 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Planning through Workspace Constraint Satisfaction and Optimization
Jun 16, 2022
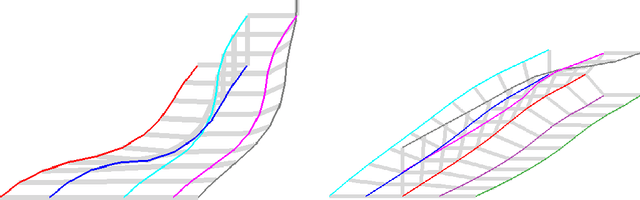
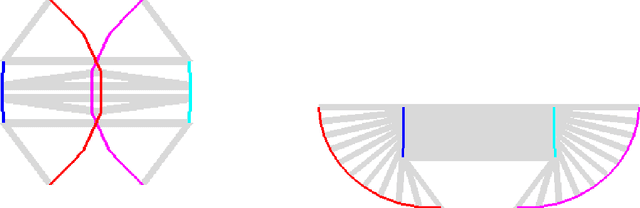
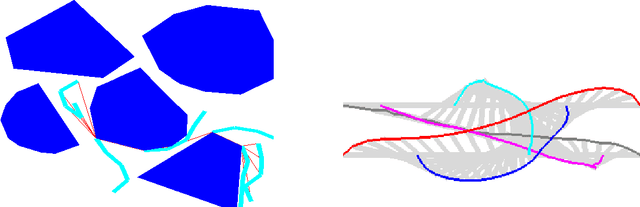
In this work, we present a workspace-based planning framework, which though using redundant workspace key-points to represent robot states, can take advantage of the interpretable geometric information to derive good quality collision-free paths for even complex robots. Using workspace geometries, we first find collision-free piece-wise linear paths for each key point so that at the endpoints of each segment, the distance constraints are satisfied among the key points. Using these piece-wise linear paths as initial conditions, we can perform optimization steps to quickly find paths that satisfy various constraints and piece together all segments to obtain a valid path. We show that these adjusted paths are unlikely to create a collision, and the proposed approach is fast and can produce good quality results.
Explore Spatio-temporal Aggregation for Insubstantial Object Detection: Benchmark Dataset and Baseline
Jun 23, 2022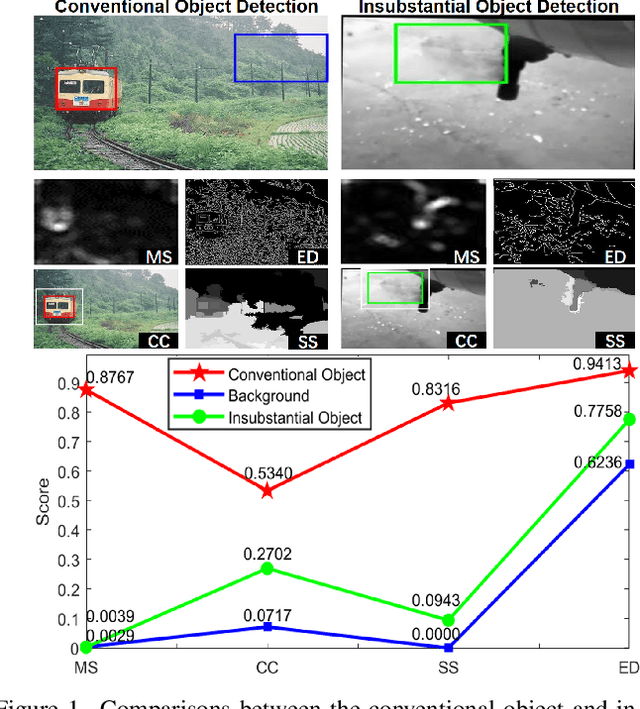
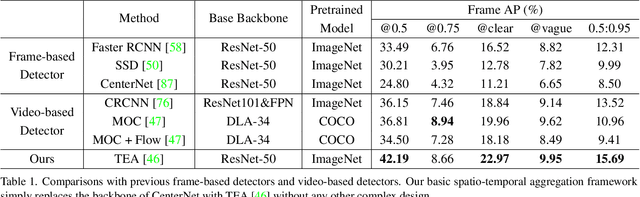
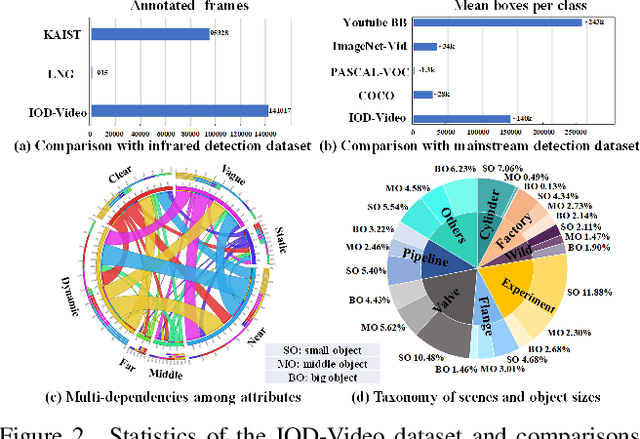
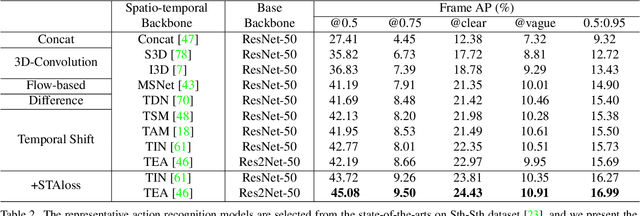
We endeavor on a rarely explored task named Insubstantial Object Detection (IOD), which aims to localize the object with following characteristics: (1) amorphous shape with indistinct boundary; (2) similarity to surroundings; (3) absence in color. Accordingly, it is far more challenging to distinguish insubstantial objects in a single static frame and the collaborative representation of spatial and temporal information is crucial. Thus, we construct an IOD-Video dataset comprised of 600 videos (141,017 frames) covering various distances, sizes, visibility, and scenes captured by different spectral ranges. In addition, we develop a spatio-temporal aggregation framework for IOD, in which different backbones are deployed and a spatio-temporal aggregation loss (STAloss) is elaborately designed to leverage the consistency along the time axis. Experiments conducted on IOD-Video dataset demonstrate that spatio-temporal aggregation can significantly improve the performance of IOD. We hope our work will attract further researches into this valuable yet challenging task. The code will be available at: \url{https://github.com/CalayZhou/IOD-Video}.
LiDAR-as-Camera for End-to-End Driving
Jun 30, 2022


The core task of any autonomous driving system is to transform sensory inputs into driving commands. In end-to-end driving, this is achieved via a neural network, with one or multiple cameras as the most commonly used input and low-level driving command, e.g. steering angle, as output. However, depth-sensing has been shown in simulation to make the end-to-end driving task easier. On a real car, combining depth and visual information can be challenging, due to the difficulty of obtaining good spatial and temporal alignment of the sensors. To alleviate alignment problems, Ouster LiDARs can output surround-view LiDAR-images with depth, intensity, and ambient radiation channels. These measurements originate from the same sensor, rendering them perfectly aligned in time and space. We demonstrate that such LiDAR-images are sufficient for the real-car road-following task and perform at least equally to camera-based models in the tested conditions, with the difference increasing when needing to generalize to new weather conditions. In the second direction of study, we reveal that the temporal smoothness of off-policy prediction sequences correlates equally well with actual on-policy driving ability as the commonly used mean absolute error.
Automatic analysis of artistic paintings using information-based measures
Feb 02, 2021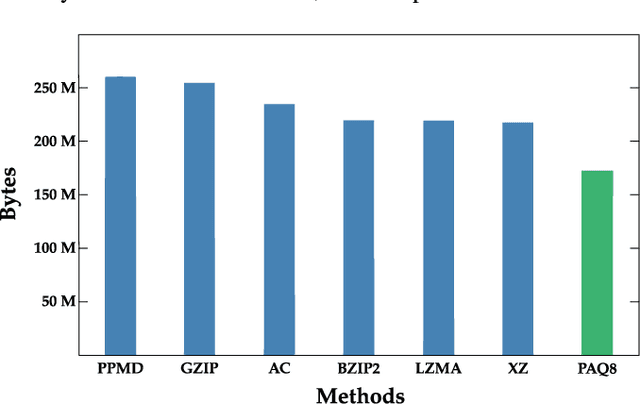

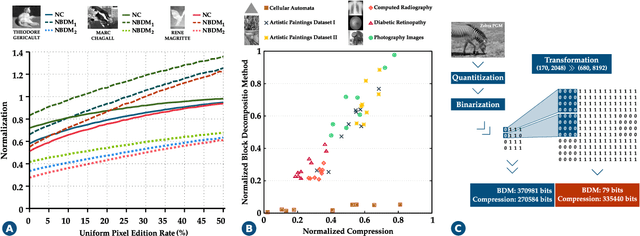

The artistic community is increasingly relying on automatic computational analysis for authentication and classification of artistic paintings. In this paper, we identify hidden patterns and relationships present in artistic paintings by analysing their complexity, a measure that quantifies the sum of characteristics of an object. Specifically, we apply Normalized Compression (NC) and the Block Decomposition Method (BDM) to a dataset of 4,266 paintings from 91 authors and examine the potential of these information-based measures as descriptors of artistic paintings. Both measures consistently described the equivalent types of paintings, authors, and artistic movements. Moreover, combining the NC with a measure of the roughness of the paintings creates an efficient stylistic descriptor. Furthermore, by quantifying the local information of each painting, we define a fingerprint that describes critical information regarding the artists' style, their artistic influences, and shared techniques. More fundamentally, this information describes how each author typically composes and distributes the elements across the canvas and, therefore, how their work is perceived. Finally, we demonstrate that regional complexity and two-point height difference correlation function are useful auxiliary features that improve current methodologies in style and author classification of artistic paintings. The whole study is supported by an extensive website (http://panther.web.ua.pt) for fast author characterization and authentication.
Variational Flow Graphical Model
Jul 06, 2022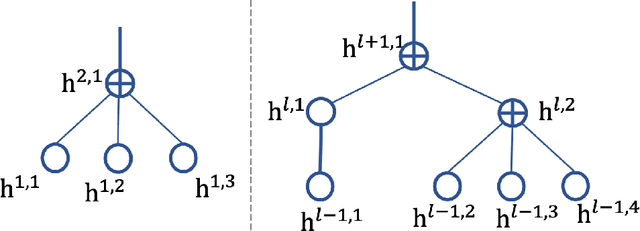
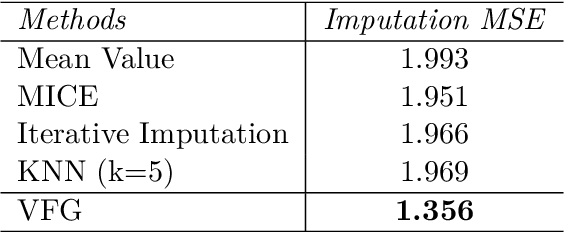
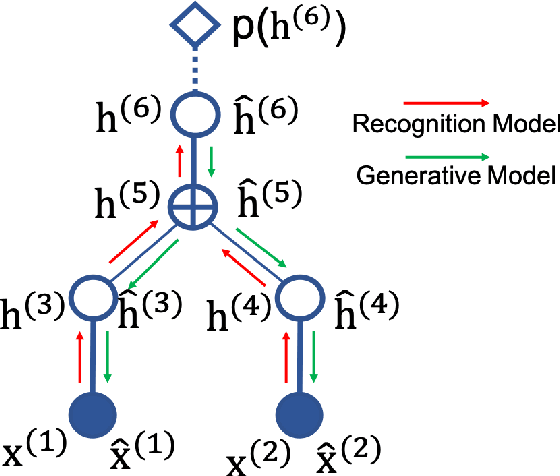

This paper introduces a novel approach to embed flow-based models with hierarchical structures. The proposed framework is named Variational Flow Graphical (VFG) Model. VFGs learn the representation of high dimensional data via a message-passing scheme by integrating flow-based functions through variational inference. By leveraging the expressive power of neural networks, VFGs produce a representation of the data using a lower dimension, thus overcoming the drawbacks of many flow-based models, usually requiring a high dimensional latent space involving many trivial variables. Aggregation nodes are introduced in the VFG models to integrate forward-backward hierarchical information via a message passing scheme. Maximizing the evidence lower bound (ELBO) of data likelihood aligns the forward and backward messages in each aggregation node achieving a consistency node state. Algorithms have been developed to learn model parameters through gradient updating regarding the ELBO objective. The consistency of aggregation nodes enable VFGs to be applicable in tractable inference on graphical structures. Besides representation learning and numerical inference, VFGs provide a new approach for distribution modeling on datasets with graphical latent structures. Additionally, theoretical study shows that VFGs are universal approximators by leveraging the implicitly invertible flow-based structures. With flexible graphical structures and superior excessive power, VFGs could potentially be used to improve probabilistic inference. In the experiments, VFGs achieves improved evidence lower bound (ELBO) and likelihood values on multiple datasets.
Detecting and Recovering Adversarial Examples from Extracting Non-robust and Highly Predictive Adversarial Perturbations
Jun 30, 2022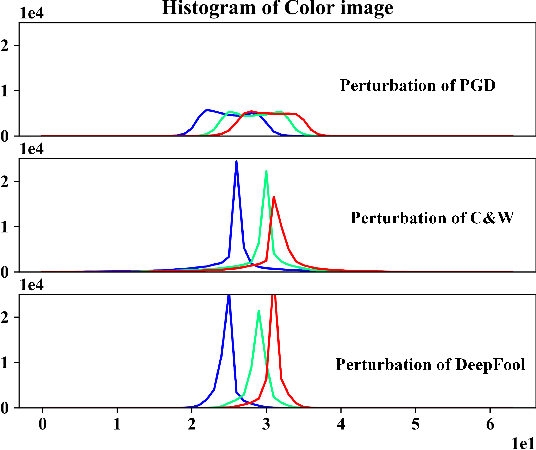
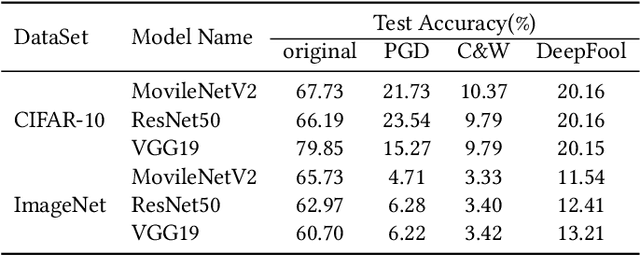
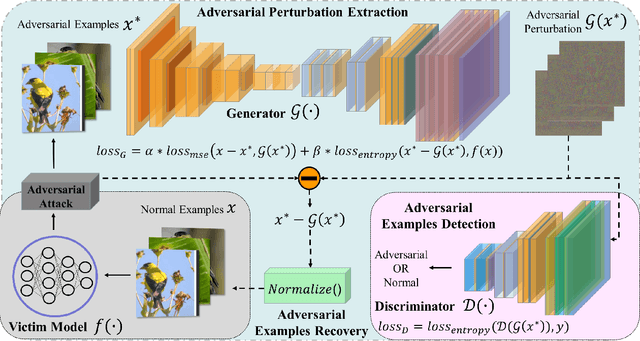
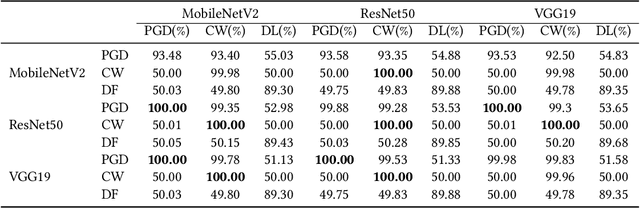
Deep neural networks (DNNs) have been shown to be vulnerable against adversarial examples (AEs) which are maliciously designed to fool target models. The normal examples (NEs) added with imperceptible adversarial perturbation, can be a security threat to DNNs. Although the existing AEs detection methods have achieved a high accuracy, they failed to exploit the information of the AEs detected. Thus, based on high-dimension perturbation extraction, we propose a model-free AEs detection method, the whole process of which is free from querying the victim model. Research shows that DNNs are sensitive to the high-dimension features. The adversarial perturbation hiding in the adversarial example belongs to the high-dimension feature which is highly predictive and non-robust. DNNs learn more details from high-dimension data than others. In our method, the perturbation extractor can extract the adversarial perturbation from AEs as high-dimension feature, then the trained AEs discriminator determines whether the input is an AE. Experimental results show that the proposed method can not only detect the adversarial examples with high accuracy, but also detect the specific category of the AEs. Meanwhile, the extracted perturbation can be used to recover the AEs to NEs.
Image deblurring based on lightweight multi-information fusion network
Jan 14, 2021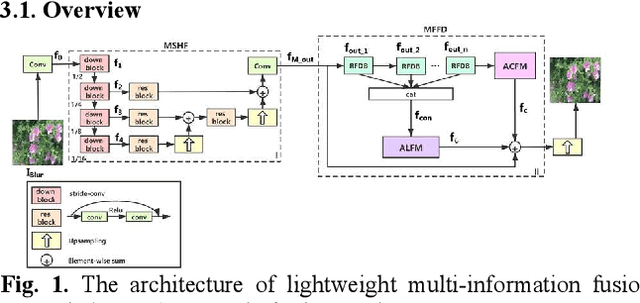
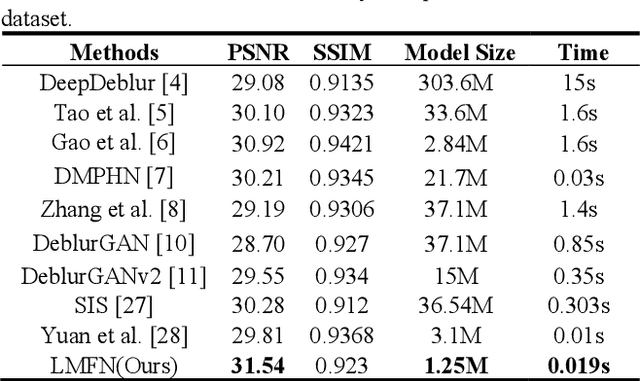
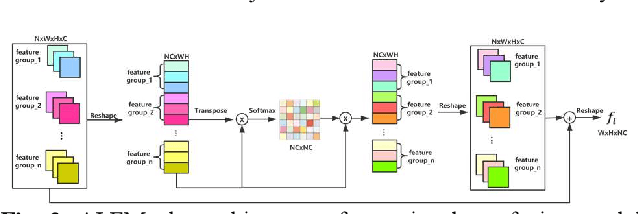

Recently, deep learning based image deblurring has been well developed. However, exploiting the detailed image features in a deep learning framework always requires a mass of parameters, which inevitably makes the network suffer from high computational burden. To solve this problem, we propose a lightweight multiinformation fusion network (LMFN) for image deblurring. The proposed LMFN is designed as an encoder-decoder architecture. In the encoding stage, the image feature is reduced to various smallscale spaces for multi-scale information extraction and fusion without a large amount of information loss. Then, a distillation network is used in the decoding stage, which allows the network benefit the most from residual learning while remaining sufficiently lightweight. Meanwhile, an information fusion strategy between distillation modules and feature channels is also carried out by attention mechanism. Through fusing different information in the proposed approach, our network can achieve state-of-the-art image deblurring result with smaller number of parameters and outperforms existing methods in model complexity.
Structural Information Preserving for Graph-to-Text Generation
Feb 12, 2021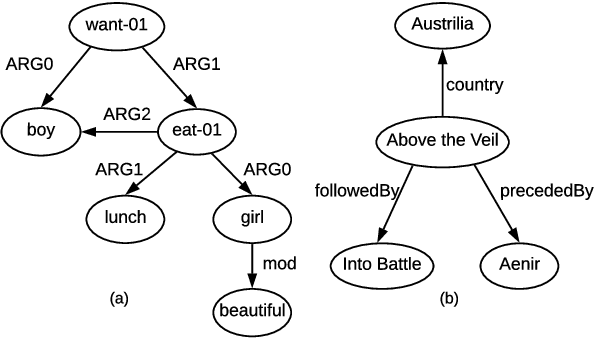
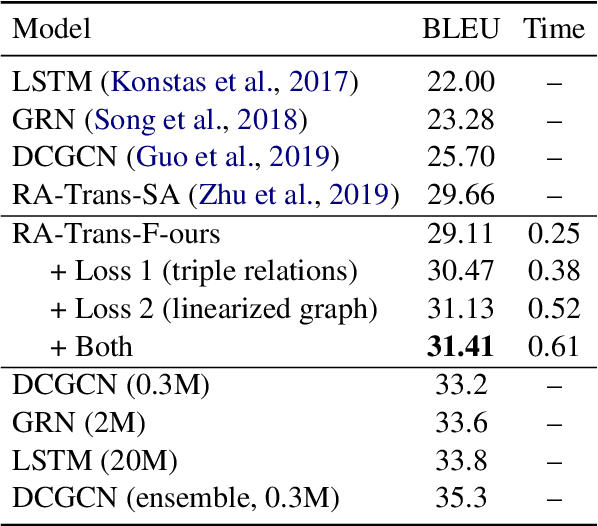
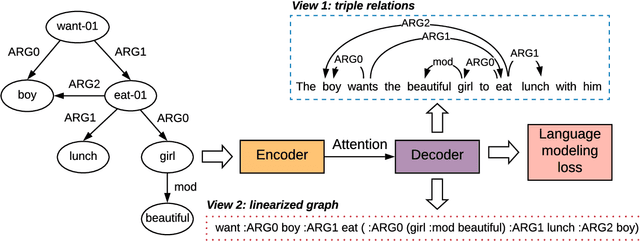

The task of graph-to-text generation aims at producing sentences that preserve the meaning of input graphs. As a crucial defect, the current state-of-the-art models may mess up or even drop the core structural information of input graphs when generating outputs. We propose to tackle this problem by leveraging richer training signals that can guide our model for preserving input information. In particular, we introduce two types of autoencoding losses, each individually focusing on different aspects (a.k.a. views) of input graphs. The losses are then back-propagated to better calibrate our model via multi-task training. Experiments on two benchmarks for graph-to-text generation show the effectiveness of our approach over a state-of-the-art baseline. Our code is available at \url{http://github.com/Soistesimmer/AMR-multiview}.
Machine Learning Based Cyber Attacks Targeting on Controlled Information: A Survey
Feb 16, 2021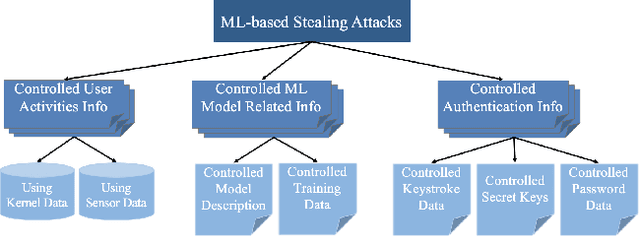

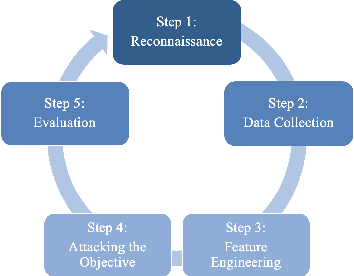
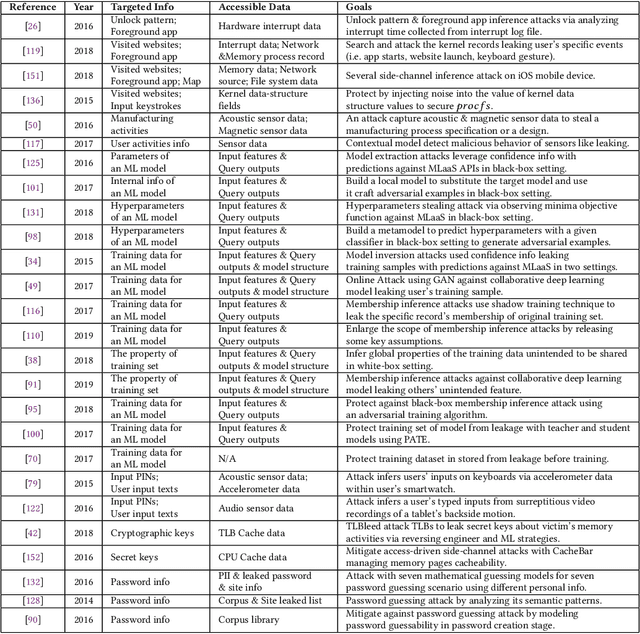
Stealing attack against controlled information, along with the increasing number of information leakage incidents, has become an emerging cyber security threat in recent years. Due to the booming development and deployment of advanced analytics solutions, novel stealing attacks utilize machine learning (ML) algorithms to achieve high success rate and cause a lot of damage. Detecting and defending against such attacks is challenging and urgent so that governments, organizations, and individuals should attach great importance to the ML-based stealing attacks. This survey presents the recent advances in this new type of attack and corresponding countermeasures. The ML-based stealing attack is reviewed in perspectives of three categories of targeted controlled information, including controlled user activities, controlled ML model-related information, and controlled authentication information. Recent publications are summarized to generalize an overarching attack methodology and to derive the limitations and future directions of ML-based stealing attacks. Furthermore, countermeasures are proposed towards developing effective protections from three aspects -- detection, disruption, and isolation.
So3krates -- Self-attention for higher-order geometric interactions on arbitrary length-scales
May 28, 2022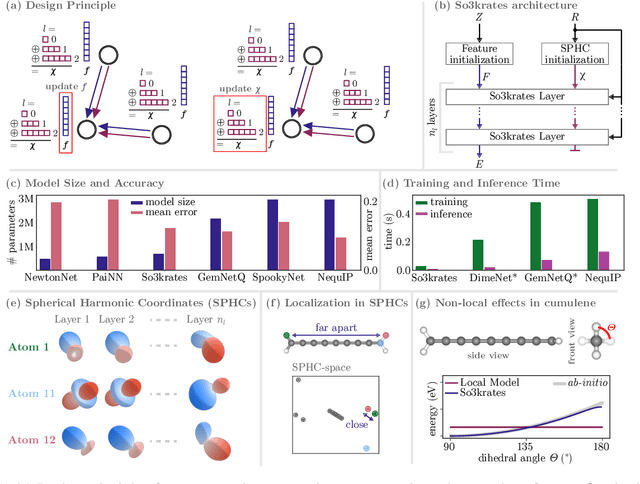
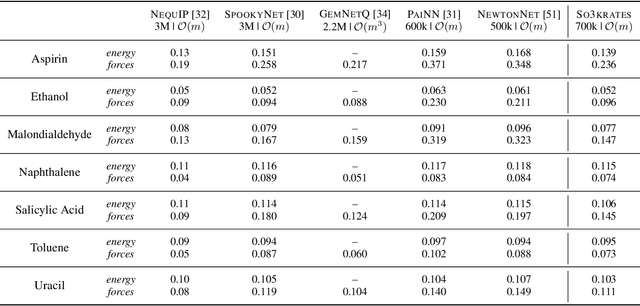
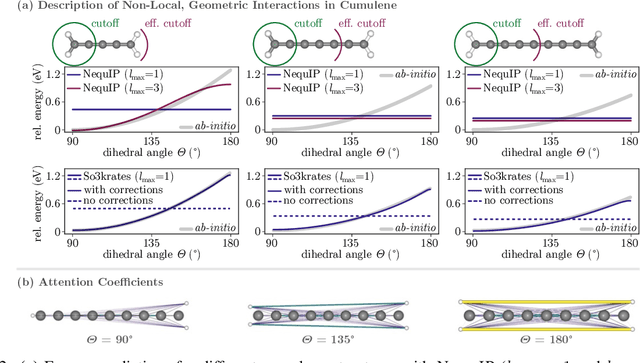

The application of machine learning methods in quantum chemistry has enabled the study of numerous chemical phenomena, which are computationally intractable with traditional ab-initio methods. However, some quantum mechanical properties of molecules and materials depend on non-local electronic effects, which are often neglected due to the difficulty of modeling them efficiently. This work proposes a modified attention mechanism adapted to the underlying physics, which allows to recover the relevant non-local effects. Namely, we introduce spherical harmonic coordinates (SPHCs) to reflect higher-order geometric information for each atom in a molecule, enabling a non-local formulation of attention in the SPHC space. Our proposed model So3krates -- a self-attention based message passing neural network -- uncouples geometric information from atomic features, making them independently amenable to attention mechanisms. We show that in contrast to other published methods, So3krates is able to describe non-local quantum mechanical effects over arbitrary length scales. Further, we find evidence that the inclusion of higher-order geometric correlations increases data efficiency and improves generalization. So3krates matches or exceeds state-of-the-art performance on popular benchmarks, notably, requiring a significantly lower number of parameters (0.25--0.4x) while at the same time giving a substantial speedup (6--14x for training and 2--11x for inference) compared to other models.