 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Context Aware Sentence Representation Pretraining for Multi-lingual Dense Retrieval
Jun 07, 2022
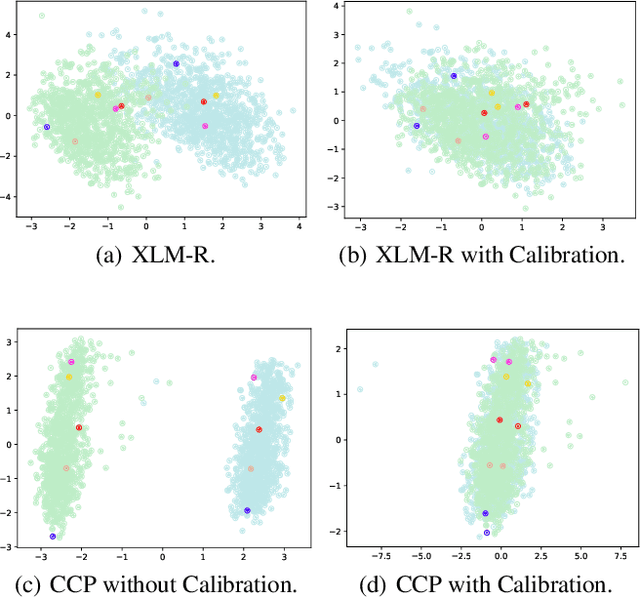

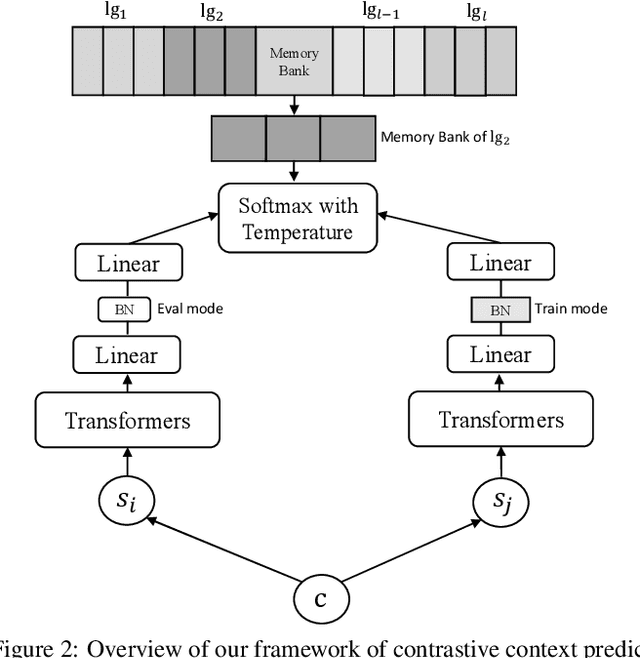

Recent research demonstrates the effectiveness of using pretrained language models (PLM) to improve dense retrieval and multilingual dense retrieval. In this work, we present a simple but effective monolingual pretraining task called contrastive context prediction~(CCP) to learn sentence representation by modeling sentence level contextual relation. By pushing the embedding of sentences in a local context closer and pushing random negative samples away, different languages could form isomorphic structure, then sentence pairs in two different languages will be automatically aligned. Our experiments show that model collapse and information leakage are very easy to happen during contrastive training of language model, but language-specific memory bank and asymmetric batch normalization operation play an essential role in preventing collapsing and information leakage, respectively. Besides, a post-processing for sentence embedding is also very effective to achieve better retrieval performance. On the multilingual sentence retrieval task Tatoeba, our model achieves new SOTA results among methods without using bilingual data. Our model also shows larger gain on Tatoeba when transferring between non-English pairs. On two multi-lingual query-passage retrieval tasks, XOR Retrieve and Mr.TYDI, our model even achieves two SOTA results in both zero-shot and supervised setting among all pretraining models using bilingual data.
STVGFormer: Spatio-Temporal Video Grounding with Static-Dynamic Cross-Modal Understanding
Jul 06, 2022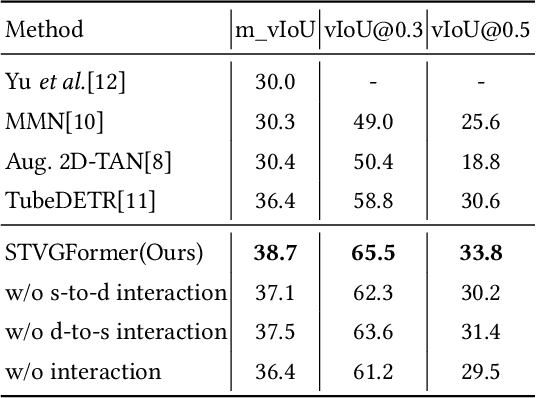
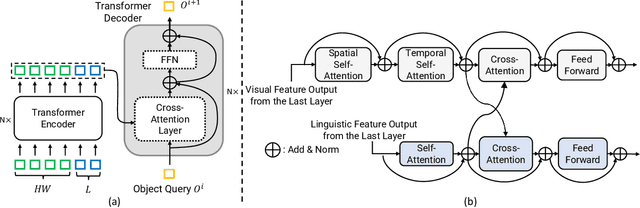
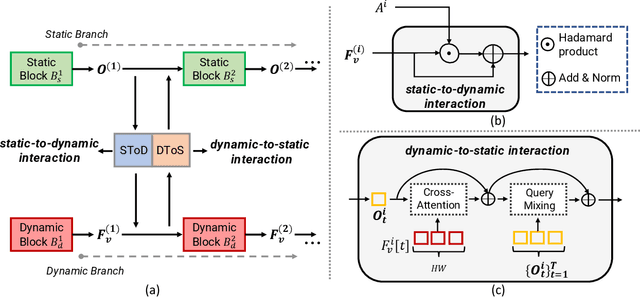
In this technical report, we introduce our solution to human-centric spatio-temporal video grounding task. We propose a concise and effective framework named STVGFormer, which models spatiotemporal visual-linguistic dependencies with a static branch and a dynamic branch. The static branch performs cross-modal understanding in a single frame and learns to localize the target object spatially according to intra-frame visual cues like object appearances. The dynamic branch performs cross-modal understanding across multiple frames. It learns to predict the starting and ending time of the target moment according to dynamic visual cues like motions. Both the static and dynamic branches are designed as cross-modal transformers. We further design a novel static-dynamic interaction block to enable the static and dynamic branches to transfer useful and complementary information from each other, which is shown to be effective to improve the prediction on hard cases. Our proposed method achieved 39.6% vIoU and won the first place in the HC-STVG track of the 4th Person in Context Challenge.
RESECT-SEG: Open access annotations of intra-operative brain tumor ultrasound images
Jul 13, 2022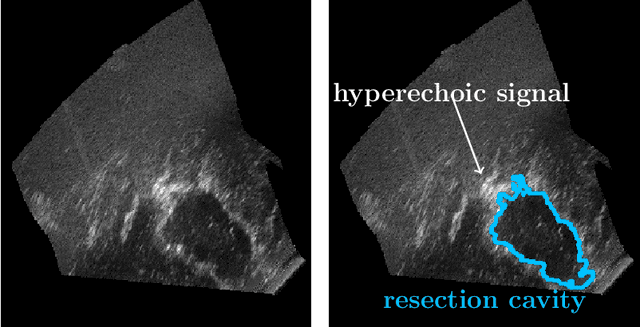
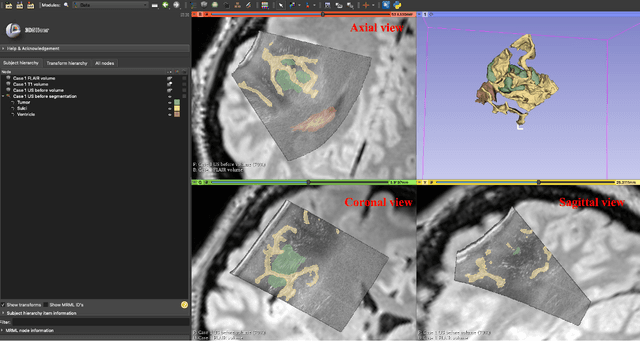
Purpose: Registration and segmentation of magnetic resonance (MR) and ultrasound (US) images play an essential role in surgical planning and resection of brain tumors. However, validating these techniques is challenging due to the scarcity of publicly accessible sources with high-quality ground truth information. To this end, we propose a unique annotation dataset of tumor tissues and resection cavities from the previously published RESECT dataset (Xiao et al. 2017) to encourage a more rigorous assessments of image processing techniques. Acquisition and validation methods: The RESECT database consists of MR and intraoperative US (iUS) images of 23 patients who underwent resection surgeries. The proposed dataset contains tumor tissues and resection cavity annotations of the iUS images. The quality of annotations were validated by two highly experienced neurosurgeons through several assessment criteria. Data format and availability: Annotations of tumor tissues and resection cavities are provided in 3D NIFTI formats. Both sets of annotations are accessible online in the \url{https://osf.io/6y4db}. Discussion and potential applications: The proposed database includes tumor tissue and resection cavity annotations from real-world clinical ultrasound brain images to evaluate segmentation and registration methods. These labels could also be used to train deep learning approaches. Eventually, this dataset should further improve the quality of image guidance in neurosurgery.
Real-Time Gesture Recognition with Virtual Glove Markers
Jul 06, 2022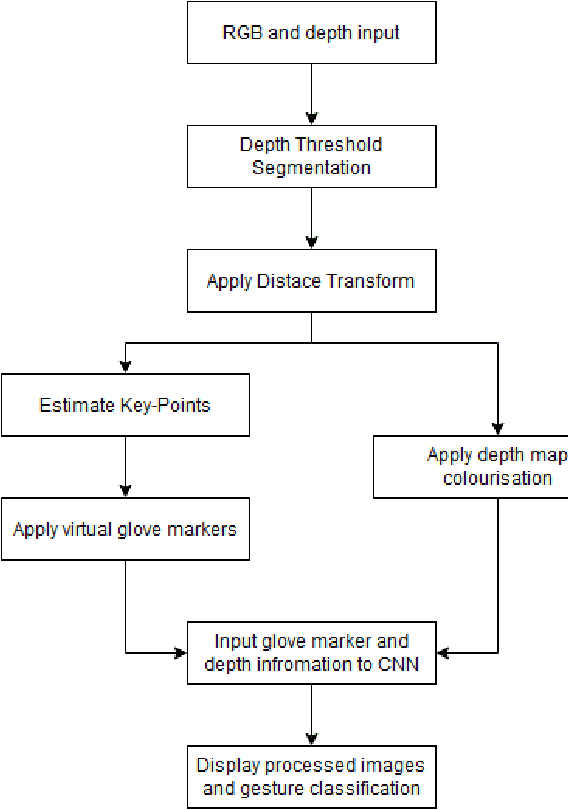



Due to the universal non-verbal natural communication approach that allows for effective communication between humans, gesture recognition technology has been steadily developing over the previous few decades. Many different strategies have been presented in research articles based on gesture recognition to try to create an effective system to send non-verbal natural communication information to computers, using both physical sensors and computer vision. Hyper accurate real-time systems, on the other hand, have only recently began to occupy the study field, with each adopting a range of methodologies due to past limits such as usability, cost, speed, and accuracy. A real-time computer vision-based human-computer interaction tool for gesture recognition applications that acts as a natural user interface is proposed. Virtual glove markers on users hands will be created and used as input to a deep learning model for the real-time recognition of gestures. The results obtained show that the proposed system would be effective in real-time applications including social interaction through telepresence and rehabilitation.
Explain to Not Forget: Defending Against Catastrophic Forgetting with XAI
May 11, 2022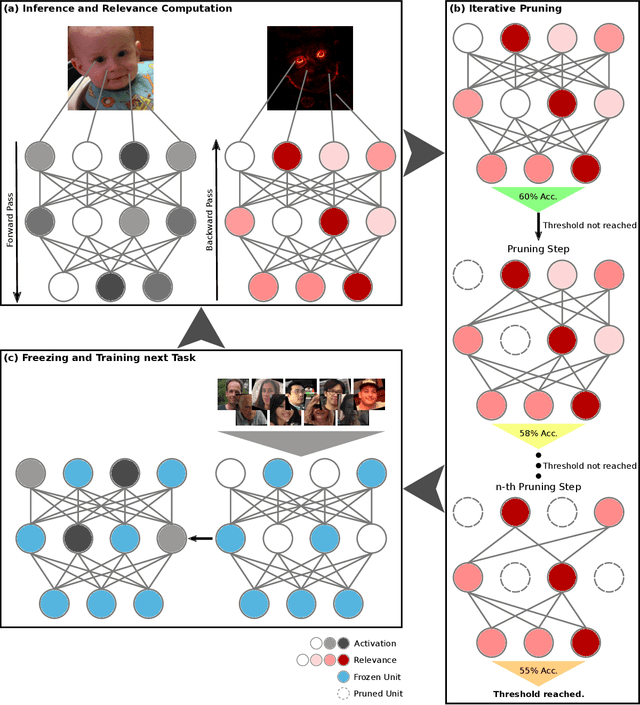
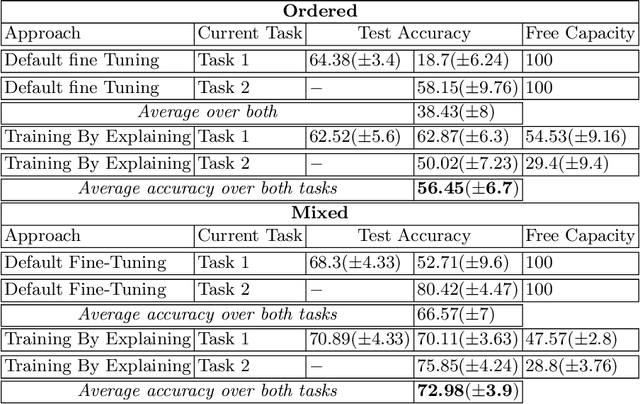
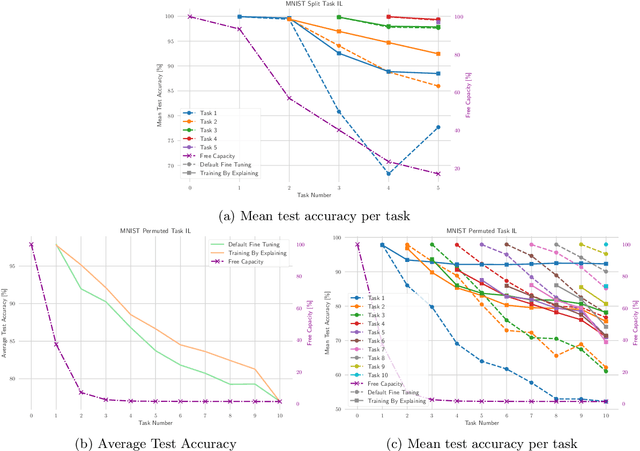
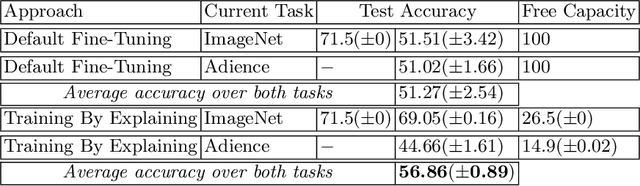
The ability to continuously process and retain new information like we do naturally as humans is a feat that is highly sought after when training neural networks. Unfortunately, the traditional optimization algorithms often require large amounts of data available during training time and updates wrt. new data are difficult after the training process has been completed. In fact, when new data or tasks arise, previous progress may be lost as neural networks are prone to catastrophic forgetting. Catastrophic forgetting describes the phenomenon when a neural network completely forgets previous knowledge when given new information. We propose a novel training algorithm called training by explaining in which we leverage Layer-wise Relevance Propagation in order to retain the information a neural network has already learned in previous tasks when training on new data. The method is evaluated on a range of benchmark datasets as well as more complex data. Our method not only successfully retains the knowledge of old tasks within the neural networks but does so more resource-efficiently than other state-of-the-art solutions.
CHARM: A Hierarchical Deep Learning Model for Classification of Complex Human Activities Using Motion Sensors
Jul 16, 2022
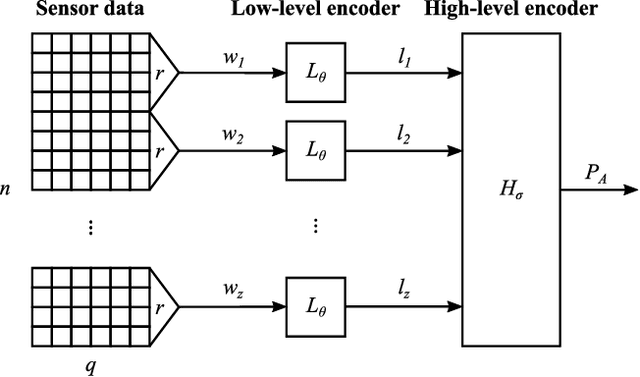
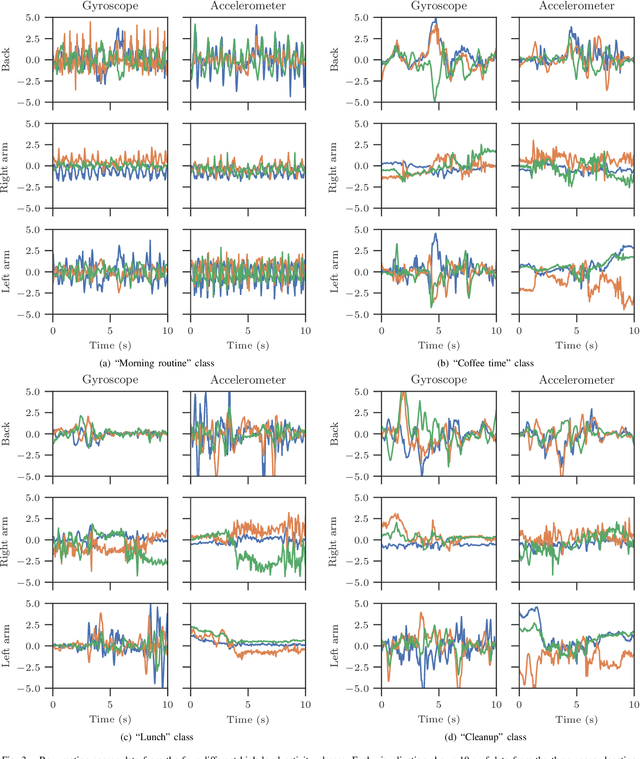
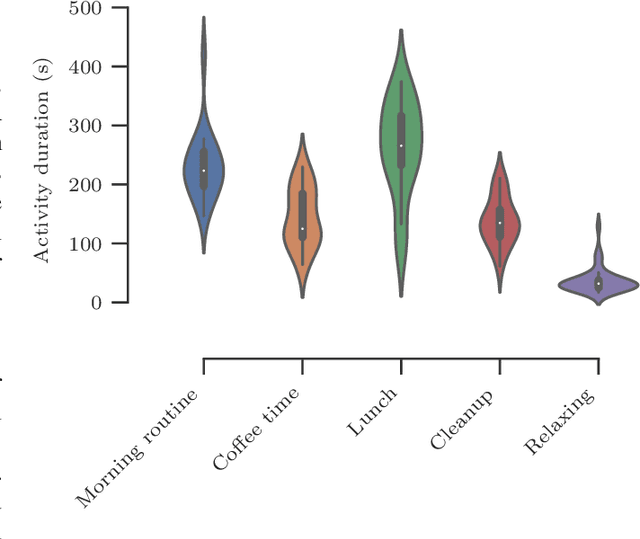
In this paper, we report a hierarchical deep learning model for classification of complex human activities using motion sensors. In contrast to traditional Human Activity Recognition (HAR) models used for event-based activity recognition, such as step counting, fall detection, and gesture identification, this new deep learning model, which we refer to as CHARM (Complex Human Activity Recognition Model), is aimed for recognition of high-level human activities that are composed of multiple different low-level activities in a non-deterministic sequence, such as meal preparation, house chores, and daily routines. CHARM not only quantitatively outperforms state-of-the-art supervised learning approaches for high-level activity recognition in terms of average accuracy and F1 scores, but also automatically learns to recognize low-level activities, such as manipulation gestures and locomotion modes, without any explicit labels for such activities. This opens new avenues for Human-Machine Interaction (HMI) modalities using wearable sensors, where the user can choose to associate an automated task with a high-level activity, such as controlling home automation (e.g., robotic vacuum cleaners, lights, and thermostats) or presenting contextually relevant information at the right time (e.g., reminders, status updates, and weather/news reports). In addition, the ability to learn low-level user activities when trained using only high-level activity labels may pave the way to semi-supervised learning of HAR tasks that are inherently difficult to label.
Network Pruning via Feature Shift Minimization
Jul 06, 2022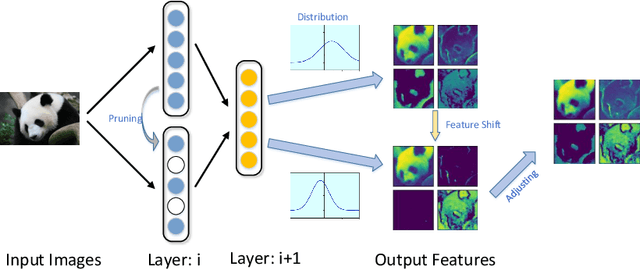
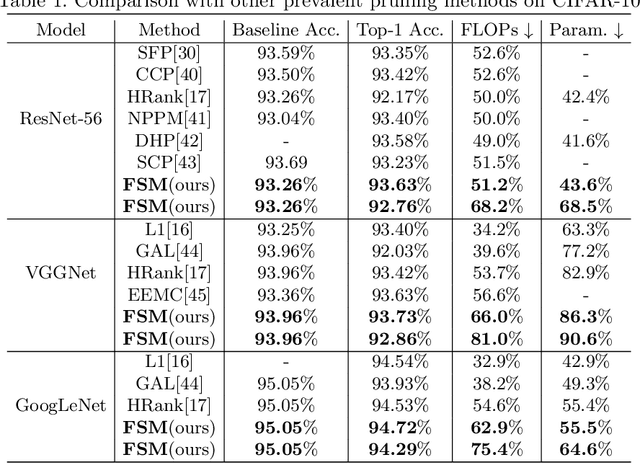
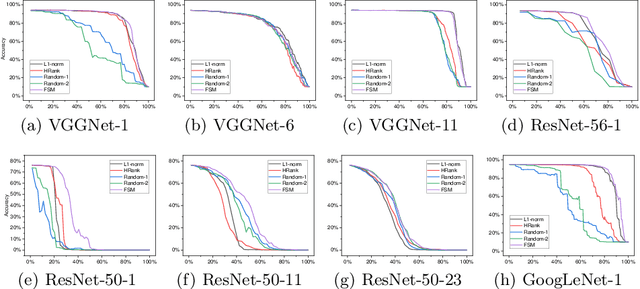
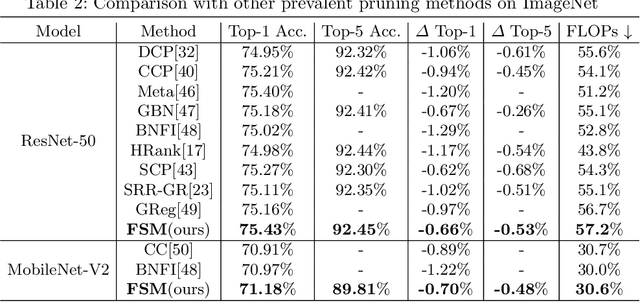
Channel pruning is widely used to reduce the complexity of deep network models. Recent pruning methods usually identify which parts of the network to discard by proposing a channel importance criterion. However, recent studies have shown that these criteria do not work well in all conditions. In this paper, we propose a novel Feature Shift Minimization (FSM) method to compress CNN models, which evaluates the feature shift by converging the information of both features and filters. Specifically, we first investigate the compression efficiency with some prevalent methods in different layer-depths and then propose the feature shift concept. Then, we introduce an approximation method to estimate the magnitude of the feature shift, since it is difficult to compute it directly. Besides, we present a distribution-optimization algorithm to compensate for the accuracy loss and improve the network compression efficiency. The proposed method yields state-of-the-art performance on various benchmark networks and datasets, verified by extensive experiments. The codes can be available at \url{https://github.com/lscgx/FSM}.
AIGenC: AI generalisation via creativity
May 23, 2022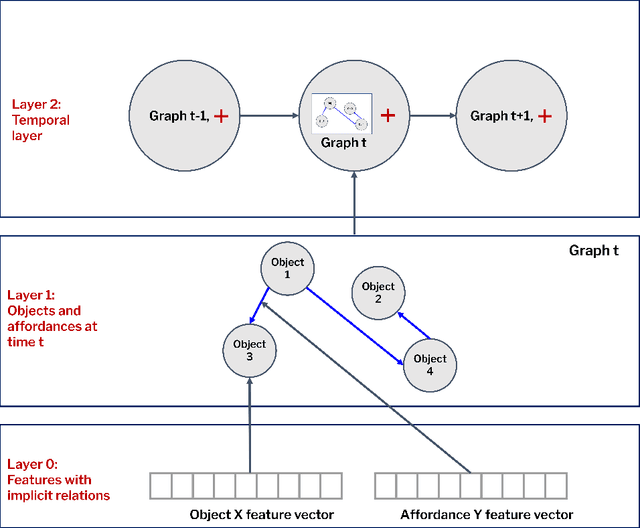
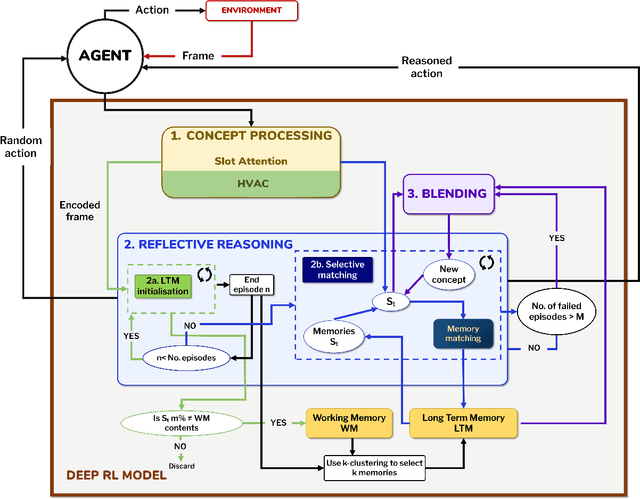
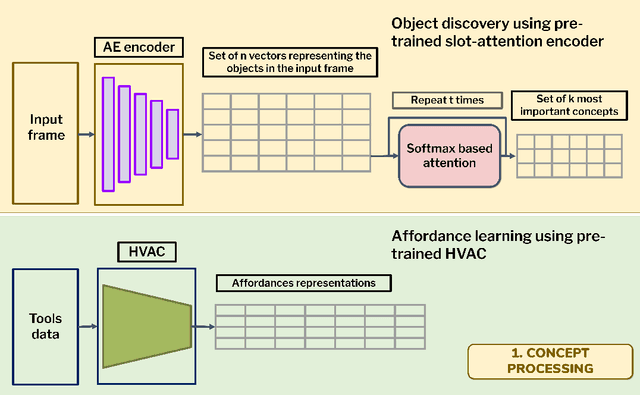
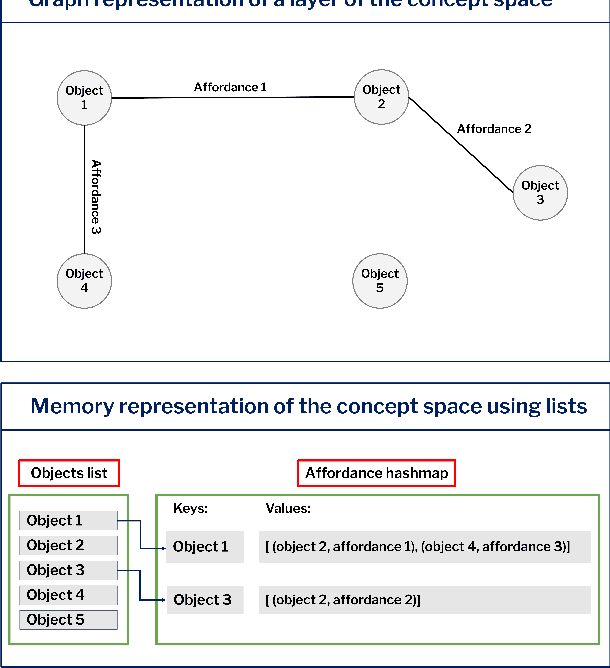
This paper introduces a computational model of creative problem solving in deep reinforcement learning agents, inspired by cognitive theories of creativity. The AIGenC model aims at enabling artificial agents to learn, use and generate transferable representations. AIGenC is embedded in a deep learning architecture that includes three main components: concept processing, reflective reasoning, and blending of concepts. The first component extracts objects and affordances from sensory input and encodes them in a concept space, represented as a hierarchical graph structure. Concept representations are stored in a dual memory system. Goal-directed and temporal information acquired by the agent during deep reinforcement learning enriches the representations creating a higher-level of abstraction in the concept space. In parallel, a process akin to reflective reasoning detects and recovers from memory concepts relevant to the task according to a matching process that calculates a similarity value between the current state and memory graph structures. Once an interaction is finalised, rewards and temporal information are added to the graph structure, creating a higher abstraction level. If reflective reasoning fails to offer a suitable solution, a blending process comes into place to create new concepts by combining past information. We discuss the model's capability to yield better out-of-distribution generalisation in artificial agents, thus advancing toward artificial general intelligence. To the best of our knowledge, this is the first computational model, beyond mere formal theories, that posits a solution to creative problem solving within a deep learning architecture.
Attention-driven Active Vision for Efficient Reconstruction of Plants and Targeted Plant Parts
Jun 21, 2022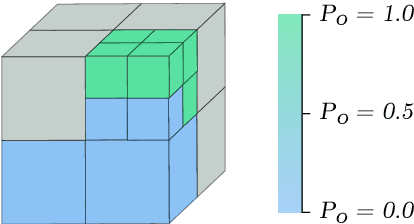
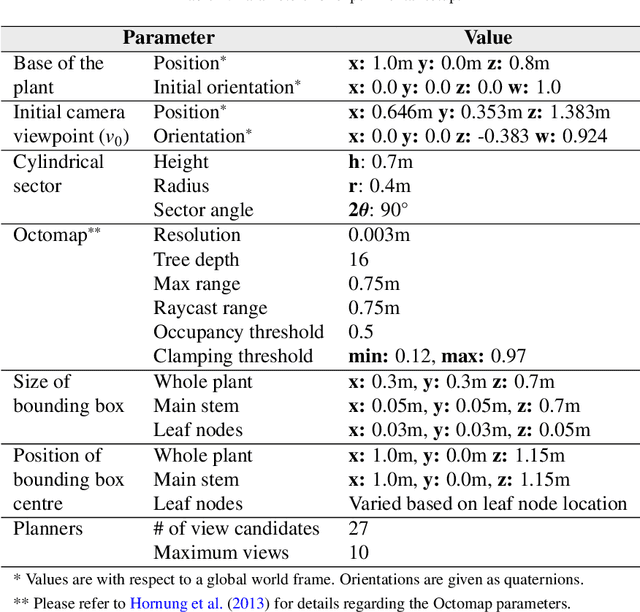
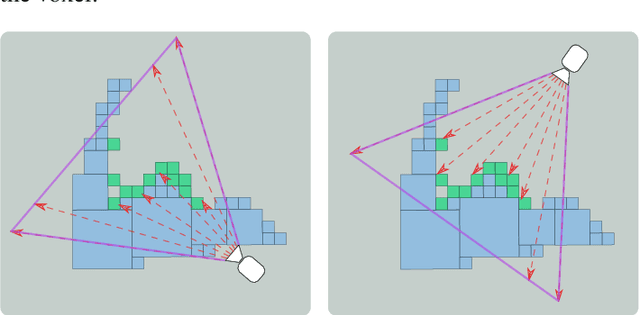
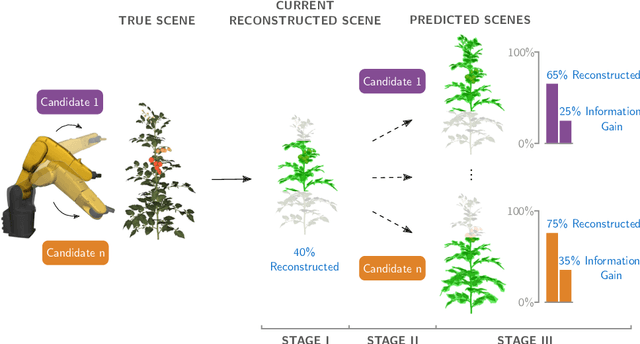
Visual reconstruction of tomato plants by a robot is extremely challenging due to the high levels of variation and occlusion in greenhouse environments. The paradigm of active-vision helps overcome these challenges by reasoning about previously acquired information and systematically planning camera viewpoints to gather novel information about the plant. However, existing active-vision algorithms cannot perform well on targeted perception objectives, such as the 3D reconstruction of leaf nodes, because they do not distinguish between the plant-parts that need to be reconstructed and the rest of the plant. In this paper, we propose an attention-driven active-vision algorithm that considers only the relevant plant-parts according to the task-at-hand. The proposed approach was evaluated in a simulated environment on the task of 3D reconstruction of tomato plants at varying levels of attention, namely the whole plant, the main stem and the leaf nodes. Compared to pre-defined and random approaches, our approach improves the accuracy of 3D reconstruction by 9.7% and 5.3% for the whole plant, 14.2% and 7.9% for the main stem, and 25.9% and 17.3% for the leaf nodes respectively within the first 3 viewpoints. Also, compared to pre-defined and random approaches, our approach reconstructs 80% of the whole plant and the main stem in 1 less viewpoint and 80% of the leaf nodes in 3 less viewpoints. We also demonstrated that the attention-driven NBV planner works effectively despite changes to the plant models, the amount of occlusion, the number of candidate viewpoints and the resolutions of reconstruction. By adding an attention mechanism to active-vision, it is possible to efficiently reconstruct the whole plant and targeted plant parts. We conclude that an attention mechanism for active-vision is necessary to significantly improve the quality of perception in complex agro-food environments.
Temporal Lift Pooling for Continuous Sign Language Recognition
Jul 18, 2022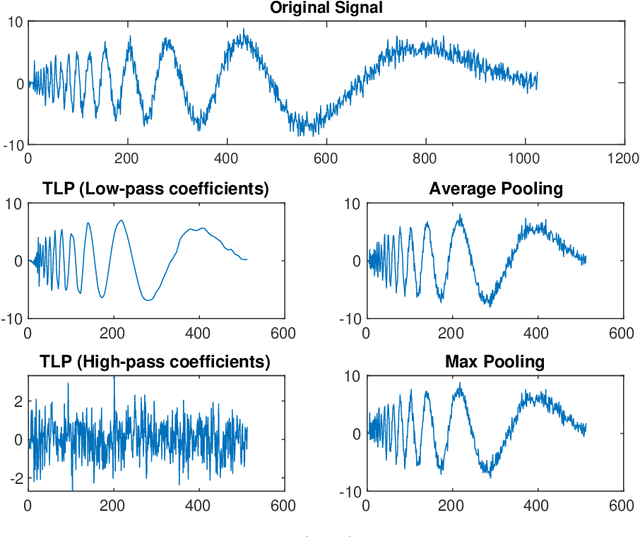

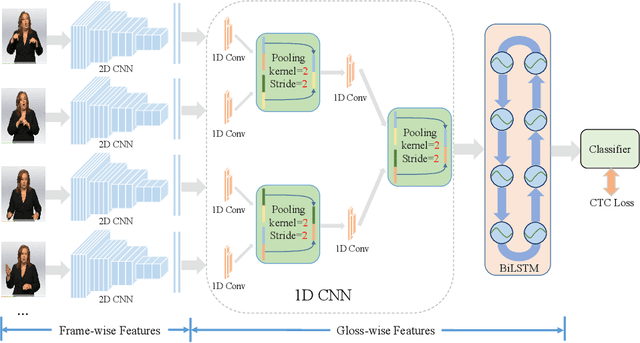
Pooling methods are necessities for modern neural networks for increasing receptive fields and lowering down computational costs. However, commonly used hand-crafted pooling approaches, e.g., max pooling and average pooling, may not well preserve discriminative features. While many researchers have elaborately designed various pooling variants in spatial domain to handle these limitations with much progress, the temporal aspect is rarely visited where directly applying hand-crafted methods or these specialized spatial variants may not be optimal. In this paper, we derive temporal lift pooling (TLP) from the Lifting Scheme in signal processing to intelligently downsample features of different temporal hierarchies. The Lifting Scheme factorizes input signals into various sub-bands with different frequency, which can be viewed as different temporal movement patterns. Our TLP is a three-stage procedure, which performs signal decomposition, component weighting and information fusion to generate a refined downsized feature map. We select a typical temporal task with long sequences, i.e. continuous sign language recognition (CSLR), as our testbed to verify the effectiveness of TLP. Experiments on two large-scale datasets show TLP outperforms hand-crafted methods and specialized spatial variants by a large margin (1.5%) with similar computational overhead. As a robust feature extractor, TLP exhibits great generalizability upon multiple backbones on various datasets and achieves new state-of-the-art results on two large-scale CSLR datasets. Visualizations further demonstrate the mechanism of TLP in correcting gloss borders. Code is released.