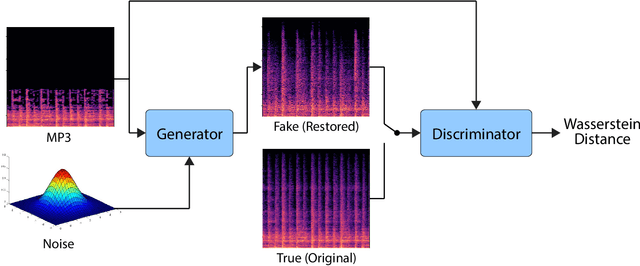
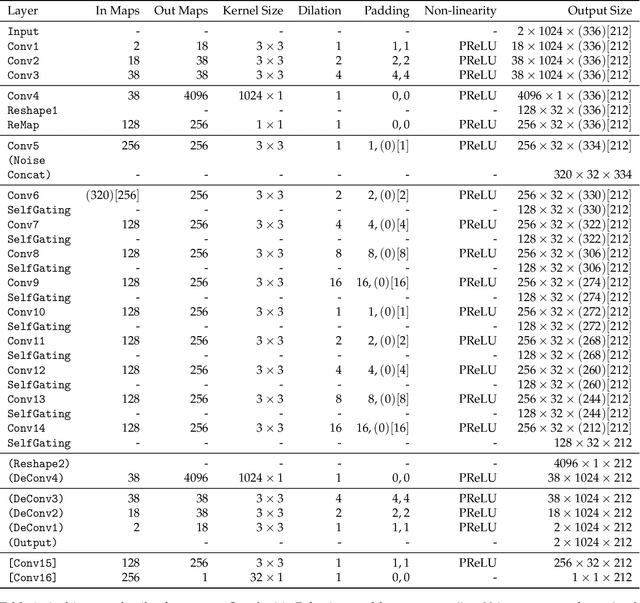
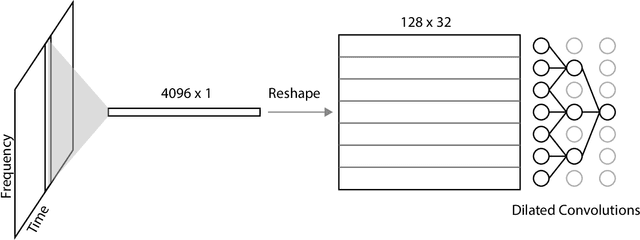
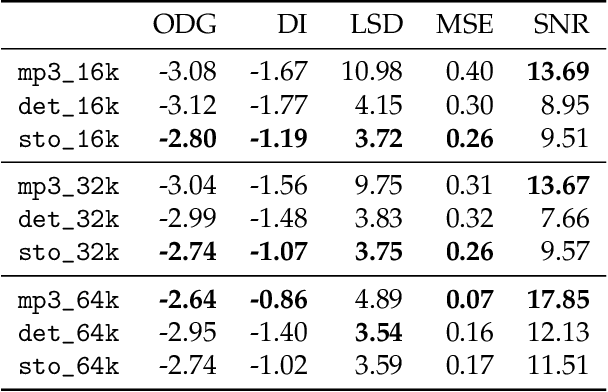
Lossy audio codecs compress (and decompress) digital audio streams by removing information that tends to be inaudible in human perception. Under high compression rates, such codecs may introduce a variety of impairments in the audio signal. Many works have tackled the problem of audio enhancement and compression artifact removal using deep learning techniques. However, only a few works tackle the restoration of heavily compressed audio signals in the musical domain. In such a scenario, there is no unique solution for the restoration of the original signal. Therefore, in this study, we test a stochastic generator of a Generative Adversarial Network (GAN) architecture for this task. Such a stochastic generator, conditioned on highly compressed musical audio signals, could one day generate outputs indistinguishable from high-quality releases. Therefore, the present study may yield insights into more efficient musical data storage and transmission. We train stochastic and deterministic generators on MP3-compressed audio signals with 16, 32, and 64 kbit/s. We perform an extensive evaluation of the different experiments utilizing objective metrics and listening tests. We find that the models can improve the quality of the audio signals over the MP3 versions for 16 and 32 kbit/s and that the stochastic generators are capable of generating outputs that are closer to the original signals than those of the deterministic generators.
* 21 pages, 5 figures, published in MDPI Electronics Special Issue "Machine Learning Applied to Music/Audio Signal Processing"
On the Convergence of the Shapley Value in Parametric Bayesian Learning Games
May 16, 2022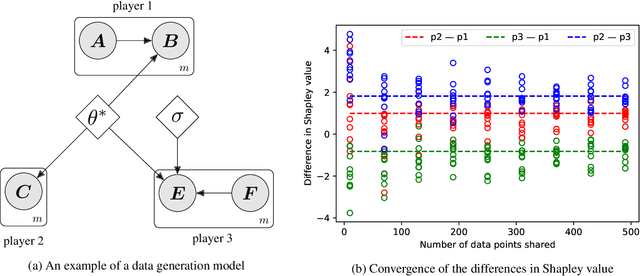
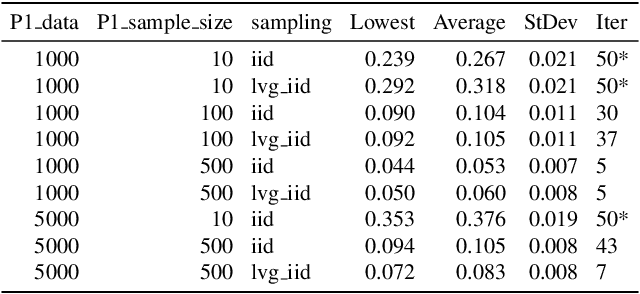
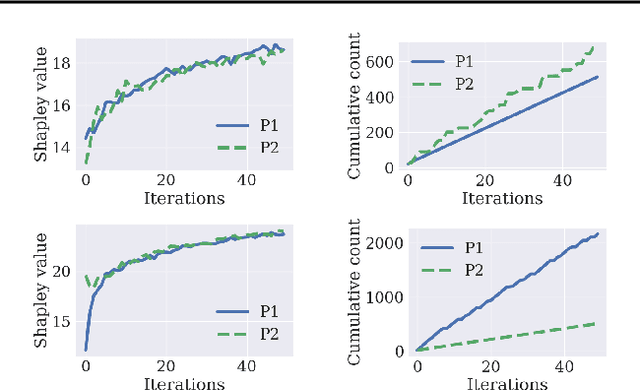
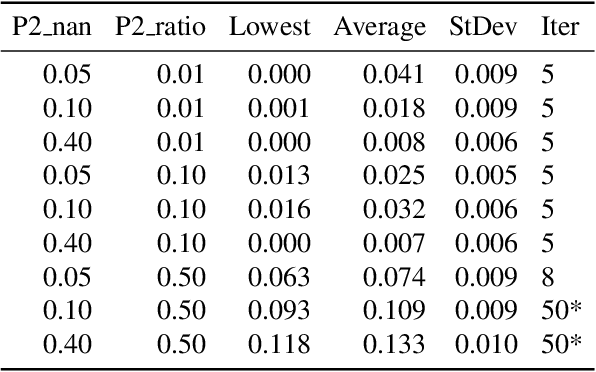
Measuring contributions is a classical problem in cooperative game theory where the Shapley value is the most well-known solution concept. In this paper, we establish the convergence property of the Shapley value in parametric Bayesian learning games where players perform a Bayesian inference using their combined data, and the posterior-prior KL divergence is used as the characteristic function. We show that for any two players, under some regularity conditions, their difference in Shapley value converges in probability to the difference in Shapley value of a limiting game whose characteristic function is proportional to the log-determinant of the joint Fisher information. As an application, we present an online collaborative learning framework that is asymptotically Shapley-fair. Our result enables this to be achieved without any costly computations of posterior-prior KL divergences. Only a consistent estimator of the Fisher information is needed. The framework's effectiveness is demonstrated with experiments using real-world data.
Clinical Dialogue Transcription Error Correction using Seq2Seq Models
May 26, 2022
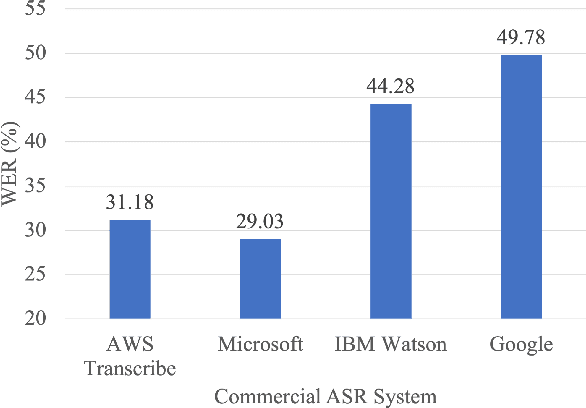
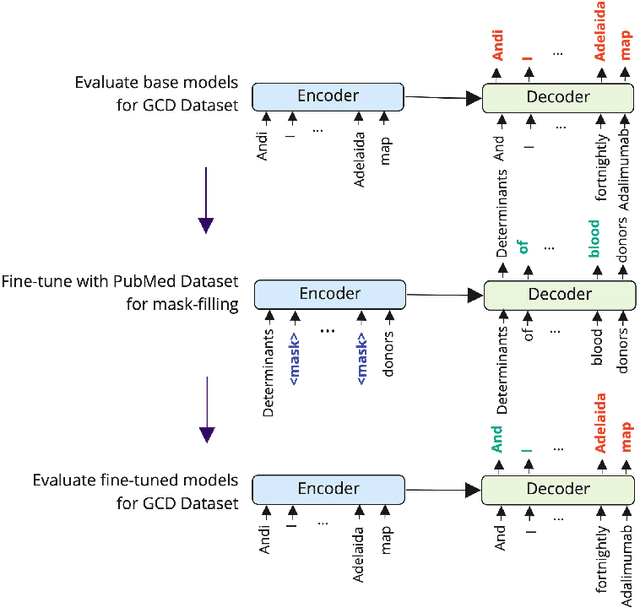

Good communication is critical to good healthcare. Clinical dialogue is a conversation between health practitioners and their patients, with the explicit goal of obtaining and sharing medical information. This information contributes to medical decision-making regarding the patient and plays a crucial role in their healthcare journey. The reliance on note taking and manual scribing processes are extremely inefficient and leads to manual transcription errors when digitizing notes. Automatic Speech Recognition (ASR) plays a significant role in speech-to-text applications, and can be directly used as a text generator in conversational applications. However, recording clinical dialogue presents a number of general and domain-specific challenges. In this paper, we present a seq2seq learning approach for ASR transcription error correction of clinical dialogues. We introduce a new Gastrointestinal Clinical Dialogue (GCD) Dataset which was gathered by healthcare professionals from a NHS Inflammatory Bowel Disease clinic and use this in a comparative study with four commercial ASR systems. Using self-supervision strategies, we fine-tune a seq2seq model on a mask-filling task using a domain-specific PubMed dataset which we have shared publicly for future research. The BART model fine-tuned for mask-filling was able to correct transcription errors and achieve lower word error rates for three out of four commercial ASR outputs.
Noise-aware Physics-informed Machine Learning for Robust PDE Discovery
Jul 04, 2022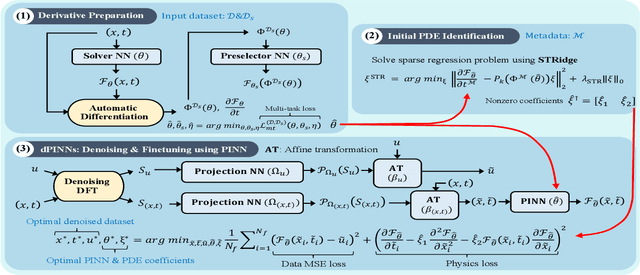
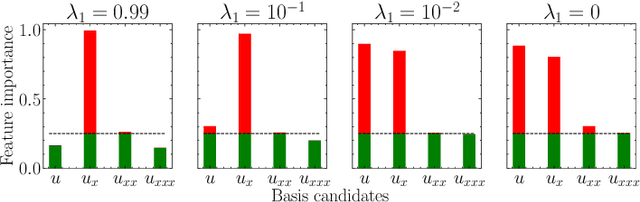
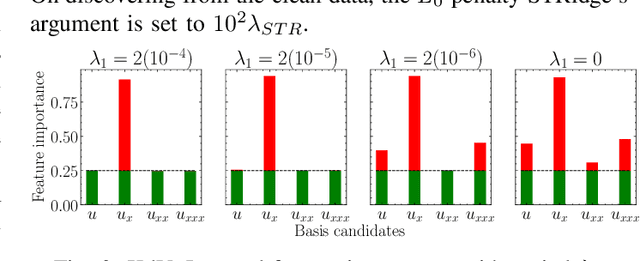
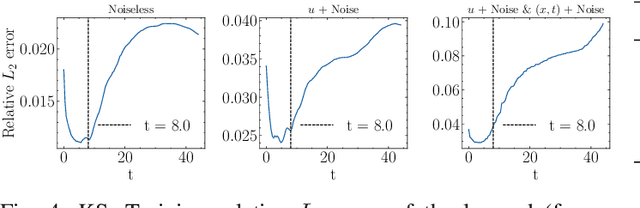
This work is concerned with discovering the governing partial differential equation (PDE) of a physical system. Existing methods have demonstrated the PDE identification from finite observations but failed to maintain satisfying performance against noisy data, partly owing to suboptimal estimated derivatives and found PDE coefficients. We address the issues by introducing a noise-aware physics-informed machine learning (nPIML) framework to discover the governing PDE from data following arbitrary distributions. Our proposals are twofold. First, we propose a couple of neural networks, namely solver and preselector, which yield an interpretable neural representation of the hidden physical constraint. After they are jointly trained, the solver network approximates potential candidates, e.g., partial derivatives, which are then fed to the sparse regression algorithm that initially unveils the most likely parsimonious PDE, decided according to the information criterion. Second, we propose the denoising physics-informed neural networks (dPINNs), based on Discrete Fourier Transform (DFT), to deliver a set of the optimal finetuned PDE coefficients respecting the noise-reduced variables. The denoising PINNs' structures are compartmentalized into forefront projection networks and a PINN, by which the formerly learned solver initializes. Our extensive experiments on five canonical PDEs affirm that the proposed framework presents a robust and interpretable approach for PDE discovery, applicable to a wide range of systems, possibly complicated by noise.
Subspace clustering in high-dimensions: Phase transitions \& Statistical-to-Computational gap
May 26, 2022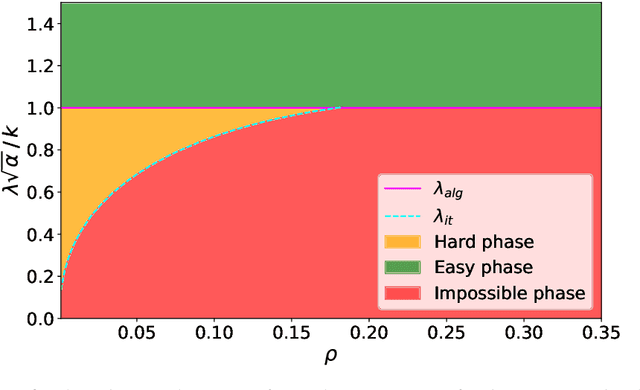
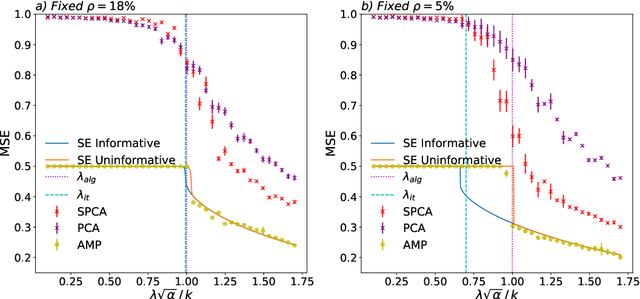
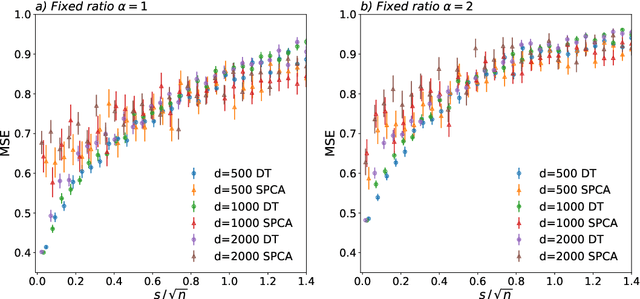
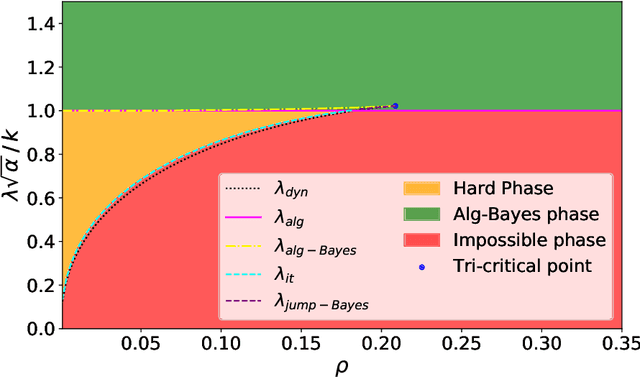
A simple model to study subspace clustering is the high-dimensional $k$-Gaussian mixture model where the cluster means are sparse vectors. Here we provide an exact asymptotic characterization of the statistically optimal reconstruction error in this model in the high-dimensional regime with extensive sparsity, i.e. when the fraction of non-zero components of the cluster means $\rho$, as well as the ratio $\alpha$ between the number of samples and the dimension are fixed, while the dimension diverges. We identify the information-theoretic threshold below which obtaining a positive correlation with the true cluster means is statistically impossible. Additionally, we investigate the performance of the approximate message passing (AMP) algorithm analyzed via its state evolution, which is conjectured to be optimal among polynomial algorithm for this task. We identify in particular the existence of a statistical-to-computational gap between the algorithm that require a signal-to-noise ratio $\lambda_{\text{alg}} \ge k / \sqrt{\alpha} $ to perform better than random, and the information theoretic threshold at $\lambda_{\text{it}} \approx \sqrt{-k \rho \log{\rho}} / \sqrt{\alpha}$. Finally, we discuss the case of sub-extensive sparsity $\rho$ by comparing the performance of the AMP with other sparsity-enhancing algorithms, such as sparse-PCA and diagonal thresholding.
Fundamental Limits of Communication Efficiency for Model Aggregation in Distributed Learning: A Rate-Distortion Approach
Jun 28, 2022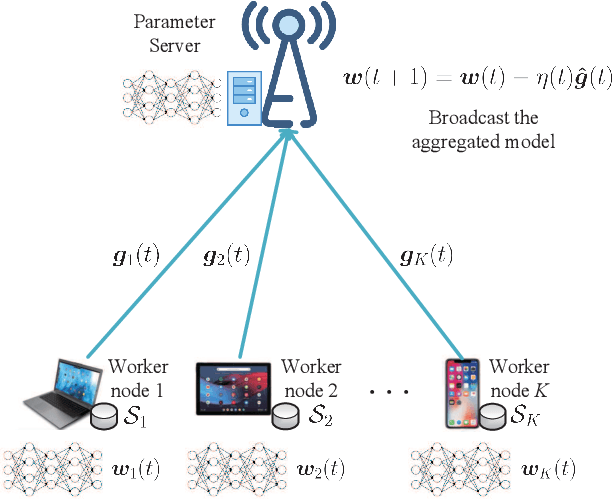
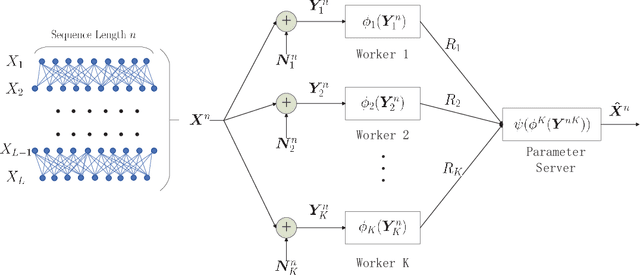
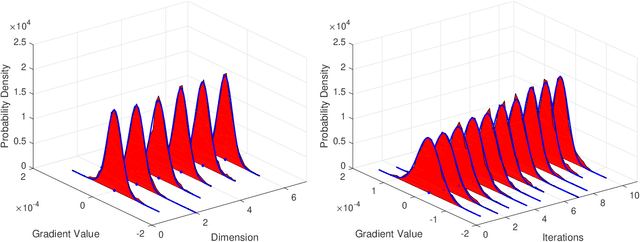
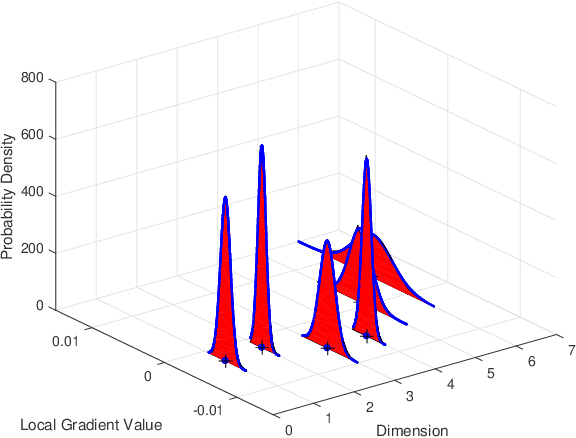
One of the main focuses in distributed learning is communication efficiency, since model aggregation at each round of training can consist of millions to billions of parameters. Several model compression methods, such as gradient quantization and sparsification, have been proposed to improve the communication efficiency of model aggregation. However, the information-theoretic minimum communication cost for a given distortion of gradient estimators is still unknown. In this paper, we study the fundamental limit of communication cost of model aggregation in distributed learning from a rate-distortion perspective. By formulating the model aggregation as a vector Gaussian CEO problem, we derive the rate region bound and sum-rate-distortion function for the model aggregation problem, which reveals the minimum communication rate at a particular gradient distortion upper bound. We also analyze the communication cost at each iteration and total communication cost based on the sum-rate-distortion function with the gradient statistics of real-world datasets. It is found that the communication gain by exploiting the correlation between worker nodes is significant for SignSGD, and a high distortion of gradient estimator can achieve low total communication cost in gradient compression.