 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reference Vector Adaptation and Mating Selection Strategy via Adaptive Resonance Theory-based Clustering for Many-objective Optimization
May 04, 2022
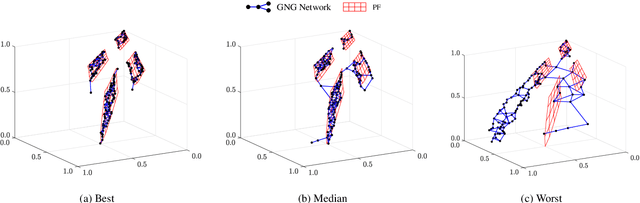
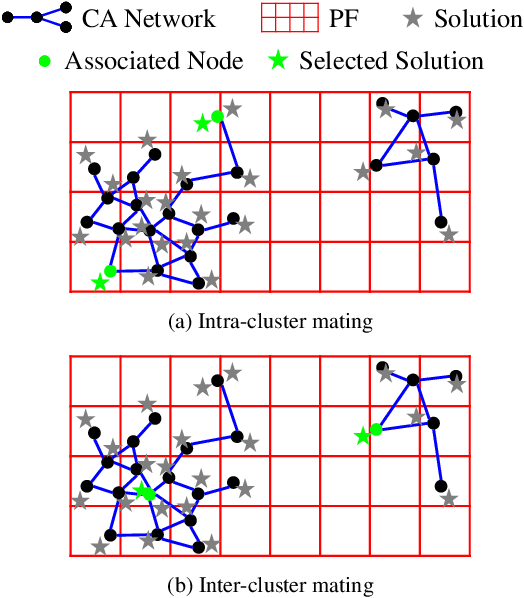

Decomposition-based multiobjective evolutionary algorithms (MOEAs) with clustering-based reference vector adaptation show good optimization performance for many-objective optimization problems (MaOPs). Especially, algorithms that employ a clustering algorithm with a topological structure (i.e., a network composed of nodes and edges) show superior optimization performance to other MOEAs for MaOPs with irregular Pareto optimal fronts (PFs). These algorithms, however, do not effectively utilize information of the topological structure in the search process. Moreover, the clustering algorithms typically used in conventional studies have limited clustering performance, inhibiting the ability to extract useful information for the search process. This paper proposes an adaptive reference vector-guided evolutionary algorithm using an adaptive resonance theory-based clustering with a topological structure. The proposed algorithm utilizes the information of the topological structure not only for reference vector adaptation but also for mating selection. The proposed algorithm is compared with 8 state-of-the-art MOEAs on 78 test problems. Experimental results reveal the outstanding optimization performance of the proposed algorithm over the others on MaOPs with various properties.
SSD-Faster Net: A Hybrid Network for Industrial Defect Inspection
Jul 03, 2022
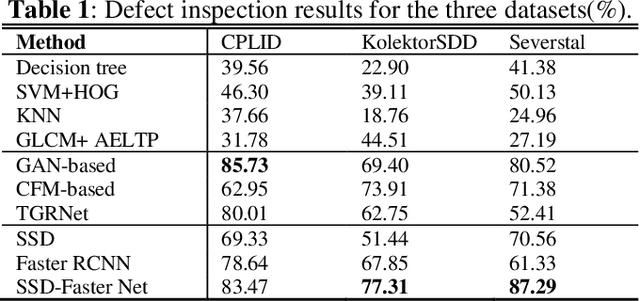
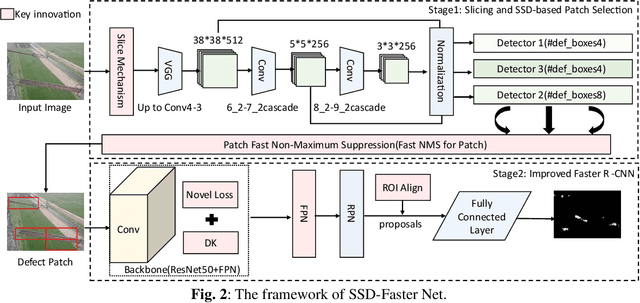
The quality of industrial components is critical to the production of special equipment such as robots. Defect inspection of these components is an efficient way to ensure quality. In this paper, we propose a hybrid network, SSD-Faster Net, for industrial defect inspection of rails, insulators, commutators etc. SSD-Faster Net is a two-stage network, including SSD for quickly locating defective blocks, and an improved Faster R-CNN for defect segmentation. For the former, we propose a novel slice localization mechanism to help SSD scan quickly. The second stage is based on improved Faster R-CNN, using FPN, deformable kernel(DK) to enhance representation ability. It fuses multi-scale information, and self-adapts the receptive field. We also propose a novel loss function and use ROI Align to improve accuracy. Experiments show that our SSD-Faster Net achieves an average accuracy of 84.03%, which is 13.42% higher than the nearest competitor based on Faster R-CNN, 4.14% better than GAN-based methods, more than 10% higher than that of DNN-based detectors. And the computing speed is improved by nearly 7%, which proves its robustness and superior performance.
Self-supervised models of audio effectively explain human cortical responses to speech
May 27, 2022

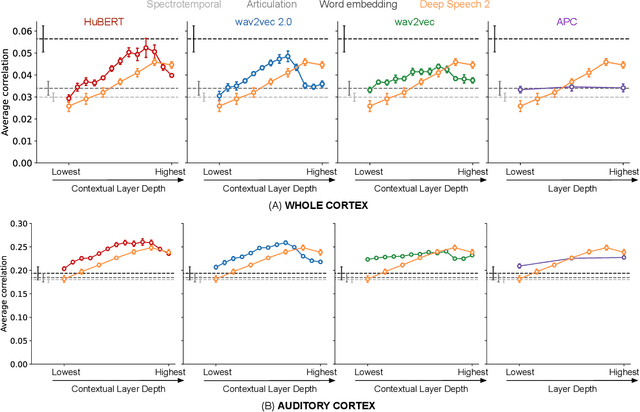
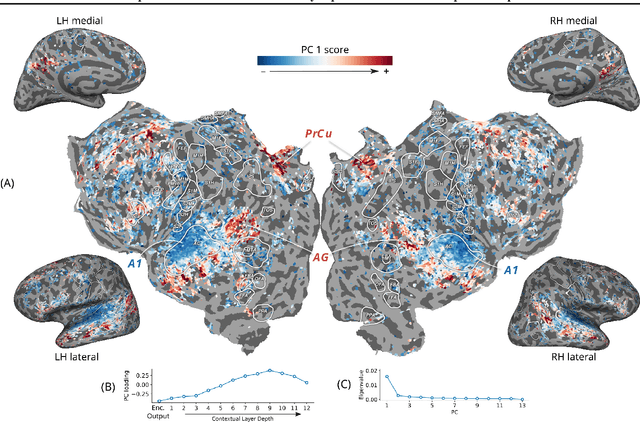
Self-supervised language models are very effective at predicting high-level cortical responses during language comprehension. However, the best current models of lower-level auditory processing in the human brain rely on either hand-constructed acoustic filters or representations from supervised audio neural networks. In this work, we capitalize on the progress of self-supervised speech representation learning (SSL) to create new state-of-the-art models of the human auditory system. Compared against acoustic baselines, phonemic features, and supervised models, representations from the middle layers of self-supervised models (APC, wav2vec, wav2vec 2.0, and HuBERT) consistently yield the best prediction performance for fMRI recordings within the auditory cortex (AC). Brain areas involved in low-level auditory processing exhibit a preference for earlier SSL model layers, whereas higher-level semantic areas prefer later layers. We show that these trends are due to the models' ability to encode information at multiple linguistic levels (acoustic, phonetic, and lexical) along their representation depth. Overall, these results show that self-supervised models effectively capture the hierarchy of information relevant to different stages of speech processing in human cortex.
e-CARE: a New Dataset for Exploring Explainable Causal Reasoning
May 12, 2022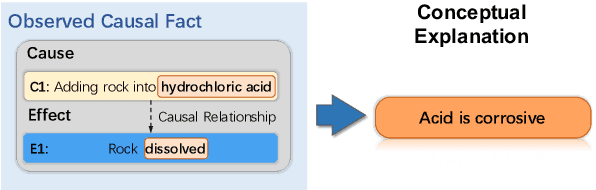
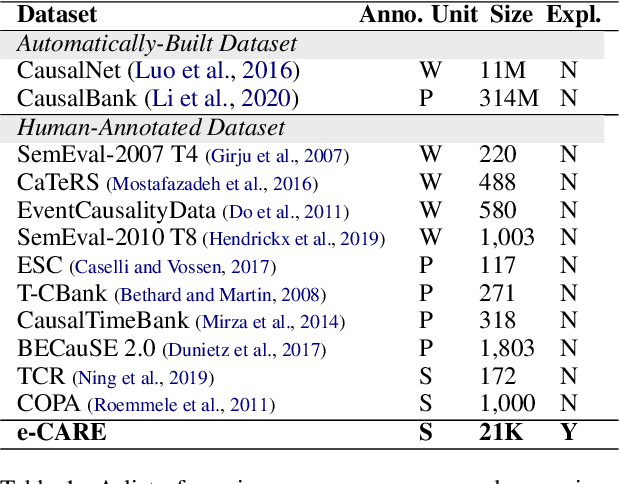
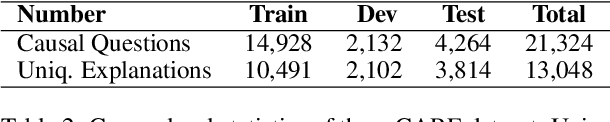
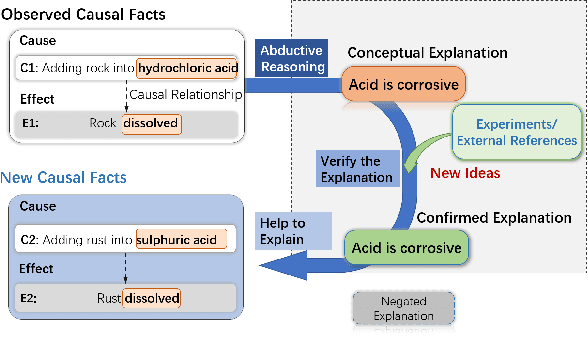
Understanding causality has vital importance for various Natural Language Processing (NLP) applications. Beyond the labeled instances, conceptual explanations of the causality can provide deep understanding of the causal facts to facilitate the causal reasoning process. However, such explanation information still remains absent in existing causal reasoning resources. In this paper, we fill this gap by presenting a human-annotated explainable CAusal REasoning dataset (e-CARE), which contains over 21K causal reasoning questions, together with natural language formed explanations of the causal questions. Experimental results show that generating valid explanations for causal facts still remains especially challenging for the state-of-the-art models, and the explanation information can be helpful for promoting the accuracy and stability of causal reasoning models.
Graph Information Bottleneck for Subgraph Recognition
Oct 12, 2020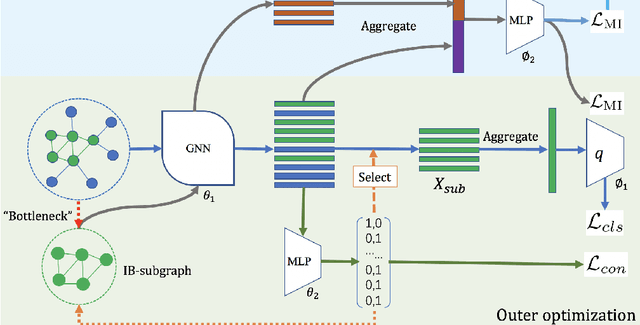
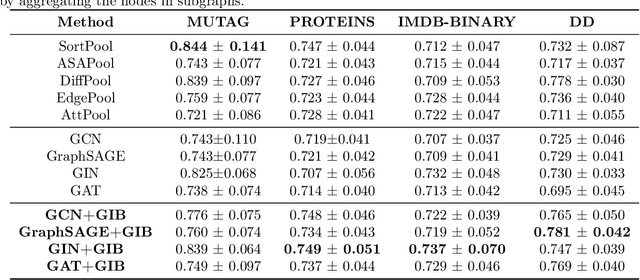
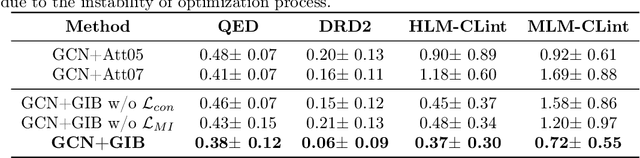
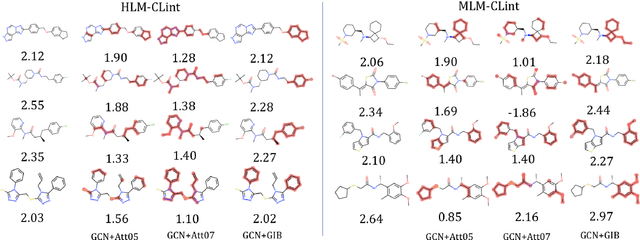
Given the input graph and its label/property, several key problems of graph learning, such as finding interpretable subgraphs, graph denoising and graph compression, can be attributed to the fundamental problem of recognizing a subgraph of the original one. This subgraph shall be as informative as possible, yet contains less redundant and noisy structure. This problem setting is closely related to the well-known information bottleneck (IB) principle, which, however, has less been studied for the irregular graph data and graph neural networks (GNNs). In this paper, we propose a framework of Graph Information Bottleneck (GIB) for the subgraph recognition problem in deep graph learning. Under this framework, one can recognize the maximally informative yet compressive subgraph, named IB-subgraph. However, the GIB objective is notoriously hard to optimize, mostly due to the intractability of the mutual information of irregular graph data and the unstable optimization process. In order to tackle these challenges, we propose: i) a GIB objective based-on a mutual information estimator for the irregular graph data; ii) a bi-level optimization scheme to maximize the GIB objective; iii) a connectivity loss to stabilize the optimization process. We evaluate the properties of the IB-subgraph in three application scenarios: improvement of graph classification, graph interpretation and graph denoising. Extensive experiments demonstrate that the information-theoretic IB-subgraph enjoys superior graph properties.
Regularized Mutual Information Neural Estimation
Nov 16, 2020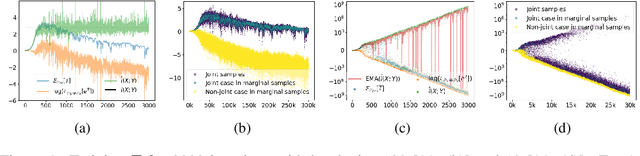
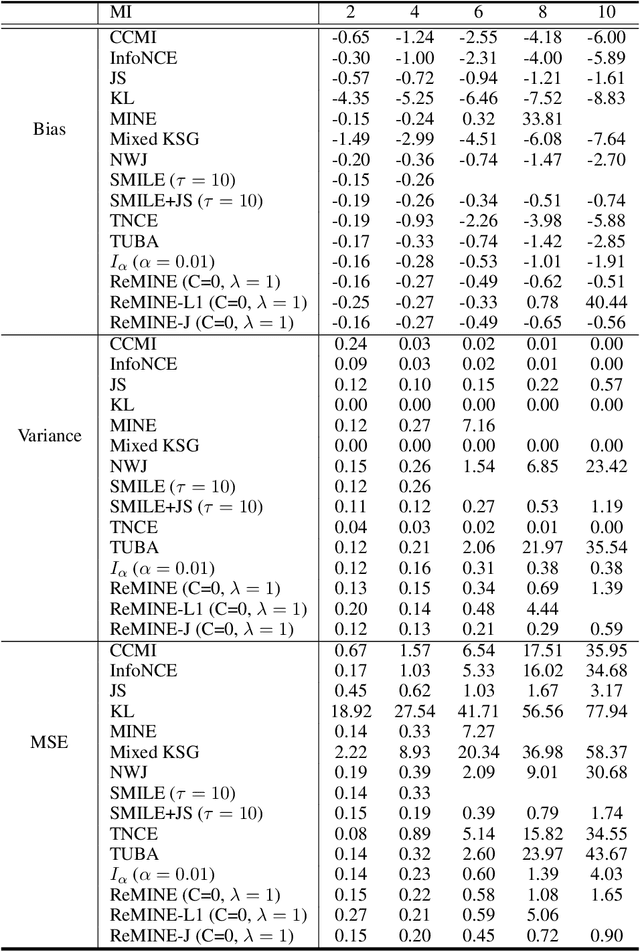
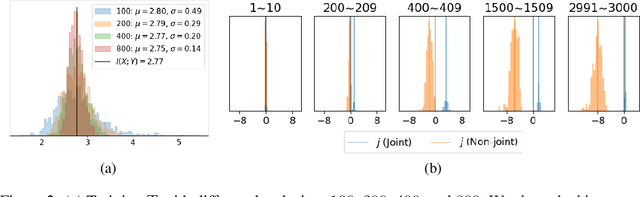
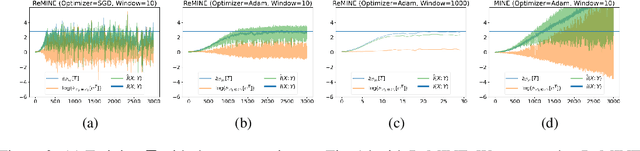
With the variational lower bound of mutual information (MI), the estimation of MI can be understood as an optimization task via stochastic gradient descent. In this work, we start by showing how Mutual Information Neural Estimator (MINE) searches for the optimal function $T$ that maximizes the Donsker-Varadhan representation. With our synthetic dataset, we directly observe the neural network outputs during the optimization to investigate why MINE succeeds or fails: We discover the drifting phenomenon, where the constant term of $T$ is shifting through the optimization process, and analyze the instability caused by the interaction between the $logsumexp$ and the insufficient batch size. Next, through theoretical and experimental evidence, we propose a novel lower bound that effectively regularizes the neural network to alleviate the problems of MINE. We also introduce an averaging strategy that produces an unbiased estimate by utilizing multiple batches to mitigate the batch size limitation. Finally, we show that $L^2$ regularization achieves significant improvements in both discrete and continuous settings.
Micro-video recommendation model based on graph neural network and attention mechanism
May 21, 2022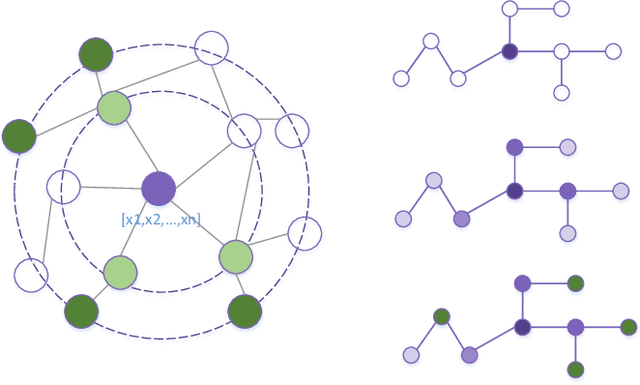
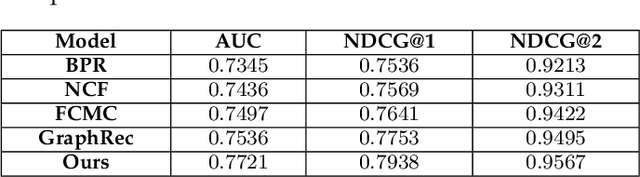
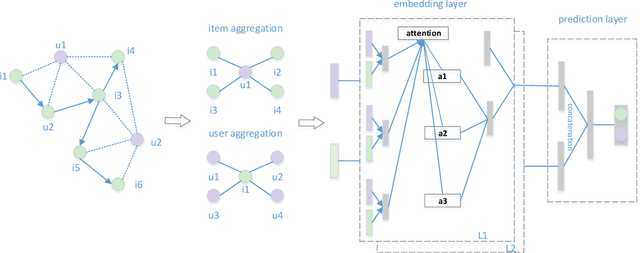
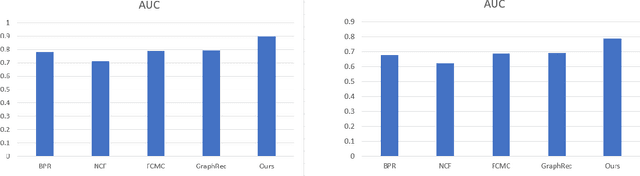
With the rapid development of Internet technology and the comprehensive popularity of Internet applications, online activities have gradually become an indispensable part of people's daily life. The original recommendation learning algorithm is mainly based on user-microvideo interaction for learning, modeling the user-micro-video connection relationship, which is difficult to capture the more complex relationships between nodes. To address the above problems, we propose a personalized recommendation model based on graph neural network, which utilizes the feature that graph neural network can tap deep information of graph data more effectively, and transforms the input user rating information and item side information into graph structure, for effective feature extraction, based on the importance sampling strategy. The importance-based sampling strategy measures the importance of neighbor nodes to the central node by calculating the relationship tightness between the neighbor nodes and the central node, and selects the neighbor nodes for recommendation tasks based on the importance level, which can be more targeted to select the sampling neighbors with more influence on the target micro-video nodes. The pooling aggregation strategy, on the other hand, trains the aggregation weights by inputting the neighborhood node features into the fully connected layer before aggregating the neighborhood features, and then introduces the pooling layer for feature aggregation, and finally aggregates the obtained neighborhood aggregation features with the target node itself, which directly introduces a symmetric trainable function to fuse the neighborhood weight training into the model to better capture the different neighborhood nodes' differential features in a learnable manner to allow for a more accurate representation of the current node features.
Pseudo-Data based Self-Supervised Federated Learning for Classification of Histopathological Images
May 31, 2022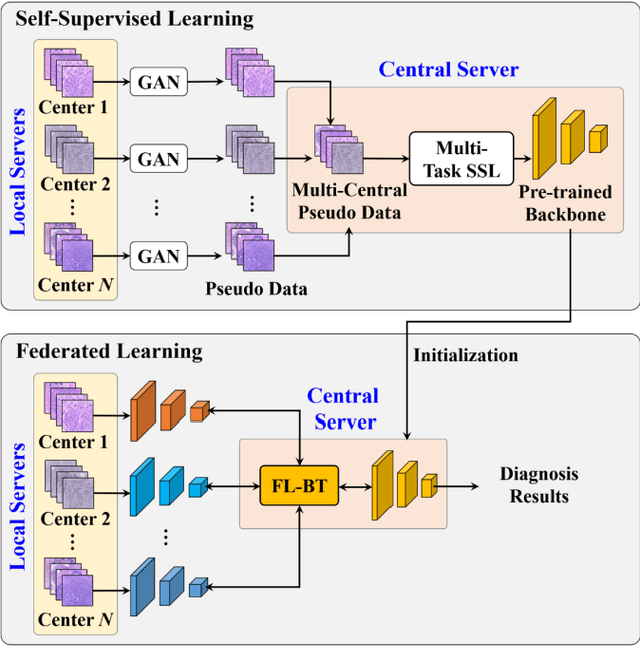
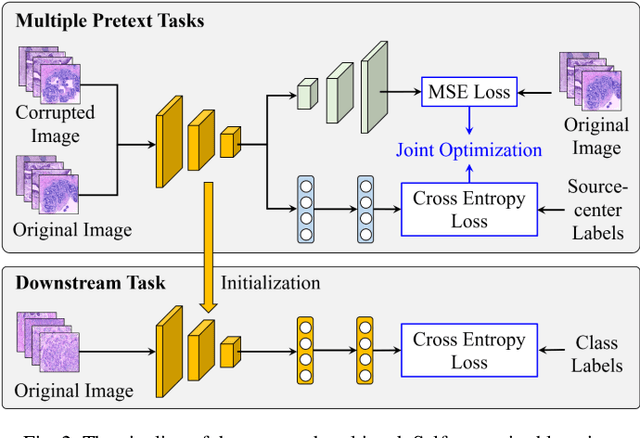
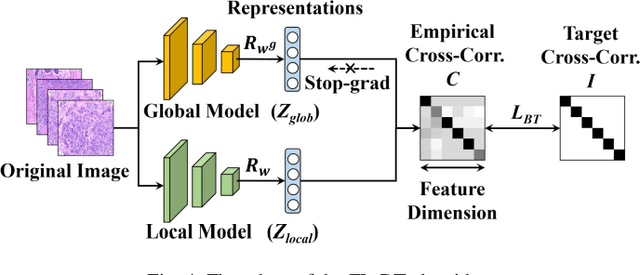
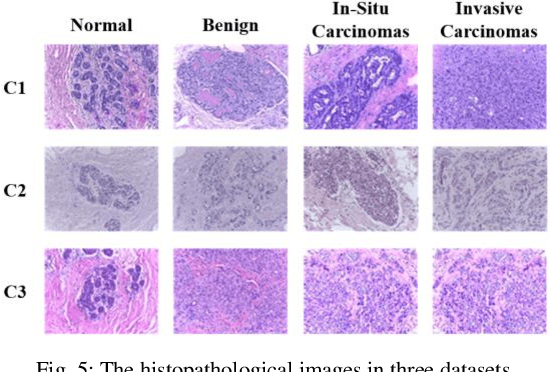
Computer-aided diagnosis (CAD) can help pathologists improve diagnostic accuracy together with consistency and repeatability for cancers. However, the CAD models trained with the histopathological images only from a single center (hospital) generally suffer from the generalization problem due to the straining inconsistencies among different centers. In this work, we propose a pseudo-data based self-supervised federated learning (FL) framework, named SSL-FT-BT, to improve both the diagnostic accuracy and generalization of CAD models. Specifically, the pseudo histopathological images are generated from each center, which contains inherent and specific properties corresponding to the real images in this center, but does not include the privacy information. These pseudo images are then shared in the central server for self-supervised learning (SSL). A multi-task SSL is then designed to fully learn both the center-specific information and common inherent representation according to the data characteristics. Moreover, a novel Barlow Twins based FL (FL-BT) algorithm is proposed to improve the local training for the CAD model in each center by conducting contrastive learning, which benefits the optimization of the global model in the FL procedure. The experimental results on three public histopathological image datasets indicate the effectiveness of the proposed SSL-FL-BT on both diagnostic accuracy and generalization.
Multi-scale Attention Flow for Probabilistic Time Series Forecasting
May 16, 2022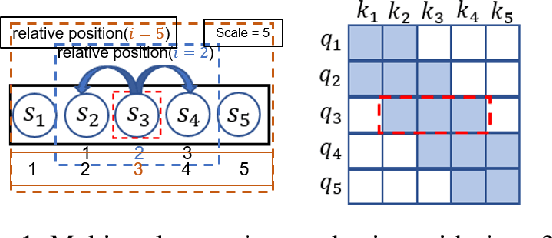
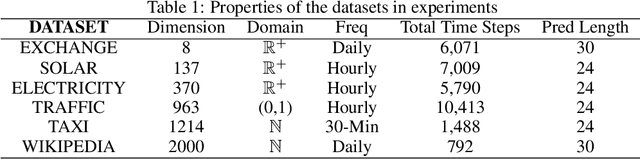
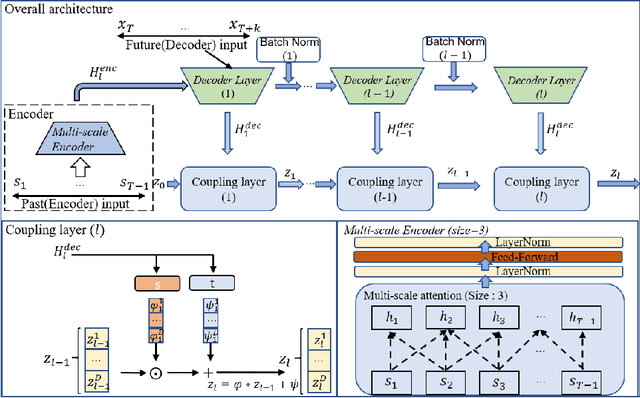
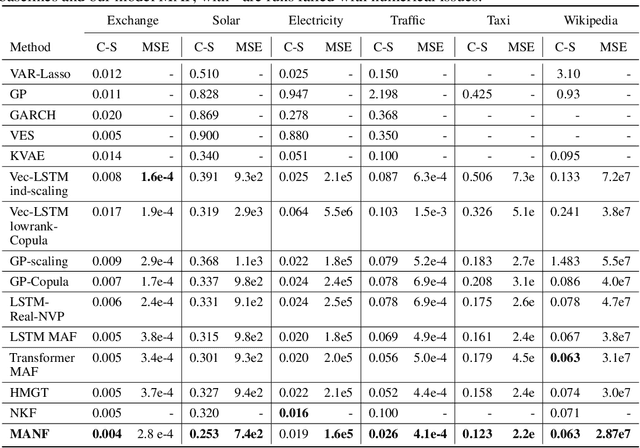
The probability prediction of multivariate time series is a notoriously challenging but practical task. On the one hand, the challenge is how to effectively capture the cross-series correlations between interacting time series, to achieve accurate distribution modeling. On the other hand, we should consider how to capture the contextual information within time series more accurately to model multivariate temporal dynamics of time series. In this work, we proposed a novel non-autoregressive deep learning model, called Multi-scale Attention Normalizing Flow(MANF), where we integrate multi-scale attention and relative position information and the multivariate data distribution is represented by the conditioned normalizing flow. Additionally, compared with autoregressive modeling methods, our model avoids the influence of cumulative error and does not increase the time complexity. Extensive experiments demonstrate that our model achieves state-of-the-art performance on many popular multivariate datasets.
Meta-Learning over Time for Destination Prediction Tasks
Jun 29, 2022
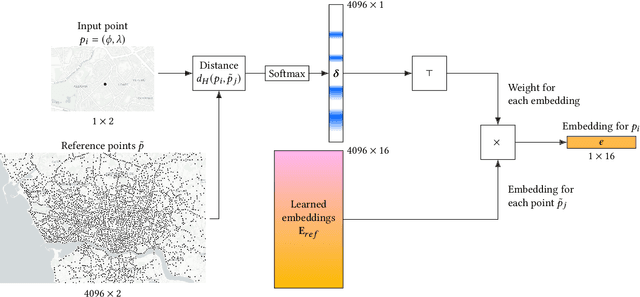

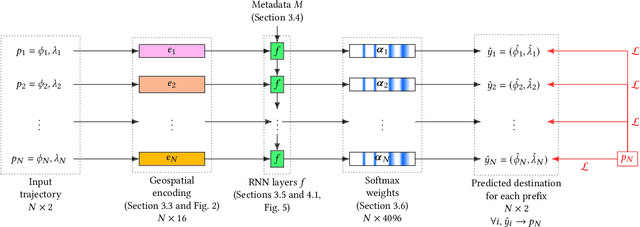
A need to understand and predict vehicles' behavior underlies both public and private goals in the transportation domain, including urban planning and management, ride-sharing services, and intelligent transportation systems. Individuals' preferences and intended destinations vary throughout the day, week, and year: for example, bars are most popular in the evenings, and beaches are most popular in the summer. Despite this principle, we note that recent studies on a popular benchmark dataset from Porto, Portugal have found, at best, only marginal improvements in predictive performance from incorporating temporal information. We propose an approach based on hypernetworks, a variant of meta-learning ("learning to learn") in which a neural network learns to change its own weights in response to an input. In our case, the weights responsible for destination prediction vary with the metadata, in particular the time, of the input trajectory. The time-conditioned weights notably improve the model's error relative to ablation studies and comparable prior work, and we confirm our hypothesis that knowledge of time should improve prediction of a vehicle's intended destination.