 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Interventional Contrastive Learning with Meta Semantic Regularizer
Jun 29, 2022
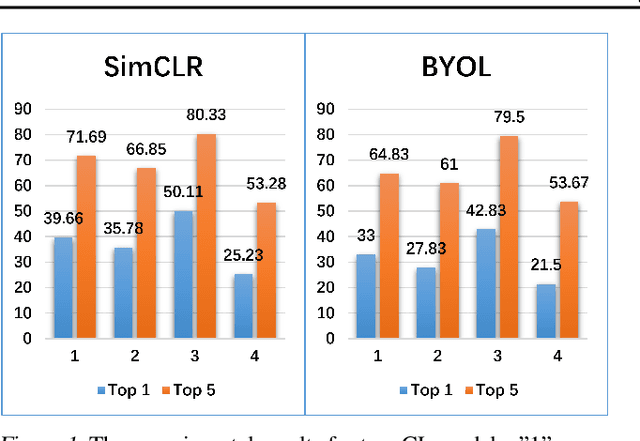
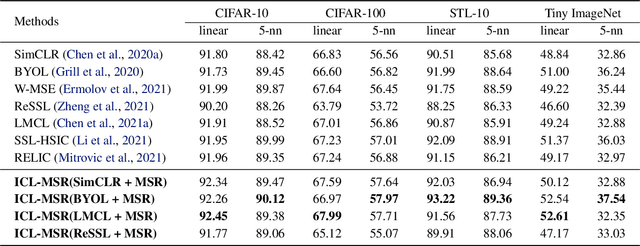
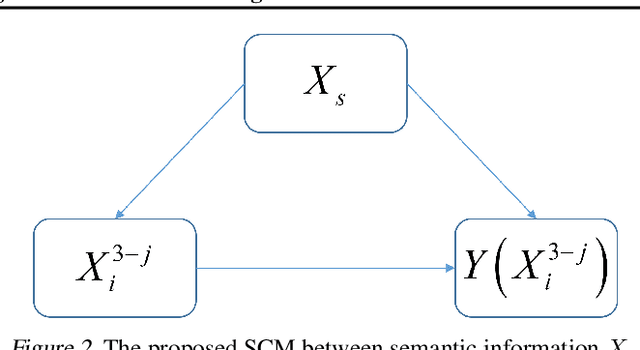
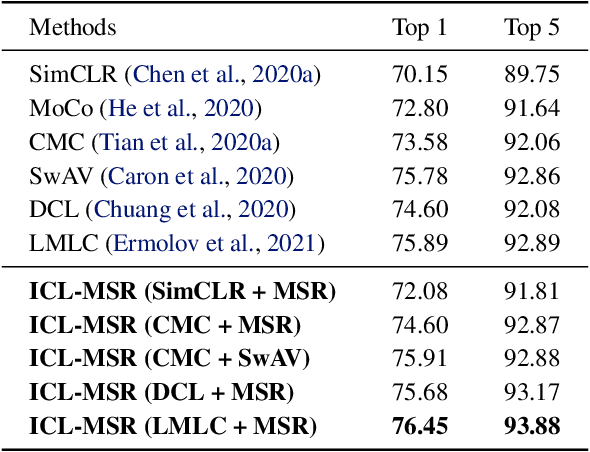
Contrastive learning (CL)-based self-supervised learning models learn visual representations in a pairwise manner. Although the prevailing CL model has achieved great progress, in this paper, we uncover an ever-overlooked phenomenon: When the CL model is trained with full images, the performance tested in full images is better than that in foreground areas; when the CL model is trained with foreground areas, the performance tested in full images is worse than that in foreground areas. This observation reveals that backgrounds in images may interfere with the model learning semantic information and their influence has not been fully eliminated. To tackle this issue, we build a Structural Causal Model (SCM) to model the background as a confounder. We propose a backdoor adjustment-based regularization method, namely Interventional Contrastive Learning with Meta Semantic Regularizer (ICL-MSR), to perform causal intervention towards the proposed SCM. ICL-MSR can be incorporated into any existing CL methods to alleviate background distractions from representation learning. Theoretically, we prove that ICL-MSR achieves a tighter error bound. Empirically, our experiments on multiple benchmark datasets demonstrate that ICL-MSR is able to improve the performances of different state-of-the-art CL methods.
You Are What You Write: Preserving Privacy in the Era of Large Language Models
Apr 20, 2022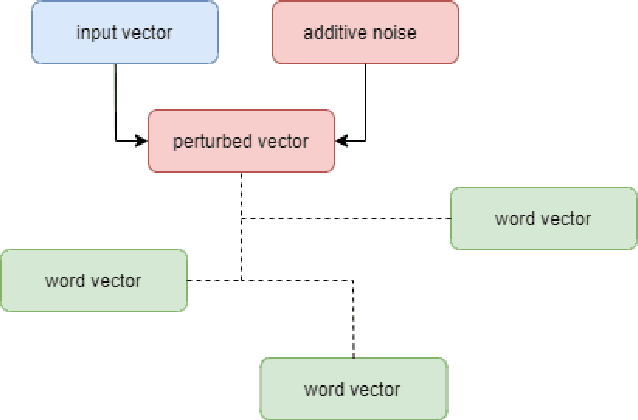

Large scale adoption of large language models has introduced a new era of convenient knowledge transfer for a slew of natural language processing tasks. However, these models also run the risk of undermining user trust by exposing unwanted information about the data subjects, which may be extracted by a malicious party, e.g. through adversarial attacks. We present an empirical investigation into the extent of the personal information encoded into pre-trained representations by a range of popular models, and we show a positive correlation between the complexity of a model, the amount of data used in pre-training, and data leakage. In this paper, we present the first wide coverage evaluation and comparison of some of the most popular privacy-preserving algorithms, on a large, multi-lingual dataset on sentiment analysis annotated with demographic information (location, age and gender). The results show since larger and more complex models are more prone to leaking private information, use of privacy-preserving methods is highly desirable. We also find that highly privacy-preserving technologies like differential privacy (DP) can have serious model utility effects, which can be ameliorated using hybrid or metric-DP techniques.
Tracing Knowledge in Language Models Back to the Training Data
May 24, 2022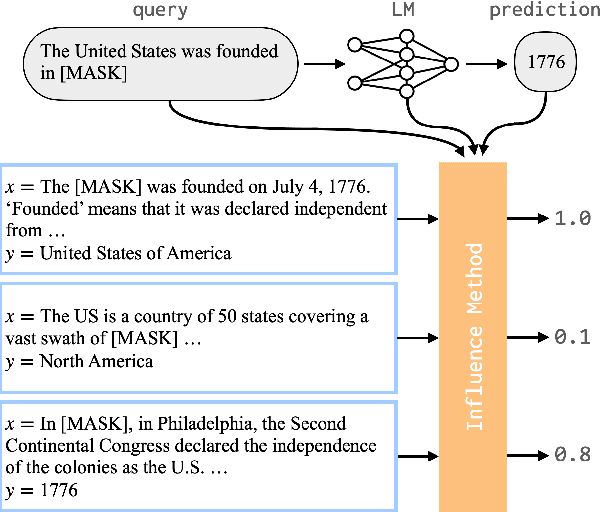
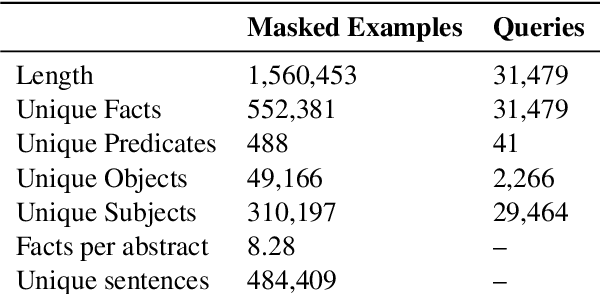
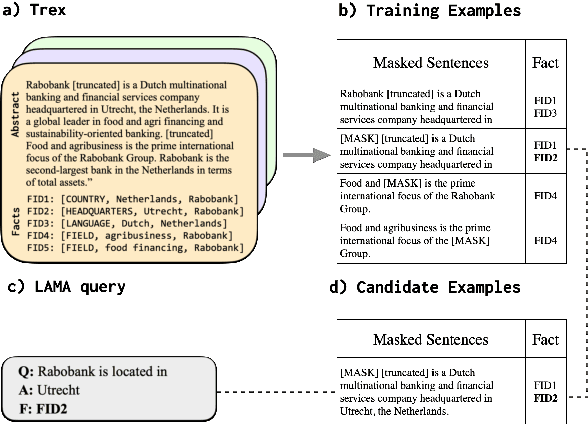
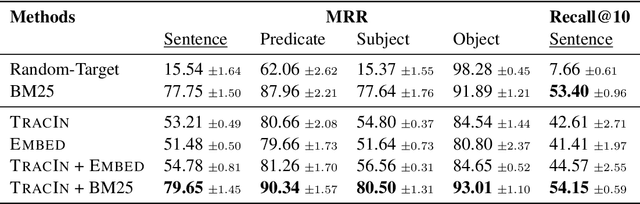
Neural language models (LMs) have been shown to memorize a great deal of factual knowledge. But when an LM generates an assertion, it is often difficult to determine where it learned this information and whether it is true. In this paper, we introduce a new benchmark for fact tracing: tracing language models' assertions back to the training examples that provided evidence for those predictions. Prior work has suggested that dataset-level influence methods might offer an effective framework for tracing predictions back to training data. However, such methods have not been evaluated for fact tracing, and researchers primarily have studied them through qualitative analysis or as a data cleaning technique for classification/regression tasks. We present the first experiments that evaluate influence methods for fact tracing, using well-understood information retrieval (IR) metrics. We compare two popular families of influence methods -- gradient-based and embedding-based -- and show that neither can fact-trace reliably; indeed, both methods fail to outperform an IR baseline (BM25) that does not even access the LM. We explore why this occurs (e.g., gradient saturation) and demonstrate that existing influence methods must be improved significantly before they can reliably attribute factual predictions in LMs.
Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
Jul 13, 2022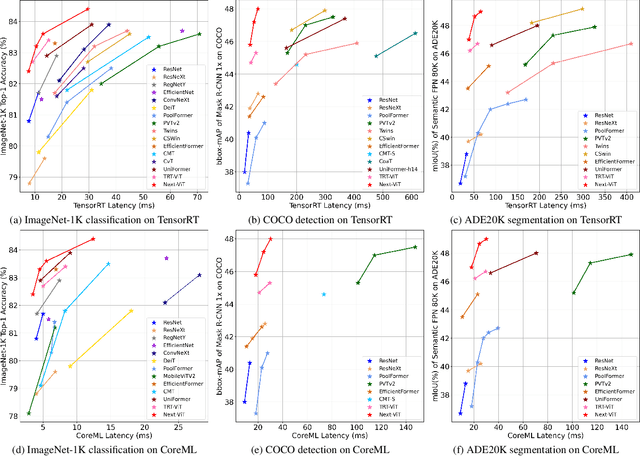
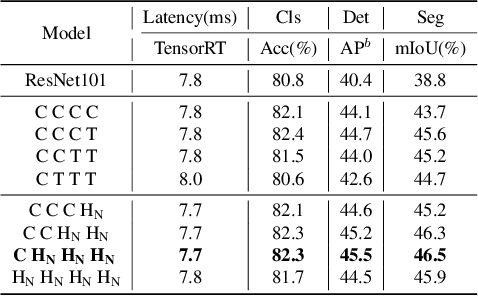
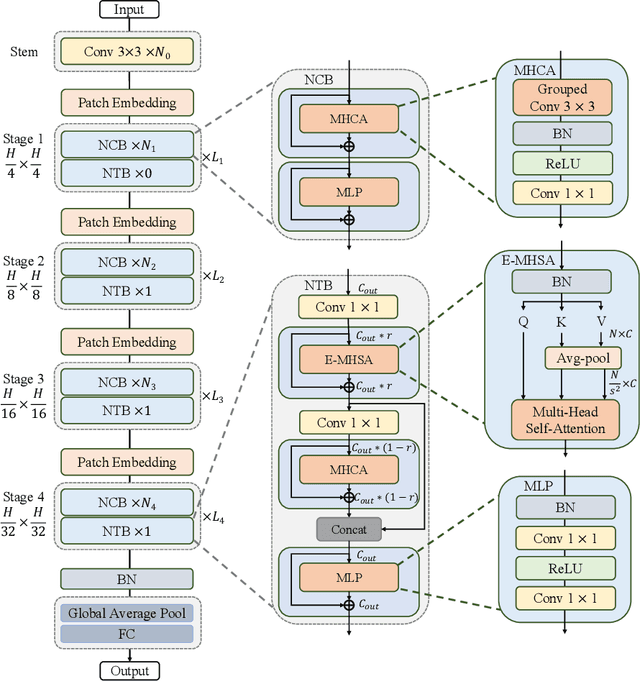
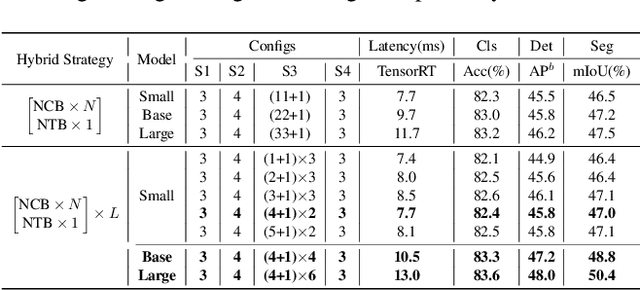
Due to the complex attention mechanisms and model design, most existing vision Transformers (ViTs) can not perform as efficiently as convolutional neural networks (CNNs) in realistic industrial deployment scenarios, e.g. TensorRT and CoreML. This poses a distinct challenge: Can a visual neural network be designed to infer as fast as CNNs and perform as powerful as ViTs? Recent works have tried to design CNN-Transformer hybrid architectures to address this issue, yet the overall performance of these works is far away from satisfactory. To end these, we propose a next generation vision Transformer for efficient deployment in realistic industrial scenarios, namely Next-ViT, which dominates both CNNs and ViTs from the perspective of latency/accuracy trade-off. In this work, the Next Convolution Block (NCB) and Next Transformer Block (NTB) are respectively developed to capture local and global information with deployment-friendly mechanisms. Then, Next Hybrid Strategy (NHS) is designed to stack NCB and NTB in an efficient hybrid paradigm, which boosts performance in various downstream tasks. Extensive experiments show that Next-ViT significantly outperforms existing CNNs, ViTs and CNN-Transformer hybrid architectures with respect to the latency/accuracy trade-off across various vision tasks. On TensorRT, Next-ViT surpasses ResNet by 5.4 mAP (from 40.4 to 45.8) on COCO detection and 8.2% mIoU (from 38.8% to 47.0%) on ADE20K segmentation under similar latency. Meanwhile, it achieves comparable performance with CSWin, while the inference speed is accelerated by 3.6x. On CoreML, Next-ViT surpasses EfficientFormer by 4.6 mAP (from 42.6 to 47.2) on COCO detection and 3.5% mIoU (from 45.2% to 48.7%) on ADE20K segmentation under similar latency. Code will be released recently.
Efficient $Φ$-Regret Minimization in Extensive-Form Games via Online Mirror Descent
May 30, 2022A conceptually appealing approach for learning Extensive-Form Games (EFGs) is to convert them to Normal-Form Games (NFGs). This approach enables us to directly translate state-of-the-art techniques and analyses in NFGs to learning EFGs, but typically suffers from computational intractability due to the exponential blow-up of the game size introduced by the conversion. In this paper, we address this problem in natural and important setups for the \emph{$\Phi$-Hedge} algorithm -- A generic algorithm capable of learning a large class of equilibria for NFGs. We show that $\Phi$-Hedge can be directly used to learn Nash Equilibria (zero-sum settings), Normal-Form Coarse Correlated Equilibria (NFCCE), and Extensive-Form Correlated Equilibria (EFCE) in EFGs. We prove that, in those settings, the \emph{$\Phi$-Hedge} algorithms are equivalent to standard Online Mirror Descent (OMD) algorithms for EFGs with suitable dilated regularizers, and run in polynomial time. This new connection further allows us to design and analyze a new class of OMD algorithms based on modifying its log-partition function. In particular, we design an improved algorithm with balancing techniques that achieves a sharp $\widetilde{\mathcal{O}}(\sqrt{XAT})$ EFCE-regret under bandit-feedback in an EFG with $X$ information sets, $A$ actions, and $T$ episodes. To our best knowledge, this is the first such rate and matches the information-theoretic lower bound.
Abnormality Detection and Localization Schemes using Molecular Communication Systems: A Survey
Jul 13, 2022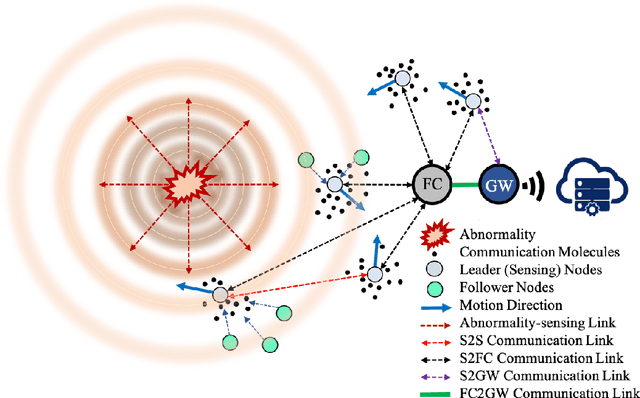
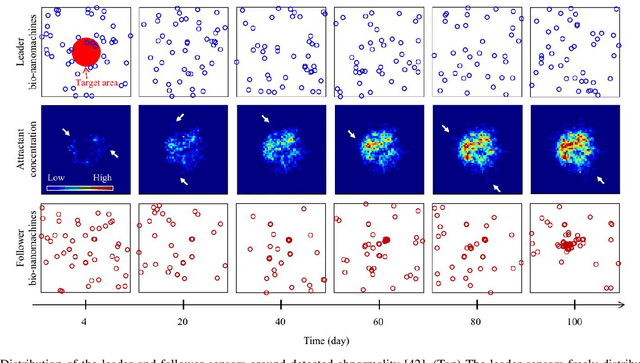
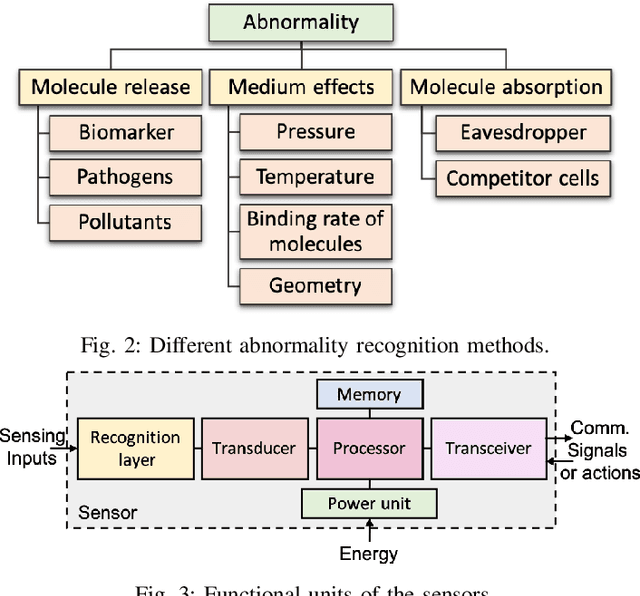
Abnormality, defined as any abnormal feature in the system, may occur in different areas such as healthcare, medicine, cyber security, industry, etc. The detection and localization of the abnormality have been studied widely in wireless sensor networks literature where the sensors use electromagnetic waves for communication. Due to their invasiveness, bio-incompatibility, and high energy consumption for some applications, molecular communication (MC) has been introduced as an alternative approach, which enables promising systems for abnormality detection and localization. In this paper, we overview the MC-based abnormality detection and localization schemes. To do this, we propose a general MC system for abnormality detection and localization to encompass the most related works. The general MC-based abnormality detection and localization system consists of multiple tiers for sensing the abnormality and communication between different agents in the system. We describe different abnormality recognition methods, which can be used by the sensors to obtain information about the abnormality. Further, we describe the functional units of the sensors and different sensor features. We explain different interfaces for connecting the internal and external communication networks and generally model the sensing and communication channels. We formulate the abnormality detection and localization problem using MC systems and present a general framework for the externally-controllable localization systems. We categorize the MC-based abnormality detection schemes based on the sensor mobility, cooperative detection, and cooperative sensing/activation. We classify the localization approaches based on the sensor mobility and propulsion mechanisms. Finally, we provide the ongoing challenges and future research directions to realize and develop MC-based systems for detection and localization of the abnormality.
Is a PET all you need? A multi-modal study for Alzheimer's disease using 3D CNNs
Jul 05, 2022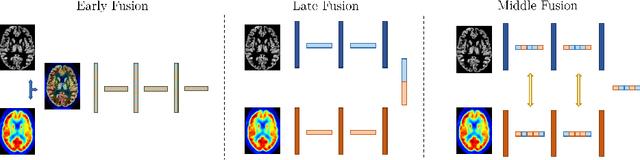
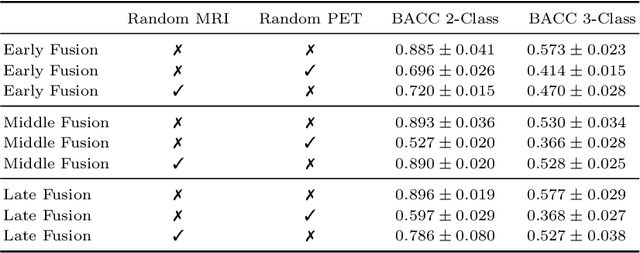

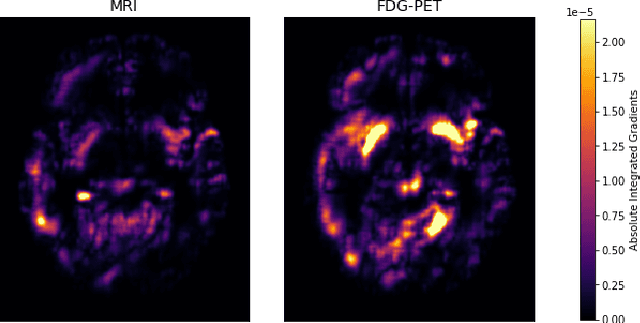
Alzheimer's Disease (AD) is the most common form of dementia and often difficult to diagnose due to the multifactorial etiology of dementia. Recent works on neuroimaging-based computer-aided diagnosis with deep neural networks (DNNs) showed that fusing structural magnetic resonance images (sMRI) and fluorodeoxyglucose positron emission tomography (FDG-PET) leads to improved accuracy in a study population of healthy controls and subjects with AD. However, this result conflicts with the established clinical knowledge that FDG-PET better captures AD-specific pathologies than sMRI. Therefore, we propose a framework for the systematic evaluation of multi-modal DNNs and critically re-evaluate single- and multi-modal DNNs based on FDG-PET and sMRI for binary healthy vs. AD, and three-way healthy/mild cognitive impairment/AD classification. Our experiments demonstrate that a single-modality network using FDG-PET performs better than MRI (accuracy 0.91 vs 0.87) and does not show improvement when combined. This conforms with the established clinical knowledge on AD biomarkers, but raises questions about the true benefit of multi-modal DNNs. We argue that future work on multi-modal fusion should systematically assess the contribution of individual modalities following our proposed evaluation framework. Finally, we encourage the community to go beyond healthy vs. AD classification and focus on differential diagnosis of dementia, where fusing multi-modal image information conforms with a clinical need.
Doubly-Iterative Sparsified MMSE Turbo Equalization for OTFS Modulation
Jul 02, 2022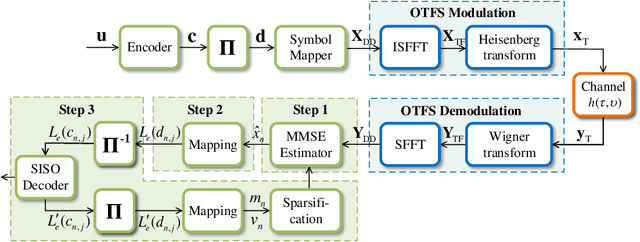
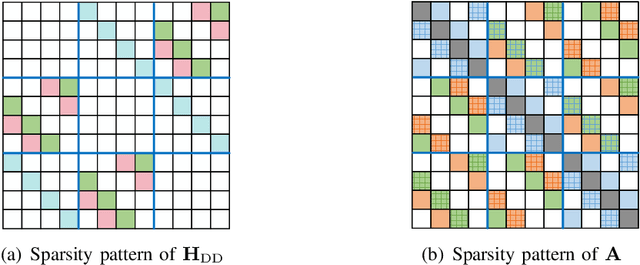
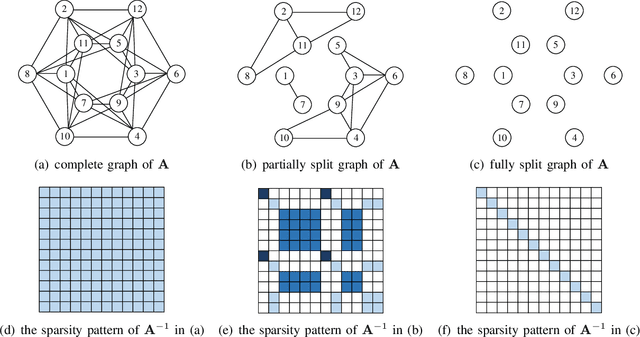
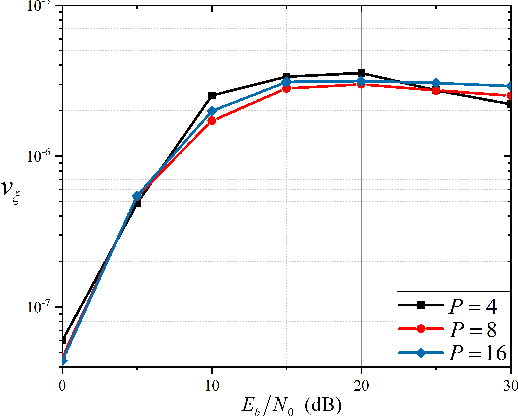
Currently, orthogonal time frequency space (OTFS) modulation has drawn much attention to reliable communications in high-mobility scenarios. This paper proposes a doubly-iterative sparsified minimum mean square error (DI-S-MMSE) turbo equalizer, which iteratively exchanges the extrinsic information between a soft-input-soft-input (SISO) MMSE estimator and a SISO decoder. Our proposed equalizer does not suffer from short loops and approaches the performance of the near-optimal symbol-wise maximum a posteriori (MAP) algorithm. To exploit the inherent sparsity of OTFS system, we resort to graph theory to investigate the sparsity pattern of the channel matrix, and propose two sparsification guidelines to reduce the complexity of calculating the matrix inverse at the MMSE estimator. Then, we apply two iterative algorithms to MMSE estimation, i.e., the Generalized Minimal Residual (GMRES) and Factorized Sparse Approximate Inverse (FSPAI) algorithms. The former is used at the initial turbo iteration, whose global convergence is proven in our equalizer, while the latter is used at the subsequent turbo iterations with the help of our proposed guidelines. Simulation results demonstrate that our equalizer has a linear order of complexity while the performance loss incurred by the sparsification is only 0.2 dB at $10^{-4}$ bit error rate.
Enhanced Security and Privacy via Fragmented Federated Learning
Jul 13, 2022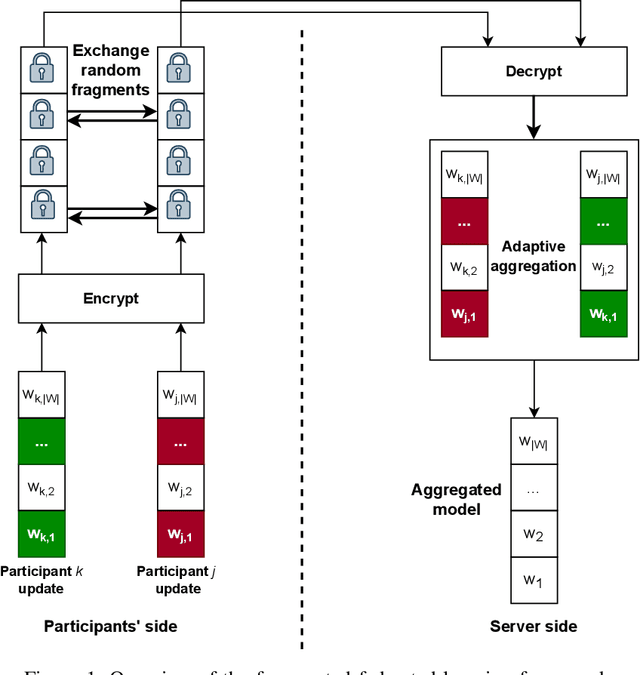


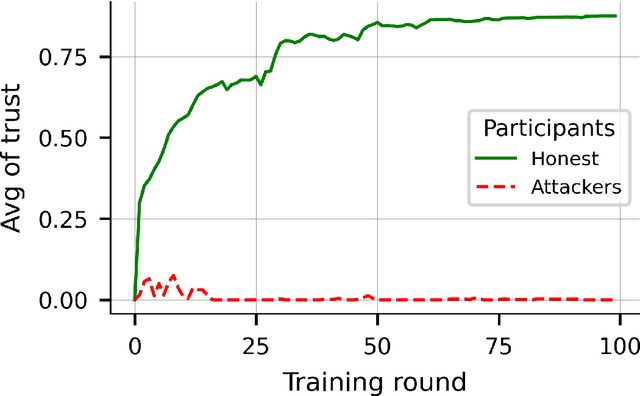
In federated learning (FL), a set of participants share updates computed on their local data with an aggregator server that combines updates into a global model. However, reconciling accuracy with privacy and security is a challenge to FL. On the one hand, good updates sent by honest participants may reveal their private local information, whereas poisoned updates sent by malicious participants may compromise the model's availability and/or integrity. On the other hand, enhancing privacy via update distortion damages accuracy, whereas doing so via update aggregation damages security because it does not allow the server to filter out individual poisoned updates. To tackle the accuracy-privacy-security conflict, we propose {\em fragmented federated learning} (FFL), in which participants randomly exchange and mix fragments of their updates before sending them to the server. To achieve privacy, we design a lightweight protocol that allows participants to privately exchange and mix encrypted fragments of their updates so that the server can neither obtain individual updates nor link them to their originators. To achieve security, we design a reputation-based defense tailored for FFL that builds trust in participants and their mixed updates based on the quality of the fragments they exchange and the mixed updates they send. Since the exchanged fragments' parameters keep their original coordinates and attackers can be neutralized, the server can correctly reconstruct a global model from the received mixed updates without accuracy loss. Experiments on four real data sets show that FFL can prevent semi-honest servers from mounting privacy attacks, can effectively counter poisoning attacks and can keep the accuracy of the global model.
Visual Concepts Tokenization
May 20, 2022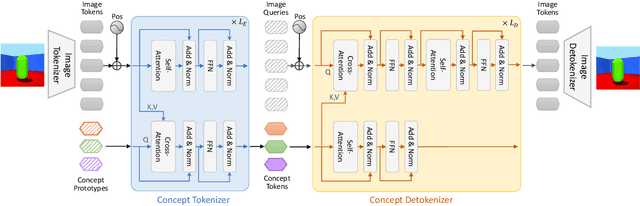
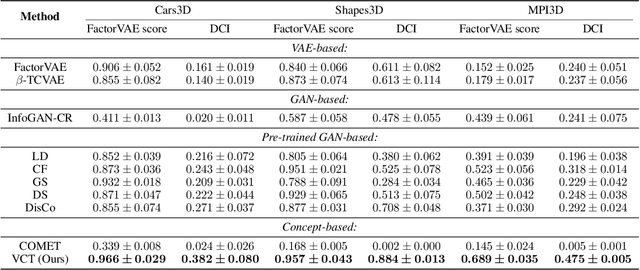
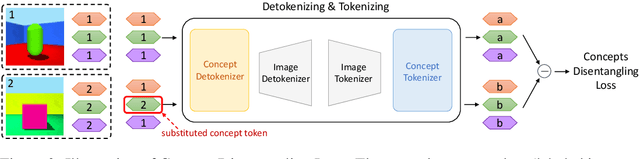
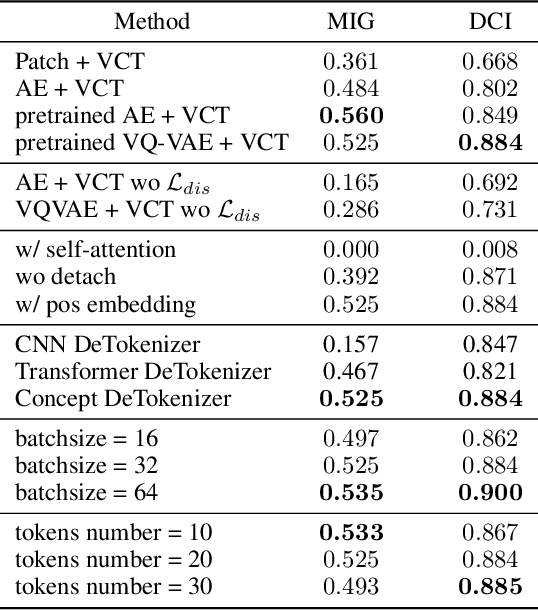
Obtaining the human-like perception ability of abstracting visual concepts from concrete pixels has always been a fundamental and important target in machine learning research fields such as disentangled representation learning and scene decomposition. Towards this goal, we propose an unsupervised transformer-based Visual Concepts Tokenization framework, dubbed VCT, to perceive an image into a set of disentangled visual concept tokens, with each concept token responding to one type of independent visual concept. Particularly, to obtain these concept tokens, we only use cross-attention to extract visual information from the image tokens layer by layer without self-attention between concept tokens, preventing information leakage across concept tokens. We further propose a Concept Disentangling Loss to facilitate that different concept tokens represent independent visual concepts. The cross-attention and disentangling loss play the role of induction and mutual exclusion for the concept tokens, respectively. Extensive experiments on several popular datasets verify the effectiveness of VCT on the tasks of disentangled representation learning and scene decomposition. VCT achieves the state of the art results by a large margin.