 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generative Modelling With Inverse Heat Dissipation
Jun 21, 2022
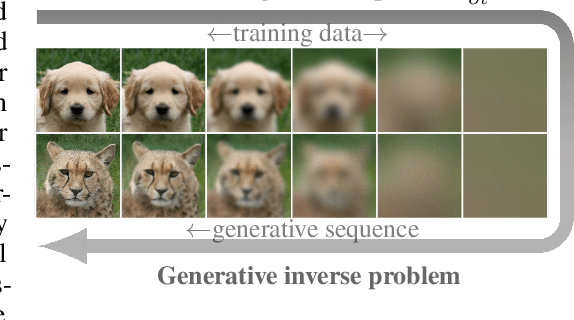

While diffusion models have shown great success in image generation, their noise-inverting generative process does not explicitly consider the structure of images, such as their inherent multi-scale nature. Inspired by diffusion models and the desirability of coarse-to-fine modelling, we propose a new model that generates images through iteratively inverting the heat equation, a PDE that locally erases fine-scale information when run over the 2D plane of the image. In our novel methodology, the solution of the forward heat equation is interpreted as a variational approximation in a directed graphical model. We demonstrate promising image quality and point out emergent qualitative properties not seen in diffusion models, such as disentanglement of overall colour and shape in images and aspects of neural network interpretability. Spectral analysis on natural images positions our model as a type of dual to diffusion models and reveals implicit inductive biases in them.
Semantic Image Synthesis via Diffusion Models
Jun 30, 2022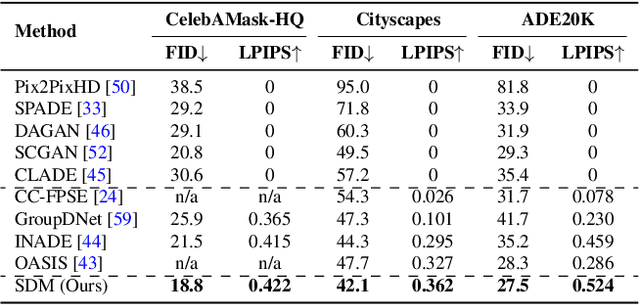
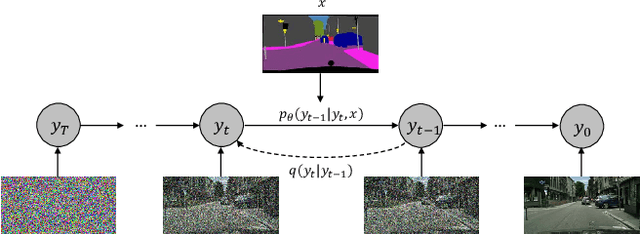
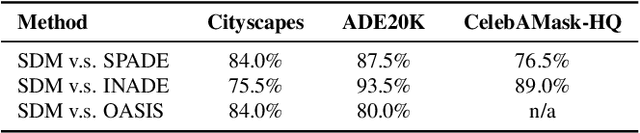
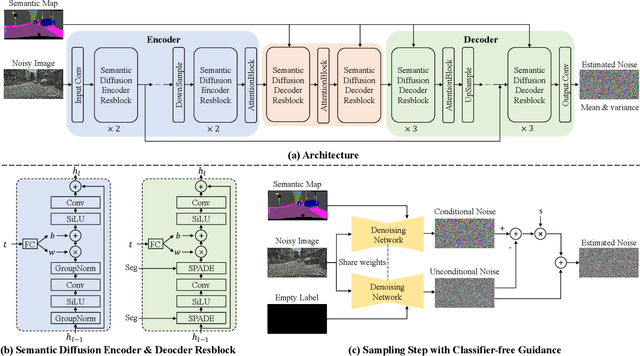
Denoising Diffusion Probabilistic Models (DDPMs) have achieved remarkable success in various image generation tasks compared with Generative Adversarial Nets (GANs). Recent work on semantic image synthesis mainly follows the \emph{de facto} GAN-based approaches, which may lead to unsatisfactory quality or diversity of generated images. In this paper, we propose a novel framework based on DDPM for semantic image synthesis. Unlike previous conditional diffusion model directly feeds the semantic layout and noisy image as input to a U-Net structure, which may not fully leverage the information in the input semantic mask, our framework processes semantic layout and noisy image differently. It feeds noisy image to the encoder of the U-Net structure while the semantic layout to the decoder by multi-layer spatially-adaptive normalization operators. To further improve the generation quality and semantic interpretability in semantic image synthesis, we introduce the classifier-free guidance sampling strategy, which acknowledge the scores of an unconditional model for sampling process. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our proposed method, achieving state-of-the-art performance in terms of fidelity~(FID) and diversity~(LPIPS).
Knowledge Graph Contrastive Learning for Recommendation
May 02, 2022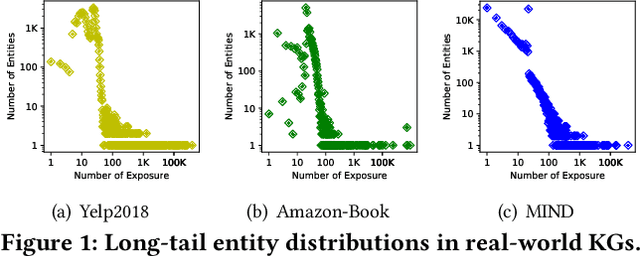

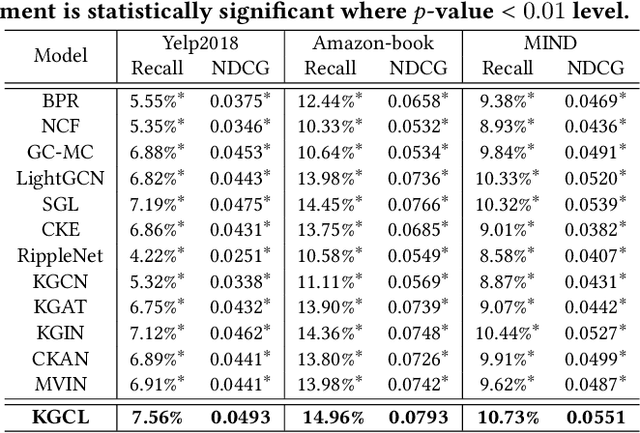
Knowledge Graphs (KGs) have been utilized as useful side information to improve recommendation quality. In those recommender systems, knowledge graph information often contains fruitful facts and inherent semantic relatedness among items. However, the success of such methods relies on the high quality knowledge graphs, and may not learn quality representations with two challenges: i) The long-tail distribution of entities results in sparse supervision signals for KG-enhanced item representation; ii) Real-world knowledge graphs are often noisy and contain topic-irrelevant connections between items and entities. Such KG sparsity and noise make the item-entity dependent relations deviate from reflecting their true characteristics, which significantly amplifies the noise effect and hinders the accurate representation of user's preference. To fill this research gap, we design a general Knowledge Graph Contrastive Learning framework (KGCL) that alleviates the information noise for knowledge graph-enhanced recommender systems. Specifically, we propose a knowledge graph augmentation schema to suppress KG noise in information aggregation, and derive more robust knowledge-aware representations for items. In addition, we exploit additional supervision signals from the KG augmentation process to guide a cross-view contrastive learning paradigm, giving a greater role to unbiased user-item interactions in gradient descent and further suppressing the noise. Extensive experiments on three public datasets demonstrate the consistent superiority of our KGCL over state-of-the-art techniques. KGCL also achieves strong performance in recommendation scenarios with sparse user-item interactions, long-tail and noisy KG entities. Our implementation codes are available at https://github.com/yuh-yang/KGCL-SIGIR22
Forecasting Future World Events with Neural Networks
Jun 30, 2022
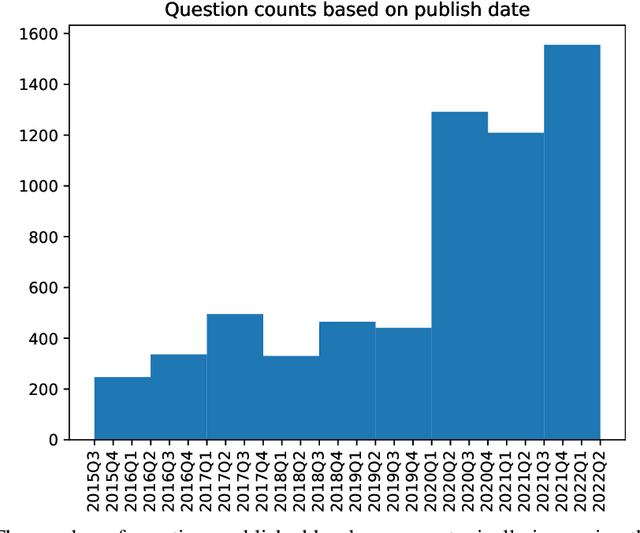
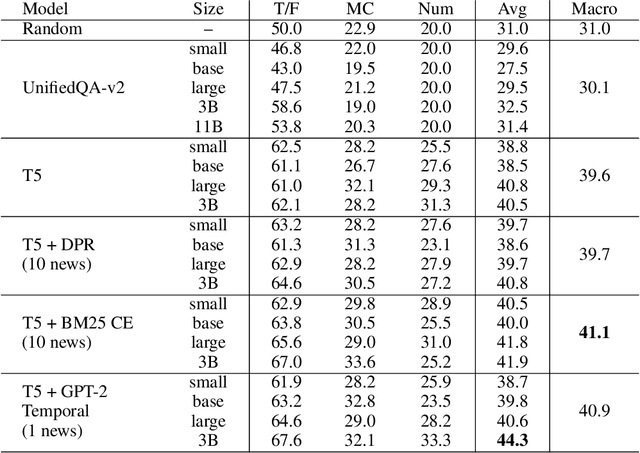

Forecasting future world events is a challenging but valuable task. Forecasts of climate, geopolitical conflict, pandemics and economic indicators help shape policy and decision making. In these domains, the judgment of expert humans contributes to the best forecasts. Given advances in language modeling, can these forecasts be automated? To this end, we introduce Autocast, a dataset containing thousands of forecasting questions and an accompanying news corpus. Questions are taken from forecasting tournaments, ensuring high quality, real-world importance, and diversity. The news corpus is organized by date, allowing us to precisely simulate the conditions under which humans made past forecasts (avoiding leakage from the future). Motivated by the difficulty of forecasting numbers across orders of magnitude (e.g. global cases of COVID-19 in 2022), we also curate IntervalQA, a dataset of numerical questions and metrics for calibration. We test language models on our forecasting task and find that performance is far below a human expert baseline. However, performance improves with increased model size and incorporation of relevant information from the news corpus. In sum, Autocast poses a novel challenge for large language models and improved performance could bring large practical benefits.
DEMI: Discriminative Estimator of Mutual Information
Oct 05, 2020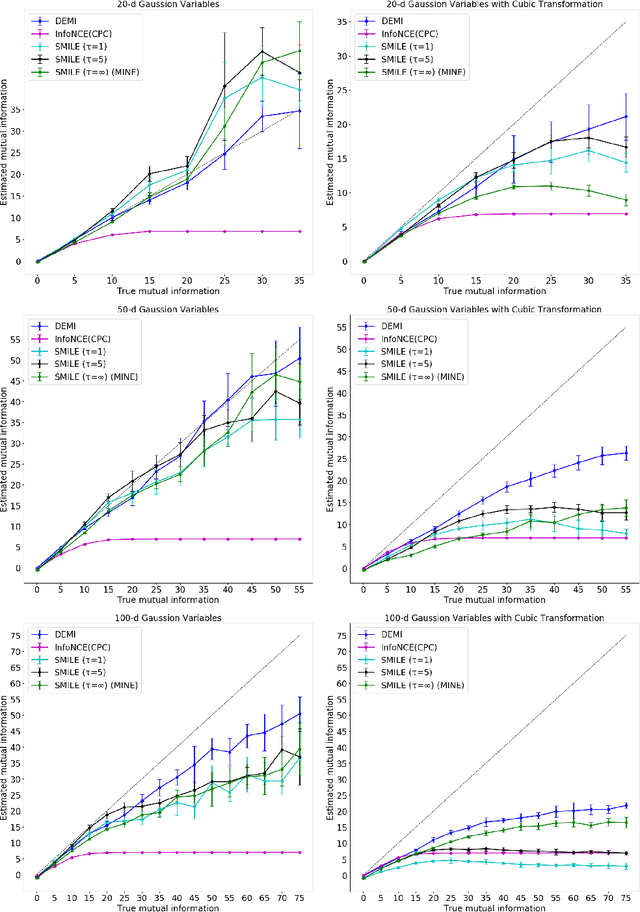
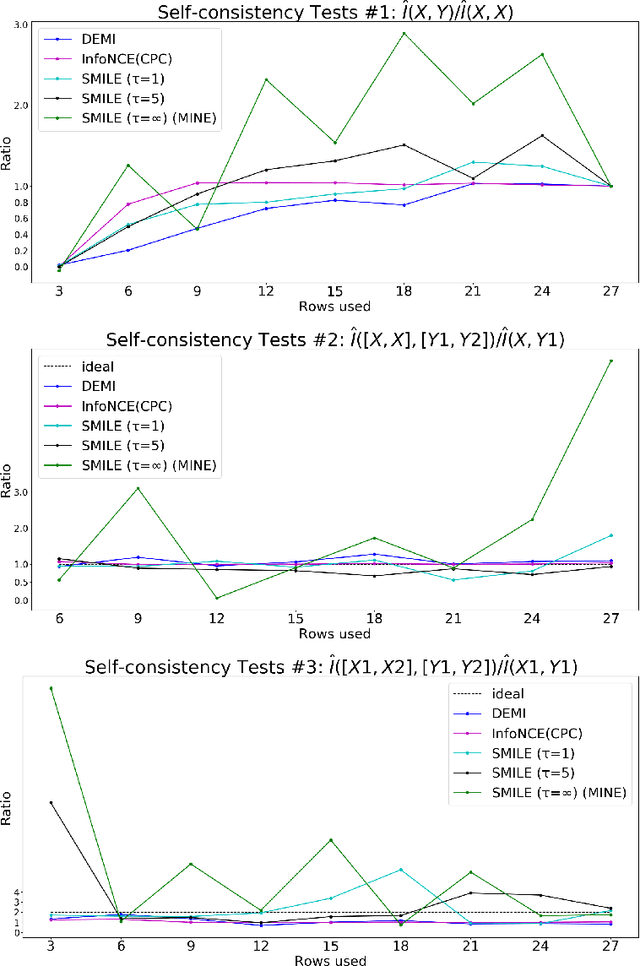
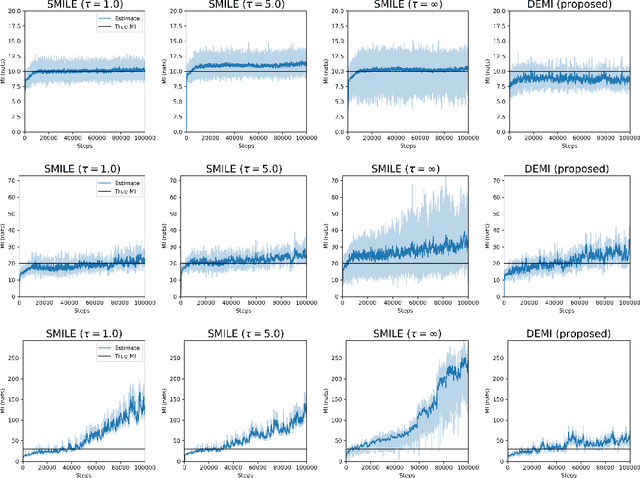
Estimating mutual information between continuous random variables is often intractable and extremely challenging for high-dimensional data. Recent progress has leveraged neural networks to optimize variational lower bounds on mutual information. Although showing promise for this difficult problem, the variational methods have been theoretically and empirically proven to have serious statistical limitations: 1) most of the approaches cannot make accurate estimates when the underlying mutual information is either low or high; 2) the resulting estimators may suffer from high variance. Our approach is based on training a classifier that provides the probability whether a data sample pair is drawn from the joint distribution or from the product of its marginal distributions. We use this probabilistic prediction to estimate mutual information. We show theoretically that our method and other variational approaches are equivalent when they achieve their optimum, while our approach does not optimize a variational bound. Empirical results demonstrate high accuracy and a good bias/variance tradeoff using our approach.
Design and Simulation of an Autonomous Quantum Flying Robot Vehicle: An IBM Quantum Experience
Jun 01, 2022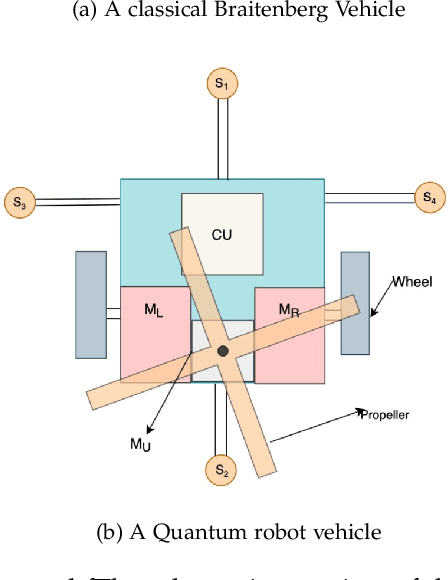
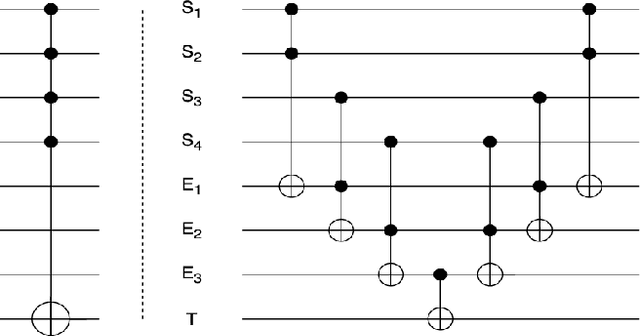
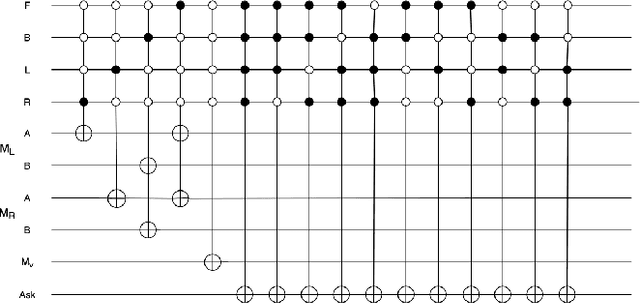
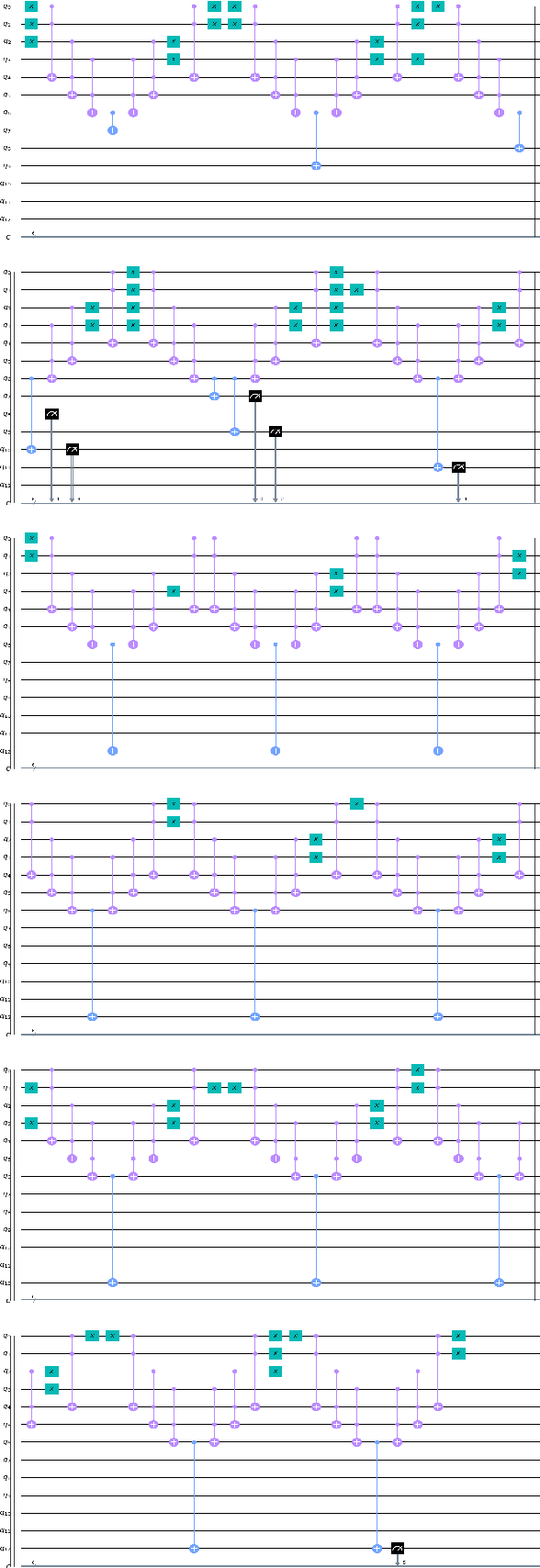
The application of quantum computation and information in robotics has caught the attention of researchers off late. The field of robotics has always put its effort on the minimization of the space occupied by the robot, and on making the robot `smarter. `The smartness of a robot is its sensitivity to its surroundings and the user input and its ability to react upon them desirably. Quantum phenomena in robotics make sure that the robots occupy less space and the ability of quantum computation to process the huge amount of information effectively, consequently making the robot smarter. Braitenberg vehicle is a simple circuited robot that moves according to the input that its sensors receive. Building upon that, we propose a quantum robot vehicle that is `smart' enough to understand the complex situations more than that of a simple Braitenberg vehicle and navigate itself as per the obstacles present. It can detect an obstacle-free path and can navigate itself accordingly. It also takes input from the user when there is more than one free path available. When left with no option on the ground, it can airlift itself off the ground. As these vehicles sort of `react to the surrounding conditions, this idea can be used to build artificial life and genetic algorithms, space exploration and deep-earth exploration probes, and a handy tool in defense and intelligence services.
Riemannian data-dependent randomized smoothing for neural networks certification
Jun 21, 2022

Certification of neural networks is an important and challenging problem that has been attracting the attention of the machine learning community since few years. In this paper, we focus on randomized smoothing (RS) which is considered as the state-of-the-art method to obtain certifiably robust neural networks. In particular, a new data-dependent RS technique called ANCER introduced recently can be used to certify ellipses with orthogonal axis near each input data of the neural network. In this work, we remark that ANCER is not invariant under rotation of input data and propose a new rotationally-invariant formulation of it which can certify ellipses without constraints on their axis. Our approach called Riemannian Data Dependant Randomized Smoothing (RDDRS) relies on information geometry techniques on the manifold of covariance matrices and can certify bigger regions than ANCER based on our experiments on the MNIST dataset.
Rethinking Unsupervised Neural Superpixel Segmentation
Jun 21, 2022


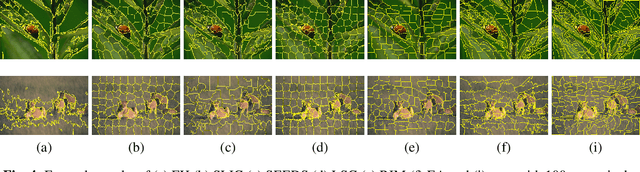
Recently, the concept of unsupervised learning for superpixel segmentation via CNNs has been studied. Essentially, such methods generate superpixels by convolutional neural network (CNN) employed on a single image, and such CNNs are trained without any labels or further information. Thus, such approach relies on the incorporation of priors, typically by designing an objective function that guides the solution towards a meaningful superpixel segmentation. In this paper we propose three key elements to improve the efficacy of such networks: (i) the similarity of the \emph{soft} superpixelated image compared to the input image, (ii) the enhancement and consideration of object edges and boundaries and (iii) a modified architecture based on atrous convolution, which allow for a wider field of view, functioning as a multi-scale component in our network. By experimenting with the BSDS500 dataset, we find evidence to the significance of our proposal, both qualitatively and quantitatively.
Recurrent Dynamic Embedding for Video Object Segmentation
May 08, 2022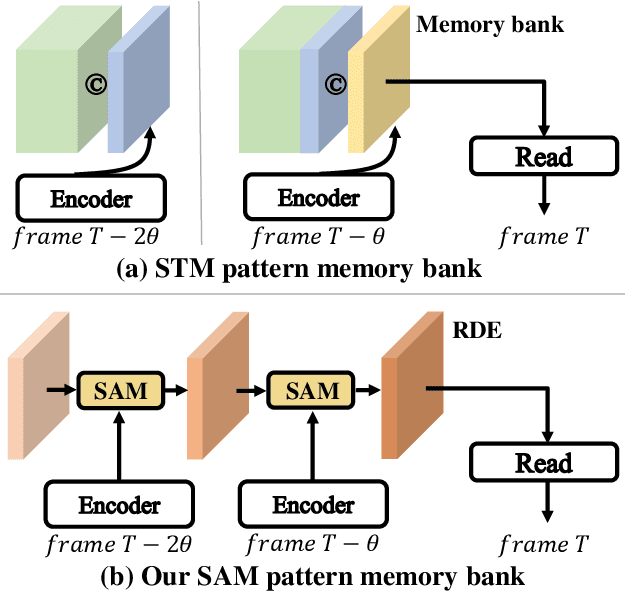
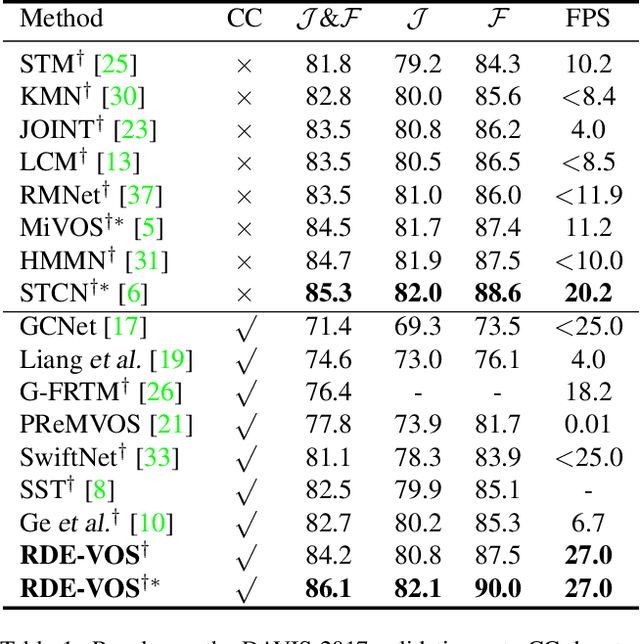
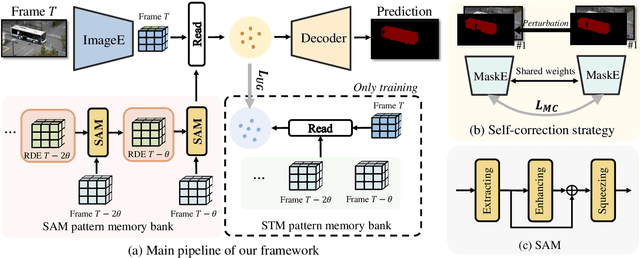
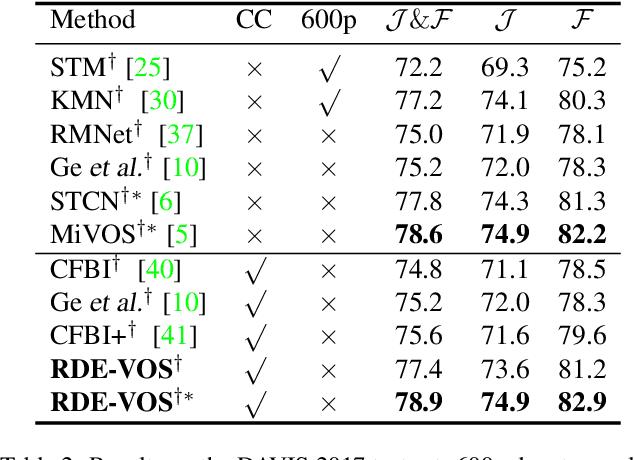
Space-time memory (STM) based video object segmentation (VOS) networks usually keep increasing memory bank every several frames, which shows excellent performance. However, 1) the hardware cannot withstand the ever-increasing memory requirements as the video length increases. 2) Storing lots of information inevitably introduces lots of noise, which is not conducive to reading the most important information from the memory bank. In this paper, we propose a Recurrent Dynamic Embedding (RDE) to build a memory bank of constant size. Specifically, we explicitly generate and update RDE by the proposed Spatio-temporal Aggregation Module (SAM), which exploits the cue of historical information. To avoid error accumulation owing to the recurrent usage of SAM, we propose an unbiased guidance loss during the training stage, which makes SAM more robust in long videos. Moreover, the predicted masks in the memory bank are inaccurate due to the inaccurate network inference, which affects the segmentation of the query frame. To address this problem, we design a novel self-correction strategy so that the network can repair the embeddings of masks with different qualities in the memory bank. Extensive experiments show our method achieves the best tradeoff between performance and speed. Code is available at https://github.com/Limingxing00/RDE-VOS-CVPR2022.
Entropy-driven Sampling and Training Scheme for Conditional Diffusion Generation
Jun 27, 2022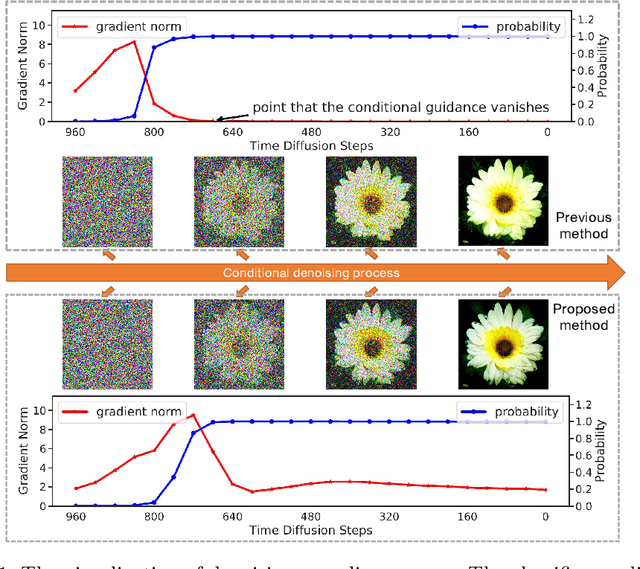
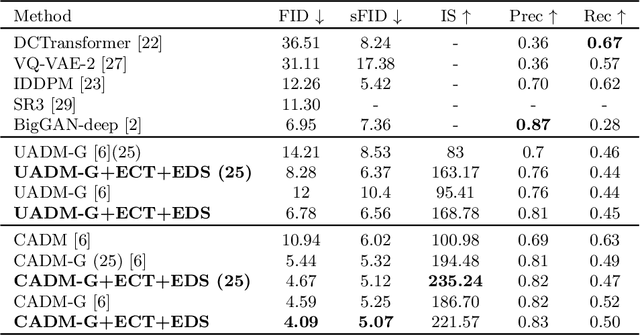
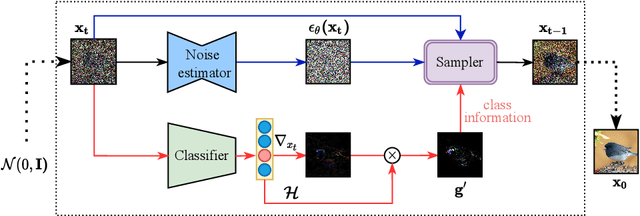
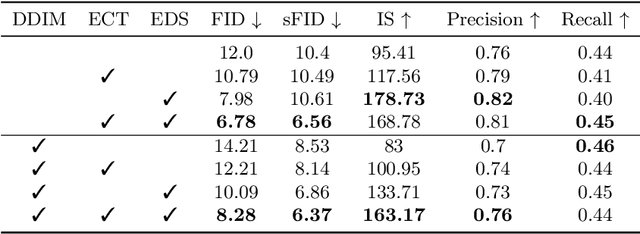
Denoising Diffusion Probabilistic Model (DDPM) is able to make flexible conditional image generation from prior noise to real data, by introducing an independent noise-aware classifier to provide conditional gradient guidance at each time step of denoising process. However, due to the ability of classifier to easily discriminate an incompletely generated image only with high-level structure, the gradient, which is a kind of class information guidance, tends to vanish early, leading to the collapse from conditional generation process into the unconditional process. To address this problem, we propose two simple but effective approaches from two perspectives. For sampling procedure, we introduce the entropy of predicted distribution as the measure of guidance vanishing level and propose an entropy-aware scaling method to adaptively recover the conditional semantic guidance. For training stage, we propose the entropy-aware optimization objectives to alleviate the overconfident prediction for noisy data.On ImageNet1000 256x256, with our proposed sampling scheme and trained classifier, the pretrained conditional and unconditional DDPM model can achieve 10.89% (4.59 to 4.09) and 43.5% (12 to 6.78) FID improvement respectively.