 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Video Dialog as Conversation about Objects Living in Space-Time
Jul 08, 2022
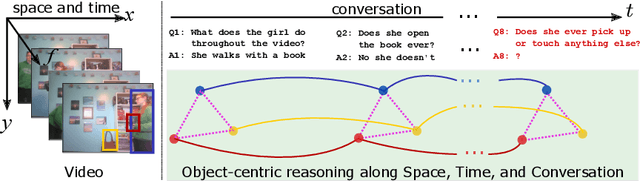

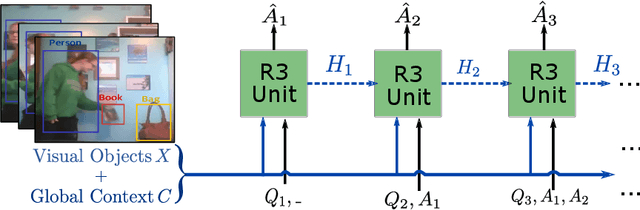
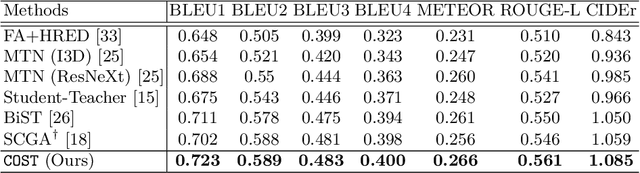
It would be a technological feat to be able to create a system that can hold a meaningful conversation with humans about what they watch. A setup toward that goal is presented as a video dialog task, where the system is asked to generate natural utterances in response to a question in an ongoing dialog. The task poses great visual, linguistic, and reasoning challenges that cannot be easily overcome without an appropriate representation scheme over video and dialog that supports high-level reasoning. To tackle these challenges we present a new object-centric framework for video dialog that supports neural reasoning dubbed COST - which stands for Conversation about Objects in Space-Time. Here dynamic space-time visual content in videos is first parsed into object trajectories. Given this video abstraction, COST maintains and tracks object-associated dialog states, which are updated upon receiving new questions. Object interactions are dynamically and conditionally inferred for each question, and these serve as the basis for relational reasoning among them. COST also maintains a history of previous answers, and this allows retrieval of relevant object-centric information to enrich the answer forming process. Language production then proceeds in a step-wise manner, taking into the context of the current utterance, the existing dialog, the current question. We evaluate COST on the DSTC7 and DSTC8 benchmarks, demonstrating its competitiveness against state-of-the-arts.
Abs-CAM: A Gradient Optimization Interpretable Approach for Explanation of Convolutional Neural Networks
Jul 08, 2022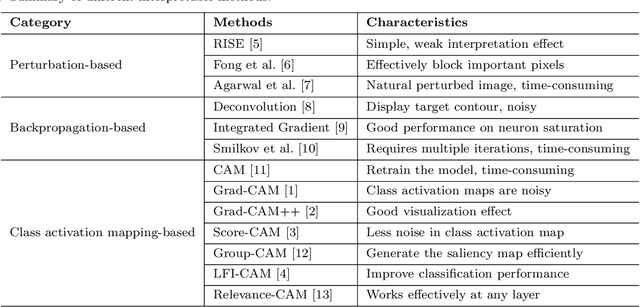
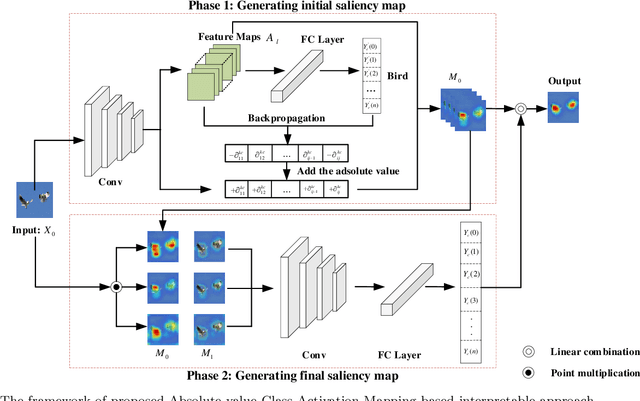
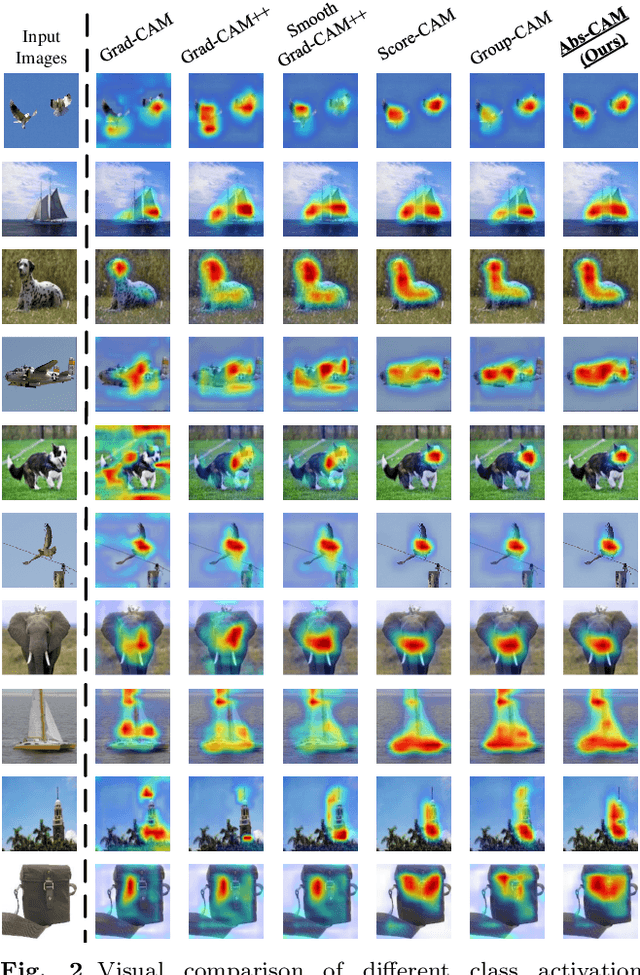
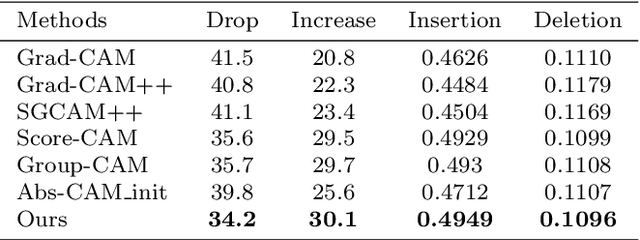
The black-box nature of Deep Neural Networks (DNNs) severely hinders its performance improvement and application in specific scenes. In recent years, class activation mapping-based method has been widely used to interpret the internal decisions of models in computer vision tasks. However, when this method uses backpropagation to obtain gradients, it will cause noise in the saliency map, and even locate features that are irrelevant to decisions. In this paper, we propose an Absolute value Class Activation Mapping-based (Abs-CAM) method, which optimizes the gradients derived from the backpropagation and turns all of them into positive gradients to enhance the visual features of output neurons' activation, and improve the localization ability of the saliency map. The framework of Abs-CAM is divided into two phases: generating initial saliency map and generating final saliency map. The first phase improves the localization ability of the saliency map by optimizing the gradient, and the second phase linearly combines the initial saliency map with the original image to enhance the semantic information of the saliency map. We conduct qualitative and quantitative evaluation of the proposed method, including Deletion, Insertion, and Pointing Game. The experimental results show that the Abs-CAM can obviously eliminate the noise in the saliency map, and can better locate the features related to decisions, and is superior to the previous methods in recognition and localization tasks.
OmniTab: Pretraining with Natural and Synthetic Data for Few-shot Table-based Question Answering
Jul 08, 2022
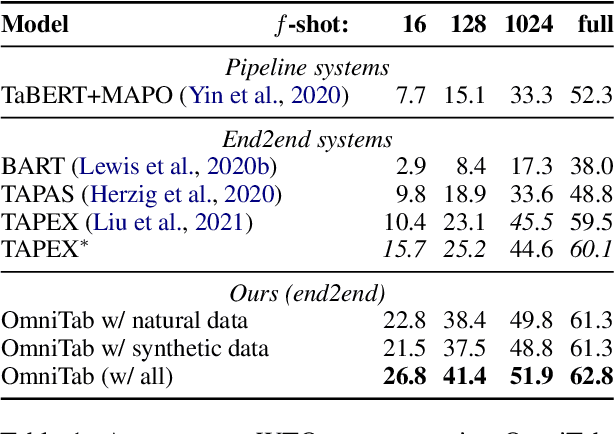
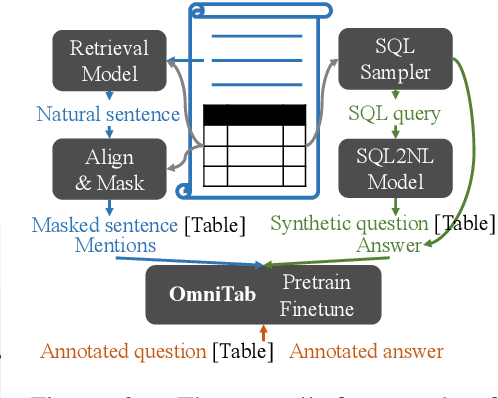
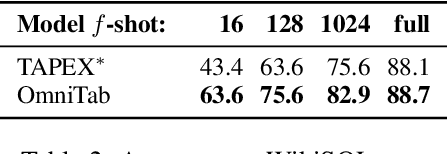
The information in tables can be an important complement to text, making table-based question answering (QA) systems of great value. The intrinsic complexity of handling tables often adds an extra burden to both model design and data annotation. In this paper, we aim to develop a simple table-based QA model with minimal annotation effort. Motivated by the fact that table-based QA requires both alignment between questions and tables and the ability to perform complicated reasoning over multiple table elements, we propose an omnivorous pretraining approach that consumes both natural and synthetic data to endow models with these respective abilities. Specifically, given freely available tables, we leverage retrieval to pair them with relevant natural sentences for mask-based pretraining, and synthesize NL questions by converting SQL sampled from tables for pretraining with a QA loss. We perform extensive experiments in both few-shot and full settings, and the results clearly demonstrate the superiority of our model OmniTab, with the best multitasking approach achieving an absolute gain of 16.2% and 2.7% in 128-shot and full settings respectively, also establishing a new state-of-the-art on WikiTableQuestions. Detailed ablations and analyses reveal different characteristics of natural and synthetic data, shedding light on future directions in omnivorous pretraining. Code, pretraining data, and pretrained models are available at https://github.com/jzbjyb/OmniTab.
Image Aesthetics Assessment Using Graph Attention Network
Jun 28, 2022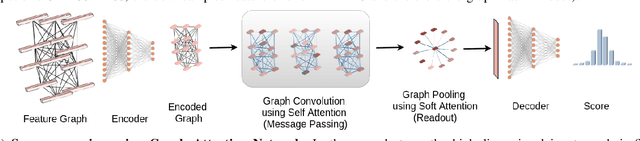
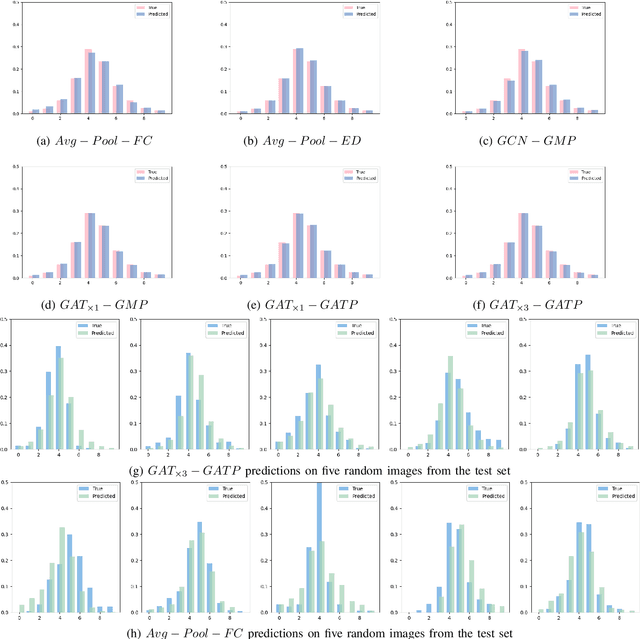

Aspect ratio and spatial layout are two of the principal factors determining the aesthetic value of a photograph. But, incorporating these into the traditional convolution-based frameworks for the task of image aesthetics assessment is problematic. The aspect ratio of the photographs gets distorted while they are resized/cropped to a fixed dimension to facilitate training batch sampling. On the other hand, the convolutional filters process information locally and are limited in their ability to model the global spatial layout of a photograph. In this work, we present a two-stage framework based on graph neural networks and address both these problems jointly. First, we propose a feature-graph representation in which the input image is modelled as a graph, maintaining its original aspect ratio and resolution. Second, we propose a graph neural network architecture that takes this feature-graph and captures the semantic relationship between the different regions of the input image using visual attention. Our experiments show that the proposed framework advances the state-of-the-art results in aesthetic score regression on the Aesthetic Visual Analysis (AVA) benchmark.
Neural Program Synthesis with Query
May 08, 2022

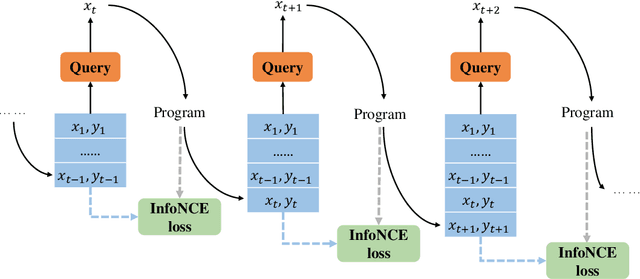

Aiming to find a program satisfying the user intent given input-output examples, program synthesis has attracted increasing interest in the area of machine learning. Despite the promising performance of existing methods, most of their success comes from the privileged information of well-designed input-output examples. However, providing such input-output examples is unrealistic because it requires the users to have the ability to describe the underlying program with a few input-output examples under the training distribution. In this work, we propose a query-based framework that trains a query neural network to generate informative input-output examples automatically and interactively from a large query space. The quality of the query depends on the amount of the mutual information between the query and the corresponding program, which can guide the optimization of the query framework. To estimate the mutual information more accurately, we introduce the functional space (F-space) which models the relevance between the input-output examples and the programs in a differentiable way. We evaluate the effectiveness and generalization of the proposed query-based framework on the Karel task and the list processing task. Experimental results show that the query-based framework can generate informative input-output examples which achieve and even outperform well-designed input-output examples.
PixelGame: Infrared small target segmentation as a Nash equilibrium
May 26, 2022
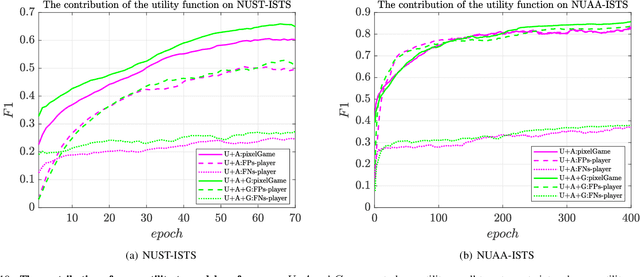


A key challenge of infrared small target segmentation (ISTS) is to balance false negative pixels (FNs) and false positive pixels (FPs). Traditional methods combine FNs and FPs into a single objective by weighted sum, and the optimization process is decided by one actor. Minimizing FNs and FPs with the same strategy leads to antagonistic decisions. To address this problem, we propose a competitive game framework (pixelGame) from a novel perspective for ISTS. In pixelGame, FNs and FPs are controlled by different player whose goal is to minimize their own utility function. FNs-player and FPs-player are designed with different strategies: One is to minimize FNs and the other is to minimize FPs. The utility function drives the evolution of the two participants in competition. We consider the Nash equilibrium of pixelGame as the optimal solution. In addition, we propose maximum information modulation (MIM) to highlight the tar-get information. MIM effectively focuses on the salient region including small targets. Extensive experiments on two standard public datasets prove the effectiveness of our method. Compared with other state-of-the-art methods, our method achieves better performance in terms of F1-measure (F1) and the intersection of union (IoU).
Attribute Exploration with Multiple Contradicting Partial Experts
May 31, 2022
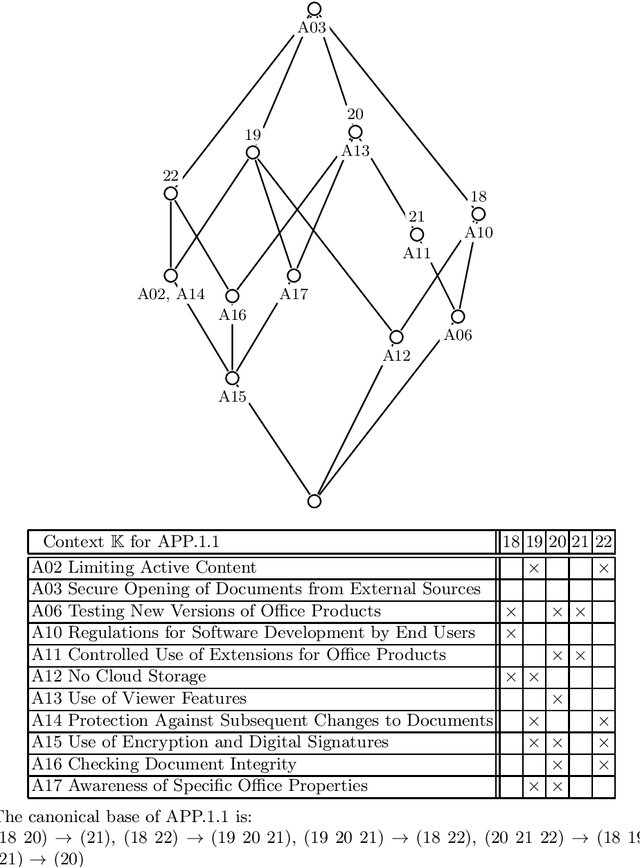
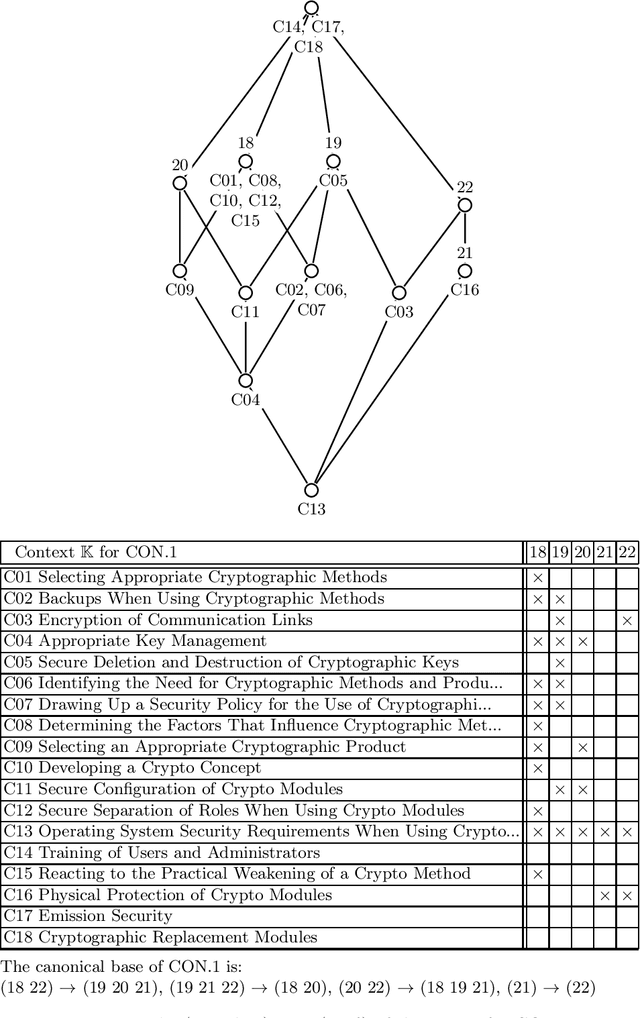
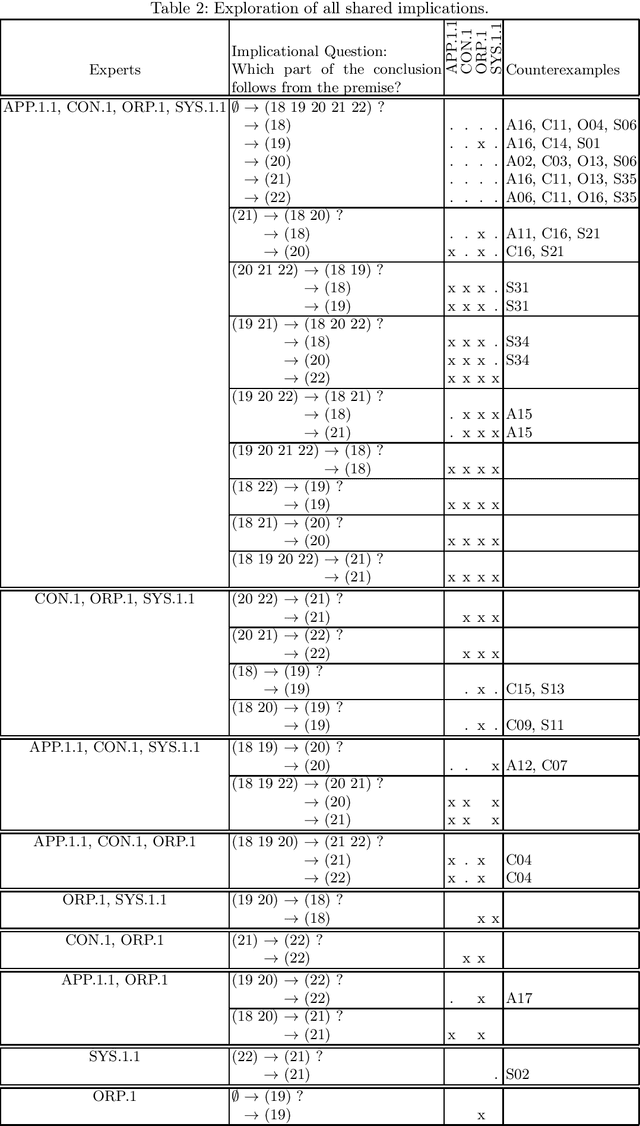
Attribute exploration is a method from Formal Concept Analysis (FCA) that helps a domain expert discover structural dependencies in knowledge domains which can be represented as formal contexts (cross tables of objects and attributes). In this paper we present an extension of attribute exploration that allows for a group of domain experts and explores their shared views. Each expert has their own view of the domain and the views of multiple experts may contain contradicting information.
FLVoogd: Robust And Privacy Preserving Federated Learning
Jun 24, 2022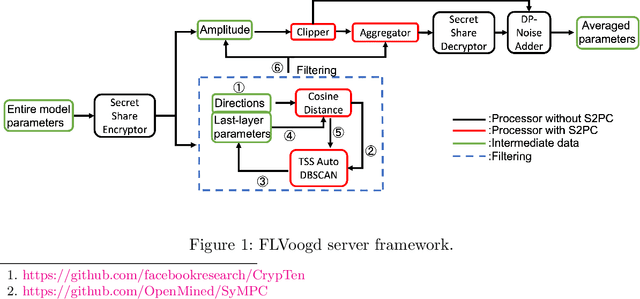

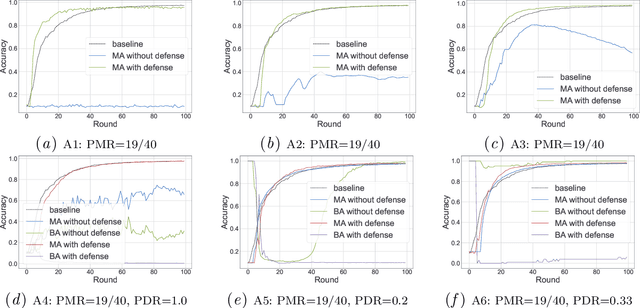
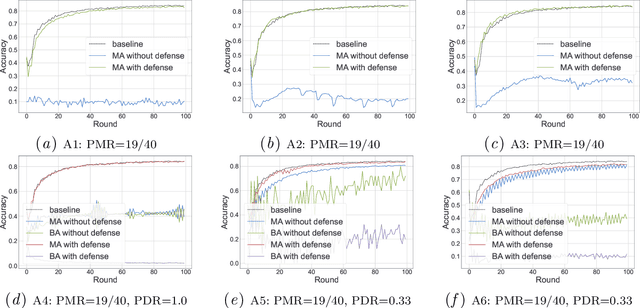
In this work, we propose FLVoogd, an updated federated learning method in which servers and clients collaboratively eliminate Byzantine attacks while preserving privacy. In particular, servers use automatic Density-based Spatial Clustering of Applications with Noise (DBSCAN) combined with S2PC to cluster the benign majority without acquiring sensitive personal information. Meanwhile, clients build dual models and perform test-based distance controlling to adjust their local models toward the global one to achieve personalizing. Our framework is automatic and adaptive that servers/clients don't need to tune the parameters during the training. In addition, our framework leverages Secure Multi-party Computation (SMPC) operations, including multiplications, additions, and comparison, where costly operations, like division and square root, are not required. Evaluations are carried out on some conventional datasets from the image classification field. The result shows that FLVoogd can effectively reject malicious uploads in most scenarios; meanwhile, it avoids data leakage from the server-side.
Panning for gold: Lessons learned from the platform-agnostic automated detection of political content in textual data
Jul 01, 2022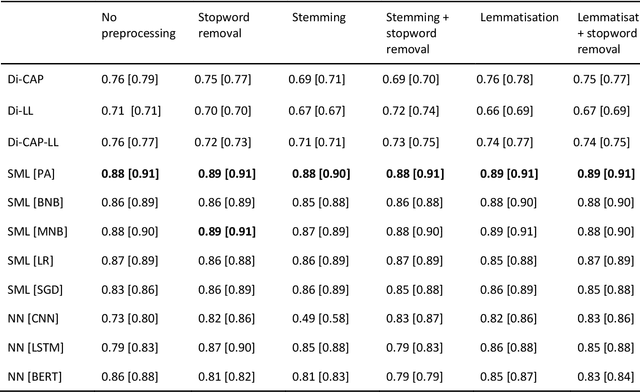
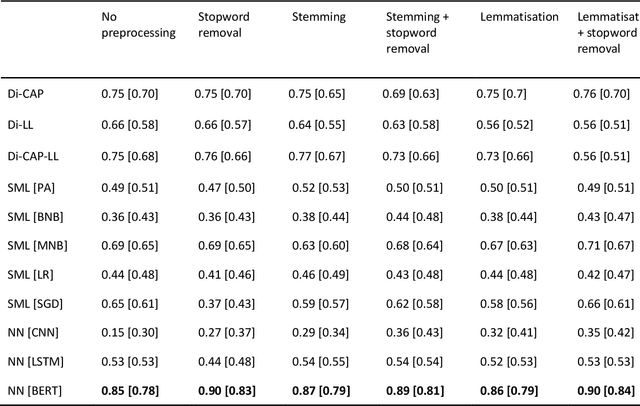
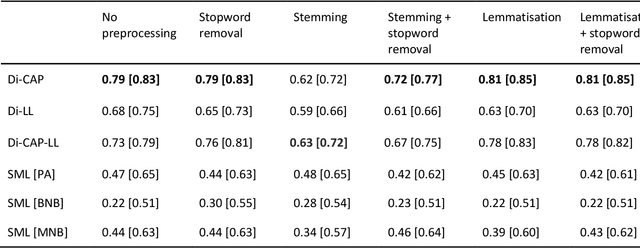
The growing availability of data about online information behaviour enables new possibilities for political communication research. However, the volume and variety of these data makes them difficult to analyse and prompts the need for developing automated content approaches relying on a broad range of natural language processing techniques (e.g. machine learning- or neural network-based ones). In this paper, we discuss how these techniques can be used to detect political content across different platforms. Using three validation datasets, which include a variety of political and non-political textual documents from online platforms, we systematically compare the performance of three groups of detection techniques relying on dictionaries, supervised machine learning, or neural networks. We also examine the impact of different modes of data preprocessing (e.g. stemming and stopword removal) on the low-cost implementations of these techniques using a large set (n = 66) of detection models. Our results show the limited impact of preprocessing on model performance, with the best results for less noisy data being achieved by neural network- and machine-learning-based models, in contrast to the more robust performance of dictionary-based models on noisy data.
Combining Reward Information from Multiple Sources
Mar 22, 2021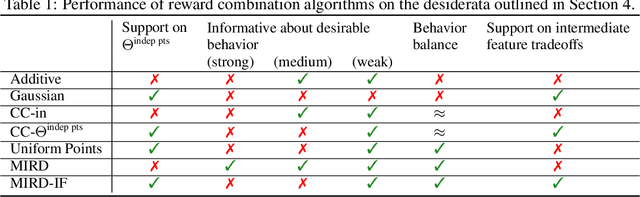
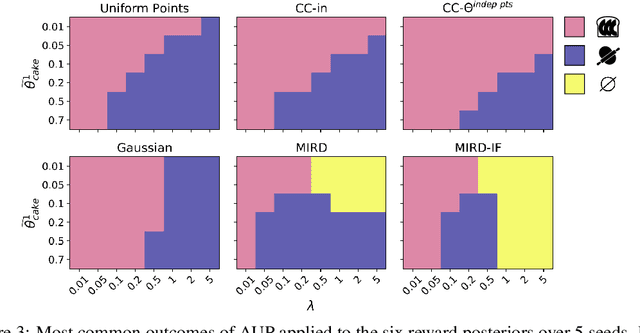
Given two sources of evidence about a latent variable, one can combine the information from both by multiplying the likelihoods of each piece of evidence. However, when one or both of the observation models are misspecified, the distributions will conflict. We study this problem in the setting with two conflicting reward functions learned from different sources. In such a setting, we would like to retreat to a broader distribution over reward functions, in order to mitigate the effects of misspecification. We assume that an agent will maximize expected reward given this distribution over reward functions, and identify four desiderata for this setting. We propose a novel algorithm, Multitask Inverse Reward Design (MIRD), and compare it to a range of simple baselines. While all methods must trade off between conservatism and informativeness, through a combination of theory and empirical results on a toy environment, we find that MIRD and its variant MIRD-IF strike a good balance between the two.