 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Doubly-Iterative Sparsified MMSE Turbo Equalization for OTFS Modulation
Jul 02, 2022
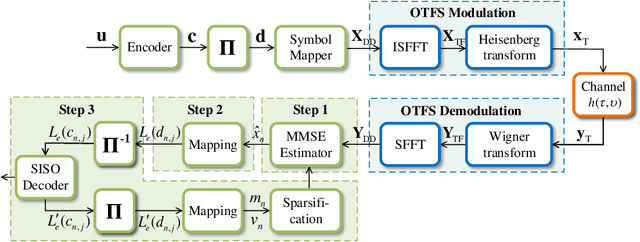
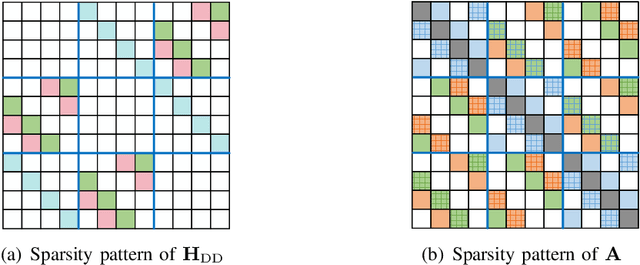
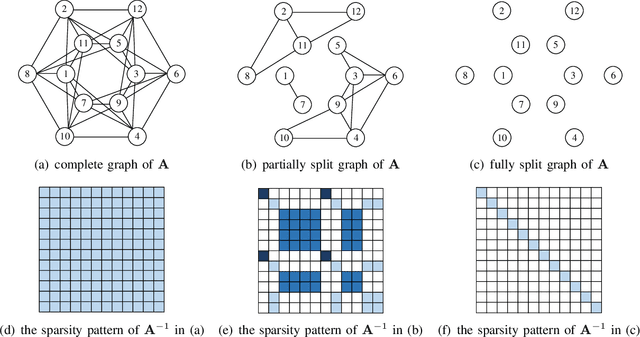
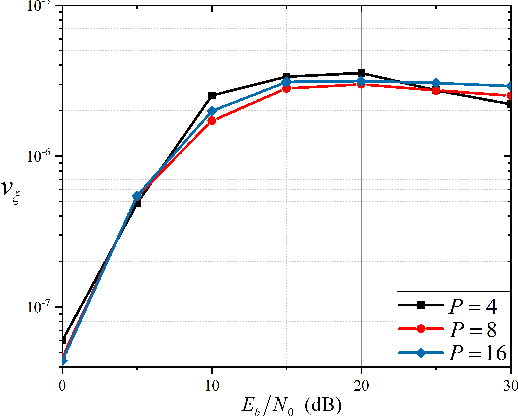
Currently, orthogonal time frequency space (OTFS) modulation has drawn much attention to reliable communications in high-mobility scenarios. This paper proposes a doubly-iterative sparsified minimum mean square error (DI-S-MMSE) turbo equalizer, which iteratively exchanges the extrinsic information between a soft-input-soft-input (SISO) MMSE estimator and a SISO decoder. Our proposed equalizer does not suffer from short loops and approaches the performance of the near-optimal symbol-wise maximum a posteriori (MAP) algorithm. To exploit the inherent sparsity of OTFS system, we resort to graph theory to investigate the sparsity pattern of the channel matrix, and propose two sparsification guidelines to reduce the complexity of calculating the matrix inverse at the MMSE estimator. Then, we apply two iterative algorithms to MMSE estimation, i.e., the Generalized Minimal Residual (GMRES) and Factorized Sparse Approximate Inverse (FSPAI) algorithms. The former is used at the initial turbo iteration, whose global convergence is proven in our equalizer, while the latter is used at the subsequent turbo iterations with the help of our proposed guidelines. Simulation results demonstrate that our equalizer has a linear order of complexity while the performance loss incurred by the sparsification is only 0.2 dB at $10^{-4}$ bit error rate.
Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
Jul 13, 2022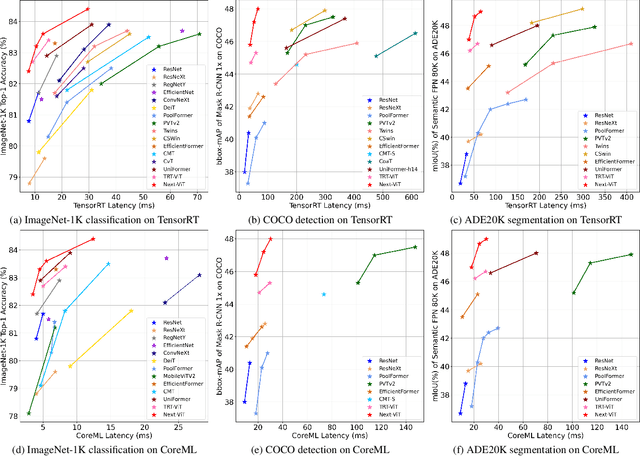
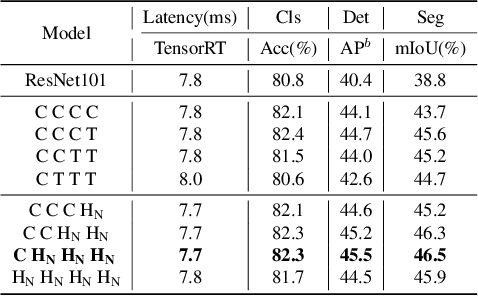
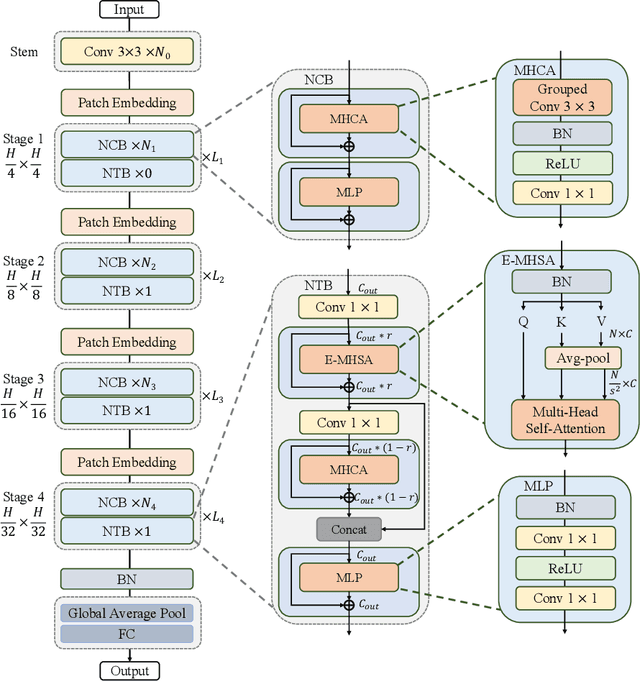
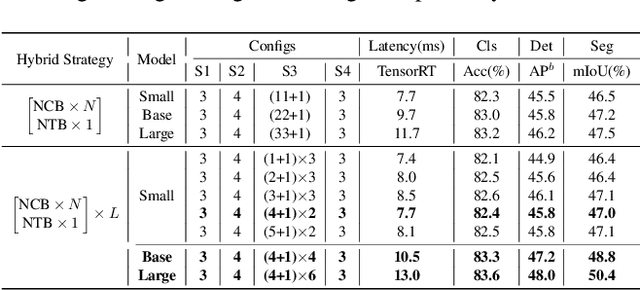
Due to the complex attention mechanisms and model design, most existing vision Transformers (ViTs) can not perform as efficiently as convolutional neural networks (CNNs) in realistic industrial deployment scenarios, e.g. TensorRT and CoreML. This poses a distinct challenge: Can a visual neural network be designed to infer as fast as CNNs and perform as powerful as ViTs? Recent works have tried to design CNN-Transformer hybrid architectures to address this issue, yet the overall performance of these works is far away from satisfactory. To end these, we propose a next generation vision Transformer for efficient deployment in realistic industrial scenarios, namely Next-ViT, which dominates both CNNs and ViTs from the perspective of latency/accuracy trade-off. In this work, the Next Convolution Block (NCB) and Next Transformer Block (NTB) are respectively developed to capture local and global information with deployment-friendly mechanisms. Then, Next Hybrid Strategy (NHS) is designed to stack NCB and NTB in an efficient hybrid paradigm, which boosts performance in various downstream tasks. Extensive experiments show that Next-ViT significantly outperforms existing CNNs, ViTs and CNN-Transformer hybrid architectures with respect to the latency/accuracy trade-off across various vision tasks. On TensorRT, Next-ViT surpasses ResNet by 5.4 mAP (from 40.4 to 45.8) on COCO detection and 8.2% mIoU (from 38.8% to 47.0%) on ADE20K segmentation under similar latency. Meanwhile, it achieves comparable performance with CSWin, while the inference speed is accelerated by 3.6x. On CoreML, Next-ViT surpasses EfficientFormer by 4.6 mAP (from 42.6 to 47.2) on COCO detection and 3.5% mIoU (from 45.2% to 48.7%) on ADE20K segmentation under similar latency. Code will be released recently.
InfoVAEGAN : learning joint interpretable representations by information maximization and maximum likelihood
Jul 09, 2021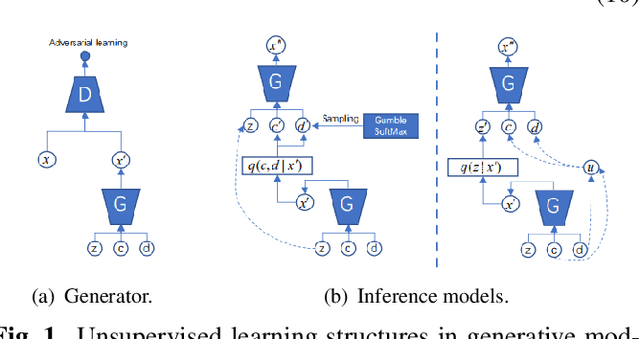
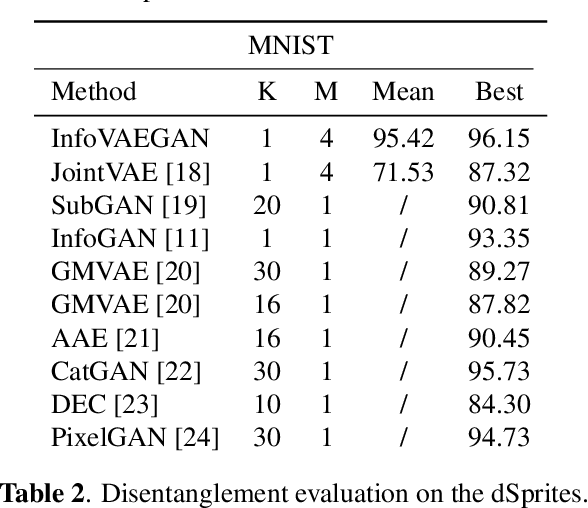

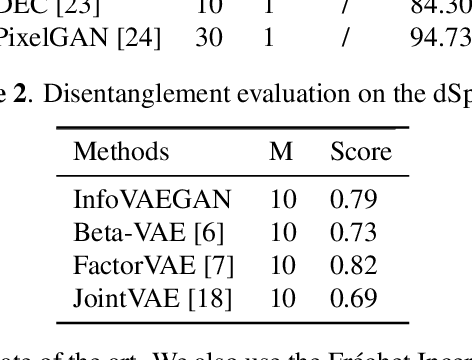
Learning disentangled and interpretable representations is an important step towards accomplishing comprehensive data representations on the manifold. In this paper, we propose a novel representation learning algorithm which combines the inference abilities of Variational Autoencoders (VAE) with the generalization capability of Generative Adversarial Networks (GAN). The proposed model, called InfoVAEGAN, consists of three networks~: Encoder, Generator and Discriminator. InfoVAEGAN aims to jointly learn discrete and continuous interpretable representations in an unsupervised manner by using two different data-free log-likelihood functions onto the variables sampled from the generator's distribution. We propose a two-stage algorithm for optimizing the inference network separately from the generator training. Moreover, we enforce the learning of interpretable representations through the maximization of the mutual information between the existing latent variables and those created through generative and inference processes.
Is a PET all you need? A multi-modal study for Alzheimer's disease using 3D CNNs
Jul 05, 2022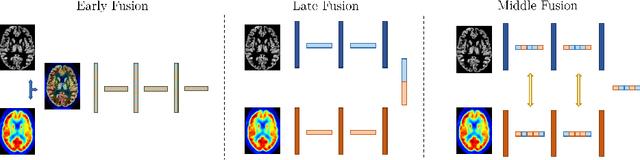
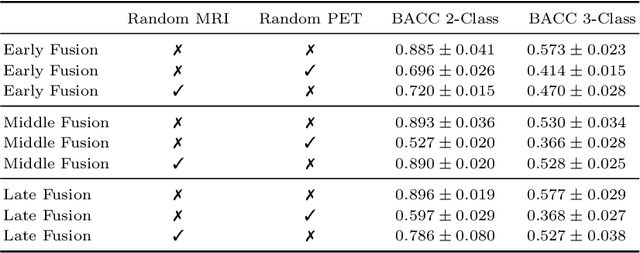

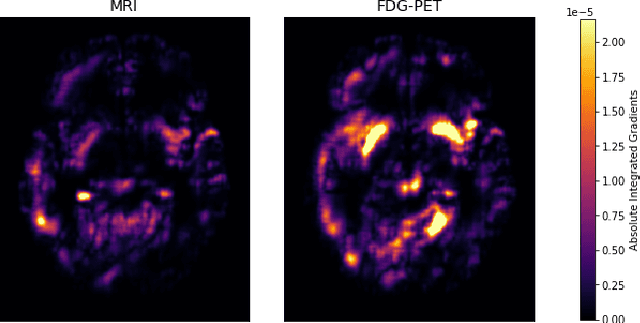
Alzheimer's Disease (AD) is the most common form of dementia and often difficult to diagnose due to the multifactorial etiology of dementia. Recent works on neuroimaging-based computer-aided diagnosis with deep neural networks (DNNs) showed that fusing structural magnetic resonance images (sMRI) and fluorodeoxyglucose positron emission tomography (FDG-PET) leads to improved accuracy in a study population of healthy controls and subjects with AD. However, this result conflicts with the established clinical knowledge that FDG-PET better captures AD-specific pathologies than sMRI. Therefore, we propose a framework for the systematic evaluation of multi-modal DNNs and critically re-evaluate single- and multi-modal DNNs based on FDG-PET and sMRI for binary healthy vs. AD, and three-way healthy/mild cognitive impairment/AD classification. Our experiments demonstrate that a single-modality network using FDG-PET performs better than MRI (accuracy 0.91 vs 0.87) and does not show improvement when combined. This conforms with the established clinical knowledge on AD biomarkers, but raises questions about the true benefit of multi-modal DNNs. We argue that future work on multi-modal fusion should systematically assess the contribution of individual modalities following our proposed evaluation framework. Finally, we encourage the community to go beyond healthy vs. AD classification and focus on differential diagnosis of dementia, where fusing multi-modal image information conforms with a clinical need.
SVoRT: Iterative Transformer for Slice-to-Volume Registration in Fetal Brain MRI
Jun 22, 2022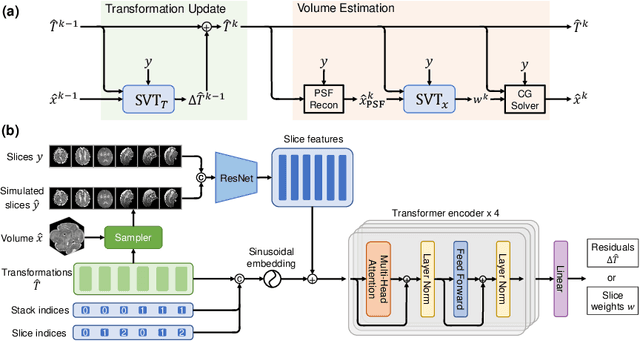
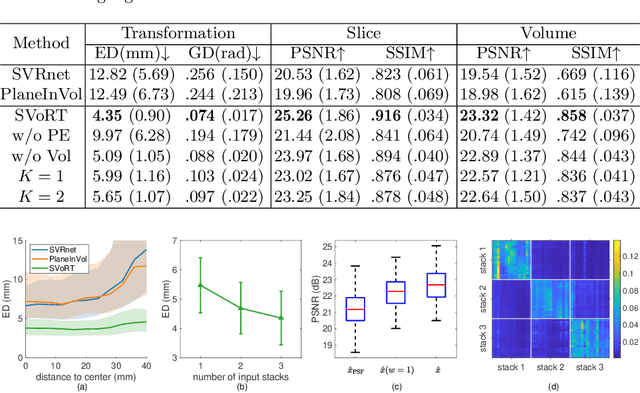
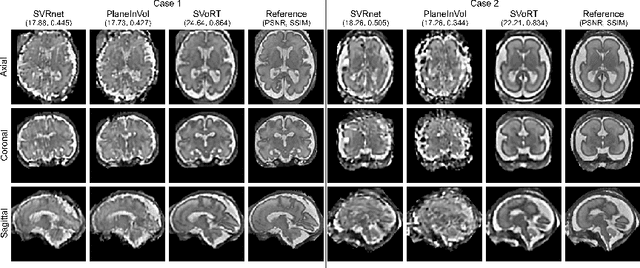
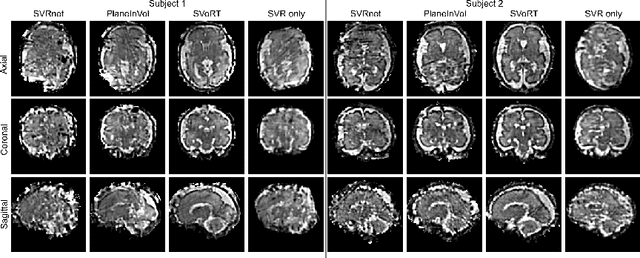
Volumetric reconstruction of fetal brains from multiple stacks of MR slices, acquired in the presence of almost unpredictable and often severe subject motion, is a challenging task that is highly sensitive to the initialization of slice-to-volume transformations. We propose a novel slice-to-volume registration method using Transformers trained on synthetically transformed data, which model multiple stacks of MR slices as a sequence. With the attention mechanism, our model automatically detects the relevance between slices and predicts the transformation of one slice using information from other slices. We also estimate the underlying 3D volume to assist slice-to-volume registration and update the volume and transformations alternately to improve accuracy. Results on synthetic data show that our method achieves lower registration error and better reconstruction quality compared with existing state-of-the-art methods. Experiments with real-world MRI data are also performed to demonstrate the ability of the proposed model to improve the quality of 3D reconstruction under severe fetal motion.
Abnormality Detection and Localization Schemes using Molecular Communication Systems: A Survey
Jul 13, 2022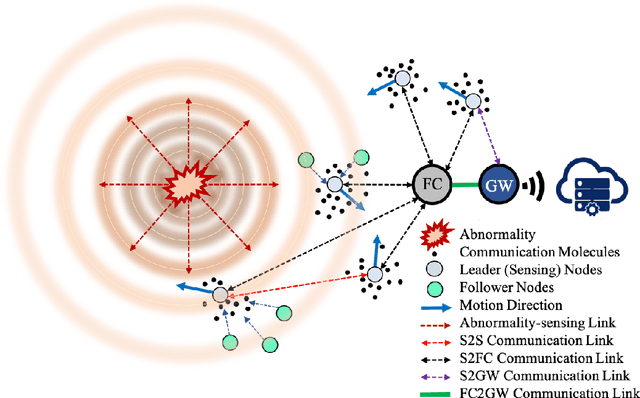
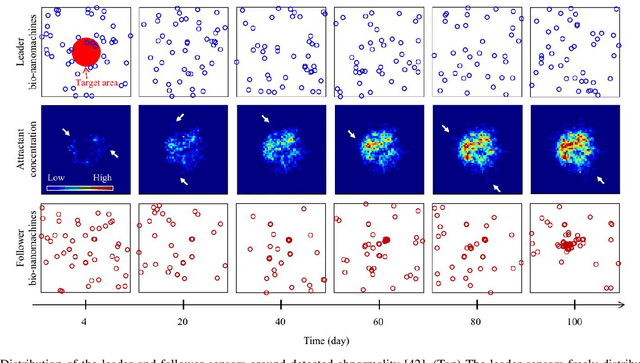
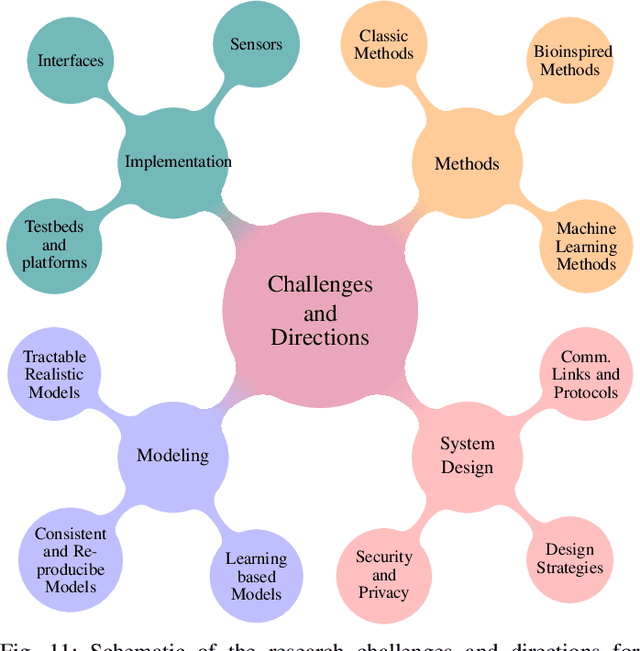
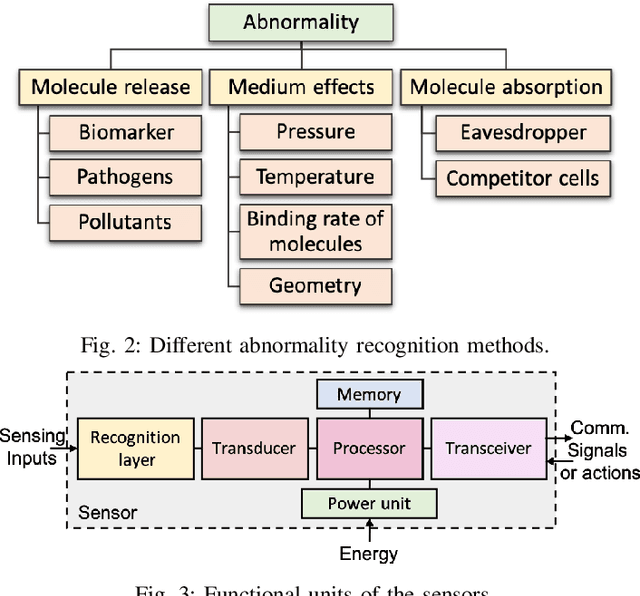
Abnormality, defined as any abnormal feature in the system, may occur in different areas such as healthcare, medicine, cyber security, industry, etc. The detection and localization of the abnormality have been studied widely in wireless sensor networks literature where the sensors use electromagnetic waves for communication. Due to their invasiveness, bio-incompatibility, and high energy consumption for some applications, molecular communication (MC) has been introduced as an alternative approach, which enables promising systems for abnormality detection and localization. In this paper, we overview the MC-based abnormality detection and localization schemes. To do this, we propose a general MC system for abnormality detection and localization to encompass the most related works. The general MC-based abnormality detection and localization system consists of multiple tiers for sensing the abnormality and communication between different agents in the system. We describe different abnormality recognition methods, which can be used by the sensors to obtain information about the abnormality. Further, we describe the functional units of the sensors and different sensor features. We explain different interfaces for connecting the internal and external communication networks and generally model the sensing and communication channels. We formulate the abnormality detection and localization problem using MC systems and present a general framework for the externally-controllable localization systems. We categorize the MC-based abnormality detection schemes based on the sensor mobility, cooperative detection, and cooperative sensing/activation. We classify the localization approaches based on the sensor mobility and propulsion mechanisms. Finally, we provide the ongoing challenges and future research directions to realize and develop MC-based systems for detection and localization of the abnormality.
Experiments on Bipolar Transmission with Direct Detection
May 11, 2022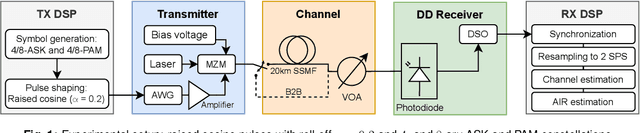
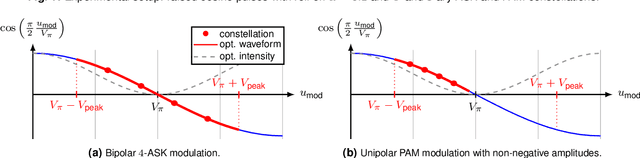
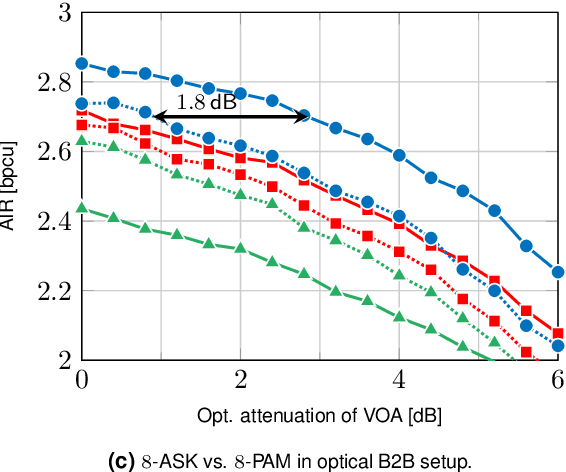
Achievable information rates of bipolar 4- and 8-ary constellations are experimentally compared to those of intensity modulation (IM) when using an oversampled direct detection receiver. The bipolar constellations gain up to 1.8 dB over their IM counterparts.
Single-domain Generalization in Medical Image Segmentation via Test-time Adaptation from Shape Dictionary
Jun 29, 2022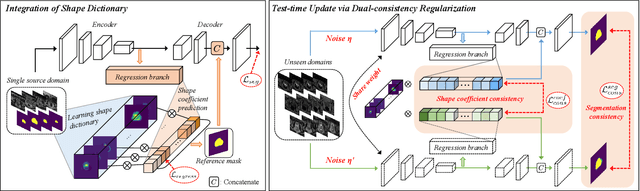
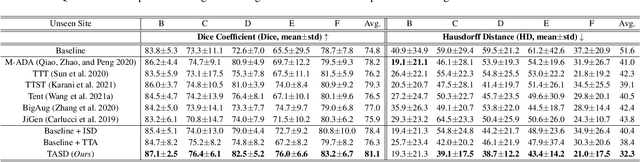

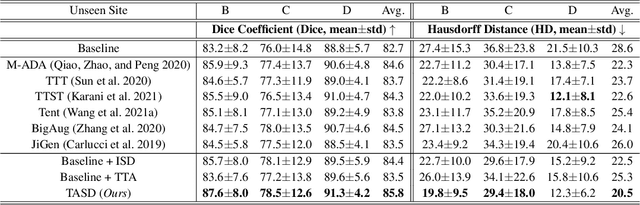
Domain generalization typically requires data from multiple source domains for model learning. However, such strong assumption may not always hold in practice, especially in medical field where the data sharing is highly concerned and sometimes prohibitive due to privacy issue. This paper studies the important yet challenging single domain generalization problem, in which a model is learned under the worst-case scenario with only one source domain to directly generalize to different unseen target domains. We present a novel approach to address this problem in medical image segmentation, which extracts and integrates the semantic shape prior information of segmentation that are invariant across domains and can be well-captured even from single domain data to facilitate segmentation under distribution shifts. Besides, a test-time adaptation strategy with dual-consistency regularization is further devised to promote dynamic incorporation of these shape priors under each unseen domain to improve model generalizability. Extensive experiments on two medical image segmentation tasks demonstrate the consistent improvements of our method across various unseen domains, as well as its superiority over state-of-the-art approaches in addressing domain generalization under the worst-case scenario.
SPI-GAN: Distilling Score-based Generative Models with Straight-Path Interpolations
Jun 29, 2022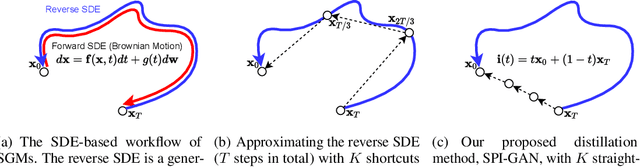
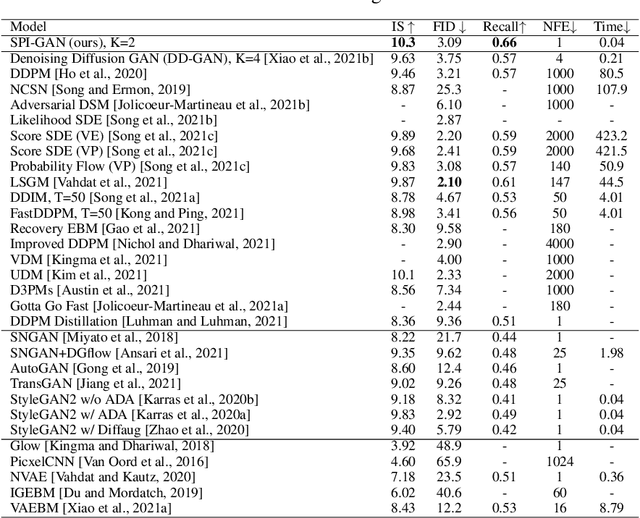
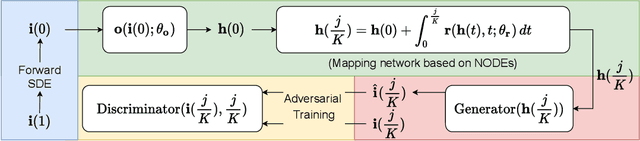
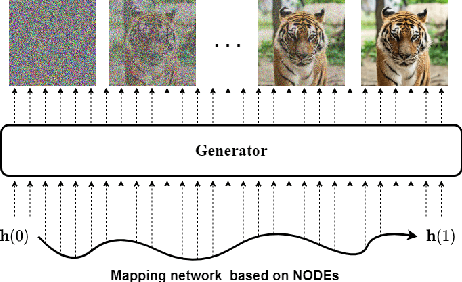
Score-based generative models (SGMs) are a recently proposed paradigm for deep generative tasks and now show the state-of-the-art sampling performance. It is known that the original SGM design solves the two problems of the generative trilemma: i) sampling quality, and ii) sampling diversity. However, the last problem of the trilemma was not solved, i.e., their training/sampling complexity is notoriously high. To this end, distilling SGMs into simpler models, e.g., generative adversarial networks (GANs), is gathering much attention currently. We present an enhanced distillation method, called straight-path interpolation GAN (SPI-GAN), which can be compared to the state-of-the-art shortcut-based distillation method, called denoising diffusion GAN (DD-GAN). However, our method corresponds to an extreme method that does not use any intermediate shortcut information of the reverse SDE path, in which case DD-GAN fails to obtain good results. Nevertheless, our straight-path interpolation method greatly stabilizes the overall training process. As a result, SPI-GAN is one of the best models in terms of the sampling quality/diversity/time for CIFAR-10, CelebA-HQ-256, and LSUN-Church-256.
ImLoveNet: Misaligned Image-supported Registration Network for Low-overlap Point Cloud Pairs
Jul 02, 2022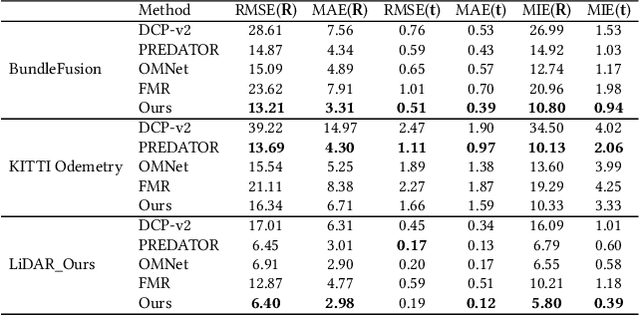
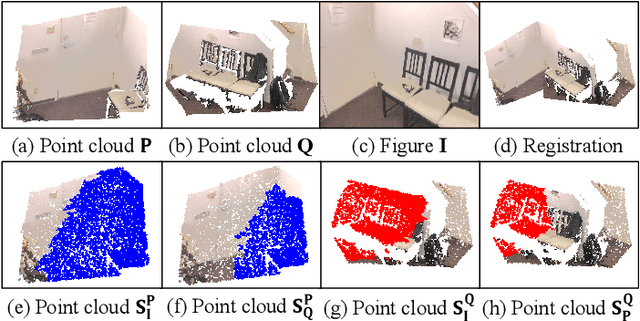
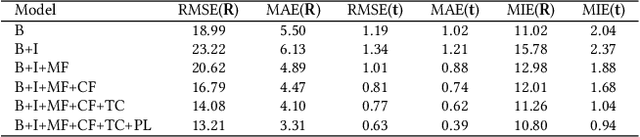
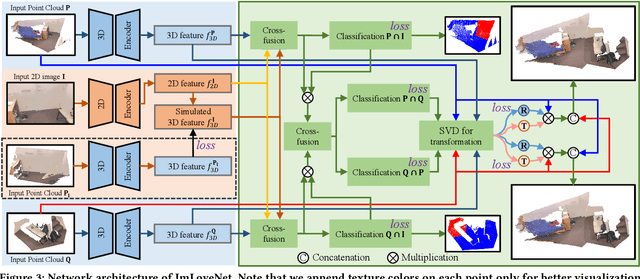
Low-overlap regions between paired point clouds make the captured features very low-confidence, leading cutting edge models to point cloud registration with poor quality. Beyond the traditional wisdom, we raise an intriguing question: Is it possible to exploit an intermediate yet misaligned image between two low-overlap point clouds to enhance the performance of cutting-edge registration models? To answer it, we propose a misaligned image supported registration network for low-overlap point cloud pairs, dubbed ImLoveNet. ImLoveNet first learns triple deep features across different modalities and then exports these features to a two-stage classifier, for progressively obtaining the high-confidence overlap region between the two point clouds. Therefore, soft correspondences are well established on the predicted overlap region, resulting in accurate rigid transformations for registration. ImLoveNet is simple to implement yet effective, since 1) the misaligned image provides clearer overlap information for the two low-overlap point clouds to better locate overlap parts; 2) it contains certain geometry knowledge to extract better deep features; and 3) it does not require the extrinsic parameters of the imaging device with respect to the reference frame of the 3D point cloud. Extensive qualitative and quantitative evaluations on different kinds of benchmarks demonstrate the effectiveness and superiority of our ImLoveNet over state-of-the-art approaches.