 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CrossCBR: Cross-view Contrastive Learning for Bundle Recommendation
Jun 08, 2022
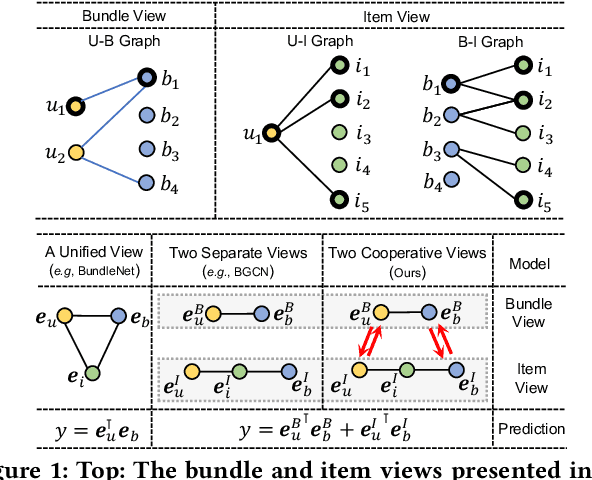
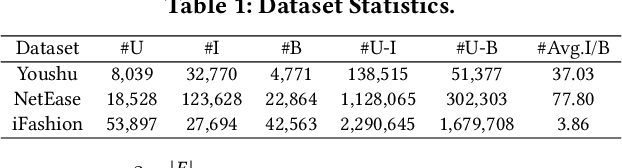
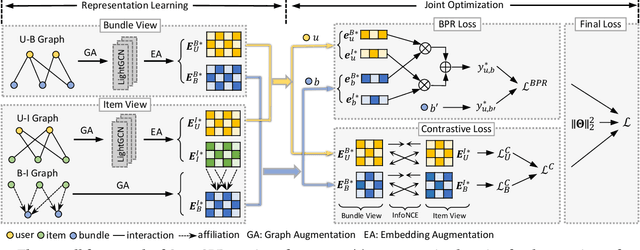
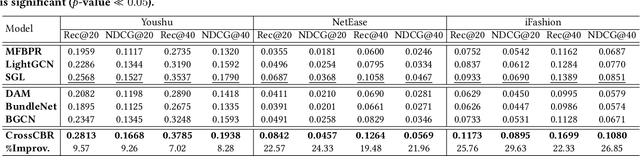
Bundle recommendation aims to recommend a bundle of related items to users, which can satisfy the users' various needs with one-stop convenience. Recent methods usually take advantage of both user-bundle and user-item interactions information to obtain informative representations for users and bundles, corresponding to bundle view and item view, respectively. However, they either use a unified view without differentiation or loosely combine the predictions of two separate views, while the crucial cooperative association between the two views' representations is overlooked. In this work, we propose to model the cooperative association between the two different views through cross-view contrastive learning. By encouraging the alignment of the two separately learned views, each view can distill complementary information from the other view, achieving mutual enhancement. Moreover, by enlarging the dispersion of different users/bundles, the self-discrimination of representations is enhanced. Extensive experiments on three public datasets demonstrate that our method outperforms SOTA baselines by a large margin. Meanwhile, our method requires minimal parameters of three set of embeddings (user, bundle, and item) and the computational costs are largely reduced due to more concise graph structure and graph learning module. In addition, various ablation and model studies demystify the working mechanism and justify our hypothesis. Codes and datasets are available at https://github.com/mysbupt/CrossCBR.
* 9 pages, 5 figures, 5 tables
Memory Efficient Patch-based Training for INR-based GANs
Jul 04, 2022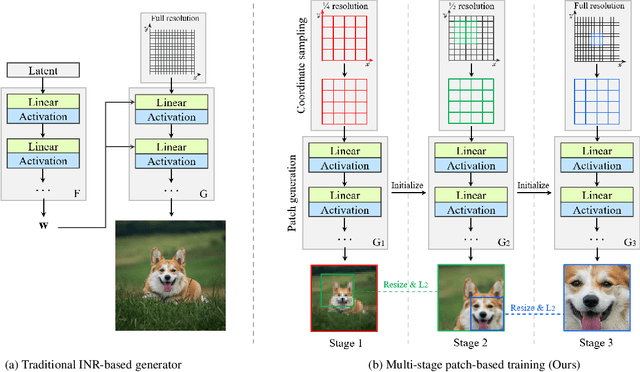
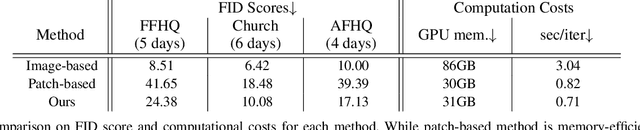


Recent studies have shown remarkable progress in GANs based on implicit neural representation (INR) - an MLP that produces an RGB value given its (x, y) coordinate. They represent an image as a continuous version of the underlying 2D signal instead of a 2D array of pixels, which opens new horizons for GAN applications (e.g., zero-shot super-resolution, image outpainting). However, training existing approaches require a heavy computational cost proportional to the image resolution, since they compute an MLP operation for every (x, y) coordinate. To alleviate this issue, we propose a multi-stage patch-based training, a novel and scalable approach that can train INR-based GANs with a flexible computational cost regardless of the image resolution. Specifically, our method allows to generate and discriminate by patch to learn the local details of the image and learn global structural information by a novel reconstruction loss to enable efficient GAN training. We conduct experiments on several benchmark datasets to demonstrate that our approach enhances baseline models in GPU memory while maintaining FIDs at a reasonable level.
LAE: Language-Aware Encoder for Monolingual and Multilingual ASR
Jun 05, 2022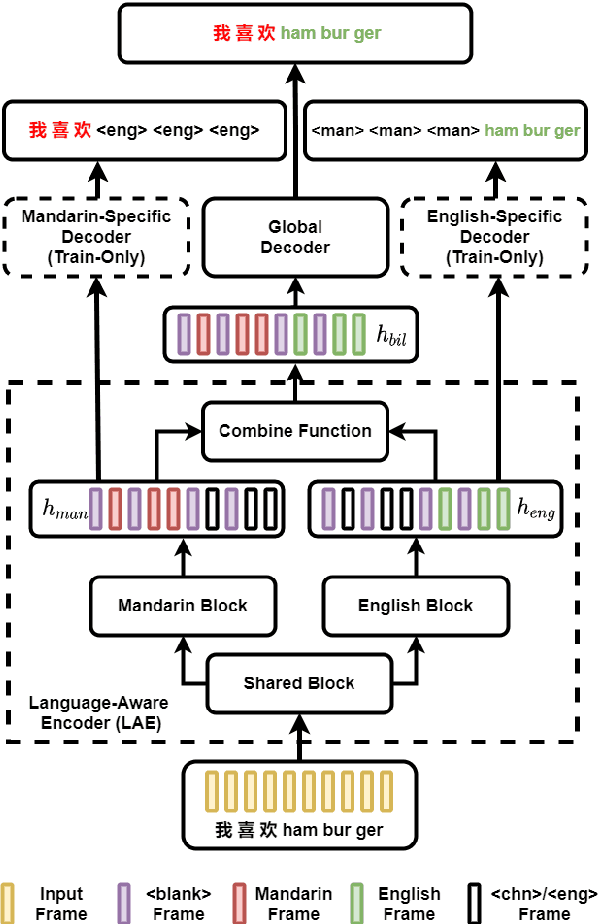
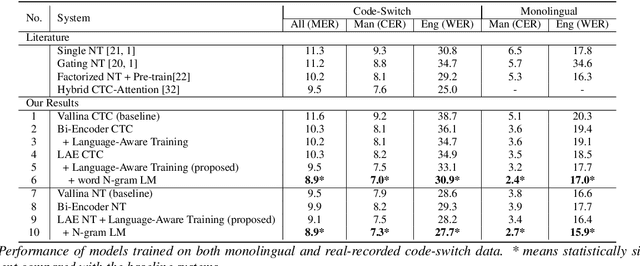
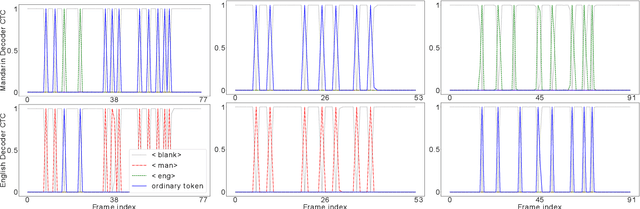
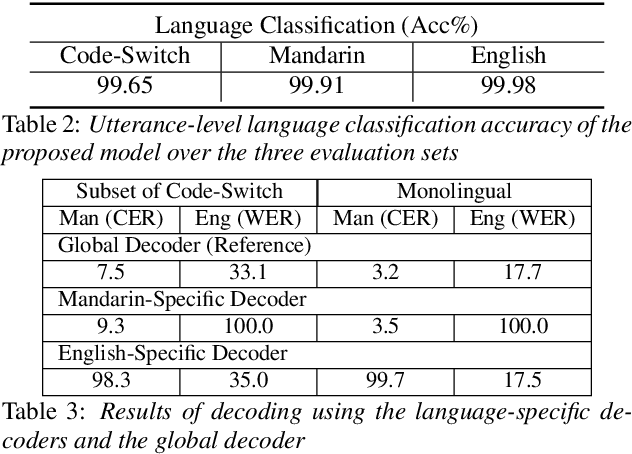
Despite the rapid progress in automatic speech recognition (ASR) research, recognizing multilingual speech using a unified ASR system remains highly challenging. Previous works on multilingual speech recognition mainly focus on two directions: recognizing multiple monolingual speech or recognizing code-switched speech that uses different languages interchangeably within a single utterance. However, a pragmatic multilingual recognizer is expected to be compatible with both directions. In this work, a novel language-aware encoder (LAE) architecture is proposed to handle both situations by disentangling language-specific information and generating frame-level language-aware representations during encoding. In the LAE, the primary encoding is implemented by the shared block while the language-specific blocks are used to extract specific representations for each language. To learn language-specific information discriminatively, a language-aware training method is proposed to optimize the language-specific blocks in LAE. Experiments conducted on Mandarin-English code-switched speech suggest that the proposed LAE is capable of discriminating different languages in frame-level and shows superior performance on both monolingual and multilingual ASR tasks. With either a real-recorded or simulated code-switched dataset, the proposed LAE achieves statistically significant improvements on both CTC and neural transducer systems. Code is released
Toward Consistent and Efficient Map-based Visual-inertial Localization: Theory Framework and Filter Design
Apr 26, 2022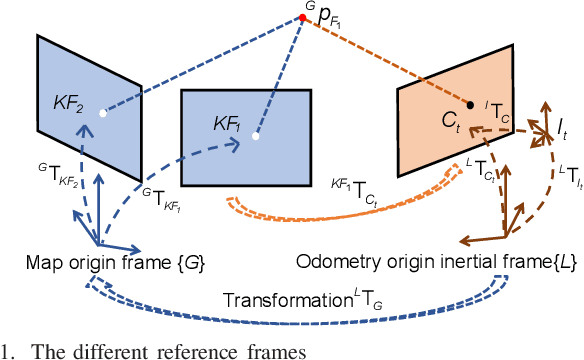
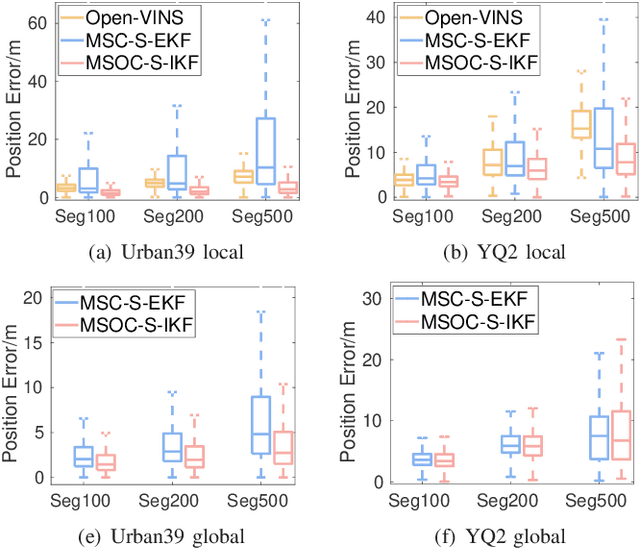
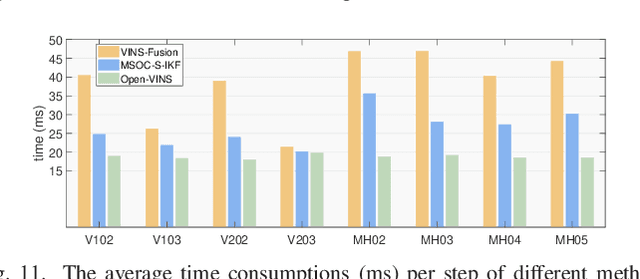
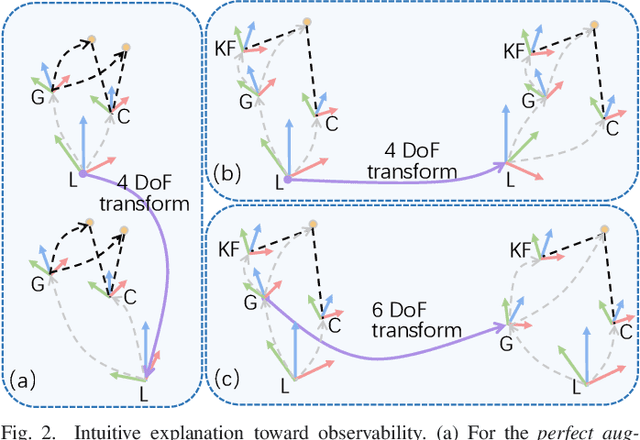
This paper focuses on designing a consistent and efficient filter for map-based visual-inertial localization. First, we propose a new Lie group with its algebra, based on which a novel invariant extended Kalman filter (invariant EKF) is designed. We theoretically prove that, when we do not consider the uncertainty of the map information, the proposed invariant EKF can naturally maintain the correct observability properties of the system. To consider the uncertainty of the map information, we introduce a Schmidt filter. With the Schmidt filter, the uncertainty of the map information can be taken into consideration to avoid over-confident estimation while the computation cost only increases linearly with the size of the map keyframes. In addition, we introduce an easily implemented observability-constrained technique because directly combining the invariant EKF with the Schmidt filter cannot maintain the correct observability properties of the system that considers the uncertainty of the map information. Finally, we validate our proposed system's high consistency, accuracy, and efficiency via extensive simulations and real-world experiments.
Neuroevolutionary Feature Representations for Causal Inference
May 21, 2022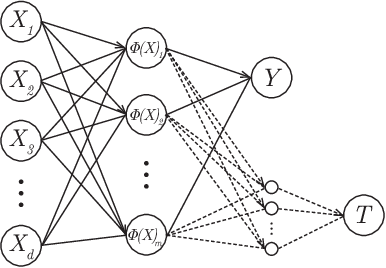
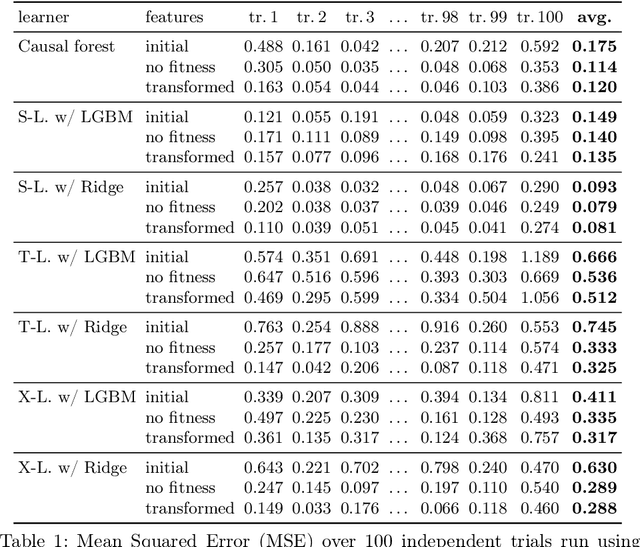
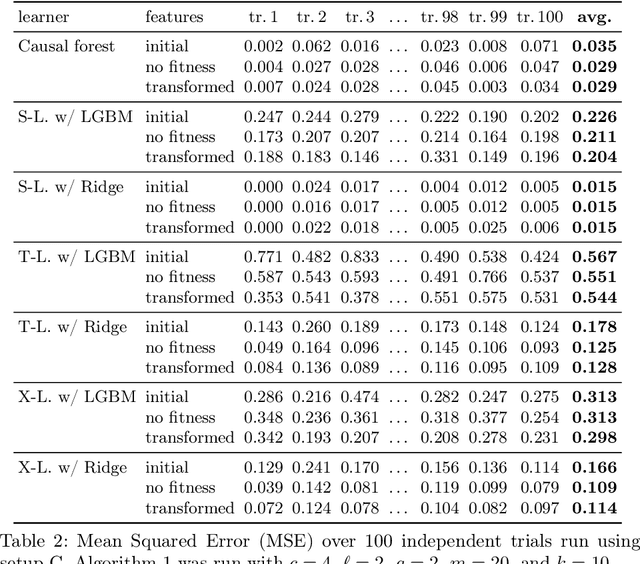
Within the field of causal inference, we consider the problem of estimating heterogeneous treatment effects from data. We propose and validate a novel approach for learning feature representations to aid the estimation of the conditional average treatment effect or CATE. Our method focuses on an intermediate layer in a neural network trained to predict the outcome from the features. In contrast to previous approaches that encourage the distribution of representations to be treatment-invariant, we leverage a genetic algorithm that optimizes over representations useful for predicting the outcome to select those less useful for predicting the treatment. This allows us to retain information within the features useful for predicting outcome even if that information may be related to treatment assignment. We validate our method on synthetic examples and illustrate its use on a real life dataset.
A multi-level interpretable sleep stage scoring system by infusing experts' knowledge into a deep network architecture
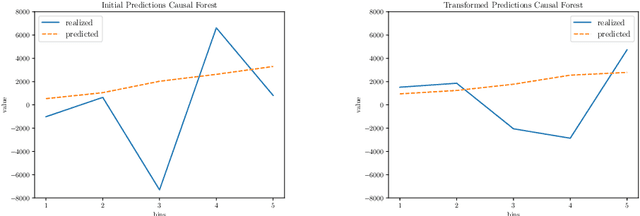
Jul 11, 2022
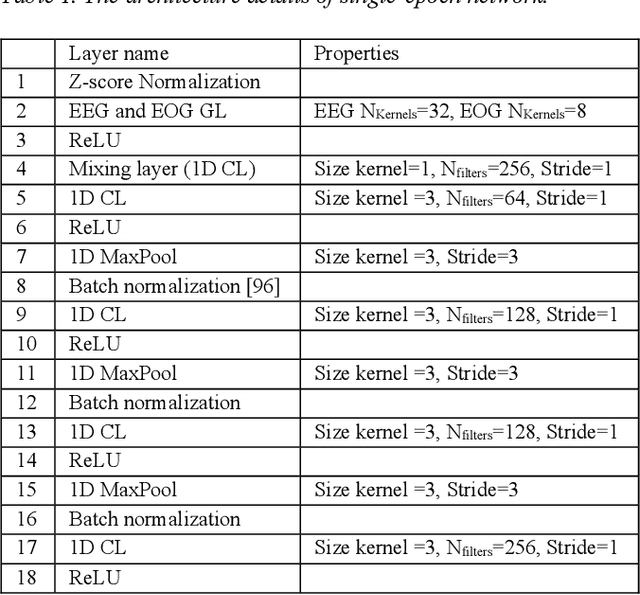
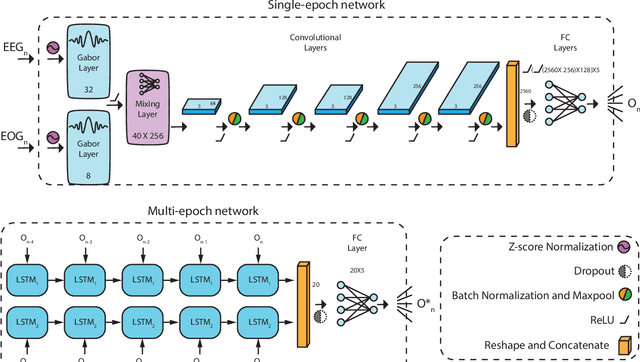
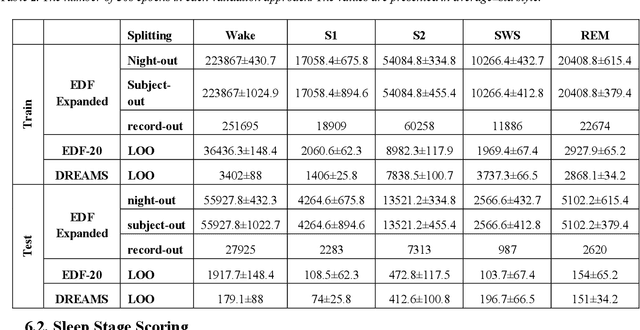
In recent years, deep learning has shown potential and efficiency in a wide area including computer vision, image and signal processing. Yet, translational challenges remain for user applications due to a lack of interpretability of algorithmic decisions and results. This black box problem is particularly problematic for high-risk applications such as medical-related decision-making. The current study goal was to design an interpretable deep learning system for time series classification of electroencephalogram (EEG) for sleep stage scoring as a step toward designing a transparent system. We have developed an interpretable deep neural network that includes a kernel-based layer based on a set of principles used for sleep scoring by human experts in the visual analysis of polysomnographic records. A kernel-based convolutional layer was defined and used as the first layer of the system and made available for user interpretation. The trained system and its results were interpreted in four levels from the microstructure of EEG signals, such as trained kernels and the effect of each kernel on the detected stages, to macrostructures, such as the transition between stages. The proposed system demonstrated greater performance than prior studies and the results of interpretation showed that the system learned information which was consistent with expert knowledge.
Polarimetric phase retrieval: uniqueness and algorithms
Jun 26, 2022
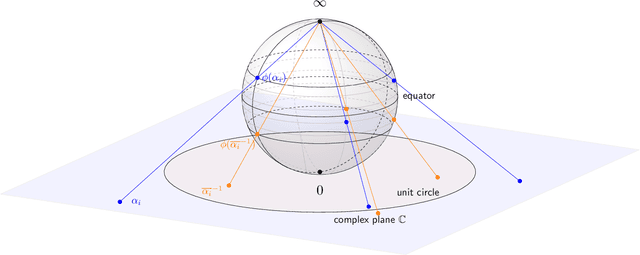
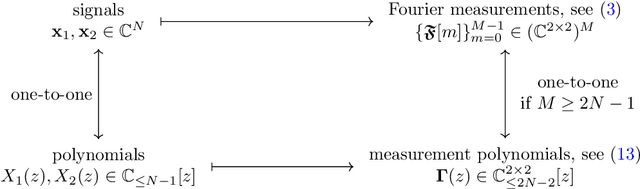

This work introduces a novel Fourier phase retrieval model, called polarimetric phase retrieval that enables a systematic use of polarization information in Fourier phase retrieval problems. We provide a complete characterization of uniqueness properties of this new model by unraveling equivalencies with a peculiar polynomial factorization problem. We introduce two different but complementary categories of reconstruction methods. The first one is algebraic and relies on the use of approximate greatest common divisor computations using Sylvester matrices. The second one carefully adapts existing algorithms for Fourier phase retrieval, namely semidefinite positive relaxation and Wirtinger-Flow, to solve the polarimetric phase retrieval problem. Finally, a set of numerical experiments permits a detailed assessment of the numerical behavior and relative performances of each proposed reconstruction strategy. We further highlight a reconstruction strategy that combines both approaches for scalable, computationally efficient and asymptotically MSE optimal performance.
G2L: A Geometric Approach for Generating Pseudo-labels that Improve Transfer Learning
Jul 07, 2022
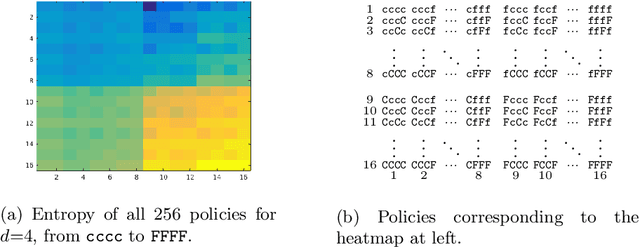
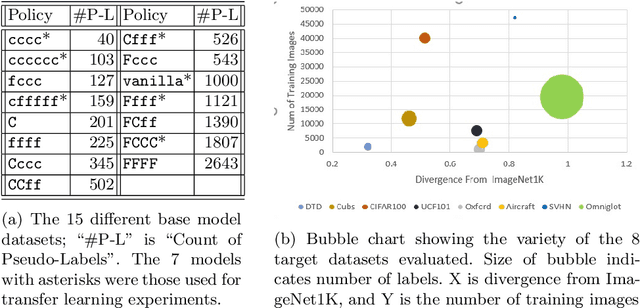
Transfer learning is a deep-learning technique that ameliorates the problem of learning when human-annotated labels are expensive and limited. In place of such labels, it uses instead the previously trained weights from a well-chosen source model as the initial weights for the training of a base model for a new target dataset. We demonstrate a novel but general technique for automatically creating such source models. We generate pseudo-labels according to an efficient and extensible algorithm that is based on a classical result from the geometry of high dimensions, the Cayley-Menger determinant. This G2L (``geometry to label'') method incrementally builds up pseudo-labels using a greedy computation of hypervolume content. We demonstrate that the method is tunable with respect to expected accuracy, which can be forecast by an information-theoretic measure of dataset similarity (divergence) between source and target. The results of 280 experiments show that this mechanical technique generates base models that have similar or better transferability compared to a baseline of models trained on extensively human-annotated ImageNet1K labels, yielding an overall error decrease of 0.43\%, and an error decrease in 4 out of 5 divergent datasets tested.
Hyperbolic Relevance Matching for Neural Keyphrase Extraction
May 04, 2022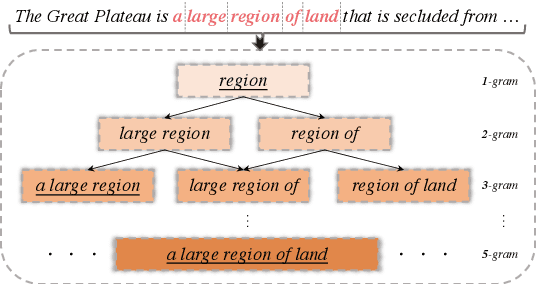


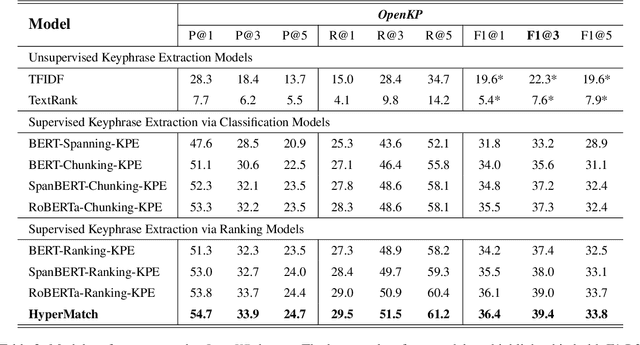
Keyphrase extraction is a fundamental task in natural language processing and information retrieval that aims to extract a set of phrases with important information from a source document. Identifying important keyphrase is the central component of the keyphrase extraction task, and its main challenge is how to represent information comprehensively and discriminate importance accurately. In this paper, to address these issues, we design a new hyperbolic matching model (HyperMatch) to represent phrases and documents in the same hyperbolic space and explicitly estimate the phrase-document relevance via the Poincar\'e distance as the important score of each phrase. Specifically, to capture the hierarchical syntactic and semantic structure information, HyperMatch takes advantage of the hidden representations in multiple layers of RoBERTa and integrates them as the word embeddings via an adaptive mixing layer. Meanwhile, considering the hierarchical structure hidden in the document, HyperMatch embeds both phrases and documents in the same hyperbolic space via a hyperbolic phrase encoder and a hyperbolic document encoder. This strategy can further enhance the estimation of phrase-document relevance due to the good properties of hyperbolic space. In this setting, the keyphrase extraction can be taken as a matching problem and effectively implemented by minimizing a hyperbolic margin-based triplet loss. Extensive experiments are conducted on six benchmarks and demonstrate that HyperMatch outperforms the state-of-the-art baselines.
PIDNet: A Real-time Semantic Segmentation Network Inspired from PID Controller
Jun 04, 2022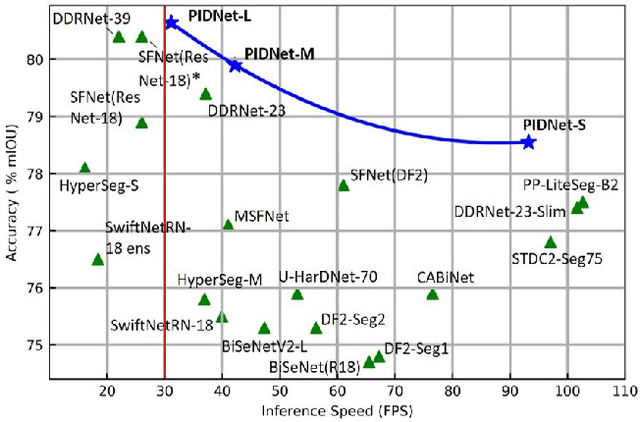
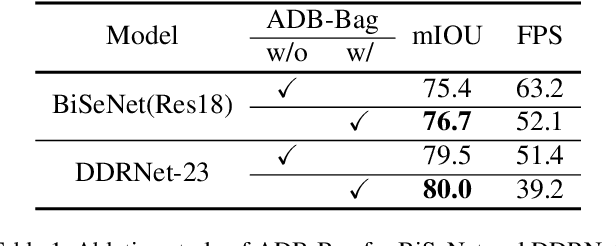
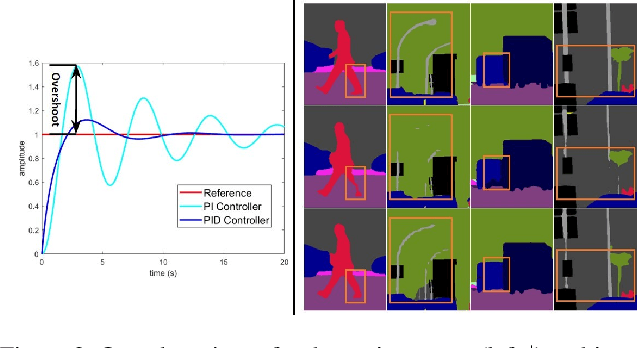

Two-branch network architecture has shown its efficiency and effectiveness for real-time semantic segmentation tasks. However, direct fusion of low-level details and high-level semantics will lead to a phenomenon that the detailed features are easily overwhelmed by surrounding contextual information, namely overshoot in this paper, which limits the improvement of the accuracy of existed two-branch models. In this paper, we bridge a connection between Convolutional Neural Network (CNN) and Proportional-Integral-Derivative (PID) controller and reveal that the two-branch network is nothing but a Proportional-Integral (PI) controller, which inherently suffers from the similar overshoot issue. To alleviate this issue, we propose a novel three-branch network architecture: PIDNet, which possesses three branches to parse the detailed, context and boundary information (derivative of semantics), respectively, and employs boundary attention to guide the fusion of detailed and context branches in final stage. The family of PIDNets achieve the best trade-off between inference speed and accuracy and their test accuracy surpasses all the existed models with similar inference speed on Cityscapes, CamVid and COCO-Stuff datasets. Especially, PIDNet-S achieves 78.6% mIOU with inference speed of 93.2 FPS on Cityscapes test set and 81.6% mIOU with speed of 153.7 FPS on CamVid test set.