 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CSI-Based Localization with CNNs Exploiting Phase Information
Jan 22, 2021
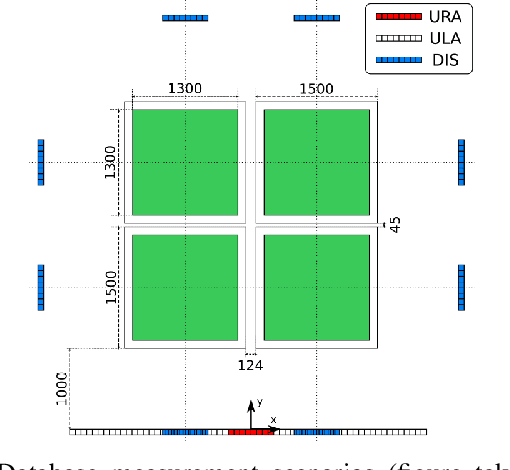
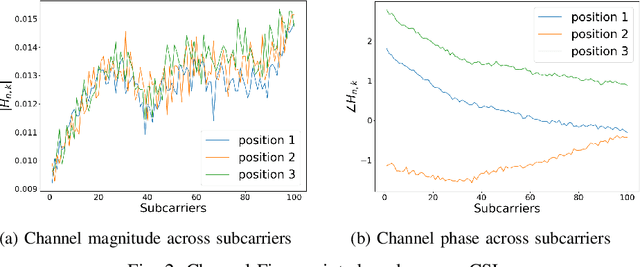
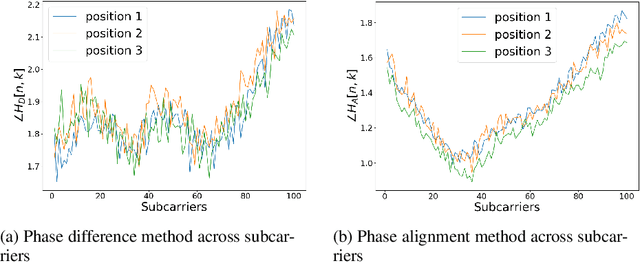
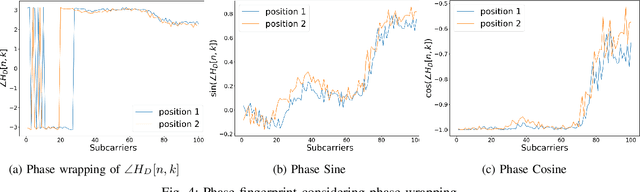
In this paper we study the use of the Channel State Information (CSI) as fingerprint inputs of a Convolutional Neural Network (CNN) for localization. We examine whether the CSI can be used as a distinct fingerprint corresponding to a single position by considering the inconsistencies with its raw phase that cause the CSI to be unreliable. We propose two methods to produce reliable fingerprints including the phase information. Furthermore, we examine the structure of the CNN and more specifically the impact of pooling on the positioning performance, and show that pooling over the subcarriers can be more beneficial than over the antennas.
So3krates -- Self-attention for higher-order geometric interactions on arbitrary length-scales
May 28, 2022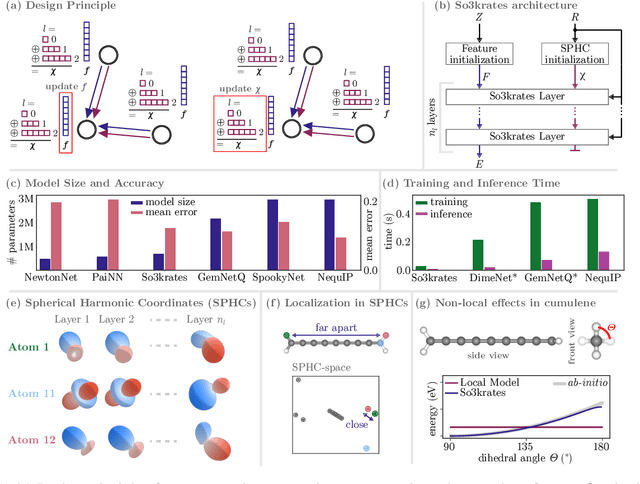
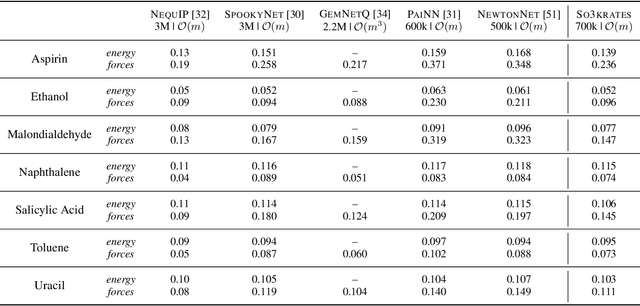
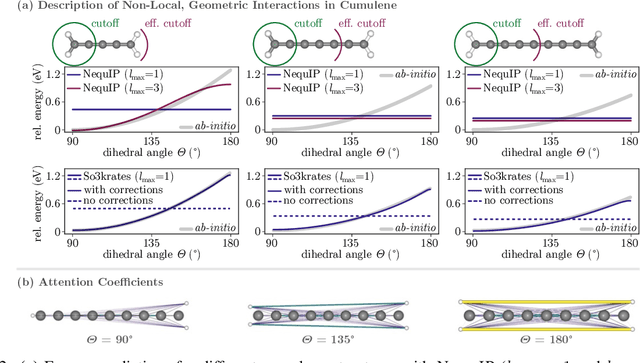

The application of machine learning methods in quantum chemistry has enabled the study of numerous chemical phenomena, which are computationally intractable with traditional ab-initio methods. However, some quantum mechanical properties of molecules and materials depend on non-local electronic effects, which are often neglected due to the difficulty of modeling them efficiently. This work proposes a modified attention mechanism adapted to the underlying physics, which allows to recover the relevant non-local effects. Namely, we introduce spherical harmonic coordinates (SPHCs) to reflect higher-order geometric information for each atom in a molecule, enabling a non-local formulation of attention in the SPHC space. Our proposed model So3krates -- a self-attention based message passing neural network -- uncouples geometric information from atomic features, making them independently amenable to attention mechanisms. We show that in contrast to other published methods, So3krates is able to describe non-local quantum mechanical effects over arbitrary length scales. Further, we find evidence that the inclusion of higher-order geometric correlations increases data efficiency and improves generalization. So3krates matches or exceeds state-of-the-art performance on popular benchmarks, notably, requiring a significantly lower number of parameters (0.25--0.4x) while at the same time giving a substantial speedup (6--14x for training and 2--11x for inference) compared to other models.
Learning-Based Near-Orthogonal Superposition Code for MIMO Short Message Transmission
Jun 30, 2022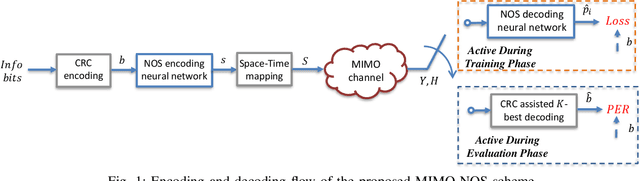
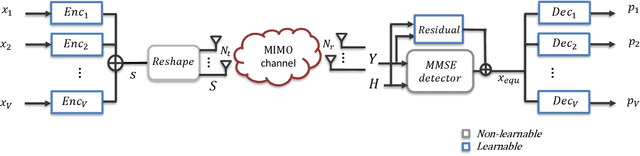
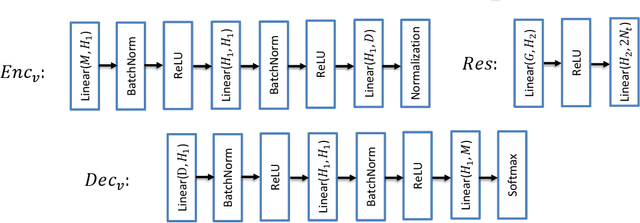
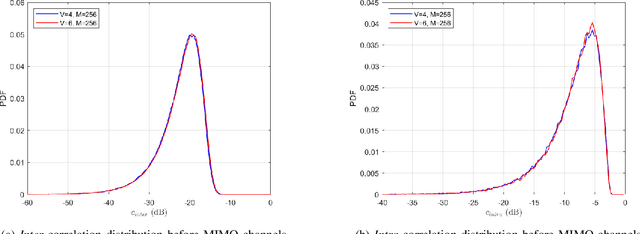
Massive machine type communication (mMTC) has attracted new coding schemes optimized for reliable short message transmission. In this paper, a novel deep learning-based near-orthogonal superposition (NOS) coding scheme is proposed to transmit short messages in multiple-input multiple-output (MIMO) channels for mMTC applications. In the proposed MIMO-NOS scheme, a neural network-based encoder is optimized via end-to-end learning with a corresponding neural network-based detector/decoder in a superposition-based auto-encoder framework including a MIMO channel. The proposed MIMO-NOS encoder spreads the information bits to multiple near-orthogonal high dimensional vectors to be combined (superimposed) into a single vector and reshaped for the space-time transmission. For the receiver, we propose a novel looped K-best tree-search algorithm with cyclic redundancy check (CRC) assistance to enhance the error correcting ability in the block-fading MIMO channel. Simulation results show the proposed MIMO-NOS scheme outperforms maximum likelihood (ML) MIMO detection combined with a polar code with CRC-assisted list decoding by 1-2 dB in various MIMO systems for short (32-64 bit) message transmission.
Regulating Facial Processing Technologies: Tensions Between Legal and Technical Considerations in the Application of Illinois BIPA
May 15, 2022Harms resulting from the development and deployment of facial processing technologies (FPT) have been met with increasing controversy. Several states and cities in the U.S. have banned the use of facial recognition by law enforcement and governments, but FPT are still being developed and used in a wide variety of contexts where they primarily are regulated by state biometric information privacy laws. Among these laws, the 2008 Illinois Biometric Information Privacy Act (BIPA) has generated a significant amount of litigation. Yet, with most BIPA lawsuits reaching settlements before there have been meaningful clarifications of relevant technical intricacies and legal definitions, there remains a great degree of uncertainty as to how exactly this law applies to FPT. What we have found through applications of BIPA in FPT litigation so far, however, points to potential disconnects between technical and legal communities. This paper analyzes what we know based on BIPA court proceedings and highlights these points of tension: areas where the technical operationalization of BIPA may create unintended and undesirable incentives for FPT development, as well as areas where BIPA litigation can bring to light the limitations of solely technical methods in achieving legal privacy values. These factors are relevant for (i) reasoning about biometric information privacy laws as a governing mechanism for FPT, (ii) assessing the potential harms of FPT, and (iii) providing incentives for the mitigation of these harms. By illuminating these considerations, we hope to empower courts and lawmakers to take a more nuanced approach to regulating FPT and developers to better understand privacy values in the current U.S. legal landscape.
Explaining GNN over Evolving Graphs using Information Flow
Nov 19, 2021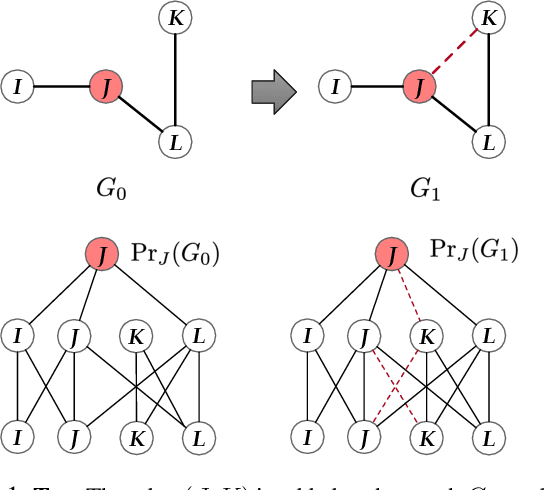
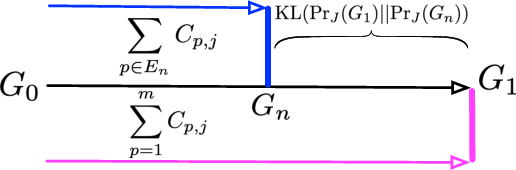
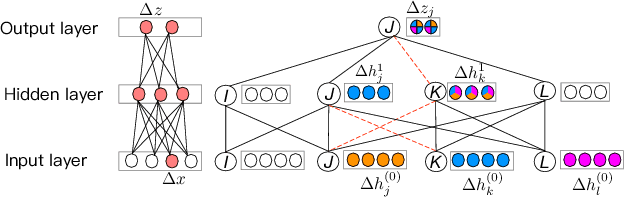
Graphs are ubiquitous in many applications, such as social networks, knowledge graphs, smart grids, etc.. Graph neural networks (GNN) are the current state-of-the-art for these applications, and yet remain obscure to humans. Explaining the GNN predictions can add transparency. However, as many graphs are not static but continuously evolving, explaining changes in predictions between two graph snapshots is different but equally important. Prior methods only explain static predictions or generate coarse or irrelevant explanations for dynamic predictions. We define the problem of explaining evolving GNN predictions and propose an axiomatic attribution method to uniquely decompose the change in a prediction to paths on computation graphs. The attribution to many paths involving high-degree nodes is still not interpretable, while simply selecting the top important paths can be suboptimal in approximating the change. We formulate a novel convex optimization problem to optimally select the paths that explain the prediction evolution. Theoretically, we prove that the existing method based on Layer-Relevance-Propagation (LRP) is a special case of the proposed algorithm when an empty graph is compared with. Empirically, on seven graph datasets, with a novel metric designed for evaluating explanations of prediction change, we demonstrate the superiority of the proposed approach over existing methods, including LRP, DeepLIFT, and other path selection methods.
Mental Illness Classification on Social Media Texts using Deep Learning and Transfer Learning
Jul 03, 2022
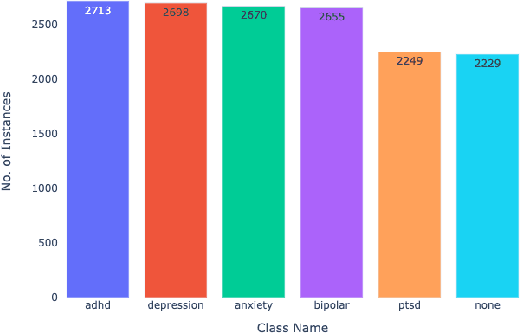
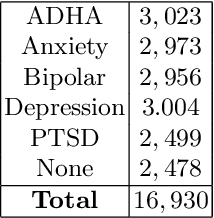
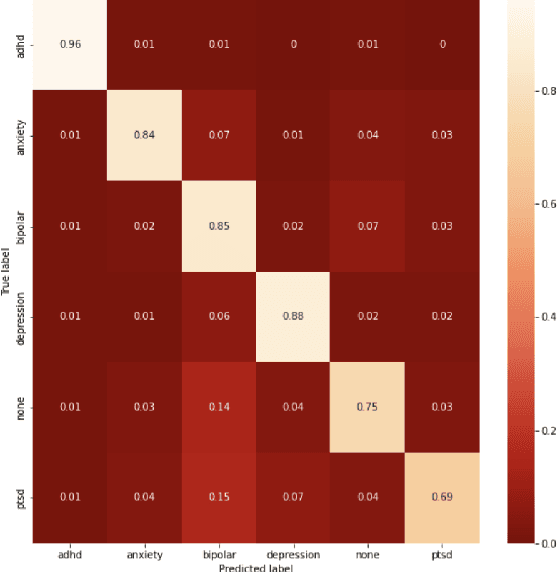
Given the current social distance restrictions across the world, most individuals now use social media as their major medium of communication. Millions of people suffering from mental diseases have been isolated due to this, and they are unable to get help in person. They have become more reliant on online venues to express themselves and seek advice on dealing with their mental disorders. According to the World health organization (WHO), approximately 450 million people are affected. Mental illnesses, such as depression, anxiety, etc., are immensely common and have affected an individuals' physical health. Recently Artificial Intelligence (AI) methods have been presented to help mental health providers, including psychiatrists and psychologists, in decision making based on patients' authentic information (e.g., medical records, behavioral data, social media utilization, etc.). AI innovations have demonstrated predominant execution in numerous real-world applications broadening from computer vision to healthcare. This study analyzes unstructured user data on the Reddit platform and classifies five common mental illnesses: depression, anxiety, bipolar disorder, ADHD, and PTSD. We trained traditional machine learning, deep learning, and transfer learning multi-class models to detect mental disorders of individuals. This effort will benefit the public health system by automating the detection process and informing appropriate authorities about people who require emergency assistance.
JPerceiver: Joint Perception Network for Depth, Pose and Layout Estimation in Driving Scenes
Jul 16, 2022
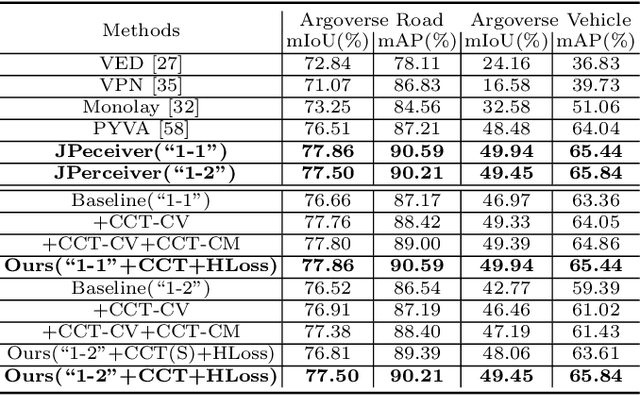
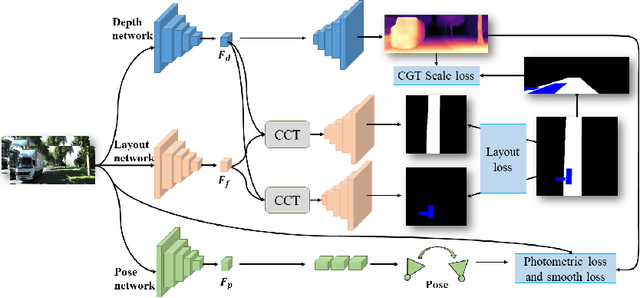
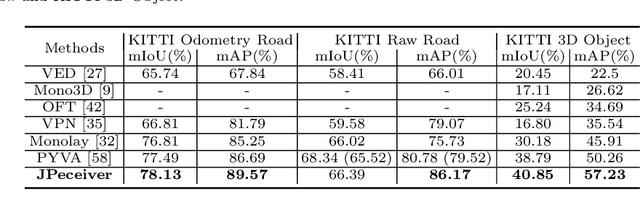
Depth estimation, visual odometry (VO), and bird's-eye-view (BEV) scene layout estimation present three critical tasks for driving scene perception, which is fundamental for motion planning and navigation in autonomous driving. Though they are complementary to each other, prior works usually focus on each individual task and rarely deal with all three tasks together. A naive way is to accomplish them independently in a sequential or parallel manner, but there are many drawbacks, i.e., 1) the depth and VO results suffer from the inherent scale ambiguity issue; 2) the BEV layout is directly predicted from the front-view image without using any depth-related information, although the depth map contains useful geometry clues for inferring scene layouts. In this paper, we address these issues by proposing a novel joint perception framework named JPerceiver, which can simultaneously estimate scale-aware depth and VO as well as BEV layout from a monocular video sequence. It exploits the cross-view geometric transformation (CGT) to propagate the absolute scale from the road layout to depth and VO based on a carefully-designed scale loss. Meanwhile, a cross-view and cross-modal transfer (CCT) module is devised to leverage the depth clues for reasoning road and vehicle layout through an attention mechanism. JPerceiver can be trained in an end-to-end multi-task learning way, where the CGT scale loss and CCT module promote inter-task knowledge transfer to benefit feature learning of each task. Experiments on Argoverse, Nuscenes and KITTI show the superiority of JPerceiver over existing methods on all the above three tasks in terms of accuracy, model size, and inference speed. The code and models are available at~\href{https://github.com/sunnyHelen/JPerceiver}{https://github.com/sunnyHelen/JPerceiver}.
The Information & Mutual Information Ratio for Counting Image Features and Their Matches
May 14, 2020

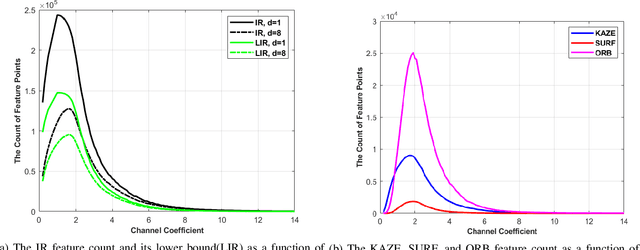
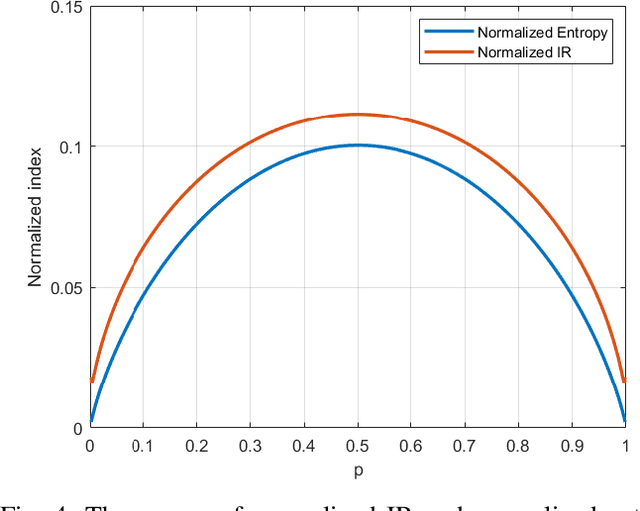
Feature extraction and description is an important topic of computer vision, as it is the starting point of a number of tasks such as image reconstruction, stitching, registration, and recognition among many others. In this paper, two new image features are proposed: the Information Ratio (IR) and the Mutual Information Ratio (MIR). The IR is a feature of a single image, while the MIR describes features common across two or more images.We begin by introducing the IR and the MIR and motivate these features in an information theoretical context as the ratio of the self-information of an intensity level over the information contained over the pixels of the same intensity. Notably, the relationship of the IR and MIR with the image entropy and mutual information, classic information measures, are discussed. Finally, the effectiveness of these features is tested through feature extraction over INRIA Copydays datasets and feature matching over the Oxfords Affine Covariant Regions. These numerical evaluations validate the relevance of the IR and MIR in practical computer vision tasks
SizeShiftReg: a Regularization Method for Improving Size-Generalization in Graph Neural Networks
Jul 16, 2022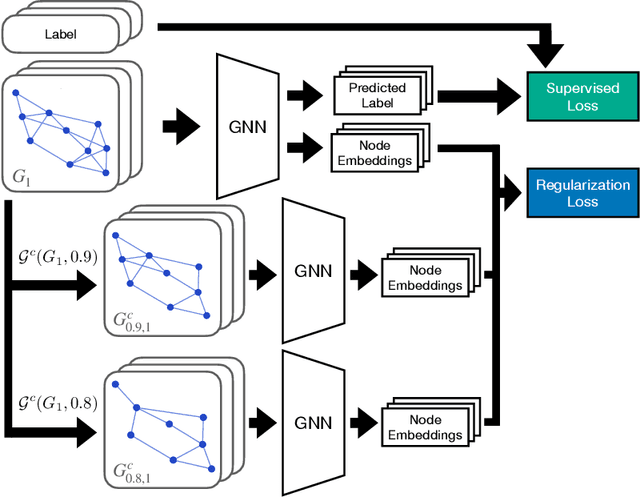

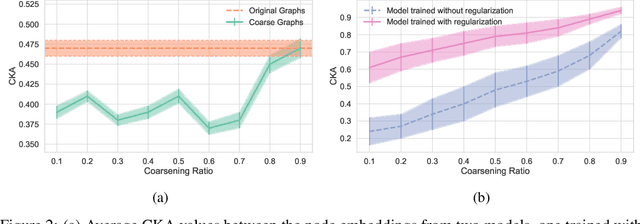

In the past few years, graph neural networks (GNNs) have become the de facto model of choice for graph classification. While, from the theoretical viewpoint, most GNNs can operate on graphs of any size, it is empirically observed that their classification performance degrades when they are applied on graphs with sizes that differ from those in the training data. Previous works have tried to tackle this issue in graph classification by providing the model with inductive biases derived from assumptions on the generative process of the graphs, or by requiring access to graphs from the test domain. The first strategy is tied to the use of ad-hoc models and to the quality of the assumptions made on the generative process, leaving open the question of how to improve the performance of generic GNN models in general settings. On the other hand, the second strategy can be applied to any GNN, but requires access to information that is not always easy to obtain. In this work we consider the scenario in which we only have access to the training data, and we propose a regularization strategy that can be applied to any GNN to improve its generalization capabilities from smaller to larger graphs without requiring access to the test data. Our regularization is based on the idea of simulating a shift in the size of the training graphs using coarsening techniques, and enforcing the model to be robust to such a shift. Experimental results on standard datasets show that popular GNN models, trained on the 50% smallest graphs in the dataset and tested on the 10% largest graphs, obtain performance improvements of up to 30% when trained with our regularization strategy.
Robotic Planning under Uncertainty in Spatiotemporal Environments in Expeditionary Science
Jun 03, 2022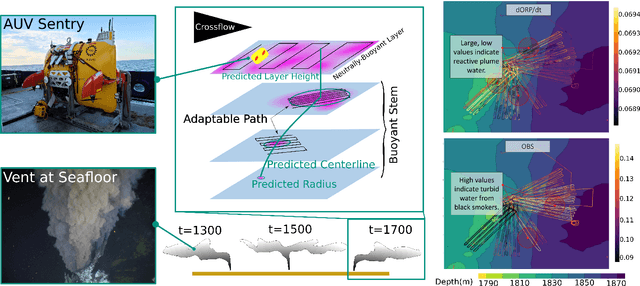
In the expeditionary sciences, spatiotemporally varying environments -- hydrothermal plumes, algal blooms, lava flows, or animal migrations -- are ubiquitous. Mobile robots are uniquely well-suited to study these dynamic, mesoscale natural environments. We formalize expeditionary science as a sequential decision-making problem, modeled using the language of partially-observable Markov decision processes (POMDPs). Solving the expeditionary science POMDP under real-world constraints requires efficient probabilistic modeling and decision-making in problems with complex dynamics and observational models. Previous work in informative path planning, adaptive sampling, and experimental design have shown compelling results, largely in static environments, using data-driven models and information-based rewards. However, these methodologies do not trivially extend to expeditionary science in spatiotemporal environments: they generally do not make use of scientific knowledge such as equations of state dynamics, they focus on information gathering as opposed to scientific task execution, and they make use of decision-making approaches that scale poorly to large, continuous problems with long planning horizons and real-time operational constraints. In this work, we discuss these and other challenges related to probabilistic modeling and decision-making in expeditionary science, and present some of our preliminary work that addresses these gaps. We ground our results in a real expeditionary science deployment of an autonomous underwater vehicle (AUV) in the deep ocean for hydrothermal vent discovery and characterization. Our concluding thoughts highlight remaining work to be done, and the challenges that merit consideration by the reinforcement learning and decision-making community.