 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Operational Adaptation of DNN Classifiers using Elastic Weight Consolidation
Apr 30, 2022
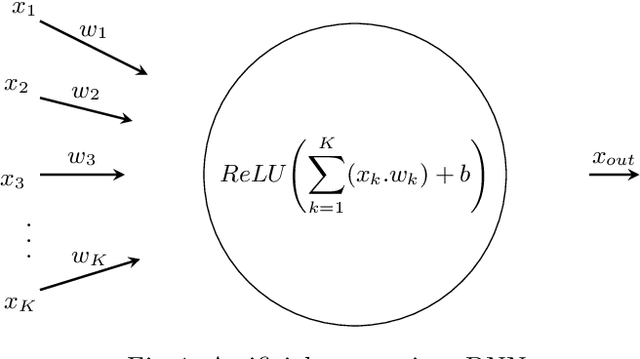
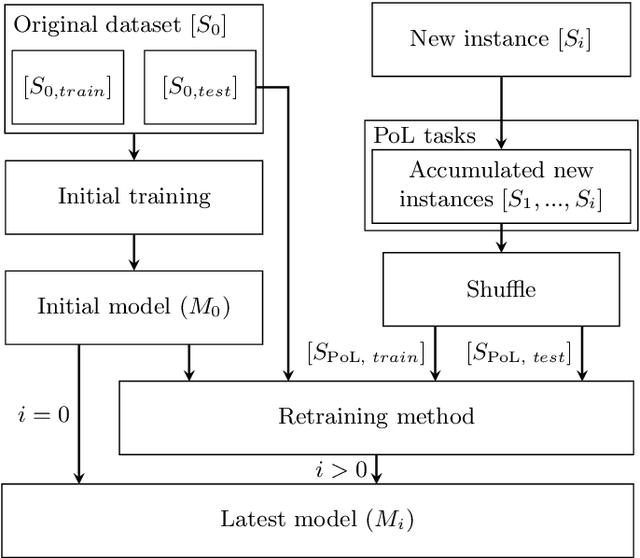
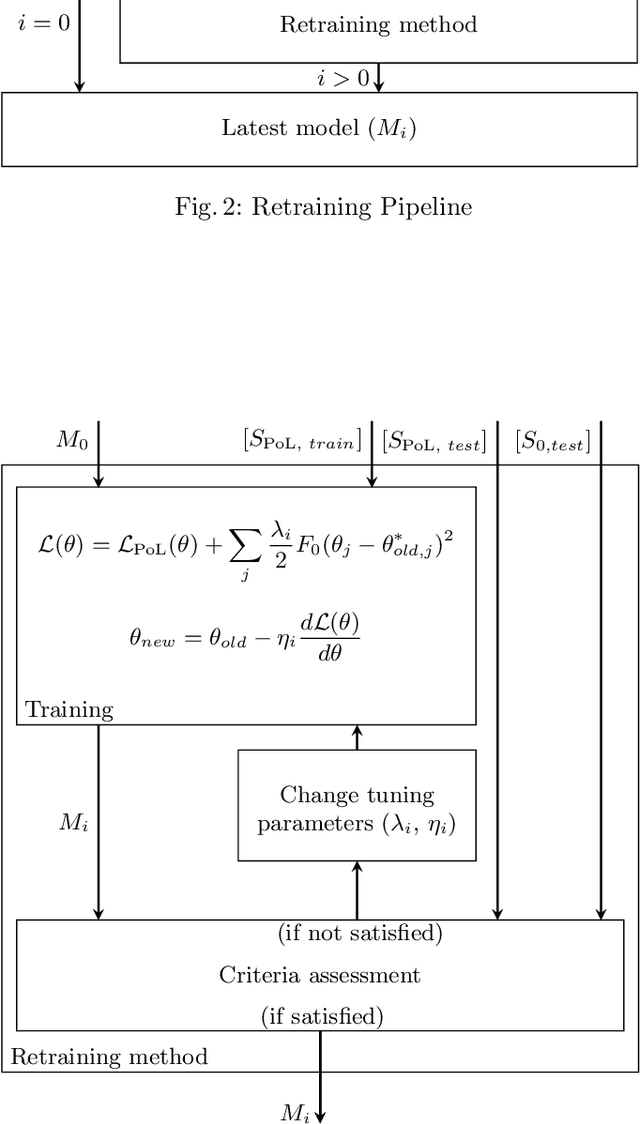
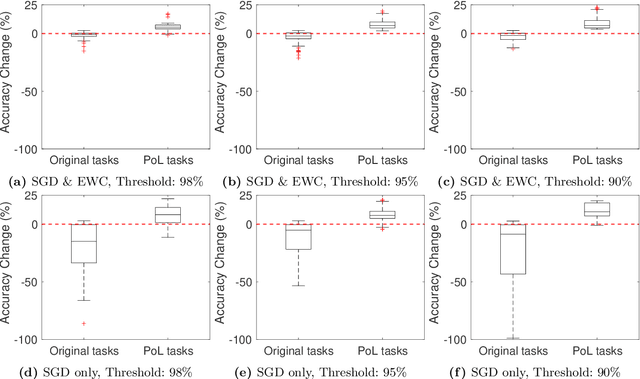
Autonomous systems (AS) often use Deep Neural Network (DNN) classifiers to allow them to operate in complex, high dimensional, non-linear, and dynamically changing environments. Due to the complexity of these environments, DNN classifiers may output misclassifications due to experiencing new tasks in their operational environments, which were not identified during development. Removing a system from operation and retraining it to include the new identified task becomes economically infeasible as the number of such autonomous systems increase. Additionally, such misclassifications may cause financial losses and safety threats to the AS or to other operators in its environment. In this paper, we propose to reduce such threats by investigating if DNN classifiers can adapt its knowledge to learn new information in the AS's operational environment, using only a limited number of observations encountered sequentially during operation. This allows the AS to adapt to new encountered information and hence increases the AS's reliability on doing correct classifications. However, retraining DNNs on different observations than used in prior training is known to cause catastrophic forgetting or significant model drift. We investigate if this problem can be controlled by using Elastic Weight Consolidation (EWC) whilst learning from limited new observations. We carry out experiments using original and noisy versions of the MNIST dataset to represent known and new information to DNN classifiers. Results show that using EWC does make the process of adaptation to new information a lot more controlled, and thus allowing for reliable adaption of ASs to new information in their operational environment.
Robust Beamforming Design for IRS-Aided URLLC in D2D Networks
Jul 11, 2022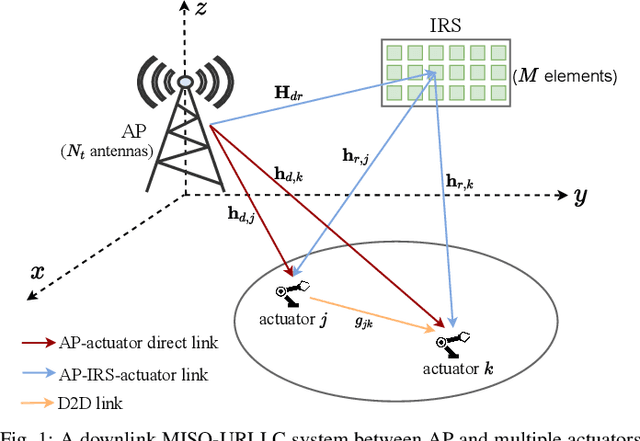
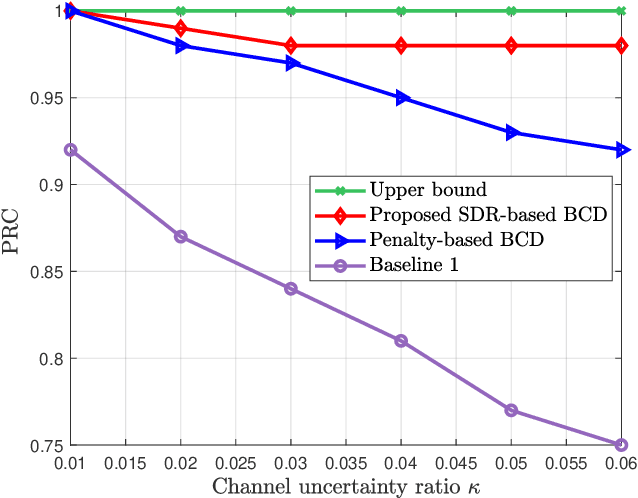
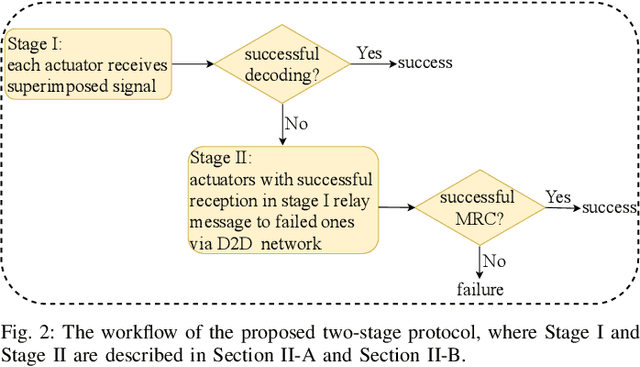
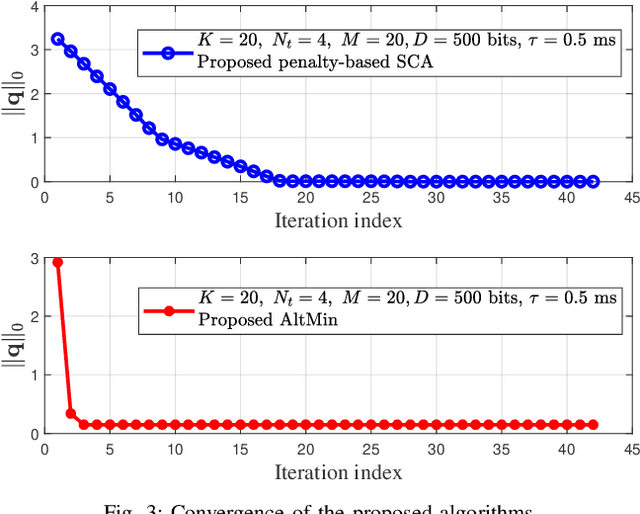
Intelligent reflecting surface (IRS) and device-to-device (D2D) communication are two promising technologies for improving transmission reliability between transceivers in communication systems. In this paper, we consider the design of reliable communication between the access point (AP) and actuators for a downlink multiuser multiple-input single-output (MISO) system in the industrial IoT (IIoT) scenario. We propose a two-stage protocol combining IRS with D2D communication so that all actuators can successfully receive the message from AP within a given delay. The superiority of the protocol is that the communication reliability between AP and actuators is doubly augmented by the IRS-aided first-stage transmission and the second-stage D2D transmission. A joint optimization problem of active and passive beamforming is formulated, which aims to maximize the number of actuators with successful decoding. We study the joint beamforming problem for cases where the channel state information (CSI) is perfect and imperfect. For each case, we develop efficient algorithms that include convergence and complexity analysis. Simulation results demonstrate the necessity and role of IRS with a well-optimized reflection matrix, and the D2D network in promoting reliable communication. Moreover, the proposed protocol can enable reliable communication even in the presence of stringent latency requirements and CSI estimation errors.
Is Lip Region-of-Interest Sufficient for Lipreading?
Jun 02, 2022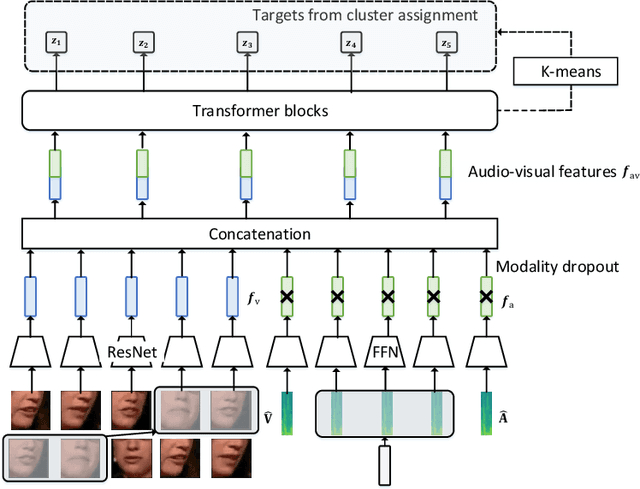
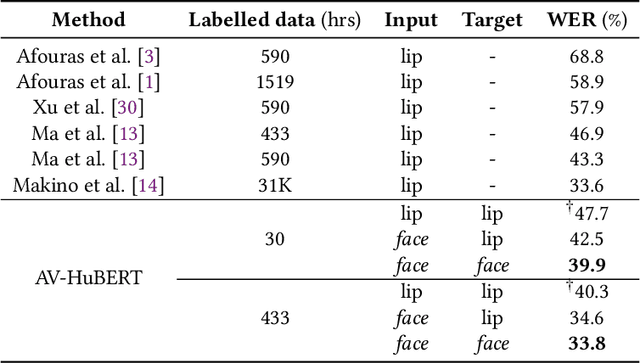

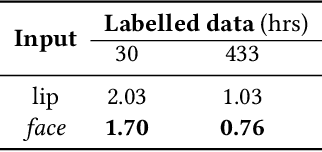
Lip region-of-interest (ROI) is conventionally used for visual input in the lipreading task. Few works have adopted the entire face as visual input because lip-excluded parts of the face are usually considered to be redundant and irrelevant to visual speech recognition. However, faces contain much more detailed information than lips, such as speakers' head pose, emotion, identity etc. We argue that such information might benefit visual speech recognition if a powerful feature extractor employing the entire face is trained. In this work, we propose to adopt the entire face for lipreading with self-supervised learning. AV-HuBERT, an audio-visual multi-modal self-supervised learning framework, was adopted in our experiments. Our experimental results showed that adopting the entire face achieved 16% relative word error rate (WER) reduction on the lipreading task, compared with the baseline method using lip as visual input. Without self-supervised pretraining, the model with face input achieved a higher WER than that using lip input in the case of limited training data (30 hours), while a slightly lower WER when using large amount of training data (433 hours).
Decision-making with E-admissibility given a finite assessment of choices
Apr 15, 2022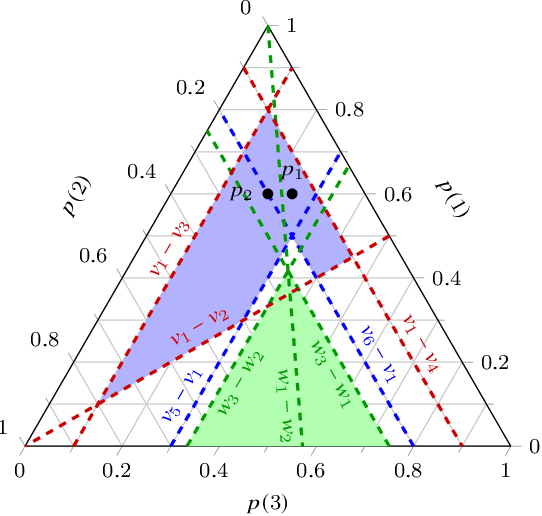
Given information about which options a decision-maker definitely rejects from given finite sets of options, we study the implications for decision-making with E-admissibility. This means that from any finite set of options, we reject those options that no probability mass function compatible with the given information gives the highest expected utility. We use the mathematical framework of choice functions to specify choices and rejections, and specify the available information in the form of conditions on such functions. We characterise the most conservative extension of the given information to a choice function that makes choices based on E-admissibility, and provide an algorithm that computes this extension by solving linear feasibility problems.
Beyond mAP: Re-evaluating and Improving Performance in Instance Segmentation with Semantic Sorting and Contrastive Flow
Jul 04, 2022
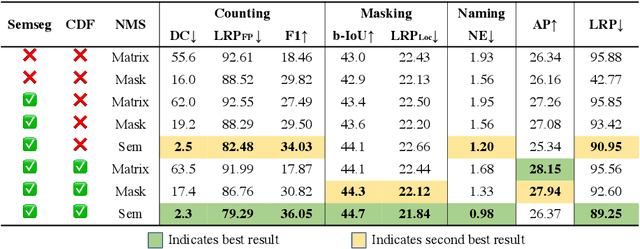
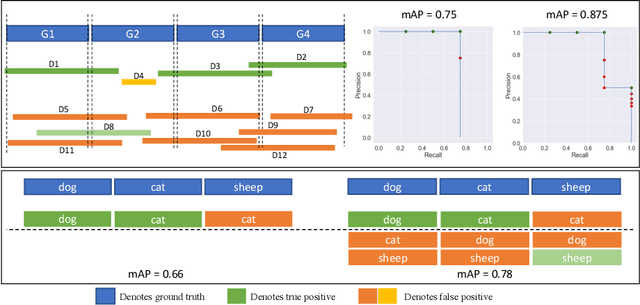

Top-down instance segmentation methods improve mAP by hedging bets on low-confidence predictions to match a ground truth. Moreover, the query-key paradigm of top-down methods leads to the instance merging problem. An excessive number of duplicate predictions leads to the (over)counting error, and the independence of category and localization branches leads to the naming error. The de-facto mAP metric doesn't capture these errors, as we show that a trivial dithering scheme can simultaneously increase mAP with hedging errors. To this end, we propose two graph-based metrics that quantifies the amount of hedging both inter-and intra-class. We conjecture the source of the hedging problem is due to feature merging and propose a) Contrastive Flow Field to encode contextual differences between instances as a supervisory signal, and b) Semantic Sorting and NMS step to suppress duplicates and incorrectly categorized prediction. Ablations show that our method encodes contextual information better than baselines, and experiments on COCO our method simultaneously reduces merging and hedging errors compared to state-of-the-art instance segmentation methods.
Type-aware Embeddings for Multi-Hop Reasoning over Knowledge Graphs
May 02, 2022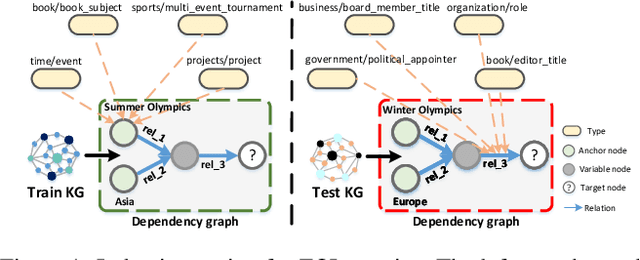
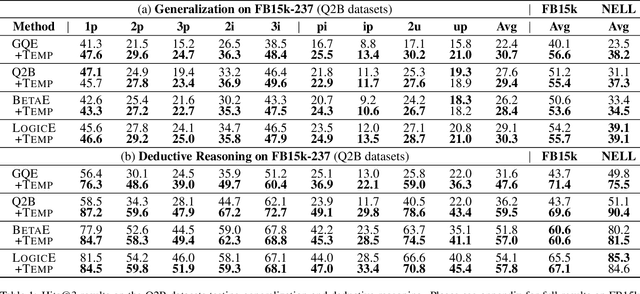
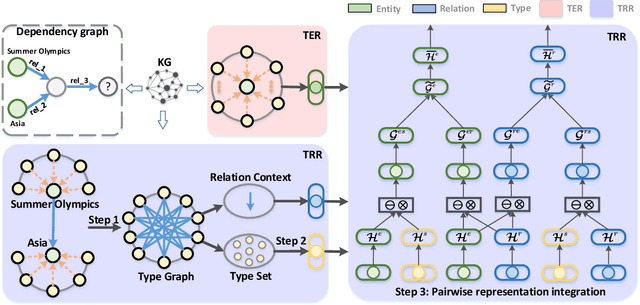
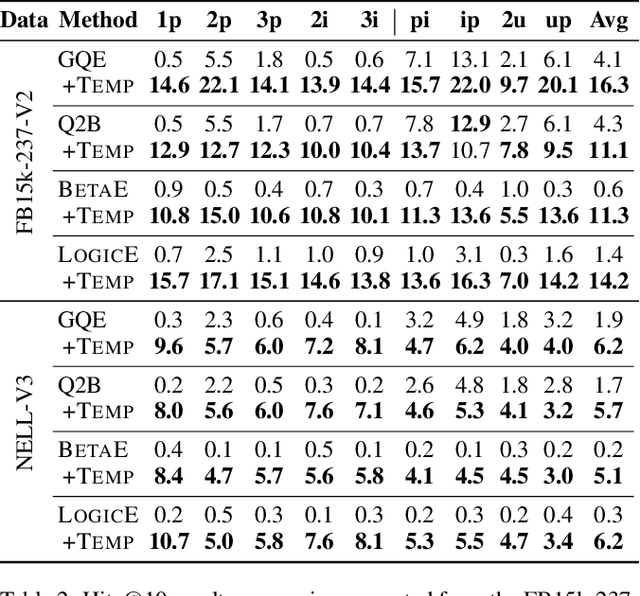
Multi-hop reasoning over real-life knowledge graphs (KGs) is a highly challenging problem as traditional subgraph matching methods are not capable to deal with noise and missing information. To address this problem, it has been recently introduced a promising approach based on jointly embedding logical queries and KGs into a low-dimensional space to identify answer entities. However, existing proposals ignore critical semantic knowledge inherently available in KGs, such as type information. To leverage type information, we propose a novel TypE-aware Message Passing (TEMP) model, which enhances the entity and relation representations in queries, and simultaneously improves generalization, deductive and inductive reasoning. Remarkably, TEMP is a plug-and-play model that can be easily incorporated into existing embedding-based models to improve their performance. Extensive experiments on three real-world datasets demonstrate TEMP's effectiveness.
A common lines approach for ab-initio modeling of molecules with tetrahedral and octahedral symmetry
Jun 17, 2022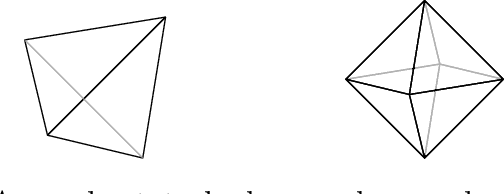

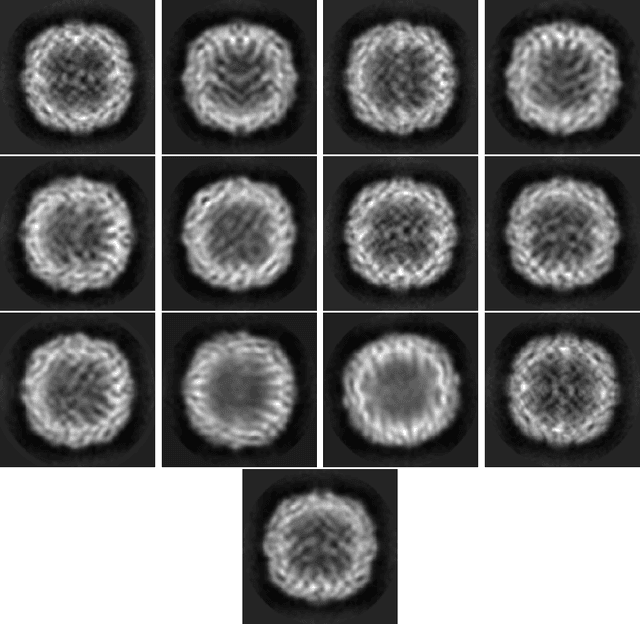
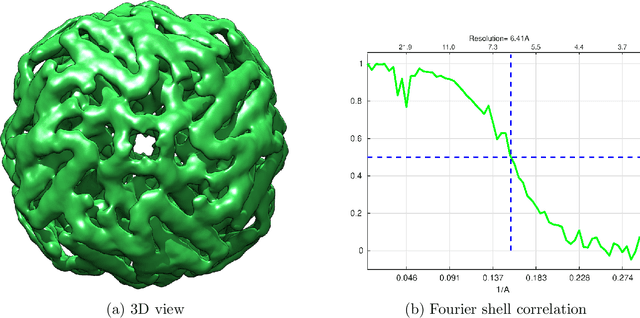
A main task in cryo-electron microscopy single particle reconstruction is to find a three-dimensional model of a molecule given a set of its randomly oriented and positioned noisy projection-images. In this work, we propose an algorithm for ab-initio reconstruction for molecules with tetrahedral or octahedral symmetry. The algorithm exploits the multiple common lines between each pair of projection-images as well as self common lines within each image. It is robust to noise in the input images as it integrates the information from all images at once. The efficiency of the proposed algorithm is demonstrated using experimental cryo-electron microscopy data.
Annotated Speech Corpus for Low Resource Indian Languages: Awadhi, Bhojpuri, Braj and Magahi
Jun 26, 2022
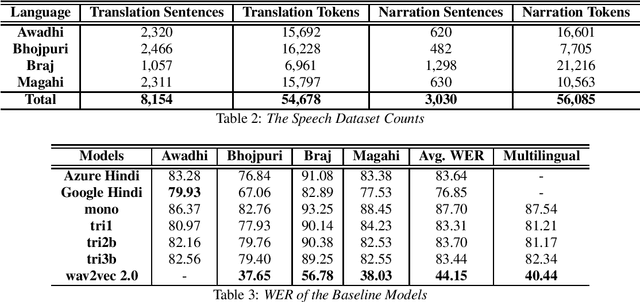
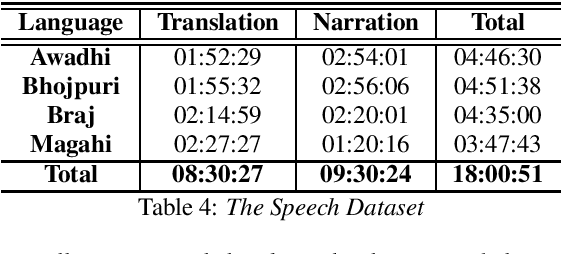
In this paper we discuss an in-progress work on the development of a speech corpus for four low-resource Indo-Aryan languages -- Awadhi, Bhojpuri, Braj and Magahi using the field methods of linguistic data collection. The total size of the corpus currently stands at approximately 18 hours (approx. 4-5 hours each language) and it is transcribed and annotated with grammatical information such as part-of-speech tags, morphological features and Universal dependency relationships. We discuss our methodology for data collection in these languages, most of which was done in the middle of the COVID-19 pandemic, with one of the aims being to generate some additional income for low-income groups speaking these languages. In the paper, we also discuss the results of the baseline experiments for automatic speech recognition system in these languages.
KOLD: Korean Offensive Language Dataset
May 23, 2022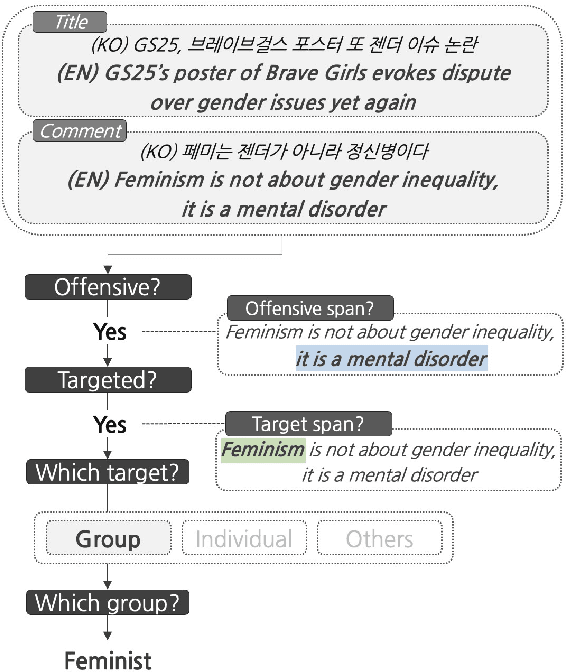
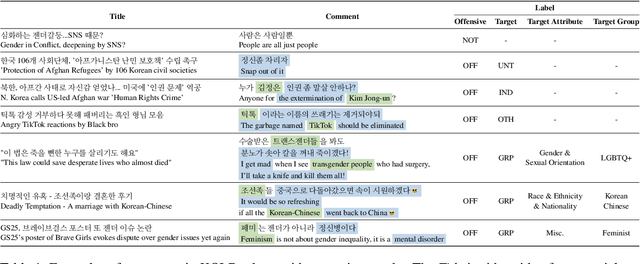
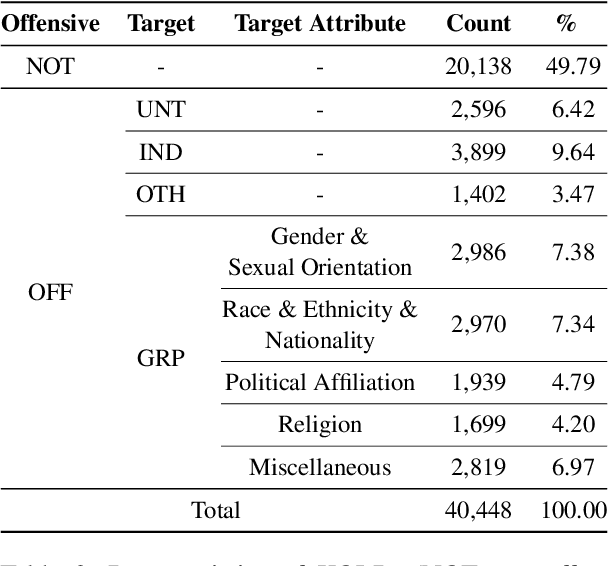
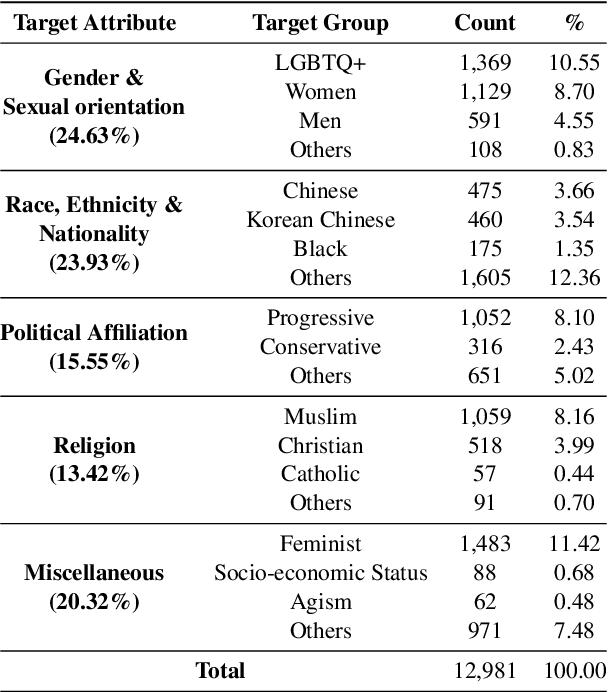
Although large attention has been paid to the detection of hate speech, most work has been done in English, failing to make it applicable to other languages. To fill this gap, we present a Korean offensive language dataset (KOLD), 40k comments labeled with offensiveness, target, and targeted group information. We also collect two types of span, offensive and target span that justifies the decision of the categorization within the text. Comparing the distribution of targeted groups with the existing English dataset, we point out the necessity of a hate speech dataset fitted to the language that best reflects the culture. Trained with our dataset, we report the baseline performance of the models built on top of large pretrained language models. We also show that title information serves as context and is helpful to discern the target of hatred, especially when they are omitted in the comment.
Memory Efficient Patch-based Training for INR-based GANs
Jul 04, 2022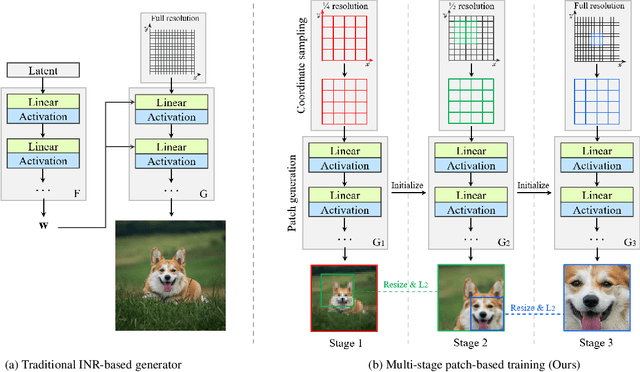
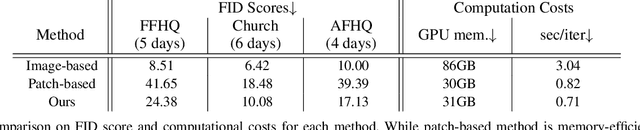


Recent studies have shown remarkable progress in GANs based on implicit neural representation (INR) - an MLP that produces an RGB value given its (x, y) coordinate. They represent an image as a continuous version of the underlying 2D signal instead of a 2D array of pixels, which opens new horizons for GAN applications (e.g., zero-shot super-resolution, image outpainting). However, training existing approaches require a heavy computational cost proportional to the image resolution, since they compute an MLP operation for every (x, y) coordinate. To alleviate this issue, we propose a multi-stage patch-based training, a novel and scalable approach that can train INR-based GANs with a flexible computational cost regardless of the image resolution. Specifically, our method allows to generate and discriminate by patch to learn the local details of the image and learn global structural information by a novel reconstruction loss to enable efficient GAN training. We conduct experiments on several benchmark datasets to demonstrate that our approach enhances baseline models in GPU memory while maintaining FIDs at a reasonable level.